水位标记:
水位或水印(watermark)一词,表示位置信息,即位移(offset)。Kafka源码中使用的名字是高水位,HW(high watermark)。
副本角色:
Kafka分区使用多个副本(replica)提供高可用。
LEO和HW:
每个分区副本对象都有两个重要的属性:LEO和HW。
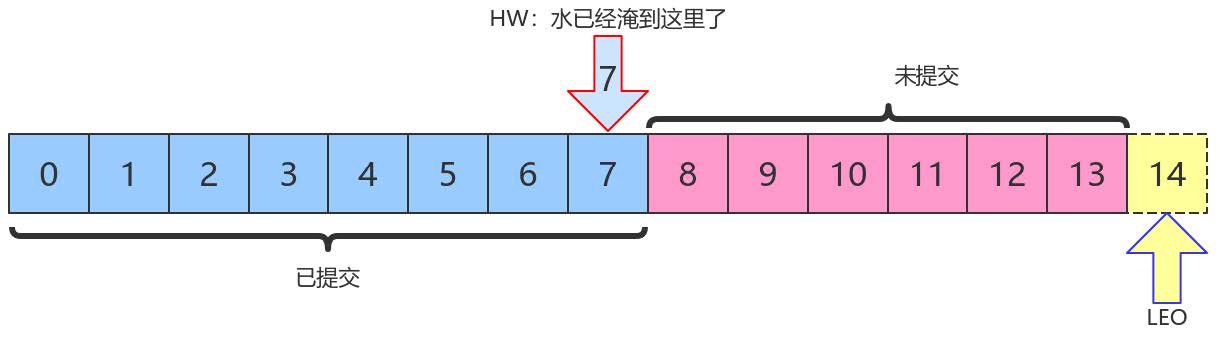
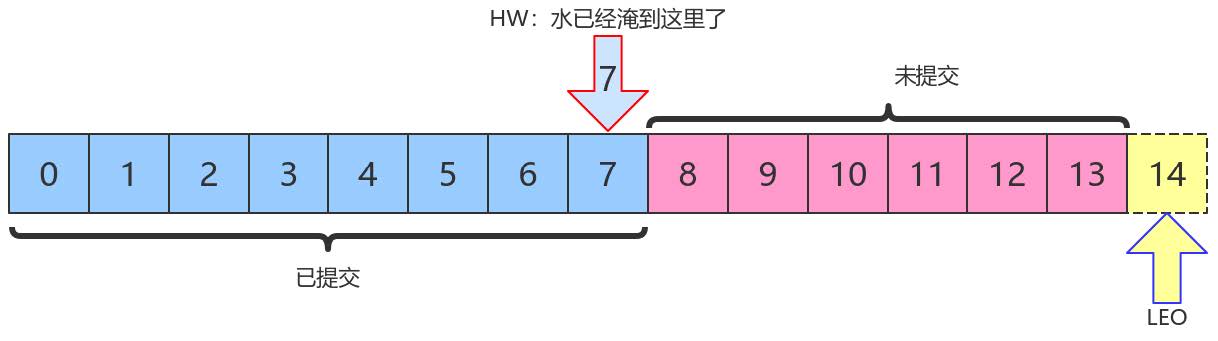
上图中,HW值是7,表示位移是0~7 的所有消息都已经处于“已提交状态”(committed),而LEO值是14,8~13的消息就是未完全备份(fully replicated)——为什么没有14?LEO指向的是下一条消息到来时的位移。
消费者无法消费分区下Leader副本中位移大于分区HW的消息。
Follower副本不停地向Leader副本所在的broker发送FETCH请求,一旦获取消息后写入自己的日志中进行备份。那么Follower副本的LEO是何时更新的呢?首先我必须言明,Kafka有两套Follower副本LEO:
Kafka使用前者帮助Follower副本更新其HW值;利用后者帮助Leader副本更新其HW。
(1)Follower副本的本地LEO何时更新?
Follower副本的LEO值就是日志的LEO值,每当新写入一条消息,LEO值就会被更新。当Follower发送FETCH请求后,Leader将数据返回给Follower,此时Follower开始Log写数据,从而自动更新LEO值。
(2)Leader端Follower的LEO何时更新?
