SQLAlchemy是一个关系型数据库框架,它提供了高层的 ORM 和底层的原生数据库的操作。
flask-sqlalchemy是一个简化了SQLAlchemy操作的flask扩展。
ORM(Object-Relation Mapping 称为对象-关系映射):
主要实现模型对象到关系数据库数据的映射,比如:把数据库表中每条记录映射为一个模型对象
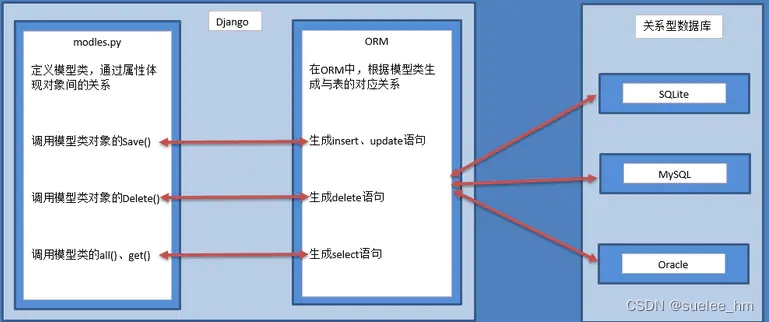
ORM提供了一种持久化模式,可以高效地对数据库进行访问。它可以把底层的 RDBMS 封装成业务实体对象,提供给业务逻辑层使用。程序员往往关注业务逻辑层面,而不是底层数据库该如何访问,以及如何编写 SQL 语句获取数据等等。采用 ORM,就可以从数据库的设计层面转化成面向对象的思维。
环境:window11+pycharm2020.1+Anaconda4.11.0 +python3.7
Flask-sqlalchemy2.5.1
Flask-Migrate:3.1.0
源代码:https://github.com/sueleeyu/flask_api_ar
1.安装pymysql,打开控制台,输入:
pip install pymysql
2.安装flask-sqlalchemy,打开控制台,输入:
pip install flask-sqlalchemy

3.安装Flask-Migrate,打开控制台,输入:
pip install flask-migrate
解决Flask-migrate安装和遇到的问题:Python入门-Flask-migrate安装和使用:
Python入门-Flask-migrate安装和使用_suelee_hm的博客-CSDN博客
flask-sqlalchemy操作数据库,使用起来比较简单,易于操作。常用的配置如下:

常用的SQLAlchemy字段类型:
| 类型名 | python中类型 | 说明 |
| Integer | int | 普通整数,一般是32位 |
| SmallInteger | int | 取值范围小的整数,一般是16位 |
| BigInteger | int或long | 不限制精度的整数 |
| Float | float | 浮点数 |
| Numeric | decimal.Decimal | 普通整数,一般是32位 |
| String | str | 变长字符串 |
| Text | str | 变长字符串,对较长或不限长度的字符串做了优化 |
| Unicode | unicode | 变长Unicode字符串 |
| UnicodeText | unicode | 变长Unicode字符串,对较长或不限长度的字符串做了优化 |
| Boolean | bool | 布尔值 |
| Date | datetime.date | 时间 |
| Time | datetime.datetime | 日期和时间 |
| LargeBinary | str | 二进制文件 |
常用的SQLAlchemy列选项:
| 选项名 | 说明 |
| primary_key | 如果为True,代表表的主键 |
| unique | 如果为True,代表这列不允许出现重复的值 |
| index | 如果为True,为这列创建索引,提高查询效率 |
| nullable | 如果为True,允许有空值,如果为False,不允许有空值 |
| default | 为这列定义默认值 |
常用的SQLAlchemy关系选项:
| 选项名 | 说明 |
| backref | 在关系的另一模型中添加反向引用 |
| primary join | 明确指定两个模型之间使用的联结条件 |
| uselist | 如果为False,不使用列表,而使用标量值 |
| order_by | 指定关系中记录的排序方式 |
| secondary | 指定多对多关系中关系表的名字 |
| secondary join | 在SQLAlchemy中无法自行决定时,指定多对多关系中的二级联结条件 |
1.创建db对象。新建exts.py文件:
# 存放db变量
from flask_sqlalchemy import SQLAlchemy
db = SQLAlchemy()
2.创建配置文件。新建configs.py文件:
# -*- coding: UTF-8 -*-
# 配置文件
# 数据库信息
HOST = 'xxx.cn'
PORT = '3306'
DATABASE = 'db'
USERNAME = 'root'
PASSWORD = 'root'
DB_URI = 'mysql+mysqldb://{}:{}@{}:{}/{}'.format(USERNAME, PASSWORD, HOSTNAME, PORT, DATABASE)
# 数据库连接编码
DB_CHARSET = "utf8"
