本篇内容一共3500字,以猫狗分类项目为例展示对ModelArts所有基础用法。这些模块在一次模型训练中不需全部用到,请根据需要跳转到相应模块:.
- 想快速完整体验深度学习/机器学习流程的初学者->自动学习
- 已经完成项目代码,想提高训练速度/习惯使用notebook,想要边写边调试的专业人士->开发环境
- 需要用到逐个功能/在其中订阅个别产品(如算法、AI应用等)->数据管理、算法管理、训练管理、AI应用管理、部署上线
文章目录
ModelArts是华为开发的人工智能领域使用的线上云平台,可以有效解决算法工程师们设备硬件性能低,不能够高效地训练模型、评估效果等问题。就比如说,尤其是接触深度学习以来,随着模型层数越来越深,自己的电脑配置已经远远达不到跑模型的标准了,但又不想立即换电脑。这时按需收费的云平台就是最合适的选择,ModelArts就是这类产品。
话不多说,上教程。
在华为云官网上切换为中国站。

点击人工智能->AI平台ModelArts。

如果之前没有华为云账号需要注册一个,并且需要实名认证,此处需要18岁以上,若是未成年,可以拿家长的身份证进行认证。登录完之后选择管理控制台。

机器学习、深度学习需要训练样本,所以想在云端操作数据,首先需要将本地数据上传到华为云的服务器中。但是只依靠电脑上传效率低,如果数据量过大的话,需要下一个配套软件OBS Browser+。
下载方式很简单,打开此链接华为云OBS Browser+下载,选择合适的版本进行安装。

下载后登录有三种方式,AK密钥方式、账号登录、授权码登录。第一次可以使用AK和账号登录。





创建完成之后将数据上传即可。

此步骤是通过机器学习使不具备算法开发能力的业务开发者实现算法的开发,也可以用来帮助初学者了解整个机器学习/深度学习的流程。这里会从零完整演示一个项目,如果读者是专业人士,请移步到板块二。


这里以物体检测为例。物体检测与图像分类的区别是它除了能够识别类别,还能判断出物体的位置。


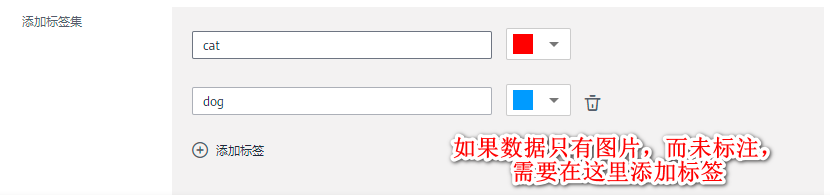
如果数据集已经完成标注可以跳过此步。



这样就标记好一张照片啦!接下来把剩下的都标记出来。
如果数据集中自带标记数据,就将标记的xml文件和源图在OBS中存储放在一个文件夹中,在已标记中同步数据源即可。如图所示:

使用的是华为云中自带的算法训练,所以相当“傻瓜式操作”,上手非常容易。


确认提交后,等待一段时间。注意自动学习免费版本仅用于体验,训练超过一小时会自动终止,相当于白训练了,所以样本量不能太大!博主训练了将近500张图片,训练了25分钟(效率可参考)。出现以下界面就代表训练完成了。接下来就需要部署上线,测试我们模型在真实情况下的准确率。

点击上传、预测即可显示出算法的威力,仅有500张训练照片,可以看出来云端内置算法预测精度还是比较准确的。

此模块可以用来标注数据,存储训练数据,也可以将自己创建的数据分享到社区。如果数据量少的可以直接在这个步骤上传,数据量大的需要借助华为云对象存储OBS将数据批量上传,速度非常快。
想要把OBS的数据加载到ModelArts,使他们产生联系,首先需要创建一个数据集。如果在自动学习中已经体验一遍了,这里应该有刚才加载的数据集,若没有,则需要按照上文同样方法进行创建。

步骤与上文自动学习部分数据标注大致相同。当然这里可以团队合作一起标注。
但需要注意的是尽管有多边形可以更精准的勾勒出狗狗位置,但与算法不兼容,训练时会报错;后面几种效果也不是很理想,所以最好选用矩形标记。

