在商城中搜索商品,只能搜索到已上架的商品。
而商品上架时,需要把数据也同步到elasticsearch中以供搜索。
但是肯定不能把完整的数据全部存到es中,因为es中的数据是存储在内存中的,就算es是分布式的,理论上可以存储非常多的数据,但是内存产品终究是比硬盘贵的。所以考虑到经济效益,我们是要取某些数据存到es中,而不是完整数据都存进去。
哪些数据存储在es中?
es中应存储能够被检索的条件。

比如这个商城能够用于检索的条件就有:
分类、品牌、综合、销量、价格区间、CPU型号,运行内存,机身内存(这些应该是每种分类特有的属性)、等等
分析:商品上架在 es 中是存 sku 还是 spu?
答:搜索一般是搜索sku的信息,因为一个spu中包含多个sku,每个sku的情况都不一样,搜索的时候可能一个spu里的某几个sku符合条件,几个sku不符合条件。(我的理解)
检索的时候输入名字,是需要按照 sku 的 title 进行全文检索的
检索使用商品规格,规格是 spu 的公共属性,每个 spu 是一样的
按照分类 id 进去的都是直接列出 spu 的,还可以切换。
我们如果将 sku 的全量信息保存到 es 中(包括 spu 属性)就太多量字段了。
我们如果将 spu 以及他包含的 sku 信息保存到 es 中,也可以方便检索。但是 sku 属于spu 的级联对象,在 es 中需要 nested 模型,这种性能差点。
但是存储与检索我们必须性能折中。
如果我们分拆存储,spu 和 attr 一个索引,sku 单独一个索引可能涉及的问题。检索商品的名字,如“手机”,对应的 spu 有很多,我们要分析出这些 spu 的所有关联属性,再做一次查询,就必须将所有 spu_id 都发出去。假设有 1 万个数据,数据传输一次就10000*4=4MB;并发情况下假设 1000 检索请求,那就是 4GB 的数据,,传输阻塞时间会很长,业务更加无法继续。
PUT product
{
"mappings": {
"properties": {
"skuId": {
"type": "long"
},
"spuId": {
"type": "keyword"
},
"skuTitle": {
"type": "text",
"analyzer": "ik_smart"
},
"skuPrice": {
"type": "keyword"
},
"skuImg": {
"type": "keyword",
"index": false,
"doc_values": false
},
"saleCount": {
"type": "long"
},
"hasStock": {
"type": "boolean"
},
"hotScore": {
"type": "long"
},
"brandId": {
"type": "long"
},
"catalogId": {
"type": "long"
},
"brandName": {
"type": "keyword",
"index": false,
"doc_values": false
},
"brandImg": {
"type": "keyword",
"index": false,
"doc_values": false
},
"catalogName": {
"type": "keyword",
"index": false,
"doc_values": false
},
"attrs": {
"type": "nested",
"properties": {
"attrId": {
"type": "long"
},
"attrName": {
"type": "keyword",
"index": false,
"doc_values": false
},
"attrValue": {
"type": "keyword"
}
}
}
}
}
}
text类型和keyword类型的区别:
text:会分词,然后进行索引
支持模糊、精确查询
不支持聚合
keyword:不进行分词,直接索引
支持模糊、精确查询
支持聚合
| 字段 | 含义 |
|---|---|
| index | 默认 true,如果为 false,表示该字段不会被索引,但是检索结果里面有,但字段本身不能 |
