先来看一个例子
有一张balance表:
需求:将tom的100块钱转到King账户中
执行的操作是:
update balance set money = money -100 where id = 100
update balance set money = money +100 where id = 200
这时,如果第一条语句执行成功,但第二条语句执行失败,就会出现问题。
这里引出一个需求,将多个dml语句(update,insert,delete)当做一个整体,要么全部成功,要么全部失败
--->使用事务来解决
事务用于保证数据的一致性,它由一组相关的dml语句(update,insert,delete)组成,该组的dml语句要么全部成功,要么全部失败。如:转账就要用事务来处理,用以保证数据的一致性。
当执行事务操作时(dml语句),mysql会在表上加锁,防止其他用户修改表的数据。这对用户来讲是非常重要的。
注意:当直接回退到保存点a时,会删除中间的保存点b
1.start transaction --开始一个事务
2.savepoint 保存点名 -- 设置保存点
3.rollback to 保存点名 -- 回退事务
4.rollback -- 回退全部事务
5.commit -- 提交事务,所有的操作生效,不能回退
细节:
在介绍回退事务前,先介绍一下保存点(savepoint)。保存点是事务中的点,用于取消部分事务,当结束事务时(commit),会自动地删除该事务所定义的所有保存点。
当执行回退事务时,通过指定保存点可以回退到指定的点
使用commit语句可以提交事务。当执行了commit语句之后,会确认事务的变化、结束事务、删除保存点、释放锁,数据生效。
当使用了commit语句结束事务之后,其它会话[其他连接] 可以查看到事务变化后的新数据 [所有的数据正式生效]
例子
-- 事务的演示操作
-- 1.创建一张测试表
CREATE TABLE t27(
id INT ,
`name` VARCHAR(32)
);
SELECT * FROM t27;
-- 2.开始事务
START TRANSACTION;
-- 3.设置保存点
SAVEPOINT a;
-- 4.执行dml操作1
INSERT INTO t27 VALUES(100,'tom');
-- 设置保存点b
SAVEPOINT b;
-- 执行dml操作2
INSERT INTO t27 VALUES(200,'jack');
-- 回退到b
ROLLBACK TO b
-- 继续回退a
ROLLBACK TO a
-- 如果是rollback,表示直接回退到事务开始的状态
ROLLBACK
COMMIT
例子
-- 讨论事务细节
-- 1. 如果不开始事务,默认情况下,dml操作是自动提交的,不能回滚
INSERT INTO t27 VALUES(300,'milan'); -- 自动提交 commit
SELECT * FROM t27;
-- 2. 如果开始一个事务,你没有创建保存点,也可以执行rollback,
-- 默认就是回到事务开始的状态
START TRANSACTION
INSERT INTO t27 VALUES(400,'king');
INSERT INTO t27 VALUES(500,'scott');
ROLLBACK -- 表示直接回退到事务开始的状态
COMMIT
-- 3. 可以在事务中(还没有提交时),创建多个保存点。
-- 比如:savepoint aaa;执行dml,savepoint bbb;
-- 4. 可以在事务没有提交前,选择回退到哪个保存点
-- 5. innodb的存储引擎支持事务,myisam不支持
-- 6. 开始一个事务的方式 start transaction或者set autocommit = off;
SET autocommit = off
概念:MySQL隔离级别定义了事务与事务之间的隔离程度
| MySQL隔离级别(4种) | 脏读 | 不可重复读 | 幻读 | 加锁读 |
|---|---|---|---|---|
| 读未提交(read uncommitted) | 会出现 | 会出现 | 会出现 | 不加锁 |
| 读已提交(read committed) | 不会出现 | 会出现 | 会出现 | 不加锁 |
| 可重复读(repeatable read) | 不会出现 | 不会出现 | 不会出现 | 不加锁 |
| 可串行化(serializable) | 不会出现 | 不会出现 | 不会出现 | 加锁 |
可重复读实际上会发生幻读?