当数据标注完成后,点击发布,可以生成一个版本,再后续训练过程中可以直接使用,或在下一个操作中出错可以恢复到当前状态。


团队一起合作标注的步骤是首先创建一个团队。

其次在标注作业创建过程中选择“启用团队标注”,选择对应团队即可。

此模块是针对图像的预处理模块,如数据清洗、数据增强等可以使数据更可靠,从而提升模型预测准确率。目前只包含图像预处理,文本预处理需要自行解决。
步骤为:点击数据处理->创建->选择合适的处理方式(数据增强/数据清洗等)->定义图片输入输出目录->点击创建,然后等待部署成功,显示如下。

开发环境相当于为开发者创建一个可以在线编写代码的集成环境IDE,可以将本地代码复制到这里,也可以直接编写,方便调试。在这一步直接像在自己电脑上的notebook里面一样操作,只是使用了云端的CPU和GPU进行加速,针对此项目不需要再使用后续模块。

创建完之后点击进入notebook。

输入以下命令并运行,可以将OBS数据同步过来。第一个路径指OBS中项目文件路径,第二个指服务器存放路径。
import moxing as mox
mox.file.copy_parallel('obs://XXX/XXX','/home/ma-user/work')



中途创建可视化,打开terminal输入tensorflow --logdir 存放路径

打开控制板中的tensorboard即可看到

其实相当于算法代码管理,可以保留原始版本记录,将代码更好的管理起来,但在此模块中并不能训练。
在上传到ModelArts后台之前需要先将代码文件夹存放到OBS中,存放的步骤同上文(准备工作->上传数据集)。

想要后续在ModelArts上训练,由于ModelArts是将OBS中的数据下载到后台再进行训练的,因此源代码中的训练路径这时不可用,需要当做一个参数动态调节。想实现添加参数需要两步:
在建立算法时要创建输入参数、输出参数

添加输入参数之后会自动添加对应的超参,也就是为了在自己的代码中识别出这是个外部的参数可以做修改,相当于在源代码中加入以下语句(默认存放数据的路径参数叫data_url,名称根据自己的代码调整):
parser.add_argument('--data_url', type=str, default=None, help='test')
也可以自行添加超参(训练时可以手动修改的参数),如max_epochs等。

随后点击确定算法就创建成功了。



调整好点击创建,开始训练,训练完后会显示已完成。

如果训练出来的结果不错,可以将算法代码(带调整好的参数)一起保存为一个模型,也叫AI应用。点击一个训练任务,可以直接创建AI应用。另华为云中有内置效果不错的模型,可以订阅拿来使用。

这部分板块适用于将算法集成于硬件中(例如摄像头),可以将数据格式进行转换。
这一步就是模型上线直接利用真实值看效果了,初学者使用在线服务足矣。
点击可以上线的模型(AI应用),点击在线服务。

基本上不做修改,保持默认即可。

打开部署任务,依次上传图片、点击预测,结果如下。


前面七个板块都是供开发者进行模型实操作业,而AI Gallery社区更像是聚集各个优秀开发者的一个大家庭。在此模块,每个人都可以通过论坛、活动等模块了解行内最新消息;跟着教学模块的路线学习提升自己;还可以参加活动比赛提升世面、认识大佬;查找案例库对行业中的热门方向拥有较强的把握,对于找工作的人士有相当大的指引作用。
总之,想学好AI的朋友一定不要错过这个网站。链接在此,赶快进来逛逛吧!
总体看来ModelArts较同类产品还是非常具有优势的,尤其是在可用性、完善性、易用性方面,对初学者来说非常友好。当然还有更高级更专业的功能等着我们去探索。此刻就行动起来吧,高峰只对攀登它而不是仰望它的人来说才有真正意义。

