单链表的实现【01】:Student-Management-System 只体现了项目功能实现,未对代码部分做出说明。
故新增随笔进行补充说明代码部分。
重构代码,迭代版本:Student Mangement System(Version 2.0)
基于单链表实现就离不开链表的几个重要概念:头结点、首元结点、头指针
线性表链式存储结构的特点是:用一组任意的存储单元存储线性表的数据元素(这组存储单元可以是连续的,也可以是不连续的)。
根据链表结点所含指针个数、指针指向和指针连接方式,可将链表分为单链表、循环链表、双向链表、二叉链表、十字链表、邻接表、邻接多重表等
本随笔基于单链表实现,这里重点介绍它。
? 不带附加结点(即头结点)的单链表
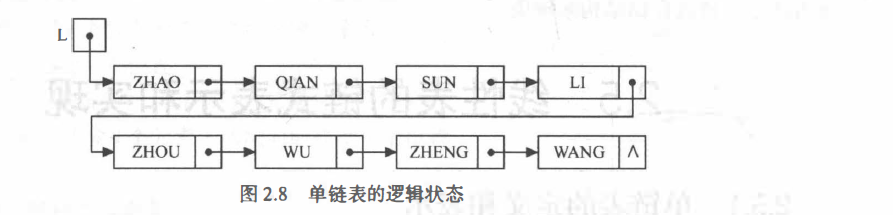
? 带附加结点(即头结点)的单链表

首元结点:指链表中存储第一个数据元素a1的结点
头结点:在首元结点之前附设的一个结点,其指针域指向首元结点
头指针:指向链表中第一个结点的指针
若链表设有头结点,则头指针所指结点为线性表的头结点;
若链表不设头结点,则头指针所指结点为该线性表的首元结点

? 链表增加头结点的作用如下:
(1)便于首元结点的处理增加了头结点后,首元结点的地址保存在头结点(即其“前驱” 结点)的指针域中,则对链表的第一个数据元素的操作与其他数据元素相同,无需进行特殊处理。
(2)便于空表和非空表的统一处理当链表不设头结点时,假设L 为单链表的头指针,它应该指向首元结点,则当单链表为长度n 为0 的空表时, L 指针为空(判定空表的条件可记为:L== NULL)。
? 为了提高程序的可读性,在此对同一结构体指针类型起了两个名称,LinkList 与LNode* , 两者本质上是等价的。通常习惯上用LinkList 定义单链表,强调定义的是某个单链表的头指针;用LNode *定义指向单链表中任意结点的指针变量
#define ERROR -1 // 错误
#define OK 0 // 成功
#define OVERFLOW -2 // 溢出
#define TRUE 1 // 真
#define FALSE 0 // 假
typedef struct
{
char stu_name[10]; // 学生姓名
char stu_sex[10]; // 学生性别
int stu_age; // 学生年龄
int stu_id; // 学生学号
}Student_T;
typedef Student_T ElemType;
typedef struct LNode_T
{
ElemType data; // 结点数据域
struct LNode_T *next; // 结点指针域
}LNode_T, *LinkList_T; //LinkList_T 为指向结构体LNode_T的指针类型
int list_init(LinkList_T *L)
{
// 构造一个空的单链表
// 生成新结点作为头结点,用头指针*L(即单链表L)指向头结点
*L = (LNode_T *)malloc(sizeof(LNode_T));
if (NULL == *L)
exit(OVERFLOW);
memset(*L, 0, sizeof(LNode_T));
(*L)->next = NULL;
return OK;
}
int list_destory(LinkList_T *L)
{
// 释放所有结点(包括头结点)空间
LNode_T *temp;
while (*L)
{
temp = *L;
*L = (*L)->next;
free(temp);
}
return OK;
}
LNode_T * list_locate(LinkList_T L, int stu_id)
{
// p指向首元结点
LNode_T *p = L->next;
LNode_T *q = NULL;
while (p != NULL)
{
if (stu_id == p->data.stu_id)
{
q = p;
break;
}
p = p->next;
}
return q;
}
int list_update(LinkList_T L, int stu_id, const char *stu_name)
{
int result = ERROR;
LNode_T *p_node = list_locate(L, stu_id);
if (NULL != p_node)
{
strcpy(p_node->data.stu_name, stu_name);
result = OK;
}
return result;
}
int list_delete(LinkList_T *L, int stu_id)
{
// p指向头结点
LNode_T *p;
LNode_T *q;
int is_found = ERROR;
for (q = NULL, p = *L; p != NULL; q = p, p = p->next)
{
if (stu_id == p->data.stu_id)
{
q->next = p->next;
free(p);
is_found = OK;
break;
}
}
return is_found;
}
int list_create_r(LinkList_T *L, ElemType elem)
{
// r指向头结点
LNode_T *r = (*L);
while (r->next != NULL)
{
r = r->next;
}
LNode_T *p = (LNode_T *)malloc(sizeof(LNode_T));
p->data = elem;
p->next = NULL;
r->next = p;
return OK;
int list_traverse(LinkList_T L)
{
// p指向首元结点
LNode_T *p;
for (p = L->next; p != NULL; p = p->next)
{
printf("%d %s %s %d\n", p->data.stu_id, p->data.stu_name,
p->data.stu_sex, p->data.stu_age);
}
return OK;
}
单链表的实现过程,需要考虑是否附加头结点,有头结点和没有头结点的实现会有所不同
单链表的操作可以独立封装,根据具体的应用场景可以进行二次封装
数据结构第二版:C语言版 【严蔚敏】 第二章 线性表(链表)
我有一个用户工厂。我希望默认情况下确认用户。但是鉴于unconfirmed特征,我不希望它们被确认。虽然我有一个基于实现细节而不是抽象的工作实现,但我想知道如何正确地做到这一点。factory:userdoafter(:create)do|user,evaluator|#unwantedimplementationdetailshereunlessFactoryGirl.factories[:user].defined_traits.map(&:name).include?(:unconfirmed)user.confirm!endendtrait:unconfirmeddoenden
华为OD机试题本篇题目:明明的随机数题目输入描述输出描述:示例1输入输出说明代码编写思路最近更新的博客华为od2023|什么是华为od,od薪资待遇,od机试题清单华为OD机试真题大全,用Python解华为机试题|机试宝典【华为OD机试】全流程解析+经验分享,题型分享,防作弊指南华为o
C#实现简易绘图工具一.引言实验目的:通过制作窗体应用程序(C#画图软件),熟悉基本的窗体设计过程以及控件设计,事件处理等,熟悉使用C#的winform窗体进行绘图的基本步骤,对于面向对象编程有更加深刻的体会.Tutorial任务设计一个具有基本功能的画图软件**·包括简单的新建文件,保存,重新绘图等功能**·实现一些基本图形的绘制,包括铅笔和基本形状等,学习橡皮工具的创建**·设计一个合理舒适的UI界面**注明:你可能需要先了解一些关于winform窗体应用程序绘图的基本知识,以及关于GDI+类和结构的知识二.实验环境Windows系统下的visualstudio2017C#窗体应用程序三.
