不久前,为了满足工作中日常的各种实验测试需求,终于按需求组装一台塔式的server T440。但是没有多久就出现些问题,以下大概是问题和现象简单描述:
(1). 最开始时,没几天就出现自动重启的问题,当时也正好做了一个比较消耗资源的大集群的实验,当时初步判断可能是内存资源不够(实际按监控来看,并没使用多少,而且也没真正跑应用),就没太理会。
(2). 没过几天,竟然发现在简单跑一台虚拟机的情况下,还是出现自动重启,但是还是没触发底线,感觉还能用,就此算了,直到一天,直出现问题了,重启后,直起不来。
(3). 出现问题时,大概有两个现象:A. 服务器的一些灯都从原先的蓝色变成黄色警告 B. 屏幕上报了内存错误 通过Output大概知道问题,但是由于自己对这方面不太熟悉,第一时间还是和售后联系。


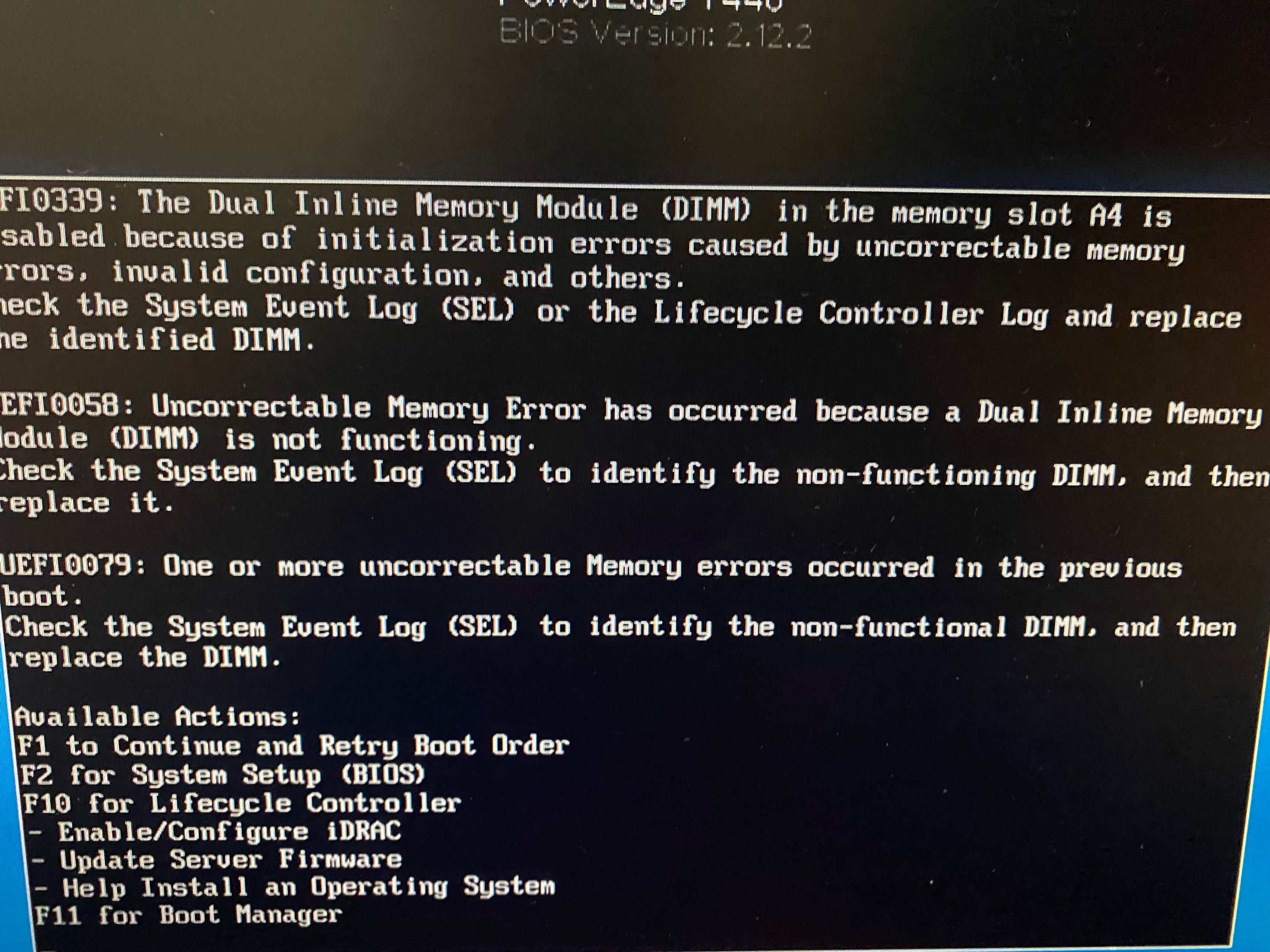
售后给出的建议是内存有问题,打开机箱重新拨插下。过程中做以下操作修复问题:
- 操作1:按照指引打开精巧的设计的server机箱,找到报错A4槽位的的内存条,重新拨插后,还是不行,而且把它拨掉进行重启,却一直卡在BIOS驱动加载,重新插回去又回到内存报错的界面。暂时判断A4的内存条出现问题。
- 操作2:按照指引关机后,拨掉电源,按住电源开关銉30秒后,再进行重启,还是无果。
- 操作3:现在8根内存A1~A8槽位,把A2-A8都拨掉,进行启动,发现可行,然后再把A2-A4的插上,这时也可以启动,再次把A5-A7的都补上,发现也正常,为了再次验证A4内存条是否正常,再次尝试插到A8的位置上进行启动,最后,竟然启动起来了,问题解决了。
小结:操作过后,一段时间也在保持服务器的运行,暂时没发现有重启的现象,有可能组装时A4上插得不太好。
我写了一个简单的脚本,它应该读取整个目录,然后通过去除HTML标签将HTML数据解析为普通脚本,然后将其写入一个文件。我有8GB内存和大量可用虚拟内存。当我这样做时,我有超过5GB的RAM可用。目录中最大的文件为3.8GB。脚本是file_count=1File.open("allscraped.txt",'w')do|out1|forfile_nameinDir["allParts/*.dat"]doputs"#{file_name}#:#{file_count}"file_count+=1File.open(file_name,"r")do|file|source=""tmp_sr
报错numpy.core._exceptions.MemoryError:Unabletoallocate1.04MiBforanarraywithshape(370,370)anddatatypefloat64原因最主要的还是电脑内存不足,因为需要处理的数据量太大,GPU性能不够,存在内存溢出现象但实际上它保存的不是模型文件,而是参数文件文件。在模型文件中,存储完整的模型,而在状态文件中,仅存储参数。因此,collections.OrderedDict只是模型的值。解决方案1.修改float精度在代码中我使用的是flaot64类型。但是实际上未必需要这么大的精度,这时候可以使用numpy中的
我开始使用一个相当大的模拟代码,它需要存储多达189383040个float。我知道,这很大,但没有太多办法可以解决这个问题,比如只查看其中的一部分或一个接一个地处理它们。我写了一个简短的脚本,它重现了错误,所以我可以在不同的环境中快速测试它:noSnapshots=1830noObjects=14784objectsDict={}forobjinrange(0,noObjects):objectsDict[obj]=[[],[],[]]forsnapshotinrange(0,noSnapshots):objectsDict[obj][0].append([1.232143454,1
我想知道在将大型数组编码为json时,json.dump()或json.dumps()中哪一个最有效格式。你能给我看一个使用json.dump()的例子吗?实际上,我正在制作一个PythonCGI,它使用ORMSQlAlchemy从MySQL数据库获取大量数据,在一些用户触发处理后,我将最终输出存储在一个数组中,我最终将其转换为Json。但是当转换为JSON时:printjson.dumps({'success':True,'data':data})#dataismyarray我收到以下错误:Traceback(mostrecentcalllast):File"C:/script/cg
我正在使用以下R代码(它也利用Java参数来增加内存):library(xlsx)options(java.parameters="-Xmx1g")library(XLConnect)NiVeversion1.xlsx文件大小为13MB。我收到以下错误:Errorin.jcall("RJavaTools","Ljava/lang/Object;","invokeMethod",cl,:java.lang.OutOfMemoryError:Javaheapspace有人可以帮忙吗? 最佳答案 尝试增加java堆大小(足够),方法是:o
我有一个Python程序,当我向它提供一个大文件时,它会因MemoryError而死。是否有任何工具可以用来确定内存的使用情况?这个程序在较小的输入文件上运行良好。该程序显然需要一些可扩展性改进;我只是想弄清楚在哪里。正如一位智者曾经说过的那样,“优化之前先进行基准测试”。(只是为了避免不可避免的“添加更多RAM”答案:这是在具有4GBRAM的32位WinXP机器上运行,因此Python可以访问2GB可用内存。添加更多内存在技术上是不可能的。重新安装我的安装64位Windows的PC不实用。)编辑:糟糕,这是WhichPythonmemoryprofilerisrecommended?
我在具有24GB内存的Windows864位系统上运行Python2.7(64位)。在对通常的Sklearn.linear_models.Ridge进行拟合时,代码运行良好。问题:但是,当使用Sklearn.linear_models.RidgeCV(alphas=alphas)进行拟合时,我遇到了显示的MemoryError错误在执行拟合过程的rr.fit(X_train,y_train)行下方。我怎样才能避免这个错误?代码片段deffit(X_train,y_train):alphas=[1e-3,1e-2,1e-1,1e0,1e1]rr=RidgeCV(alphas=alphas
我用try/exceptblock包装了一些可能会耗尽内存的代码。但是,虽然生成了MemoryError,但它没有被捕获。我有以下代码:whileTrue:try:self.create_indexed_vocab(vocab)self.reset_weights()break;exceptMemoryError:#Stufftoreducesizeofvocabularyself.vocab,self.index2word=None,Noneself.syn0,self.syn1=None,Noneself.min_count+=1logger.info(...formatstrin
我用try/exceptblock包装了一些可能会耗尽内存的代码。但是,虽然生成了MemoryError,但它没有被捕获。我有以下代码:whileTrue:try:self.create_indexed_vocab(vocab)self.reset_weights()break;exceptMemoryError:#Stufftoreducesizeofvocabularyself.vocab,self.index2word=None,Noneself.syn0,self.syn1=None,Noneself.min_count+=1logger.info(...formatstrin
上下文我的小型Python脚本使用一个库来处理一些相对较大的数据。此任务的标准算法是动态规划算法,因此大概“幕后”库分配了一个大数组来跟踪DP的部分结果。事实上,当我尝试给它相当大的输入时,它会立即给出一个MemoryError。最好不要深入库的深处,我想弄清楚是否值得在具有更多内存的不同机器上尝试这个算法,或者尝试减少我的输入大小,或者它是否丢失导致我尝试使用的数据大小。问题当我的Python代码抛出MemoryError时,是否有一种“自上而下”的方式让我调查我的代码尝试分配的内存大小是什么导致了错误,例如通过检查错误对象? 最佳答案