Prometheus+Grafana监控
Prometheus(普罗米修斯)是一套开源的监控、报警、时间序列数据库的组合。
Prometheus基本原理是通过HTTP协议周期性抓取被监控组件的状态,这样做的好处是任意组件只要提供HTTP接口就可以接入监控系统,不需要任何SDK或者其他的集成过程。这样做非常适合虚拟化环境比如VM或者Docker。
Prometheus应该是为数不多的适合Docker、Mesos、Kubernetes环境的监控系统之一。
输出被监控组件信息的HTTP接口被叫做exporter 。目前互联网公司常用的组件大部分都有exporter可以直接使用,比如Varnish、Haproxy、Nginx、MySQL、Linux 系统信息 (包括磁盘、内存、CPU、网络等等),具体支持的源看:https://github.com/prometheus。
与其他监控系统相比,Prometheus的主要特点是:
一个多维数据模型(时间序列由指标名称定义和设置键/值尺寸)。
非常高效的存储,平均一个采样数据占~3.5bytes左右,320万的时间序列,每30秒采样,保持60天,消耗磁盘大概228G。
一种灵活的查询语言。
不依赖分布式存储,单个服务器节点。
时间集合通过HTTP上的PULL模型进行。
通过中间网关支持推送时间。
通过服务发现或静态配置发现目标。
多种模式的图形和仪表板支持。
下面介绍如何使用Prometheus、Grafana、CAdvisor、node-exporter、mysqld-exporter对本机服务器性能、Docker容器、MySQL数据库进行监控。
node-exporter 用于机器系统数据收集
mysqld-exporter 用于MySQL数据库数据收集
redis-exporter 用于Redis缓存数据库的数据收集
cadvisor 用于收集宿主机上的docker容器数据
prometheus 用于周期性抓取被监控组件的状态
Grafana是一个开源的功能丰富的数据可视化平台,通常用于时序数据的可视化
监控服务器CPU、内存、磁盘、I/O等信息,首先需要安装node exporter。node exporter的作用是用于机器系统数据收集。
由于node-exporter要获取主机的信息,最好直接部署到宿主机上。
Docker部署
docker run -d --name node-exporter --restart=always -p 9100:9100 \
-v "/proc:/host/proc:ro" \
-v "/sys:/host/sys:ro" \
-v "/:/rootfs:ro" prom/node-exporter
浏览器访问: http://ip:9100/metrics,收集到数据,有了它就可以做宿主机Linux数据展示了
用来收集MysQL或者Mariadb数据库相关指标的,mysql exporter需要连接到数据库并有相关权限。
Docker部署
docker run -d --name mysqld_exporter --restart=always -p 9104:9104 -e DATA_SOURCE_NAME="root:123456@(localhost:3306)/" prom/mysqld-exporter