//1.验证返回状态码是否是200pm.test("Statuscodeis200",function(){pm.response.to.have.status(200);});//2.验证返回body内是否含有某个值pm.test("Bodymatchesstring",function(){pm.expect(pm.response.text()).to.include("string_you_want_to_search");});//3.验证某个返回值是否是100pm.test("Yourtestname",function(){varjsonData=pm.response.json
MIMO技术的优缺点优点通过下面三个增益来总体概括:阵列增益。阵列增益是指由于接收机通过对接收信号的相干合并而活得的平均SNR的提高。在发射机不知道信道信息的情况下,MIMO系统可以获得的阵列增益与接收天线数成正比复用增益。在采用空间复用方案的MIMO系统中,可以获得复用增益,即信道容量成倍增加。信道容量的增加与min(Nt,Nr)成正比分集增益。在采用空间分集方案的MIMO系统中,可以获得分集增益,即可靠性性能的改善。分集增益用独立衰落支路数来描述,即分集指数。在使用了空时编码的MIMO系统中,由于接收天线或发射天线之间的间距较远,可认为它们各自的大尺度衰落是相互独立的,因此分布式MIMO
遍历文件夹我们通常是使用递归进行操作,这种方式比较简单,也比较容易理解。本文为大家介绍另一种不使用递归的方式,由于没有使用递归,只用到了循环和集合,所以效率更高一些!一、使用递归遍历文件夹整体思路1、使用File封装初始目录,2、打印这个目录3、获取这个目录下所有的子文件和子目录的数组。4、遍历这个数组,取出每个File对象4-1、如果File是否是一个文件,打印4-2、否则就是一个目录,递归调用代码实现publicclassSearchFile{publicstaticvoidmain(String[]args){//初始目录Filedir=newFile("d:/Dev");Datebeg
1.在Python3中,下列关于数学运算结果正确的是:(B)a=10b=3print(a//b)print(a%b)print(a/b)A.3,3,3.3333...B.3,1,3.3333...C.3.3333...,3.3333...,3D.3.3333...,1,3.3333...解析: 在Python中,//表示地板除(向下取整),%表示取余,/表示除(Python2向下取整返回3)2.如下程序Python2会打印多少个数:(D)k=1000whilek>1: print(k)k=k/2A.1000 B.10C.11D.9解析: 按照题意每次循环K/2,直到K值小于等
通常,数组被实现为内存块,集合被实现为HashMap,有序集合被实现为跳跃列表。在Ruby中也是如此吗?我正在尝试从性能和内存占用方面评估Ruby中不同容器的使用情况 最佳答案 数组是Ruby核心库的一部分。每个Ruby实现都有自己的数组实现。Ruby语言规范只规定了Ruby数组的行为,并没有规定任何特定的实现策略。它甚至没有指定任何会强制或至少建议特定实现策略的性能约束。然而,大多数Rubyist对数组的性能特征有一些期望,这会迫使不符合它们的实现变得默默无闻,因为实际上没有人会使用它:插入、前置或追加以及删除元素的最坏情况步骤复
在ruby中,你可以这样做:classThingpublicdeff1puts"f1"endprivatedeff2puts"f2"endpublicdeff3puts"f3"endprivatedeff4puts"f4"endend现在f1和f3是公共(public)的,f2和f4是私有(private)的。内部发生了什么,允许您调用一个类方法,然后更改方法定义?我怎样才能实现相同的功能(表面上是创建我自己的java之类的注释)例如...classThingfundeff1puts"hey"endnotfundeff2puts"hey"endendfun和notfun将更改以下函数定
我目前有一个reddit克隆类型的网站。我正在尝试根据我的用户之前喜欢的帖子推荐帖子。看起来K最近邻或k均值是执行此操作的最佳方法。我似乎无法理解如何实际实现它。我看过一些数学公式(例如k表示维基百科页面),但它们对我来说并没有真正意义。有人可以推荐一些伪代码,或者可以查看的地方,以便我更好地了解如何执行此操作吗? 最佳答案 K最近邻(又名KNN)是一种分类算法。基本上,您采用包含N个项目的训练组并对它们进行分类。如何对它们进行分类完全取决于您的数据,以及您认为该数据的重要分类特征是什么。在您的示例中,这可能是帖子类别、谁发布了该项