在学习的过程中,很多同学会因为没有带GPU的电脑影响了模型训练从而影响学习;此文详细介绍如何通过云服务器租用GPU进行模型训练,得到模型权重参数。
大家在身边没有GPU服务器,或者算力不够的情况下,也可以采用这些云端算力平台进行使用。本次课程采用的算力平台主要是AutoDL AI算力云,官网链接是:AutoDL-品质GPU租用平台-租GPU就上AutoDL。

1.点击右上角的“注册”选项先进行注册。
2.注册成功后,进入算力市场。可以看到不同区域,空闲的一些GPU服务器,每台服务器的显卡和算力都不相同,大家可以根据自己的需求进行选择。
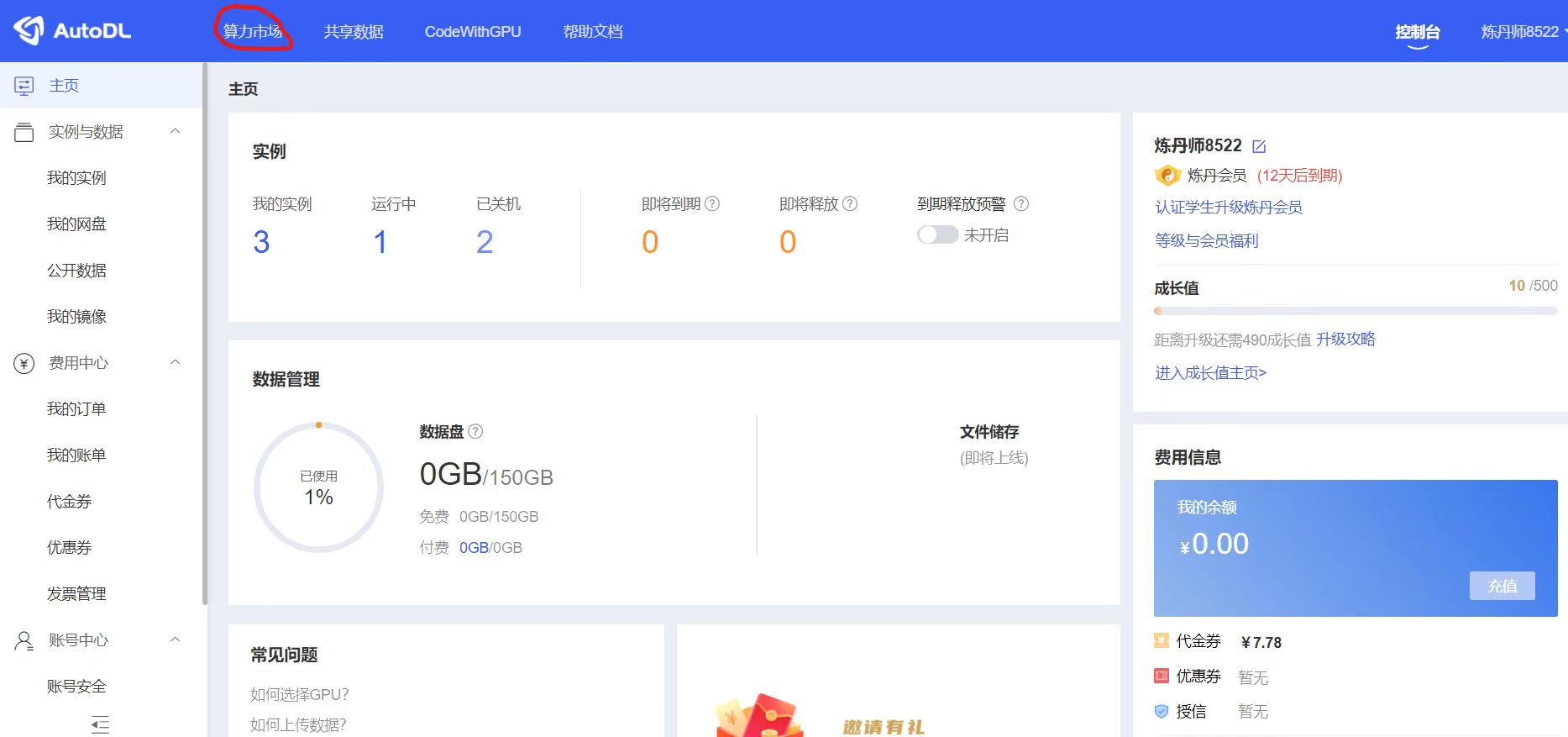
3.可以看到不同区域,空闲的一些GPU服务器,每台服务器的显卡和算力都不相同,大家可以根据自己的需求进行选择。我们也可以看到,代金券这边刚申请的话,都是10元,可以让大家免费使用,我们训练一下Yolo数据集是够用了。
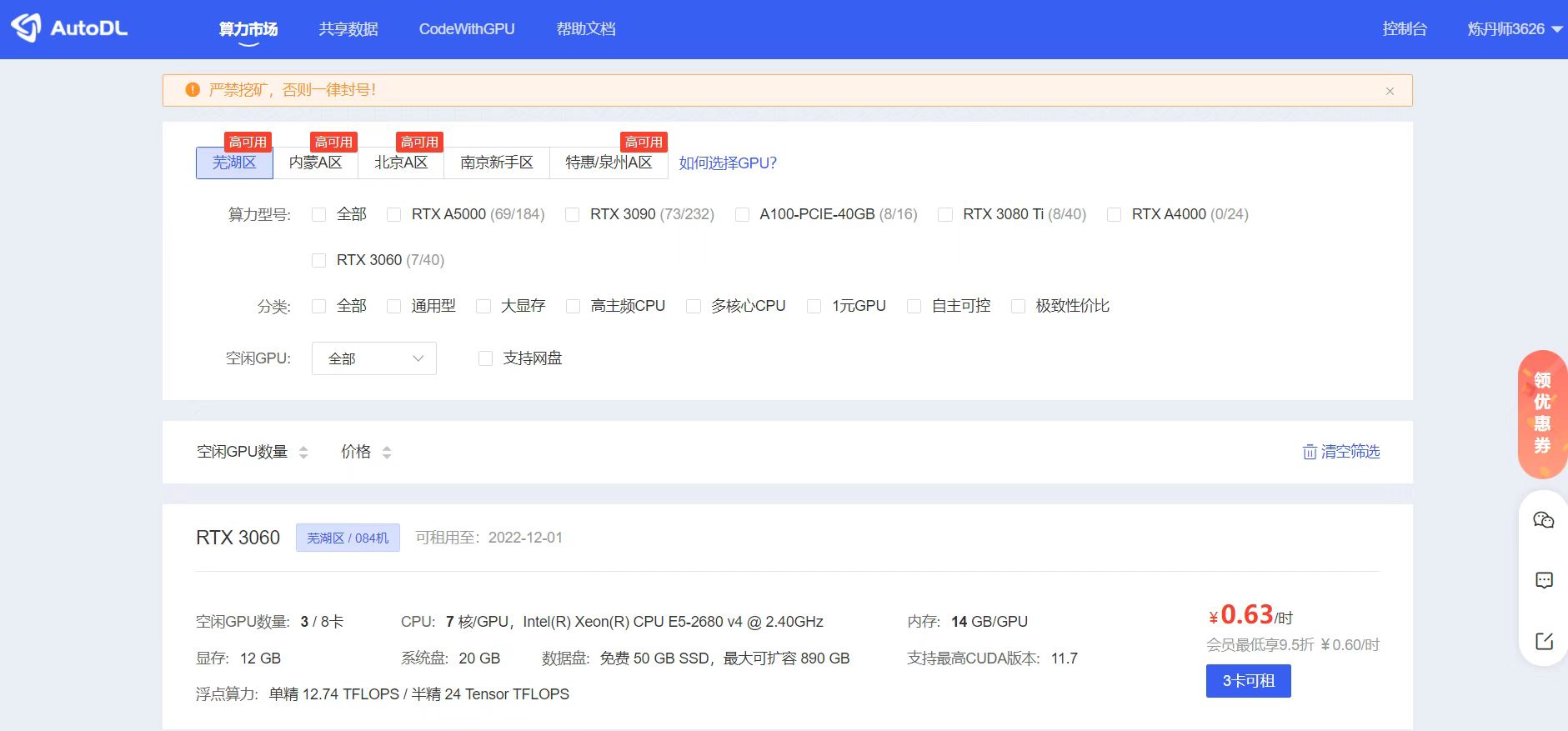
4. 查看符合条件的云网盘
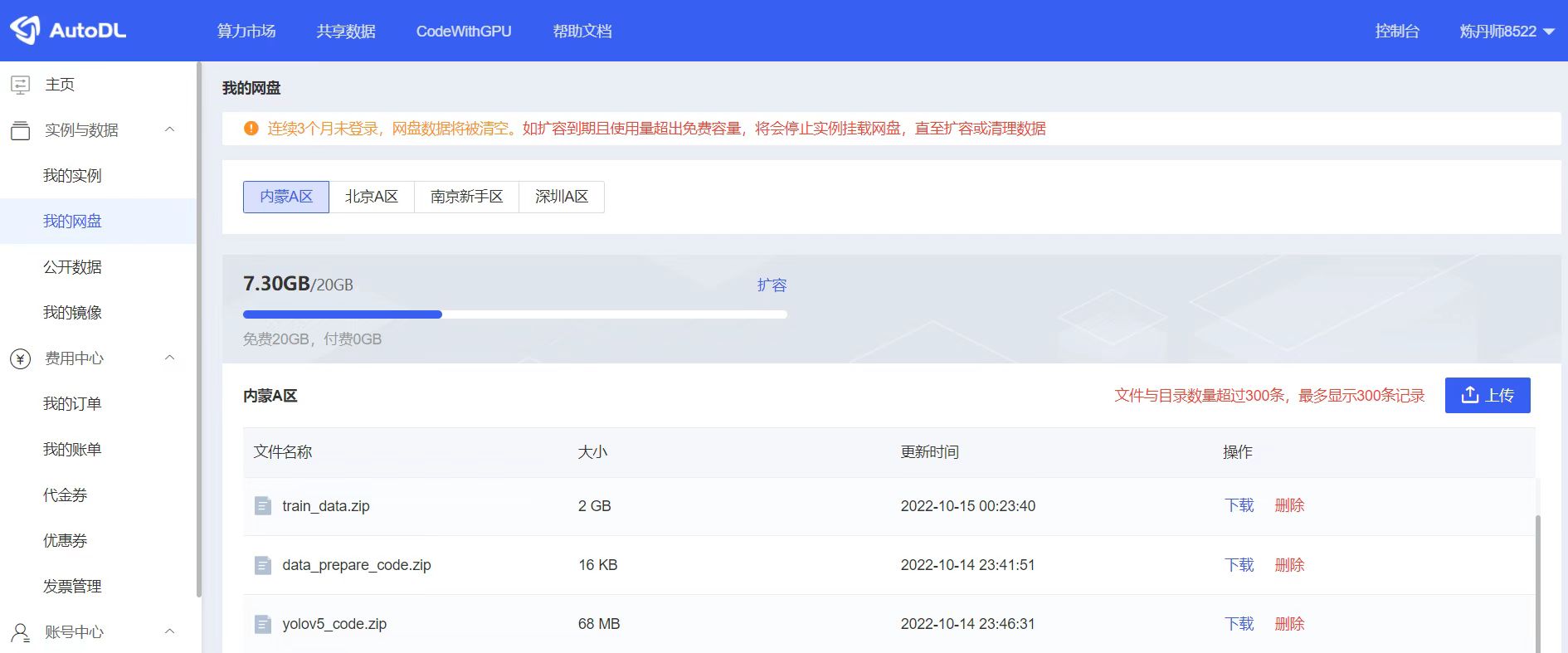
因为后面训练都是在云服务器上,所以需要将数据集和代码都先上传到云服务器的网盘里面,后面就可以直接在上面操作。
不过大家在实例中可以看到,这里存在不同的地方设备。而且在云服务器网盘中,也有相应的不同地方。
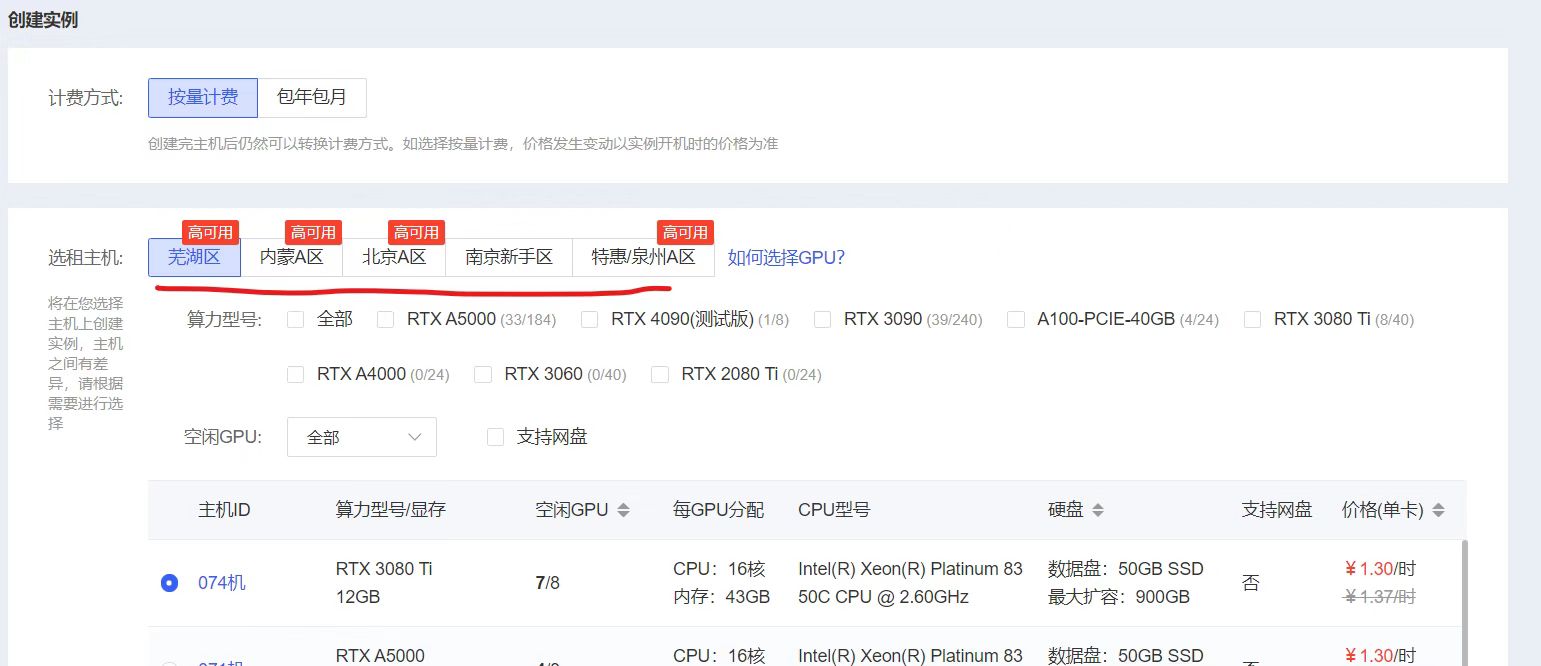
所以需要注意,我们首先查看以下实例中,哪些区域的算力设备,符合自己租赁的范围,再选择相应的地方的网盘,上传代码文件等。
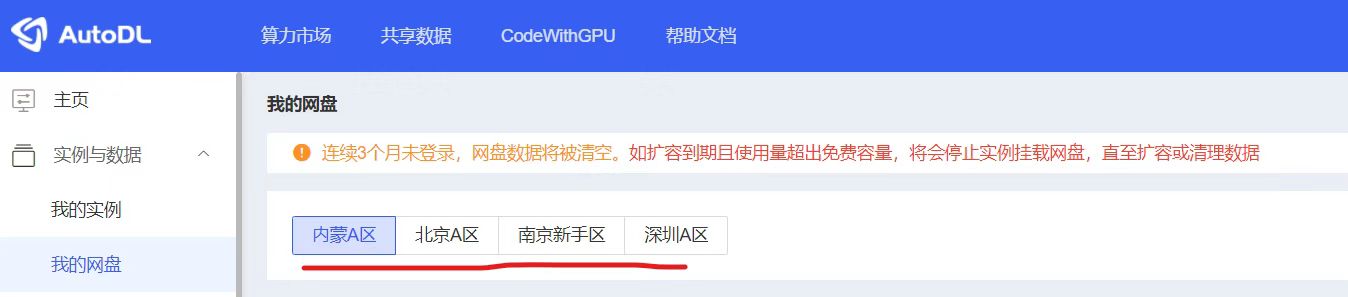
比如大白这里使用的是内蒙的服务器,后面实例购买的时候,还是购买内蒙的实例,就可以在系统盘中直接找到相应的文件。如果后面再购买北京的实例,则在系统盘中,就找不到相应的数据文件。
