前言
- 本文是之前做云计算实验整理的内容,借博客保存一下!
- 使用不同方法对算法加速还是很有意思的!
自选一张图片,按照实验指南说明在jetson05节点上基于OpenMP和CUDA对图片进行边缘提取实验,记录梯度向量幅度的最小值和最大值,比较串行算法和并行算法的运行时间,并提交处理后的边缘提取结果图片。试一下:如果编译时开启优化选项(比如选择“-O3”级别的优化),串行算法和并行算法的运行时间分别有什么变化。
使用提供的opencl-examples源码在你自己的计算机上进行基于OpenCL的GPU并行算法实验,记录你的实验环境参数(包括CPU和GPU相关参数等,可从实验程序日志中获取)以及各个算法的串行版本和GPU并行版本的运行时间,并进行简单的对比分析。

a. 运行命令
zz@jetson05:~/examples$ g++ -fopenmp -o sobel sobel.cpp -lfreeimage
zz@jetson05:~/examples$ ./sobel IBM_Blue_Gene_P_supercomputer.jpg
Filtering of input image start ...
the minimum value: 0
the maximum value: 1052.84
The total time for execution is 7.66395s
b. 运行截图

c. 图片处理结果

a. 运行命令
zz@jetson05:~/examples$ g++ -fopenmp -o sobel_omp sobel_omp.cpp -lfreeimage
zz@jetson05:~/examples$ ./sobel_omp IBM_Blue_Gene_P_supercomputer.jpg
Filtering of input image start ...
the minimum value: 0
the maximum value: 1052.84
actual threads number: 8
The total time for execution is 2.20083s
b. 运行截图

c. 图片处理结果

a. 修改代码

zz@jetson05:~/examples$ g++ -fopenmp -o sobel_omp16 sobel_omp.cpp -lfreeimage
zz@jetson05:~/examples$ ./sobel_omp16 IBM_Blue_Gene_P_supercomputer_out.jpg
Filtering of input image start ...
the minimum value: 0
the maximum value: 1001.81
actual threads number: 16
The total time for execution is 1.84612s
b. 运行截图及结果

a. 串行算法
选择“-O3”级别的优化
zz@jetson05:~/examples$ g++ -fopenmp -O3 sobel sobel.cpp -lfreeimage
zz@jetson05:~/examples$ ./sobel IBM_Blue_Gene_P_supercomputer.jpg
Filtering of input image start ...
the minimum value: 0
the maximum value: 1052.84
The total time for execution is 7.65937s

b. 并行算法
选择“-O3”级别的优化
zz@jetson05:~/examples$ g++ -fopenmp -O3 sobel_omp16 sobel_omp.cpp -lfreeimage
zz@jetson05:~/examples$ ./sobel_omp16 IBM_Blue_Gene_P_supercomputer_out.jpg
Filtering of input image start ...
the minimum value: 0
the maximum value: 1001.81
actual threads number: 16
The total time for execution is 0.741739s

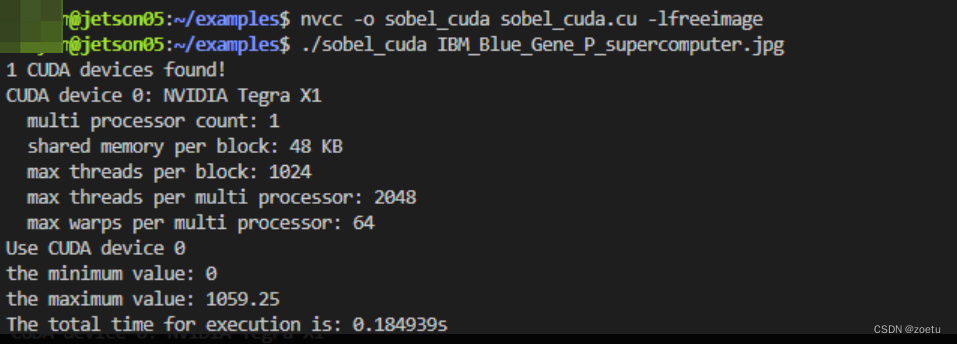
zz@jetson05:~/examples$ nvcc -o sobel_cuda sobel_cuda.cu -lfreeimage
zz@jetson05:~/examples$ ./sobel_cuda IBM_Blue_Gene_P_supercomputer.jpg
1 CUDA devices found!
CUDA device 0: NVIDIA Tegra X1
multi processor count: 1
shared memory per block: 48 KB
max threads per block: 1024
max threads per multi processor: 2048
max warps per multi processor: 64
Use CUDA device 0
the minimum value: 0
the maximum value: 1059.25
The total time for execution is: 0.184939s
3) 图片处理结果


