作者: 张斌斌:Nacos&Sentinel Committer
最近 ChatGPT 很火,激起了社会广泛关注和学习热潮,记得上次我通宵学习 AI 知识还是 Goolgle 发布最新算法的时候。当时我考虑是不是要转行去搞 AI,不然就有被淘汰的风险,随着学完斯坦福大学的 AI 公开课,突然就释然了。我发现这个行业极少天才去演进算法,大部分人只是训练和调整参数运用到不同的场景。但是最近 ChatGPT 火了,又引起了我的焦虑和好奇,随即尝试挑战一下 AI 能力,问了几个问题。
作为Nacos 的Committer,想看一下 AI 到底能否理解技术,所以问了一个带有感情色彩的问题,结果让人震惊。我布道 Nacos 也就是从开源定位、优势结构化的去分享,要知道结构化是专家级工程师的核心思维要求,AI 能达到专家级的思维水平了? 多尝试几次,结果每次都不一样,似乎越问越精简,最后居然能总结回答,太妙啦~
能够结构化按照定位、优势回答
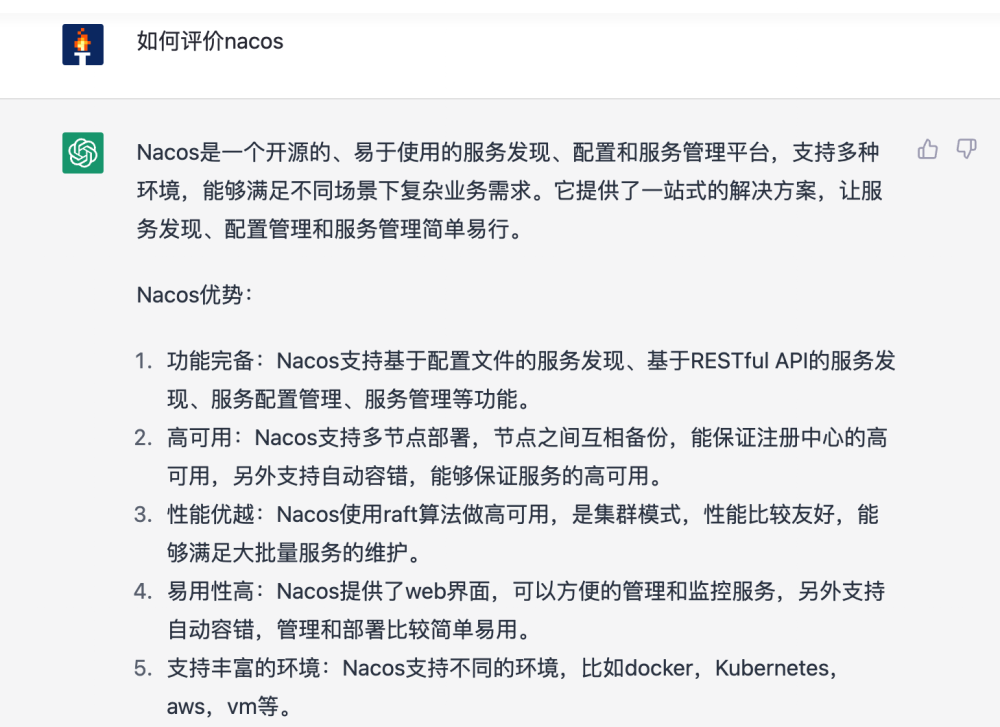 能够做提炼精简
能够做提炼精简
 能够用总体来说-总结
能够用总体来说-总结
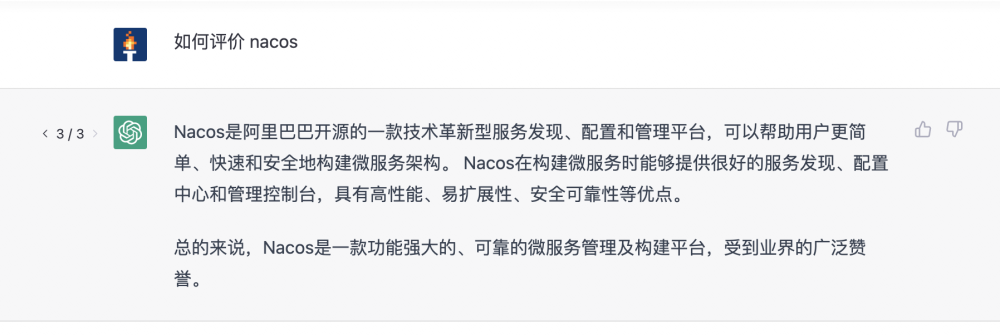
为了发挥程序员和测试的思维,我把电脑切成英文,看看他的回答是否专业,看到几次结果后,我笑了。看来也不是万能的嘛,但是想了一下,应该是 Nacos 海外影响力不够,所以结果不能很好命中。
 总的来说,ChatGPT 超出了预期,激发了我的热情。晚上睡觉的时候都在考虑怎么问 ChatGPT,想看看他是怎么回答的,要知道上一次有这么高热情还是谈恋爱的时候,哈哈~
总的来说,ChatGPT 超出了预期,激发了我的热情。晚上睡觉的时候都在考虑怎么问 ChatGPT,想看看他是怎么回答的,要知道上一次有这么高热情还是谈恋爱的时候,哈哈~
继续提问。。 。
ChatGPT 能自我认知吗? 但这次提问,居然崩了。。
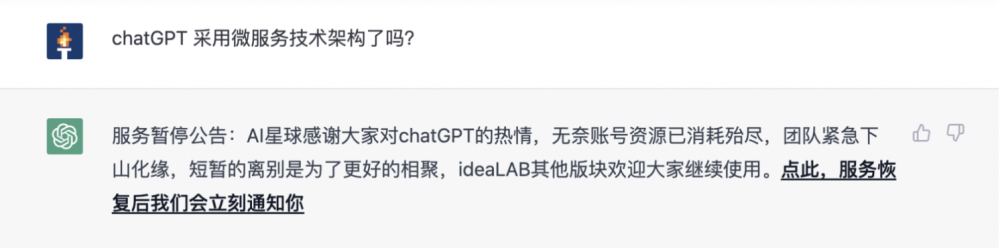 限流了。。我好奇的是,AI 也会限流?AI 能写限流代码吗?看来 Java 程序员这个工作还是能继续干下去的,哈哈。