5 训练&验证集图片上传
我们再将前面的一些文件,传输到“我的网盘”里面。主要上传三个文件:
1)将train_data文件夹中的images_label_split文件夹删除,只留下刚刚划分的train和test文件夹。
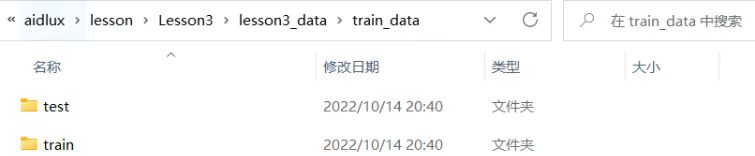
为了上传方便,将train_data文件夹,压缩成一个train_data.zip。
2)数据集整理代码
将data_prepare_code文件夹,进行压缩,变成data_prepare_code.zip文件夹。
3)Yolov5训练代码
将Yolov5_code训练代码,进行压缩,变成yolov5_code.zip。
4)后台上传文件
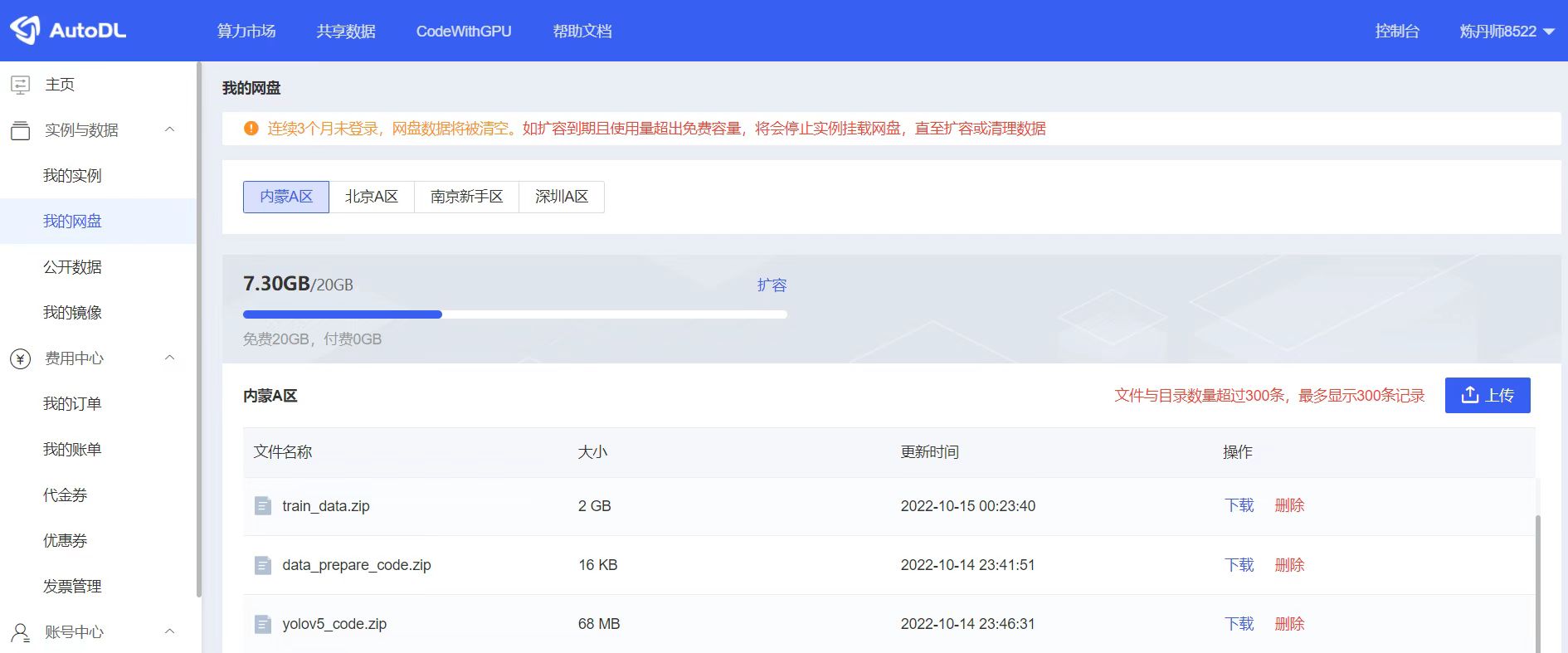
点击AutoDL后台的我的网盘,将刚刚的三个zip文件进行上传,即以下图中的三个文件,当然可能网络原因,有的文件可以上传的会稍微慢一些。
6 新建实例设备
到了这里,我们的代码、数据集都准备好了,就准备新建一个实例设备操作了。这里大白还是选择和网盘所对应的,内蒙A区的实例。
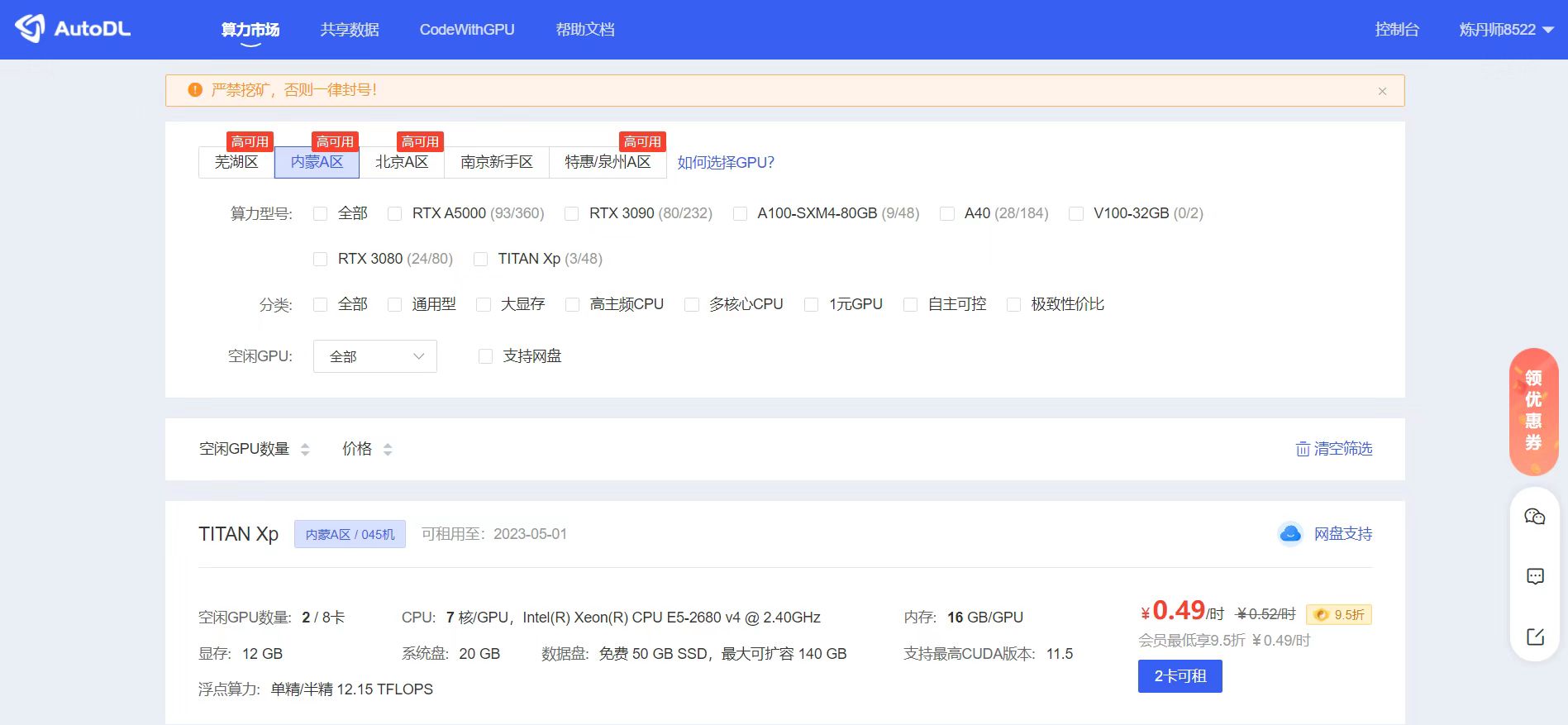
可以挑选自己选择一个GPU服务器,可以看到显示多少钱,这里展示的都是单卡的价格,有的设备必须要N卡一租的,可以看到对应的价格。
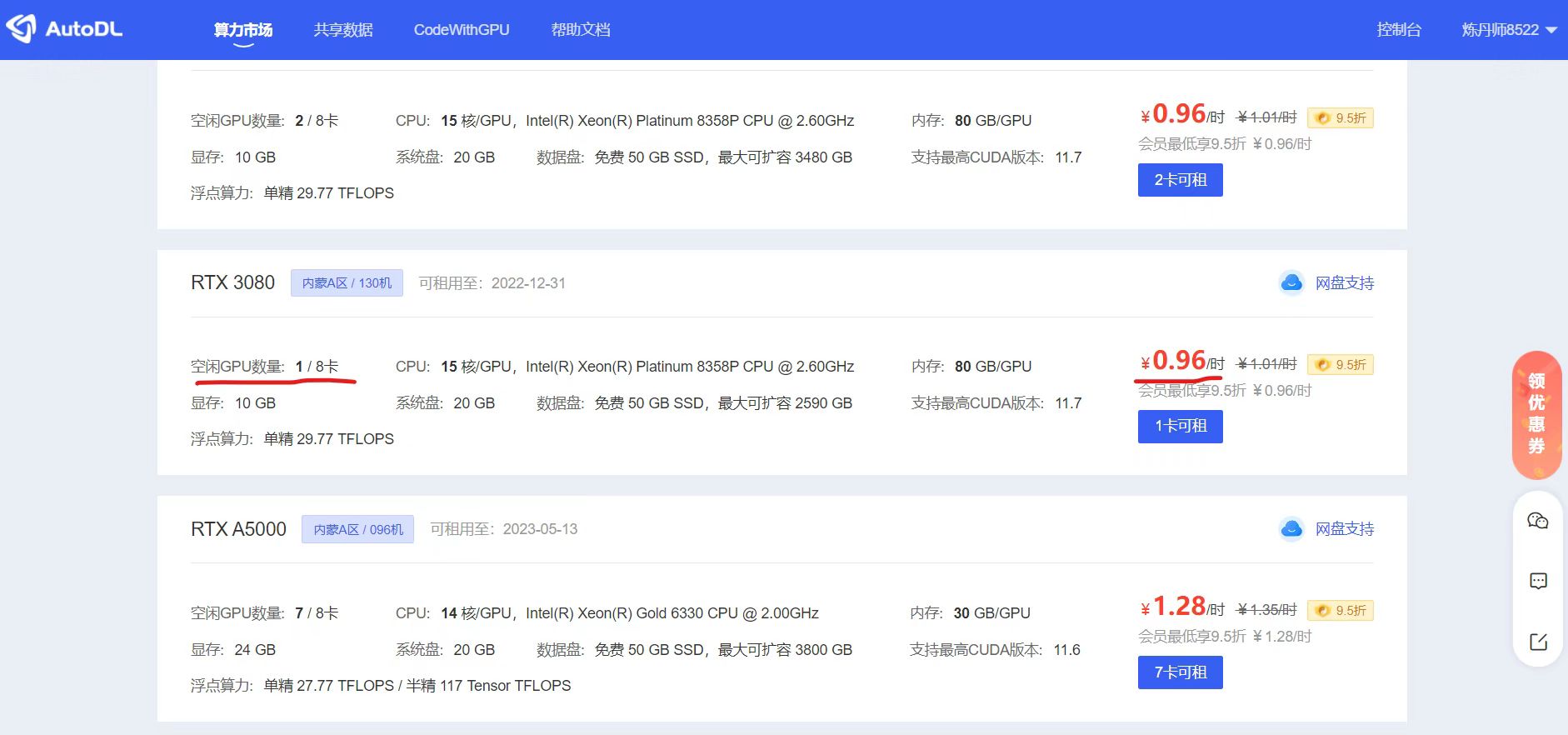
点击进入后,可以修改两个地方,一个是GPU数量,一个是新建实例的基础镜像。大白这里,GPU数量选择1,表示单卡。新建实例镜像,选择了Pytorch的版本。我们也可以看到最下方,有一个可用代金券,即表示我们可以先免费使用10元钱。
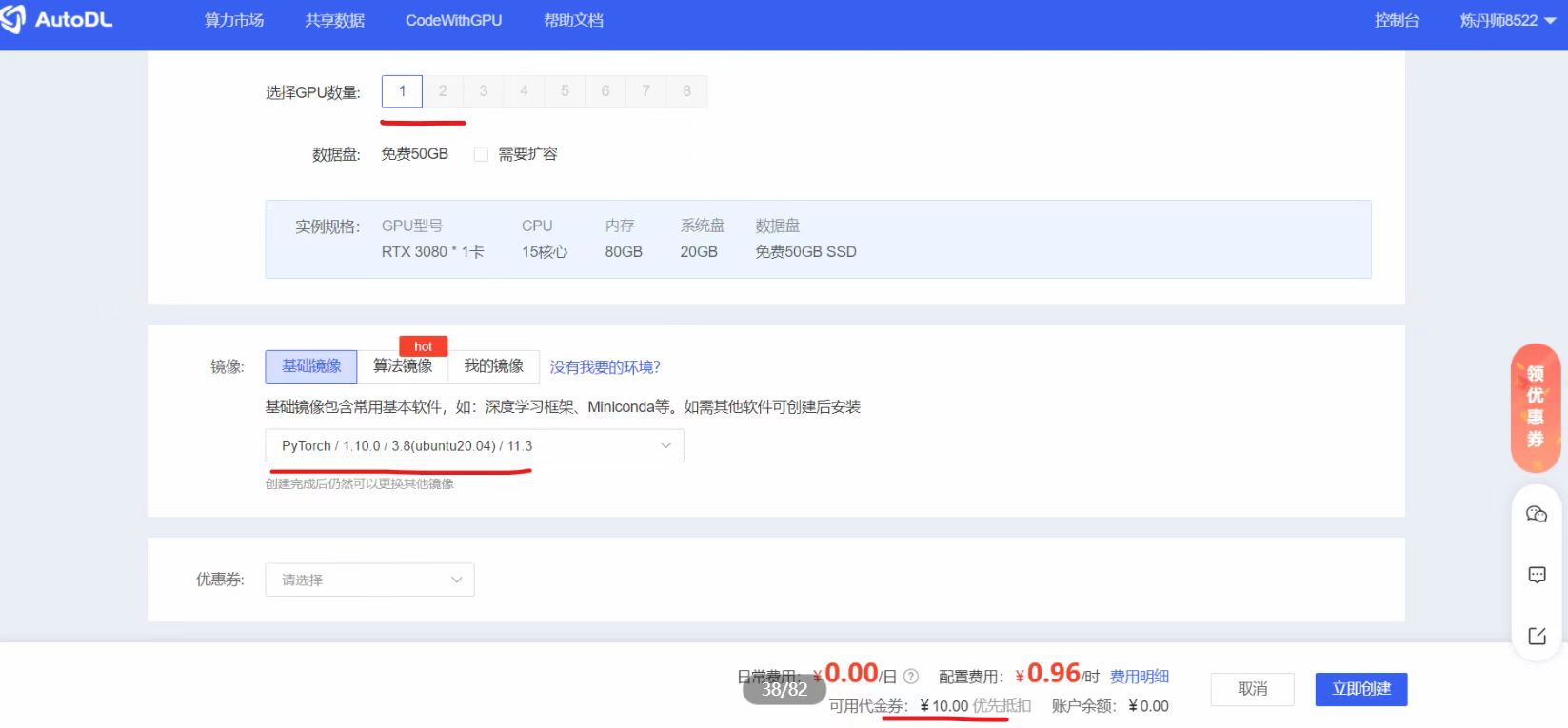
点击“立即创建”后,就可以看到创建的实例了。
