VGGNet在2014年由牛津大学计算机视觉组VGG (Visual Geometry Group) 提出,斩获该年ImageNet竞赛中Localization Task (定位任务) 第一名和Classification Task(分类任务)第二名(第一名是GoogLeNet)。
VGGNet探索了卷积神经网络的深度与其性能之间的关系,成功地构筑了16~19层深的卷积神经网络,证明了增加网络的深度能够在一定程度上影响网络最终的性能,使错误率大幅下降,同时拓展性又很强,迁移到其它图片数据上的泛化性也非常好。到目前为止,VGG仍然被用来提取图像特征。
VGGNet可以看成是加深版的AlexNet,把网络分成了5段,每段都把多个尺寸为3×3的卷积核串联在一起,每段卷积接一个尺寸2×2的最大池化层,最后面接3个全连接层和一个softmax层,所有隐层的激活单元都采用ReLU函数。
VGGNet包含很多级别的网络,深度从11层到19层不等。为了解决初始化(权重初始化)等问题,VGG采用的是一种Pre-training的方式,先训练浅层的的简单网络VGG11,再复用VGG11的权重初始化VGG13,如此反复训练并初始化VGG19,能够使训练时收敛的速度更快。比较常用的是VGGNet-16和VGGNet-19。VGGNet-16的网络结构如下图所示:
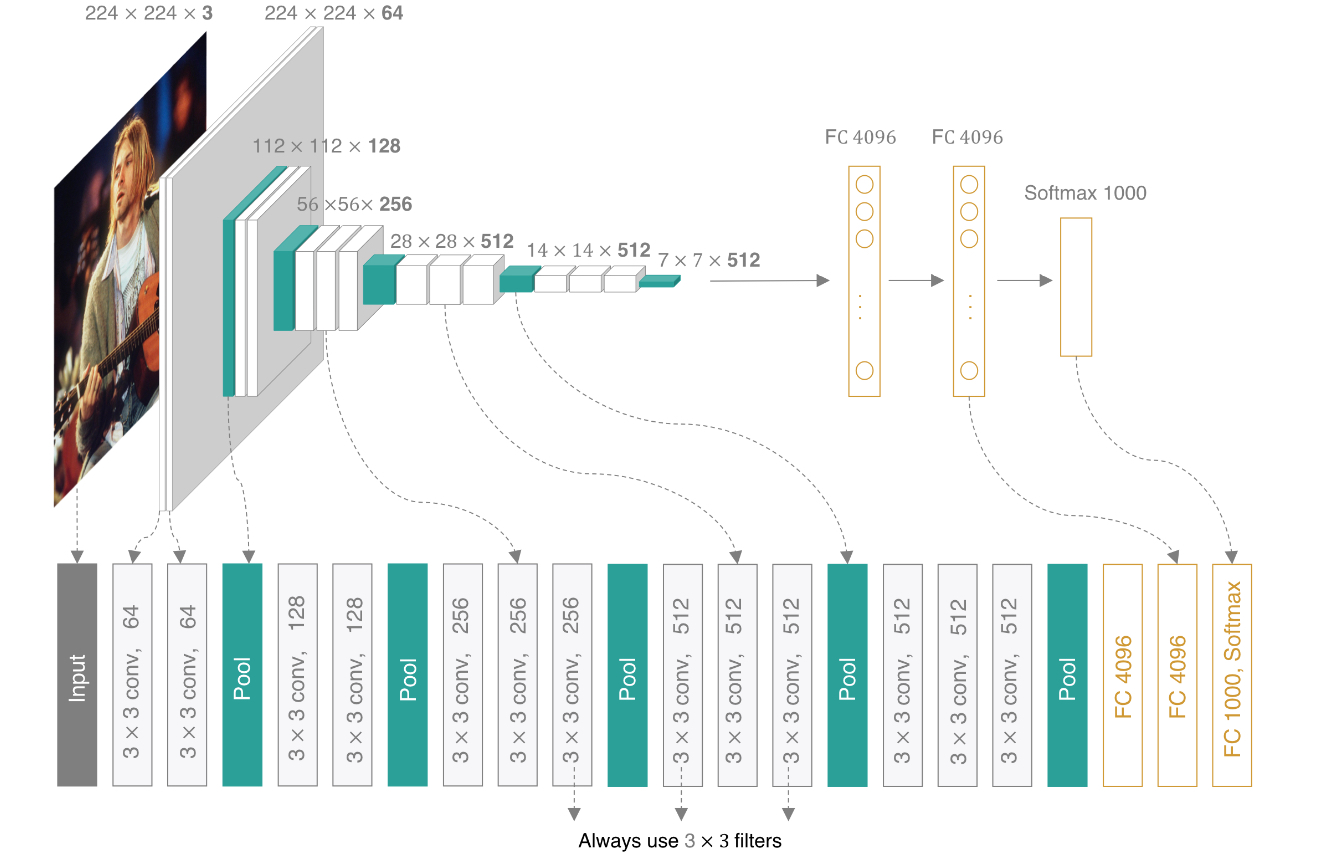
结构详解:VGG详解
import torch.nn as nn
import torch
# 定义VggNet网络模型
class VGG(nn.Module):
# init():进行初始化,申明模型中各层的定义
# features:make_features(cfg: list)生成提取特征的网络结构
# num_classes:需要分类的类别个数
# init_weights:是否对网络进行权重初始化
def __init__(self, features, num_classes=1000, init_weights=False):
# super:引入父类的初始化方法给子类进行初始化
super(VGG, self).__init__()
# 生成提取特征的网络结构
self.features = features
# 生成分类的网络结构
# Sequential:自定义顺序连接成模型,生成网络结构
self.classifier = nn.Sequential(
# Dropout:随机地将输入中50%的神经元激活设为0,即去掉了一些神经节点,防止过拟合
nn.Dropout(p=0.5),
nn.Linear(512 * 7 * 7, 4096),
# ReLU(inplace=True):将tensor直接修改,不找变量做中间的传递,节省运算内存,不用多存储额外的变量
nn.ReLU(True),
nn.Dropout(p=0.5),
nn.Linear(4096, 4096),
nn.ReLU(True),
nn.Dropout(p=0.5),
nn.Linear(4096, num_classes)
)
# 如果为真,则对网络参数进行初始化
if init_weights:
self._initialize_weights()
# forward():定义前向传播过程,描述了各层之间的连接关系
def forward(self, x):
# 将数据输入至提取特征的网络结构,N x 3 x 224 x 224
x = self.features(x)
# N x 512 x 7 x 7
# 图像经过提取特征网络结构之后,得到一个7*7*512的特征矩阵,进行展平
# Flatten():将张量(多维数组)平坦化处理,神经网络中第0维表示的是batch_size,所以Flatten()默认从第二维开始平坦化
x = torch.flatten(x, start_dim=1)
# 将数据输入分类网络结构,N x 512*7*7
x = self.classifier(x)
return x
# 网络结构参数初始化
def _initialize_weights(self):
# 遍历网络中的每一层
# 继承nn.Module类中的一个方法:self.modules(), 他会返回该网络中的所有modules
for m in self.modules():
# isinstance(object, type):如果指定对象是指定类型,则isinstance()函数返回True
# 如果是卷积层
if isinstance(m, nn.Conv2d):
# uniform_(tensor, a=0, b=1):服从~U(a,b)均匀分布,进行初始化
nn.init.xavier_uniform_(m.weight)
# 如果偏置不是0,将偏置置成0,对偏置进行初始化
if m.bias is not None:
# constant_(tensor, val):初始化整个矩阵为常数val
nn.init.constant_(m.bias, 0)
# 如果是全连接层
elif isinstance(m, nn.Linear):
# 正态分布初始化
nn.init.xavier_uniform_(m.weight)