MySQL的事务隔离级别--案例
我们举例一个案例来说明mysql的事务隔离级别。以account表进行操作为例。(id、name、money)
开启两个mysql的控制台
查看当前mysql的隔离级别,均为可重复读
mysql> select @@tx_isolation;
+-----------------+
| @@tx_isolation |
+-----------------+
| REPEATABLE-READ |
+-----------------+
1 row in set (0.00 sec)
将其中一个连接的隔离级别设置为 read uncommitted(读未提交)
-- 把其中一个控制台的隔离级别设置为read uncommitted
SET SESSION TRANSACTION ISOLATION LEVEL READ UNCOMMITTED

此时的情况:左边的隔离级别为读未提交;右边的隔离级别为可重复读
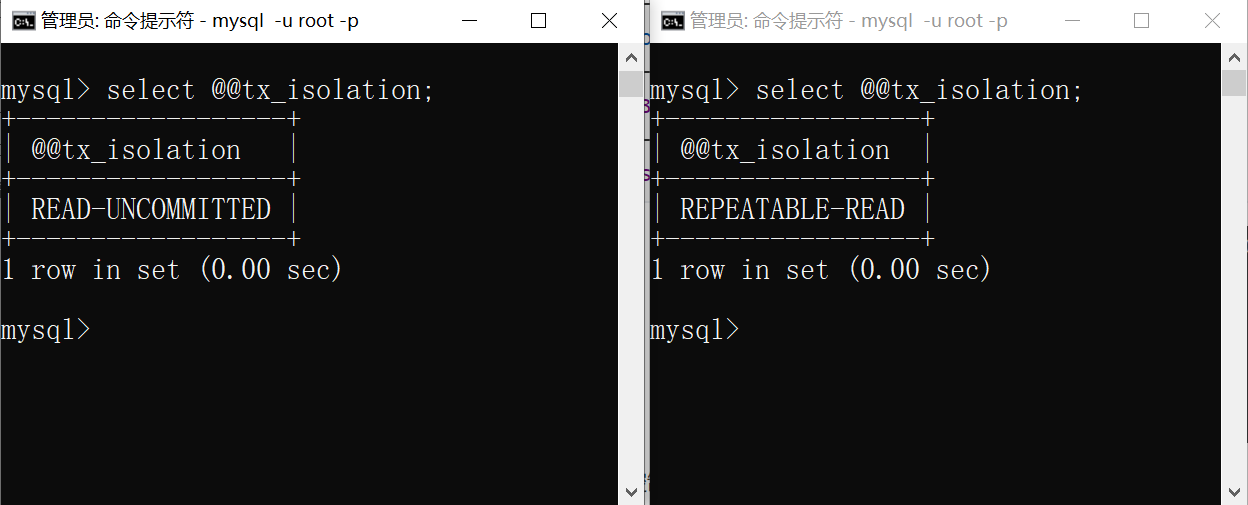
然后两边都开启事务

在两个连接控制台中选择数据库,在隔离级别为 可重复读 的连接中 创建表account
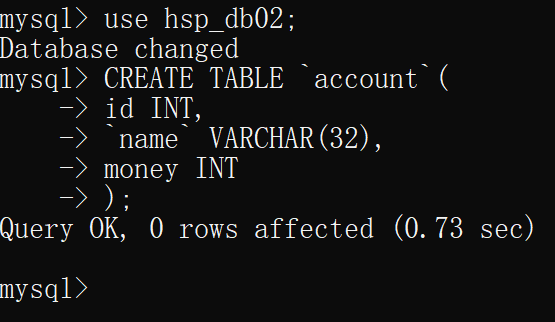
再在隔离级别为 可重复读 的连接中插入一条数据(但未提交)
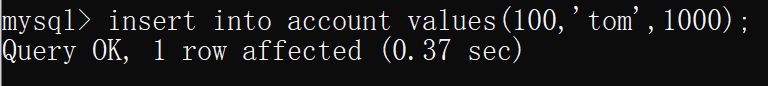
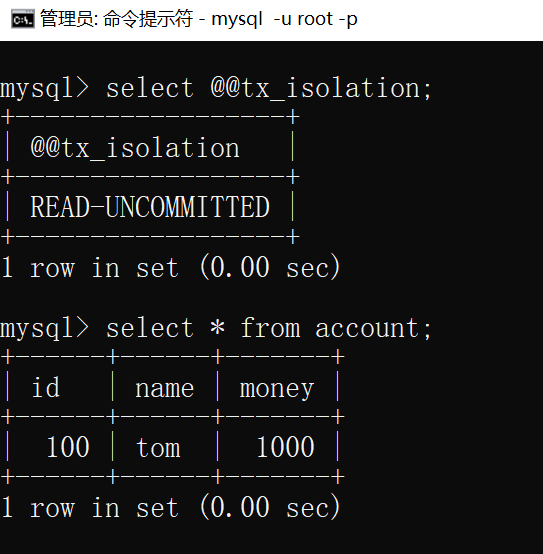
在另一个连接(隔离级别为 读未提交 READ-UNCOMMITTED)中查询该表,发现可以查询到另一事务尚未提交的插入的数据,这时就发生了脏读
脏读:当一个事务读取另一个事务尚未提交的改变(delete,insert,update)时,产生脏读
在隔离级别为 可重复读 的连接中更新一条数据,同时插入一条数据,然后提交commit
此时在另一个连接(隔离级别为 读未提交)中,查询同一张表,可以看到在这个(隔离级别为 读未提交的)连接中,已经可以看到另一个事务中提交的数据
即一个事务的操作影响了另一个事务的查询,这时候就发生了不可重复读和幻读
这将会导致,当有多个连接开启事务时,某一连接的事务的查询会受到其他所有连接的事务的影响,这无疑将会导致混乱
最佳情况应该是:一个连接 连接到数据库,操作account表的时候,希望看到的数据应该是,开启事务的这一时刻的数据
在连接(隔离级别为 读未提交)中提交commit结束一个事务,此时两个连接中的事务均已结束
例子
在上个例子开启的两个连接中,将其中一个连接的隔离级别修改为 读已提交,
另一个保持隔离级别为可重复读
两边都开启事务
在隔离级别为可重复读的连接中插入一条数据
然后在隔离级别为读已提交的连接中 插询表account,可以看到查询到的数据还是本连接开启事务时的数据
即,读已提交的隔离级别不会出现脏读现象
在隔离级别为可重复读的连接中更新一条数据
然后在隔离级别为读已提交的连接中 插询表account,可以看到查询到的数据变成了其他连接的事务提交的 数据,说明,在隔离级别为读已提交下,出现了不可重复读和幻读
重新开启两个连接,两个连接的隔离级别均为可重复读
然后两边均开启事务

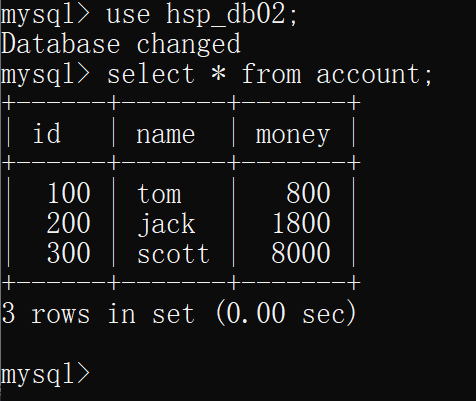
在一个连接中选择数据库,然后在account表中插入一条数据,再更新一条数据(未提交)