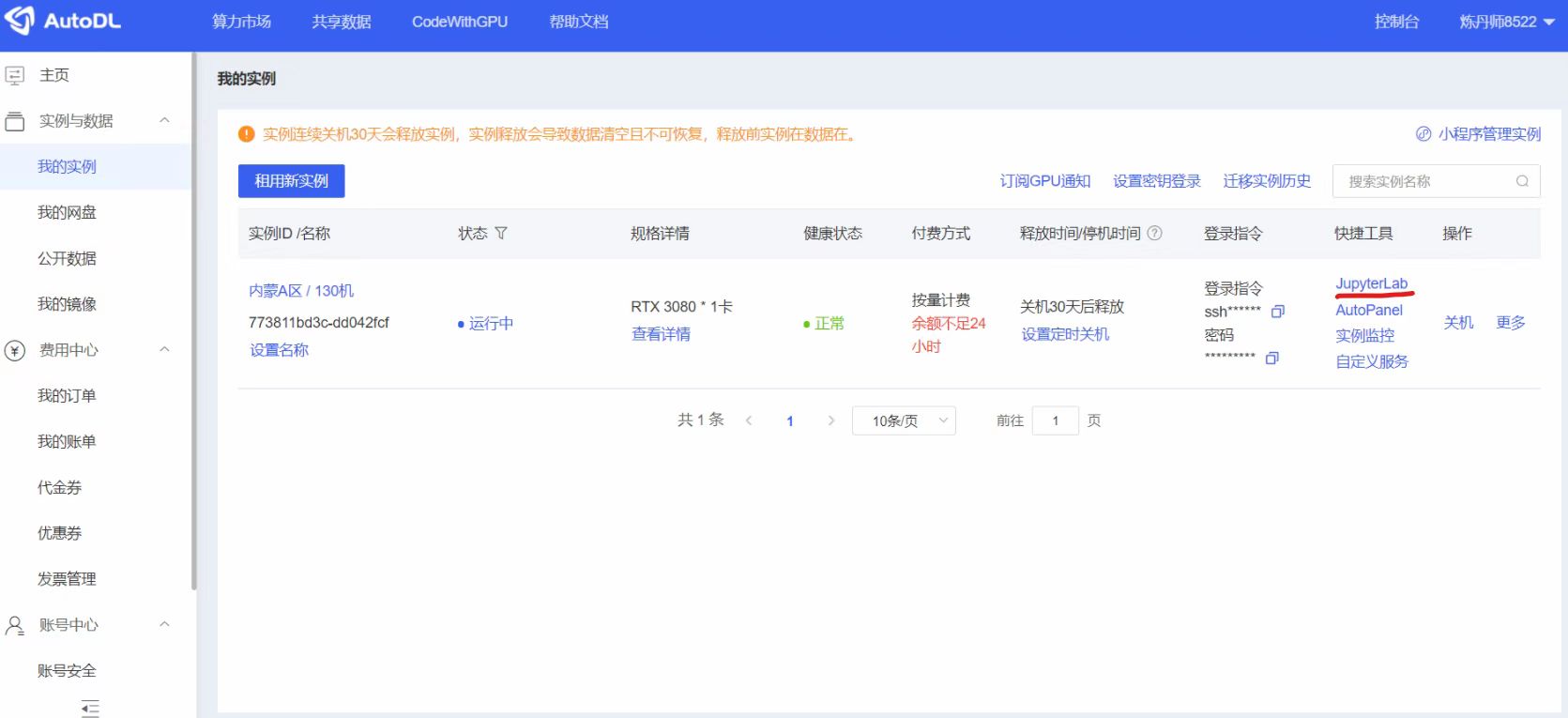
点击右面的“JupyterLab”,可以进入控制台页面。可以点击下面的“终端”,打开一个终端页面,就可以进行操作了。
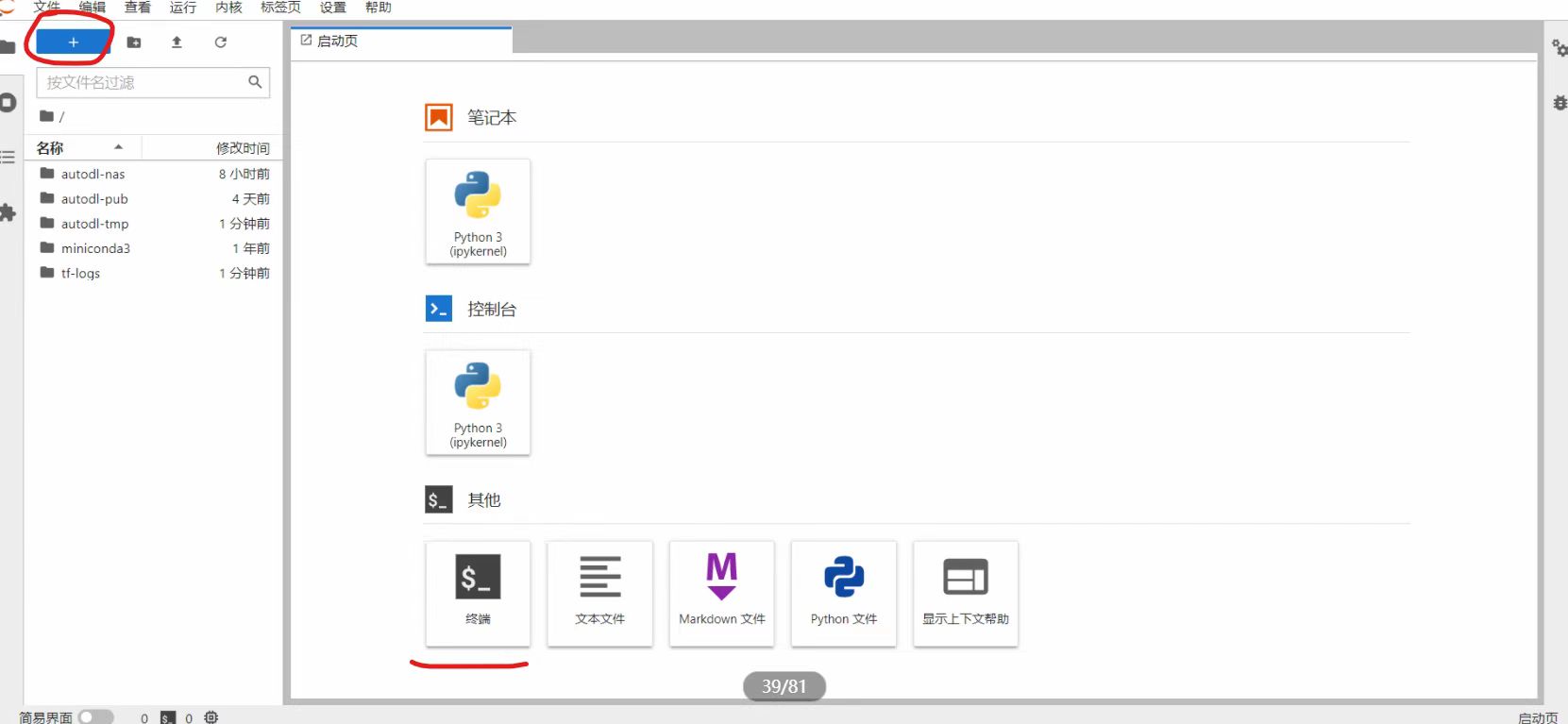
当然如果一个终端页面不够操作的话,可以点击左上方的“+”号,新增加几个终端页面。比如大白这里新建了4个终端页面。并且在上面,我们看到autodl-nas即我们刚刚使用的网盘。
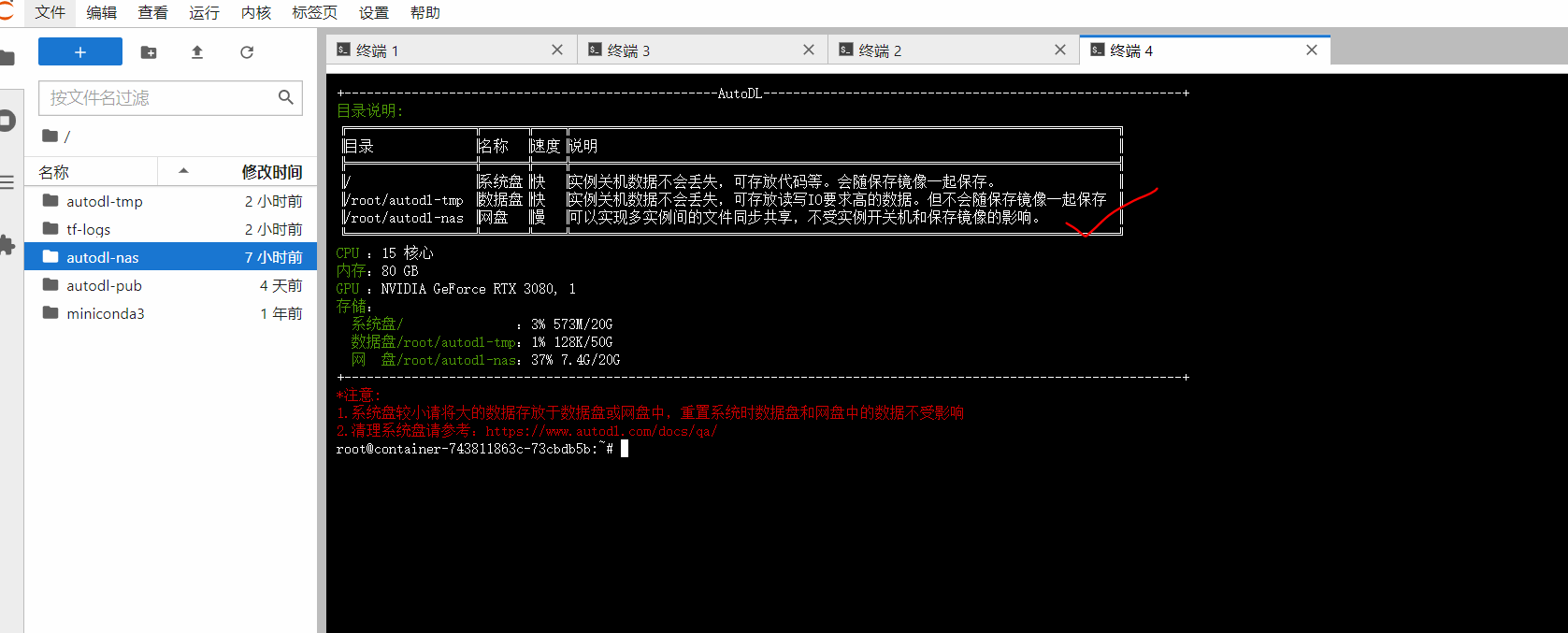
进入autodl-nas文件夹后,我们也可以看到,里面有刚刚新上传的三个zip文件。
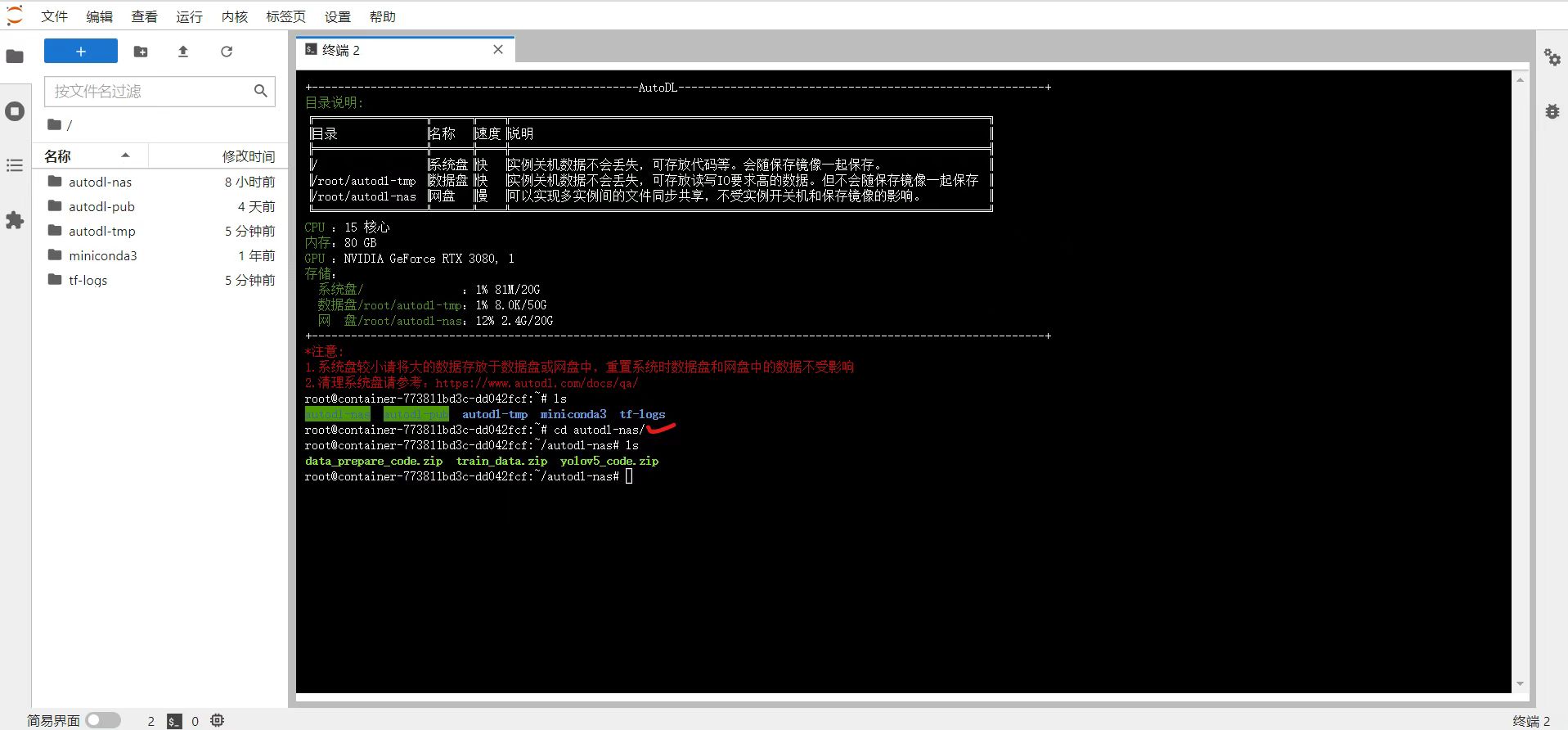
再将三个zip文件,使用unzip的方式进行解压。
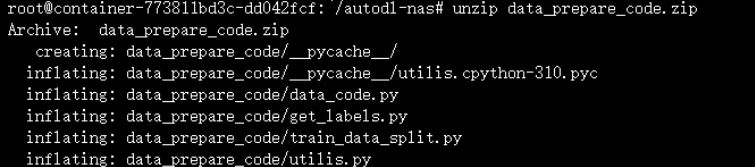
最后可以看到,三个文件夹都被解压缩成功。
7.标注文件xml格式转换txt格式
先查看一下训练数据集train_data的路径,因为会涉及到转换后的txt路径,在云服务器上运行加训练。先cd train_data文件夹,再输入pwd,可以看到这时的数据集路径是:/root/autodl-nas/train_data。

然后再去修改代码中的路径,首先cd data_prepare_code文件夹里,再vim train_data_split.py,使用前面的阶段三中的代码,将标注的人体xml文件转换成txt文件。

vim train_data_split.py后,打开页面,拖到最下方,即这个部分。
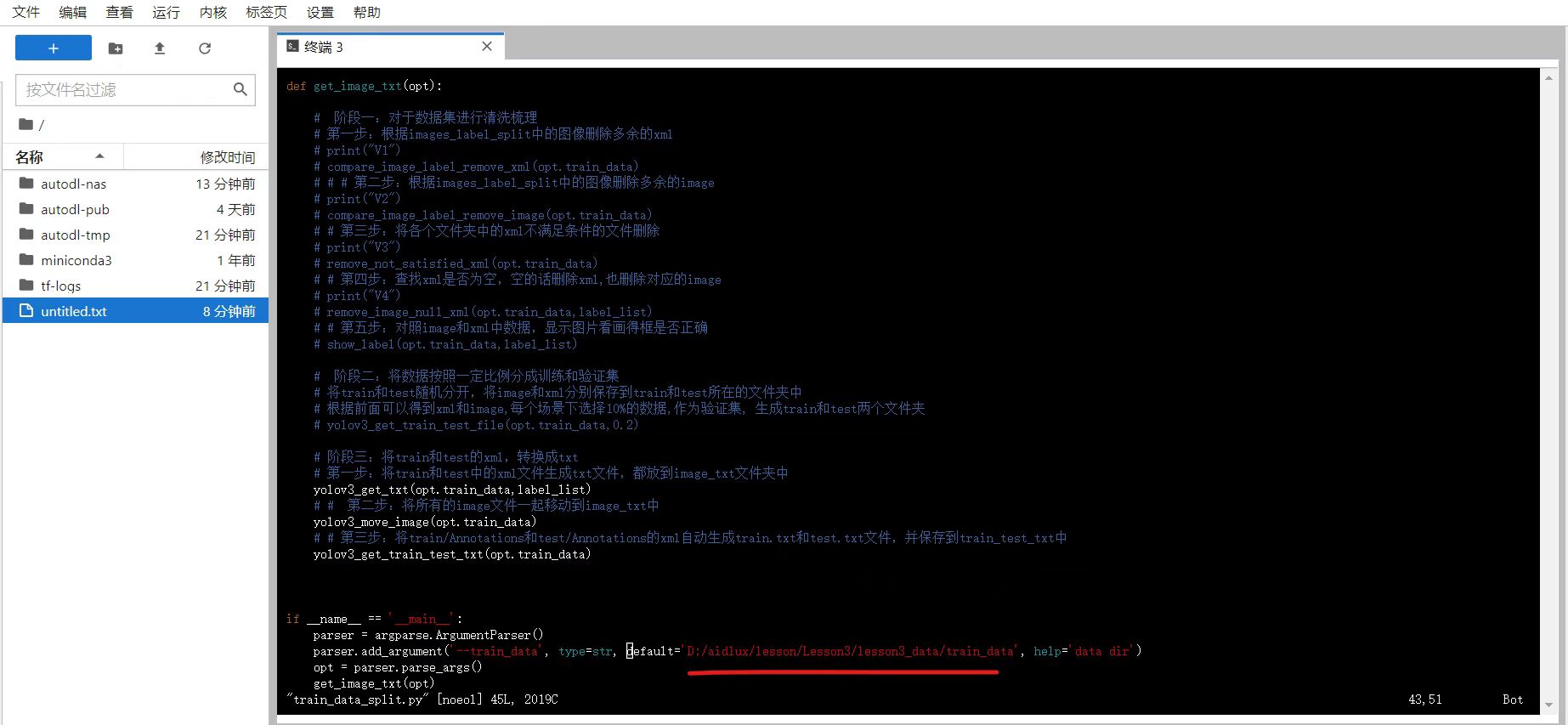
按键盘上的“i”,进入代码的编辑状态,移动到路径处,修改成云服务器上对应的路径,大白这里是/root/autodl-nas/train_data,大家可以对应修改。