Leader端的Follower的LEO更新发生在Leader在处理Follower FETCH请求时。一旦Leader接收到Follower发送的FETCH请求,它先从Log中读取相应的数据,给Follower返回数据前,先更新Follower的LEO。
Leader副本何时更新LEO?
和Follower更新LEO相同,Leader写Log时自动更新自己的LEO值。
Leader的HW值就是分区HW值,直接影响分区数据对消费者的可见性 。
Leader会尝试去更新分区HW的四种情况:
结论:
当Kafka broker都正常工作时,分区HW值的更新时机有两个:
Leader如何更新自己的HW值?Leader broker上保存了一套Follower副本的LEO以及自己的LEO。当尝试确定分区HW时,它会选出所有满足条件的副本,比较它们的LEO(包括Leader的LEO),并选择最小的LEO值作为HW值。
需要满足的条件,(二选一):
如果Kafka只判断第一个条件的话,确定分区HW值时就不会考虑这些未在ISR中的副本,但这些副本已经具备了“立刻进入ISR”的资格,因此就可能出现分区HW值越过ISR中副本LEO的情况——不允许。因为分区HW定义就是ISR中所有副本LEO的最小值。
我们假设有一个topic,单分区,副本因子是2,即一个Leader副本和一个Follower副本。我们看下当producer发送一条消息时,broker端的副本到底会发生什么事情以及分区HW是如何被更新的。
(1)初始状态
初始时Leader和Follower的HW和LEO都是0(严格来说源代码会初始化LEO为-1,不过这不影响之后的讨论)。Leader中的Remote LEO指的就是Leader端保存的Follower LEO,也被初始化成0。此时,生产者没有发送任何消息给Leader,而Follower已经开始不断地给Leader发送FETCH请求了,但因为没有数据因此什么都不会发生。值得一提的是,Follower发送过来的FETCH请求因为无数据而暂时会被寄存到Leader端的purgatory中,待500ms ( replica.fetch.wait.max.ms 参数)超时后会强制完成。倘若在寄存期间生产者发来数据,则Kafka会自动唤醒该FETCH请求,让Leader继续处理。

(2) Follower发送FETCH请求在Leader处理完PRODUCE请求之后
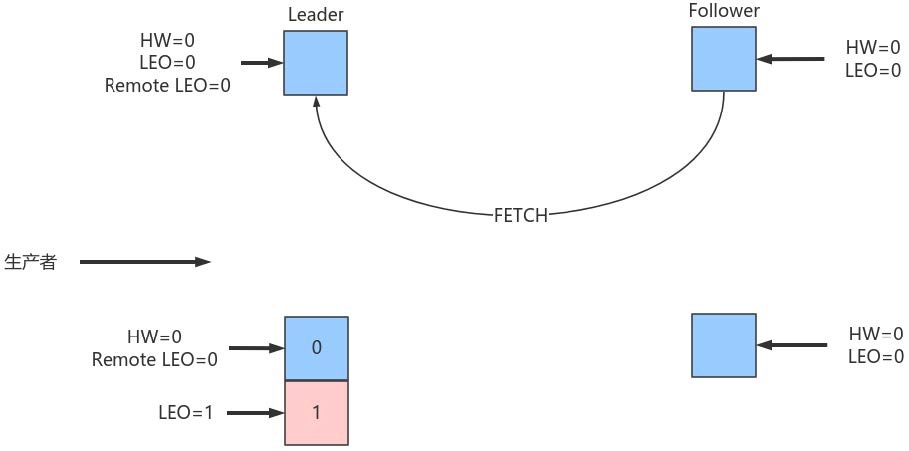
如上图所示,Leader接收到PRODUCE请求主要做两件事情:
PRODUCE请求处理完成后各值如下,Leader端的HW值依然是0,而LEO是1,Remote LEO也是0。
| 属性 | 阶段 | 旧值 | 新值 | 备注 |
| Leader LEO | PRODUCE处理完成 | 0 | 1 | 写入了一条数据 |
| Remote LEO | PRODUCE处理完成 | 0 | 0 | 还未Fetch |
| Leader HW | PRODUCE处理完成 | 0 | 0 | min(LeaderLEO=1, RemoteLEO=0)=0 |
| Follower LEO | PRODUCE处理完成 | 0 | 0 | 还未Fetch |
| Follower HW | PRODUCE处理完成 | 0 | 0 | min(LeaderHW=0, FollowerLEO=0)=0 |
