文章目录
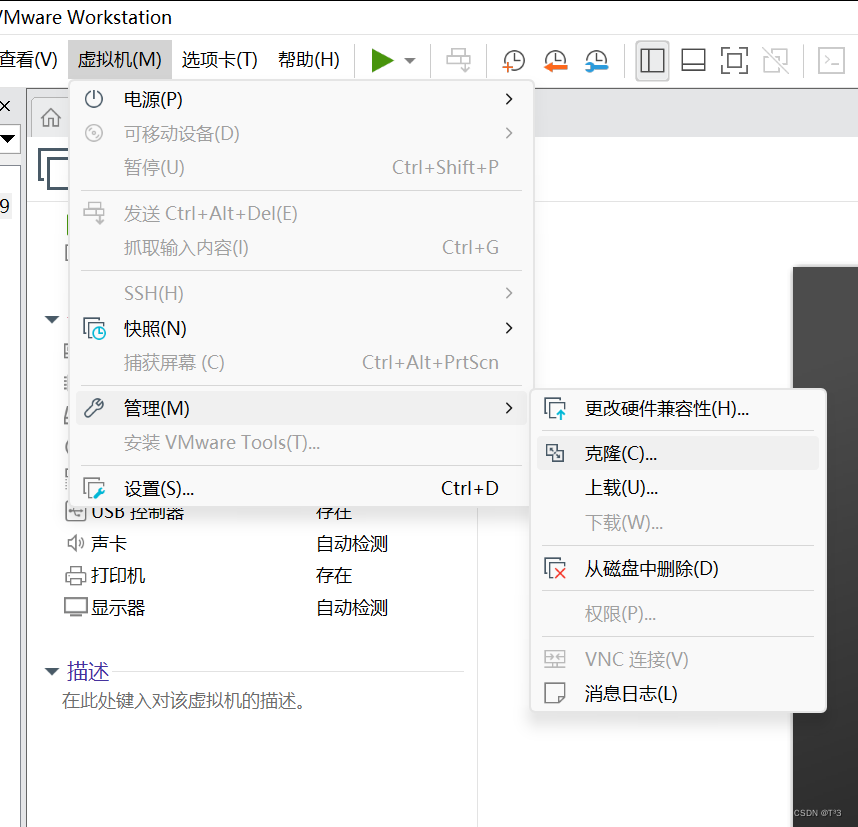
1.在虚拟机关机的状态下选择克隆
2.开始克隆
3.选择从当前状态创建
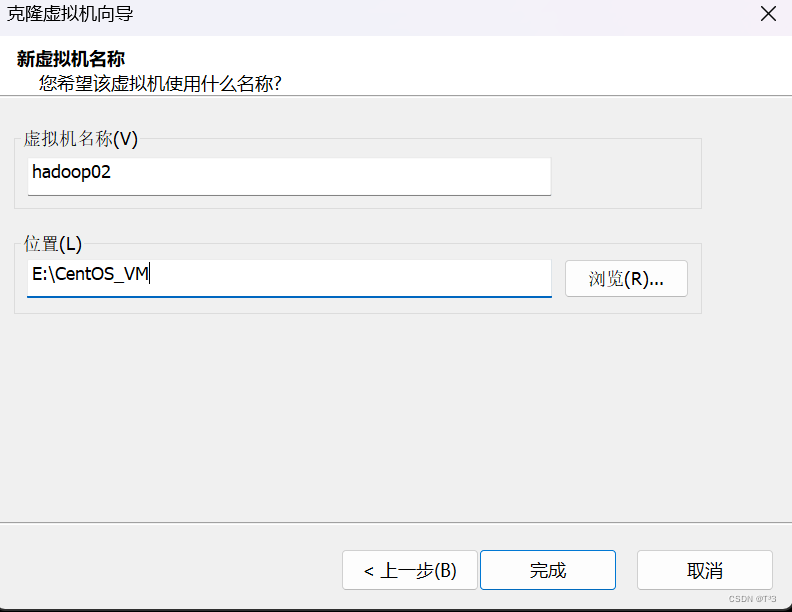
4.创建一个完整的克隆
5.选择新的虚拟机存储位置(选择内存充足的磁盘)
6.开始克隆
7.克隆完成
8.同样的方法克隆第二台虚拟机
9.在计算机中存在三台虚拟机
将第一台虚拟机更名为hadoop01