SQLALCHEMY_DATABASE_URI = DB_URI
SQLALCHEMY_TRACK_MODIFICATIONS = False
SQLALCHEMY_ECHO = True
3.绑定app。新建app.py,编写代码创建app,注册蓝图:
# app.py
# 主app文件,运行文件
from flask import Flask
from flask_migrate import Migrate
from controller import ar
import configs
from exts import db
def create_app():
app1 = Flask(__name__)
# 注册蓝图
app1.register_blueprint(ar, url_prefix='/ar')
# 加载配置文件
app1.config.from_object(configs)
# db绑定app
db.init_app(app1)
# 要让Flask-Migrate能够管理app中的数据库,需要使用Migrate(app,db)来绑定app和数据库。假如现在有以下app文件
# 绑定app和数据库
migrate = Migrate(app=app1, db=db)
return app1
app = create_app()
if __name__ == '__main__':
#app = create_app()
app.run()
4.创建表。新建models.py,编写每个数据库表类:
# models.py
# 模型文件,用来存放所有的模型
from exts import db
"""
以下表关系:
一个用户对应多个(一对多)
"""
"""
一对一关系中,需要设置relationship中的uselist=Flase,其他数据库操作一样。
一对多关系中,外键设置在多的一方中,关系(relationship)可设置在任意一方。
多对多关系中,需建立关系表,设置 secondary=关系表
"""
if __name__ == '__main__':
import app
app1 = app.create_app()
app1.run()
# 用户表
class ARUser(db.Model): # User 模型名
__tablename__ = 'ar_user' # 表名
id = db.Column(db.BigInteger, primary_key=True, autoincrement=True) # id,主键自增
user_name = db.Column(db.String(20), index=True) # 用户名称
create_time = db.Column(db.TIMESTAMP)
update_time = db.Column(db.TIMESTAMP)
# relationship
# 1.第一个参数是模型的名字,必须要和模型的名字一致
# 2.backref(bsck reference):代表反向引用,代表对方访问我的时候的字段名称
geospatials = db.relationship('GeoHistory', backref='ARUser', lazy='select') # 添加关系
def __init__(self, name):
self.user_name = name
# Geospatial锚点表
class GeoHistory(db.Model): # GeoHistory 模型名
__tablename__ = 'ar_geo_history' # 表名
id = db.Column(db.BigInteger, primary_key=True, autoincrement=True) # id,主键自增
bid = db.Column(db.String(20), index=True) # geo id
# 外键
# 1.外键的数据类型一定要看所引用的字段类型,要一样
# 2. db.Foreignkey("表名. 字段名")fl
# 3.外键是属于数据库层面的,不推荐直接在ORM直接使用
uid = db.Column(db.BigInteger, db.ForeignKey('ar_user.id')) # 用户 id,设置外键
name = db.Column(db.String(20), index=True) # 锚点名称
latitude = db.Column(db.Float)
longitude = db.Column(db.Float)
altitude = db.Column(db.Float)
heading = db.Column(db.Float) # 手机摄像头朝向
state = db.Column(db.SmallInteger) # 锚点状态 0隐藏,1显示
create_time = db.Column(db.TIMESTAMP)