# 将所有偏执置为0
nn.init.constant_(m.bias, 0)
# 生成提取特征的网络结构
# 参数是网络配置变量,传入对应配置的列表(list类型)
def make_features(cfg: list):
# 定义空列表,存放创建的每一层结构
layers = []
# 输入图片是RGB彩色图片
in_channels = 3
# for循环遍历配置列表,得到由卷积层和池化层组成的一个列表
for v in cfg:
# 如果列表的值是M字符,说明该层是最大池化层
if v == "M":
# 创建一个最大池化层,在VGG中所有的最大池化层的kernel_size=2,stride=2
layers += [nn.MaxPool2d(kernel_size=2, stride=2)]
# 否则是卷积层
else:
# in_channels:输入的特征矩阵的深度,v:输出的特征矩阵的深度,深度也就是卷积核的个数
# 在Vgg中,所有的卷积层的padding=1,stride=1
conv2d = nn.Conv2d(in_channels, v, kernel_size=3, stride=1, padding=1)
# 将卷积层和ReLU放入列表
layers += [conv2d, nn.ReLU(True)]
in_channels = v
# 将列表通过非关键字参数的形式返回,*layers可以接收任意数量的参数
return nn.Sequential(*layers)
# 定义cfgs字典文件,每一个key代表一个模型的配置文件,如:VGG11代表A配置,也就是一个11层的网络
# 数字代表卷积层中卷积核的个数,'M'代表池化层的结构
# 通过函数make_features(cfg: list)生成提取特征网络结构
cfgs = {
'vgg11': [64, 'M', 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'],
'vgg13': [64, 64, 'M', 128, 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'],
'vgg16': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 'M', 512, 512, 512, 'M', 512, 512, 512, 'M'],
'vgg19': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 256, 'M', 512, 512, 512, 512, 'M', 512, 512, 512, 512, 'M'],
}
# 实例化给定的配置模型,这里使用VGG16
# **kwargs表示可变长度的字典变量,在调用VGG函数时传入的字典变量
def vgg(model_name="vgg16", **kwargs):
# 如果model_name不在cfgs,序会抛出AssertionError错误,报错为参数内容“ ”
assert model_name in cfgs, "Warning: model number {} not in cfgs dict!".format(model_name)
# 得到VGG16对应的列表
cfg = cfgs[model_name]
# 实例化VGG网络
# 这个字典变量包含了分类的个数以及是否初始化权重的布尔变量
model = VGG(make_features(cfg), **kwargs)
return modelimport os
import sys
import json
import torch
import torch.nn as nn
from torchvision import transforms, datasets
import torch.optim as optim
from tqdm import tqdm
from model import vgg
def main():
# 如果有NVIDA显卡,转到GPU训练,否则用CPU
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print("using {} device.".format(device))
data_transform = {
# Compose():将多个transforms的操作整合在一起
# 训练
"train": transforms.Compose([
# RandomResizedCrop(224):将给定图像随机裁剪为不同的大小和宽高比,然后缩放所裁剪得到的图像为给定大小
transforms.RandomResizedCrop(224),
# RandomVerticalFlip():以0.5的概率竖直翻转给定的PIL图像
transforms.RandomHorizontalFlip(),
# ToTensor():数据转化为Tensor格式
transforms.ToTensor(),
# Normalize():将图像的像素值归一化到[-1,1]之间,使模型更容易收敛
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]),
