本文 ffmpeg4.4.1 源码为准,用以下命令分析 ffmpeg.c 里面的硬件加速逻辑实现。
命令如下:
ffmpeg.exe -hwaccel cuvid -vcodec h264_cuvid -i juren_10s.mp4 -vcodec h264_nvenc -acodec copy juren_h264_nvenc_10s.mp4 -y以上命令使用 h264_cuvid 硬件解码 MP4,然后再使用 h264_nvenc 硬件编码成 MP4。juren_10s.mp4 下载地址,百度网盘,提取码:3khn
如何搭建 qt creator 的 ffmpeg 硬件加速调试环境,请看以下文章。
CUDA 硬件加速的代码,貌似不是ABI 兼容的,所以只能用 MSVC 编译出 DLL。然后 qt creator 里面也必须使用 msvc 编译调试,不能用 MinGW ,会报错。
完整项目下载:百度网盘,提取码:9yeu,qt creator 编译 Kits 请选择 MSVC 2019 64 bits ,调试环境如图:
其实ffmpeg.c 工程的硬件加速代码在3地方都有分布,解码,filter,编码。本文分开讲述。
硬件加速,解码的流程图如下:
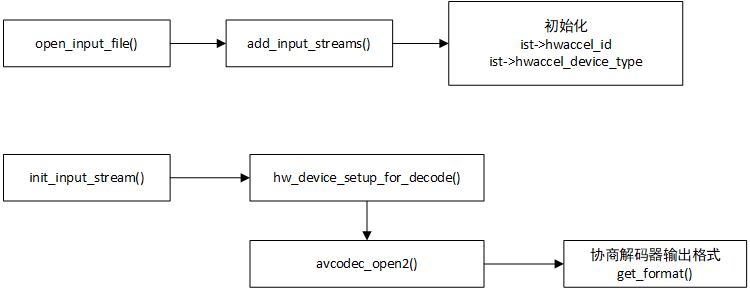
首先,在 ffmpeg_opt.c 的 add_input_streams() 添加输入流的时候,初始化硬件解码相关变量参数,如下:
ffmpeg_opt.c
if (hwaccel) {
// The NVDEC hwaccels use a CUDA device, so remap the name here.
if (!strcmp(hwaccel, "nvdec") || !strcmp(hwaccel, "cuvid"))
hwaccel = "cuda";
if (!strcmp(hwaccel, "none"))
ist->hwaccel_id = HWACCEL_NONE;
else if (!strcmp(hwaccel, "auto"))
ist->hwaccel_id = HWACCEL_AUTO;
else {
enum AVHWDeviceType type;
int i;
for (i = 0; hwaccels[i].name; i++) {
if (!strcmp(hwaccels[i].name, hwaccel)) {
ist->hwaccel_id = hwaccels[i].id;
break;
}
}
if (!ist->hwaccel_id) {
type = av_hwdevice_find_type_by_name(hwaccel);
if (type != AV_HWDEVICE_TYPE_NONE) {
ist->hwaccel_id = HWACCEL_GENERIC;
ist->hwaccel_device_type = type;
}
}
if (!ist->hwaccel_id) {
av_log(NULL, AV_LOG_FATAL, "Unrecognized hwaccel: %s.\n",
hwaccel);
av_log(NULL, AV_LOG_FATAL, "Supported hwaccels: ");
type = AV_HWDEVICE_TYPE_NONE;
while ((type = av_hwdevice_iterate_types(type)) !=
AV_HWDEVICE_TYPE_NONE)
av_log(NULL, AV_LOG_FATAL, "%s ",
av_hwdevice_get_type_name(type));
av_log(NULL, AV_LOG_FATAL, "\n");
exit_program(1);
}
}
}上面这段代码主要有以下重点:
-hwaccel cuvid 到 hwaccel 变量,所以上图中的 hwaccel 等于 cuvid,后续被合并修改为 cuda。-hwaccel cuvid 会导致 ist->hwaccel_id 没设置,会影响 get_format() 里面的逻辑然后在 ffmpeg.c 的 init_input_stream() 函数里面,初始化输入流的时候,也有一部分硬件解码相关代码 ,如下:
ffmpeg.c
static int init_input_stream(int ist_index, char *error, int error_len)
{
//省略代码...
if (ist->decoding_needed) {
ist->dec_ctx->opaque = ist;
//注意 get_format
ist->dec_ctx->get_format = get_format;
ist->dec_ctx->get_buffer2 = get_buffer;
省略代码...