我正在学习如何使用Nokogiri,根据这段代码我遇到了一些问题:require'rubygems'require'mechanize'post_agent=WWW::Mechanize.newpost_page=post_agent.get('http://www.vbulletin.org/forum/showthread.php?t=230708')puts"\nabsolutepathwithtbodygivesnil"putspost_page.parser.xpath('/html/body/div/div/div/div/div/table/tbody/tr/td/div
总的来说,我对ruby还比较陌生,我正在为我正在创建的对象编写一些rspec测试用例。许多测试用例都非常基础,我只是想确保正确填充和返回值。我想知道是否有办法使用循环结构来执行此操作。不必为我要测试的每个方法都设置一个assertEquals。例如:describeitem,"TestingtheItem"doit"willhaveanullvaluetostart"doitem=Item.new#HereIcoulddotheitem.name.shouldbe_nil#thenIcoulddoitem.category.shouldbe_nilendend但我想要一些方法来使用
我有一个Ruby程序,它使用rubyzip压缩XML文件的目录树。gem。我的问题是文件开始变得很重,我想提高压缩级别,因为压缩时间不是问题。我在rubyzipdocumentation中找不到一种为创建的ZIP文件指定压缩级别的方法。有人知道如何更改此设置吗?是否有另一个允许指定压缩级别的Ruby库? 最佳答案 这是我通过查看rubyzip内部创建的代码。level=Zlib::BEST_COMPRESSIONZip::ZipOutputStream.open(zip_file)do|zip|Dir.glob("**/*")d
类classAprivatedeffooputs:fooendpublicdefbarputs:barendprivatedefzimputs:zimendprotecteddefdibputs:dibendendA的实例a=A.new测试a.foorescueputs:faila.barrescueputs:faila.zimrescueputs:faila.dibrescueputs:faila.gazrescueputs:fail测试输出failbarfailfailfail.发送测试[:foo,:bar,:zim,:dib,:gaz].each{|m|a.send(m)resc
很好奇,就使用rubyonrails自动化单元测试而言,你们正在做什么?您是否创建了一个脚本来在cron中运行rake作业并将结果邮寄给您?git中的预提交Hook?只是手动调用?我完全理解测试,但想知道在错误发生之前捕获错误的最佳实践是什么。让我们理所当然地认为测试本身是完美无缺的,并且可以正常工作。下一步是什么以确保他们在正确的时间将可能有害的结果传达给您? 最佳答案 不确定您到底想听什么,但是有几个级别的自动代码库控制:在处理某项功能时,您可以使用类似autotest的内容获得关于哪些有效,哪些无效的即时反馈。要确保您的提
假设我做了一个模块如下:m=Module.newdoclassCendend三个问题:除了对m的引用之外,还有什么方法可以访问C和m中的其他内容?我可以在创建匿名模块后为其命名吗(就像我输入“module...”一样)?如何在使用完匿名模块后将其删除,使其定义的常量不再存在? 最佳答案 三个答案:是的,使用ObjectSpace.此代码使c引用你的类(class)C不引用m:c=nilObjectSpace.each_object{|obj|c=objif(Class===objandobj.name=~/::C$/)}当然这取决于
我正在尝试使用ruby和Savon来使用网络服务。测试服务为http://www.webservicex.net/WS/WSDetails.aspx?WSID=9&CATID=2require'rubygems'require'savon'client=Savon::Client.new"http://www.webservicex.net/stockquote.asmx?WSDL"client.get_quotedo|soap|soap.body={:symbol=>"AAPL"}end返回SOAP异常。检查soap信封,在我看来soap请求没有正确的命名空间。任何人都可以建议我
我正在尝试设置一个puppet节点,但rubygems似乎不正常。如果我通过它自己的二进制文件(/usr/lib/ruby/gems/1.8/gems/facter-1.5.8/bin/facter)在cli上运行facter,它工作正常,但如果我通过由rubygems(/usr/bin/facter)安装的二进制文件,它抛出:/usr/lib/ruby/1.8/facter/uptime.rb:11:undefinedmethod`get_uptime'forFacter::Util::Uptime:Module(NoMethodError)from/usr/lib/ruby
关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭4年前。Improvethisquestion我想在固定时间创建一系列低音和高音调的哔哔声。例如:在150毫秒时发出高音调的蜂鸣声在151毫秒时发出低音调的蜂鸣声200毫秒时发出低音调的蜂鸣声250毫秒的高音调蜂鸣声有没有办法在Ruby或Python中做到这一点?我真的不在乎输出编码是什么(.wav、.mp3、.ogg等等),但我确实想创建一个输出文件。
我在我的项目目录中完成了compasscreate.和compassinitrails。几个问题:我已将我的.sass文件放在public/stylesheets中。这是放置它们的正确位置吗?当我运行compasswatch时,它不会自动编译这些.sass文件。我必须手动指定文件:compasswatchpublic/stylesheets/myfile.sass等。如何让它自动运行?文件ie.css、print.css和screen.css已放在stylesheets/compiled。如何在编译后不让它们重新出现的情况下删除它们?我自己编译的.sass文件编译成compiled/t