目录
原创声明:本创作是本人的原创内容,未经授权及禁止肆意转载。此外并未与任何机构合作,原创不易,尊重原创
调度系统在数据处理流程中开箱即用。
|
| DolphinScheduler | Azkaban | Oozie |
| 定位 | 解决数据处理流程中错综复杂的依赖关系 | 为了解决Hadoop的任务依赖关系问题 | 管理Hdoop作业(job)的工作流程调度管理系统 |
| 任务类型支持 | 支持传统的shell任务,同时支持大数据平台任务调度:MR、Spark、SQL(mysql、postgresql、hive/sparksql)、python、procedure、sub_process | ommand、HadoopShell、Java、HadoopJava、Pig、Hive等,支持插件式扩展 | 统一调度hadoop系统中常见的mr任务启动、Java MR、Streaming MR、Pig、Hive、Sqoop、Spark、Shell等 |
| 可视化流程定义 | 所有流、定时操作都是可视化的,通过拖拽来绘制DAG,配置数据源及资源,同时对于第三方系统,提供api方式的操作。 | 通过自定义DSL绘制DAG并打包上传 | 配置相关的调度任务复杂,依赖关系、时间触发、事件触发使用xml语言进行表达 |
| 任务监控支持 | 任务状态、任务类型、重试次数、任务运行机器、可视化变量,以及任务流执行日志 | 只能看到任务状态 | 任务状态、任务类型、任务运行机器、创建时间、启动时间、完成时间等。 |
| 暂停/恢复/补数 | 支持暂停、恢复 补数操作 | 只能先将工作流杀死在重新运行 | 支持启动/停止/暂停/恢复/重新运行:支持启动/停止/暂停/恢复/重新运行: Oozie支持Web,RestApi,Java API操作 |
| 高可用支持 | 支持HA,去中心化的多Master和多Worker | 通过DB支持HA,-但Web Server存在单点故障风险 | 通过DB支持HA |
| 多租户支持 | dolphinscheduler上的用户可以通过租户和hadoop用户实现多对一或一对一的映射关系。无法做到细节的权限管控。 | —— | —— |
| 过载处理能力 | 任务队列机制,单个机器上可调度的任务数量可以灵活配置,当任务过多时会缓存在任务队列中,不会操作机器卡死 | 任务太多时会卡死服务器 | 调度任务时可能出现死锁 |
| 集群扩展支持 | 调度器使用分布式调度,整体的调度能力会随集群的规模线性正常,Master和Worker支持动态上下线,可以自由进行配置 | 只Executor水平扩展 | 参照集群标准 |
| 文件管理 | 支持,可视化管理文件,及相关udf函数等。 | —— | —— |
| 邮件报警 | 支持 | 支持 | 支持 |
| 权限控制 | 可以通过对用户进行资源、项目、数据源的访问授权 | —— | —— |
| 版本更新迭代 | 持续发展中,升级不会影响当前集群,升级方式操作简单 | —— | 依赖当前集群版本,如更新最新版,易于现阶段集群不兼容 |
安装部署文档使用的dolphinscheduler版本为1.3.8,如需升级至最新版2.0以上版本可参照官网升级操作。upgrade
MySQL5.7以上
JDK1.8
zookeeper
Python
其余配置要求参照官网内容即可。
0.下载安装包
可以在官网下载安装包(https://dolphinscheduler.apache.org/zh-cn/download/download.html)此处选择1.3.8版本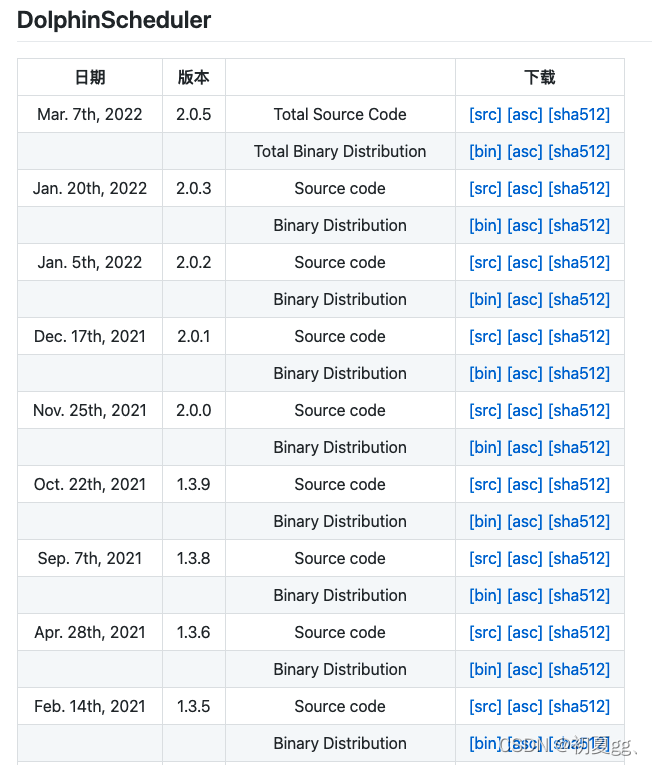
1)点开根目录下的pom文件,修改里面的集群版本信息,修改为现有集群的信息。
主要修改集群版本、Hadoop及hive版本信息
<hadoop.version>2.X.0</hadoop.version>
<hive.jdbc.version>3.X.0</hive.jdbc.version>