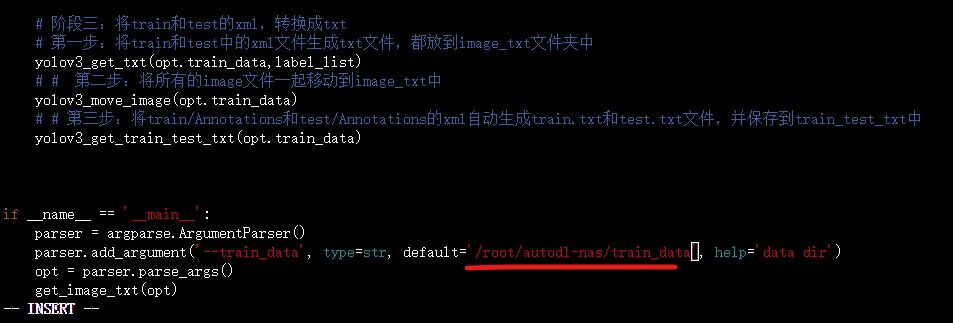
修改完成后,按键盘上的Esc键,跳出编辑状态。再输入“:”,会跳出输入框,再输入"wq!",表示对于该修改内容,保存编辑强制退出,回到原始页面。
因为云服务器我们刚刚新建实例的时候,没有安装任何安装包。所以先pip install opencv-python,安装一下。

将xml转换成txt格式进行中。

再进入train_data文件夹中,会发现多了两个文件夹,即训练时可以使用。

8.训练人体检测模型
训练人体模型,主要就用到/autodl-nas/yolov5_code文件了,不过在训练之前还要修改一下参数。
(1)新建person.yaml
因为训练的是人体检测模型,所以在yolov5_code/data文件夹中,新增一个person.yaml。不过需要注意的是,训练集和验证集的路径都要修改一下,此外还有类别数,以及类别标签。
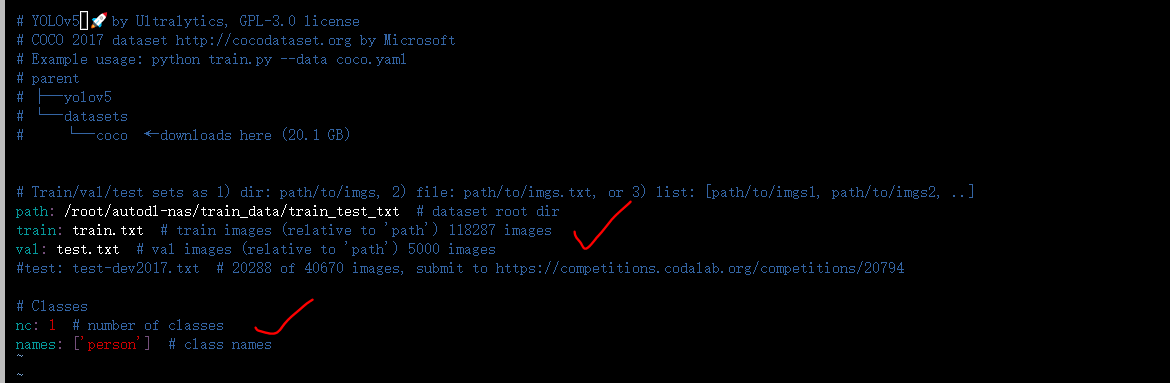
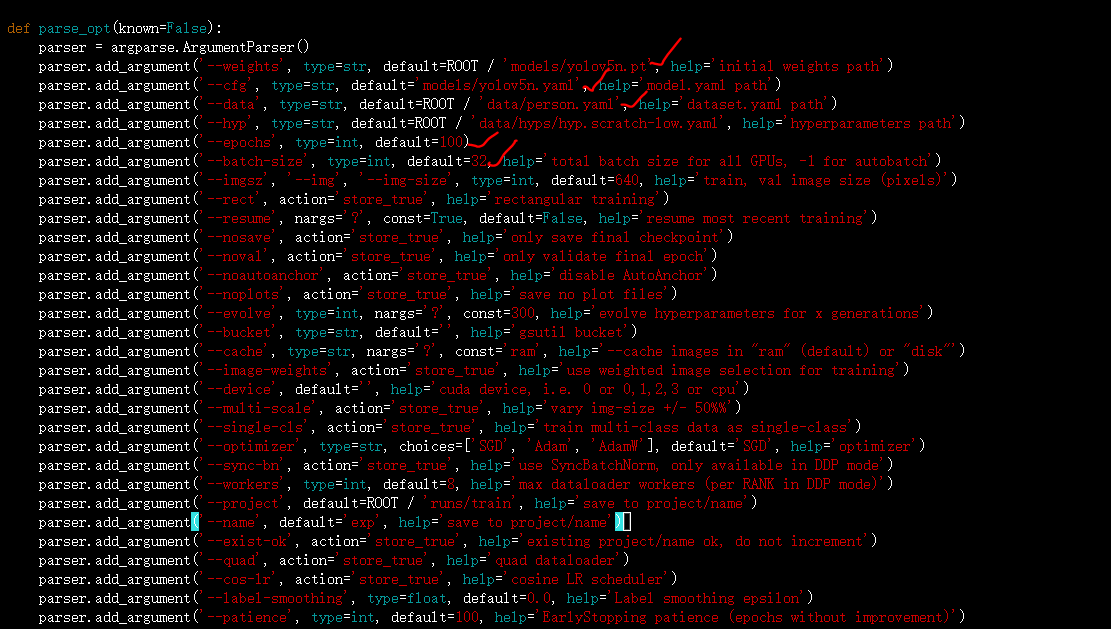
(2)修改train.py参数
而yolov5_code/train.py文件中,主要修改models初始化模型的路径,这里大白使用的yolov5n的模型权重。cfg即模型对应的网络结构路径,data是新增的person.yaml路径。此外还有epochs训练迭代的次数,batch-size大小,当然imgsz也可以修改,这里大白默认640。
(3)修改models/yolov5n.yaml
修改其中的类别数量,因为人体就一个类别,修改成1。
(4)训练人体检测模型
因为训练的时候,需要一系列的库文件,所以回到yolov5_code的路径下,输入 pip install -r requirements,安装一系列的库文件。