修改hadoop01的主机名为hadoop01

修改hadoop02的主机名为hadoop02

同样的方式修改hadoop03的主机名为hadoop03
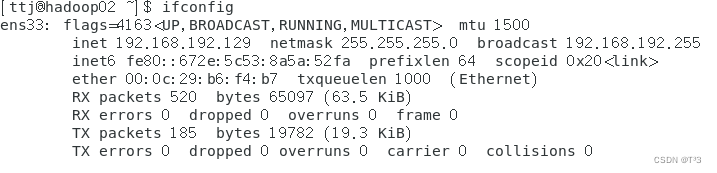
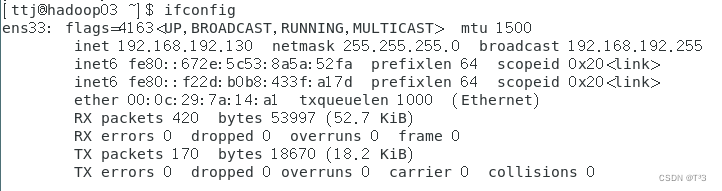
查看三台虚拟机IP地址,该地址为动态分配
设置三台主机IP地址为固定地址:
点击【编辑】——【虚拟网络编辑器】

【选择VMnet】模式——【NAT设置】
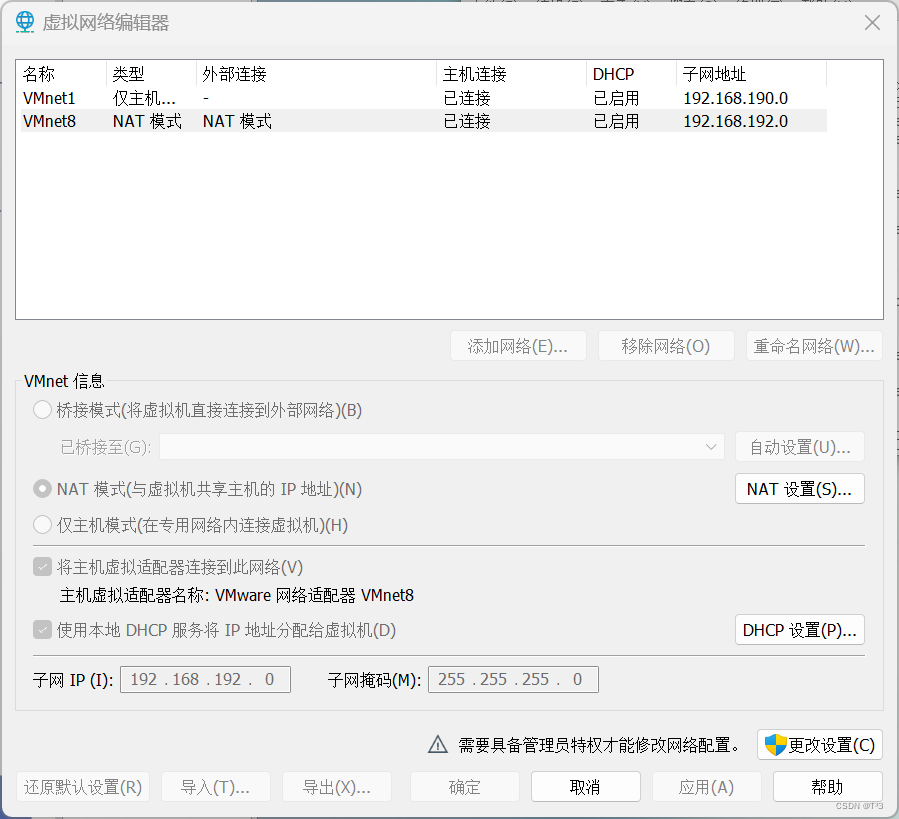
输入自己设置的子网IP和子网掩码
我这里设置的 子网IP:192.168.10.0
子网掩码:255.255.255.0
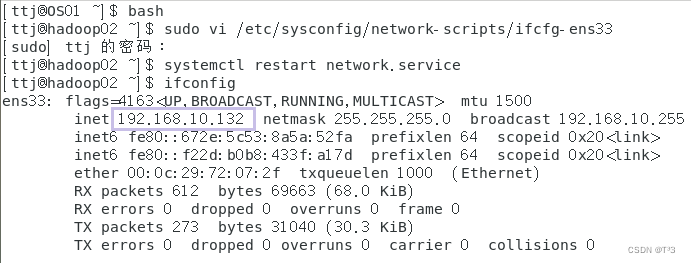
 hadoop01主机设置固定IP地址:
hadoop01主机设置固定IP地址:
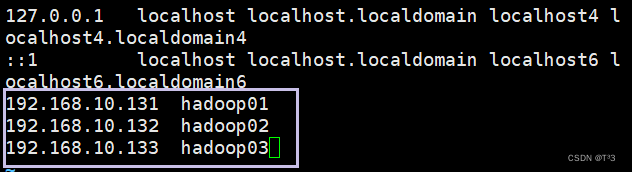
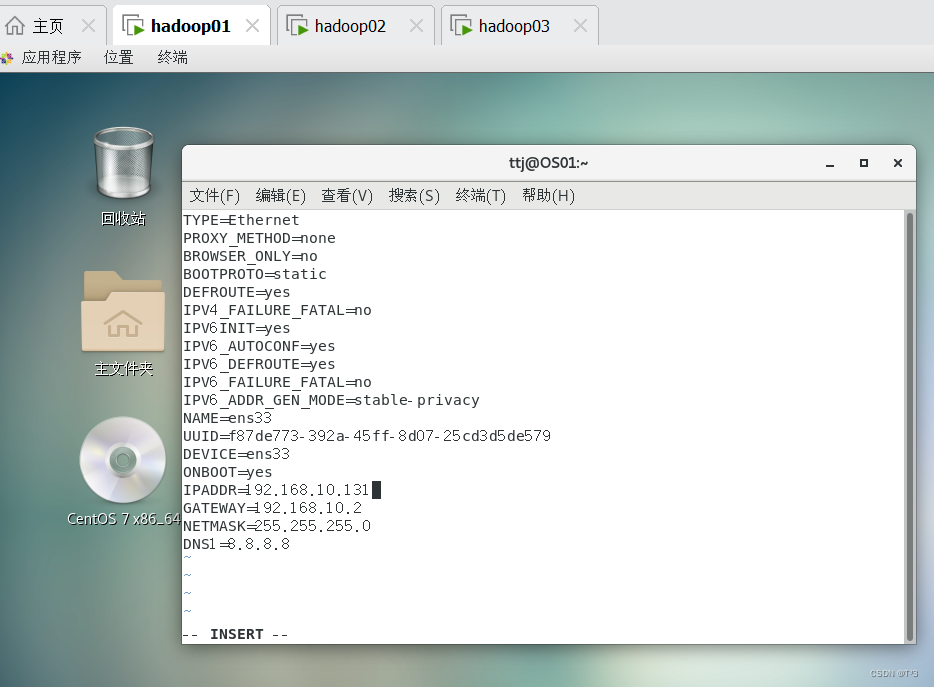
输入命令:
sudo vi /etc/sysconfig/network-scripts/ifcfg-ens33
修改文件信息:
IPADDR=192.168.10.131
GATEWAY=192.168.10.2
NETMASK=255.255.255.0
DNS1=8.8.8.8
执行命令重启网络服务:
systemctl restart network.service

查看配置后的网络信息:
ifconfig
hadoop02和hadoop03配置方法和hadoop01方法一致
使用Xshell工具继续操作较为方便,所以我以下的操作均在Xshell中进行
分别连接三台主机(【新建连接】——【输入主机IP】——【连接】)