限流了。。我好奇的是,AI 也会限流?AI 能写限流代码吗?看来 Java 程序员这个工作还是能继续干下去的,哈哈。
 作为一名从事微服务架构和稳定性的程序员,我立马就想了 ChatGPT 限流用的是什么技术呢?
作为一名从事微服务架构和稳定性的程序员,我立马就想了 ChatGPT 限流用的是什么技术呢?
基于 IP 限流?
我想基于 IP 限流是不能搞定的,因为 IP 是变化的,一定是跟采用了服务限流,背后需要采用类似 Sentinel 的服务级别的限流技术。
那限流是在入口做的,还是在后端应用,或者算法层面做的呢?
猜测应该是在入口或者前端业务做的,因为这样能快速的构建入口高可用防线,类似 Higress+Sentinel 的开源组合。可以从入口快速进行服务级别的限流。
那为什么要限流呢? 是系统还是单体应用撑不住了呢? 还是不具备弹性水平扩容能力呢?是不是采用微服务+容器架构能够大幅提升并发能力,快速弹性伸缩呢?
如果 ChatGPT 的后端已经云原生化,那么猜测是类似 Higress + Sentinel + Dubbo + Nacos + K8s 的技术栈,这样可以快速构建高并发、高可用、自动弹性的后端体系。(由于目前未从官方公开文档找到 ChatGPT 的后端架构,所以这里只是假设情况)
作为云计算从业者,就在思考了,ChatGPT 的现象级爆火,让很多公司都羡慕不已,在这个信息大爆炸的时代,每个公司都有着在短时间迅速爆火的可能,在机遇到来时,能不能抗住流量洪峰,保证服务的质量,抓住这次机遇呢?如何快速构建高并发、高可用的微服务架构呢? 我初步构思了一个架构,仅供参考讨论:
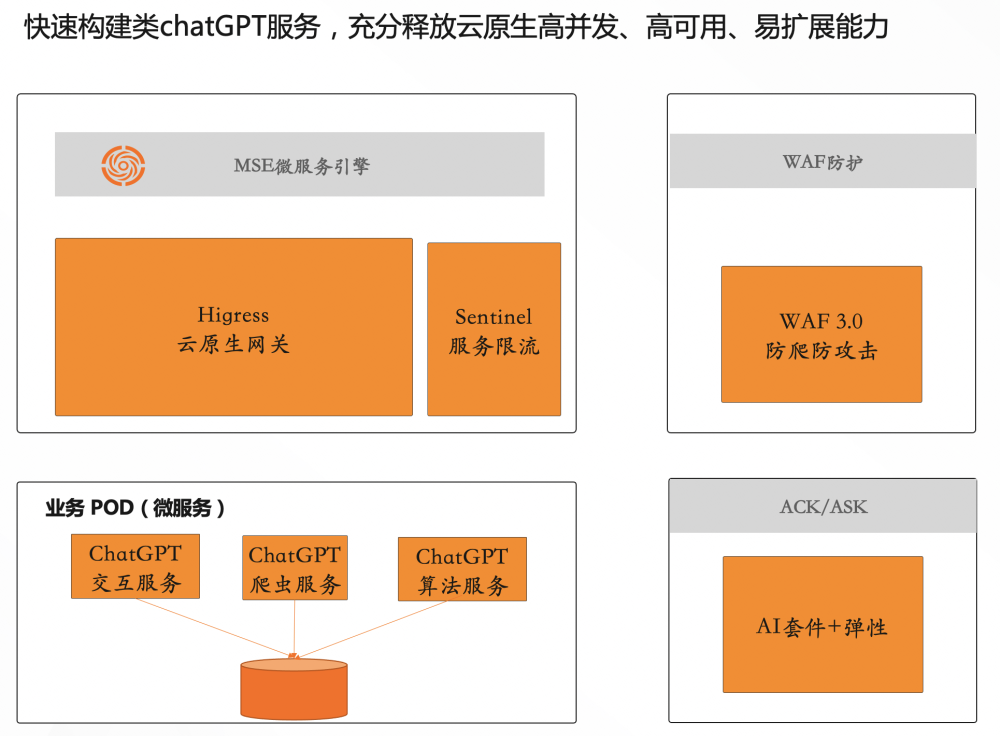 那么如何结合云原生网关与服务治理来保障业务的稳定性与连续性呢?下面来为大家进行揭秘。
那么如何结合云原生网关与服务治理来保障业务的稳定性与连续性呢?下面来为大家进行揭秘。
全链路服务治理,全方位保障业务稳定性
在分布式系统架构中,每个请求都会经过很多层处理,从入口网关再到 Web Server 再到服务之间的调用,再到服务访问缓存或 DB 等存储。在高可用防护体系中,我们通常遵循流量漏斗原则进行高可用流量防护。在流量链路的每一层,我们都需要进行针对性的流量防护与容错手段,来保障服务的稳定性;同时,我们要尽可能地将流量防护进行前置,比如将一部分请求的流量控制前置到网关层,这样可以避免多余的流量打到后端,对后端造成压力同时也造成资源的浪费。