<version>1.3.1-cdh5.XX.X</version>-------可改可不改
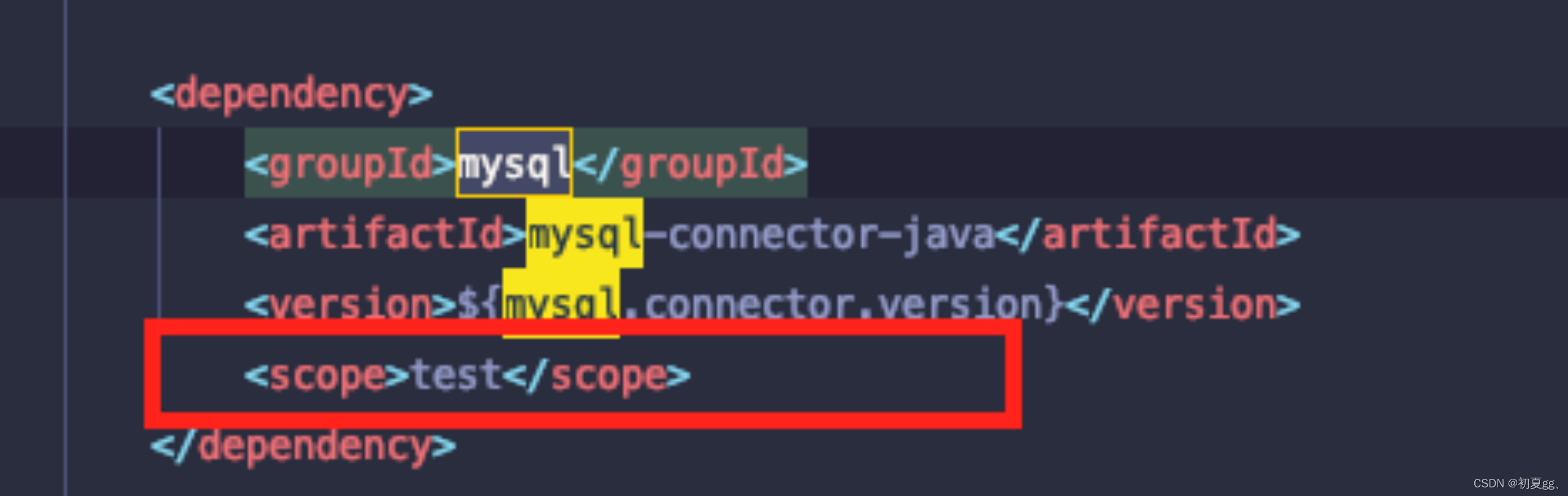
2)去除MySQL包的scope
3) 编译
可以通过服务器进行编译,也可以通过idea编译。
mvn -U clean package -Prelease -Dmaven.test.skip=true
编译后的包如下:
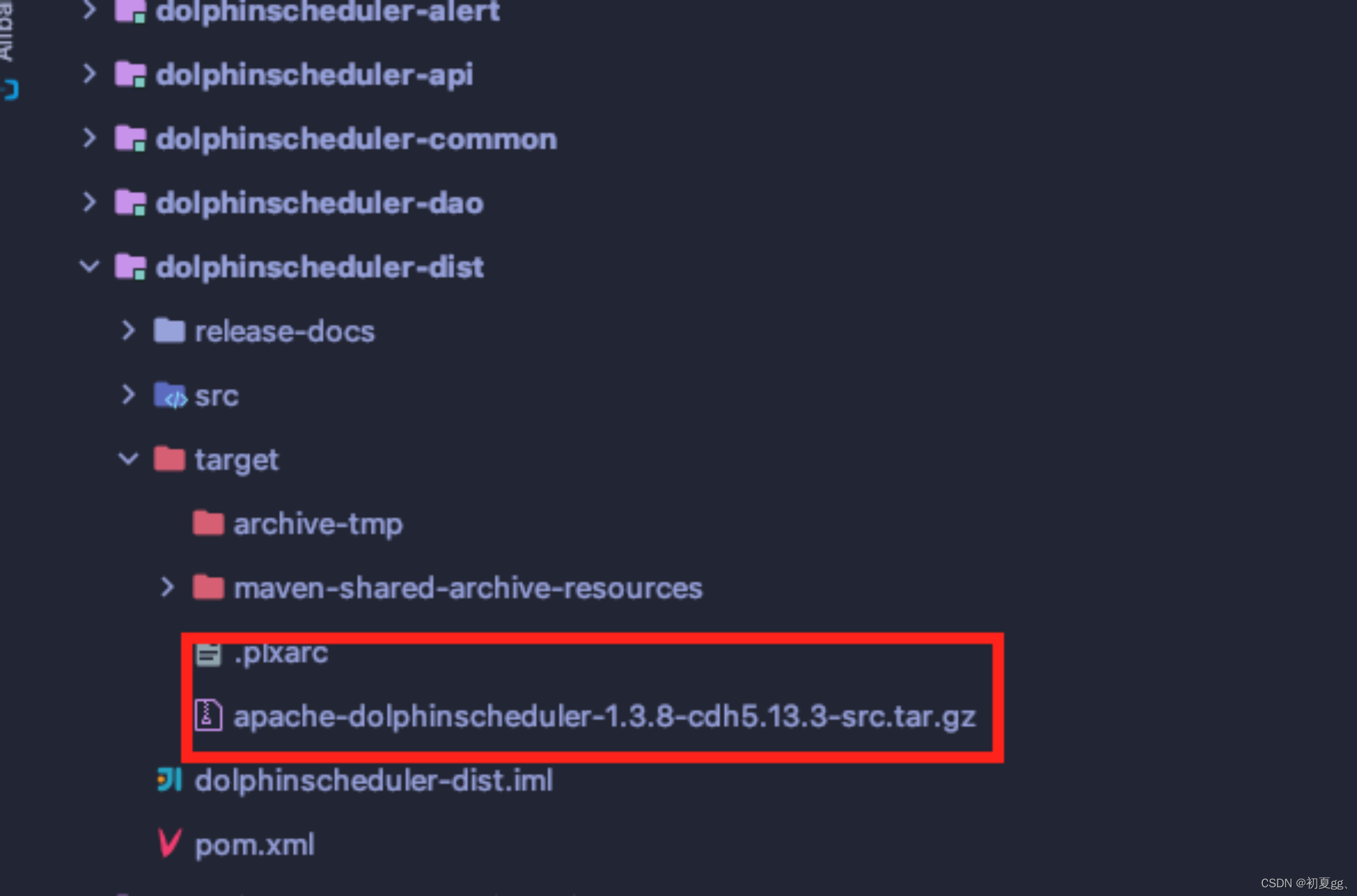
4)将安装包上传至服务器相关目录解压。
tar -zxvf apache-dolphinscheduler-1.3.8-cdh5.13.3-src.tar.gz
修改文件夹权限
chmod -R 755 apache-dolphinscheduler-1.3.8-cdh5.13.3-src
chown -R root:root apache-dolphinscheduler-1.3.8-cdh5.13.3-src
5)使用高权限用户(建议直接使用root),并配置ssh免密。
6)创建dolphinscheduler元数据库-MySQL(用户名及密码可以进行修改)
CREATE DATABASE dolphinscheduler DEFAULT CHARACTER SET utf8 DEFAULT COLLATE utf8_general_ci;
CREATE USER 'dscheduler'@'%' IDENTIFIED BY 'dscheduler';
GRANT ALL PRIVILEGES ON dolphinscheduler.* TO 'dscheduler'@'%' IDENTIFIED BY 'dscheduler';
flush privileges;
7)初始化数据库连接
vi apache-dolphinscheduler-1.3.8-cdh5.13.3-src/conf/datasource.properties
spring.datasource.driver-class-name=com.mysql.jdbc.Driver spring.datasource.url=jdbc:mysql://MySQL连接名:3306/dolphinscheduler?useUnicode=true&characterEncoding=UTF-8&allowMultiQueries=true
spring.datasource.username=dscheduler
spring.datasource.password=dscheduler
注意:需将postgresql模块屏蔽,将MySQL模块打开,修改MySQL模块信息。
8)在ds的安装目录下执行数据库初始化脚本
./script/create-dolphinscheduler.sh
9)配置ds所需的环境变量
vi apache-dolphinscheduler-1.3.8-cdh5.13.3-src/conf/env/dolphinscheduler_env.sh
注:根据集群上具有的环境进行配置,无用的建议屏蔽掉,也可进行删除。
10)修改配置文件conf/config/install_config.conf相关参数,以下为参考,详细可见配置文件均有标识。
# --------# INSTALL MACHINE# --------#
#因为是在单节点上部署master、worker、API server,所以服务器的IP均为机器IP或者localhost ips="localhost"
masters="localhost"
workers="localhost:default"
alertServer="localhost"
apiServers="localhost"
# DolphinScheduler安装路径,如果不存在会创建
installPath="~/dolphinscheduler"