}
ret = hw_device_setup_for_decode(ist);
if (ret < 0) {
snprintf(error, error_len, "Device setup failed for "
"decoder on input stream #%d:%d : %s",
ist->file_index, ist->st->index, av_err2str(ret));
return ret;
}
if ((ret = avcodec_open2(ist->dec_ctx, codec, &ist->decoder_opts)) < 0) {
//省略代码...
}
return 0;
}上面代码,有两个重点。
1,hw_device_setup_for_decode() 初始化硬件解码设备
2,get_format() ,get_format() 这是一个回调函数,在 avcodec_open2() 打开的解码器的时候会调用 get_format(),根据 get_format 的返回值决定解码器输出哪种 像素格式,一般解码器支持输出的像素格式有限,例如 h264_cuvid 只支持输出 NV12 跟 CUDA 两种像素格式。
先讲 hw_device_setup_for_decode() 函数,主要代码如下:
int hw_device_setup_for_decode(InputStream *ist)
{
const AVCodecHWConfig *config;
enum AVHWDeviceType type;
HWDevice *dev = NULL;
int err, auto_device = 0;
if (ist->hwaccel_device) {
//省略代码...
//命令行没指定 -hwaccel_device,这里逻辑没执行。
} else {
if (ist->hwaccel_id == HWACCEL_AUTO) {
auto_device = 1;
} else if (ist->hwaccel_id == HWACCEL_GENERIC) {
type = ist->hwaccel_device_type;
dev = hw_device_get_by_type(type);
if (!dev){
//重点代码
err = hw_device_init_from_type(type, NULL, &dev);
}
} else {
//省略代码.,逻辑没有执行
}
}
if (auto_device) {
//省略代码.,逻辑没有执行
}
if (!dev) {
av_log(ist->dec_ctx, AV_LOG_ERROR, "No device available "
"for decoder: device type %s needed for codec %s.\n",
av_hwdevice_get_type_name(type), ist->dec->name);
return err;
}
//重点代码
ist->dec_ctx->hw_device_ctx = av_buffer_ref(dev->device_ref);
if (!ist->dec_ctx->hw_device_ctx)
return AVERROR(ENOMEM);
return 0;
}由于我们命令行没使用 -hwaccel_device 指定硬件加速设备,所以 if (ist->hwaccel_device) {xxx} 的条件并没有跑进去。
以上代码都是经过删减的代码,有以下重点。
1,调用 hw_device_init_from_type(type, NULL, &dev); 初始化 dev 变量。
2,ist->dec_ctx->hw_device_ctx 初始化,用了 av_buffer_ref() 函数,AVBuffer 是ffmpeg的一个通用结构,很多字段都是 AVBuffer。C语言就是用一块void *内存来实现泛型,然后做指针强制转换,这块内存就会被解析成相应的类型(struct)。
接着分析 get_format 函数,get_format 是用来给调用层 决定解码出来什么样的 pixel format 的。get_format() 的定义如下:
/**
* callback to negotiate the pixelFormat
* @param fmt is the list of formats which are supported by the codec,
* it is terminated by -1 as 0 is a valid format, the formats are ordered by quality.
* The first is always the native one.
* @note The callback may be called again immediately if initialization for
* the selected (hardware-accelerated) pixel format failed.
* @warning Behavior is undefined if the callback returns a value not
* in the fmt list of formats.
* @return the chosen format
* - encoding: unused
* - decoding: Set by user, if not set the native format will be chosen.