update_time = db.Column(db.TIMESTAMP)
def __init__(self, bid, name, latitude, longitude, altitude, heading):
self.bid = bid
self.name = name
self.latitude = latitude
self.longitude = longitude
self.altitude = altitude
self.heading = heading
db.relationship和backref的用处:
5.映射表。创建好表后需要映射到数据库中,这里需要用到flask-migrate库。
app.py中的Migrate绑定代码:
# db绑定app
db.init_app(app)
# 要让Flask-Migrate能够管理app中的数据库,需要使用Migrate(app,db)来绑定app和数据库。假如现在有以下app文件
# 绑定app和数据库
migrate = Migrate(app=app, db=db)
pycharm进入控制台:
执行init命令,初始化一个迁移文件夹:
flask db init
执行migrate命令,把当前的模型添加到迁移文件中:
flask db migrate
执行update命令,把迁移文件中对应的数据库操作,真正的映射到数据库中:
flask db upgrade
执行完毕,数据库中会生成和models.py中对应的表:

Request请求有GET和POST两种,flask获取参数的方式:
route装饰器通过methods指定请求方式,默认为GET:
@app.route('/ar/add_anchor', methods=['POST'])
GET:参数在url中,可用以下两种方式获取参数:
POST:
POST请求的发送通过Content-Type标记不同数据。
不同Content-Type的处理方式:
a. application/json:
请求:
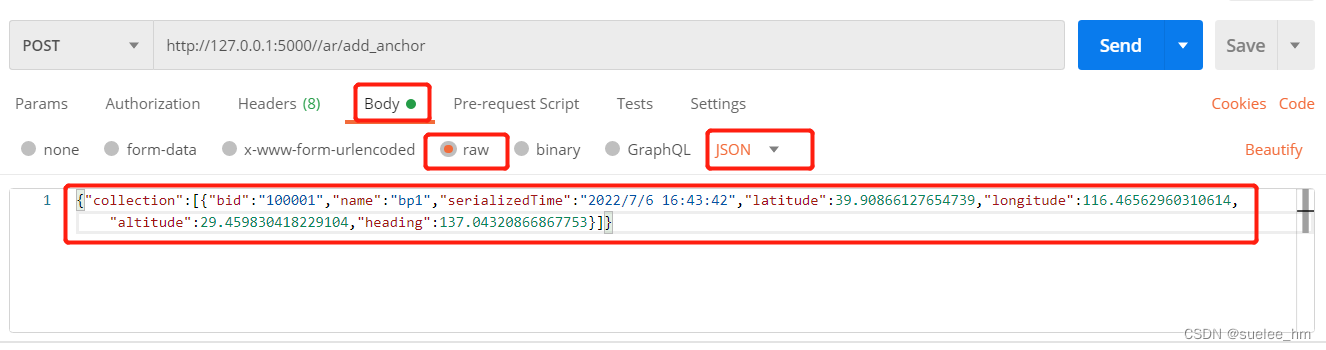
接收:
jdata = request.get_json() # 或者 request.json.get('content')
b. application/x-www-form-urlencoded:
请求:
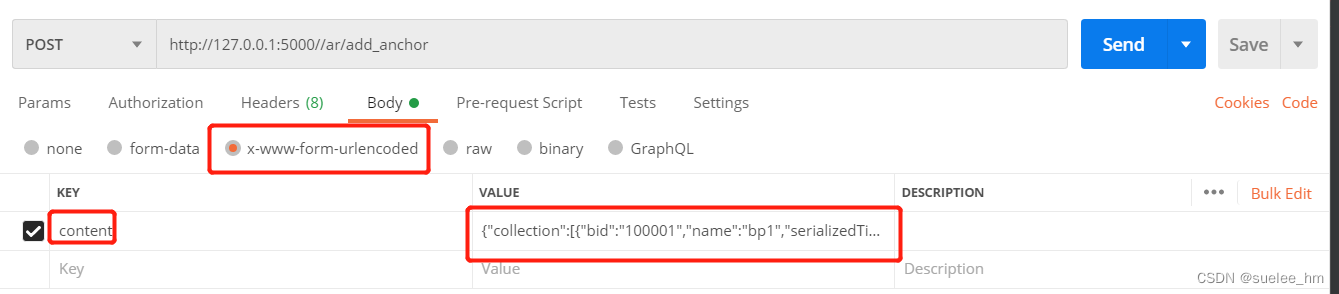
接收:
jdata = request.values.get("content")
c. multipart/form-data
请求:
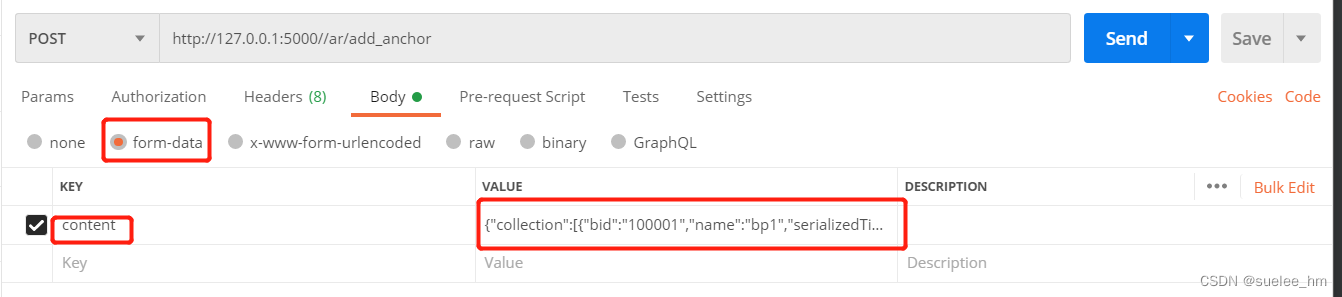
接收:
jdata = request.form.get('content')
1.插入:
geoHistory = GeoHistory("100001", "bp1", 39.4632, 116.3679, 28.3135, 137.1354)
db.session.add(geoHistory)
db.session.commit()
批量插入:
geoHistory = GeoHistory("100001", "bp1", 39.4632, 116.3679, 28.3135, 137.1354)
geoHistory2 = GeoHistory("100001", "bp2", 39.4632, 116.3679, 28.3135, 137.1354)
db.session.add(geoHistory) # 插入一个
db.session.commit()
anchors = [geoHistory, geoHistory2]
# 批量
db.session.execute(GeoHistory.__table__.insert(), anchors) # SQLAlchemy Core
db.session.commit()
# 批量 or
db.session.add_all(anchors)
db.session.commit()
2.查询
Filter进行过滤,filter内条件为and。limit限制数据:
latitude_min, latitude_max, longitude_min, longitude_max = utils.get_area(latitude, longitude, 1000)
anchors = GeoHistory.query.filter(
GeoHistory.latitude.between(latitude_min, latitude_max),
GeoHistory.longitude.between(longitude_min, longitude_max)).limit(
20).all()
1.入口
@app.route('/')
def hello_world():
return 'Hello World!'