# 部署用户,填写在 **配置用户免密及权限** 中创建的用户
deployUser="dolphinscheduler"
# -----------------# DolphinScheduler ENV# --------------#
#JAVA_HOME 的路径,是在 **前置准备工作** 安装的JDK中 JAVA_HOME 所在的位置 javaHome="/your/java/home/here"
# ----------------# Database# ---------------------#
#数据库的类型,用户名,密码,IP,端口。其中dbtype目前支持 mysql 和 postgresql
dbtype="mysql" dbhost="localhost:3306"
# 如果你不是以 dolphinscheduler/dolphinscheduler 作为用户名和密码的,需要进行修改 username="dolphinscheduler"
password="dolphinscheduler"
dbname="dolphinscheduler"
# ----------------------# Registry Server# -----------------#
#注册中心地址,zookeeper服务的地址
registryServers="localhost:2181"
11)添加集群配置文件
12)一键部署
sh install.sh
13) 进程检查
LoggerServer
WorkerServer
MasterServer
14) 服务启停
# 一键停止 sh ./bin/stop-all.sh
# 一键开启 sh ./bin/start-all.sh
# 启停master
sh ./bin/dolphinscheduler-daemon.sh start master-server
sh ./bin/dolphinscheduler-daemon.sh stop master-server
# 启停worker
sh ./bin/dolphinscheduler-daemon.sh start worker-server
sh ./bin/dolphinscheduler-daemon.sh stop worker-server
# 启停api-server
sh ./bin/dolphinscheduler-daemon.sh start api-server
sh ./bin/dolphinscheduler-daemon.sh stop api-server
# 启停logger
sh ./bin/dolphinscheduler-daemon.sh start logger-server
sh ./bin/dolphinscheduler-daemon.sh stop logger-server
# 启停alert
sh ./bin/dolphinscheduler-daemon.sh start alert-server
sh ./bin/dolphinscheduler-daemon.sh stop alert-server
15)前端访问(红色标记为替换实际内容)
apiserver:12345/dolphinscheduler
账户:admin
密码:dolphinscheduler123
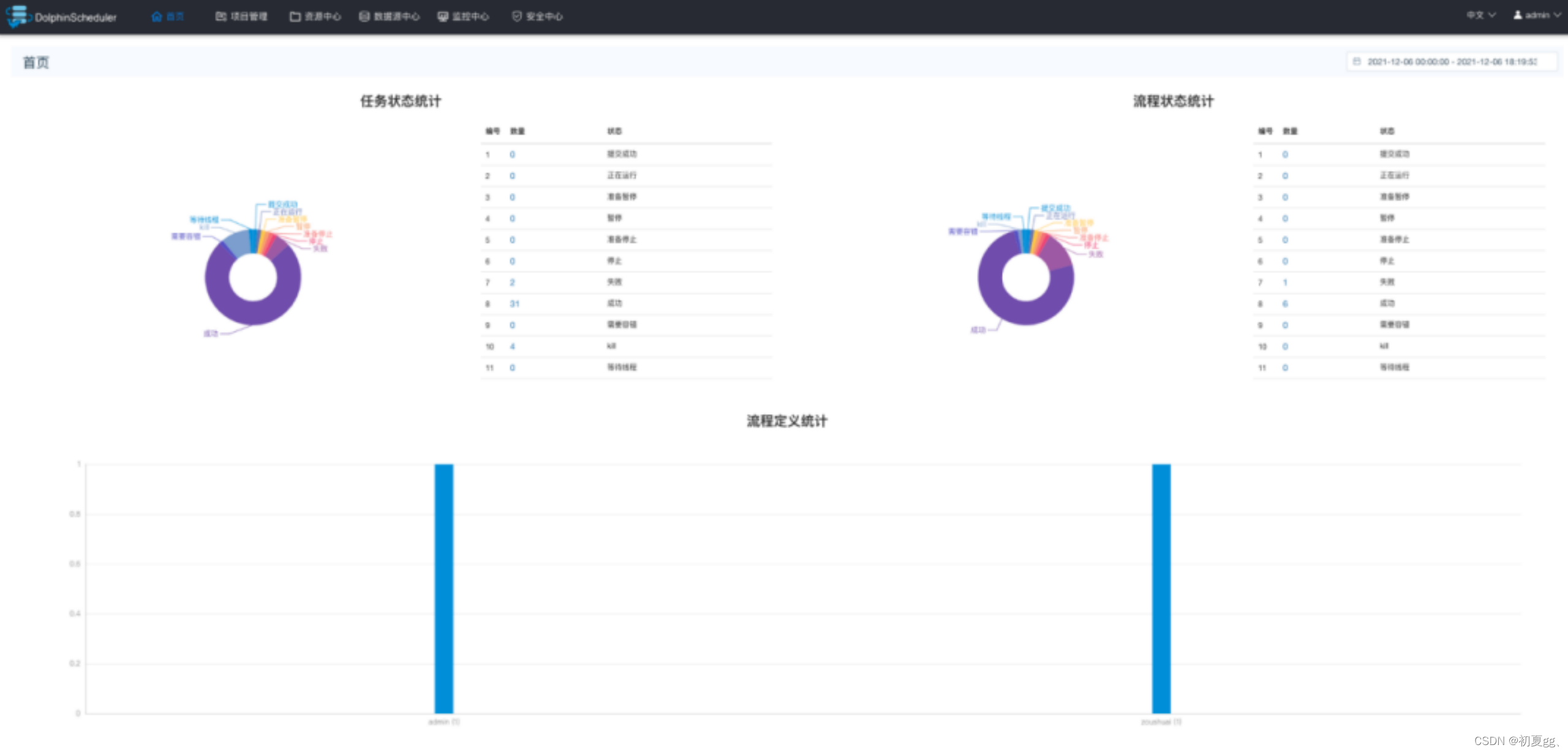
首页包含用户所有项目的任务状态统计、流程状态统计、工程流定义统计。
点击项目管理模块下的创建项目进行项目创建。

项目管理包括以下模块:项目首页、工作流(工作流定义、工作流实例、任务实例)

4.1.2.1 项目首页
4.1.2.2 工作流定义
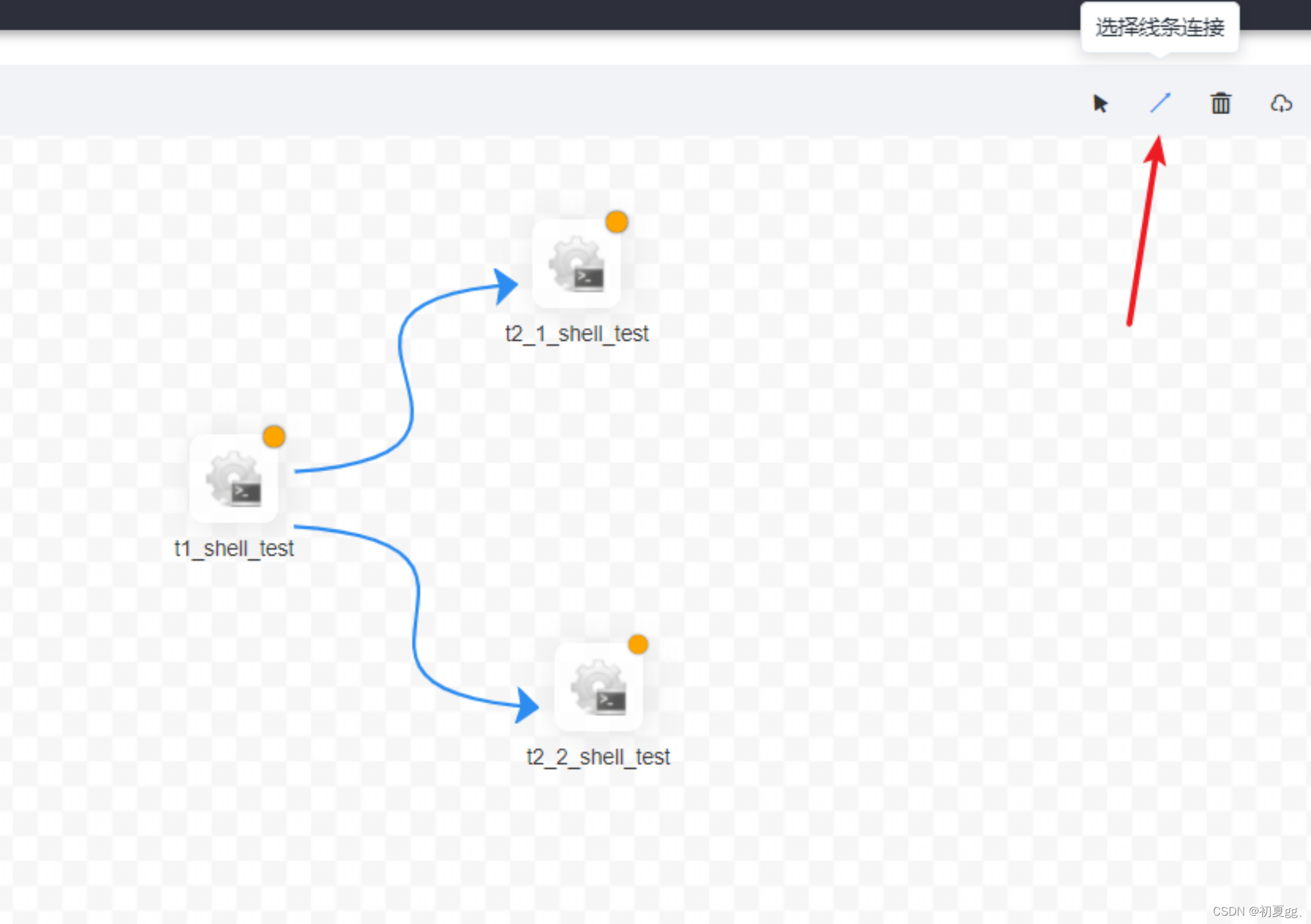
工作流定义可以在画板中创建任务的执行流程,此处以shell任务为例。配置如下:

点击连接线添加任务依赖关系:
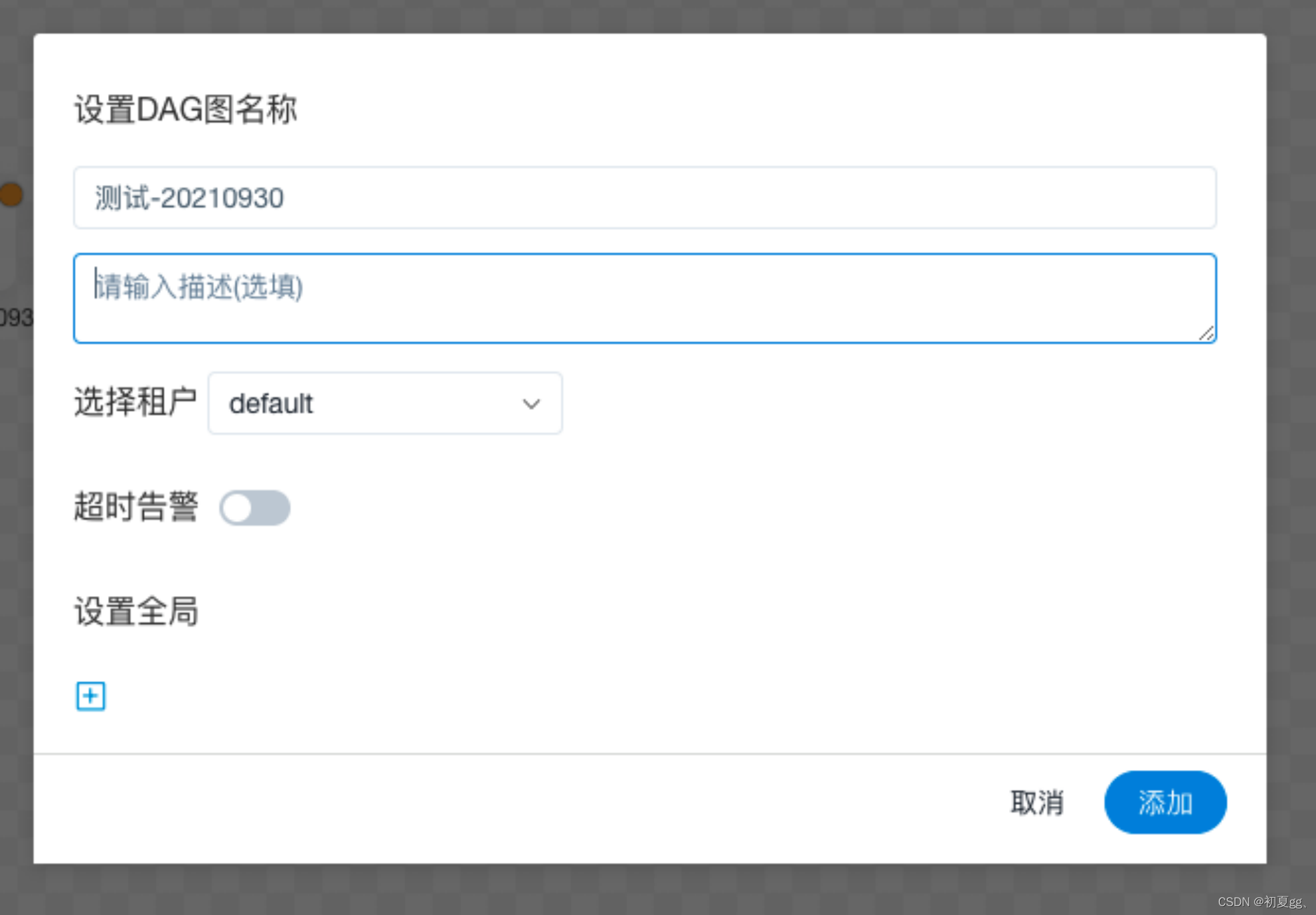
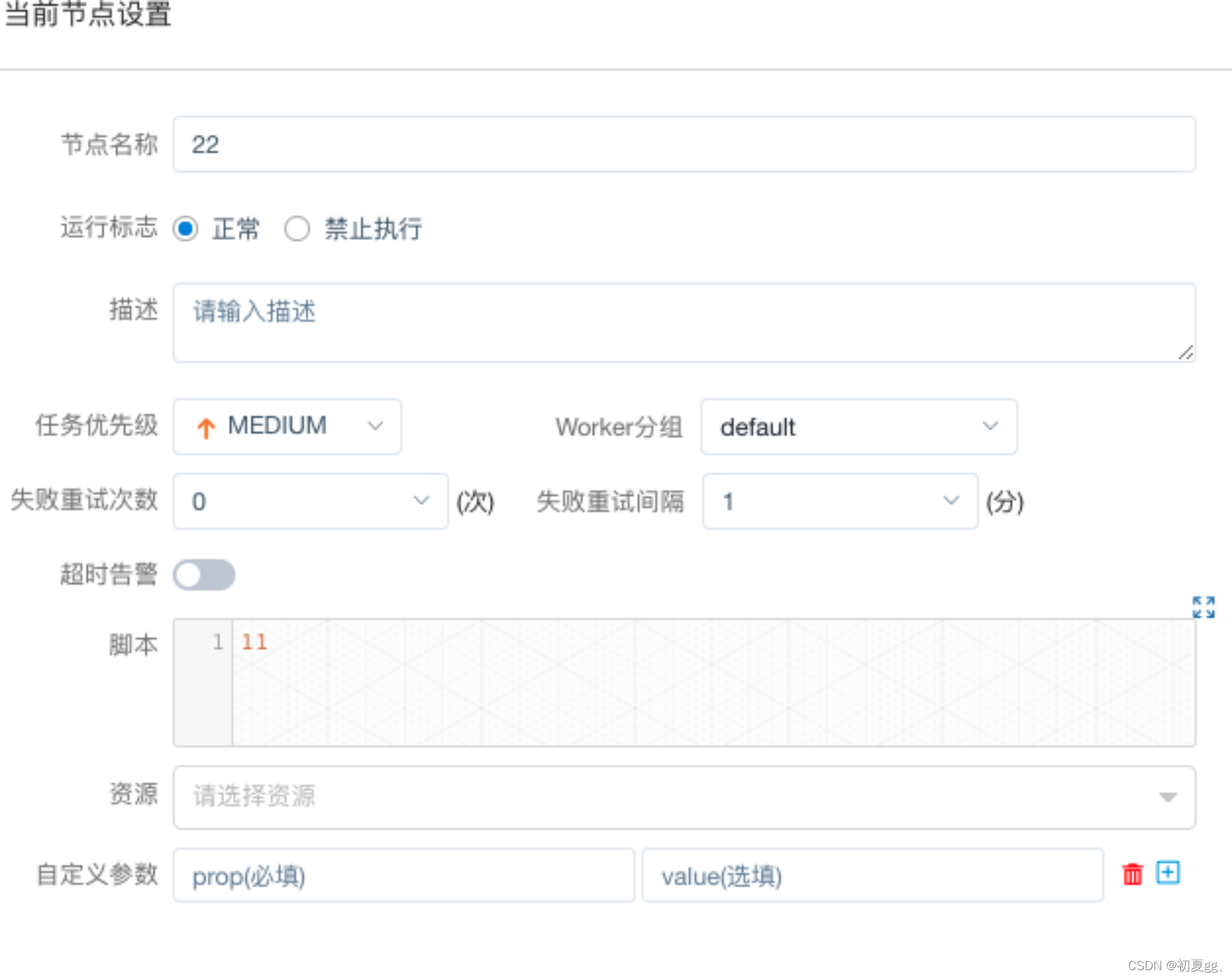
当任务实例定义完成后,点击保存,设置相关参数:
完成以上操作即成功创建一个工作流,可以对工作流进行编辑、上下线、添加定时任务、查看属性图等操作。
步骤中涉及到的一些名词解释:
正常:运行工作流时正常执行该任务
禁止执行:运行工作流不会执行该任务
资源中心 ->文件管理页面
创建或上传的文件,如文件名为
test.sh
,脚本中调用资源命令为
sh test.sh(如果脚本是在相应创建目录下,则应带入文件夹名称。)例如:创建test.sh在文件夹test_2021下,调用资源命令为sh test/test.sh
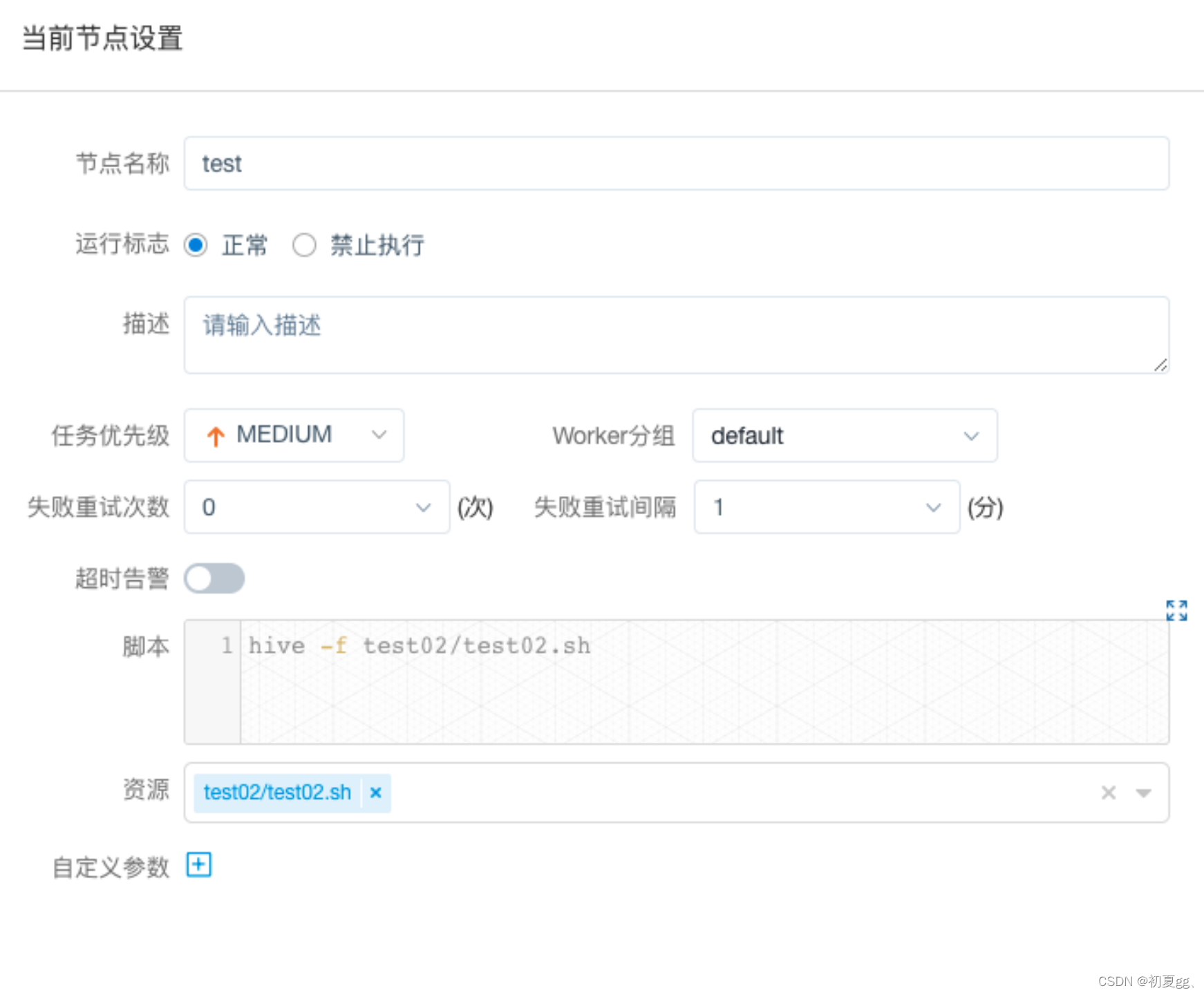
在操作工作流时注意:
当工作流上线后可以手动运行或定时运行。当工作流开始运行,工作流实例页面回生成一条工作流实例。
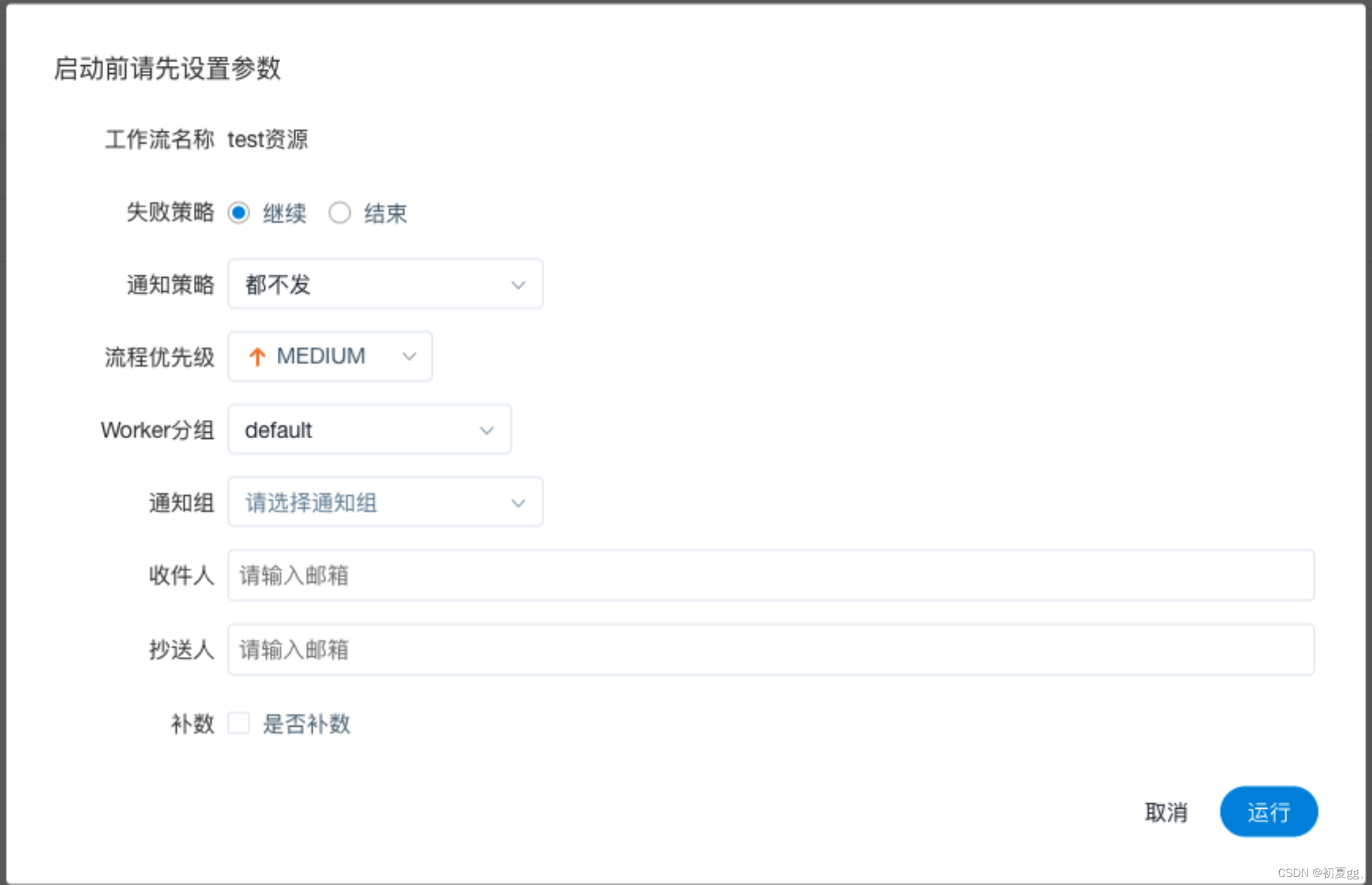
工作流运行参数说明:
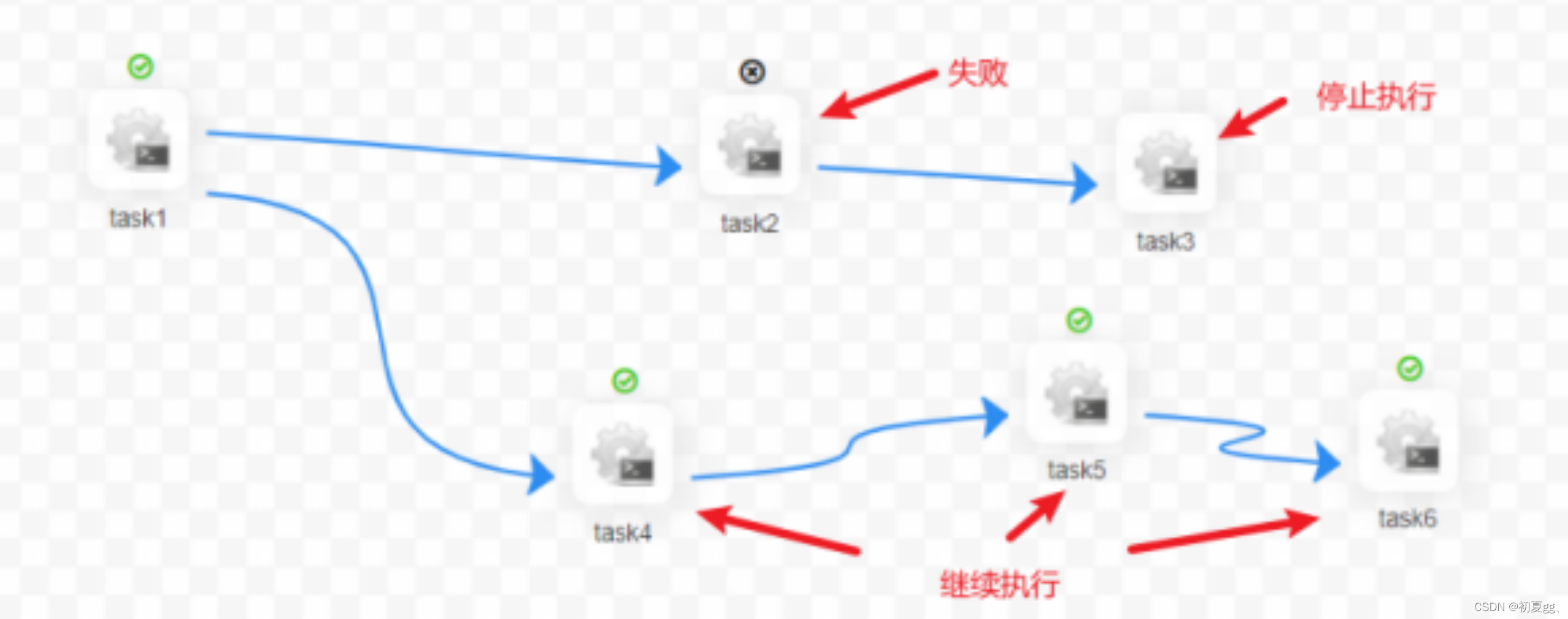
结束:终止所有正在执行的任务,并终止整个流程。
当 master 线程数不足时,级别高的流程在执行队列中会优先执行,相同优先级的流程按照先进先出的顺序执行。
注:
补数目前只支持针对连续的天进行补数,比如需要补 11月1号 到 11月10号 的数据:

工作流完成上线操作后可以设置定时运行。
点击定时按钮,选择起止时间。在起止时间范围内,定时运行工作流;不在起止时间范围内,不再产生定时工作流实例。例如配置自 2020-09-01 到 2020-09-30,每 10分钟 运行一次,设置通知策略为失败发,并添加告警组,此处配置示例如下:
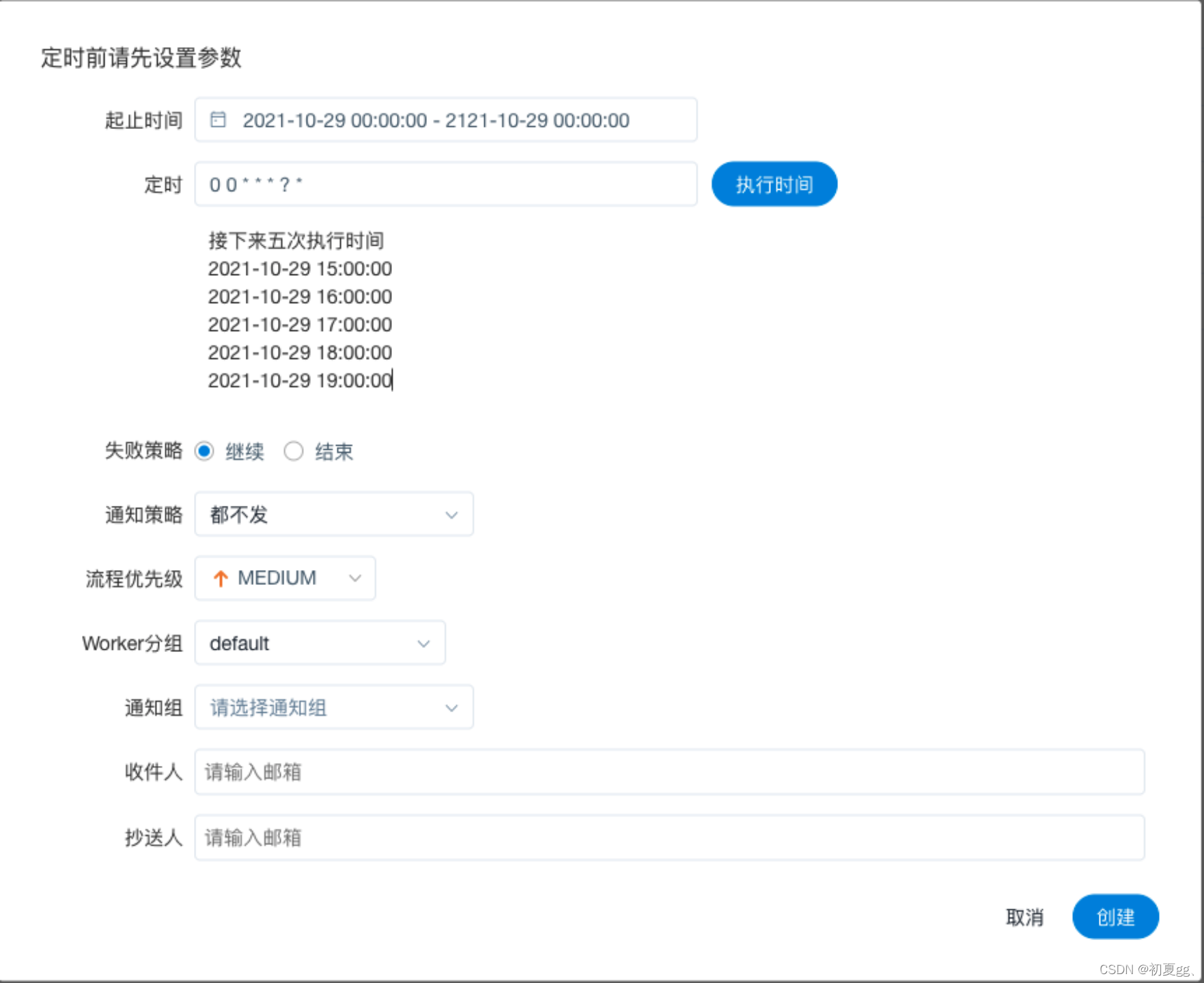
点击 "创建" 按钮,创建定时成功,此时定时状态为 "下线",定时需上线才生效。
点击 "定时管理" 按钮

点击 "上线" 按钮,工作流定时生效。

定时上线成功。

当状态、定时状态都为上线时,代表任务流可以按时调度。
注意:当将工作流下线后,定时任务调度会跟着下线,而再次上线工作流时,里面定时任务调度不会跟着上线,需手动将定时任务调度上线。
实际生产中可以将测试环境中完成的工作流进行导出,并在生产环境中导入工作流。工作流导入后默认为下线状态,需要手动上线。
4.1.2.3 工作流实例

工作流实例操作功能:
4.1.2.4 任务实例
右侧可以查看日志,点击工作流实例名称,可以跳转到工作流实例DAG图查看任务状态。
DolphinScheduler 支持:Shell、SUB_PROCESS、PROCEDURE、SQL、SPARK、FLINK、MR、PYTHON、DEPENDENT、HTTP、DATAX、SQOOP、CONDITIONS 等任务类型。
4.1.3.1 Shell
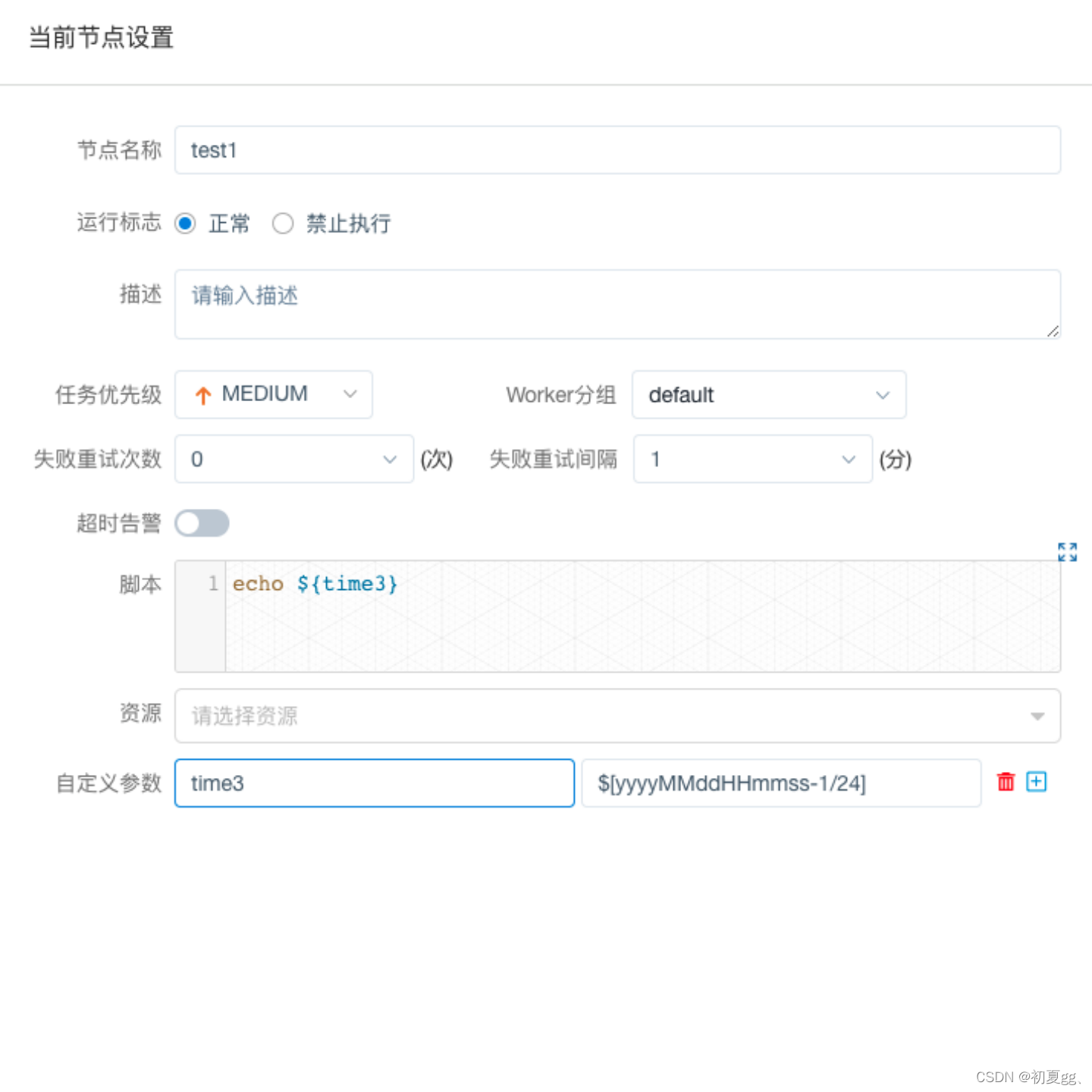
注意:
用shell脚本封装的hql里面必定不能用--来写注释,可能碰到任务一直处于运行状态,一直卡在那里。
在shell节点内需要调用其他内容时,建议创建多个shell节点来进行分别调用,方便出现问题时日志排查。
4.1.3.2 SUB_PROCESS(子流程)
子流程节点,就是把外部的某个工作流定义当做一个任务节点去执行。
创建工作流,在工作流中创建SUB_PROCESS任务:
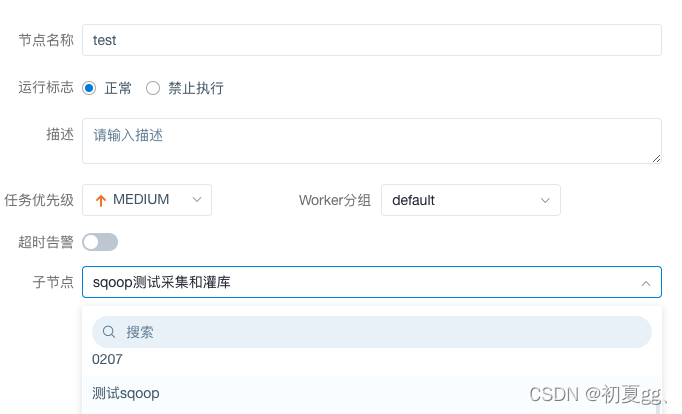
右上角进入子流程需该任务已经执行一次后才可以进入相应的子流程内,否则显示为空白内容。
在使用中,当B工做流依赖于A这个子工做流时,咱们执行B工做流便可,它会先执行A工做流,只有A工做流执行成功,才会继续执行B工做流.注意:不要先把A工做流本身执行一遍,而后再去执行B工做流,这样的话A工做流会被执行2次,会致使错误的结果.
4.1.3.3 PROCEDURE(存储过程)
存储过程节点根据选择的数据源,执行存储过程。
主要参数说明:
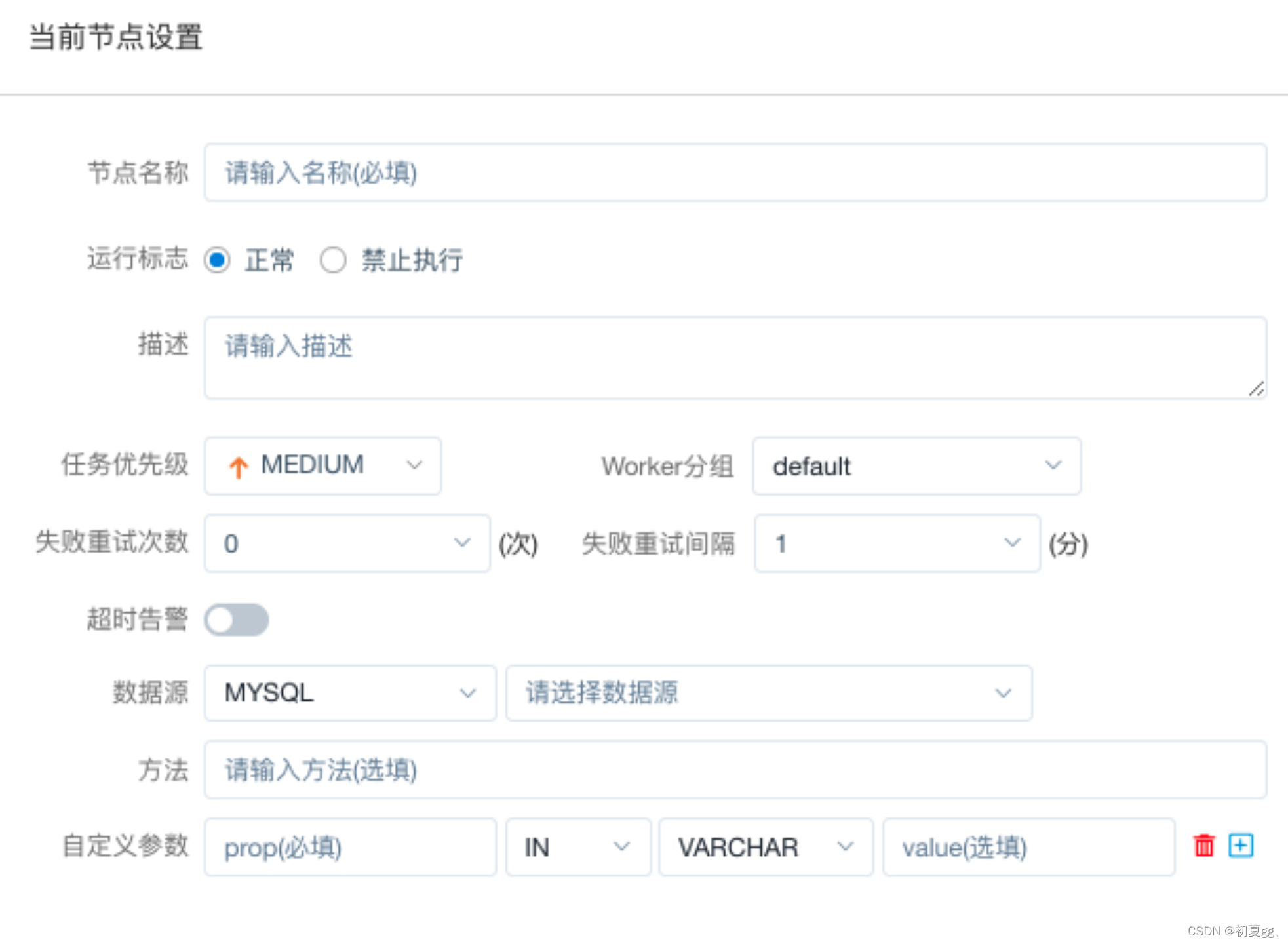
4.1.3.4 SQL
主要参数说明:

4.1.3.5 SPARK
通过 SPARK 节点,可以直接直接执行 SPARK 程序,对于 spark 节点,worker 会使用 spark-submit 方式提交任务。
主要参数说明:
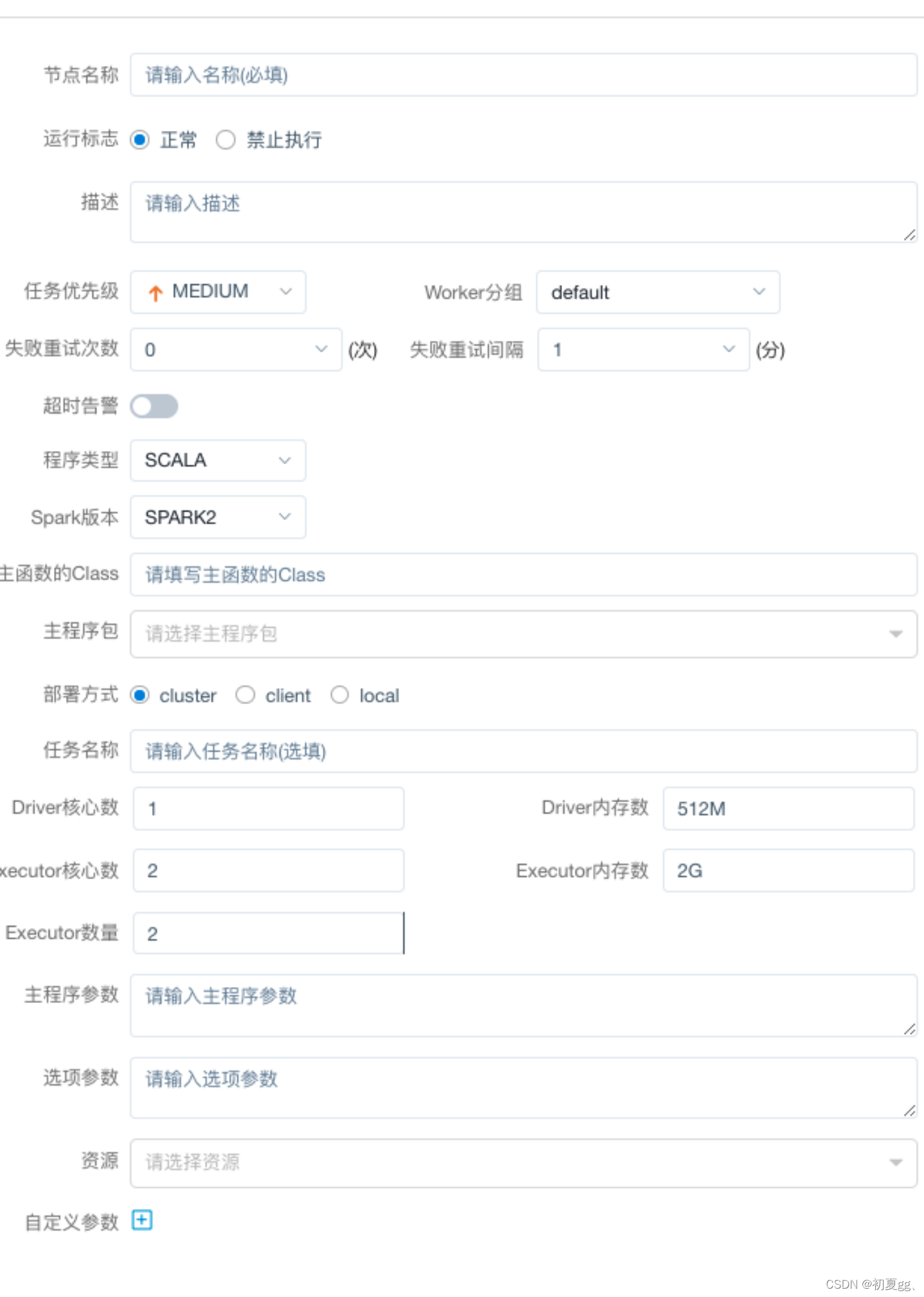
4.1.3.6 FLINK
flink只作为参数说明,具体使用后续同步。
主要参数说明:
若使用的时 Flink local 模式,可以正常运行;若使用前文中源码编译方式部署,且注释了相关参数,则不支持 Flink local 模式,仅能使用 Flink cluster 的模式进行提交。
4.1.3.7 MAPREDUCE
主要参数说明:
4.1.3.8 Python
与shell同理。
4.1.3.9 DEPENDENT(依赖节点)
依赖节点,就是依赖检查节点,,提供了逻辑判断功能。比如 A 流程依赖昨天的 B 流程执行成功,依赖节点会去检查 B 流程在昨天是否有执行成功的实例。

4.1.3.10 HTTP
主要参数说明:
4.1.3.11 DATAX
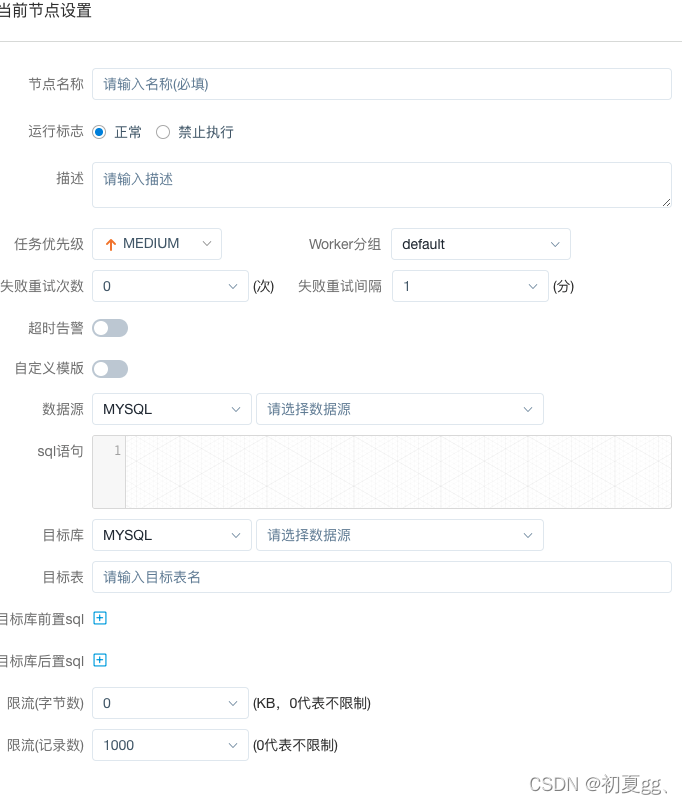
4.1.3.12SQOOP
Sqoop 是 Hadoop 和关系数据库服务器之间传送数据的一种工具。它是用来从关系数据库如:MySQL,Oracle 到Hadoop 的 HDFS,并从 Hadoop 的文件系统导出数据到关系数据库。
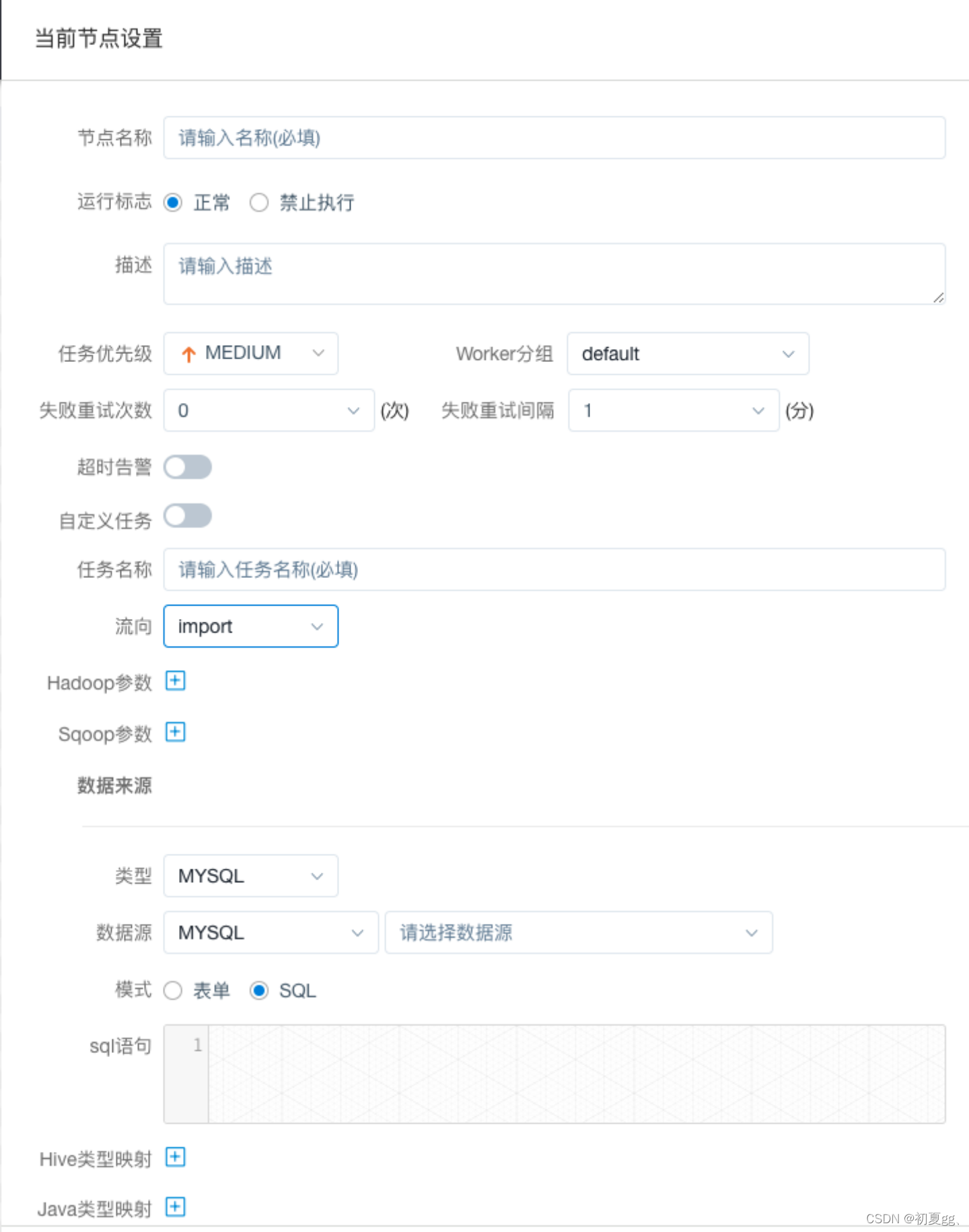
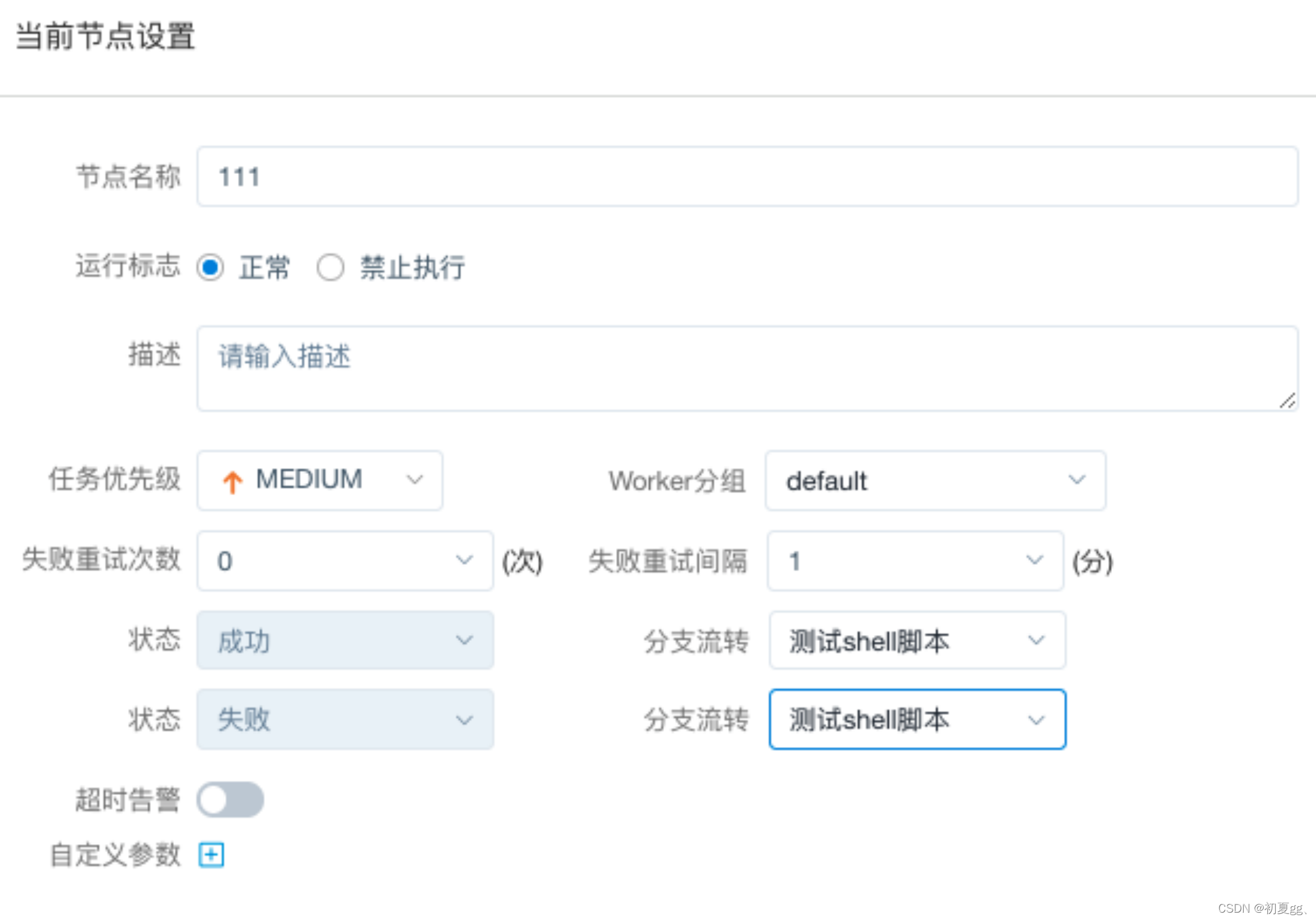
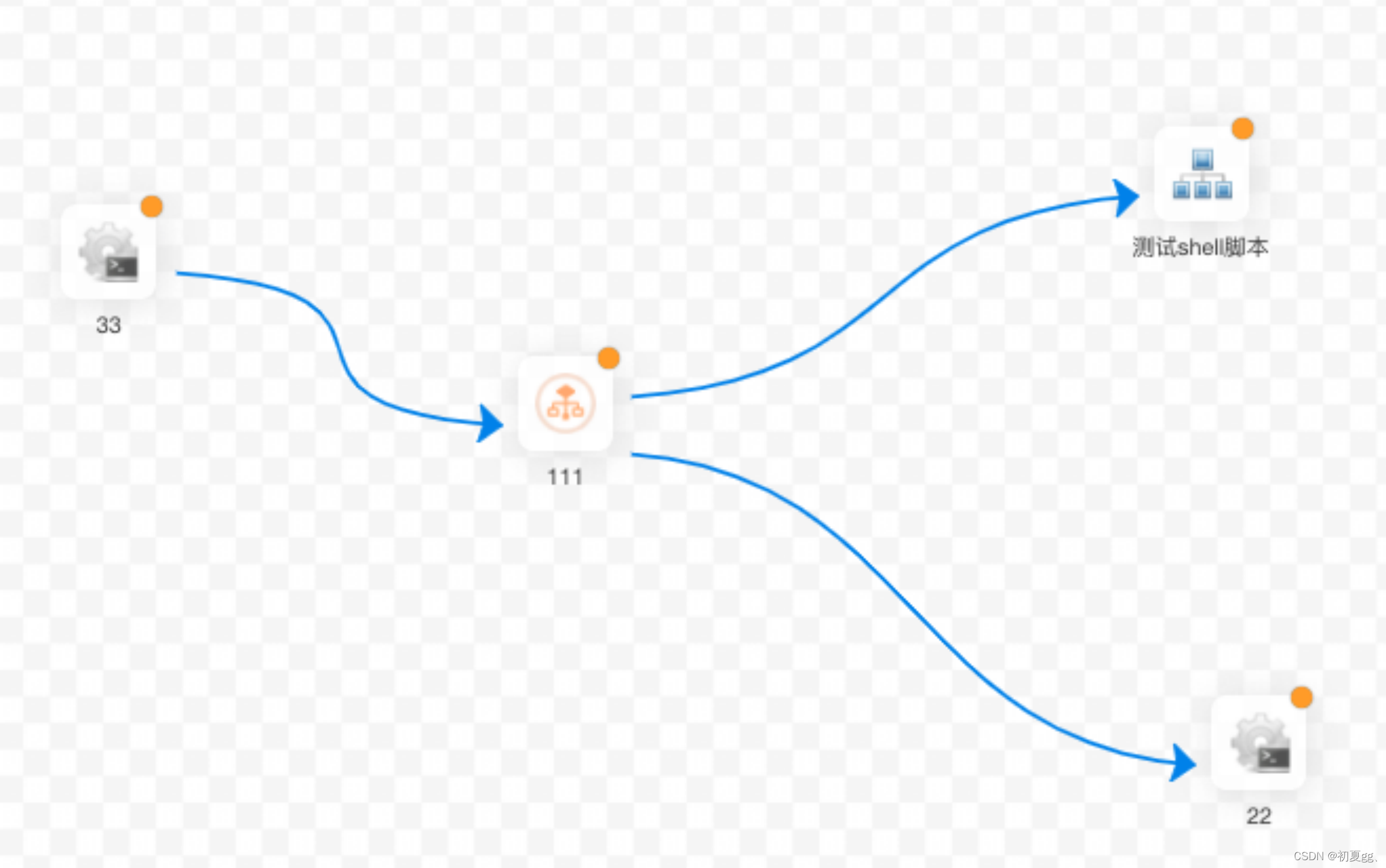
4.1.3.13 CONDITIONS
CONDITIONS 用于判断上个作业执行结果,根据成功或失败继续后面不同的流程。
注意:使用此节点应先将此节点 保存添加后,即可选择分支流转内容,否则无法选择分支流转内容。
是对各种资源文件的管理,包括创建文件夹、创建文件、上传文件等操作。
文件格式支持以下几种类型:txt、log、sh、conf、cfg、py、java、sql、xml、hql、properties
文件可在线编辑、重命名、下载、删除。
1)资源管理
资源管理和文件管理功能类似,不同之处是专门上传UDF函数
2)函数管理
可以创建临时UDF函数。
数据源中心支持 MySQL、POSTGRESQL、HIVE/IMPALA、SPARK、CLICKHOUSE、ORACLE、SQLSERVER 等数据源。
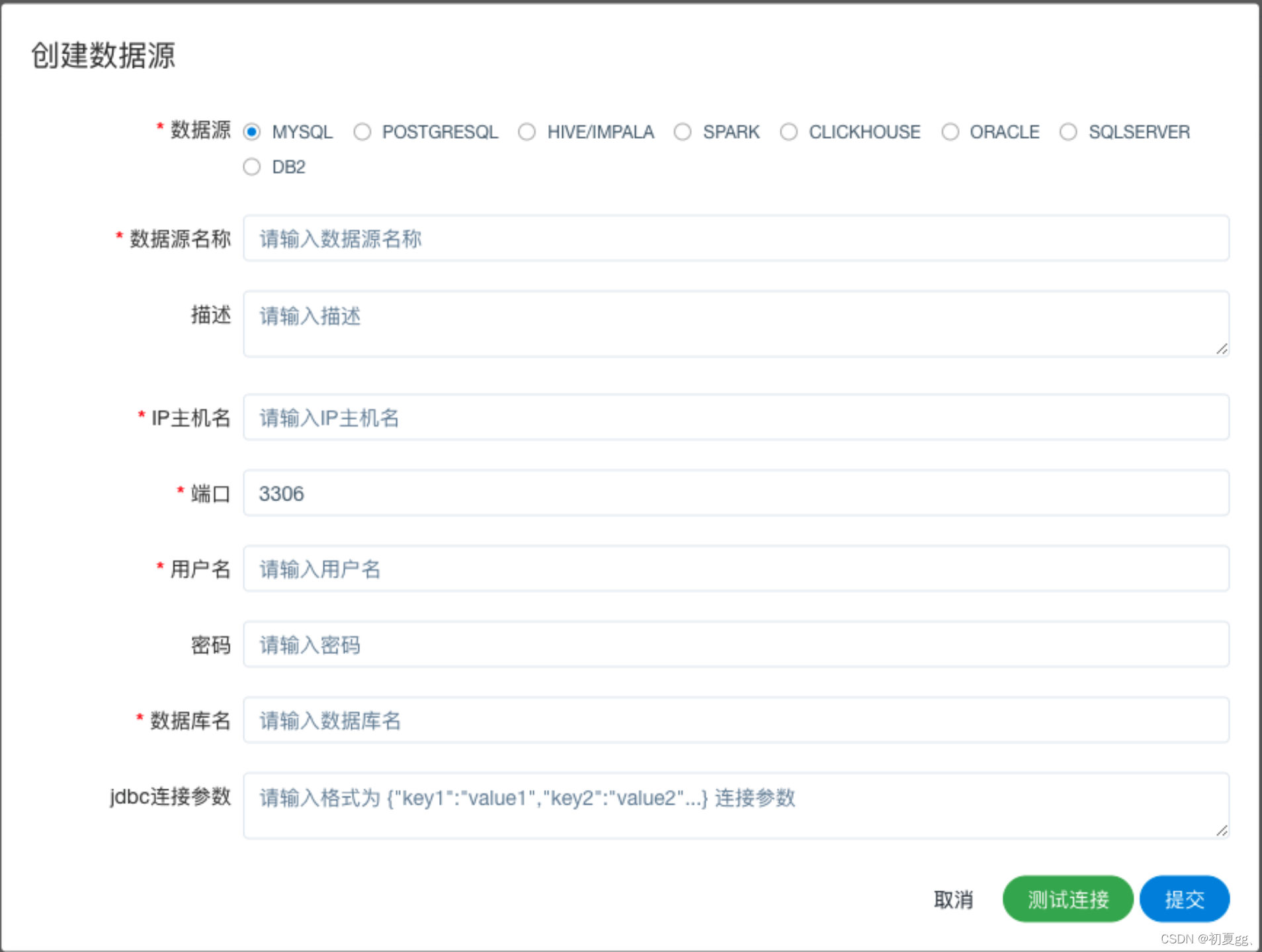
包含以下功能:
服务管理
租户:对应的linux系统的用户,用于worker提交作业锁使用的用户。如果Linux没有这个用户,worker会在执行脚本时自动创建用户(在部署时使用的高权限linux用户)。
租户编码:与租户填写一致。
新建租户会在HDFS上/user目录下创建租户目录,租户目录下为改租户上传的文件和UDF函数。文件夹名称为home、resources、udfs。
租户名称:租户编码的别名。
安全中心—>用户管理—>创建用户
用户分为管理员用户和普通用户。在创建用户时根据需要,给予用户相应租户权限。
通过管理员用户,对相应普通用户授予权限,包括:项目权限、资源权限、数据源权限、udf函数权限。
实际使用中,若需要删除用户,需将该用户所建立项目内的任务删除----》删除项目------》删除用户,否则会出现任务无法运行,项目不可见等情况。
安全中心—>告警组管理—>创建告警组 (目前仅支持邮件告警)
告警组根据需要进行创建,创建后可以添加项目组内成员及部门邮箱。
安全中心—>worker管理—>创建worker分组
安全中心—>队列管理—>创建队列
队列是在执行spark、MR任务等程序,需要指定“队列”参数时使用
安全中心—>令牌管理—>创建令牌
可以对相关用户创建token,便于后端调用平台相关任务。
(2.0.2版本已经优化补数时存在的问题)
${system.biz.date}
日常调度实例定时的定时时间前一天,格式为 yyyyMMdd,补数据时,该日期 +1
${system.biz.curdate}
日常调度实例定时的定时时间,格式为 yyyyMMdd,补数据时,该日期 +1
${system.datetime}
日常调度实例定时的定时时间,格式为 yyyyMMddHHmmss,补数据时,该日期 +1
例:当前时间为20211207111418
| 序号 | 表达式 | 结果 |
| 1 | 后 N 年:$[add_months(yyyyMMdd,12*N)] | echo "后 1 年:" 20221207 |
| 2 | 前 N 年:$[add_months(yyyyMMdd,-12*N)] | echo "前 1 年:" 20201207 |
| 3 | 后 N 月:$[add_months(yyyyMMdd,N)] | echo "后 1 月:" 20220107 |
| 4 | 前 N 月:$[add_months(yyyyMMdd,-N)] | echo "前 1 月:" 20211107 |
| 5 | 后 N 周:$[yyyyMMdd+7*N] | echo "后 1 周:" 20211214 |
| 6 | 前 N 周:$[yyyyMMdd-7*N] | echo "前 1 周:" 20211130 |
| 7 | 后 N 天:$[yyyyMMdd+N] | echo "后 1 天:" 20211208 |
| 8 | 前 N 天:$[yyyyMMdd-N] | echo "前 1 天:" 20211206 |
| 9 | 后 N 小时:$[HHmmss+N/24] | echo "后 1 小时:" 121418 |
| 10 | 前 N 小时:$[HHmmss-N/24] | echo "前 1 小时:" 101418 |
| 11 | 后 N 分钟:$[HHmmss+N/24/60] | echo "后 1 分钟:" 111518 |
| 12 | 前 N 分钟:$[HHmmss-N/24/60] | echo "前 1 分钟:" 111318 |
| 13 | 前一小时:$[yyyyMMddHHmmss-1/24] | echo”前 1 小时:“20211207101418 |
用户自定义参数分为 全局参数 和 局部参数。
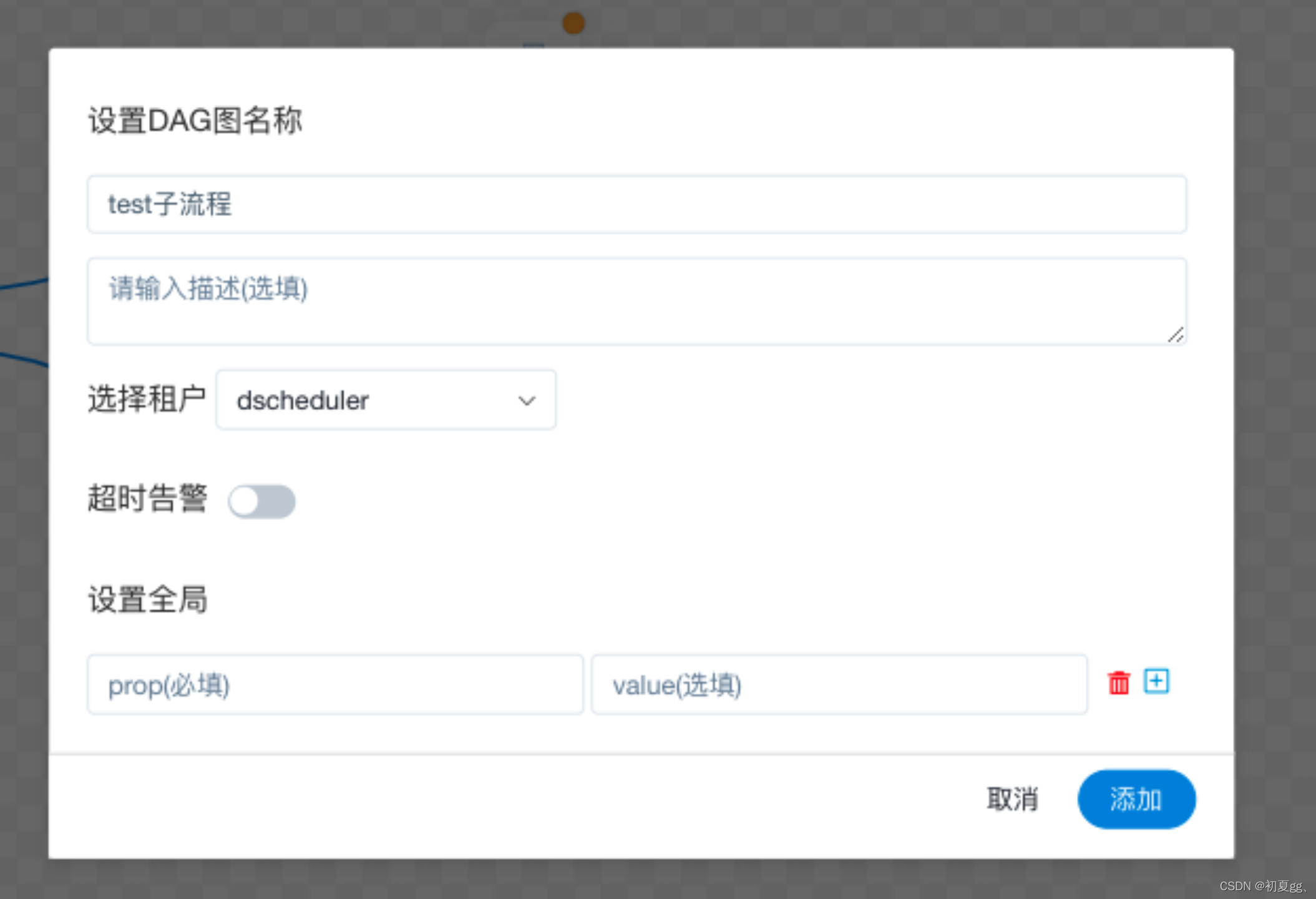
1、下载新版本源码包(2.0.3)
2、修改新版本配置文件内容 conf/config/install_config.conf
注意点:所有修改的配置信息应在引号内进行填写,多余的引用字符需去除。
相关配置信息可以参照老版本的install_config.conf进行修改配置
配置安装目录建议新建目录
3、需将新版本文件夹在每个服务器进行上传,需注意创建的目录用户权限问题,注意安装目录下data目录的创建及权限
4、将mysql的jar包上传至新版本目录、lib下,并设置权限
5、将hadoop配置文件上传至、conf文件夹下 包括:core-site.xml 和hdfs-site.xml
6、conf/env下的环境变量可以在配置文件中设置,也可以后期通过平台进行设置
7、在升级平台后,会短暂出现数据访问不到的问题,大约过十分钟左右数据加载上即可展示。
1、相关配置信息进行可配置化管理,例如环境变量、告警组等信息
2、工作流新增版本信息,可记录工作流中个版本内容,方便进行工作流的版本控制工作。注意:针对于已上线工作流,如需切换版本,需将任务流进行下线操作,
3、优化页面内容,使任务流绘制更易操作,减去上一版本的重复操作内容。
有部分内容显示存在异常问题,需对源码进行调整。
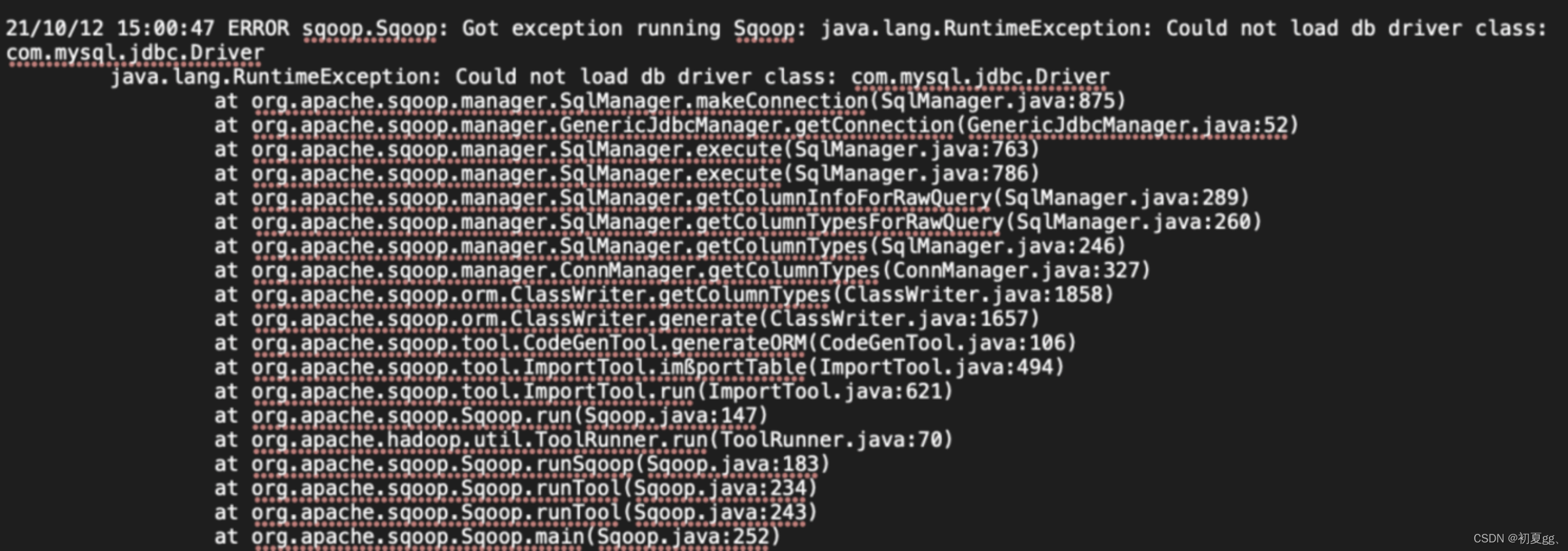
在sqoop目录lib下,添加MySQL的jdbc连接jar包即可(版本至少为5.1.35,同时确认jar包权限)。
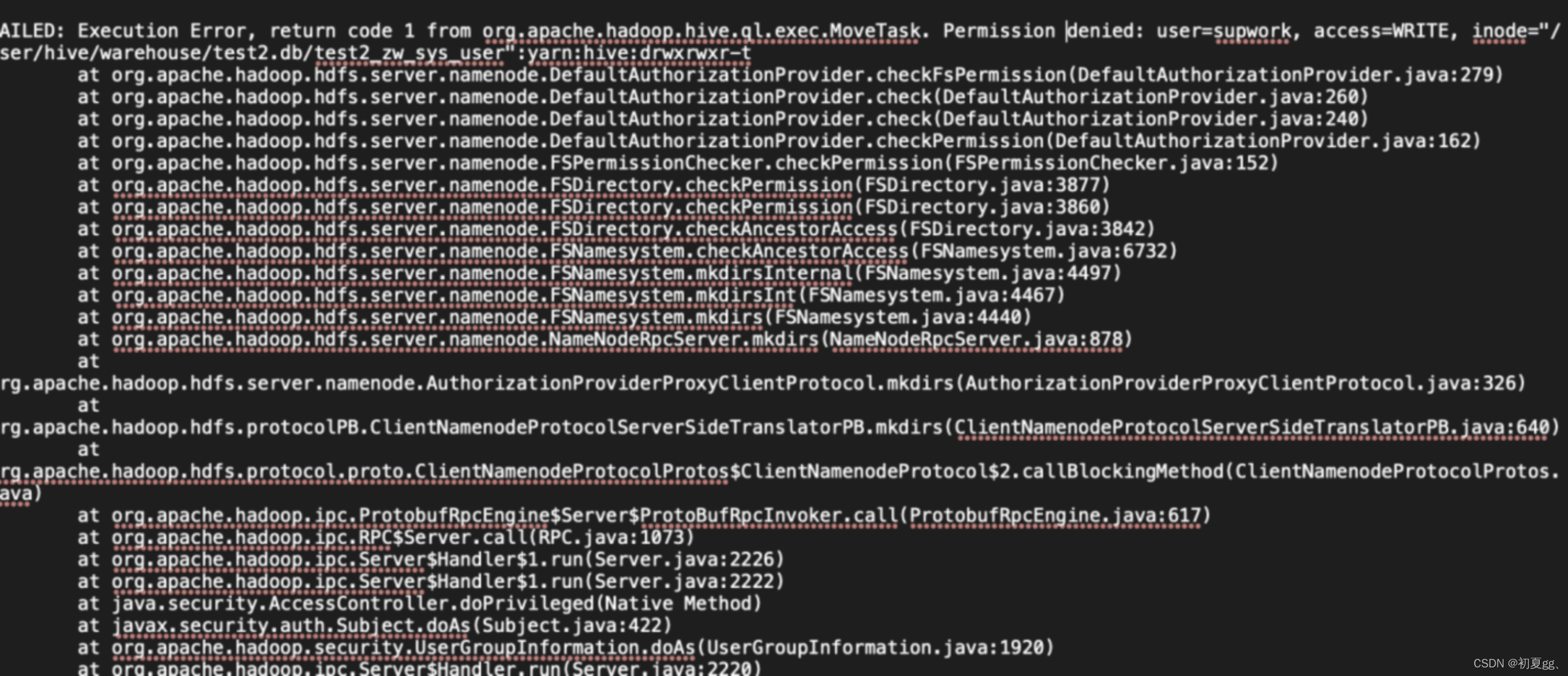
确认执行脚本的平台租户是否具有权限访问hive相关数据表。在平台创建租户时注意租户应与服务器用户对应。
由于平台并没有过多设计权限管理的工作,如需详细的权限管理需进行二次开发。
排查日志
查看worker 日志
tail -f /opt/soft/dolphinscheduler/logs/dolphinscheduler-worker.log
查看master日志
tail -f /opt/soft/dolphinscheduler/logs/dolphinscheduler-master.log
查看api 日志
tail -f /opt/soft/dolphinscheduler/logs/dolphinscheduler-api-server.log
查看告警alert日志
tail -f /opt/soft/dolphinscheduler/logs/dolphinscheduler-alert.log
查看日志服务logger日志
tail -f dolphinscheduler-worker-server-rh-hadoop02-n011-011.out
tail -f dolphinscheduler-worker-server-rh-hadoop02-n013-013.out
平台元数据MySQL说明
| 表名 | 表信息 |
| t_ds_access_token | 访问 ds 后端的 token |
| t_ds_alert | 告警信息 |
| t_ds_alertgroup | 告警组 |
| t_ds_command | 执行命令 |
| t_ds_datasource | 数据源 |
| t_ds_error_command | 错误命令 |
| t_ds_process_definition | 流程定义 |
| t_ds_process_instance | 流程实例 |
| t_ds_project | 项目 |
| t_ds_queue | 队列 |
| t_ds_relation_datasource_user | 用户关联数据源 |
| t_ds_relation_process_instance | 子流程 |
| t_ds_relation_project_user | 用户关联项目 |
| t_ds_relation_resources_user | 用户关联资源 |
| t_ds_relation_udfs_user | 用户关联 UDF 函数 |
| t_ds_relation_user_alertgroup | 用户关联告警组 |
| t_ds_resources | 资源文件 |
| t_ds_schedules | 流程定时调度 |
| t_ds_session | 用户登录的 session |
| t_ds_task_instance | 任务实例 |
| t_ds_tenant | 租户 |
| t_ds_udfs | UDF 资源 |
| t_ds_user | 用户 |
| t_ds_version | ds 版本信息 |
相关表内字段信息参照官网链接:
https://dolphinscheduler.apache.org/zh-cn/docs/1.3.2/user_doc/metadata-1.3.html
无论您是想搭建桌面端、WEB端或者移动端APP应用,HOOPSPlatform组件都可以为您提供弹性的3D集成架构,同时,由工业领域3D技术专家组成的HOOPS技术团队也能为您提供技术支持服务。如果您的客户期望有一种在多个平台(桌面/WEB/APP,而且某些客户端是“瘦”客户端)快速、方便地将数据接入到3D应用系统的解决方案,并且当访问数据时,在各个平台上的性能和用户体验保持一致,HOOPSPlatform将帮助您完成。利用HOOPSPlatform,您可以开发在任何环境下的3D基础应用架构。HOOPSPlatform可以帮您打造3D创新型产品,HOOPSSDK包含的技术有:快速且准确的CAD
C#实现简易绘图工具一.引言实验目的:通过制作窗体应用程序(C#画图软件),熟悉基本的窗体设计过程以及控件设计,事件处理等,熟悉使用C#的winform窗体进行绘图的基本步骤,对于面向对象编程有更加深刻的体会.Tutorial任务设计一个具有基本功能的画图软件**·包括简单的新建文件,保存,重新绘图等功能**·实现一些基本图形的绘制,包括铅笔和基本形状等,学习橡皮工具的创建**·设计一个合理舒适的UI界面**注明:你可能需要先了解一些关于winform窗体应用程序绘图的基本知识,以及关于GDI+类和结构的知识二.实验环境Windows系统下的visualstudio2017C#窗体应用程序三.
1.postman介绍Postman一款非常流行的API调试工具。其实,开发人员用的更多。因为测试人员做接口测试会有更多选择,例如Jmeter、soapUI等。不过,对于开发过程中去调试接口,Postman确实足够的简单方便,而且功能强大。2.下载安装官网地址:https://www.postman.com/下载完成后双击安装吧,安装过程极其简单,无需任何操作3.使用教程这里以百度为例,工具使用简单,填写URL地址即可发送请求,在下方查看响应结果和响应状态码常用方法都有支持请求方法:getpostputdeleteGet、Post、Put与Delete的作用get:请求方法一般是用于数据查询,