浏览器访问: http://ip:9104/metrics,收集到数据,有了它就可以做MySQL数据库数据展示了
cadvisor可以对节点机器上的资源及容器进行实时监控和性能数据采集,包括CPU使用情况、内存使用情况、网络吞吐量及文件系统使用情况。
Docker部署
docker run -d -p 8080:8080 --name cadvisor \
-v /:/rootfs:ro \
-v /var/run:/var/run:rw \
-v /sys:/sys:ro \
-v /var/lib/docker/:/var/lib/docker:ro \
-v /dev/disk/:/dev/disk:ro --restart=always --privileged=true google/cadvisor
浏览器访问: http://ip:8080/metrics,收集到数据,有了它就可以做Docker容器数据展示了。
如果获取不到CPU的信息,可通过下方命令,进行挂载和建立软连接
sudo mount -o remount,rw '/sys/fs/cgroup'
sudo ln -s /sys/fs/cgroup/cpu,cpuacct /sys/fs/cgroup/cpuacct,cpu
Prometheus的基本原理是通过HTTP协议周期性抓取被监控组件的状态,任意组件只要提供对应的HTTP接口就可以接入监控。
docker
docker run -d -p 9090:9090 --name prometheus \
-v /mnt/e/Docker/volumes/prometheus/:/prometheus \
-v /mnt/e/Docker/volumes/prometheus/data:/data \
-v /opt/prometheus/prometheus.yml:/etc/prometheus/prometheus.yml \
--restart=always prom/prometheus
注意:
宿主机的路径必须是绝对路径: /opt/prometheus/prometheus.yml,否则报错
prometheus.yml
global:
# 抓取间隔,60秒向目标抓取一次数据
scrape_interval: 60s
evaluation_interval: 60s
# 这里表示抓取对象的配置
scrape_configs:
- job_name: 'prometheus'
# 重写了全局抓取间隔时间,由60秒重写成30秒
scrape_interval: 30s
static_configs:
- targets: ['172.23.200.252:9090']
- job_name: 'mysqld'
static_configs:
- targets: ['172.23.200.252:9104']
- job_name: 'linux'
static_configs:
- targets: ['172.23.200.252:9100']
- job_name: 'docker'
static_configs:
- targets: ['172.23.200.252:8080']
浏览器访问: http://部署的机器IP地址:9090/graph ,效果如下
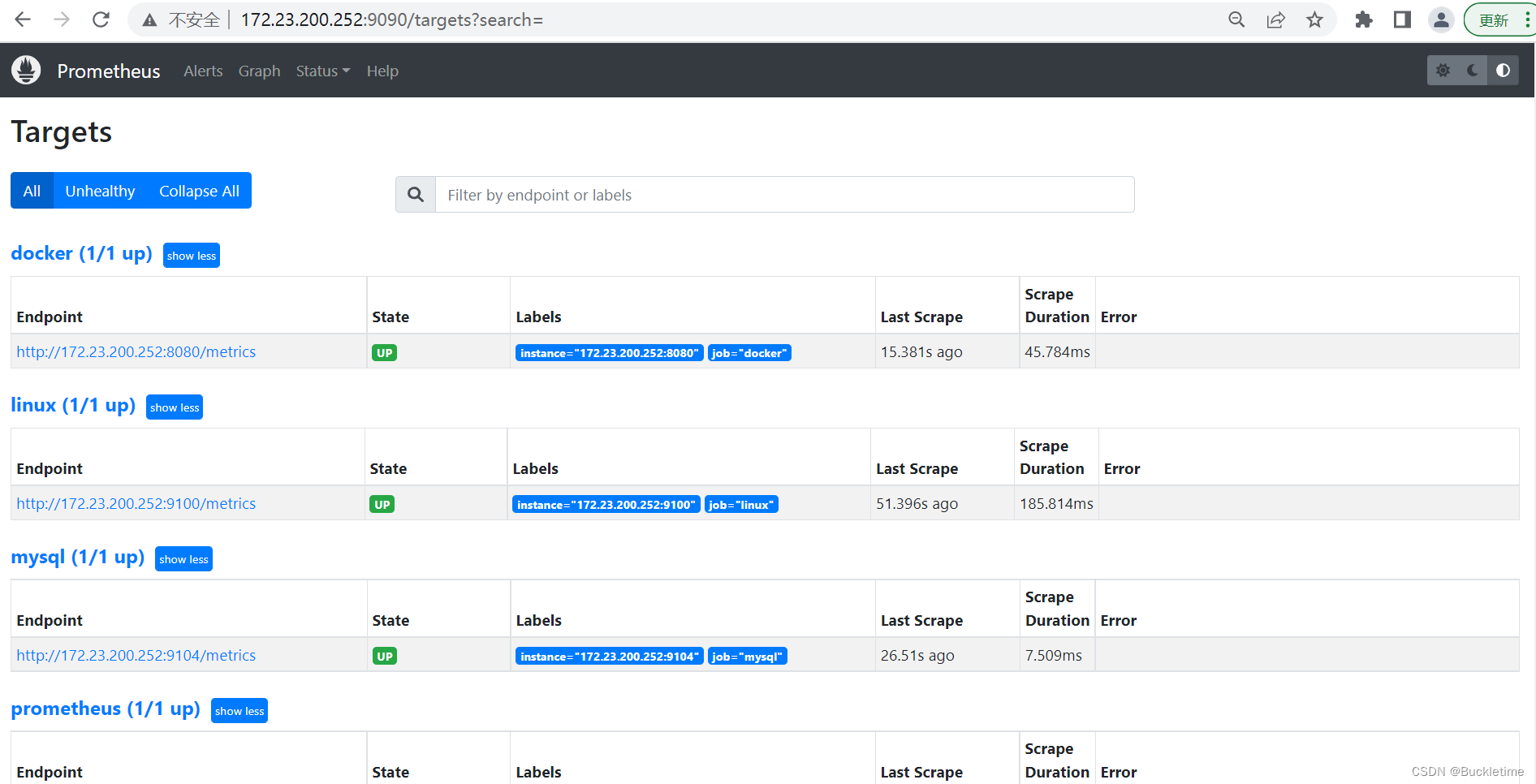
访问targets,http://部署的机器IP地址:9090/targets,效果如下。
Grafana是用于可视化大型测量数据的开源程序,他提供了强大和优雅的方式去创建、共享、浏览数据。Dashboard中显示了不同metric数据源中的数据。
Grafana是一个开源的,拥有丰富Dashboard和图表编辑的指标分析平台,和Kibana不同的是Grafana专注于时序类图表分析,而目支持多种数据源,如Graphite、 InfluxDB、Elasticsearch、Mysql、K8s、Zabbix、 Prometheus等。
新建空文件夹grafana-storage,用来存储数据
mkdir /opt/grafana-storage
添加权限,因为grafana用户会在这个目录写入文件,直接设置777,也可以设置其它权限
chmod 777 -R /opt/grafana-storage
Docker部署
docker run -d --name grafana --restart=always -p 3000:3000 -v /opt/grafana-storage:/var/lib/grafana grafana/grafana
访问URL
http://部署机器的IP地址:3000
默认会先跳转到登录页面,默认的用户名和密码都是admin
登录之后,它会要求你重置密码。你还可以再输次admin密码!
密码设置完成之后,就会跳转到首页。
点击Setting -> Data sources -> Add data source
选择Prometheus
name名字写Prometheus
ype 选择Prometheus,因为数据都从它那里获取
url 输入Prometheus的ip和端口
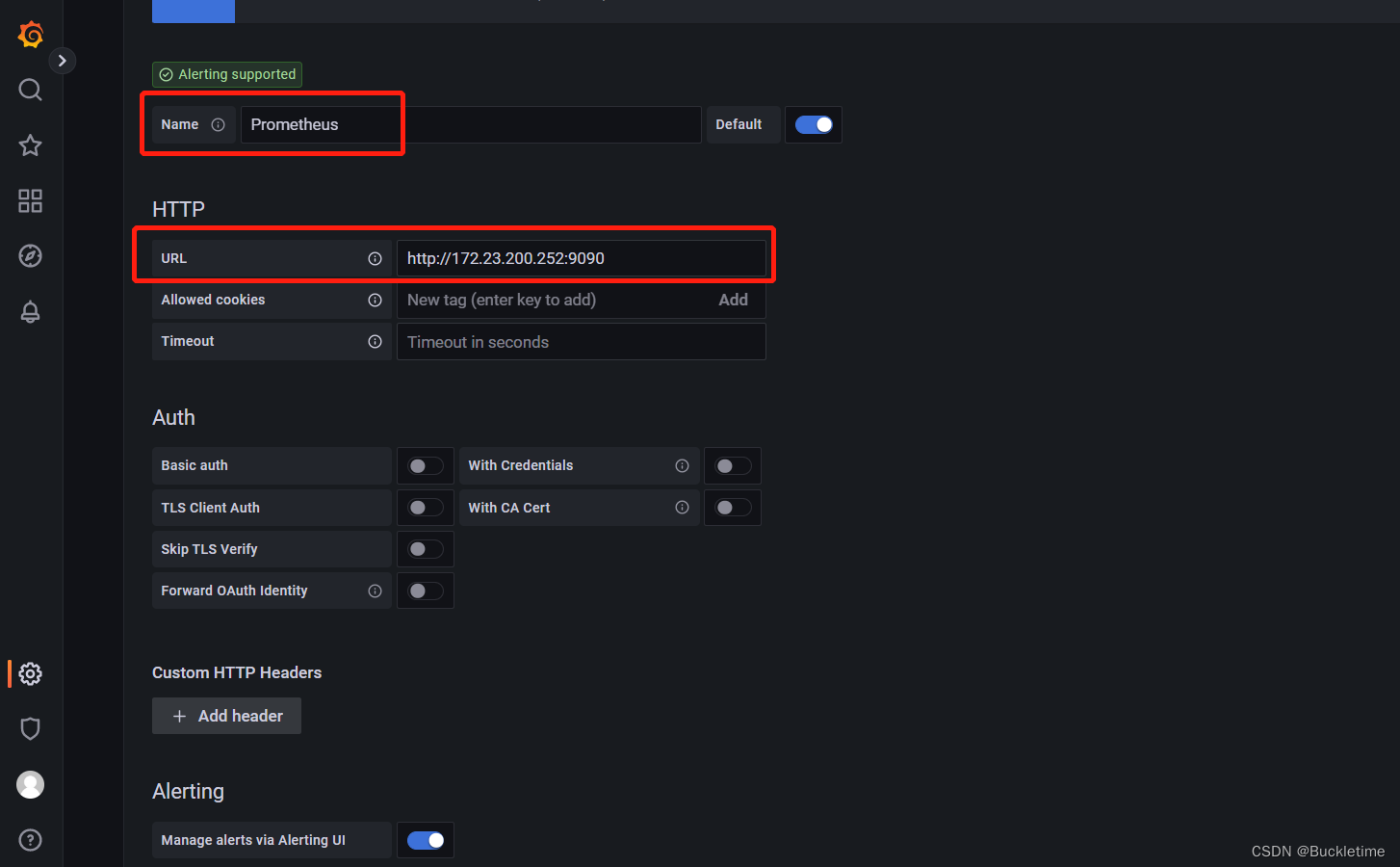
点击下面的Save & Test,如果出现绿色提示信息,说明可以了。
回到首页,Dashboard -> import 导入grafana监控模板,模板导入有三种方式:
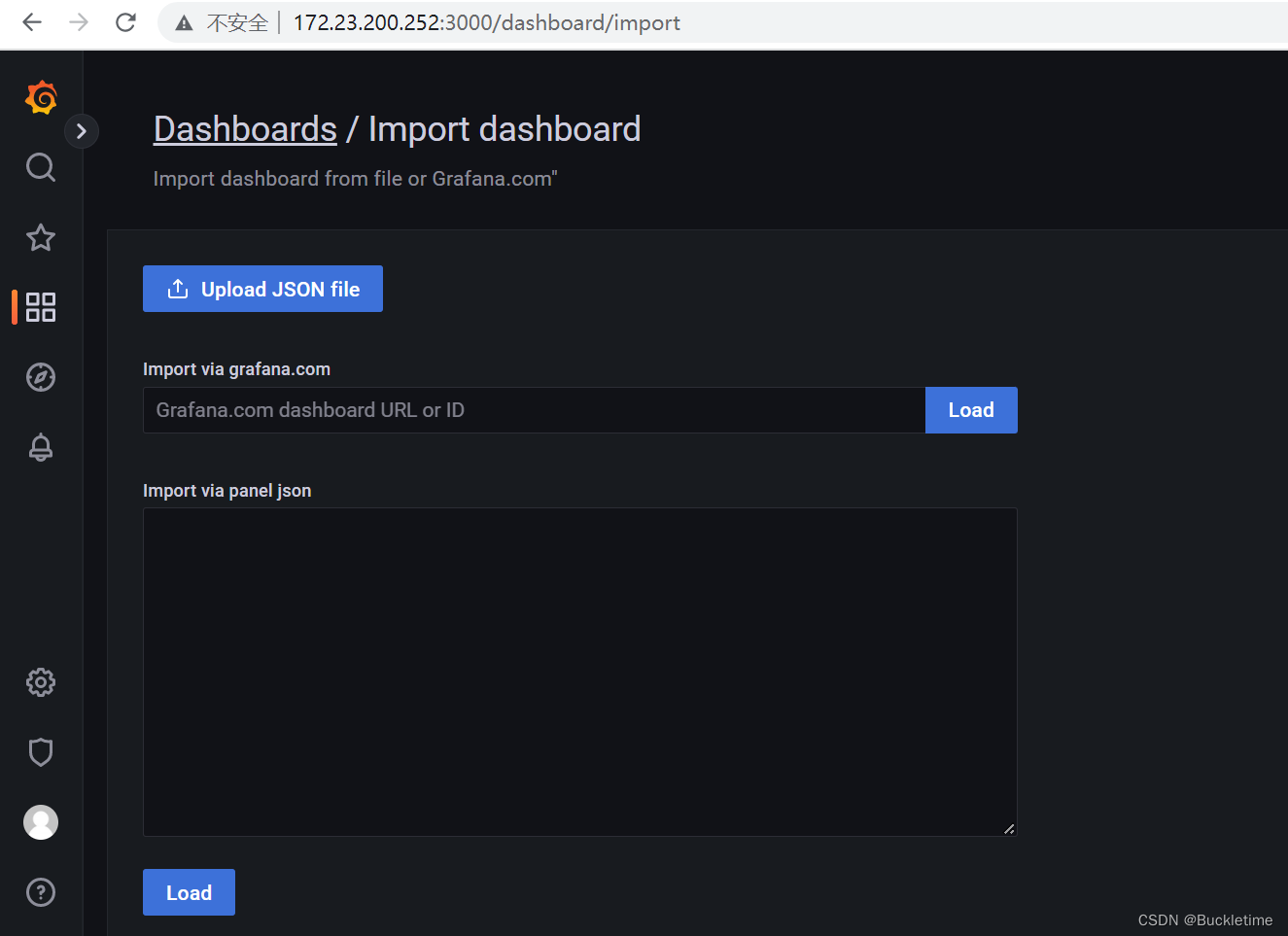
官网下载Dashboard地址:https://grafana.com/grafana/dashboards
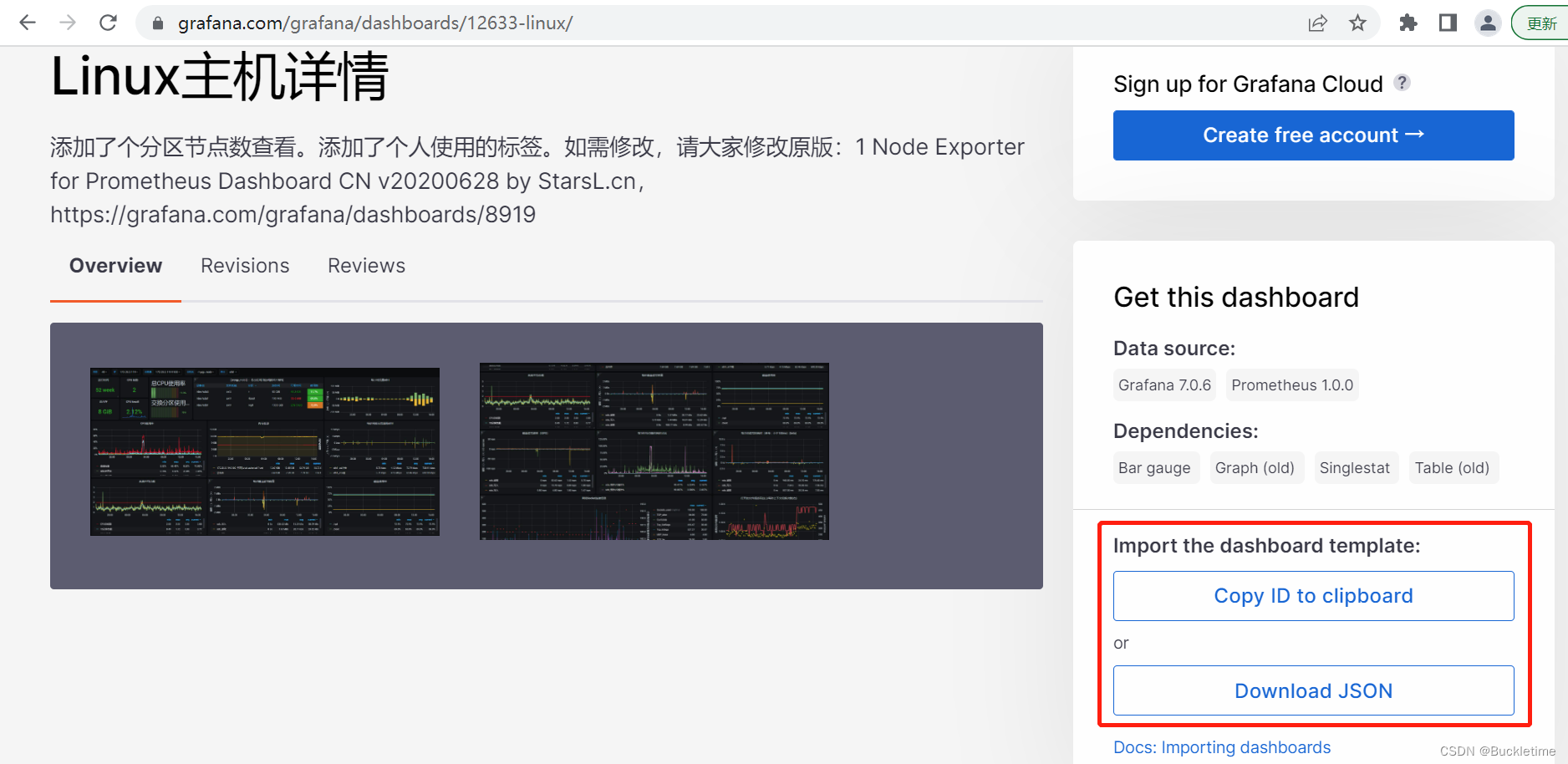
导入主机的监控模板,模板id为: 12633,填入import via grafana.com输入框内,点击【load】进入选项配置界面
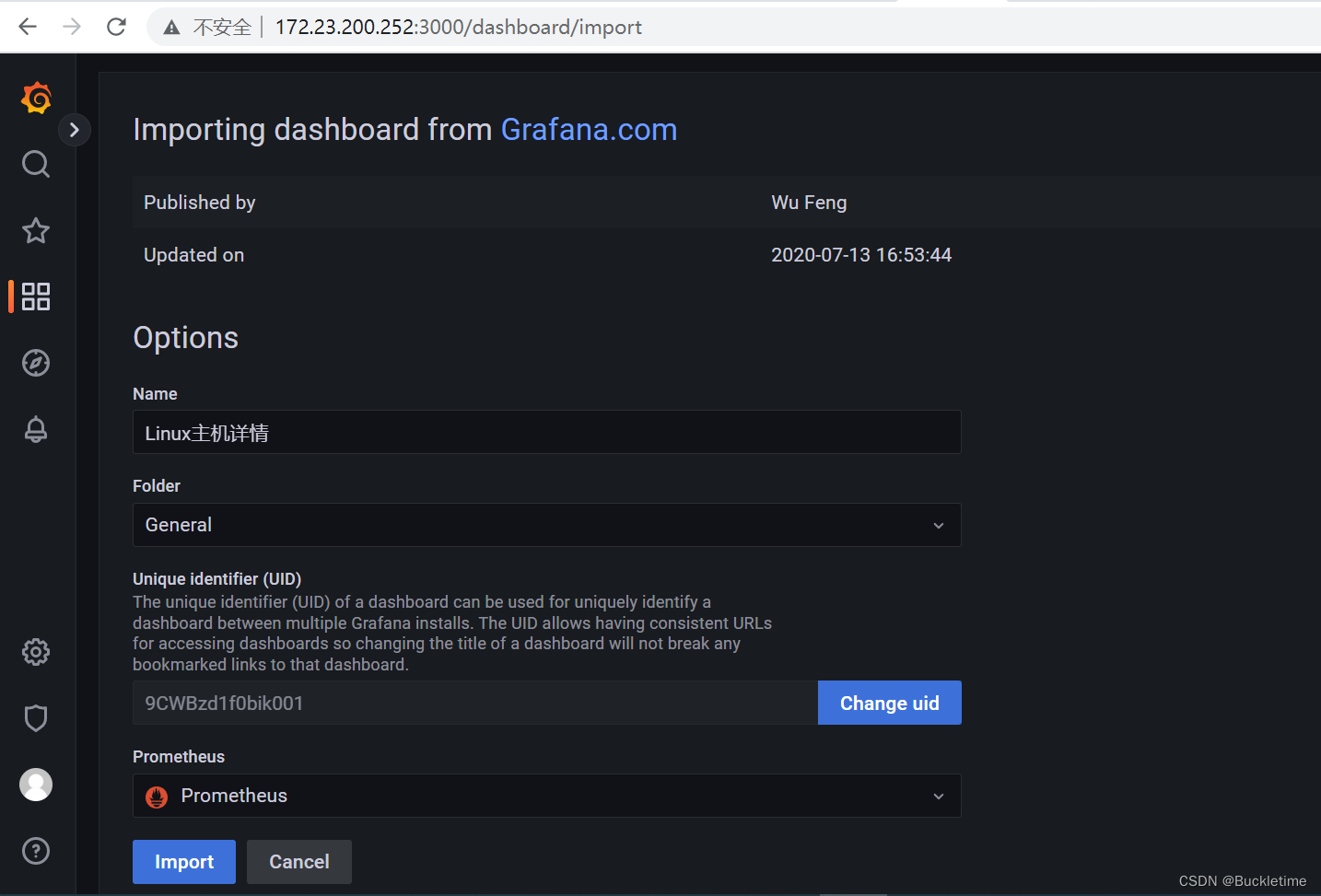
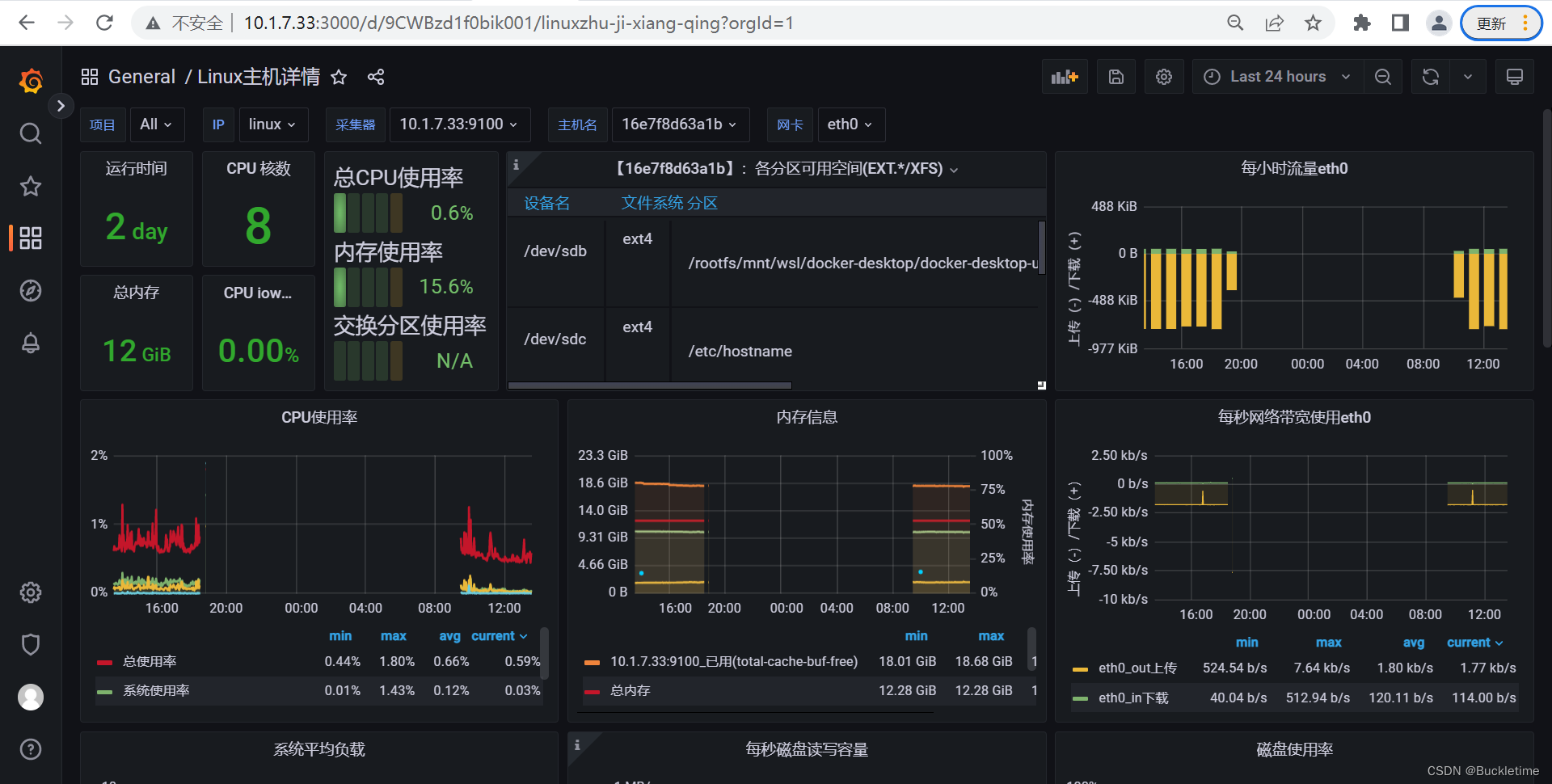