2.app内注册蓝图:
# 注册蓝图
app1.register_blueprint(ar, url_prefix='/ar')
3.新建controller.py,创建蓝图,编写接口:
from flask import Blueprint, request
from R import R
from service import ARService
ar = Blueprint("ar", __name__)
@ar.route('/nearby')
def nearby():
latitude = float(request.args.get('latitude'))
longitude = float(request.values.get('longitude'))
result = ARService.query_histories(latitude, longitude)
return R.ok(result)
@ar.route('/add_anchors', methods=["GET", "POST"])
def add_anchor():
json_data = ''
if request.method == "GET":
json_data = request.args.get("content")
if request.method == "POST":
if request.content_type.startswith('application/json'):
json_data = request.get_json()
# application/json 获取的原始参数,接受的是type是'bytes’的对象,如:b{'name':'lucy', 'age':22}
# data = request.get_data()
elif request.content_type.startswith('multipart/form-data'):
json_data = request.form.get('content')
else:
json_data = request.values.get("content")
anchors = json_data["collection"]
ARService.add_anchor(anchors)
return R.ok(data=None)
4.新建service.py,实现数据逻辑:
import utils
from models import GeoHistory
from exts import db
from utils import O2d
class ARService(object):
@staticmethod
def query_histories(latitude, longitude):
# 查询所有
latitude_min, latitude_max, longitude_min, longitude_max = utils.get_area(latitude, longitude, 1000)
anchors = GeoHistory.query.filter(
GeoHistory.latitude.between(latitude_min, latitude_max),
GeoHistory.longitude.between(longitude_min, longitude_max)).limit(
20).all()
return O2d.obj_to_list(anchors)
@staticmethod
def add_anchor(anchors):
db.session.execute(GeoHistory.__table__.insert(), anchors) # SQLAlchemy Core
db.session.commit()
if __name__ == '__main__':
geoHistory = GeoHistory("100001", "bp1", 39.4632, 116.3679, 28.3135, 137.1354)
geoHistory2 = GeoHistory("100001", "bp2", 39.4632, 116.3679, 28.3135, 137.1354)
测试Json数据:
{"collection":[{"bid":"100001","name":"bp1","serializedTime":"2022/7/6 16:43:42","latitude":39.90866127654739,"longitude":116.46562960310614,"altitude":29.459830418229104,"heading":137.04320866867753}]}
Content-Type:application/json
utils.py:
class O2d:
@staticmethod
def obj_to_dic(obj):
'''
将传入的data对象转成字典
'''
result = {}
for temp in obj.__dict__:
if temp.startswith('_') or temp == 'metadata':
continue
result[temp] = getattr(obj, temp)
return result
@staticmethod
def obj_to_list(list_obj):
'''
将传入的data对象转成List,list中的元素是字典
'''
result = []
for obj in list_obj:
result.append(O2d.obj_to_dic(obj))
return result
[1] flask-migrate文档:
Flask-Migrate — Flask-Migrate documentation
[1] 源代码: https://github.com/sueleeyu/flask_api_ar
