在 HTML DOM 中,所有事物都是节点。DOM 是被视为节点树的 HTML。
根据 W3C 的 HTML DOM 标准,HTML 文档中的所有内容都是节点:
HTML DOM 将 HTML 文档视作树结构。这种结构被称为节点树:
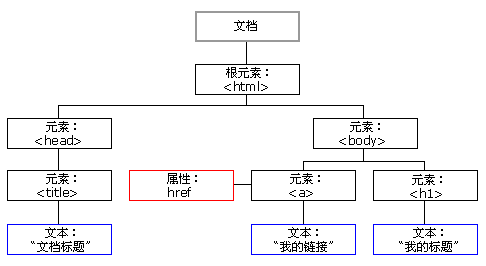
节点树中的节点彼此拥有层级关系。
我们常用父(parent)、子(child)和同胞(sibling)等术语来描述这些关系。父节点拥有子节点。同级的子节点被称为同胞(兄弟或姐妹)。
下面的图片展示了节点树的一部分,以及节点之间的关系:
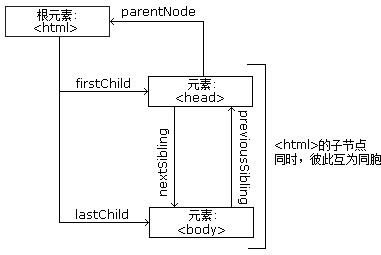
请看下面的 HTML 片段:
从上面的 HTML 中:
并且:
并且:
DOM 处理中的常见错误是希望元素节点包含文本。
在本例中:<title>DOM 教程</title>,元素节点 <title>,包含值为 "DOM 教程" 的文本节点。
可通过节点的 innerHTML 属性来访问文本节点的值。
您将在稍后的章节中学习更多有关 innerHTML 属性的知识。
文章目录1.任务背景2.任务目标3.相关知识点4.任务实操4.1安装配置JDK4.2启动FISCOBCOS4.3下载解压WeBASE-Front4.4拷贝sdk证书文件4.5启动节点4.6访问节点4.7检查运行状态5.任务总结1.任务背景FISCOBCOS其实是有控制台管理工具,用来对区块链系统进行各种管理操作。但是对于初学者来说,还是可视化界面更友好,本节就来介绍WeBASE管理平台,这是一款微众银行开源的自研区块链中间件平台,可以降低区块链使用的门槛,大幅提高区块链应用的开发效率。微众银行是腾讯牵头设立的民营银行,在国内民营银行里还是比较出名的。微众银行参与FISCOBCOS生态建设,一定
基本上我想选择一个节点(div),其中它的子节点(h1,b,h3)包含指定的文本。Childtext1Childtext2...Childtext3我期待的是/html/div/而不是/html/div/h1我在下面有这个,但不幸的是返回了child,而不是div的xpath。expression="//div[contains(text(),'Childtext1')]"doc.xpath(expression)我期待的是/html/div/而不是/html/div/h1那么有没有一种方法可以简单地使用xpath语法来做到这一点? 最佳答案
这个问题在这里已经有了答案:Nokogiri:SelectcontentbetweenelementAandB(3个答案)关闭2年前。我正在从url中抓取文本的div,并想删除具有backtotop类的段落下方的所有内容。我在stackoverflow上看到了一段遍历代码片段,看起来很有希望,但我不知道如何将它合并,所以@el只包含第一个p.backtotop之前的所有内容分区我的代码:@doc=Nokogiri::HTML(open(url))@el=@doc.css("div")[0]end遍历片段:doc=Nokogiri::HTML(code)stop_node=doc.css
我正在尝试为ChefRecipe编写一个库,以简化一些常见的搜索。例如,我希望能够在cookbook/libraries/library.rb中执行类似的操作,然后从同一Recipe中的Recipe中使用它:moduleExampledefself.search_attribute(attribute_name)returnsearch(:nodes,node[attribute_name])endend问题是,在Chef库文件中,node对象或search函数都不可用。似乎可以使用Chef::Search::Query.new().search(...)进行搜索,但我找不到任何可以访
我正在尝试使用Nokogiri来解析带有一些相当古怪的标记的HTML文件。具体来说,我正在尝试获取同时定义了id、多个类和样式的div。标记看起来像这样:titleListofstuff我正在尝试获取里面的问题.我可以毫无问题地获得具有单个id属性的div,但我想不出一种方法让Nokogiri获取具有和两个id类的div。所以这些工作正常:content=@doc.xpath("//div[id='foo']")content=@doc.css('div#foo')但是这些不返回任何东西:content=@doc.xpath("//div[id='bar']")content=@doc
elasticsearch查看当前集群中的master节点是哪个需要使用_cat监控命令,具体如下。查看方法es主节点确定命令,以kibana上查看示例如下:GET_cat/nodesv返回结果示例如下:ipheap.percentram.percentcpuload_1mload_5mload_15mnode.rolemastername172.16.16.188529952.591.701.45mdi-elastic3172.16.16.187329950.990.991.19mdi-elastic2172.16.16.231699940.871.001.03mdi-elastic4172
Kubernetes(K8s)是一个用于管理容器化应用程序的开源平台,可以帮助开发人员更轻松地部署、管理和扩展应用程序。在Kubernetes中,集群划分是一种重要的概念,可以帮助我们更好地组织和管理集群中的节点和资源。本文将介绍如何使用Kubernetes对集群进行划分,并提供详细的操作示例,希望能够帮助读者更好地了解和使用Kubernetes平台。Node划分Node划分是将集群中的节点按照一定的规则进行划分。在Kubernetes中,可以使用NodeSelector和Affinity机制来实现Node划分。NodeSelectorNodeSelector是一种将Pod调度到符合特定节点标
我有这样的代码:@doc=Nokogiri::HTML(open(url)@doc.xpath(query).eachdo|html|putshtml#howgetcontentofanodeend我如何获取节点的内容而不是像这样: 最佳答案 这是READMEfile中的概要示例为Nokogiri展示了一种使用CSS、XPath或混合的方法:require'nokogiri'require'open-uri'#GetaNokogiri::HTML:Documentforthepagewe’reinterestedin...doc=N
有没有什么干净的方法可以用Nokogiri获取文本节点的内容?现在我正在使用some_node.at_xpath("//whatever").first.content这对于获取文本来说似乎真的很冗长。 最佳答案 您只想要文本?doc.search('//text()').map(&:text)也许您不想要所有的空白和噪音。如果您只想要包含单词字符的文本节点,doc.search('//text()').map(&:text).delete_if{|x|x!~/\w/}编辑:看来您只想要单个节点的文本内容:some_node.at_
使用Rails5、Ruby2.4。如果我使用Nokogiri解析定位了一个节点,我将如何找到在我找到的节点之前出现但不包含该找到的节点的所有节点?也就是说,假设我的文档是HelloHowdyNext然后我运行一个查询node=doc.search('//*[contains(@class,"def")]').first我如何找到所有前面的节点(不包括我刚刚确定的节点)?我期望的节点是HelloHowdy 最佳答案 您只需要遍历叶节点,直到到达目标节点。#Nodetoexcludenode=doc.search('//*[contai