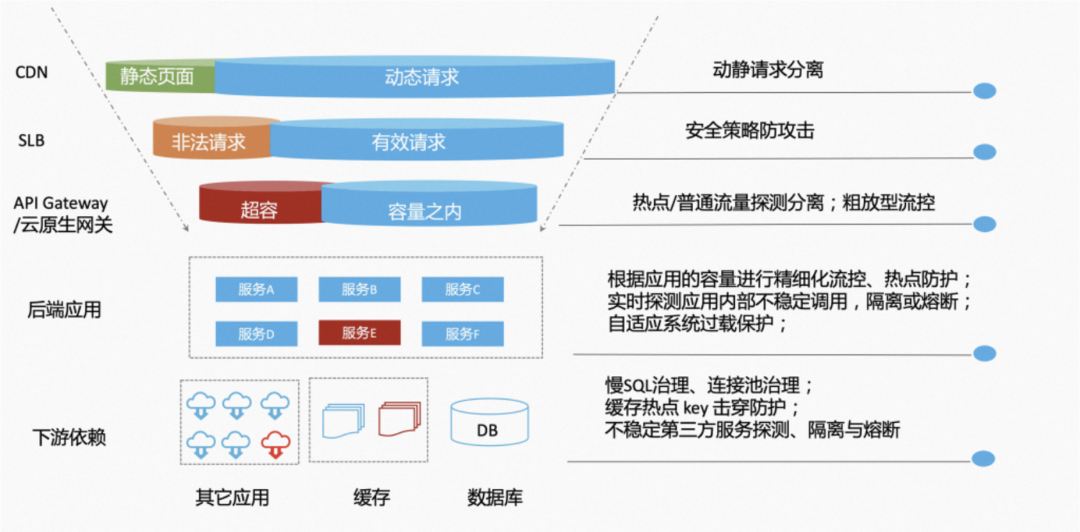
网关入口流控
网关做高可用入口防护为什么重要?一言以蔽之,网关具备将大促的各种不确定性因素转化为确定性因素的能力,并且这种能力是不可替代的。分别从三个方面来看:
第一点是应对流量峰值的不确定性,必须通过流控规则将不确定的流量变为确定。实现流量防护有个前提,承载这突发流量的服务仍能保持正常的 CPU 负载。业务服务模块即使实现了应用层的 QPS 流控,在瞬时高并发场景下,仍可能因为网络层大量的新建连接导致 CPU 猛涨,还没有到流控这道“保险杠”就崩溃了。业务模块应该专注在应用层业务逻辑上,若要通过扩容去应对其不擅长的网络层开销,所需的资源成本是相当高的。而网关作为业务流量入口的地位,决定了其必须擅长应对高并发的网络流量,并且这块性能也是衡量网关能力的一个重要指标,应对高并发的性能越强,所需的资源成本就越低,将大促流量从不确定变为确定的能力就越强。我们推荐在流量入口进行前置流量防护,提前粗粒度地限制一部分超容流量,避免多余的流量打到后端,对后端造成压力同时也造成资源的浪费。
第二点是应对用户行为的不确定性,需要根据不同的大促场景,模拟用户行为进行多轮压测演练,提前发现系统的瓶颈和优化点。网关既是用户访问的流量入口,也是后端业务应答的最终出口。这决定了网关是模拟用户行为进行流量压测的必经一站,也决定了是观测压测指标评估用户体验的必须环节。在网关上边压测,边观察,边调整限流配置,对大促高可用体系的建设,可以起到事半功倍的效果。
第三点是应对安全攻击的不确定性。在业务峰值时,大量异常的流量,甚至是普通用户的重试流量,都很可能导致整体流量超出业务承载范围,从而影响正常用户的访问。基于网关的流量安全防护能力,例如 WAF 等功能,通过识别出异常流量提前拦截,以及将异常 IP、cookie 自动加入黑名单等手段,既可以使这部分流量排除在流控阈值之外,也可以保障后端业务逻辑安全。这也是从入口层面保障业务稳定性的重要一环。