此时该连接中的表情况为:
在另一个连接中选择数据库,查询表account,可以看到查询到的表数据依旧是开启事务时的样子,没有受到其他事务的影响,即没有产生脏读
在原先修改数据的连接中输入commit提交

在另一个连接中再查询表account,可以看到数据依旧是开启事务的时刻的样子
即,没有产生不可重复读和幻读
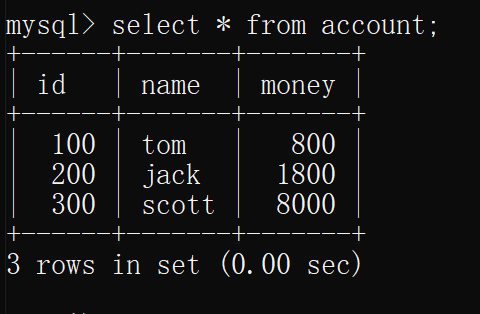
综上,隔离级别为可重复读的情况下 既不会出现脏读,也不会出现不可重复读和幻读
将上面两个连接其中一个重新启动,将新连接设置隔离级别为可串行化(serializable)

此时两个连接的隔离级别分别为 可重复读 和可串行化(serializable)
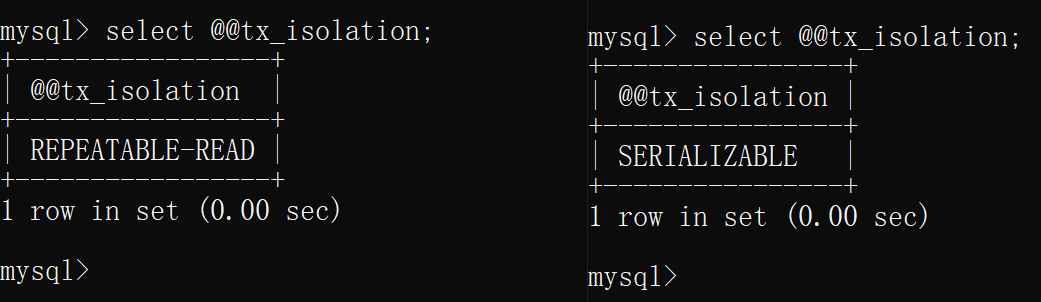
这时分别在两个连接中均开启事务

在隔离级别为可重复读的连接中分别插入、更新数据(未提交)
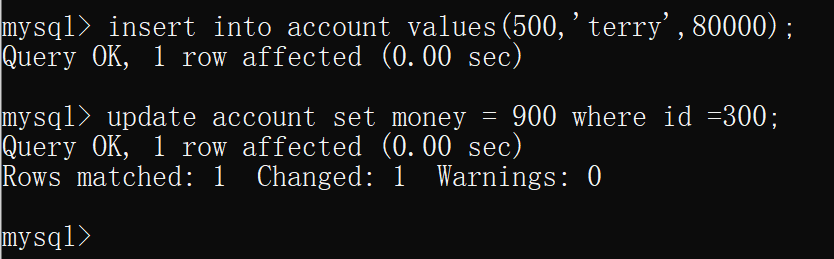
在另一个隔离级别为可串行化的连接中选择数据库。然后查询表account,回车时会发现卡住了,这是因为 可串行化会加锁
A连接在操作表的时候,事务还没有结束,这时B连接也尝试操作该表,此时将会检查A的事务有没有结束,如果没有结束,B连接的操作就会进行等待,直到A连接的事务提交
这时,在隔离级别为可重复读的连接中提交事务

可以看到可串行化级别的连接中可以成功操作表了
综上说明,可串行化级别下,不仅不会出现脏读、不可重复读、幻读,还会加锁读
查看当前会话隔离级别
select @@tx_isolation;
查看系统当前隔离级别
select @@global.tx_isolation;
设置当前会话隔离级别
SET SESSION TRANSACTION ISOLATION LEVEL 隔离级别;
设置系统当前隔离级别
SET global TRANSACTION ISOLATION LEVEL 隔离级别;
mysql默认的事务隔离级别是repeatable read,一般情况下,没有特殊要求,没有必要修改(因为该隔离级别满足绝大部分项目要求)
[mysqld]
transaction-isolation = 隔离级别;
然后重启mysql服务即可
原子性(Atomicity)
原子性是指事务是一个不可分割的工作单位,事务中的操作要么都发生,要么都不发生。
一致性(Consistency)
事务必须使数据库从一个一致性状态变换到另一个一致性状态
隔离性(Isolation)
事务的隔离性是多个用户并发访问数据库时,数据库为每一个用户开启的事务,不能被其他事务的操作数据所干扰,多个并发事务之间要相互隔离。
持久性(Durability)
持久性是指一个事务一旦被提交,它对数据库中数据的改变就是永久性的,接下来即使数据库发生故障也不应该对其有任何影响。
登录mysql控制客户端A,创建表dog(id,name),开启一个事务,添加两条记录
登录mysql控制客户端B,开启一个事务,设置为读未提交
A客户端修改Dog一条记录,不要提交。看看B客户端是否看到变化,说明什么问题?
答:B客户端可以看到A客户端的修改数据,说明在读未提交的隔离级别下,出现了脏读现象
登录mysql客户端C,开始一个事务,设置为读已提交,这时A客户修改一条记录,不要提交,看看C客户端是否看到变化,说明什么问题?