# 验证
"val": transforms.Compose([transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])}
# abspath():获取文件当前目录的绝对路径
# join():用于拼接文件路径,可以传入多个路径
# getcwd():该函数不需要传递参数,获得当前所运行脚本的路径
data_root = os.path.abspath(os.getcwd())
# 得到数据集的路径
image_path = os.path.join(data_root, "flower_data")
# exists():判断括号里的文件是否存在,可以是文件路径
# 如果image_path不存在,则会抛出AssertionError错误,报错为参数内容“ ”
assert os.path.exists(image_path), "{} path does not exist.".format(image_path)
# 加载训练数据集
# ImageFolder:假设所有的文件按文件夹保存,每个文件夹下存储同一个类别的图片,文件夹名为类名,其构造函数如下:
# ImageFolder(root, transform=None, target_transform=None, loader=default_loader)
# root:在指定路径下寻找图片,transform:对PILImage进行的转换操作,输入是使用loader读取的图片
train_dataset = datasets.ImageFolder(root=os.path.join(image_path, "train"),
transform=data_transform["train"])
# 训练集长度
train_num = len(train_dataset)
# {'daisy':0, 'dandelion':1, 'roses':2, 'sunflower':3, 'tulips':4}
# class_to_idx:获取分类名称对应索引
flower_list = train_dataset.class_to_idx
# dict():创建一个新的字典
# 循环遍历数组索引并交换val和key的值重新赋值给数组,这样模型预测的直接就是value类别值
cla_dict = dict((val, key) for key, val in flower_list.items())
# 把字典编码成json格式
json_str = json.dumps(cla_dict, indent=4)
# 把字典类别索引写入json文件
with open('class_indices.json', 'w') as json_file:
json_file.write(json_str)
# 一次训练载入32张图像
batch_size = 32
# 确定进程数
# min():返回给定参数的最小值,参数可以为序列
# cpu_count():返回一个整数值,表示系统中的CPU数量,如果不确定CPU的数量,则不返回任何内容
nw = min([os.cpu_count(), batch_size if batch_size > 1 else 0, 8])
print('Using {} dataloader workers every process'.format(nw))
# DataLoader:将读取的数据按照batch size大小封装给训练集
# dataset (Dataset):输入的数据集
# batch_size (int, optional):每个batch加载多少个样本,默认: 1
# shuffle (bool, optional):设置为True时会在每个epoch重新打乱数据,默认: False
# num_workers(int, optional): 决定了有几个进程来处理,默认为0意味着所有的数据都会被load进主进程
train_loader = torch.utils.data.DataLoader(train_dataset,
batch_size=batch_size, shuffle=True,
num_workers=nw)
# 加载测试数据集
validate_dataset = datasets.ImageFolder(root=os.path.join(image_path, "val"),
transform=data_transform["val"])
# 测试集长度
val_num = len(validate_dataset)
validate_loader = torch.utils.data.DataLoader(validate_dataset,
batch_size=batch_size, shuffle=False,
num_workers=nw)
print("using {} images for training, {} images for validation.".format(train_num,
val_num))