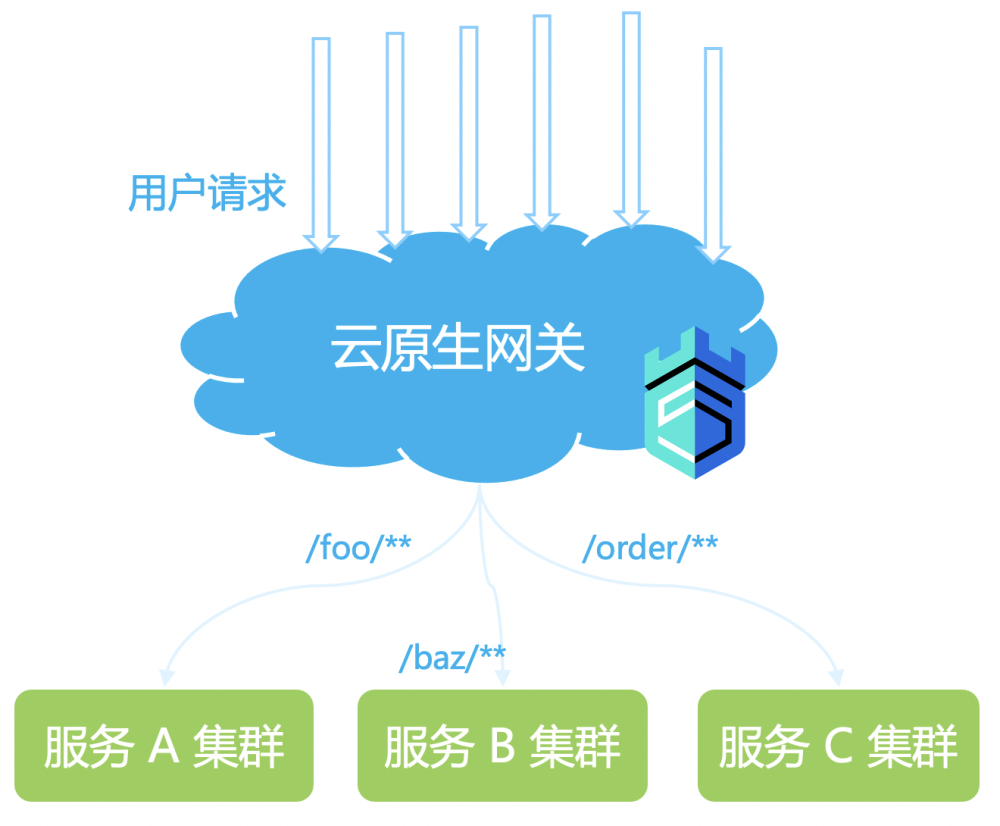
Higress 云原生网关内置了 Sentinel 高可用模块,历经多年双十一大促洪峰流量考验,提供了丰富的高可用防护能力,包括流控、并发控制、熔断,可以从入口层面保障服务稳定性;此外,Higress 商业版 MSE 还具备流量预热能力,通过小流量预热方法,可以有效解决大促场景下,资源初始化慢所导致的大量请求响应慢、请求阻塞问题,避免刚扩容的节点无法提供正常服务,影响用户体验。
那么,仅仅依靠入口流量防护来保障整体业务稳定性是否是足够的?随着我们业务规模、量级的不断增长,业务架构趋于复杂,微服务间的调用拓扑关系呈复杂网状结构。影响稳定性的因素有非常多,除了流量超过承载能力导致不可用的场景之外,服务之间调用的稳定性问题也是不可忽视的一点。比如 ChatGPT 可能依赖几个第三方服务,假设某个搜索服务出现异常,慢调用、超时的请求非常多,而调用端又没有有效地进行预防与处理,则调用端的线程池会被占满,影响服务自身正常运转。在分布式系统中,调用关系是网状的、错综复杂的,某个服务出现故障可能会导致级联反应,导致整个链路不可用,整体 RT 升高,并发升高,此时仅在网关层面做流控是无法保障业务稳定性的。我们需要在应用层结合流控、慢调用熔断、并发隔离等手段,配合网关层的流控来达到整体业务稳定的目标。
应用视角的稳定性治理手段
通过细粒度流控与热点防护,避免业务超过承载能力导致不可用
面对突发的流量,流控能力可以将超出系统服务能力以外的请求拒绝掉。在应用层,建议结合容量评估,通过压测等手段评估流量阈值,针对核心 API、接口、方法进行细粒度的流控配置,起到“安全气囊”的作用。注意并不是只有大流量场景才需要流控,任何服务与接口都有其容量上限,对于核心接口,无论流量大小,都需要配置流控来起到保护作用。
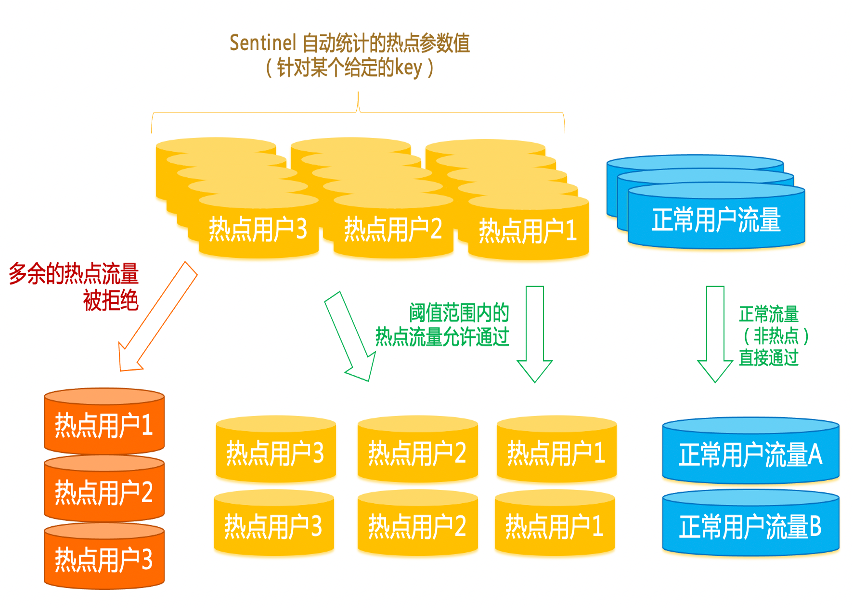
同时,针对热点流量的防护也是保障服务稳定性的重要一环。比如请求中的某些 UID、某些 IP 具有热点访问性质,业务方事先无法准确预知热点属性;这些突发的热点流量会击穿缓存,将 DB 打挂,影响了正常流量的业务处理,造成整体不可用。这种场景下,通过借助 Sentinel 的热点参数流控能力,自动识别参数中的 TopN 访问热度的参数值,并对这些参数分别进行流控,避免单个热点访问过载导致系统不可用。
通过并发隔离与熔断,保障调用端不被不稳定服务拖垮
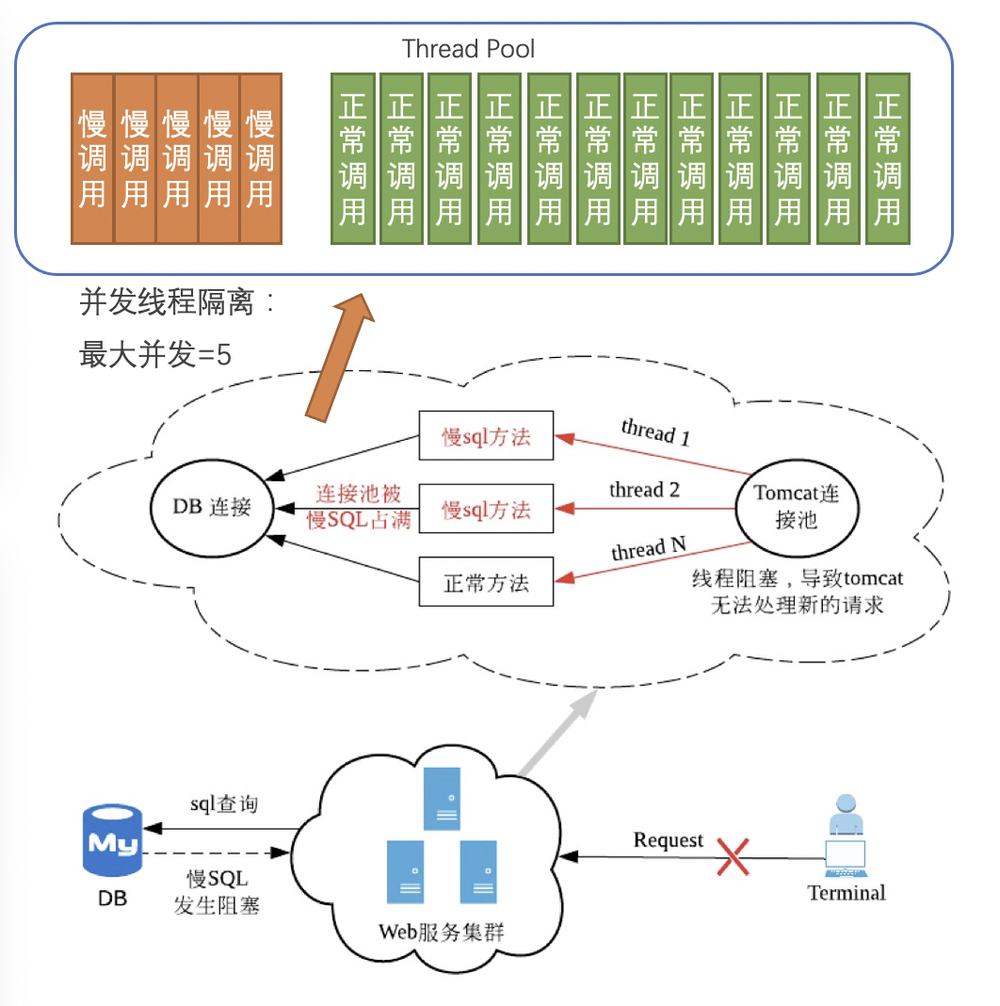
想象这样一个场景,某系统对外提供某查询接口,SQL 语句涉及多表 join,某些情况下会触发慢查询,耗时长达30s,最终导致 DB 连接池/Tomcat 线程池满,应用整体不可用。这种场景下,借助 Sentinel 的并发隔离能力,可以给重要服务调用、SQL 访问配置并发线程数限制,相当于一道“软保险”,防止不稳定调用过多挤占正常连接池、线程池资源造成服务被拖垮。
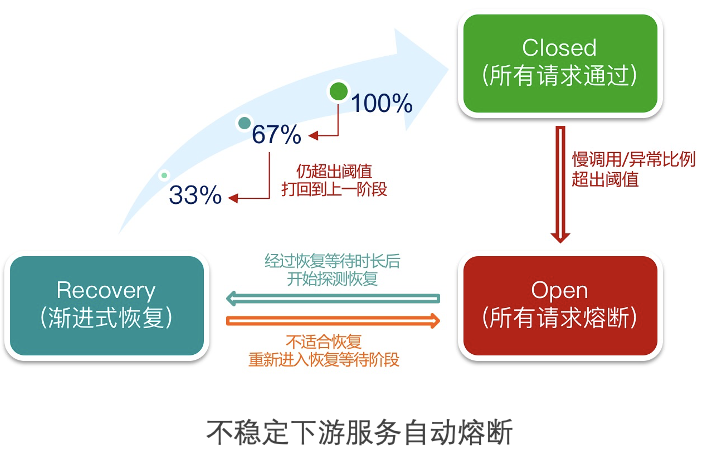
业务高峰期,某些下游的服务提供者遇到性能瓶颈,甚至影响业务。我们可以对部分非关键服务消费者(弱依赖服务)配置熔断规则,当一段时间内的慢调用比例或错误比例达到一定条件时自动触发熔断,后续一段时间服务调用直接返回Mock的结果,这样既可以保障调用端不被不稳定服务拖垮,又可以给不稳定下游服务一些“喘息”的时间,同时可以保障整个业务链路的正常运转。
通过离群实例摘除解决实例单点异常问题
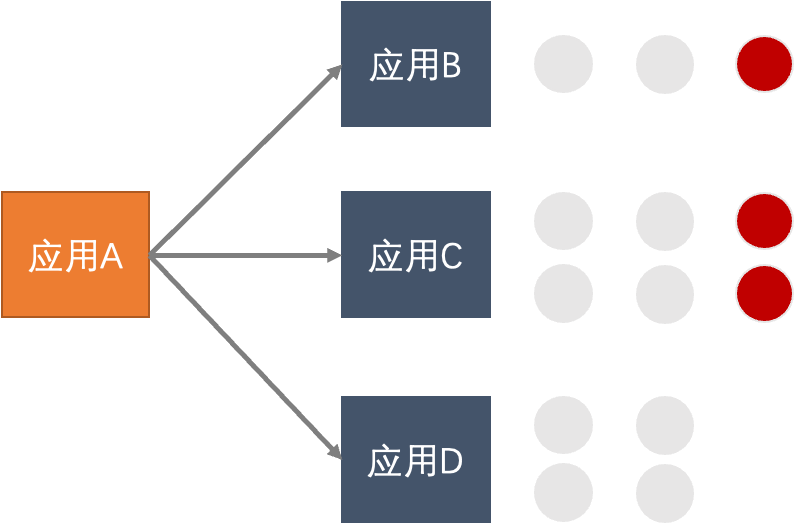
在业务峰值时刻,应用的某几台机器由于磁盘满,或者是宿主机资源争抢导致load很高,导致 consumer 出现调用超时,从而影响系统的整体稳定性。我们可以通过配置离群实例摘除规则,自动摘除异常的实例,避免单点故障引起的整体不可用问题。
展望
如今是 AI 技术突破爆发的时代,我们再脑洞大开一些,是否可以把 AI 技术结合到流量防护体系,基于 AI+大数据的能力与策略来做到智能化保障服务稳定性呢?其实,Sentinel 一直在进行自适应、智能化流量治理的探索,结合控制论、排队论、强化学习等理论与策略来达到自动化保障业务稳定性的目标。目前 Sentinel 提供的基于 load + BBR 的自适应过载保护策略已经可以保障一部分场景下稳定性兜底,我们也在持续探索与演进,针对更多的稳定性场景进行落地。
作为技术小伙伴,大家是怎么看待 ChatGPT,如何将 ChatGPT 运营在自己的业务和技术领域呢?欢迎交流,留言点赞最高的 TOP10,我们将送出Nacos + Sentinel 的社区礼物。
参考阅读:
本文由高可用架构首发。技术原创及架构实践文章,欢迎通过公众号菜单「联系我们」进行投稿
我正在学习如何使用Nokogiri,根据这段代码我遇到了一些问题:require'rubygems'require'mechanize'post_agent=WWW::Mechanize.newpost_page=post_agent.get('http://www.vbulletin.org/forum/showthread.php?t=230708')puts"\nabsolutepathwithtbodygivesnil"putspost_page.parser.xpath('/html/body/div/div/div/div/div/table/tbody/tr/td/div
总的来说,我对ruby还比较陌生,我正在为我正在创建的对象编写一些rspec测试用例。许多测试用例都非常基础,我只是想确保正确填充和返回值。我想知道是否有办法使用循环结构来执行此操作。不必为我要测试的每个方法都设置一个assertEquals。例如:describeitem,"TestingtheItem"doit"willhaveanullvaluetostart"doitem=Item.new#HereIcoulddotheitem.name.shouldbe_nil#thenIcoulddoitem.category.shouldbe_nilendend但我想要一些方法来使用
关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭4年前。Improvethisquestion我想在固定时间创建一系列低音和高音调的哔哔声。例如:在150毫秒时发出高音调的蜂鸣声在151毫秒时发出低音调的蜂鸣声200毫秒时发出低音调的蜂鸣声250毫秒的高音调蜂鸣声有没有办法在Ruby或Python中做到这一点?我真的不在乎输出编码是什么(.wav、.mp3、.ogg等等),但我确实想创建一个输出文件。