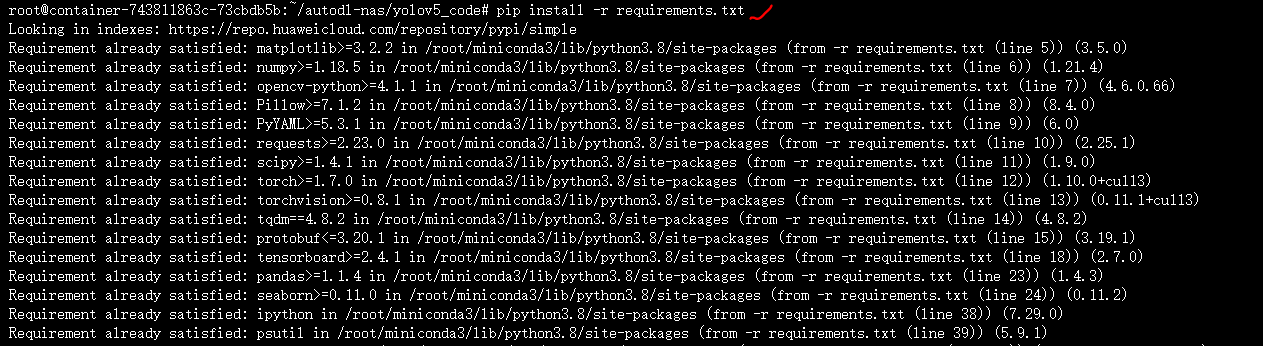
当然大家如果遇到tqdm安装的报错,可以输入pip install tqdm,看下有哪些版本,找对应的版本下载,如果没有报错,就可以直接跳过。
安装完成后,输入python train.py,就可以开始训练了。
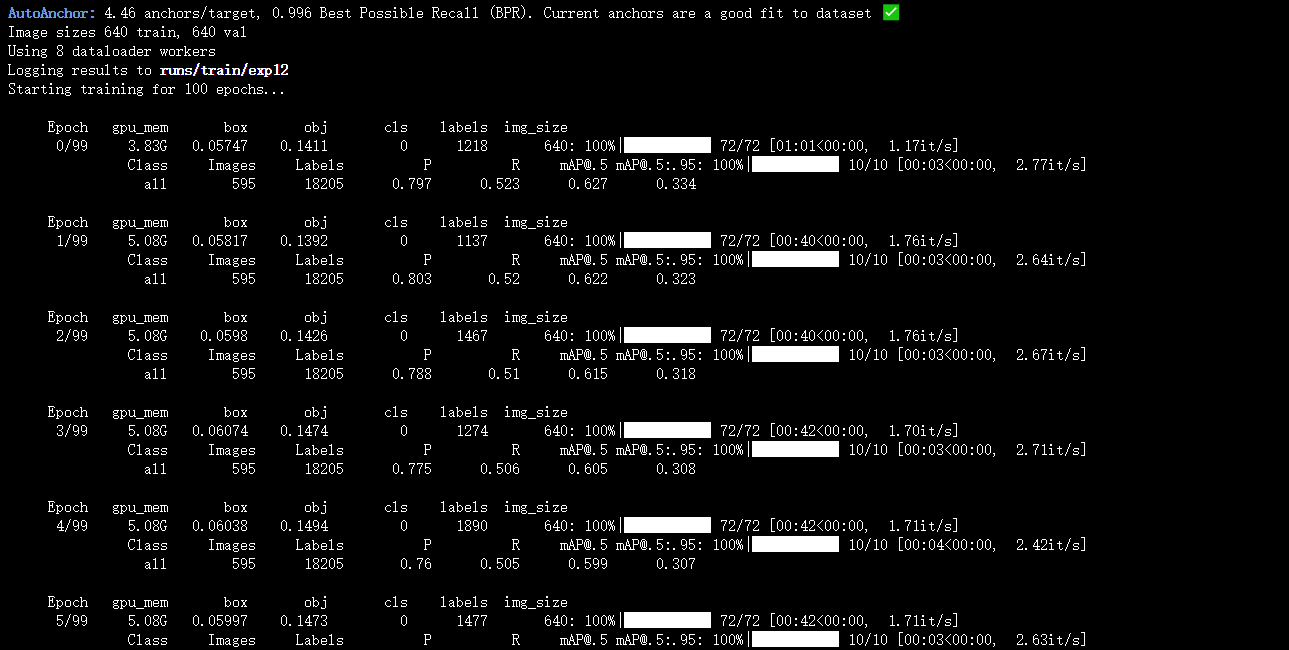
训练过程中,一般会得到两个模型,一个best.pt,即epoch迭代的过程中,map精度对比比较好保存的模型。一个是last.pt,即迭代过程中,最后一次epoch保存的模型。比如大白训练过程中,保存的这两个,在后面测试的时候,主要使用best.pt文件。

9 下载检测模型
在AutoDL的我的网盘,找到runs下面最新训练人体检测模型,路径可以参考:
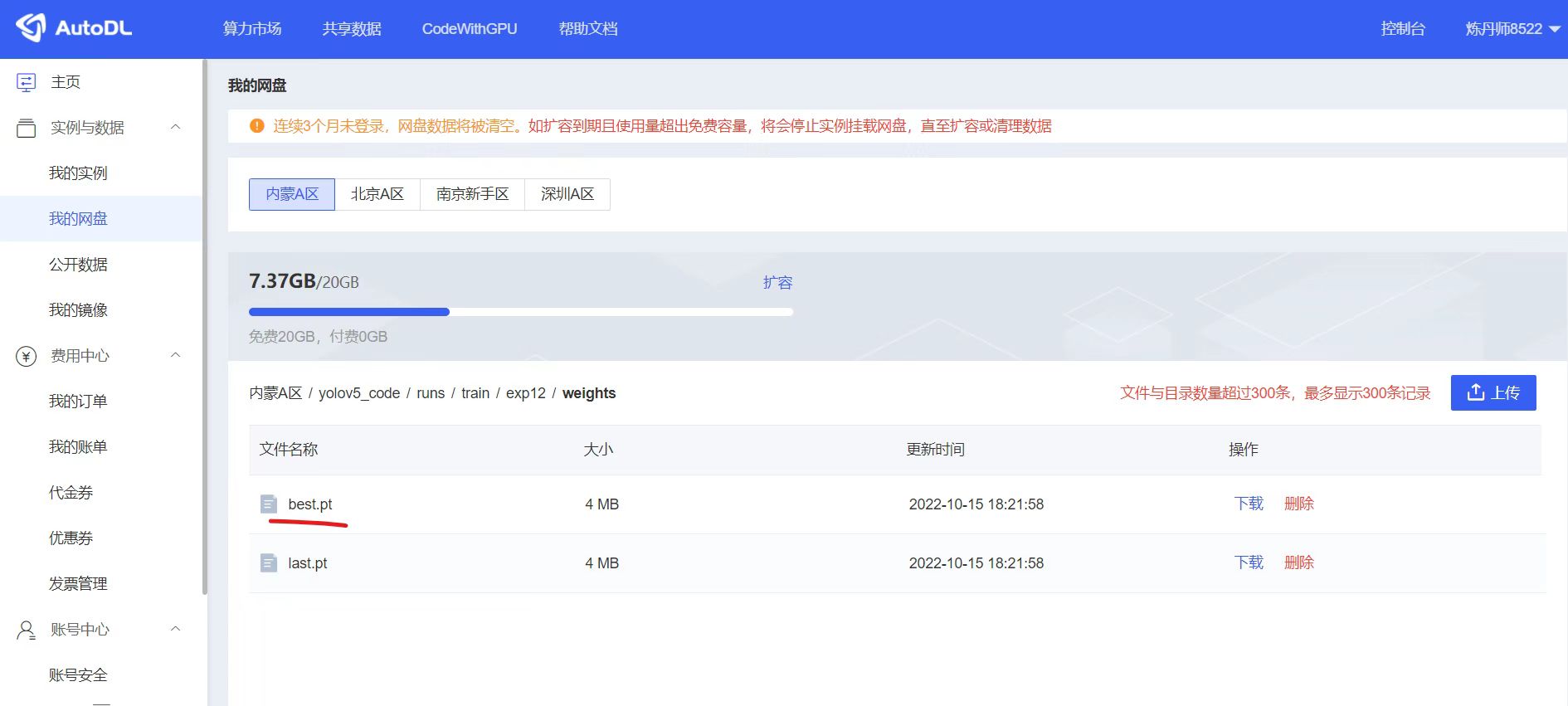
将best.pt模型下载下来,修改成yolov5n_best.pt。并放到资料包代码文件夹中。
得到训练结果以后,就可以将参数文件下载到本地中用于本地测试了。
我正在尝试使用ruby和Savon来使用网络服务。测试服务为http://www.webservicex.net/WS/WSDetails.aspx?WSID=9&CATID=2require'rubygems'require'savon'client=Savon::Client.new"http://www.webservicex.net/stockquote.asmx?WSDL"client.get_quotedo|soap|soap.body={:symbol=>"AAPL"}end返回SOAP异常。检查soap信封,在我看来soap请求没有正确的命名空间。任何人都可以建议我