*/
enum AVPixelFormat (*get_format)(struct AVCodecContext *s, const enum AVPixelFormat * fmt);第二个参数 const enum AVPixelFormat * fmt 是解码器支持的 像素格式。本命令使用的解码器是 h264_cuvid ,只支持 NV12,CUDA 两种像素格式。
get_format 函数的实现在 ffmpeg.c 里面:
static enum AVPixelFormat get_format(AVCodecContext *s, const enum AVPixelFormat *pix_fmts)
{
InputStream *ist = s->opaque;
const enum AVPixelFormat *p;
int ret;
省略代码...
return *p;
}主要有以下重点:
1,非硬件加速的解码器 (NV12 像素格式是非硬件加速的),默认取第一个支持的像素格式作为解码输出。可以看到这里直接 break ,跳过循环。
if (!(desc->flags & AV_PIX_FMT_FLAG_HWACCEL))
break;2,如果是硬件加速的解码 (CUDA 像素格式是硬件加速的),就会继续执行,用 avcodec_get_hw_config() 找出一个 config 是支持 AV_CODEC_HW_CONFIG_METHOD_HW_DEVICE_CTX 的。
if (ist->hwaccel_id == HWACCEL_GENERIC ||
ist->hwaccel_id == HWACCEL_AUTO) {
for (i = 0;; i++) {
config = avcodec_get_hw_config(s->codec, i);
if (!config)
break;
if (!(config->methods &
AV_CODEC_HW_CONFIG_METHOD_HW_DEVICE_CTX))
continue;
if (config->pix_fmt == *p)
break;
}
}3,尝试初始化硬件解码器。
ret = hwaccel_decode_init(s);
if (ret < 0) {
if (ist->hwaccel_id == HWACCEL_GENERIC) {
av_log(NULL, AV_LOG_FATAL,
" %s hwaccel requested for input stream #%d:%d, "
"but cannot be initialized.\n",
av_hwdevice_get_type_name(config->device_type),
ist->file_index, ist->st->index);
return AV_PIX_FMT_NONE;
}
continue;
}4,设置 硬件解码输出的 格式 为 CUDA 格式,break,然后会 return。
ist->hwaccel_pix_fmt = *p;
break;以上就是 ffmpeg.c 里 get_foramt() 对于普通的解码跟硬件解码的区别处理,主要重点如下:
1,普通解码直接返回第一个解码器支持的像素格式。
2,硬件解码会多做一些检测,跟变量初始化。
硬件解码还有一个函数 get_buffer(),也是在 ffmpeg.c 里面,代码如下:
static int get_buffer(AVCodecContext *s, AVFrame *frame, int flags)
{
InputStream *ist = s->opaque;
if (ist->hwaccel_get_buffer && frame->format == ist->hwaccel_pix_fmt)
return ist->hwaccel_get_buffer(s, frame, flags);
return avcodec_default_get_buffer2(s, frame, flags);
}这里面其实是对 qsv 硬件解码做了特殊处理,ist->hwaccel_get_buffer 这个只会在 qsv_init() 里面被初始化赋值。
我们用的是 cuda,会直接走默认的 get_buffer 函数,就是 avcodec_default_get_buffer2()。
至此 ,ffmpeg 的硬件解码已经分析完毕。
硬件加速 filter的处理如下:
ffmpeg_filter.c 1037行
ret = hw_device_setup_for_filter(fg);int hw_device_setup_for_filter(FilterGraph *fg)
{
HWDevice *dev;
int i;
// If the user has supplied exactly one hardware device then just
// give it straight to every filter for convenience. If more than
// one device is available then the user needs to pick one explcitly
// with the filter_hw_device option.