假设此时follower发送了FETCH请求,则状态变更如下:

本例中当follower发送FETCH请求时,Leader端的处理依次是:
而Follower副本接收到FETCH Response后依次执行下列操作:
此时,第一轮FETCH RPC结束,我们会发现虽然Leader和Follower都已经在Log中保存了这条消息,但分区HW值尚未被更新,仍为0。
| 属性 | 阶段 | 旧值 | 新值 | 备注 |
| Leader LEO | PRODUCE和Follower FETCH处理完成 | 0 | 1 | 写入了一条数据 |
| Remote LEO | PRODUCE和Follower FETCH处理完成 | 0 | 0 | 第一次fetch中offset为0 |
| Leader HW | PRODUCE和Follower FETCH处理完成 | 0 | 0 | min(LeaderLEO=1, RemoteLEO=0)=0 |
| Follower LEO | PRODUCE和Follower FETCH处理完成 | 0 | 1 | 同步了一条数据 |
| Follower HW | PRODUCE和Follower FETCH处理完成 | 0 | 0 | min(LeaderHW=0, FollowerLEO=1)=0 |
Follower第二轮FETCH
分区HW是在第二轮FETCH RPC中被更新的,如下图所示:

Follower发来了第二轮FETCH请求,Leader端接收到后仍然会依次执行下列操作:
同样地,Follower副本接收到FETCH response后依次执行下列操作:
| 属性 | 阶段 | 旧值 | 新值 | 备注 |
| Leader LEO | 第二次Follower FETCH处理完成 | 1 | 1 | 未写入新数据 |
| Remote LEO | 第二次Follower FETCH处理完成 | 0 | 1 | 第2次fetch中offset为1 |
| Leader HW | 第二次Follower FETCH处理完成 | 0 | 1 | min(RemoteLEO,LeaderLEO)=1 |
| Follower LEO | 第二次Follower FETCH处理完成 | 1 | 1 | 未写入新数据 |
| Follower HW | 第二次Follower FETCH处理完成 | 0 | 1 | 第2次fetch resp中的LeaderHW和本地Follower LEO都是1 |
此时消息已经成功地被复制到Leader和Follower的Log中且分区HW是1,表明消费者能够消费offset = 0的消息。
(3)FETCH请求保存在purgatory中,PRODUCE请求到来。
当Leader无法立即满足FECTH返回要求的时候(比如没有数据),那么该FETCH请求被暂存到Leader端的purgatory中(炼狱),待时机成熟尝试再次处理。Kafka不会无限期缓存,默认有个超时时间(500ms),一旦超时时间已过,则这个请求会被强制完成。当寄存期间还没超时,生产者发送PRODUCE请求从而使之满足了条件以致被唤醒。此时,Leader端处理流程如下:
Kafka使用HW值来决定副本备份的进度,而HW值的更新通常需要额外一轮FETCH RPC才能完成。但这种设计是有问题的,可能引起的问题包括:
(1)数据丢失
