文章目录
我们现在想实现这种情况:

Person组件的总人数就是Person中列表的长度
br上的是Count组件,br下的是Person组件。
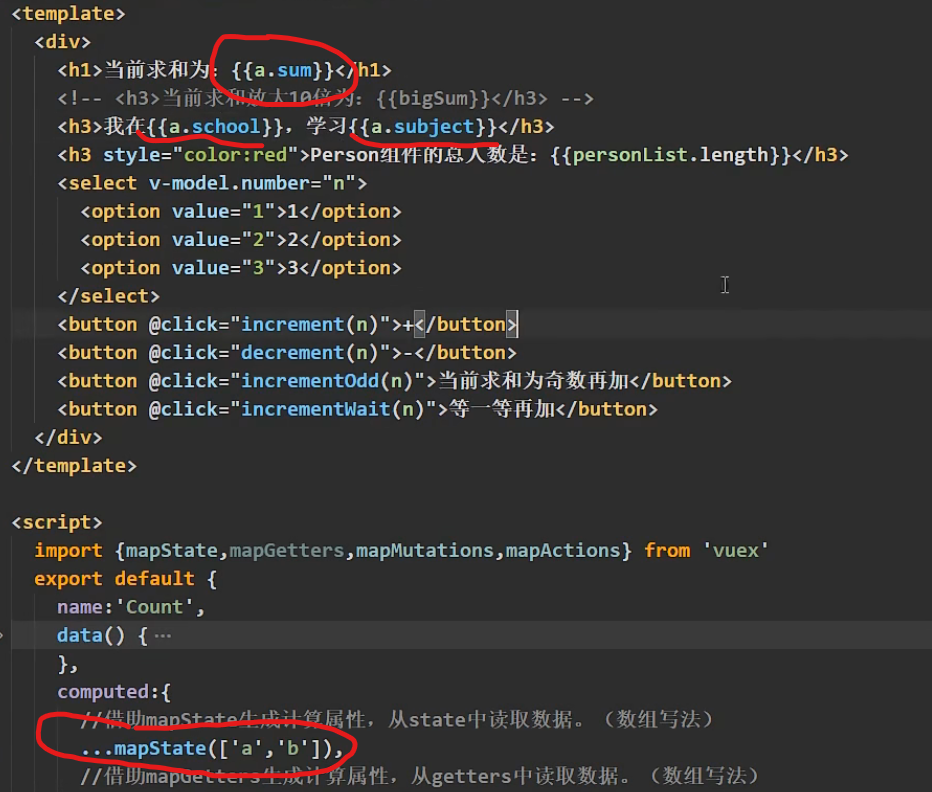
我们通过vuex中的state实现一些数据的多组件共享: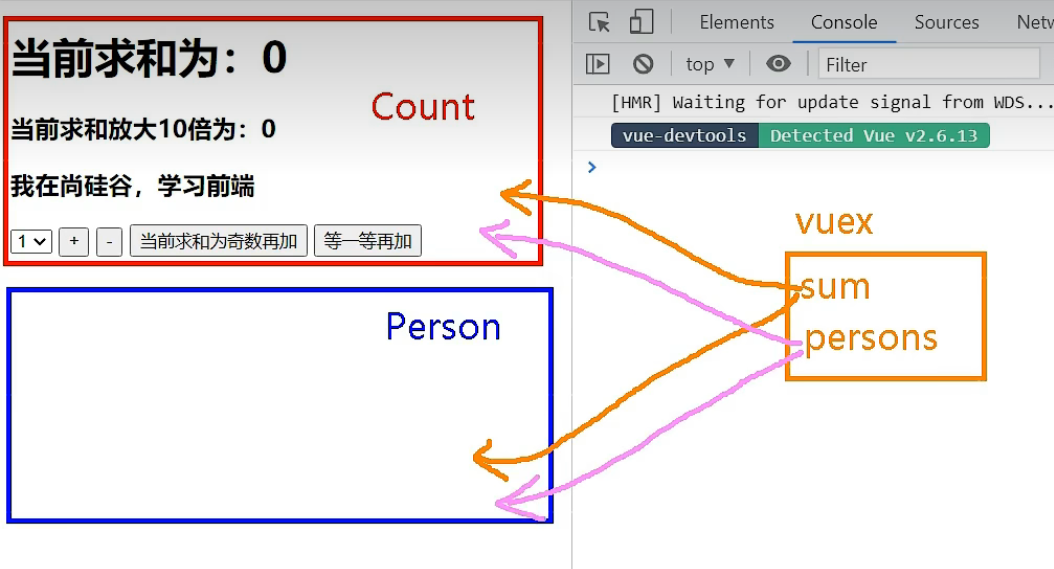
Person.vue
<template>
<div>
<h1>人员列表</h1>
<h3 style="color:red">Count组件求和为:{{sum}}</h3>
<input type="text" placeholder="请输入名字" v-model="name">
<button @click="add">添加</button>
<ul>
<li v-for="p in personList" :key="p.id">{{p.name}}</li>
</ul>
</div>
</template>
<script>
import {nanoid} from 'nanoid'
export default {
name:'Person',
data() {
return {
name:''
}
},
computed:{
personList(){
return this.$store.state.personList
},
sum(){
return this.$store.state.sum
}
},
methods: {
add(){
const personObj = {id:nanoid(),name:this.name}
this.$store.commit('ADD_PERSON',personObj)
this.name = ''
}
},
}
</script>
注意点:
这里使用了id生成类nanoid,如果要使用先安装包
yarn add nanoid
或者
npm install nanoid
使用方法:
import { nanoid } from 'nanoid'
const person = {name:'张三', age:18}
// 最后用nanoid给它添加一个id
