您好,我是@马哥python说,今天继续分享爬虫案例。
爬取网站:雪球网的沪深股市行情数据
具体菜单:雪球网 > 行情中心 > 沪深股市 > 沪深一览
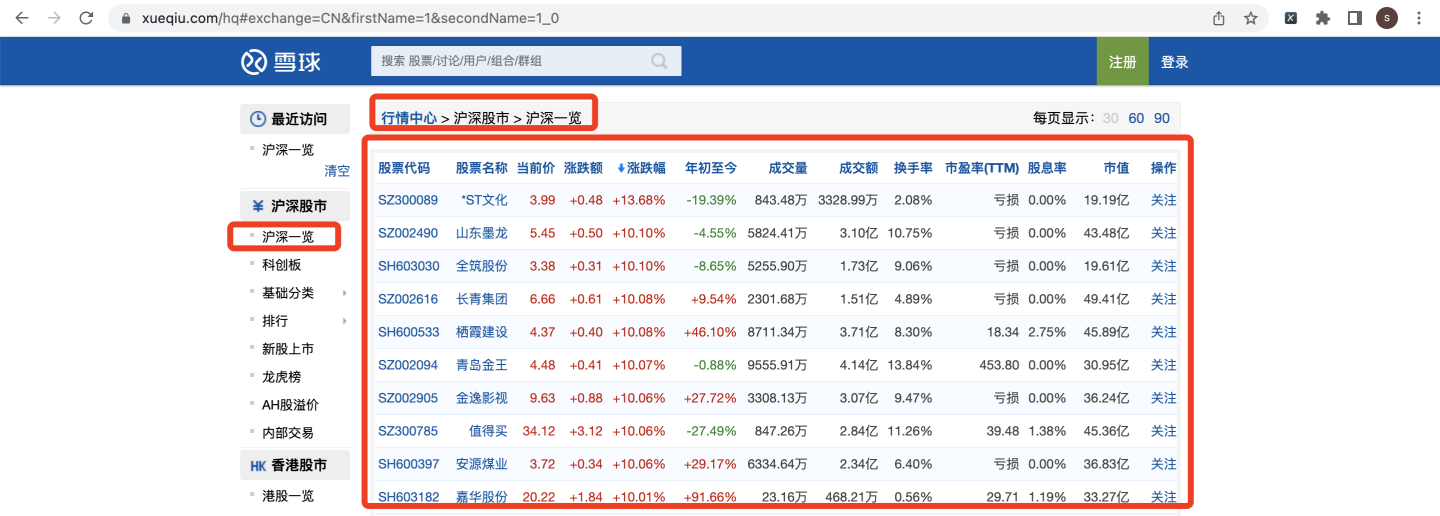
爬取字段,含:
股票代码,股票名称,当前价,涨跌额,涨跌幅,年初至今,成交量,成交额,换手率,市盈率,股息率,市值。
在网页中,我们注意到,默认每页显示30条:
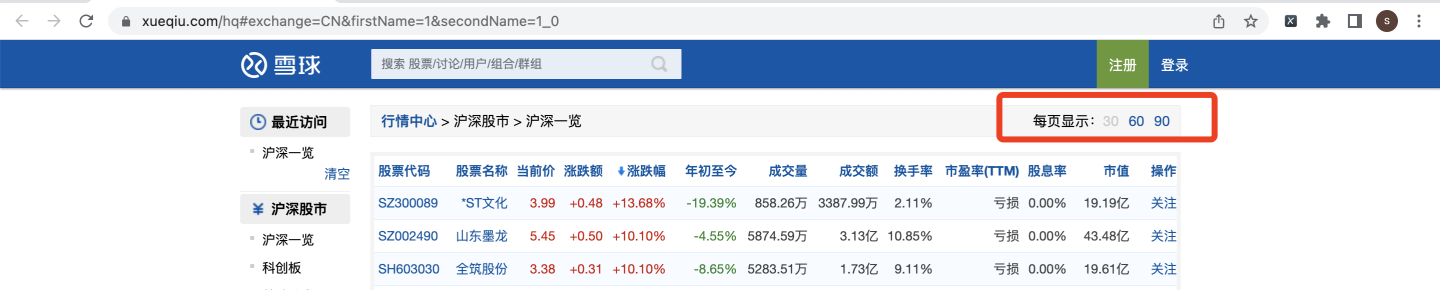
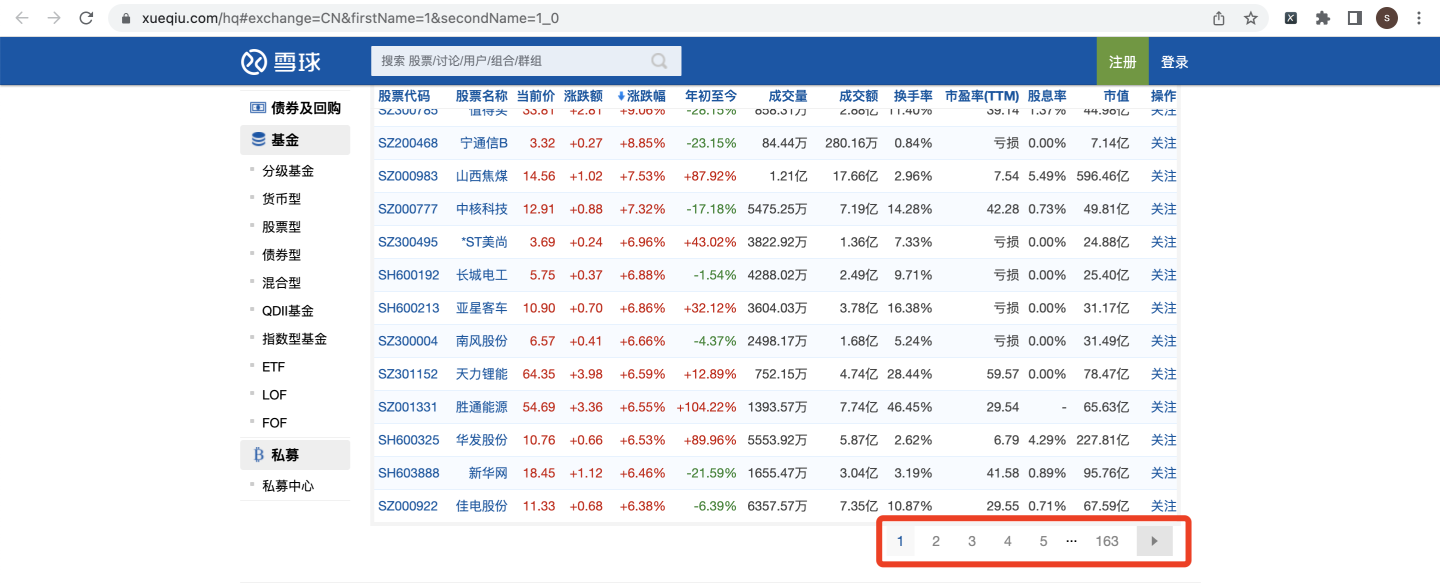
一共163页:
如果切换到每页90条,总页数就会变成55页:
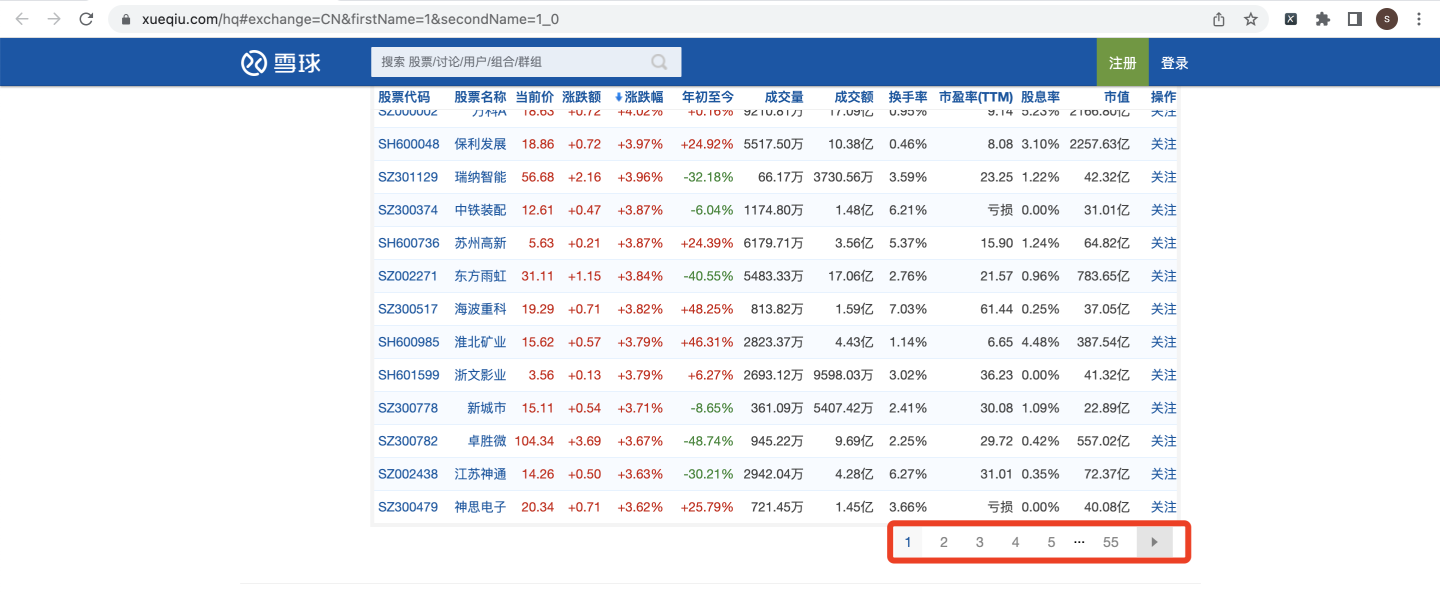
基于尽量少的向页面发送请求,防止反爬的考虑,选择每页90条。
下面,开始分析网页接口。
按F12,打开chrome浏览器的开发者模式,重新刷新网页,并翻页3次,发现3个网页请求:
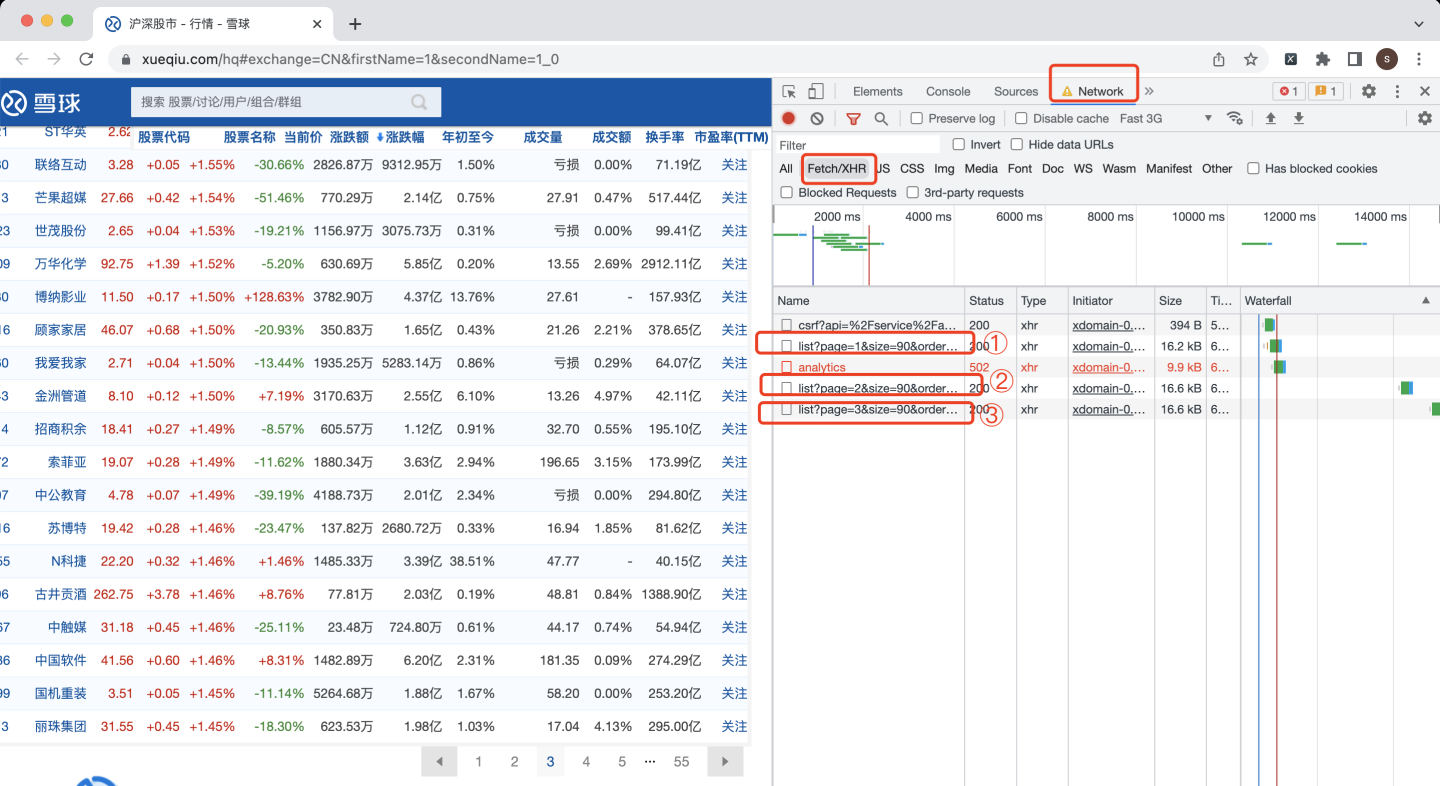
由此推测,这就是目标股票数据。
为了验证此猜测,打开预览页面,展开json数据,找到第0只股票:
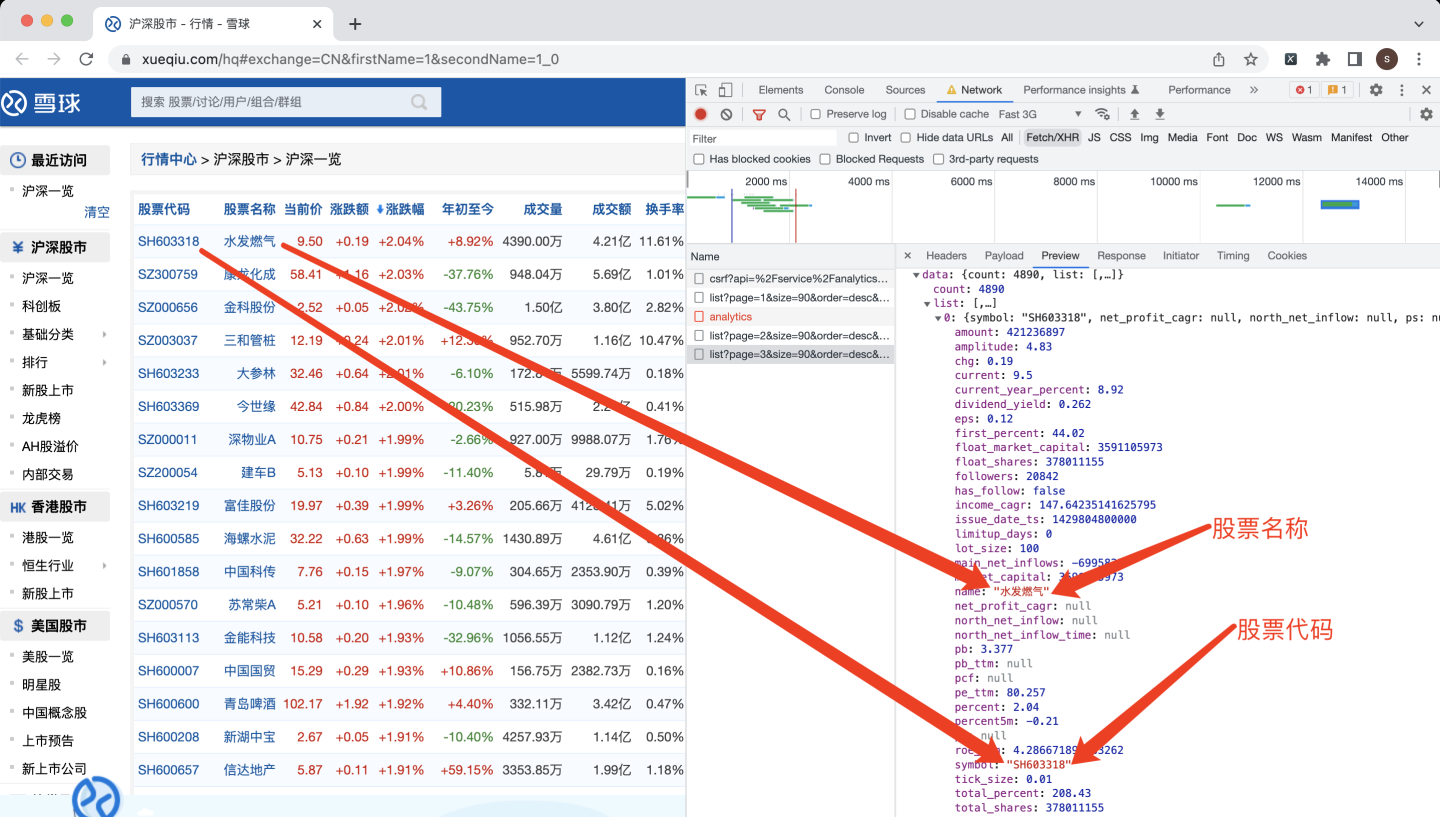
经过和页面对比,发现数据一致。