采用输入主机名称与密码的方式进行连接

成功连接三台主机
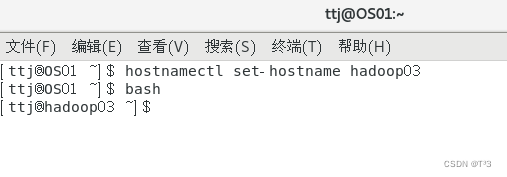
添加主机名与IP地址的映射关系
在hadoop01、hadoop02和hadoop03三台主机中分别添加主机名与IP地址的映射关系
执行命令:
sudo vi /etc/hosts
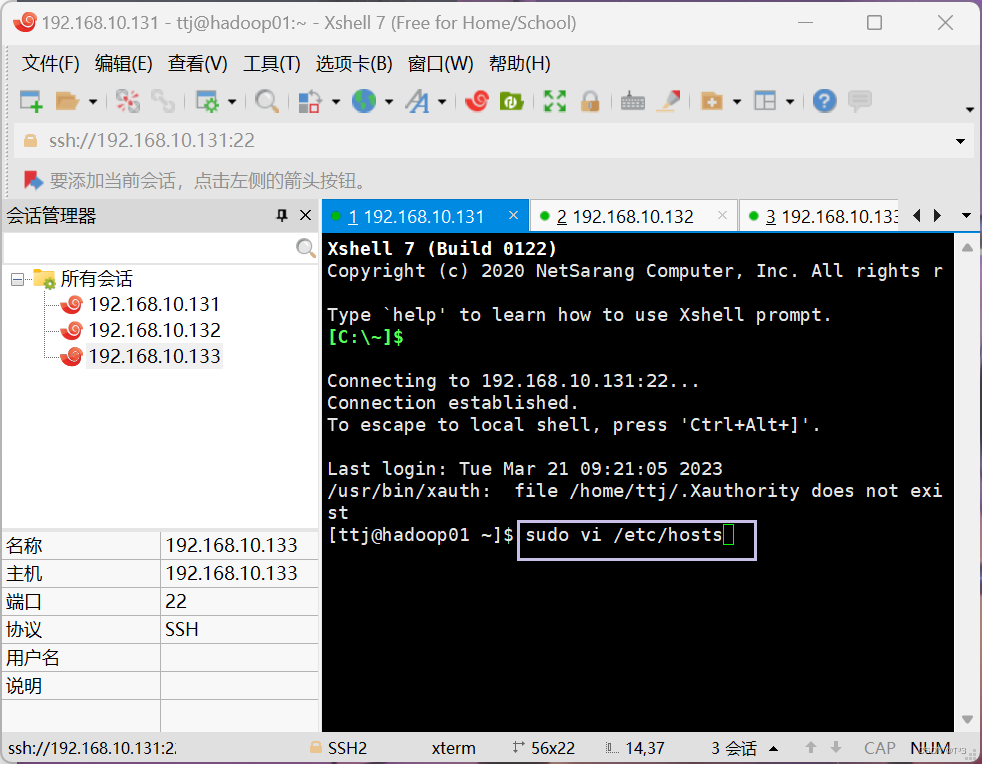
内容如下:
复制hadoop01的公钥到hadoop02和hadoop03中



验证免密码登录

Hadoop完全分布式配置目标:
| hadoop01 | hadoop02 | hadoop03 |
|---|---|---|
| NameNode进程 | DataNode进程 | DataNode进程 |
| ResourceManager进程 | NodeManage进程 | NodeManage进程 |
| \ | SecondaryNameNode进程 | \ |
配置主节点
进入hadoop目录下执行命令
cd /usr/local/java/hadoop-2.7.7/etc/hadoop

修改core-site.xml文件
sudo vi core-site.xml
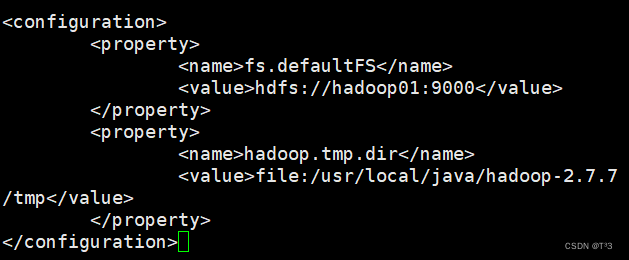
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/java/hadoop-2.7.7/tmp</value>
</property>
</configuration>
修改hdfs-site.xml