# 模型实例化,将模型转到device
model_name = "vgg16"
net = vgg(model_name=model_name, num_classes=5, init_weights=True)
net.to(device)
# 定义损失函数(交叉熵损失)
loss_function = nn.CrossEntropyLoss()
# 定义adam优化器
# params(iterable):要训练的参数,一般传入的是model.parameters()
# lr(float):learning_rate学习率,也就是步长,默认:1e-3
optimizer = optim.Adam(net.parameters(), lr=0.0001)
# 迭代次数(训练次数)
epochs = 30
# 用于判断最佳模型
best_acc = 0.0
# 最佳模型保存地址
save_path = './{}Net.pth'.format(model_name)
train_steps = len(train_loader)
for epoch in range(epochs):
# 训练
net.train()
running_loss = 0.0
# tqdm:进度条显示
train_bar = tqdm(train_loader, file=sys.stdout)
# train_bar: 传入数据(数据包括:训练数据和标签)
# enumerate():将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,同时列出数据和数据下标,一般用在for循环当中
# enumerate返回值有两个:一个是序号,一个是数据(包含训练数据和标签)
# x:训练数据(inputs)(tensor类型的),y:标签(labels)(tensor类型)
for step, data in enumerate(train_bar):
# 前向传播
images, labels = data
# 计算训练值
outputs = net(images.to(device))
# 计算观测值(label)与训练值的损失函数
loss = loss_function(outputs, labels.to(device))
# 反向传播
# 清空过往梯度
optimizer.zero_grad()
# 反向传播,计算当前梯度
loss.backward()
# 根据梯度更新网络参数
optimizer.step()
# item():得到元素张量的元素值
running_loss += loss.item()
# 进度条的前缀
# .3f:表示浮点数的精度为3(小数位保留3位)
train_bar.desc = "train epoch[{}/{}] loss:{:.3f}".format(epoch + 1,
epochs,
loss)
# 测试
# eval():如果模型中有Batch Normalization和Dropout,则不启用,以防改变权值
net.eval()
acc = 0.0
# 清空历史梯度,与训练最大的区别是测试过程中取消了反向传播
with torch.no_grad():
val_bar = tqdm(validate_loader, file=sys.stdout)
for val_data in val_bar:
val_images, val_labels = val_data
outputs = net(val_images.to(device))
# torch.max(input, dim)函数
# input是具体的tensor,dim是max函数索引的维度,0是每列的最大值,1是每行的最大值输出
# 函数会返回两个tensor,第一个tensor是每行的最大值;第二个tensor是每行最大值的索引
predict_y = torch.max(outputs, dim=1)[1]
# 对两个张量Tensor进行逐元素的比较,若相同位置的两个元素相同,则返回True;若不同,返回False
# .sum()对输入的tensor数据的某一维度求和
acc += torch.eq(predict_y, val_labels.to(device)).sum().item()
val_accurate = acc / val_num
print('[epoch %d] train_loss: %.3f val_accuracy: %.3f' %
(epoch + 1, running_loss / train_steps, val_accurate))
# 保存最好的模型权重
if val_accurate > best_acc:
best_acc = val_accurate
# torch.save(state, dir)保存模型等相关参数,dir表示保存文件的路径+保存文件名
# model.state_dict():返回的是一个OrderedDict,存储了网络结构的名字和对应的参数
torch.save(net.state_dict(), save_path)
print('Finished Training')
if __name__ == '__main__':