关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭4年前。Improvethisquestion我想在固定时间创建一系列低音和高音调的哔哔声。例如:在150毫秒时发出高音调的蜂鸣声在151毫秒时发出低音调的蜂鸣声200毫秒时发出低音调的蜂鸣声250毫秒的高音调蜂鸣声有没有办法在Ruby或Python中做到这一点?我真的不在乎输出编码是什么(.wav、.mp3、.ogg等等),但我确实想创建一个输出文件。
我正在查看instance_variable_set的文档并看到给出的示例代码是这样做的:obj.instance_variable_set(:@instnc_var,"valuefortheinstancevariable")然后允许您在类的任何实例方法中以@instnc_var的形式访问该变量。我想知道为什么在@instnc_var之前需要一个冒号:。冒号有什么作用? 最佳答案 我的第一直觉是告诉你不要使用instance_variable_set除非你真的知道你用它做什么。它本质上是一种元编程工具或绕过实例变量可见性的黑客攻击
在我的应用程序中,我需要能够找到所有数字子字符串,然后扫描每个子字符串,找到第一个匹配范围(例如5到15之间)的子字符串,并将该实例替换为另一个字符串“X”。我的测试字符串s="1foo100bar10gee1"我的初始模式是1个或多个数字的任何字符串,例如,re=Regexp.new(/\d+/)matches=s.scan(re)给出["1","100","10","1"]如果我想用“X”替换第N个匹配项,并且只替换第N个匹配项,我该怎么做?例如,如果我想替换第三个匹配项“10”(匹配项[2]),我不能只说s[matches[2]]="X"因为它做了两次替换“1fooX0barXg
我有一个正在构建的应用程序,我需要一个模型来创建另一个模型的实例。我希望每辆车都有4个轮胎。汽车模型classCar轮胎模型classTire但是,在make_tires内部有一个错误,如果我为Tire尝试它,则没有用于创建或新建的activerecord方法。当我检查轮胎时,它没有这些方法。我该如何补救?错误是这样的:未定义的方法'create'forActiveRecord::AttributeMethods::Serialization::Tire::Module我测试了两个环境:测试和开发,它们都因相同的错误而失败。 最佳答案
我正在处理旧代码的一部分。beforedoallow_any_instance_of(SportRateManager).toreceive(:create).and_return(true)endRubocop错误如下:Avoidstubbingusing'allow_any_instance_of'我读到了RuboCop::RSpec:AnyInstance我试着像下面那样改变它。由此beforedoallow_any_instance_of(SportRateManager).toreceive(:create).and_return(true)end对此:let(:sport_
我收到格式为的回复#我需要将其转换为哈希值(针对活跃商家)。目前我正在遍历变量并执行此操作:response.instance_variables.eachdo|r|my_hash.merge!(r.to_s.delete("@").intern=>response.instance_eval(r.to_s.delete("@")))end这有效,它将生成{:first="charlie",:last=>"kelly"},但它似乎有点hacky和不稳定。有更好的方法吗?编辑:我刚刚意识到我可以使用instance_variable_get作为该等式的第二部分,但这仍然是主要问题。
这个问题在这里已经有了答案:关闭10年前。PossibleDuplicate:Pythonconditionalassignmentoperator对于这样一个简单的问题表示歉意,但是谷歌搜索||=并不是很有帮助;)Python中是否有与Ruby和Perl中的||=语句等效的语句?例如:foo="hey"foo||="what"#assignfooifit'sundefined#fooisstill"hey"bar||="yeah"#baris"yeah"另外,类似这样的东西的通用术语是什么?条件分配是我的第一个猜测,但Wikipediapage跟我想的不太一样。
什么是ruby的rack或python的Java的wsgi?还有一个路由库。 最佳答案 来自Python标准PEP333:Bycontrast,althoughJavahasjustasmanywebapplicationframeworksavailable,Java's"servlet"APImakesitpossibleforapplicationswrittenwithanyJavawebapplicationframeworktoruninanywebserverthatsupportstheservletAPI.ht
华为OD机试题本篇题目:明明的随机数题目输入描述输出描述:示例1输入输出说明代码编写思路最近更新的博客华为od2023|什么是华为od,od薪资待遇,od机试题清单华为OD机试真题大全,用Python解华为机试题|机试宝典【华为OD机试】全流程解析+经验分享,题型分享,防作弊指南华为o
文章目录一、概述简介原理模块二、配置Mysql使用版本环境要求1.操作系统2.mysql要求三、配置canal-server离线下载在线下载上传解压修改配置单机配置集群配置分库分表配置1.修改全局配置2.实例配置垂直分库水平分库3.修改group-instance.xml4.启动监听四、配置canal-adapter1修改启动配置2配置映射文件3启动ES数据同步查询所有订阅同步数据同步开关启动4.验证五、配置canal-admin一、概述简介canal是Alibaba旗下的一款开源项目,Java开发。基于数据库增量日志解析,提供增量数据订阅&消费。Git地址:https://github.co