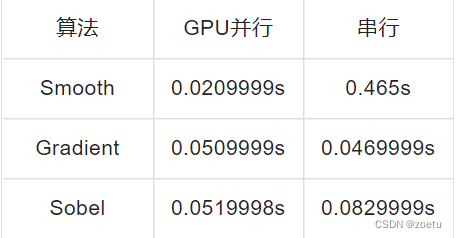
显然,并行算法比串行要快,CUDA并行比OpenMP并行快。
使用提供的opencl-examples源码在你自己的计算机上进行基于OpenCL的GPU并行算法实验,记录你的实验环境参数(包括CPU和GPU相关参数等,可从实验程序日志中获取)以及各个算法的串行版本和GPU并行版本的运行时间,并进行简单的对比分析。
实验源码参考:https://github.com/jianxuecn/cccourse-examples
导读:随着叮咚买菜业务的发展,不同的业务场景对数据分析提出了不同的需求,他们希望引入一款实时OLAP数据库,构建一个灵活的多维实时查询和分析的平台,统一数据的接入和查询方案,解决各业务线对数据高效实时查询和精细化运营的需求。经过调研选型,最终引入ApacheDoris作为最终的OLAP分析引擎,Doris作为核心的OLAP引擎支持复杂地分析操作、提供多维的数据视图,在叮咚买菜数十个业务场景中广泛应用。作者|叮咚买菜资深数据工程师韩青叮咚买菜创立于2017年5月,是一家专注美好食物的创业公司。叮咚买菜专注吃的事业,为满足更多人“想吃什么”而努力,通过美好食材的供应、美好滋味的开发以及美食品牌的孵
C#实现简易绘图工具一.引言实验目的:通过制作窗体应用程序(C#画图软件),熟悉基本的窗体设计过程以及控件设计,事件处理等,熟悉使用C#的winform窗体进行绘图的基本步骤,对于面向对象编程有更加深刻的体会.Tutorial任务设计一个具有基本功能的画图软件**·包括简单的新建文件,保存,重新绘图等功能**·实现一些基本图形的绘制,包括铅笔和基本形状等,学习橡皮工具的创建**·设计一个合理舒适的UI界面**注明:你可能需要先了解一些关于winform窗体应用程序绘图的基本知识,以及关于GDI+类和结构的知识二.实验环境Windows系统下的visualstudio2017C#窗体应用程序三.
需求:要创建虚拟机,就需要给他提供一个虚拟的磁盘,我们就在/opt目录下创建一个10G大小的raw格式的虚拟磁盘CentOS-7-x86_64.raw命令格式:qemu-imgcreate-f磁盘格式磁盘名称磁盘大小qemu-imgcreate-f磁盘格式-o?1.创建磁盘qemu-imgcreate-fraw/opt/CentOS-7-x86_64.raw10G执行效果#ls/opt/CentOS-7-x86_64.raw2.安装虚拟机使用virt-install命令,基于我们提供的系统镜像和虚拟磁盘来创建一个虚拟机,另外在创建虚拟机之前,提前打开vnc客户端,在创建虚拟机的时候,通过vnc
我明白了:x,(y,z)=1,*[2,3]x#=>1y#=>2z#=>nil我想知道为什么z的值为nil。 最佳答案 x,(y,z)=1,*[2,3]右侧的splat*是内联扩展的,所以它等同于:x,(y,z)=1,2,3左边带括号的列表被视为嵌套赋值,所以它等价于:x=1y,z=23被丢弃,而z被分配给nil。 关于ruby-带括号和splat运算符的并行赋值,我们在StackOverflow上找到一个类似的问题: https://stackoverflow
假设您在Ruby中执行此操作:ar=[1,2]x,y=ar然后,x==1和y==2。是否有一种方法可以在我自己的类中定义,从而产生相同的效果?例如rb=AllYourCode.newx,y=rb到目前为止,对于这样的赋值,我所能做的就是使x==rb和y=nil。Python有这样一个特性:>>>classFoo:...def__iter__(self):...returniter([1,2])...>>>x,y=Foo()>>>x1>>>y2 最佳答案 是的。定义#to_ary。这将使您的对象被视为要分配的数组。irb>o=Obje