下面继续看网页请求参数:
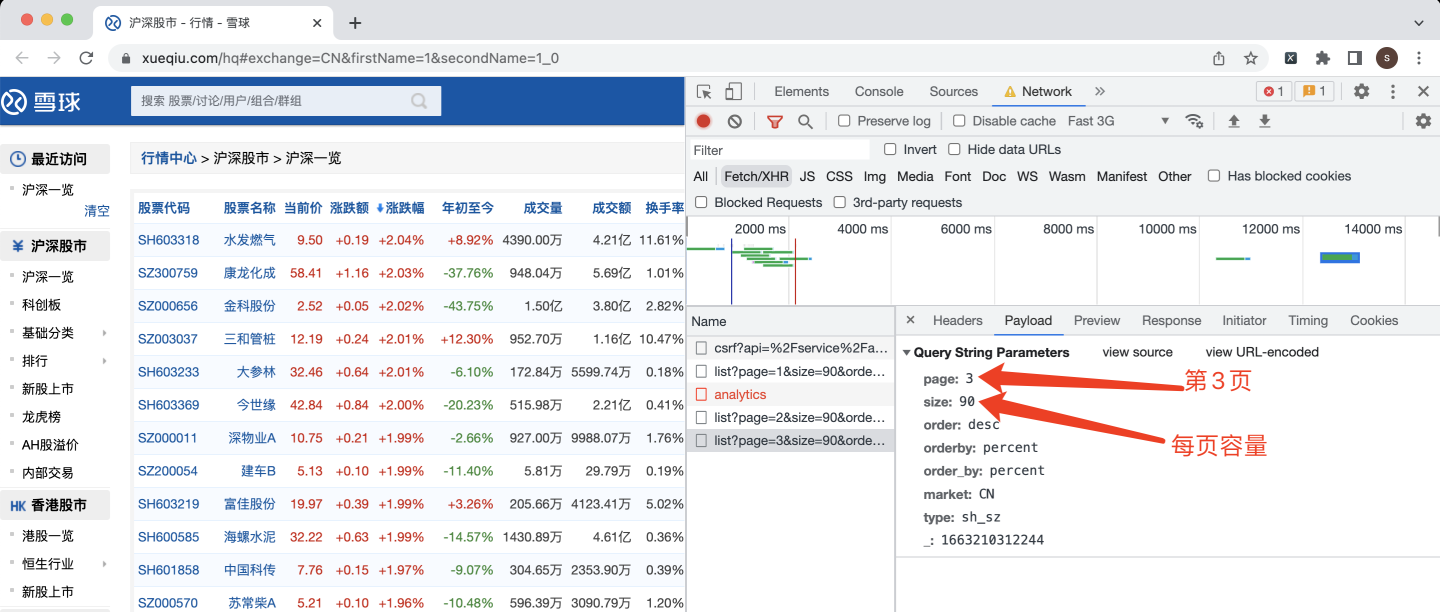
这里每页容量是90条数据,大胆猜测一下,如果每页容量指定为5000,只爬取1页,是不是更省事儿。
虽然大胆猜测,但要小心求证,毕竟一名合格的接口开发者不会这么做。
一般情况下,如果发现用户请求大于每页容量,会返回一个exceed max size或者invalid request之类的error给用户,但我们不妨试试。。
下面开始开发爬虫代码:
首先,定义一个请求头,直接从开发者模式里copy过来:
# 定义字符串请求头
header1 = """
Accept: */*
Accept-Encoding: gzip, deflate, br
Accept-Language: zh-CN,zh;q=0.9,en-US;q=0.8,en;q=0.7
cache-control: no-cache
Connection: keep-alive
Cookie: 换成自己的
Host: xueqiu.com
Referer: https://xueqiu.com/hq
sec-ch-ua: "Google Chrome";v="105", "Not)A;Brand";v="8", "Chromium";v="105"
sec-ch-ua-mobile: ?0
sec-ch-ua-platform: "macOS"
Sec-Fetch-Dest: empty
Sec-Fetch-Mode: cors
Sec-Fetch-Site: same-origin
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.0.0 Safari/537.36
X-Requested-With: XMLHttpRequest
"""
通过copy_headers_dict转换成dict格式:
# 转换成dict格式请求头
header2 = copy_headers_dict(header1)
如此方便!