person.id = nanoid() //=> "V1StGXR8_Z5jdHi6B-myT"
Count.vue
<template>
<div>
<h1>当前求和为:{{sum}}</h1>
<h3>当前求和放大10倍为:{{bigSum}}</h3>
<h3>我在{{school}},学习{{subject}}</h3>
<h3 style="color:red">Person组件的总人数是:{{personList.length}}</h3>
<select v-model.number="n">
<option value="1">1</option>
<option value="2">2</option>
<option value="3">3</option>
</select>
<button @click="increment(n)">+</button>
<button @click="decrement(n)">-</button>
<button @click="incrementOdd(n)">当前求和为奇数再加</button>
<button @click="incrementWait(n)">等一等再加</button>
</div>
</template>
<script>
import {mapState,mapGetters,mapMutations,mapActions} from 'vuex'
export default {
name:'Count',
data() {
return {
n:1, //用户选择的数字
}
},
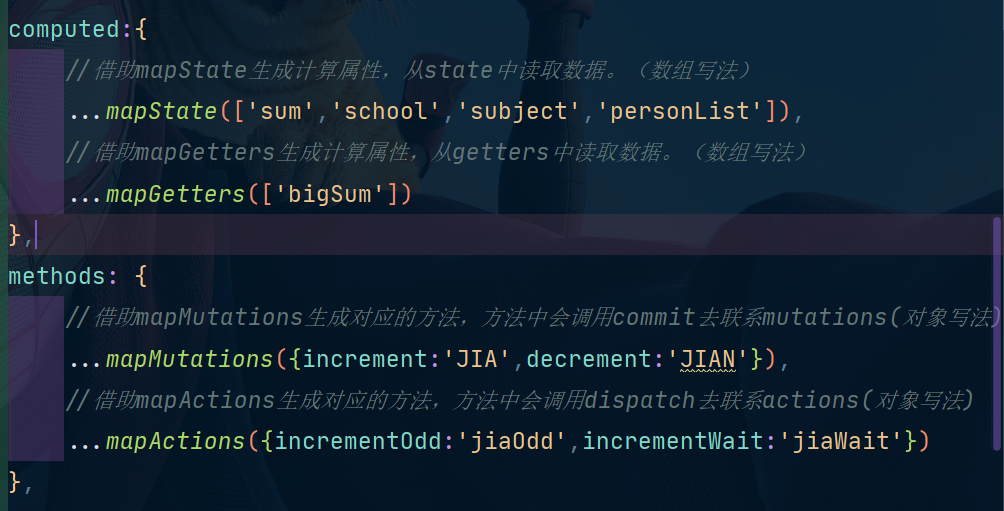
computed:{
//借助mapState生成计算属性,从state中读取数据。(数组写法)
...mapState(['sum','school','subject','personList']),
//借助mapGetters生成计算属性,从getters中读取数据。(数组写法)
...mapGetters(['bigSum'])
},
methods: {
//借助mapMutations生成对应的方法,方法中会调用commit去联系mutations(对象写法)
