目录
动态规划(Dynamic Programming)算法的核心思想是:将大问题划分为小问题,进行解决,从而一步步获取最优解的处理算法
动态规划对于解决最优子结构啊和重叠子问题等问题时候,有着很好的应用
对于动态规划问题,大致可以分为以下几步:
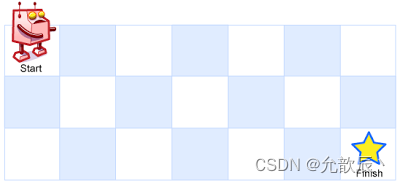
一个机器人位于一个
m x n网格的左上角 (起始点在下图中标记为 “Start” )。机器人每次只能向下或者向右移动一步。机器人试图达到网格的右下角(在下图中标记为 “Finish” )。
问总共有多少条不同的路径?
力扣:力扣
1.确定dp数组(dp table)以及下标的含义
dp[i][j]:机器人走到(i,j)网格的位置有dp[i][j]种方法
2.确定递推公式
因为机器人每次只能向下或者向右移动,所以机器人到达(i,j)的位置只存在两种情况
第一种:从上边的格子走过来,一共有dp[i-1][j]种情况
第二种:从左边的格子走过来,一种有dp[i][j-1]种情况
所以dp[i][j]=dp[i-1][j]+dp[i][j-1]
3.dp数组如何初始化
由递推公式可以看出来,至少初始化第一行和第一列,因为机器人只能左走和下走,所以第一行和第一列只可能有一种情况到达(一直左走或者一直向下走)
4.确定遍历顺序
由递推公式可以看出来,从左到右,从上到下
5.举例推导dp数组
对m = 3, n = 7进行推导
[1, 1, 1, 1, 1, 1, 1]
[1, 2, 3, 4, 5, 6, 7]
[1, 3, 6, 10, 15, 21, 28]
public int uniquePaths(int m, int n) {
int[][] dp=new int[m][n];
for(int i=0;i<n;i++){
dp[0][i]=1;
}
for(int i=1;i<m;i++){
dp[i][0]=1;
}
for(int i=1;i<m;i++){
for(int j=1;j<n;j++){
dp[i][j]=dp[i][j-1]+dp[i-1][j];
}
}
return dp[m-1][n-1];
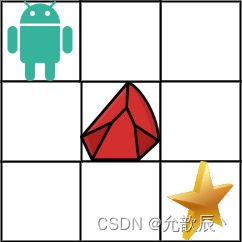
}一个机器人位于一个
m x n网格的左上角 (起始点在下图中标记为 “Start” )。机器人每次只能向下或者向右移动一步。机器人试图达到网格的右下角(在下图中标记为 “Finish”)。
现在考虑网格中有障碍物。那么从左上角到右下角将会有多少条不同的路径?
网格中的障碍物和空位置分别用
1和0来表示。
力扣:力扣
这一题与上一题的区别就是多了障碍,有障碍的地方右走是无法到达的,但是可以从上方到达(不是第一行),知道这个易解
1.确定dp数组(dp table)以及下标的含义
dp[i][j]:机器人走到(i,j)网格的位置有dp[i][j]种方法
2.确定递推公式
因为机器人每次只能向下或者向右移动,所以机器人到达(i,j)的位置(左方不存在任何障碍)只存在两种情况
第一种:从上边的格子走过来,一共有dp[i-1][j]种情况
第二种:从左边的格子走过来,一种有dp[i][j-1]种情况
所以dp[i][j]=dp[i-1][j]+dp[i][j-1]
左方一格存在障碍的时候,只能从上方到来(默认障碍位置到达的方法dp[i][j]为0即可)
3.dp数组如何初始化
由递推公式可以看出来,至少初始化第一行和第一列,当右方存在障碍,第一行和第一列只可能有一种情况到达,当上方或者左方存在障碍的时候,障碍之后的路没有情况可以到达
for (int i = 0; i < m && obstacleGrid[i][0] == 0; ++i) {
dp[i][0] = 1;
}
for (int i = 0; i < n && obstacleGrid[0][i] == 0; ++i) {
dp[0][i] = 1;
}4.确定遍历顺序
由递推公式可以看出来,从左到右,从上到下
5.举例推导dp数组
对obstacleGrid = [[0,0,0],[0,1,0],[0,0,0]]进行推导
[1, 1, 1]
[1, 0, 1]
[1, 1, 2]
public int uniquePathsWithObstacles(int[][] obstacleGrid) {
int m = obstacleGrid.length;
int n = obstacleGrid[0].length;
int[][] dp = new int[m][n];
if(obstacleGrid[0][0] == 1)
return 0;
for (int i = 0; i < m && obstacleGrid[i][0] == 0; ++i) {
dp[i][0] = 1;
}
for (int i = 0; i < n && obstacleGrid[0][i] == 0; ++i) {
dp[0][i] = 1;
}
for (int i = 1; i < m; ++i) {
for (int j = 1; j < n; ++j) {
if (obstacleGrid[i][j] == 0)
dp[i][j] = dp[i - 1][j] + dp[i][j - 1];
}
}
return dp[m-1][n-1];
}假设有排成一行的N个位置,记为1~N,(N>=2),开始时机器人在start位置,有如下约束
- 机器人在1位置,下一步只能走到2位置
- 机器人在N位置,下一步只能走到N-1位置
- 机器人在其他位置,下一步能走左边,也能走右边
求机器人从start位置经过k步到达target位置的方法数。