答:C客户端不能看到A客户端的修改数据,说明在读已提交的隔离级别下,不会出现脏读现象
我发现ActiveRecord::Base.transaction在复杂方法中非常有效。我想知道是否可以在如下事务中从AWSS3上传/删除文件:S3Object.transactiondo#writeintofiles#raiseanexceptionend引发异常后,每个操作都应在S3上回滚。S3Object这可能吗?? 最佳答案 虽然S3API具有批量删除功能,但它不支持事务,因为每个删除操作都可以独立于其他操作成功/失败。该API不提供任何批量上传功能(通过PUT或POST),因此每个上传操作都是通过一个独立的API调用完成的
我有一个涉及多台机器、消息队列和事务的问题。因此,例如用户点击网页,点击将消息发送到另一台机器,该机器将付款添加到用户的帐户。每秒可能有数千次点击。事务的所有方面都应该是容错的。我以前从未遇到过这样的事情,但一些阅读表明这是一个众所周知的问题。所以我的问题。我假设安全的方法是使用两阶段提交,但协议(protocol)是阻塞的,所以我不会获得所需的性能,我是否正确?我通常写Ruby,但似乎Redis之类的数据库和Rescue、RabbitMQ等消息队列系统对我的帮助不大——即使我实现某种两阶段提交,如果Redis崩溃,数据也会丢失,因为它本质上只是内存。所有这些让我开始关注erlang和
文章目录一、概述简介原理模块二、配置Mysql使用版本环境要求1.操作系统2.mysql要求三、配置canal-server离线下载在线下载上传解压修改配置单机配置集群配置分库分表配置1.修改全局配置2.实例配置垂直分库水平分库3.修改group-instance.xml4.启动监听四、配置canal-adapter1修改启动配置2配置映射文件3启动ES数据同步查询所有订阅同步数据同步开关启动4.验证五、配置canal-admin一、概述简介canal是Alibaba旗下的一款开源项目,Java开发。基于数据库增量日志解析,提供增量数据订阅&消费。Git地址:https://github.co
我看到其他人也遇到过类似的问题,但没有一个解决方案对我有用。0.3.14gem与其他gem文件一起存在。我已经完全按照此处指示完成了所有操作:https://github.com/brianmario/mysql2.我仍然得到以下信息。我不知道为什么安装程序指示它找不到include目录,因为我已经检查过它存在。thread.h文件存在,但不在ruby目录中。相反,它在这里:C:\RailsInstaller\DevKit\lib\perl5\5.8\msys\CORE\我正在运行Windows7并尝试在Aptana3中构建我的Rails项目。我的Ruby是1.9.3。$gemin
我已经开始使用mysql2gem。我试图弄清楚一些基本的事情——其中之一是如何明确地执行事务(对于批处理操作,比如多个INSERT/UPDATE查询)。在旧的ruby-mysql中,这是我的方法:client=Mysql.real_connect(...)inserts=["INSERTINTO...","UPDATE..WHEREid=..",#etc]client.autocommit(false)inserts.eachdo|ins|beginclient.query(ins)rescue#handleerrorsorabortentirelyendendclient.commi