选择Prometheus组件,点击【Import】保存就可以进行数据可视化展示
导入Mysql模板,模板id为: 7362
prometheus 监控 nginx 使用 nginx-vts-exporter 采集数据。同时,需要 nginx 支持 nginx-module-vts 模块获取 nginx 自身的一些数据。
nginx-vts
nginx,默认是没有nginx-module-vts模块的。需要下载对应的nginx源码,进行重新编译才行。为了快速演示,这里使用nginx-vts镜像,包含nginx和nginx-module-vts模块
docker run -d -it --name nginx -p 80:80 gaciaga/nginx-vts
此镜像已经默认开启了status,访问http://10.1.7.33/status
nginx-vts-exporter
主要用于收集nginx的监控数据,并给Prometheus提供监控接口,默认端口号9913。
docker run -d -it --name nginx-vts-exporter -e NGINX_STATUS="http://10.1.7.33/status/format/json" -p 9913:9913 sophos/nginx-vts-exporter
注意:请根据实际情况修改NGINX_STATUS变量,确保能正常访问。
浏览器访问: http://ip:9913/metrics,收集到数据,有了它就可以做Nginx数据展示了
修改prometheus.yml配置,增加nginx统计配置
- job_name: 'nginx'
static_configs:
- targets: ['10.1.7.33:9913']
重启prometheus
docker restart prometheus
导入Nginx模板,模板id为: 2949
prometheus监控redis需要用到redis_exporter。
启动redis_exporter
docker run -d --name redis_exporter -p 9121:9121 oliver006/redis_exporter --redis.addr redis://10.1.7.33:6379 --redis.password '你的密码'
参数说明:
--redis.addr:指明一个或多个 Redis 节点的地址,多个节点使用逗号分隔,默认为redis://localhost:6379
--redis.password:验证 Redis 时使用的密码;
--redis.file:包含一个或多个redis 节点的文件路径,每行一个节点,此选项与 --redis.addr 互斥。
--web.listen-address:监听的地址和端口,默认为 0.0.0.0:9121
修改prometheus.yml配置,增加redis统计配置
- job_name: 'redis'
static_configs:
- targets: ['10.1.7.33:9121']
重启prometheus
docker restart prometheus