这一题从二维变成了一维,显然是增加了难度的,因为可能存在在一个位置上来回移动的情况,所以dp数组和前几题有明显的的不一样,采用从后到前的推导方式,从target位置推导到start位置
1.确定dp数组(dp table)以及下标的含义
dp[i][j]的含义:机器人剩余j步,在i位置走到target位置可以有dp[i][j]中方法数
2.确定递推公式
因为机器人只能向左或是向右移动,所以dp[i][j]可以有两种方式推导出来
从左格移动到i位置:dp[i][j]=dp[i-1][j-1];
从右格移动到i位置:dp[i][j]=dp[i+1][j-1];
所以递推公式为:dp[i][j]=dp[i-1][j-1]+dp[i+1][j-1]
但是存在两种特殊情况,当机器人位于1位置的时候,只能向右移动到2位置
当机器人位于n位置的时候,只能向左移动到n-1位置
if (i == 1) {
dp[i][j] = dp[2][j - 1];
} else if (i == n) {
dp[i][j] = dp[n - 1][j - 1];
} else {
dp[i][j] = dp[i + 1][j - 1] + dp[i - 1][j - 1];
}3.dp数组如何初始化
当机器人剩余0步的时候,已经在target位置的时候,这种情况下到达dp显然是1中情况
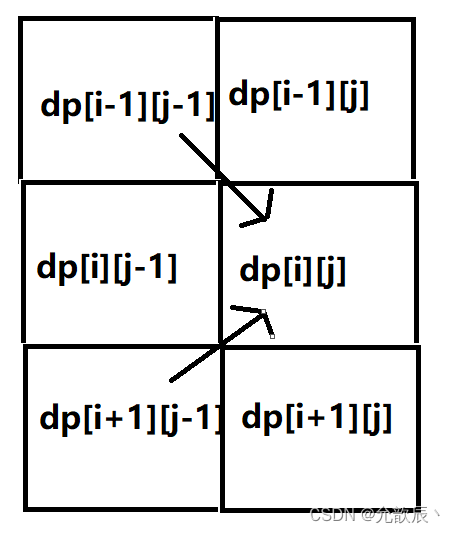
4.确定遍历顺序
由下图可以看出,遍历顺序应该先从左到右,然后从上到下进行遍历,也就是j(剩余的步数)在外层循环,i(机器人目前的位置)在内存循环
5.举例推导dp数组
对n=5,steps=3,start=2,target=3进行推导
[0, 1, 0, 2] [1, 0, 2, 0] [0, 1, 0, 3] [0, 0, 1, 0] [0, 0, 0, 1]
也就是这三种情况
1).2->1,1->2,2->3 2).2->3,3->2,2->3 3).2->3,3->4,4->3
public int move(int n, int steps, int start, int target) {
int[][] dp = new int[n + 1][steps + 1];
//剩余的步数为0,当前位置为target时
dp[target][0] = 1;
for (int j = 1; j <= steps; ++j) {
for (int i = 1; i <= n; ++i) {
if (i == 1) {
dp[i][j] = dp[2][j - 1];
} else if (i == n) {
dp[i][j] = dp[n - 1][j - 1];
} else {
dp[i][j] = dp[i + 1][j - 1] + dp[i - 1][j - 1];
}
}
}
return dp[start][steps];
}回溯代码
/**
* @param n 能够到达位置的最大值(1--n位置移动)
* @param steps 剩余需要移动的步数
* @param start 当前开始所处的位置
* @param target 需要到达的目标位置
* @return 一共到达目标位置的方法数
*/
public int move(int n, int steps, int start, int target) {
if (steps == 0) {
if (start == target) {
return 1;
} else
return 0;
} else if (start == 1) {
return move(n, steps - 1, 2, target);
} else if (start == n) {
return move(n, steps - 1, n - 1, target);
} else {
return move(n, steps - 1,
start + 1, target) + move(n, steps - 1, start - 1, target);
}
}我的代码目前看起来像这样numbers=[1,2,3,4,5]defpop_threepop=[]3.times{pop有没有办法在一行中完成pop_three方法中的内容?我基本上想做类似numbers.slice(0,3)的事情,但要删除切片中的数组项。嗯...嗯,我想我刚刚意识到我可以试试slice! 最佳答案 是numbers.pop(3)或者numbers.shift(3)如果你想要另一边。 关于ruby-多次弹出/移动ruby数组,我们在StackOverflow上找到一
我真的很习惯使用Ruby编写以下代码:my_hash={}my_hash['test']=1Java中对应的数据结构是什么? 最佳答案 HashMapmap=newHashMap();map.put("test",1);我假设? 关于java-等价于Java中的RubyHash,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/22737685/
当我在我的Rails应用程序根目录中运行rakedoc:app时,API文档是使用/doc/README_FOR_APP作为主页生成的。我想向该文件添加.rdoc扩展名,以便它在GitHub上正确呈现。更好的是,我想将它移动到应用程序根目录(/README.rdoc)。有没有办法通过修改包含的rake/rdoctask任务在我的Rakefile中执行此操作?是否有某个地方可以查找可以修改的主页文件的名称?还是我必须编写一个新的Rake任务?额外的问题:Rails应用程序的两个单独文件/README和/doc/README_FOR_APP背后的逻辑是什么?为什么不只有一个?