if (filter_hw_device)
dev = filter_hw_device;
else if (nb_hw_devices == 1)
dev = hw_devices[0];
else
dev = NULL;
if (dev) {
for (i = 0; i < fg->graph->nb_filters; i++) {
fg->graph->filters[i]->hw_device_ctx =
av_buffer_ref(dev->device_ref);
if (!fg->graph->filters[i]->hw_device_ctx)
return AVERROR(ENOMEM);
}
}
return 0;
}hw_device_setup_for_filter() 重点就是设置了 filter里面的 hw_device_ctx 变量,估计是用来处理 硬件像素格式的 filter 逻辑。
硬件加速,编码流程图如下:
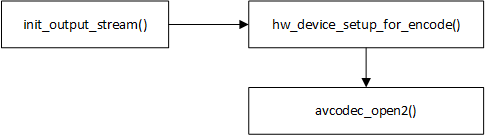
hw_device_setup_for_encode() 函数里的代码就不粘贴了,比较容易理解,在本文命令里主要就设置了一个变量 ost->enc_ctx->hw_frames_ctx
hw_device_setup_for_encode()
ost->enc_ctx->hw_frames_ctx = av_buffer_ref(frames_ref);命令行参数中,有个奇怪的地方, -hwaccel cuvid,我个人比较疑惑,这个参数起到什么样的作用,硬件编解码应该只需要指定解码器是什么就行了,为什么还要多此一举指定 -hwaccel cuvid 呢?带着这个疑问继续研究。接下来分析如果没有指定 -hwaccel cuvid 这个会有何影响,命令如下:
ffmpeg.exe -vcodec h264_cuvid -i juren_10s.mp4 -vcodec h264_nvenc -acodec copy juren_h264_nvenc_10s.mp4 -y
没设置 -hwaccel cuvid 会导致以下变化:
1,导致 add_input_streams() 里面的以下逻辑不会执行,导致 ist->hwaccel_id 没有值 。
add_input_streams()
if( hwaccel ){
设置 ist->hwaccel_id
设置 ist->hwaccel_device_type
}2,ist->hwaccel_id 没有值,就会导致 get_format() 函数返回的 AVPixelFormat *p 是 NV12,而不是 CUDA。这里 NV12 是没有 AV_PIX_FMT_FLAG_HWACCEL 这个标记的,CUDA有这个标记。所以会导致 h264_cuvid 这个解码器输出的 AVFrame 是 NV12 格式的,不是原来的 CUDA 格式。但 h264_cuvid 依然是一个硬件解码器。
3,影响 hw_device_setup_for_decode() 函数的逻辑,导致 ist->dec_ctx->hw_device_ctx 没有值。
4,影响 hw_device_setup_for_decode() 函数的逻辑,导致 hw_device_init_from_type() 没有执行,所以变量 nb_hw_devices 等于 0,应该是没有硬件设备的意思。
4,变量 nb_hw_devices 等于 0 会影响 hw_device_setup_for_filter() 函数的逻辑,导致 fg->graph->filters[i]->hw_device_ctx 没有赋值,hw_device_setup_for_filte() 函数的代码上面有,不贴了。
5,fg->graph->filters[i]->hw_device_ctx 没有赋值,会导致 hw_device_setup_for_encode() 里面的 av_buffersink_get_hw_frames_ctx() 函数拿不到值,进而导致 ost->enc_ctx->hw_frames_ctx 没有被设置,代码如下:
hw_device_setup_for_encode()
frames_ref = av_buffersink_get_hw_frames_ctx(ost->filter->filter);
ost->enc_ctx->hw_frames_ctx = av_buffer_ref(frames_ref); //没有执行做下总结, -hwaccel cuvid 没设置,所以