我想安装一个带有一些身份验证的私有(private)Rubygem服务器。我希望能够使用公共(public)Ubuntu服务器托管内部gem。我读到了http://docs.rubygems.org/read/chapter/18.但是那个没有身份验证-如我所见。然后我读到了https://github.com/cwninja/geminabox.但是当我使用基本身份验证(他们在他们的Wiki中有)时,它会提示从我的服务器获取源。所以。如何制作带有身份验证的私有(private)Rubygem服务器?这是不可能的吗?谢谢。编辑:Geminabox问题。我尝试“捆绑”以安装新的gem..
尝试通过RVM将RubyGems升级到版本1.8.10并出现此错误:$rvmrubygemslatestRemovingoldRubygemsfiles...Installingrubygems-1.8.10forruby-1.9.2-p180...ERROR:Errorrunning'GEM_PATH="/Users/foo/.rvm/gems/ruby-1.9.2-p180:/Users/foo/.rvm/gems/ruby-1.9.2-p180@global:/Users/foo/.rvm/gems/ruby-1.9.2-p180:/Users/foo/.rvm/gems/rub
我正在使用puppet为ruby程序提供一组常量。我需要提供一组主机名,我的程序将对其进行迭代。在我之前使用的bash脚本中,我只是将它作为一个puppet变量hosts=>"host1,host2"我将其提供给bash脚本作为HOSTS=显然这对ruby不太适用——我需要它的格式hosts=["host1","host2"]自从phosts和putsmy_array.inspect提供输出["host1","host2"]我希望使用其中之一。不幸的是,我终其一生都无法弄清楚如何让它发挥作用。我尝试了以下各项:我发现某处他们指出我需要在函数调用前放置“function_”……这