导入Redis模板,模板id为: 11835
prometheus监控PostgreSQL需要用到postgres-exporter
docker启动
docker run -p 9187:9187 -d --name postgresqldb-exporter -e DATA_SOURCE_NAME="postgresql://swap:swap@piesat@10.1.100.167:5432/zxj_sdp_db?sslmode=disable" quay.io/prometheuscommunity/postgres-exporter
浏览器访问: http://ip:9187/metrics,收集到数据,有了它就可以做PostgreSQL数据展示了
修改prometheus.yml配置,增加postgres统计配置
- job_name: 'postgres'
static_configs:
- targets: ['172.23.200.252:9187']
重启prometheus
docker restart prometheus
压缩包启动
注意:docker直接启动有一个问题,无法监测到postgresql服务的启动时间。若要监测服务启动时间,需要添加自定义监测指标:
2.上传服务器并进行解压
tar -xzvf postgres_exporter-0.11.0.linux-amd64.tar.gz
3.添加环境变量
vim ~/.bash_profile
# 在文件最后加上新的路径
export DATA_SOURCE_NAME="postgresql://<你的用户>:<你的密码>@<数据库ip>:5432/zxj_sdp_db?sslmode=disable"
# 手动生效
source ~/.bash_profile
4.指定一个包含自定义查询语句的 YAML 文件,参考 queries.yaml
pg_postmaster:
query: "SELECT pg_postmaster_start_time as start_time_seconds from pg_postmaster_start_time()"
master: true
metrics:
- start_time_seconds:
usage: "GAUGE"
description: "Time at which postmaster started"
5.启动postgres_exporter
./postgres_exporter --web.listen-address :9187 --extend.query-path="/home/prometheus/postgresql/queries.yaml"
参数说明:
--web.listen-address:监听地址
--extend.query-path:指定一个包含自定义查询语句的 YAML 文件
导入PostgreSQ模板,模板id为: 9628
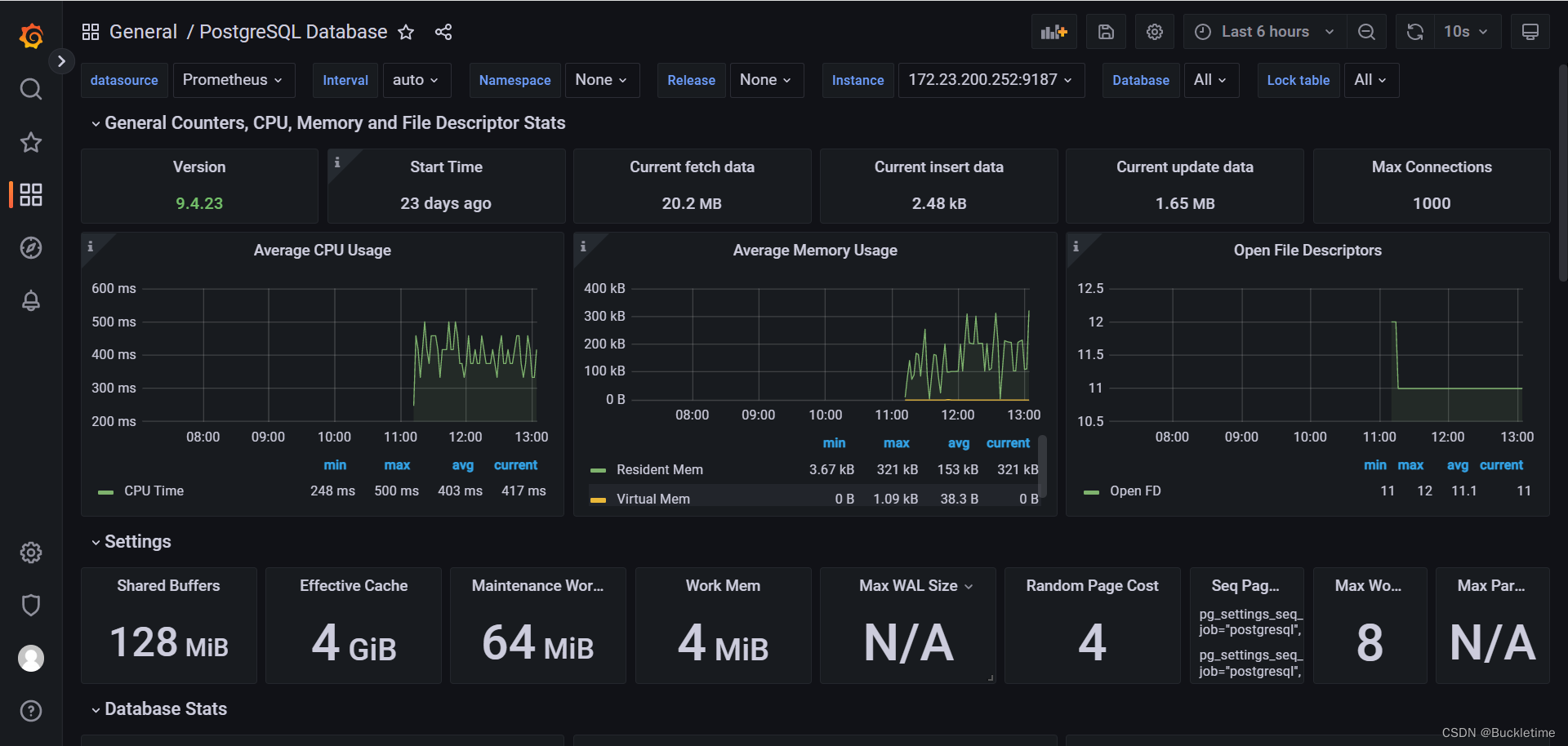
docker安装kafka-exporter