下面开始发送请求,如上所讲,大胆尝试请求第1页,页容量5000条:
# 请求地址
url = "https://xueqiu.com/service/v5/stock/screener/quote/list?page=1&size=5000&order=desc&orderby=percent&order_by=percent&market=CN&type=sh_sz&_=1663203107799"
# 发送请求
resp = requests.get(url, headers=header2)
查看响应码及响应数据,真的请求到了!
估计过不了多久,雪球网的程序员小哥哥该被领导请去喝茶了~
下面开始解析json数据:
# 解析json数据
json_data = resp.json()
data_list = json_data['data']['list']
先定义一些空列表用于存储数据:
# 定义空列表用于存储数据
symbol_list = [] # 股票代码
name_list = [] # 股票名称
current_list = [] # 当前价
chg_list = [] # 涨跌额
percent_list = [] # 涨跌幅
current_year_percent_list = [] # 年初至今
volume_list = [] # 成交量
amount_list = [] # 成交额
turnover_rate_list = [] # 换手率
pe_ttm_list = [] # 市盈率
dividend_yield_list = [] # 股息率
market_capital_list = [] # 市值
其实,接口里还有更多字段,这里我只爬取了网页上有的字段。
把解析好的字段数据append到空列表中,以股票代码和股票名称为例:
for data in data_list:
symbol_list.append(data['symbol'])
name_list.append(data['name'])
print('已爬取第{}只股票,股票代码:{},股票名称:{}'.format(count, data['symbol'], data['name']))
其他字段同理,不再演示。
最后,把列表数据存入DataFrame数据中:
df = pd.DataFrame(
{
'股票代码': symbol_list,
'股票名称': name_list,
'当前价': current_list,
'涨跌额': chg_list,
'涨跌幅': percent_list,
'年初至今': current_year_percent_list,
'成交量': volume_list,
'成交额': amount_list,
'换手率': turnover_rate_list,
'市盈率': pe_ttm_list,
'股息率': dividend_yield_list,
'市值': market_capital_list,
}
)
最后,用to_csv把最终数据落地成csv文件,大功告成!
演示视频:
https://www.zhihu.com/zvideo/1553775083570802688
附完整源码:点击这里完整源码
我是 马哥python说,感谢阅读!