| doc_values | 默认 true,设置为 false,表示不可以做排序、聚合以及脚本操作,这样更节省磁盘空间。还可以通过设定 doc_values 为 true,index 为 false 来让字段不能被搜索但可以用于排序、聚合以及脚本操作 |
| 字段 | 含义 |
|---|---|
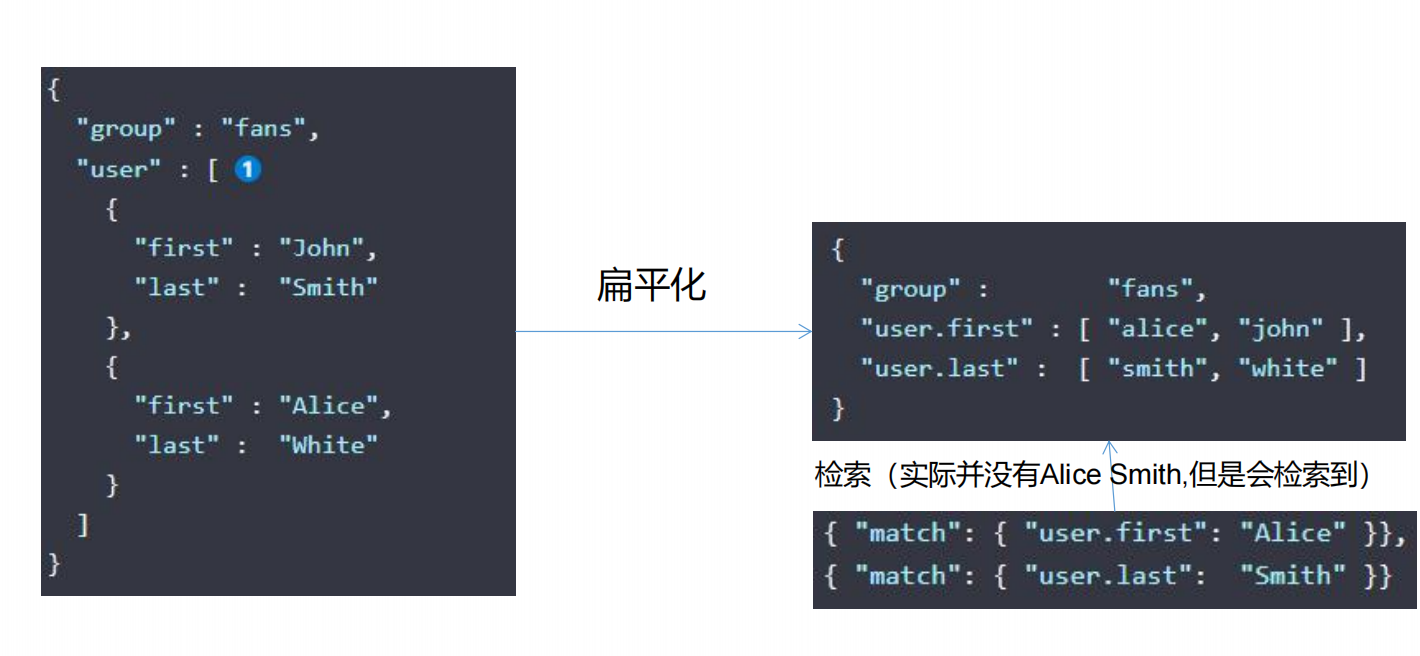
| nested | 嵌入式的字段,就可以不使用es的扁平化处理了。 |
由于这些数据是要在多个服务之间进行传输的,所以定义为to类型。为了方便每一个服务调用,我们直接创建在common模块中。
// 根据分析出来的模型构建
@Data
public class SkuEsTo {
private Long skuId;
private Long spuId;
private String skuTitle;
private BigDecimal skuPrice;
private String skuImg;
private Long saleCount;
private Boolean hasStock;
private Long hotScore;
private Long brandId;
private Long catalogId;
private String brandName;
private String brandImg;
private String catalogName;
private List<Attr> attrs;
@Data
public static class Attr {
private Long attrId;
private String attrName;
private String attrValue;
}
}
spu下的所有所属skusku中的需要使用的信息
SkuEsTo的数据到集合中。List<SkuEsTo>发送给es,让es保存,达到上架的状态。spu的发布状态(1-上架)
- 因为可检索属性是每一个sku都相同的,所以能在一开始直接获取,不要在循环内获取。
- 库存信息需要调用其他服务,这种操作速度应该会比较慢,所以也在循环外一次性获取,需要新建一个存储库存信息的TO实体类。
以下列出部分代码。(因为代码太多了,只列出一些关键的)
@Override
public void up(Long spuId) {
// 1.获取该spu的所有可检索属性。
// attrs;因为spu的属性是每个sku共享的,用空间换时间,所以在每一个sku里面都存一遍!!过滤出需要检索的属性,0为不需要检索,1为需要检索
List<ProductAttrValueEntity> productAttrValueList = productAttrValueService.getAttrsBySpuId(spuId);
// 获取spu下所有属性id
List<Long> attrIds = productAttrValueList.stream().map(ProductAttrValueEntity::getAttrId).collect(Collectors.toList());
// 得到spu下所有的可检索属性id
List<Long> searchAttrIds = attrService.selectSearchAttrIds(attrIds);
// 过滤出所有可检索的属性信息
List<SkuEsTo.Attr> searchAttrList = productAttrValueList.stream()
.filter(attr -> searchAttrIds.contains(attr.getAttrId()))
// 组装skuEsTo中的attrs
.map(searchAttrItem -> {
SkuEsTo.Attr attr = new SkuEsTo.Attr();
attr.setAttrId(searchAttrItem.getAttrId());
attr.setAttrName(searchAttrItem.getAttrName());
attr.setAttrValue(searchAttrItem.getAttrValue());
return attr;
}).collect(Collectors.toList());
// 2.获取sku库存信息