sudo vi hadf-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop02:50090/</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/java/hadoop-2.7.7/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/java/hadoop-2.7.7/dfs/data</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
<property>
<name>dfs.support.append</name>
<value>true</value>
</property>
</configuration>
修改mapred-site.xml文件

sudo vi mapred-site.xml

<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobtracker.address</name>
<value>hadoop01:9001</value>
</property>
</configuration>
修改yarn-site.xml文件

sudo vi yarn-site.xml
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop01</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>hadoop01:8099</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>1024</value>
</property>
<property>
<name>yarn.nodemanager.resource.cpu-vcores</name>
<value>1</value>
</property>
修改slaves文件
sudo vi slaves

slaves的内容如下:
在主节点hadoop01中格式化文件系统
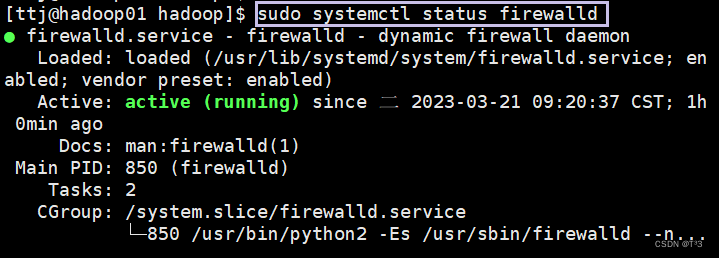
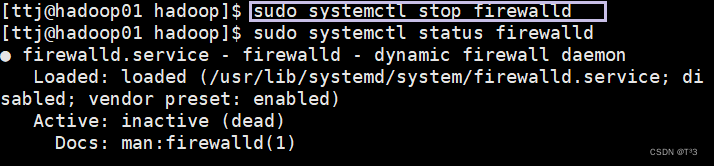
输入命令之前需要将三台主机的防火墙关闭
sudo systemctl status firewalld sudo systemctl stop firewalldsudo systemctl disable firewalld建议执行顺序:【1】——【2】——【3】
关闭前:
关闭后:
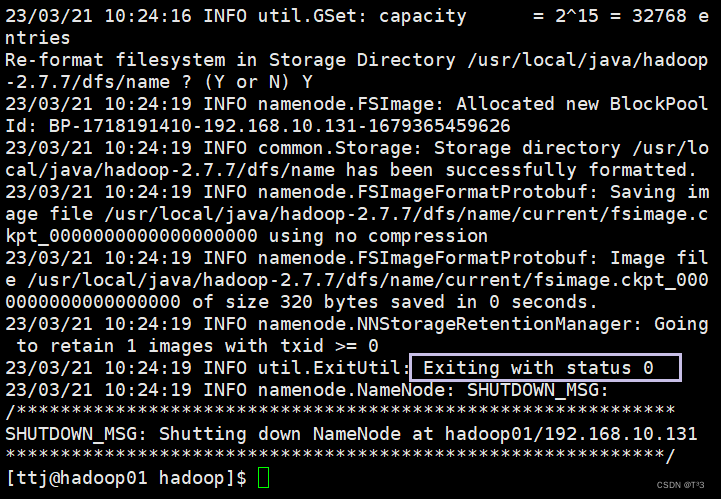
在主节点hadoop01中格式化文件系统
输入命令hdfs namenode -format或者hadoop namenode -format

集群格式化成功
分发配置文件
注意:如果是第二次或者多次执行格式化操作,在进行分发配置文件之前,需要将hadoop01、hadoop02、hadoop03下的hadoop-2.7.7/dfs目录下的name和data目录全部删掉后,再进行拷贝操作。
删除后文件夹为空:
将hadoop01节点下的hadoop-2.7.7拷贝给hadoop02和hadoop03
执行命令:
scp -r /usr/local/java/hadoop-2.7.7 hadoop02:/usr/local/java/
scp -r /usr/local/java/hadoop-2.7.7 hadoop03:/usr/local/java/