docker run --name kafka-exporter -d -p 9308:9308 danielqsj/kafka-exporter --kafka.server=10.1.7.33:9092 --zookeeper.server=10.1.7.33:2181
浏览器访问: http://ip:9308/metrics,收集到数据,有了它就可以做kafka数据展示了
修改prometheus.yml配置,增加kafka统计配置
- job_name: 'kafka'
static_configs:
- targets: ['10.1.7.33:9308']
重启prometheus
docker restart prometheus
导入Kafka模板,模板id为: 7589
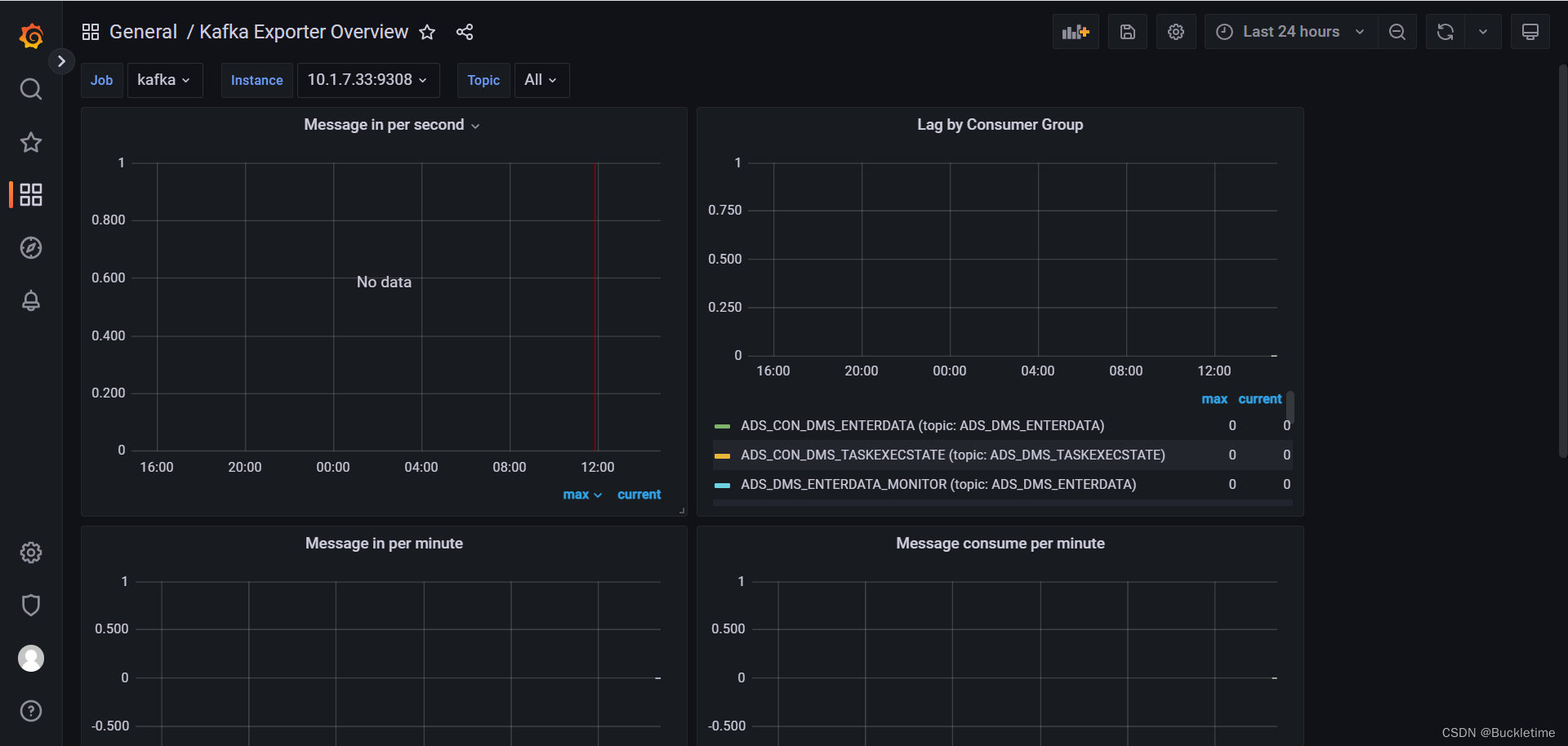
docker-compose启动elasticsearch-exporter
docker-compose.yml
version: "3.9"
services:
elasticsearch_exporter:
container_name: 'es_exporter'
image: prometheuscommunity/elasticsearch-exporter
command:
- '--es.uri=http://10.1.7.33:9200'
# 如果使用了身份验证 http://username:password@elasticsearch_address:9200
- '--es.all'
restart: always
ports:
- "9114:9114"
参数说明:
--es.uri 默认http://localhost:9200,连接到的Elasticsearch节点的地址(主机和端口)。 这可以是本地节点(例如localhost:9200),也可以是远程Elasticsearch服务器的地址
--es.all 默认flase,如果为true,则查询群集中所有节点的统计信息,而不仅仅是查询我们连接到的节点。
--es.cluster_settings 默认flase,如果为true,请在统计信息中查询集群设置
--es.indices 默认flase,如果为true,则查询统计信息以获取集群中的所有索引。
--es.indices_settings 默认flase,如果为true,则查询集群中所有索引的设置统计信息。
--es.shards 默认flase,如果为true,则查询集群中所有索引的统计信息,包括分片级统计信息(意味着es.indices = true)。
--es.snapshots 默认flase,如果为true,则查询集群快照的统计信息。
启动elasticsearch_exporter
docker-compose up -d
浏览器访问: http://ip:9114/metrics,收集到数据,有了它就可以做es数据展示了
修改prometheus.yml配置,增加elasticsearch统计配置
- job_name: 'elasticsearch'
static_configs:
- targets: ['10.1.7.33:9114']
重启prometheus
docker restart prometheus
导入elasticsearch模板,模板id为: 2322
这篇文章是继上一篇文章“Observability:从零开始创建Java微服务并监控它(一)”的续篇。在上一篇文章中,我们讲述了如何创建一个Javaweb应用,并使用Filebeat来收集应用所生成的日志。在今天的文章中,我来详述如何收集应用的指标,使用APM来监控应用并监督web服务的在线情况。源码可以在地址 https://github.com/liu-xiao-guo/java_observability 进行下载。摄入指标指标被视为可以随时更改的时间点值。当前请求的数量可以改变任何毫秒。你可能有1000个请求的峰值,然后一切都回到一个请求。这也意味着这些指标可能不准确,你还想提取最小/
是否可以在我的服务器上运行任何工具来监控多个Rails应用程序?我需要监控每个应用程序收到的请求数、每个应用程序使用了多少内存、使用了多少CPU以及其他类似的统计信息。我需要查看每个单独的Rails应用程序的统计信息。 最佳答案 我建议你试试NewRelicRPM.免费版:RPMLiteisthemostwidelyusedsolutionforbasicwebapplicationmonitoring.RPMLiteprovidesapplicationmonitoringforunlimitedJava,RubyorJRubya
我正在寻找一种方法来监视流上的事件,以便我可以确定是否有任何内容通过流。如果有,我将开始使用rtmpdump进行录制。我想象这是通过运行一个每60秒检查一次流的cron任务来实现的。如果它确定流正在通过,则调用rtmpdump开始记录它。如果没有,则什么都不做,并在60秒后再次检查。由于rtmpdump只是在没有流数据时出现错误,因此尝试使用它来监视流似乎不是一个好主意,但也许我错了。如果我在逐个案例的基础上手动执行此操作会很容易,但我正在尝试自动执行自动录制流的任务(如果它们可用)。有没有人遇到过这样做的方法?也许我可以在命令行(linux)中使用其他一些工具?如果有帮助,我正在使用
每5分钟(例如)ping20个网站的列表以了解该网站是否响应HTTP202的最佳方法是什么?最简单的想法是将20个URLS保存在数据库中,然后运行数据库并对每个URL执行ping操作。但是,当一个人不回答时会发生什么?之后的人会怎样?此外,是否有更好但更简单的解决方案?恐怕该列表会增长到20000个网站,然后没有足够的时间在我需要ping的5分钟内全部ping通它们。基本上,我是在描述PingDom、UptimeRobot等的工作原理。我正在使用node.js和RubyonRails构建这个系统。我也倾向于使用MongoDB来保存所有ping和监控结果的历史记录。建议?非常感谢!