重点:解码的时候用的是 dec_ctx->hw_device_ctx ,编码的时候设置的 enc_ctx->hw_frames_ctx,hw_device_ctx 跟 hw_frames_ctx 应该是两个不同的东西,这里埋个坑,后续讲解。
虽然没设置 -hwaccel cuvid 导致这么多变量没有值,但是我看我的GPU,却实实在在跑满了,这个问题,我也百思不得其解,如下图:
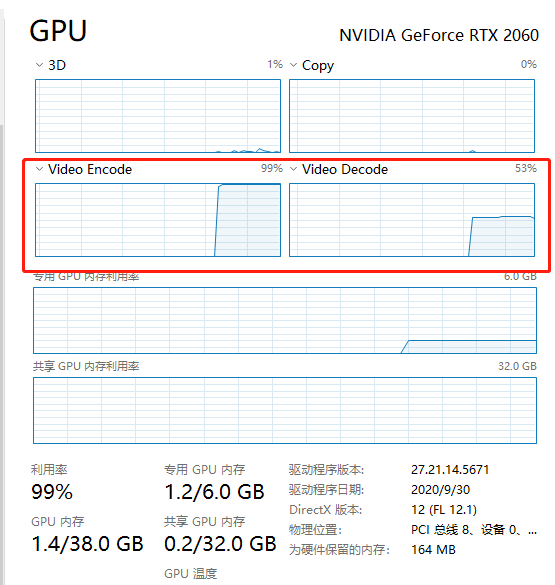
从上面的分析看起来,-hwaccel cuvid 貌似并不会影响到使用GPU编解码
讨论补充:
CUDA 跟 CUVID 是 ffmpeg 实现的两种使用硬件加速的方式,主要区别是 frame 怎么解码,然后内存数据怎么转发。

还有最后一个分析,h264_cuvid 解码器解码出来 CUDA 格式的 AVFrame,因为某些编码器只支持NV12格式,我们想转成 NV12 的AVFrame,再传递给 编码器如何操作。可以指定 -hwaccel_output_format nv12 ,命令如下:
ffmpeg.exe -hwaccel cuvid -hwaccel_output_format nv12 -vcodec h264_cuvid -i juren_10s.mp4 -vcodec h264_nvenc -acodec copy juren_h264_nvenc_10s.mp4 -y这个功能是由 hwaccel_retrieve_data() 函数实现的,在 hwaccel_retrieve_data() 内部 如果 ist->hwaccel_pix_fmt 跟 ist->hwaccel_output_format 不一致,就会进行硬件格式转换。
这里的像素格式转换跟 《ffmpeg命令分析-pix_fmt》 不太一样,-pix_fmt 是通过 format filter 来实现的,针对的是非硬件像素格式,如果 format filter 的输入是 cuda 像素格式,输出是 nv12 之类的非硬件像素格式,format filter会报错。
总结:
1,-pix_fmt ,通过 format filter 来实现,用于非硬件像素格式的转换。
2,-hwaccel_output_format,通过 hwaccel_retrieve_data() 来实现,用于硬件像素格式的转换。
ffmpeg cuda 硬件加速 分析完毕。
由于笔者的水平有限, 加之编写的同时还要参与开发工作,文中难免会出现一些错误或者不准确的地方,恳请读者批评指正。如果读者有任何宝贵意见,或者希望交流音视频技术的,可以加我微信 Loken1。
推荐一个零声学院免费公开课程,个人觉得老师讲得不错,分享给大家:
Linux,Nginx,ZeroMQ,MySQL,Redis,fastdfs,MongoDB,ZK,流媒体,CDN,P2P,K8S,Docker,TCP/IP,协程,DPDK等技术内容,立即学习
2022/8/4更新支持加入水印水印必须包含透明图像,并且水印图像大小要等于原图像的大小pythonconvert_image_to_video.py-f30-mwatermark.pngim_dirout.mkv2022/6/21更新让命令行参数更加易用新的命令行使用方法pythonconvert_image_to_video.py-f30im_dirout.mkvFFMPEG命令行转换一组JPG图像到视频时,是将这组图像视为MJPG流。我需要转换一组PNG图像到视频,FFMPEG就不认了。pyav内置了ffmpeg库,不需要系统带有ffmpeg工具因此我使用ffmpeg的python包装p
我正在尝试使用以下代码通过将ffmpeg实用程序作为子进程运行并获取其输出并解析它来确定视频分辨率:IO.popen'ffmpeg-i'+path_to_filedo|ffmpegIO|#myparsegoeshereend...但是ffmpeg输出仍然连接到标准输出并且ffmepgIO.readlines是空的。ffmpeg实用程序是否需要一些特殊处理?或者还有其他方法可以获得ffmpeg输出吗?我在WinXP和FedoraLinux下测试了这段代码-结果是一样的。 最佳答案 要跟进mouviciel的评论,您需要使用类似pope
我有33个规范以大约5秒的速度运行,以这种速度运行会导致测试套件变慢。我追踪到请求规范(4秒以上),因为模型规范只用了一小部分时间。我已经检查过,我的请求规范没有任何过于复杂或不必要的东西,所以我不知道该去哪里让它们更快,而不是只在推送代码之前运行它们以确保一切正常.加快请求规范的最佳方法是什么? 最佳答案 我使用Spork来加速我的测试。它保持整个环境加载以赢得时间。看看这个博客:http://ykyuen.wordpress.com/2010/12/14/rails-running-rspec-with-spork-test-s