启动和查看Hadoop进程
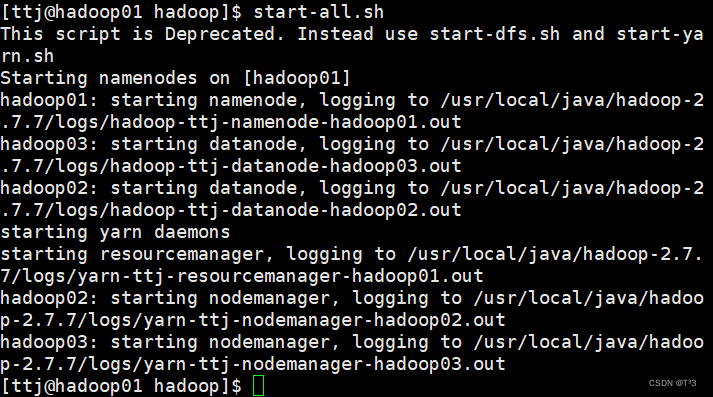
在hadoop01节点启动服务
start-all.sh
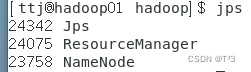
输入jsp查看进程
hadoop01节点进程
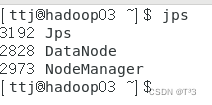
hadoop02节点进程

hadoop03节点进程
关闭所有进程:
stop-all.sh
搭建过程中遇到的问题: hadoop02节点没有出现SecondaryNameNode节点,关闭集群时出现no
resourcemanager to stop、no nodemanager to stop、no namenode to stop、no
datanode to stop,但是相关进程都真实存在,并且可用。失败原因:当启动节点服务的过程中没有指定pid的存放位置,hadoop默认会放在Linux的/tmp目录下,进程名命名规则一般是框架名-用户名-角色名.pid,而默认情况下/tmp里面的东西会自动清除,因为pid不存在,所以执行stop相关命令的时候找不到pid,也就无法停止相关进程。
解决方法: 使用自定义进程存放目录
修改配置文件hadoop-env.sh 如果没有相关的配置,就直接进行添加

修改配置文件mapred-env.sh

修改配置文件yarn-env.sh

以上文件配置好以后,启动hdfs和yarn,启动成功后查看jps,进程都存在,pidDir目录下有以下文件:
yarn-ttj-nodemanager.pid
yarn-ttj-resourcemanager.pid
hadoop-ttj-namenode.pid
hadoop-ttj-secondarynamenode.pid
hadoop-ttj-datanode.pid
我打算为ruby脚本创建一个安装程序,但我希望能够确保机器安装了RVM。有没有一种方法可以完全离线安装RVM并且不引人注目(通过不引人注目,就像创建一个可以做所有事情的脚本而不是要求用户向他们的bash_profile或bashrc添加一些东西)我不是要脚本本身,只是一个关于如何走这条路的快速指针(如果可能的话)。我们还研究了这个很有帮助的问题:RVM-isthereawayforsimpleofflineinstall?但有点误导,因为答案只向我们展示了如何离线在RVM中安装ruby。我们需要能够离线安装RVM本身,并查看脚本https://raw.github.com/wayn
我有一个涉及多台机器、消息队列和事务的问题。因此,例如用户点击网页,点击将消息发送到另一台机器,该机器将付款添加到用户的帐户。每秒可能有数千次点击。事务的所有方面都应该是容错的。我以前从未遇到过这样的事情,但一些阅读表明这是一个众所周知的问题。所以我的问题。我假设安全的方法是使用两阶段提交,但协议(protocol)是阻塞的,所以我不会获得所需的性能,我是否正确?我通常写Ruby,但似乎Redis之类的数据库和Rescue、RabbitMQ等消息队列系统对我的帮助不大——即使我实现某种两阶段提交,如果Redis崩溃,数据也会丢失,因为它本质上只是内存。所有这些让我开始关注erlang和
1.1.1 YARN的介绍 为克服Hadoop1.0中HDFS和MapReduce存在的各种问题⽽提出的,针对Hadoop1.0中的MapReduce在扩展性和多框架⽀持⽅⾯的不⾜,提出了全新的资源管理框架YARN. ApacheYARN(YetanotherResourceNegotiator的缩写)是Hadoop集群的资源管理系统,负责为计算程序提供服务器计算资源,相当于⼀个分布式的操作系统平台,⽽MapReduce等计算程序则相当于运⾏于操作系统之上的应⽤程序。 YARN被引⼊Hadoop2,最初是为了改善MapReduce的实现,但是因为具有⾜够的通⽤性,同样可以⽀持其他的分布式计算模
背景here.在上面的链接中,给出了以下示例:classauthor.id)endend除了这种语法对于像我这样的初学者来说很陌生——我一直认为类方法是用defself.my_class_method定义的——我在哪里可以找到关于类的文档RubyonRails中的方法?据我所知,类方法总是在类本身(MyClass.my_class_method)上调用,但如果Rails中的类方法是可链接的,似乎必须进行其他操作在这里!编辑:我想我通过对类方法的语法发表评论有点被骗了。我真的想问Rails如何使类方法可链接—我了解方法链接的工作原理,但不知道Rails如何允许您链接类方法而无需实际返
首先,关于我们系统的一些信息,它基本上是建筑行业的电子招标解决方案。所以:列表项我们的系统有多家公司每个公司都有多个用户每家公司可以创建多个拍卖然后其他公司可以为可用的拍卖提交他们的出价。一个出价包含数百或数千个单独的项目,我们只需要加密这些记录的“价格”部分。我们面临的问题是,我们的大客户不希望我们知道投标价格,至少在投标过程中是这样,这是完全可以理解的。现在,我们只是通过对称加密对价格进行加密,因此即使价格在数据库中有效加密,他们担心的是我们拥有解密价格的key。因此,我们正在研究某种形式的公钥加密系统。以下是我们对解决方案的初步想法:当一家公司注册时,我们会使用OpenSSL为其
Ruby是完全面向对象的语言。在ruby中,一切都是对象,因此属于某个类。例如5属于Objectclass1.9.3p194:001>5.class=>Fixnum1.9.3p194:002>5.class.superclass=>Integer1.9.3p194:003>5.class.superclass.superclass=>Numeric1.9.3p194:005>5.class.superclass.superclass.superclass=>Object1.9.3p194:006>5.class.superclass.superclass.superclass.su
我想生成一个包含数字、字母和特殊字符的给定(长度可能不同)长度的完全随机的“唯一”(我将确保使用我的模型)标识符例如:161551960578281|2.AQAIPhEcKsDLOVJZ.3600.1310065200.0-514191032|有人可以建议在RubyonRails中最有效的方法吗?编辑:重要:如果可能,请评论您提出的解决方案的效率,因为每次用户进入网站时都会使用它!谢谢 最佳答案 将其用于访问token与UUID不同。您不仅需要伪随机性,而且还需要加密安全PRNG.如果您真的不关心您使用的是什么字符(它们不会增加任何
在RSpec测试中,我创建了一个记录,其中包含多个内存值。foo.reload对对象的属性按预期工作,但内存的属性仍然存在。到目前为止,它通过完全重新创建对象来工作:foo=Foo.find(123)但在我的例子中,查找记录的逻辑实际上更复杂。什么是完全重新加载记录并删除所有内存值的好方法? 最佳答案 好的方法是您已有的方法:完全重新创建对象。您不能以任何简单的“Rails”方式“重新加载”对象的内存值,因为内存属性不是Rails或ActiveRecord的功能。两者都不知道您是如何内存方法的。
classAdo_something_from_bdefmethod_in_aendendmoduleBdefself.includedbasebase.extendClassMethodsendmoduleClassMethodsdefdo_something_from_bA.class_evaldoalias_method:aliased_method_in_a,:method_in_aendendendendA.send(:include,B)该代码将失败,因为当调用do_somethind_from_b时,method_in_a尚不存在。那么有没有一种方法可以在classA完全
我有一个启动DRb服务的脚本,然后生成处理程序对象并通过DRb.thread.join等待。我希望脚本一直运行直到被明确杀死,所以我添加了trap"INT"doDRb.stop_serviceend在Ruby1.8下成功停止DRb服务并退出,但在1.9下似乎死锁(在OSX10.6.7上)。对该进程进行采样显示在semaphore_wait_signal_trap中有几个线程在旋转。我假设我在调用stop_service时做错了什么,但我不确定是什么。谁能给我任何关于如何正确处理它的指示? 最佳答案 好的,我想我已经找到了解决方案。如