我正在编写一个gem,我必须在其中fork两个启动两个webrick服务器的进程。我想通过基类的类方法启动这个服务器,因为应该只有这两个服务器在运行,而不是多个。在运行时,我想调用这两个服务器上的一些方法来更改变量。我的问题是,我无法通过基类的类方法访问fork的实例变量。此外,我不能在我的基类中使用线程,因为在幕后我正在使用另一个不是线程安全的库。所以我必须将每个服务器派生到它自己的进程。我用类变量试过了,比如@@server。但是当我试图通过基类访问这个变量时,它是nil。我读到在Ruby中不可能在分支之间共享类变量,对吗?那么,还有其他解决办法吗?我考虑过使用单例,但我不确定这是
我的最终目标是安装当前版本的RubyonRails。我在OSXMountainLion上运行。到目前为止,这是我的过程:已安装的RVM$\curl-Lhttps://get.rvm.io|bash-sstable检查已知(我假设已批准)安装$rvmlistknown我看到当前的稳定版本可用[ruby-]2.0.0[-p247]输入命令安装$rvminstall2.0.0-p247注意:我也试过这些安装命令$rvminstallruby-2.0.0-p247$rvminstallruby=2.0.0-p247我很快就无处可去了。结果:$rvminstall2.0.0-p247Search
最近,当我启动我的Rails服务器时,我收到了一长串警告。虽然它不影响我的应用程序,但我想知道如何解决这些警告。我的估计是imagemagick以某种方式被调用了两次?当我在警告前后检查我的git日志时。我想知道如何解决这个问题。-bcrypt-ruby(3.1.2)-better_errors(1.0.1)+bcrypt(3.1.7)+bcrypt-ruby(3.1.5)-bcrypt(>=3.1.3)+better_errors(1.1.0)bcrypt和imagemagick有关系吗?/Users/rbchris/.rbenv/versions/2.0.0-p247/lib/ru