main()import os
import json
import torch
from PIL import Image
from torchvision import transforms
import matplotlib.pyplot as plt
from model import vgg
def main():
# 如果有NVIDA显卡,转到GPU训练,否则用CPU
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# 将多个transforms的操作整合在一起
data_transform = transforms.Compose(
[transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
# 加载图片
img_path = "./tulip.jpg"
# 确定图片存在,否则反馈错误
assert os.path.exists(img_path), "file: '{}' dose not exist.".format(img_path)
img = Image.open(img_path)
# imshow():对图像进行处理并显示其格式,show()则是将imshow()处理后的函数显示出来
plt.imshow(img)
# [C, H, W],转换图像格式
img = data_transform(img)
# [N, C, H, W],增加一个维度N
img = torch.unsqueeze(img, dim=0)
# 获取结果类型
json_path = './class_indices.json'
# 确定路径存在,否则反馈错误
assert os.path.exists(json_path), "file: '{}' dose not exist.".format(json_path)
# 读取内容
with open(json_path, "r") as f:
class_indict = json.load(f)
# 模型实例化,将模型转到device,结果类型有5种
model = vgg(model_name="vgg16", num_classes=5).to(device)
# 载入模型权重
weights_path = "./vgg16Net.pth"
# 确定模型存在,否则反馈错误
assert os.path.exists(weights_path), "file: '{}' dose not exist.".format(weights_path)
model.load_state_dict(torch.load(weights_path, map_location=device))
# 进入验证阶段
model.eval()
with torch.no_grad():
# 预测类别
# squeeze():维度压缩,返回一个tensor(张量),其中input中大小为1的所有维都已删除
output = torch.squeeze(model(img.to(device))).cpu()
# softmax:归一化指数函数,将预测结果输入进行非负性和归一化处理,最后将某一维度值处理为0-1之内的分类概率
predict = torch.softmax(output, dim=0)
# argmax(input):返回指定维度最大值的序号
# .numpy():把tensor转换成numpy的格式
predict_cla = torch.argmax(predict).numpy()
# 输出的预测值与真实值
print_res = "class: {} prob: {:.3}".format(class_indict[str(predict_cla)],
predict[predict_cla].numpy())
# 图片标题
plt.title(print_res)
for i in range(len(predict)):
print("class: {:10} prob: {:.3}".format(class_indict[str(i)],
predict[i].numpy()))
plt.show()
if __name__ == '__main__':
main()
import os
from shutil import copy, rmtree
import random
def mk_file(file_path: str):
if os.path.exists(file_path):
# 如果文件夹存在,则先删除原文件夹在重新创建
rmtree(file_path)
os.makedirs(file_path)
def main():
# 保证随机可复现
random.seed(0)
# 将数据集中10%的数据划分到验证集中
split_rate = 0.1
# 指向解压后的flower_photos文件夹
# getcwd():该函数不需要传递参数,获得当前所运行脚本的路径
cwd = os.getcwd()
# join():用于拼接文件路径,可以传入多个路径
data_root = os.path.join(cwd, "flower_data")