使用HW值来确定备份进度时其值的更新是在下一轮RPC中完成的。如果Follower副本在标记上方的的第一步与第二步之间发生崩溃,那么就有可能造成数据的丢失。
| 代 | 属性 | 阶段 | 旧值 | 新值 | 备注 |
| 1 | Leader LEO | PRODUCE和Follower FETCH处理完成 | 0 | 1 | 写入了一条数据 |
| 1 | Remote LEO | PRODUCE和Follower FETCH处理完成 | 0 | 0 | 第一次fetch中offset为0 |
| 1 | Leader HW | PRODUCE和Follower FETCH处理完成 | 0 | 0 | min(LeaderLEO=1,FollowerLEO=0)=0 |
| 1 | Follower LEO | PRODUCE和Follower FETCH处理完成 | 0 | 1 | 同步了一条数据 |
| 1 | Follower HW | PRODUCE和Follower FETCH处理完成 | 0 | 0 | min(LeaderHW=0, FollowerLEO=1)=0 |
| 2 | Leader LEO | 第二次Follower FETCH处理完成 | 1 | 2 | 写入了第二条数据 |
| 2 | Remote LEO | 第二次Follower FETCH处理完成 | 0 | 1 | 第2次fetch中offset为1 |
| 2 | Leader HW | 第二次Follower FETCH处理完成 | 0 | 1 | min(RemoteLEO=1,LeaderLEO=2)=1 |
| 2 | Follower LEO | 第二次Follower FETCH处理完成 | 1 | 2 | 写入了第二条数据 |
| 2 | Follower HW | 第二次Follower FETCH处理完成 | 0 | 1 | min(LeaderHW=1,FollowerLEO=2)=1 |
| 3 | Leader LEO | 第三次Follower FETCH处理完成 | 2 | 2 | 未写入新数据 |
| 3 | Remote LEO | 第三次Follower FETCH处理完成 | 1 | 2 | 第3次fetch中offset为2 |
| 3 | Leader HW | 第三次Follower FETCH处理完成 | 1 | 2 | min(RemoteLEO=2,LeaderLEO)=2 |
| 3 | Follower LEO | 第三次Follower FETCH处理完成 | 2 | 2 | 未写入新数据 |
| 3 | Follower HW | 第三次Follower FETCH处理完成 | 1 | 2 | 第3次fetch resp中的LeaderHW和本地FollowerLEO都是2 |
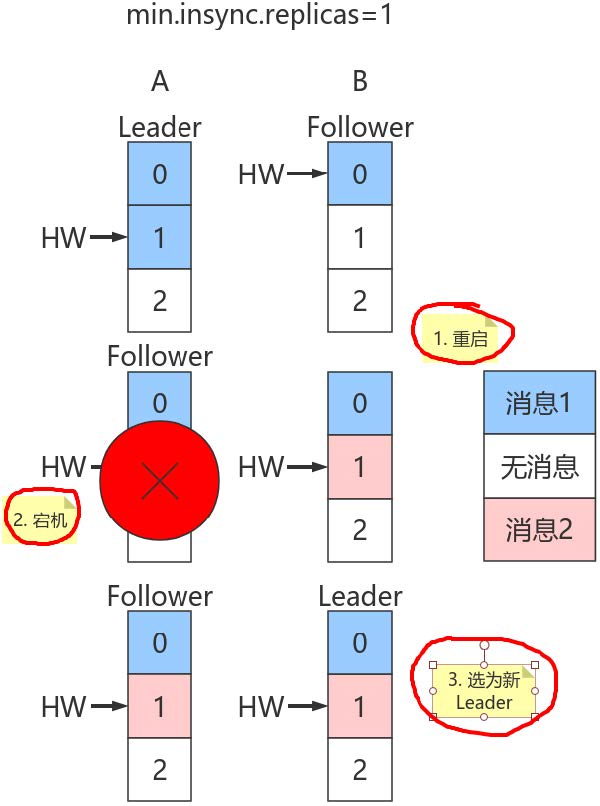
但是在broker端,Leader和Follower的Log虽都写入了2条消息且分区HW已经被更新到2,但Follower HW尚未被更新还是1,也就是上面标记的第二步尚未执行,表中最后一条未执行。
倘若此时副本B所在的broker宕机,那么重启后B会自动把LEO调整到之前的HW值1,故副本B会做日志截断(log truncation),将offset = 1的那条消息从log中删除,并调整LEO = 1。此时follower副本底层log中就只有一条消息,即offset = 0的消息!