...mapMutations({increment:'JIA',decrement:'JIAN'}),
//借助mapActions生成对应的方法,方法中会调用dispatch去联系actions(对象写法)
...mapActions({incrementOdd:'jiaOdd',incrementWait:'jiaWait'})
},
mounted() {
// const x = mapState({he:'sum',xuexiao:'school',xueke:'subject'})
// console.log(x)
},
}
</script>
<style lang="css">
button{
margin-left: 5px;
}
</style>
store
//该文件用于创建Vuex中最为核心的store
import Vue from 'vue'
//引入Vuex
import Vuex from 'vuex'
//应用Vuex插件
Vue.use(Vuex)
//准备actions——用于响应组件中的动作
const actions = {
/* jia(context,value){
console.log('actions中的jia被调用了')
context.commit('JIA',value)
},
jian(context,value){
console.log('actions中的jian被调用了')
context.commit('JIAN',value)
}, */
jiaOdd(context,value){
console.log('actions中的jiaOdd被调用了')
if(context.state.sum % 2){
context.commit('JIA',value)
}
},
jiaWait(context,value){
console.log('actions中的jiaWait被调用了')
setTimeout(()=>{
context.commit('JIA',value)
},500)
}
}
//准备mutations——用于操作数据(state)
const mutations = {
JIA(state,value){
console.log('mutations中的JIA被调用了')
state.sum += value
},
JIAN(state,value){
console.log('mutations中的JIAN被调用了')
state.sum -= value
},
ADD_PERSON(state,value){
console.log('mutations中的ADD_PERSON被调用了')
state.personList.unshift(value)
}
}
//准备state——用于存储数据
const state = {
sum:0, //当前的和
school:'尚硅谷',
subject:'前端',
personList:[
{id:'001',name:'张三'}
]
}
//准备getters——用于将state中的数据进行加工
const getters = {
bigSum(state){
return state.sum*10
}
}
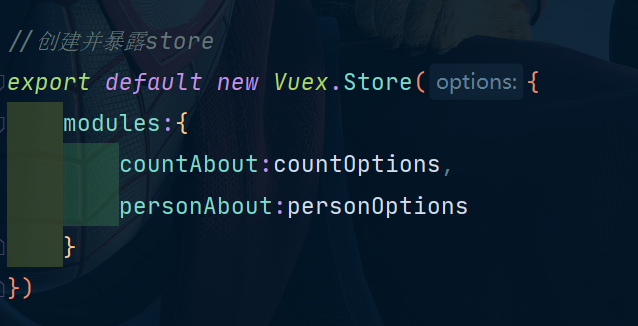
//创建并暴露store
export default new Vuex.Store({
actions,
mutations,
state,
getters
})
我们查看我们前面的代码不难发现一个问题:那就是多个组件的代码都放在了唯一的actions、mutations、state、getters中,我们前面的案例中只涉及到了两个组件,但是如果我们有几百个几千个组件,这些代码全部堆积到一起,会非常的繁杂。所以我们想对他进行一个分类,将各组件的代码分离开来。
原来我们是这样:
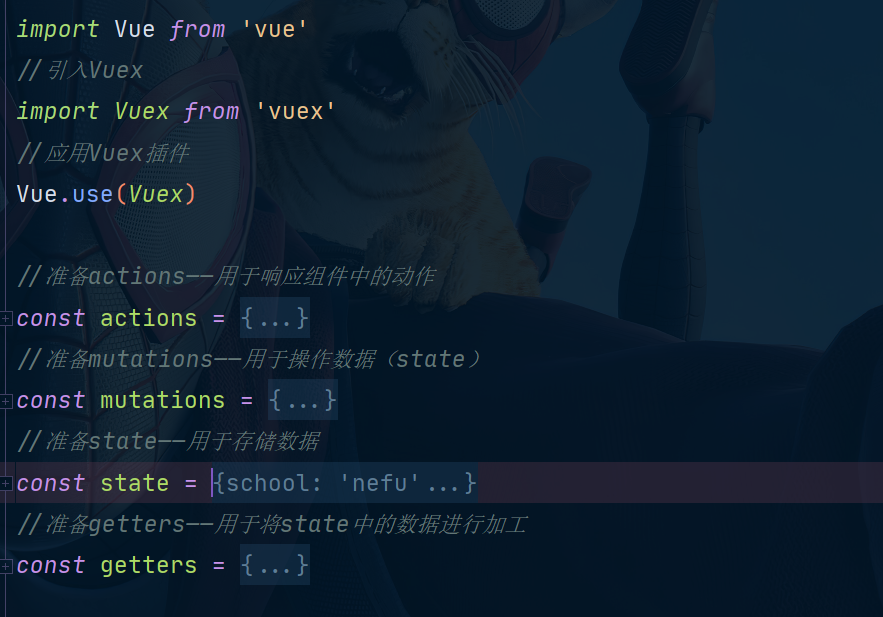
现在我们变成这样:
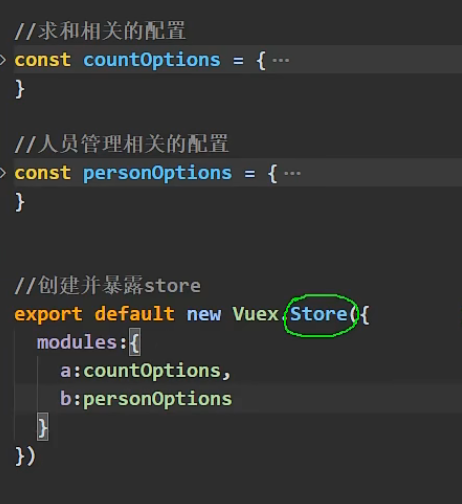
每个配置里面都有其各自的actions、mutations、state、getters。
也就是说现在的store结构发生了变化:

当然这个a,b起的有点随便,我们稍微语义化一下:
因为接口暴露的形式发生了变化,接下来我们的组件里面就要发生一些变化。
先来看看Count.vue:
原来是这样:
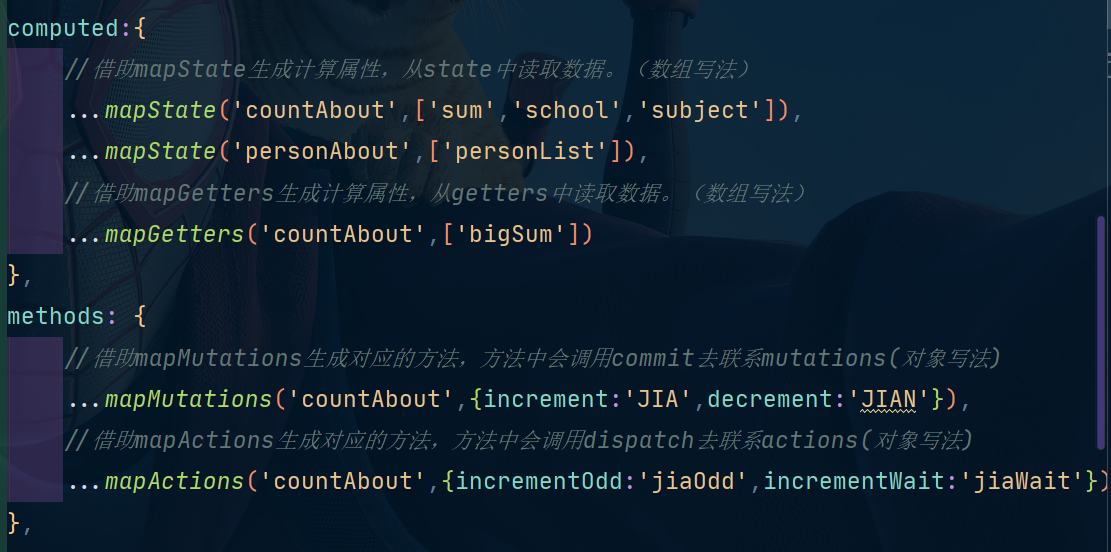
现在变成了这样:
还有一种方法:
最后我们还有最重要的一步:给配置的命名空间打开。
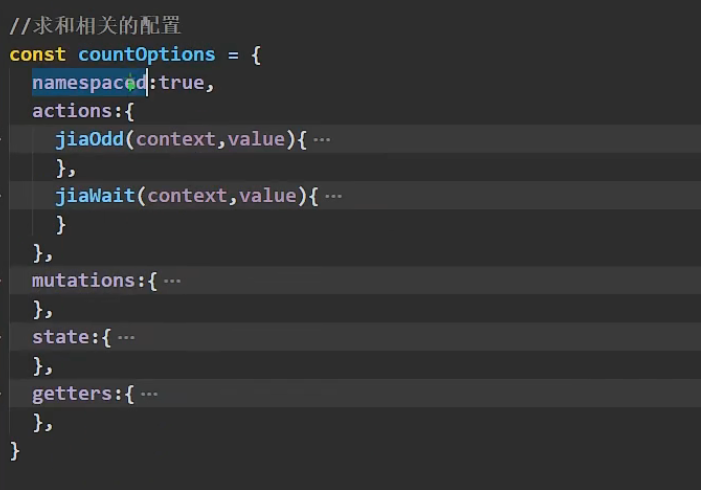
如果我们缺失了这一步,这些map的第一个参数,countAbout、personAbout这些是识别不出来的!
computed:{
//借助mapState生成计算属性,从state中读取数据。(数组写法)
...mapState('countAbout',['sum','school','subject']),
...mapState('personAbout',['personList']),
//借助mapGetters生成计算属性,从getters中读取数据。(数组写法)
...mapGetters('countAbout',['bigSum'])
},
methods: {
//借助mapMutations生成对应的方法,方法中会调用commit去联系mutations(对象写法)
...mapMutations('countAbout',{increment:'JIA',decrement:'JIAN'}),
//借助mapActions生成对应的方法,方法中会调用dispatch去联系actions(对象写法)
...mapActions('countAbout',{incrementOdd:'jiaOdd',incrementWait:'jiaWait'})
},
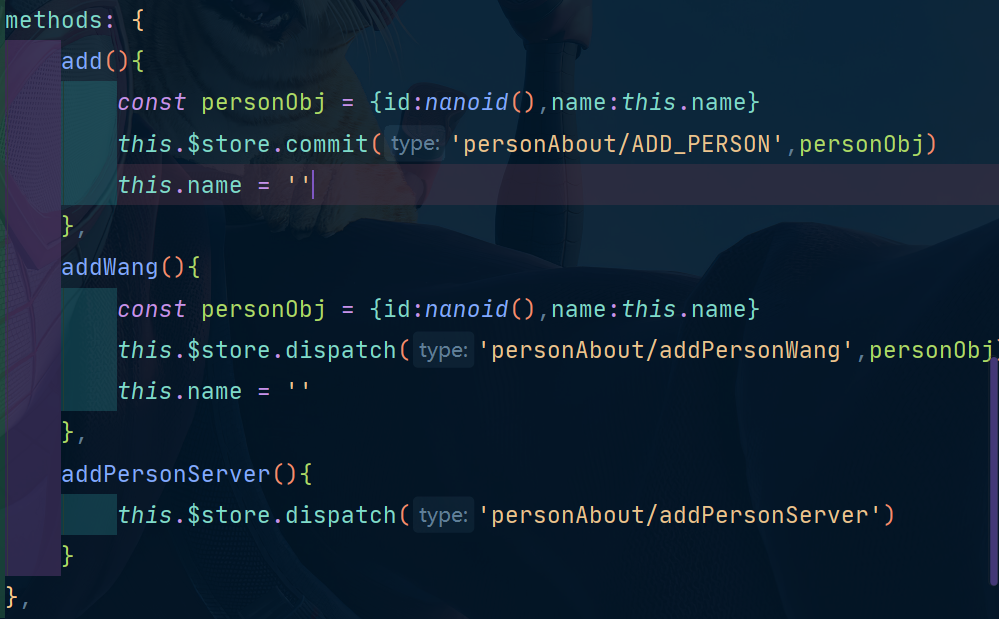
接下来我们修改Person.vue,这里我们不使用map方法,而是使用原生的方法看看怎么修改:
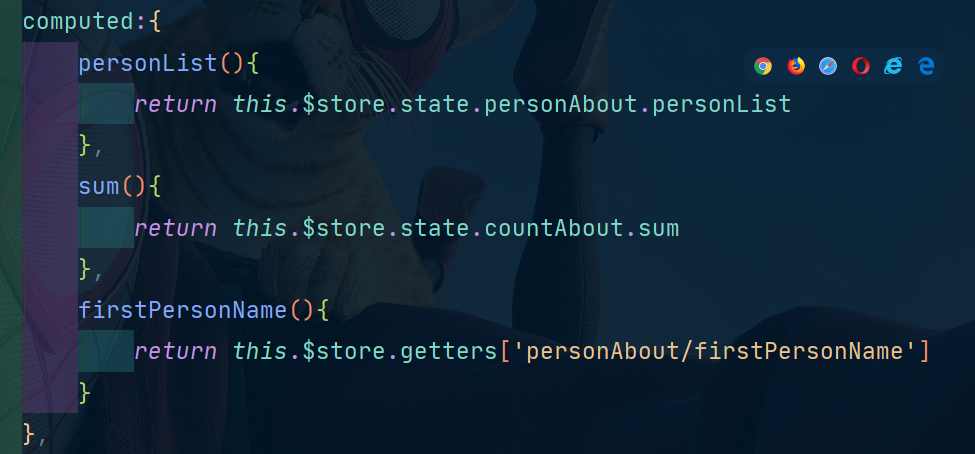
我们上面的firstPersonName这样写是因为:
我们原来store里的state是长这样的:

但是现在我们store里的getters是长这样的:

也就是他的key变成了这种形式,但是我们在使用的对象的属性的时候如果使用的是.这种语法那么这个/是不能使用的,凭借js语法的特性我们可以使用[]语法去访问它的属性。
最后我们还可以对最后一次优化,那就是把分类后的代码分文件放置:
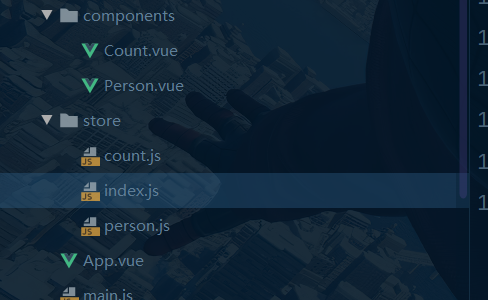
我们来看看这几个文件:
count.js
//求和相关的配置
export default {
namespaced:true,
actions:{
jiaOdd(context,value){
console.log('actions中的jiaOdd被调用了')
if(context.state.sum % 2){
context.commit('JIA',value)
}
},
jiaWait(context,value){
console.log('actions中的jiaWait被调用了')
setTimeout(()=>{
context.commit('JIA',value)
},500)
}
},
mutations:{
JIA(state,value){
console.log('mutations中的JIA被调用了')
state.sum += value
},
JIAN(state,value){
console.log('mutations中的JIAN被调用了')
state.sum -= value
},
},
state:{
sum:0, //当前的和
school:'尚硅谷',
subject:'前端',
},
getters:{
bigSum(state){
return state.sum*10
}
},
}
person.js
//人员管理相关的配置
import axios from 'axios'
import { nanoid } from 'nanoid'
export default {
namespaced:true,
actions:{
addPersonWang(context,value){
if(value.name.indexOf('王') === 0){
context.commit('ADD_PERSON',value)
}else{
alert('添加的人必须姓王!')