我最喜欢的Google文档功能之一是它会在我工作时不断自动保存我的文档版本。这意味着即使我在进行关键更改之前忘记在某个点进行保存,也很有可能会自动创建一个保存点。至少,我可以将文档恢复到错误更改之前的状态,并从该点继续工作。对于在MacOS(或UNIX)上运行的Ruby编码器,是否有具有等效功能的工具?例如,一个工具会每隔几分钟自动将Gitcheckin我的本地存储库以获取我正在处理的文件。也许我有点偏执,但这点小保险可以让我在日常工作中安心。 最佳答案 虚拟机有些人可能讨厌我对此的回应,但我在编码时经常使用VIM,它具有自动保存功
我正在尝试上传文件。一个简单的hello.txt。我正在关注文档,但无法将其上传到我的存储桶。#STARTAWSCLIENTs3=Aws::S3::Resource.newbucket=s3.bucket(BUCKET_NAME)begins3.buckets[BUCKET_NAME].objects[KEY].write(:file=>FILE_NAME)puts"Uploadingfile#{FILE_NAME}tobucket#{BUCKET_NAME}."bucket.objects.eachdo|obj|puts"#{obj.key}=>#{obj.etag}"endresc
我有一个Highstock图表(带有标记和阴影的线条),并且想以编程方式显示一个highstock工具提示,例如,当我选择某个表上的一行(包含图表数据)我想显示相应的highstock工具提示。这可能吗? 最佳答案 股票图表thissolution不起作用:在thisexample你必须更换这个:chart.tooltip.refresh(chart.series[0].data[i]);为此:chart.tooltip.refresh([chart.series[0].points[i]]);解决方案可用here.
一、机器人介绍 此处是基于MATLABRVC工具箱,对ABB-IRB-1200型号的微型机械臂进行正逆向运动学分析,并利Simulink工具实现对机械臂进行具有动力学参数的末端轨迹规划仿真,最后根据机械模型设计Simulink-Adams联合仿真。 图1.ABBIRB 1200尺寸参数示意图ABBIRB 1200提供的两种型号广泛适用于各作业,且两者间零部件通用,两种型号的工作范围分别为700 mm 和 900 mm,大有效负载分别为 7 kg 和5 kg。 IRB 1200 能够在狭小空间内能发挥其工作范围与性能优势,具有全新的设计、小型化的体积、高效的性能、易于集成、便捷的接
我是syslog的新手。我们决定使用系统日志来跟踪Rails应用程序中的一些特殊事件。问题是我不想使用默认的/var/log/system.log文件,而是使用自定义文件,例如/var/log/myapp_events.log.我看到我必须像这样在/etc/syslog.conf中定义我自己的设施:myapp_events.*/var/log/myapp_events.log重新启动syslogd后,我发现我可以直接在bash控制台中使用它:syslog-s-kFacilitymyapp_eventsMessage"thisismymessage"该消息按预期出现在/var/log/m
我需要一个用于大型动态任务集合的调度程序。目前我正在查看resque-scheduler,rufus-scheduler,和clockwork.如果您提供有关选择使用哪一个(或其他替代方案)的建议,我将不胜感激。一些细节:有大量要定期执行的任务(最多100K)。最短执行周期为1h。新任务可能会不时出现。现有任务可能会更改或删除。调度延迟最小化在这里不是关键任务(可扩展性和可持续性最重要)。任务执行不是繁重的操作,可以轻松并行。总结,我需要类似cron的Ruby项目,它可以处理大量动态变化的任务集合。更新:我花了一天时间尝试调度库,现在我想简单总结一下新获得的经验。我已经不再关注Cloc
目前我有一小套针对我的网络服务器运行的集成测试,它发出请求并断言一些关于响应应该是什么的假设。这些是用Ruby编写的,生成http请求。我一直在看Gatling作为压力测试工具,但我想知道它是否也可以用于集成测试。这样,所有端点请求都可以在压力测试和集成测试中重复使用。我可能在这里失去了一些东西,因为没有RSpec的BDD,但不必两次创建相同的测试。有没有人有这样使用gatling的经验? 最佳答案 您可以使用AssertionAPI并设置验收标准。但是,Gatling不是浏览器,不会运行/测试您的Javascript,因此这种方法