B重启之后需要给A发FETCH请求,但若A所在broker机器在此时宕机,那么Kafka会令B成为新的Leader,而当A重启回来后也会执行日志截断,将HW调整回1。这样,offset=1的消息就从两个副本的log中被删除,也就是说这条已经被生产者认为发送成功的数据丢失。
丢失数据的前提是min.insync.replicas=1 时,一旦消息被写入Leader端Log即被认为是committed 。延迟一轮FETCH RPC 更新HW值的设计使follower HW值是异步延迟更新,若在这个过程中Leader发生变更,那么成为新Leader的Follower的HW值就有可能是过期的,导致生产者本是成功提交的消息被删除。
(2)Leader和Follower数据离散
看图:
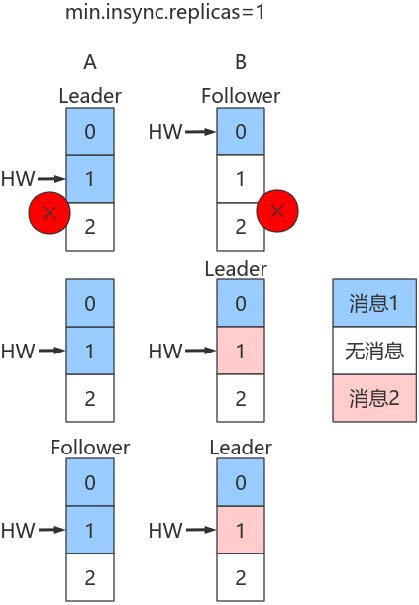
假设:A是Leader,A的Log写入了2条消息,但B的Log只写了1条消息。分区HW更新到2,但B的HW还是1,同时生产者min.insync.replicas 仍然为1。
假设A和B所在Broker同时宕机,B先重启回来,因此B成为Leader,分区HW = 1。假设此时生产者发送了第3条消息(红色表示)给B,于是B的log中offset = 1的消息变成了红框表示的消息,同时分区HW更新到2(A还没有回来,就B一个副本,故可以直接更新HW而不用理会A)之后A重启回来,需要执行日志截断,但发现此时分区HW=2而A之前的HW值也是2,故不做任何调整。此后A和B将以这种状态继续正常工作。
显然,这种场景下,A和B的Log中保存在offset = 1的消息是不同的记录,从而引发不一致的情形出现。
Kafka解决方案
造成上述两个问题的根本原因在于
但HW值的更新是异步延迟的,特别是需要额外的FETCH请求处理流程才能更新,故这中间发生的任何崩溃都可能导致HW值的过期。
Kafka从0.11引入了leader epoch 来取代HW值。Leader端使用内存保存Leader的epoch信息,即使出现上面的两个场景也能规避这些问题。
所谓Leader epoch实际上是一对值:<epoch, offset>:
<0, 0>
<1, 120>
则表示第一个Leader从位移0开始写入消息;共写了120条[0, 119];而第二个Leader版本号是1,从位移120处开始写入消息。
(1)规避数据丢失
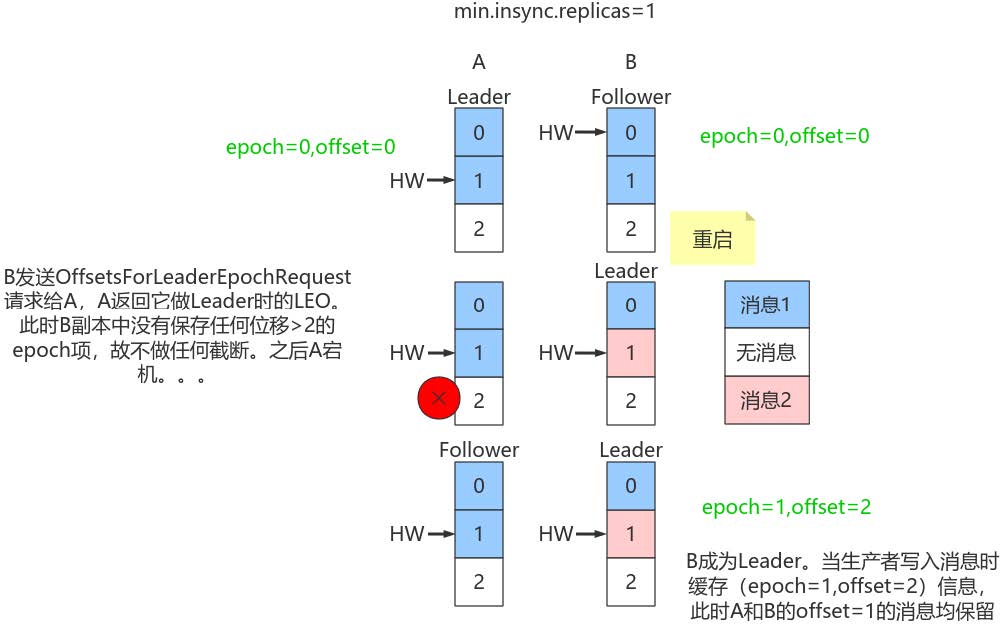
只需要知道每个副本都引入了新的状态来保存自己当leader时开始写入的第一条消息的offset以及leader版本。这样在恢复的时候完全使用这些信息而非HW来判断是否需要截断日志。
(2)规避数据不一致
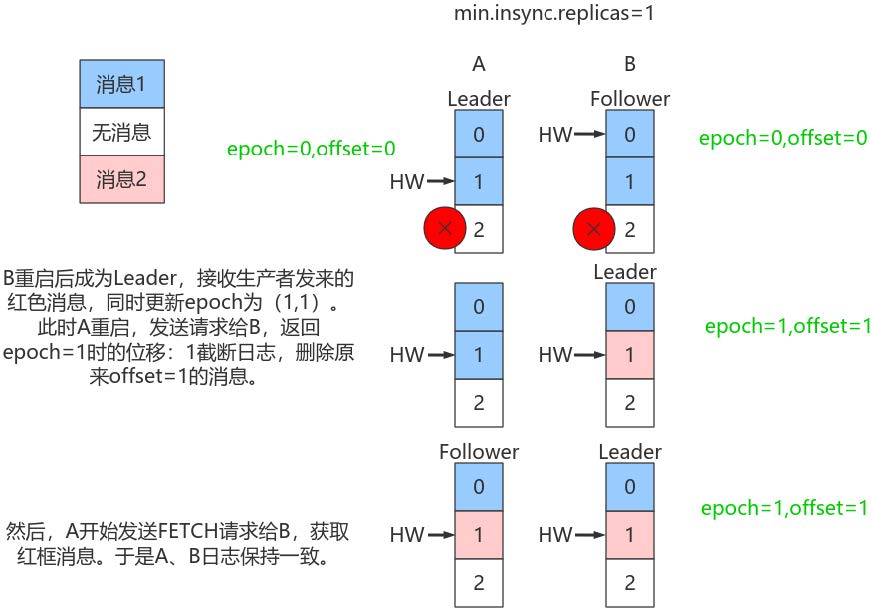
依靠Leader epoch的信息可以有效地规避数据不一致的问题。
消息重复和丢失是kafka中很常见的问题,主要发生在以下三个阶段:
(1)根本原因
(2)重试过程

说明:
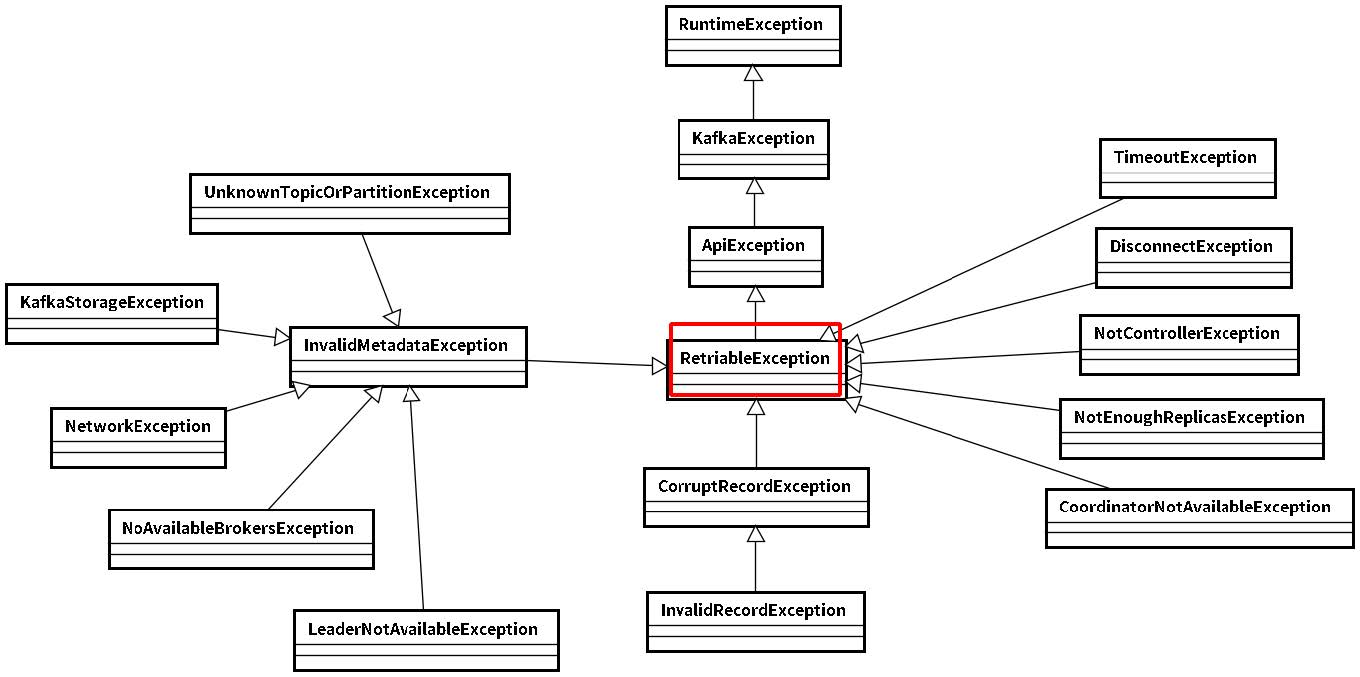
(3)可恢复异常说明
异常是RetriableException类型或者TransactionManager允许重试;RetriableException类继承关系如下:
(4) 记录顺序问题
如果设置max.in.flight.requests.per.connection 大于1(默认5,单个连接上发送的未确认请求的最大数量,表示上一个发出的请求没有确认下一个请求又发出了)。大于1可能会改变记录的顺序,因为如果将两个batch发送到单个分区,第一个batch处理失败并重试,但是第二个batch处理成功,那么第二个batch处理中的记录可能先出现被消费。
设置max.in.flight.requests.per.connection 为1,可能会影响吞吐量,可以解决单个生产者发送顺序问题。如果多个生产者,生产者1先发送一个请求,生产者2后发送请求,此时生产者1返回可恢复异常,重试一定次数成功了。虽然生产者1先发送消息,但生产者2发送的消息会被先消费。
(1)启动kafka的幂等性
要启动kafka的幂等性,设置: enable.idempotence=true ,以及ack=all 以及retries > 1 。
(2)ack=0,不重试
可能会丢消息,适用于吞吐量指标重要性高于数据丢失,例如:日志收集。
(3)生产者和broker阶段消息丢失场景
(4)解决生产者和broker阶段消息丢失
禁用unclean选举,ack=all
配置:min.insync.replicas > 1
当生产者将acks 设置为all (或-1 )时, min.insync.replicas>1 。指定确认消息写成功需要的最小副本数量。达不到这个最小值,生产者将引发一个异常(要么是NotEnoughReplicas,要么是NotEnoughReplicasAfterAppend)。
当一起使用时, min.insync.replicas 和ack 允许执行更大的持久性保证。一个典型的场景是创建一个复制因子为3的主题,设置min.insync复制到2个,用all 配置发送。将确保如果大多数副本没有收到写操作,则生产者将引发异常。
失败的offset单独记录
生产者发送消息,会自动重试,遇到不可恢复异常会抛出,这时可以捕获异常记录到数据库或缓存,进行单独处理。
(5)消费者数据重复场景及解决方案
(6)解决方案
两个gsub产生不同的结果。谁能解释一下为什么?代码也可在https://gist.github.com/franklsf95/6c0f8938f28706b5644d获得.ver=9999str="\tCFBundleDevelopmentRegion\n\ten\n\tCFBundleVersion\n\t0.1.190\n\tAppID\n\t000000000000000"putsstr.gsub/(CFBundleVersion\n\t.*\.).*()/,"#{$1}#{ver}#{$2}"puts'--------'putsstr.gsub/(CFBundleVersio