List<SkuInfoEntity> skuInfoEntityList = skuInfoService.getInfoBySpuId(spuId);
// 得到所有的skuId,调用远程服务,获取库存信息
List<Long> skuIds = skuInfoEntityList.stream().map(SkuInfoEntity::getSkuId).collect(Collectors.toList());
Object skuStockInfoList = null;
try {
R r = wareFeignService.hasStock(skuIds);
skuStockInfoList = r.get("skuStockToList");
}catch (Exception e){
log.error("库存服务查询失败,原因:{}", e.getMessage());
}
Object finalSkuStockInfoList = skuStockInfoList;
List<SkuEsTo> esProductList = skuInfoEntityList.stream().map(skuInfoEntity -> {
SkuEsTo skuEsTo = new SkuEsTo();
BeanUtils.copyProperties(skuInfoEntity, skuEsTo);
// skuPrice;skuImg;
skuEsTo.setSkuPrice(skuInfoEntity.getPrice());
skuEsTo.setSkuImg(skuInfoEntity.getSkuDefaultImg());
// hasStock;hotScore;
if (finalSkuStockInfoList != null){
// 做一个类型转换,把list中的数据放到map中,map<skuId, 是否有库存>
Map<Long, Boolean> stockInfoMap = TypeConversion.objListToMapOfLongBoolean(finalSkuStockInfoList);
Boolean hasStock = stockInfoMap.get(skuInfoEntity.getSkuId());
skuEsTo.setHasStock(hasStock);
} else {
skuEsTo.setHasStock(true);
}
// todo:热度评分,默认新上架的商品评分为0,给钱就高分
skuEsTo.setHotScore(0L);
// brandName;brandImg;
BrandEntity brandEntity = brandService.getById(skuInfoEntity.getBrandId());
skuEsTo.setBrandName(brandEntity.getName());
skuEsTo.setBrandImg(brandEntity.getLogo());
// catalogName;
CategoryEntity categoryEntity = categoryService.getById(skuInfoEntity.getCatalogId());
skuEsTo.setCatalogName(categoryEntity.getName());
// attrs;
skuEsTo.setAttrs(searchAttrList);
return skuEsTo;
}).collect(Collectors.toList());
// 3.将数据发给es,让es做一个保存
R r = searchFeignService.productStatusUp(esProductList);
if (r.getCode() == 0){
boolean status = (boolean) r.get("status");
// 4.上架成功,修改数据库中的上架状态
spuInfoDao.updateSpuPublishStatus(spuId, ProductConstant.StatusEnum.SPU_UP.getCode());
}else {
log.error("商品上架失败");
// TODO: 重复调用?接口幂等性?重试机制?