}
},
addPersonServer(context){
axios.get('https://api.uixsj.cn/hitokoto/get?type=social').then(
response => {
context.commit('ADD_PERSON',{id:nanoid(),name:response.data})
},
error => {
alert(error.message)
}
)
}
},
mutations:{
ADD_PERSON(state,value){
console.log('mutations中的ADD_PERSON被调用了')
state.personList.unshift(value)
}
},
state:{
personList:[
{id:'001',name:'张三'}
]
},
getters:{
firstPersonName(state){
return state.personList[0].name
}
},
}
index.js
//该文件用于创建Vuex中最为核心的store
import Vue from 'vue'
//引入Vuex
import Vuex from 'vuex'
import countOptions from './count'
import personOptions from './person'
//应用Vuex插件
Vue.use(Vuex)
//创建并暴露store
export default new Vuex.Store({
modules:{
countAbout:countOptions,
personAbout:personOptions
}
})
模块化+命名空间
目的:让代码更好维护,让多种数据分类更加明确。
修改store.js
const countAbout = {
namespaced:true,//开启命名空间
state:{x:1},
mutations: { ... },
actions: { ... },
getters: {
bigSum(state){
return state.sum * 10
}
}
}
const personAbout = {
namespaced:true,//开启命名空间
state:{ ... },
mutations: { ... },
actions: { ... }
}
const store = new Vuex.Store({
modules: {
countAbout,
personAbout
}
})
开启命名空间后,组件中读取state数据:
//方式一:自己直接读取
this.$store.state.personAbout.list
//方式二:借助mapState读取:
...mapState('countAbout',['sum','school','subject']),
开启命名空间后,组件中读取getters数据:
//方式一:自己直接读取
this.$store.getters['personAbout/firstPersonName']
//方式二:借助mapGetters读取:
...mapGetters('countAbout',['bigSum'])
开启命名空间后,组件中调用dispatch
//方式一:自己直接dispatch
this.$store.dispatch('personAbout/addPersonWang',person)
//方式二:借助mapActions:
...mapActions('countAbout',{incrementOdd:'jiaOdd',incrementWait:'jiaWait'})
开启命名空间后,组件中调用commit
//方式一:自己直接commit
this.$store.commit('personAbout/ADD_PERSON',person)
//方式二:借助mapMutations:
...mapMutations('countAbout',{increment:'JIA',decrement:'JIAN'}),
假设我做了一个模块如下:m=Module.newdoclassCendend三个问题:除了对m的引用之外,还有什么方法可以访问C和m中的其他内容?我可以在创建匿名模块后为其命名吗(就像我输入“module...”一样)?如何在使用完匿名模块后将其删除,使其定义的常量不再存在? 最佳答案 三个答案:是的,使用ObjectSpace.此代码使c引用你的类(class)C不引用m:c=nilObjectSpace.each_object{|obj|c=objif(Class===objandobj.name=~/::C$/)}当然这取决于