关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭4年前。Improvethisquestion我想在固定时间创建一系列低音和高音调的哔哔声。例如:在150毫秒时发出高音调的蜂鸣声在151毫秒时发出低音调的蜂鸣声200毫秒时发出低音调的蜂鸣声250毫秒的高音调蜂鸣声有没有办法在Ruby或Python中做到这一点?我真的不在乎输出编码是什么(.wav、.mp3、.ogg等等),但我确实想创建一个输出文件。
这个问题在这里已经有了答案:关闭10年前。PossibleDuplicate:Pythonconditionalassignmentoperator对于这样一个简单的问题表示歉意,但是谷歌搜索||=并不是很有帮助;)Python中是否有与Ruby和Perl中的||=语句等效的语句?例如:foo="hey"foo||="what"#assignfooifit'sundefined#fooisstill"hey"bar||="yeah"#baris"yeah"另外,类似这样的东西的通用术语是什么?条件分配是我的第一个猜测,但Wikipediapage跟我想的不太一样。
什么是ruby的rack或python的Java的wsgi?还有一个路由库。 最佳答案 来自Python标准PEP333:Bycontrast,althoughJavahasjustasmanywebapplicationframeworksavailable,Java's"servlet"APImakesitpossibleforapplicationswrittenwithanyJavawebapplicationframeworktoruninanywebserverthatsupportstheservletAPI.ht
华为OD机试题本篇题目:明明的随机数题目输入描述输出描述:示例1输入输出说明代码编写思路最近更新的博客华为od2023|什么是华为od,od薪资待遇,od机试题清单华为OD机试真题大全,用Python解华为机试题|机试宝典【华为OD机试】全流程解析+经验分享,题型分享,防作弊指南华为o
我想解析一个已经存在的.mid文件,改变它的乐器,例如从“acousticgrandpiano”到“violin”,然后将它保存回去或作为另一个.mid文件。根据我在文档中看到的内容,该乐器通过program_change或patch_change指令进行了更改,但我找不到任何在已经存在的MIDI文件中执行此操作的库.他们似乎都只支持从头开始创建的MIDI文件。 最佳答案 MIDIpackage会为您完成此操作,但具体方法取决于midi文件的原始内容。一个MIDI文件由一个或多个音轨组成,每个音轨是十六个channel中任何一个上的
本文主要介绍在使用Selenium进行自动化测试或者任务时,对于使用了iframe的页面,如何定位iframe中的元素文章目录场景描述解决方案具体代码场景描述当我们在使用Selenium进行自动化测试的时候,可能会遇到一些界面或者窗体是使用HTML的iframe标签进行承载的。对于iframe中的标签,如果直接查找是无法找到的,会抛出没有找到元素的异常。比如近在咫尺的例子就是,CSDN的登录窗体就是使用的iframe,大家可以尝试通过F12开发者模式查看到的tag_name,class_name,id或者xpath来定位中的页面元素,会抛出NoSuchElementException异常。解决
1.postman介绍Postman一款非常流行的API调试工具。其实,开发人员用的更多。因为测试人员做接口测试会有更多选择,例如Jmeter、soapUI等。不过,对于开发过程中去调试接口,Postman确实足够的简单方便,而且功能强大。2.下载安装官网地址:https://www.postman.com/下载完成后双击安装吧,安装过程极其简单,无需任何操作3.使用教程这里以百度为例,工具使用简单,填写URL地址即可发送请求,在下方查看响应结果和响应状态码常用方法都有支持请求方法:getpostputdeleteGet、Post、Put与Delete的作用get:请求方法一般是用于数据查询,
在VMware16.2.4安装Ubuntu一、安装VMware1.打开VMwareWorkstationPro官网,点击即可进入。2.进入后向下滑动找到Workstation16ProforWindows,点击立即下载。3.下载完成,文件大小615MB,如下图:4.鼠标右击,以管理员身份运行。5.点击下一步6.勾选条款,点击下一步7.先勾选,再点击下一步8.去掉勾选,点击下一步9.点击下一步10.点击安装11.点击许可证12.在百度上搜索VM16许可证,复制填入,然后点击输入即可,亲测有效。13.点击完成14.重启系统,点击是15.双击VMwareWorkstationPro图标,进入虚拟机主
2022/8/4更新支持加入水印水印必须包含透明图像,并且水印图像大小要等于原图像的大小pythonconvert_image_to_video.py-f30-mwatermark.pngim_dirout.mkv2022/6/21更新让命令行参数更加易用新的命令行使用方法pythonconvert_image_to_video.py-f30im_dirout.mkvFFMPEG命令行转换一组JPG图像到视频时,是将这组图像视为MJPG流。我需要转换一组PNG图像到视频,FFMPEG就不认了。pyav内置了ffmpeg库,不需要系统带有ffmpeg工具因此我使用ffmpeg的python包装p
1.1.1 YARN的介绍 为克服Hadoop1.0中HDFS和MapReduce存在的各种问题⽽提出的,针对Hadoop1.0中的MapReduce在扩展性和多框架⽀持⽅⾯的不⾜,提出了全新的资源管理框架YARN. ApacheYARN(YetanotherResourceNegotiator的缩写)是Hadoop集群的资源管理系统,负责为计算程序提供服务器计算资源,相当于⼀个分布式的操作系统平台,⽽MapReduce等计算程序则相当于运⾏于操作系统之上的应⽤程序。 YARN被引⼊Hadoop2,最初是为了改善MapReduce的实现,但是因为具有⾜够的通⽤性,同样可以⽀持其他的分布式计算模