我们有一个带有广泛管理部分的应用程序。我们对功能有点满意(就像您一样),并且正在寻找一些快速简便的方法来监控“谁使用什么”。理想情况下,一个简单的gem将允许我们在每个用户的基础上跟踪Controller/操作,以构建使用的功能和未使用的功能的图片。任何你会推荐的..谢谢主场 最佳答案 我不知道有什么流行的gem或插件可以解决这个问题;过去,我在ApplicationController中将这种审计实现为before_filter:从内存中:classApplicationControllercurrent_user,:contro
我有一堆长时间运行的Ruby脚本,我想确保每30秒左右运行一次。我通常通过简单地启动命令rubyscript-name.rb我如何配置monit来管理这些脚本?更新:我试着关注thismethodtocreateawrapperscript然后它会启动ruby进程,但它似乎没有创建.pid文件并且键入“./wrapper-scriptstop”什么也没做:/我应该在ruby中编写pid还是使用包装脚本来创建monit所需的pid? 最佳答案 MonitWiki有很多配置示例:http://mmonit.com/wiki/Mo
我们想设置自动化作业(通过Jenkins)以在第三方API出现故障或他们部署了不兼容的API时发出警报。我说的是针对真实的HTTPAPI进行测试,而不是模拟,但是因为我们已经使用rspec编写了模拟,所以我不确定我们是否应该通过编写两个独立的睾丸来重复这项工作。有人有这方面的经验吗?(如果其他工具可以提供帮助,我不限于Ruby/Rspec) 最佳答案 你看过VCR了吗??使用它,您可以“记录您的测试套件的HTTP交互并在未来的测试运行期间重播它们以进行快速、确定性、准确的测试”。在测试来自外部API的预期响应时,我将它与RSpec一
我正在使用Sidekiqworker在用户首次登录后完成对Facebook的一些请求。通常该任务大约需要20秒左右。我想在同步完成后立即使用ajax请求将一些信息加载到页面上,但不确定使用Javascript检查作业完成情况的最佳方式。一种可能性是配置Sidekiqworker在完成其余工作后设置cookie。然后我可以使用setTimeout函数在调用加载函数之前继续检查cookie。但我不确定这是否是最好的方法。我可以改用Redis吗? 最佳答案 Paul,最初你必须看一下这个PubSubonRailstutorial!当异步事
关闭。这个问题需要更多focused.它目前不接受答案。想改进这个问题吗?更新问题,使其只关注一个问题editingthispost.关闭7年前。Improvethisquestion使用哪个进行过程监控?为什么?
网络上是否有关于如何使用Monit监控delayed_job的示例??我能找到的所有东西都使用God,但我拒绝使用上帝,因为在Ruby中长时间运行的进程通常很糟糕。(上帝邮件列表中的最新帖子?GodMemoryUsageGrowsSteadily。)更新:delayed_job现在带有samplemonitconfig基于这个问题。 最佳答案 下面是我如何让它工作的。使用collectiveideaforkofdelayed_job除了积极维护之外,这个版本还有一个不错的script/delayed_job可以与monit一起使用的