这似乎非常适得其反,因为太多的gem会在window上破裂。我一直在处理很多mysql和ruby-mysqlgem问题(gem本身发生段错误,一个名为UnixSocket的类显然在Windows机器上不能正常工作,等等)。我只是在浪费时间吗?我应该转向不同的脚本语言吗? 最佳答案 我在Windows上使用Ruby的经验很少,但是当我开始使用Ruby时,我是在Windows上,我的总体印象是它不是Windows原生系统。因此,在主要使用Windows多年之后,开始使用Ruby促使我切换回原来的系统Unix,这次是Linux。Rub
我正在尝试使用boilerpipe来自JRuby。我看过guide从JRuby调用Java,并成功地将它与另一个Java包一起使用,但无法弄清楚为什么同样的东西不能用于boilerpipe。我正在尝试基本上从JRuby中执行与此Java等效的操作:URLurl=newURL("http://www.example.com/some-location/index.html");Stringtext=ArticleExtractor.INSTANCE.getText(url);在JRuby中试过这个:require'java'url=java.net.URL.new("http://www
我只想对我一直在思考的这个问题有其他意见,例如我有classuser_controller和classuserclassUserattr_accessor:name,:usernameendclassUserController//dosomethingaboutanythingaboutusersend问题是我的User类中是否应该有逻辑user=User.newuser.do_something(user1)oritshouldbeuser_controller=UserController.newuser_controller.do_something(user1,user2)我
什么是ruby的rack或python的Java的wsgi?还有一个路由库。 最佳答案 来自Python标准PEP333:Bycontrast,althoughJavahasjustasmanywebapplicationframeworksavailable,Java's"servlet"APImakesitpossibleforapplicationswrittenwithanyJavawebapplicationframeworktoruninanywebserverthatsupportstheservletAPI.ht
这篇文章是继上一篇文章“Observability:从零开始创建Java微服务并监控它(一)”的续篇。在上一篇文章中,我们讲述了如何创建一个Javaweb应用,并使用Filebeat来收集应用所生成的日志。在今天的文章中,我来详述如何收集应用的指标,使用APM来监控应用并监督web服务的在线情况。源码可以在地址 https://github.com/liu-xiao-guo/java_observability 进行下载。摄入指标指标被视为可以随时更改的时间点值。当前请求的数量可以改变任何毫秒。你可能有1000个请求的峰值,然后一切都回到一个请求。这也意味着这些指标可能不准确,你还想提取最小/
HashMap中为什么引入红黑树,而不是AVL树呢1.概述开始学习这个知识点之前我们需要知道,在JDK1.8以及之前,针对HashMap有什么不同。JDK1.7的时候,HashMap的底层实现是数组+链表JDK1.8的时候,HashMap的底层实现是数组+链表+红黑树我们要思考一个问题,为什么要从链表转为红黑树呢。首先先让我们了解下链表有什么不好???2.链表上述的截图其实就是链表的结构,我们来看下链表的增删改查的时间复杂度增:因为链表不是线性结构,所以每次添加的时候,只需要移动一个节点,所以可以理解为复杂度是N(1)删:算法时间复杂度跟增保持一致查:既然是非线性结构,所以查询某一个节点的时候
我从Ubuntu服务器上的RVM转移到rbenv。当我使用RVM时,使用bundle没有问题。转移到rbenv后,我在Jenkins的执行shell中收到“找不到命令”错误。我内爆并删除了RVM,并从~/.bashrc'中删除了所有与RVM相关的行。使用后我仍然收到此错误:rvmimploderm~/.rvm-rfrm~/.rvmrcgeminstallbundlerecho'exportPATH="$HOME/.rbenv/bin:$PATH"'>>~/.bashrcecho'eval"$(rbenvinit-)"'>>~/.bashrc.~/.bashrcrbenvversions