我正在寻找用于Rails的优质管理插件。似乎大多数现有的插件/gem(例如“restful_authentication”、“acts_as_authenticated”)都围绕着self注册等展开。但是,我正在寻找一种功能齐全的基于管理/管理角色的解决方案——但不是简单地附加到另一个非基于角色的解决方案。如果我找不到,我想我会自己动手......只是不想重新发明轮子。 最佳答案 RyanBates最近做了两个关于授权的railscast(注意身份验证和授权之间的区别;身份验证检查用户是否如她所说的那样,授权检查用户是否有权访问资源
我正在根据Rakefile中的现有测试文件动态生成测试任务。假设您有各种以模式命名的单元测试文件test_.rb.所以我正在做的是创建一个以“测试”命名空间内的文件名命名的任务。使用下面的代码,我可以用raketest:调用所有测试require'rake/testtask'task:default=>'test:all'namespace:testdodesc"Runalltests"Rake::TestTask.new(:all)do|t|t.test_files=FileList['test_*.rb']endFileList['test_*.rb'].eachdo|task|n
我想要像“嘿那里”这样的东西变成,例如,#316583。我希望将任意长度的字符串“归结”为十六进制颜色。我不知道从哪里开始。我在想,每个字符串的MD5散列都是不同的-但如何将该散列转换为十六进制颜色数字? 最佳答案 你可以只取几位前几位:require'digest/md5'color=Digest::MD5.hexdigest('Mytext')[0..5] 关于ruby-如何使用Ruby基于字母数字字符串生成颜色?,我们在StackOverflow上找到一个类似的问题:
文章目录1.自动驾驶实战:基于Paddle3D的点云障碍物检测1.1环境信息1.2准备点云数据1.3安装Paddle3D1.4模型训练1.5模型评估1.6模型导出1.7模型部署效果附录show_lidar_pred_on_image.py1.自动驾驶实战:基于Paddle3D的点云障碍物检测项目地址——自动驾驶实战:基于Paddle3D的点云障碍物检测课程地址——自动驾驶感知系统揭秘1.1环境信息硬件信息CPU:2核AI加速卡:v100总显存:16GB总内存:16GB总硬盘:100GB环境配置Python:3.7.4框架信息框架版本:PaddlePaddle2.4.0(项目默认框架版本为2.3
RuntimeError:CUDAerror:device-sideasserttriggered问题描述解决思路发现问题:总结问题描述当我在调试模型的时候,出现了如下的问题/opt/conda/conda-bld/pytorch_1656352465323/work/aten/src/ATen/native/cuda/IndexKernel.cu:91:operator():block:[5,0,0],thread:[63,0,0]Assertion`index>=-sizes[i]&&index通过提示信息可以知道是个数组越界的问题。但是如图一中第二行话所说这个问题可能并不出在提示的代码段