origin_flower_path = os.path.join(data_root, "flower_photos")
# 确定路径存在,否则反馈错误
assert os.path.exists(origin_flower_path), "path '{}' does not exist.".format(origin_flower_path)
# isdir():判断某一路径是否为目录
# listdir():返回指定的文件夹包含的文件或文件夹的名字的列表
flower_class = [cla for cla in os.listdir(origin_flower_path)
if os.path.isdir(os.path.join(origin_flower_path, cla))]
# 创建训练集train文件夹,并由类名在其目录下创建子目录
train_root = os.path.join(data_root, "train")
mk_file(train_root)
for cla in flower_class:
# 建立每个类别对应的文件夹
mk_file(os.path.join(train_root, cla))
# 创建验证集val文件夹,并由类名在其目录下创建子目录
val_root = os.path.join(data_root, "val")
mk_file(val_root)
for cla in flower_class:
# 建立每个类别对应的文件夹
mk_file(os.path.join(val_root, cla))
# 遍历所有类别的图像并按比例分成训练集和验证集
for cla in flower_class:
cla_path = os.path.join(origin_flower_path, cla)
# iamges列表存储了该目录下所有图像的名称
images = os.listdir(cla_path)
num = len(images)
# 随机采样验证集的索引
# 从images列表中随机抽取k个图像名称
# random.sample:用于截取列表的指定长度的随机数,返回列表
# eval_index保存验证集val的图像名称
eval_index = random.sample(images, k=int(num*split_rate))
for index, image in enumerate(images):
if image in eval_index:
# 将分配至验证集中的文件复制到相应目录
image_path = os.path.join(cla_path, image)
new_path = os.path.join(val_root, cla)
copy(image_path, new_path)
else:
# 将分配至训练集中的文件复制到相应目录
image_path = os.path.join(cla_path, image)
new_path = os.path.join(train_root, cla)
copy(image_path, new_path)
# '\r'回车,回到当前行的行首,而不会换到下一行,如果接着输出,本行以前的内容会被逐一覆盖
# end="":将print自带的换行用end中指定的str代替
print("\r[{}] processing [{}/{}]".format(cla, index+1, num), end="")
print()
print("processing done!")
if __name__ == '__main__':
main()
大话卷积神经网络(CNN):VGG![]() https://my.oschina.net/u/876354/blog/1634322
https://my.oschina.net/u/876354/blog/1634322
https://download.csdn.net/download/qq_43307074/86730499?spm=1001.2014.3001.5503
我有一个模型:classItem项目有一个属性“商店”基于存储的值,我希望Item对象对特定方法具有不同的行为。Rails中是否有针对此的通用设计模式?如果方法中没有大的if-else语句,这是如何干净利落地完成的? 最佳答案 通常通过Single-TableInheritance. 关于ruby-on-rails-Rails-子类化模型的设计模式是什么?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.co
如何在buildr项目中使用Ruby?我在很多不同的项目中使用过Ruby、JRuby、Java和Clojure。我目前正在使用我的标准Ruby开发一个模拟应用程序,我想尝试使用Clojure后端(我确实喜欢功能代码)以及JRubygui和测试套件。我还可以看到在未来的不同项目中使用Scala作为后端。我想我要为我的项目尝试一下buildr(http://buildr.apache.org/),但我注意到buildr似乎没有设置为在项目中使用JRuby代码本身!这看起来有点傻,因为该工具旨在统一通用的JVM语言并且是在ruby中构建的。除了将输出的jar包含在一个独特的、仅限ruby