我运行的是OSX,对视频转换一无所知。但我有大约200个视频都是mp4格式,无法在Firefox中播放。我需要将它们转换为ogg才能使用html5视频标签。这些文件位于一个文件夹结构中,这使得一次一个地处理一个文件变得困难。我希望bash命令或Ruby命令遍历所有子文件夹并找到所有.mp4并转换它们。我找到了一份关于如何使用Google执行此操作的引用资料:http://athmasagar.wordpress.com/2011/05/12/a-bash-script-to-convert-mp4-files-to-oggogv/#!/bin/bashforfin$(ls*mp4|se
目录需求基于JavaCV跨平台执行ffmpeg命令[^1]坑一内存不足坑二多个ffmpeg进程并行导致IO负载大,进而导致ioerror?坑三使用Java操作ffmpeg时,有时会卡死坑四Process的waitFor死锁问题及解决办法需求给透明背景的视频自动叠加一张背景图片基于JavaCV跨平台执行ffmpeg命令1我测试发现的本需求的最小依赖:dependency>groupId>org.bytedecogroupId>artifactId>ffmpeg-platform-gplartifactId>version>5.0-1.5.7version>dependency>核心代码:Stri
对于一个项目,我需要解析一些非常大的CSV文件。一些条目的内容存储在MySQL数据库中。我正在尝试使用多线程来加快速度,但到目前为止,这只会减慢速度。我解析了一个CSV文件(最大10GB),其中一些记录(20M+记录CSV中的大约5M)需要插入到MySQL数据库中。为了确定需要插入的记录,我们使用Redis服务器和包含正确ID/引用的集合。由于我们在任何给定时间处理大约30个这样的文件,并且存在一些依赖关系,我们将每个文件存储在一个Resque队列中,并让多个服务器处理这些(优先级)队列。简而言之:classWorkerdefself.perform(file)CsvParser.ea
在编译sass时,我的编译时间往往很长(在当前的中型项目中长达9秒),而我的笔记本电脑速度非常快,而且带有ssd。我通过grunt-contrib-sass使用sassass一个grunt任务,但是直接从命令行运行sass时编译时间差别不大。Libsass另一方面,同一个项目只需要大约100毫秒,但它不支持我需要的几个功能。所以我想知道我有什么可能加快编译过程?拆分文件当然有帮助,但是还有其他副作用更小的方法吗?编辑:此外,我也很乐意解释libsass为什么比ruby-sass快得多。不知何故,我非常怀疑这只是因为ruby比C/C++慢得多。还是我错了?编辑2:当我使用Ubun
我使用Octopress作为我的博客引擎。这是完美的。但是如果帖子很多,比如400+,生成速度就很慢了。那么,有什么方法可以加快Jekyll/Octopress的生成速度吗?谢谢。 最佳答案 显然,如果您只处理一篇文章,则无需等待整个站点生成。您正在寻找的是rakeisolate[partial_post_name]任务。使用rakeisolate,您可以仅“隔离”您正在处理的帖子,并将所有其他帖子移至source/_stash文件夹。partial_post_name参数只是帖子文件名中的一些单词。例如,如果我想将帖子与前面的示例
基于ffmpeg的视频处理与MPEG的压缩试验ffmpeg介绍与基础知识对提取到的图像进行处理RGB并转化为YUV对YUV进行DCT变换对每个8*8的图像块进行进行量化操作ffmpeg介绍与基础知识ffmpeg是视频和图像处理的工具包,它的下载网址是https://ffmpeg.org/download.html。页面都是英文且下载正确的包的路径笔者找的时候还费点劲,这里记录一下也方便读者。选中这个Windows下的下午files,选择第一个这里有essential和full版本的,大家根据需要自行选择版本包下载下载好之后,在官网上下载ffmpeg的full包,一共300+MB解压,然后安装b
我正在上介绍性软件开发课,我的作业是创建一个带有两个参数的剪刀石头布程序(石头,纸)等,并返回获胜的arg。现在,如果我可以使用条件语句,我会快速解决这个问题,但作业说我们需要知道的一切都在前三个ruby教科书的章节,这些章节不包括条件!没有它们是否可以创建这个程序?或者他只是希望我们足智多谋并使用条件句?这是一个非常简单的条件分配......我在想我可能在这里遗漏了一些东西。编辑:我正在考虑那个chmod数字系统,并认为通过该加法系统可能有解决方案...... 最佳答案 这是一个只使用哈希的方法:RULES={:rock=>{:r