我希望特定模型的所有数据库交互都通过集群中的mongo主节点,因此我将模型设置为使用强一致性。classPhotoincludeMongoid::Documentwithconsistency::strongfield:number,type:Integer#let'ssayaphotonumberisuniqueinthedbvalidate:unique_numberend但这似乎不起作用,因为当我保存两张非常靠近的照片时,我仍然遇到验证错误。photo1#dbhasnumber=1forthisobjectphoto1.update_attributes(number:2)pho
gemspec语义版本控制运算符~>(又名twiddle-wakka,又名pessimistic运算符)允许限制gem版本但允许进行一些升级。我经常看到它可以读作:"~>3.1"=>"Anyversion3.x,butatleast3.1""~>3.1.1"=>"Anyversion3.1.x,butatleast3.1.1"但是有了一个数字,这条规则就失效了:"~>3"=>"Anyversionx,butatleast3"*NOTTRUE!*"~>3"=>"Anyversion3.x"*True.Butwhy?*如果我想要“任何版本3.x”,我可以只使用“~>3.0”,这是一致的。就
一、解决痛点使用spring-kafka客户端,每次新增topic主题,都需要硬编码客户端并重新发布服务,操作麻烦耗时长。kafkaListener虽可以支持通配符消费topic,缺点是并发数需要手动改并且重启服务。对于业务逻辑相似场景,创建新主题动态监听可以用kafka-batch-starter组件二、组件能力1、新增topic名称为:auto.topic1(由于配置spring.kafka.consumer.prefix为auto,因此只有auto前缀的topic,才会被组件动态监听。)2、应用输出日志,监听到新增auto.topic1,并初始化客户端(主题刷新间隔为10s)3、发新的消
我正在用列表“a”做这样的事情:a.each_with_index|outer,i|a.each_with_index|inner,j|if(j>i)#dosomeoperationwithouterandinnerendendend如果迭代器不打算使用相同的顺序,这将不起作用。我不关心实际顺序是什么,我只需要两个.each_with_index迭代器使用相同的顺序。我假设它是一个数组的一个属性,它有一个固定的顺序,我只是偏执地认为迭代器不会使用那个顺序...... 最佳答案 这取决于您正在操作的特定Enumerable对象。例如,