作为我的Rails应用程序的一部分,我编写了一个小导入程序,它从我们的LDAP系统中吸取数据并将其塞入一个用户表中。不幸的是,与LDAP相关的代码在遍历我们的32K用户时泄漏了大量内存,我一直无法弄清楚如何解决这个问题。这个问题似乎在某种程度上与LDAP库有关,因为当我删除对LDAP内容的调用时,内存使用情况会很好地稳定下来。此外,不断增加的对象是Net::BER::BerIdentifiedString和Net::BER::BerIdentifiedArray,它们都是LDAP库的一部分。当我运行导入时,内存使用量最终达到超过1GB的峰值。如果问题存在,我需要找到一些方法来更正我的代
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
我有一个包含模块的模型。我想在模块中覆盖模型的访问器方法。例如:classBlah这显然行不通。有什么想法可以实现吗? 最佳答案 您的代码看起来是正确的。我们正在毫无困难地使用这个确切的模式。如果我没记错的话,Rails使用#method_missing作为属性setter,因此您的模块将优先,阻止ActiveRecord的setter。如果您正在使用ActiveSupport::Concern(参见thisblogpost),那么您的实例方法需要进入一个特殊的模块:classBlah
我正在编写一个gem,我必须在其中fork两个启动两个webrick服务器的进程。我想通过基类的类方法启动这个服务器,因为应该只有这两个服务器在运行,而不是多个。在运行时,我想调用这两个服务器上的一些方法来更改变量。我的问题是,我无法通过基类的类方法访问fork的实例变量。此外,我不能在我的基类中使用线程,因为在幕后我正在使用另一个不是线程安全的库。所以我必须将每个服务器派生到它自己的进程。我用类变量试过了,比如@@server。但是当我试图通过基类访问这个变量时,它是nil。我读到在Ruby中不可能在分支之间共享类变量,对吗?那么,还有其他解决办法吗?我考虑过使用单例,但我不确定这是
我刚刚被困在这个问题上一段时间了。以这个基地为例:moduleTopclassTestendmoduleFooendend稍后,我可以通过这样做在Foo中定义扩展Test的类:moduleTopmoduleFooclassSomeTest但是,如果我尝试通过使用::指定模块来最小化缩进:moduleTop::FooclassFailure这失败了:NameError:uninitializedconstantTop::Foo::Test这是一个错误,还是仅仅是Ruby解析变量名的方式的逻辑结果? 最佳答案 Isthisabug,or
有时我需要处理键/值数据。我不喜欢使用数组,因为它们在大小上没有限制(很容易不小心添加超过2个项目,而且您最终需要稍后验证大小)。此外,0和1的索引变成了魔数(MagicNumber),并且在传达含义方面做得很差(“当我说0时,我的意思是head...”)。散列也不合适,因为可能会不小心添加额外的条目。我写了下面的类来解决这个问题:classPairattr_accessor:head,:taildefinitialize(h,t)@head,@tail=h,tendend它工作得很好并且解决了问题,但我很想知道:Ruby标准库是否已经带有这样一个类? 最佳
我想获取模块中定义的所有常量的值:moduleLettersA='apple'.freezeB='boy'.freezeendconstants给了我常量的名字:Letters.constants(false)#=>[:A,:B]如何获取它们的值的数组,即["apple","boy"]? 最佳答案 为了做到这一点,请使用mapLetters.constants(false).map&Letters.method(:const_get)这将返回["a","b"]第二种方式:Letters.constants(false).map{|c
我的假设是moduleAmoduleBendend和moduleA::Bend是一样的。我能够从thisblog找到解决方案,thisSOthread和andthisSOthread.为什么以及什么时候应该更喜欢紧凑语法A::B而不是另一个,因为它显然有一个缺点?我有一种直觉,它可能与性能有关,因为在更多命名空间中查找常量需要更多计算。但是我无法通过对普通类进行基准测试来验证这一点。 最佳答案 这两种写作方法经常被混淆。首先要说的是,据我所知,没有可衡量的性能差异。(在下面的书面示例中不断查找)最明显的区别,可能也是最著名的,是你的
我一直致力于让我们的Rails2.3.8应用程序在JRuby下正确运行。一切正常,直到我启用config.threadsafe!以实现JRuby提供的并发性。这导致lib/中的模块和类不再自动加载。使用config.threadsafe!启用:$rubyscript/runner-eproduction'pSim::Sim200Provisioner'/Users/amchale/.rvm/gems/jruby-1.5.1@web-services/gems/activesupport-2.3.8/lib/active_support/dependencies.rb:105:in`co