在rails源中:https://github.com/rails/rails/blob/master/activesupport/lib/active_support/lazy_load_hooks.rb可以看到以下内容@load_hooks=Hash.new{|h,k|h[k]=[]}在IRB中,它只是初始化一个空哈希。和做有什么区别@load_hooks=Hash.new 最佳答案 查看rubydocumentationforHashnew→new_hashclicktotogglesourcenew(obj)→new_has
我需要从一个View访问多个模型。以前,我的links_controller仅用于提供以不同方式排序的链接资源。现在我想包括一个部分(我假设)显示按分数排序的顶级用户(@users=User.all.sort_by(&:score))我知道我可以将此代码插入每个链接操作并从View访问它,但这似乎不是“ruby方式”,我将需要在不久的将来访问更多模型。这可能会变得很脏,是否有针对这种情况的任何技术?注意事项:我认为我的应用程序正朝着单一格式和动态页面内容的方向发展,本质上是一个典型的网络应用程序。我知道before_filter但考虑到我希望应用程序进入的方向,这似乎很麻烦。最终从任何
我有一个包含模块的模型。我想在模块中覆盖模型的访问器方法。例如:classBlah这显然行不通。有什么想法可以实现吗? 最佳答案 您的代码看起来是正确的。我们正在毫无困难地使用这个确切的模式。如果我没记错的话,Rails使用#method_missing作为属性setter,因此您的模块将优先,阻止ActiveRecord的setter。如果您正在使用ActiveSupport::Concern(参见thisblogpost),那么您的实例方法需要进入一个特殊的模块:classBlah
我有一个表单,其中有很多字段取自数组(而不是模型或对象)。我如何验证这些字段的存在?solve_problem_pathdo|f|%>... 最佳答案 创建一个简单的类来包装请求参数并使用ActiveModel::Validations。#definedsomewhere,atthesimplest:require'ostruct'classSolvetrue#youcouldevencheckthesolutionwithavalidatorvalidatedoerrors.add(:base,"WRONG!!!")unlesss
我想向我的Controller传递一个参数,它是一个简单的复选框,但我不知道如何在模型的form_for中引入它,这是我的观点:{:id=>'go_finance'}do|f|%>Transferirde:para:Entrada:"input",:placeholder=>"Quantofoiganho?"%>Saída:"output",:placeholder=>"Quantofoigasto?"%>Nota:我想做一个额外的复选框,但我该怎么做,模型中没有一个对象,而是一个要检查的对象,以便在Controller中创建一个ifelse,如果没有检查,请帮助我,非常感谢,谢谢
我有一些非常大的模型,我必须将它们迁移到最新版本的Rails。这些模型有相当多的验证(User有大约50个验证)。是否可以将所有这些验证移动到另一个文件中?说app/models/validations/user_validations.rb。如果可以,有人可以提供示例吗? 最佳答案 您可以为此使用关注点:#app/models/validations/user_validations.rbrequire'active_support/concern'moduleUserValidationsextendActiveSupport:
我有一个用户工厂。我希望默认情况下确认用户。但是鉴于unconfirmed特征,我不希望它们被确认。虽然我有一个基于实现细节而不是抽象的工作实现,但我想知道如何正确地做到这一点。factory:userdoafter(:create)do|user,evaluator|#unwantedimplementationdetailshereunlessFactoryGirl.factories[:user].defined_traits.map(&:name).include?(:unconfirmed)user.confirm!endendtrait:unconfirmeddoenden
对于Rails模型,是否可以/建议让一个类的成员不持久保存到数据库中?我想将用户最后选择的类型存储在session变量中。由于我无法从我的模型中设置session变量,我想将值存储在一个“虚拟”类成员中,该成员只是将值传递回Controller。你能有这样的类(class)成员吗? 最佳答案 将非持久属性添加到Rails模型就像任何其他Ruby类一样:classUser扩展解释:在Ruby中,所有实例变量都是私有(private)的,不需要在赋值前定义。attr_accessor创建一个setter和getter方法:classUs