}
}
@Data
public class SkuStockTo {
/**
* skuId
*/
private Long skuId;
/**
* 是否有库存
*/
private Boolean hasStock;
}
es中@Override
public boolean productStatusUp(List<SkuEsTo> skuEsToList) {
boolean success = true;
// 1.给es中建立索引。product,建立好映射关系。
// 2.在es中保存这些数据。数据多,不可能一个一个组装,使用bulk批量处理
// BulkRequest bulkRequest, RequestOptions options
BulkRequest bulkRequest = new BulkRequest();
for (SkuEsTo skuEsTo : skuEsToList) {
// 3.组装数据
IndexRequest request = new IndexRequest(SearchConstant.IndexEnum.PRODUCT_INDEX.getIndex());
// 指定id
request.id(String.valueOf(skuEsTo.getSkuId()));
String skuEsToJson = JSON.toJSONString(skuEsTo);
// 指定json数据
System.out.println(skuEsTo);
request.source(skuEsToJson, XContentType.JSON);
bulkRequest.add(request);
}
try {
// 4.执行
BulkResponse response = client.bulk(bulkRequest, GulimallElasticsearchConfig.COMMON_OPTIONS);
if (response.hasFailures()){
success = false;
List<String> failureList = Arrays.stream(response.getItems()).filter(item -> item.getFailure() != null).map(BulkItemResponse::getId).collect(Collectors.toList());
log.error("批量操作错误项:{}", failureList);
}
} catch (IOException e) {
log.error("批量操作遇到错误,原因:{}", e.getMessage());
}
return success;
}
我有一个PORO(普通旧Ruby对象)来处理一些业务逻辑。它接收一个ActiveRecord对象并对其进行分类。为了简单起见,以下面为例:classClassificatorSTATES={1=>"Positive",2=>"Neutral",3=>"Negative"}definitializer(item)@item=itemenddefnameSTATES.fetch(state_id)endprivatedefstate_idreturn1if@item.value>0return2if@item.value==0return3if@item.value但是,我还想根据这些st
Ruby社区最近出现了大量关于使用更好的OO设计的好处的博客文章、推文和评论,特别是将业务逻辑与持久性逻辑分开。特别是对于较大的应用程序,我认为这是很好的建议。http://solnic.eu/2011/08/01/making-activerecord-models-thin.htmlhttp://blog.steveklabnik.com/2011/09/06/the-secret-to-rails-oo-design.htmlhttp://avdi.org/devblog/2011/11/15/early-access-beta-of-objects-on-rails-now-a
基于Java+uniapp框架开发的全开源微信小程序商城源码源码免费分享 应用介绍基于Java+uniapp框架开发的全开源微信小程序商城系统源码,前端采用目前主流的uniapp框架开发,后端采用Java语言开发,前后端代码全部开源,减少重复造轮子,支持小程序商城秒杀、优惠券、多商户、直播卖货、分销等功能,帮助商家快速搭建一个属于自己的微信小程序商城。 主要功能:一:会员管理会员管理、会员等级、收货地址管理、会员优惠劵、会员收藏、会员足迹、搜索历史、购物车二:商城配置区域配置、商品属性种类、品牌制造商、商品规格、订单管理、商品类型、渠道管理、商品问答、反馈、关键词三:商品编辑所有商品、用户评论