好的,所以我将我自己的DSL中的一些东西与Ruby进行了比较。他们都支持的一个结构是这个x=["key"=>"value"]知道数组和散列的区别,我会认为这是不合法的,但是在Ruby中的结果是[{"key"=>"value"}]这是为什么?有了这种语法,你为什么不能这样做x=("key"=>"value")为什么数组是隐式创建的哈希的特例? 最佳答案 另一个特殊情况是在函数调用中,考虑:deff(x)puts"OK:#{x.inspect}"endf("foo"=>"bar")=>OK:{"foo"=>"bar"}因此在某些情况下,
我今天在定义我解决的自定义RSpec匹配器时遇到了一个问题,但实际上看不出任何一种方法有效而另一种方法无效的原因,这是代码:方法1——if+else:RSpec::Matchers.define:have_success_messagedo|message|matchdo|page|ifmessage.nil?page.shouldhave_selector('div.alert.alert-success')elsepage.shouldhave_selector('div.alert.alert-success',text:message)endendend方法2--if后跟unl
为了用虚假数据填充我的Rails应用程序,我经常这样做:person=Person.create(:first_name=>Faker::Name.first_name,:last_name=>Faker::Name.last_name,:email=>Faker::Internet.email)这可能会产生一个像这样的人:Firstname:OliviaLastname:KuberaEmail:milan_nieklauson@bachmannjacob.net有没有办法生成更连贯的假数据,例如:Firstname:OliviaLastname:KuberaEmail:olivia_
我为String的子类覆盖了=~方法:classMyString重写的方法在某些情况下被正确调用:r=/abc/s=~r#=>"Overriddenmethod."s.send(:=~,r)#=>"Overriddenmethod."s.send(:=~,/abc/)#=>"Overriddenmethod."而在其他情况下它被绕过,而是调用String#=~:s=~/abc/#=>0s=~(/abc/)#=>0我可以在Ruby1.8.7、2.1.0上重现这些结果。有人知道为什么会这样吗?是错误吗? 最佳答案 在String#=~的
我尝试在Ruby中创建一个HMAC,然后在PHP中验证它。ruby:require'openssl'message="A522EBF2-5083-484D-99D9-AA97CE49FC6C,1234567890,/api/comic/aWh62,GET"key="3D2143BD-6F86-449F-992C-65ADC97B968B"hash=OpenSSL::HMAC.hexdigest('sha256',message,key)phashPHP:对于Ruby,我得到:20e3f261b762e8371decdf6f42a5892b530254e666508e885c708c5b