给定这段代码defcreate@upgrades=User.update_all(["role=?","upgraded"],:id=>params[:upgrade])redirect_toadmin_upgrades_path,:notice=>"Successfullyupgradeduser."end我如何在该操作中实际验证它们是否已保存或未重定向到适当的页面和消息? 最佳答案 在Rails3中,update_all不返回任何有意义的信息,除了已更新的记录数(这可能取决于您的DBMS是否返回该信息)。http://ar.ru
我在我的项目目录中完成了compasscreate.和compassinitrails。几个问题:我已将我的.sass文件放在public/stylesheets中。这是放置它们的正确位置吗?当我运行compasswatch时,它不会自动编译这些.sass文件。我必须手动指定文件:compasswatchpublic/stylesheets/myfile.sass等。如何让它自动运行?文件ie.css、print.css和screen.css已放在stylesheets/compiled。如何在编译后不让它们重新出现的情况下删除它们?我自己编译的.sass文件编译成compiled/t
我正在寻找执行以下操作的正确语法(在Perl、Shell或Ruby中):#variabletoaccessthedatalinesappendedasafileEND_OF_SCRIPT_MARKERrawdatastartshereanditcontinues. 最佳答案 Perl用__DATA__做这个:#!/usr/bin/perlusestrict;usewarnings;while(){print;}__DATA__Texttoprintgoeshere 关于ruby-如何将脚