本篇文章给大家谈谈抖音开放api接口,以及抖音开放api接口对应的知识点,希望对各位有所帮助,不要忘了收藏本文章喔。当用户打开抖音,在默认推荐页中,就会被推送到带有POI链接的视频。这类视频通常分为两类。一、商户POI的打卡类视频第一种是标记有点击POI链接跳转至商户的POI聚合页。(注意,这里跳转的并不是商户的企业号页面。)如图:二、城市类视频第二种包含POI信息的视频为“城市类”视频,点击POI则会进入城市的聚合页。在城市聚合页中,除抖音开放api接口poi了大量的基于POI所聚合的视频外,系统还会为用户推荐当地商户,包括:必体验、吃什么、玩什么、住哪里四大类。item_get获得抖音商
一、上架基本需求资料1、苹果开发者账号(公司已有可以不用申请,需要开通开发者功能,每年99美元)2、开发好的APP二、证书上架版本需要使用正式的证书1、创建证书AppleDeveloper2、上传证书SignIn-Apple3、进入开发者中心Certificates,Identifiers&Profiles点击Certificates旁边的+新增证书4、选择最新的分发版证书AppleDistrbution,右上角continue5、按要求填写后提交。一般都要创建两个证书一个用于开发,一个用于上架,如果有支付内容,还必需要6、创建profile左侧菜单选上传app包
实现商品详情页json里边设置一下页面标题"navigationBarTitleText":"商品详情"界面组成上方由一个轮播图展示,中间为商品信息,后台会返回图文详情富文本,前台只需赋值下方固定一个工具栏客服分享购物车添加购物车立即购买界面编写分享是将一个按钮隐藏且将其定位在分享处,客服也是一样的加入购物车:如果已经加入则提示已经加入…view>viewclass=
我有一个简单的应用程序,它从API中提取产品并将它们显示在页面上,如下所示:我已将Vuex添加到应用程序,这样当路由器将用户移动到特定产品页面时,搜索结果和产品搜索数组不会消失。搜索本身包含以下步骤:显示加载微调器(更新store对象)发送访问API的操作用产品更新store对象,spinner判断产品列表是否用尽隐藏加载微调器你明白了。所有变量都存储在Vuex中,按理说所有业务逻辑也应该属于那里,但真的应该这样吗?我正在专门谈论访问商店参数,例如productsExhausted(当没有更多产品可显示时)或productPage(每次无限滚动模块时递增被触发)等Vuex中有多少逻辑?
ChatGPT的加速迭代在推动世界劳动力向数字化转变,在“基于人类反馈的强化学习”的模式下,证明千亿规模模型训练+人类反馈可以融合世界的知识和规则,极大提升模型表现,取得接近人的水准。ChatGPT作为基于Transformer架构大型预训练语言模型,在对话中生成类似人类的文本响应。ChatGPT可以通过从数百万个网站收集信息,以对话式、人性化的方式生成独特的答案,为用户提供写论文、写代码、设计商业策划、担任人们的治疗师等一系列服务。它代表了OpenAI最新一代的大型语言模型,在设计上非常注重交互性。5G消息的核心应用Chatbot(聊天机器人),其本质是随时响应用户消息服务,与ChatGPT
看完officialguide关于如何构建项目和经历各种(1、2、3仅举几例)示例和项目我不禁想知道我构建REST-API服务器应用程序的方法是否结构化正确地。API的用途是什么?POST/auth/sign-in接受用户名和密码并发出JWT(JSON网络token)。GET/auth/sign-out将JWT添加到黑名单以使身份验证session无效。获取/资源检索所有资源的列表。POST/resources(需要有效的JWT身份验证)接受JSON正文,创建新资源并向所有人发送有关新资源的电子邮件和通知。我的项目是什么样的目前我没有创建任何库。一切都在主包中,带有路由的总体服务器设置
原创| BFT机器人 智能机器人研究 01马老板回国释放信号资本市场异常躁动3月26日,有民间传闻,在世界兜兜转转云游了近两年的马老板,终于回国了。次日,网络上迅速传开了一段疑似马云乘坐中巴车与同行人士亲切交谈的视频,但从视频拍摄角度和画面清晰度难以判定为马云本人。图片来源:网传视频截图(后经《科创板日报》证实,车内人士分别为马云、阿里巴巴集团董事会主席兼首席执行官张勇、阿里集团资深副总裁邵晓锋)一时间罗生门上演,多方媒体的“独家”众说纷纭。马老板到底是否回国的消息还未证实,但资本市场已经兴奋难抑。视频流出后,阿里巴巴港股一路“狂飙”近5个点,连带整个互联网板块也一齐攀升。图片来源:格隆汇直