保存成功后可以回滚吗?让我有一个带有属性名称、电子邮件等的用户模型。例如u=User.newu.name="test_name"u.email="test@email.com"u.save现在记录将成功保存在数据库中,之后我想回滚我的事务(不是销毁或删除)。有什么想法吗? 最佳答案 您可以通过交易来做到这一点,请参阅http://markdaggett.com/blog/2011/12/01/transactions-in-rails/例子:User.transactiondoUser.create(:username=>'Nemu
我有一个任务列表(名称、starts_at),我试图在每日View中显示它们(就像iCal)。deftodays_tasks(day)Task.find(:all,:conditions=>["starts_atbetween?and?",day.beginning,day.ending]end我不知道如何将Time.now(例如“2009-04-1210:00:00”)动态转换为一天的开始(和结束),以便进行比较。 最佳答案 deftodays_tasks(now=Time.now)Task.find(:all,:conditio
什么是0day漏洞?0day漏洞,是指已经被发现,但是还未被公开,同时官方还没有相关补丁的漏洞;通俗的讲,就是除了黑客,没人知道他的存在,其往往具有很大的突发性、破坏性、致命性。0day漏洞之所以称为0day,正是因为其补丁永远晚于攻击。所以攻击者利用0day漏洞攻击的成功率极高,往往可以达到目的并全身而退,而防守方却一无所知,只有在漏洞公布之后,才后知后觉,却为时已晚。“后知后觉、反应迟钝”就是当前安全防护面对0day攻击的真实写照!为了方便大家理解,中科三方为大家梳理当前安全防护模式下,一个漏洞从发现到解决的三个时间节点:T0:此时漏洞即0day漏洞,是已经被发现,还未被公开,官方还没有相
我正在尝试绕过rails配置这个极其复杂的迷宫。到目前为止,我设法在ubuntu上设置了rvm(出于某种原因,ruby在ubuntu存储库中已经过时了)。我设法建立了一个Rails项目。我希望我的测试项目使用mysql而不是mysqlite。当我尝试“rakedb:migrate”时,出现错误:“!!!缺少mysql2gem。将其添加到您的Gemfile:gem'mysql2'”当我尝试“geminstallmysql”时,出现错误,告诉我需要为安装命令提供参数。但是,参数列表很大,我不知道该选择哪些。如何通过在ubuntu上运行的rvm和mysql获取rails3?谢谢。
ruby1.9.3dev(2011-09-23修订版33323)[i686-linux]轨道3.0.20最近为什么在与DateTimeonRails相关的RSpecs项目上工作我发现在给定日期以下语句发出的值date.end_of_day.to_datetime和date.to_datetime.end_of_day虽然它们表示相同的日期时间,但比较时返回false。为了确认这一点,我打开了Rails控制台并尝试了以下操作1.9.3dev:053>monday=Time.now.monday=>2013-02-2500:00:00+05301.9.3dev:054>monday.cla