Rackup通过Rack的默认处理程序成功运行任何Rack应用程序。例如:classRackAppdefcall(environment)['200',{'Content-Type'=>'text/html'},["Helloworld"]]endendrunRackApp.new但是当最后一行更改为使用Rack的内置CGI处理程序时,rackup给出“NoMethodErrorat/undefinedmethod`call'fornil:NilClass”:Rack::Handler::CGI.runRackApp.newRack的其他内置处理程序也提出了同样的反对意见。例如Rack
在选择我想要运行操作的频率时,唯一的选项是“每天”、“每小时”和“每10分钟”。谢谢!我想为我的Rails3.1应用程序运行调度程序。 最佳答案 这不是一个优雅的解决方案,但您可以安排它每天运行,并在实际开始工作之前检查日期是否为当月的第一天。 关于ruby-如何每月在Heroku运行一次Scheduler插件?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/8692687/
我有一个对象has_many应呈现为xml的子对象。这不是问题。我的问题是我创建了一个Hash包含此数据,就像解析器需要它一样。但是rails自动将整个文件包含在.........我需要摆脱type="array"和我该如何处理?我没有在文档中找到任何内容。 最佳答案 我遇到了同样的问题;这是我的XML:我在用这个:entries.to_xml将散列数据转换为XML,但这会将条目的数据包装到中所以我修改了:entries.to_xml(root:"Contacts")但这仍然将转换后的XML包装在“联系人”中,将我的XML代码修改为
我有一大串格式化数据(例如JSON),我想使用Psychinruby同时保留格式转储到YAML。基本上,我希望JSON使用literalstyle出现在YAML中:---json:|{"page":1,"results":["item","another"],"total_pages":0}但是,当我使用YAML.dump时,它不使用文字样式。我得到这样的东西:---json:!"{\n\"page\":1,\n\"results\":[\n\"item\",\"another\"\n],\n\"total_pages\":0\n}\n"我如何告诉Psych以想要的样式转储标量?解