我在理解Enumerator.new方法的工作原理时遇到了一些困难。假设文档中的示例:fib=Enumerator.newdo|y|a=b=1loopdoy[1,1,2,3,5,8,13,21,34,55]循环中断条件在哪里,它如何知道循环应该迭代多少次(因为它没有任何明确的中断条件并且看起来像无限循环)? 最佳答案 Enumerator使用Fibers在内部。您的示例等效于:require'fiber'fiber=Fiber.newdoa=b=1loopdoFiber.yieldaa,b=b,a+bendend10.times.m
在Rails4.0.2中,我使用s3_direct_upload和aws-sdkgems直接为s3存储桶上传文件。在开发环境中它工作正常,但在生产环境中它会抛出如下错误,ActionView::Template::Error(noimplicitconversionofnilintoString)在View中,create_cv_url,:id=>"s3_uploader",:key=>"cv_uploads/{unique_id}/${filename}",:key_starts_with=>"cv_uploads/",:callback_param=>"cv[direct_uplo
几个月前,我读了一篇关于rubygem的博客文章,它可以通过阅读代码本身来确定编程语言。对于我的生活,我不记得博客或gem的名称。谷歌搜索“ruby编程语言猜测”及其变体也无济于事。有人碰巧知道相关gem的名称吗? 最佳答案 是这个吗:http://github.com/chrislo/sourceclassifier/tree/master 关于ruby-寻找通过阅读代码确定编程语言的rubygem?,我们在StackOverflow上找到一个类似的问题: