为了更好的阅读体验,请点击这里
本文大部分内容翻译自 Chapter 1 - Basics,原因是之前翻译的版本太老了,不得不亲自披挂上阵拿机器翻译一下。只截取了部分自己可能用得到的,所以如果有看不太懂的地方,去翻一下原网页吧。QWQ
附赠 libzmq 的 api 接口函数说明 一份。
int zmq_recv (void *socket, void *buf, size_t len, int flags);
zmq_recv() 函数应从 socket 参数引用的套接字接收消息,并将其存储在 buf 参数引用的缓冲区中。任何超过 len 参数指定长度的字节都将被截断。如果指定套接字上没有可用消息,则 zmq_recv() 函数将阻塞,直到请求得到满足。 flags 参数是下面定义的标志的组合: 如果 len 为零,则 buf 参数可以为 null。
int zmq_send (void *socket, void *buf, size_t len, int flags);
zmq_send() 函数应排队从 buf 和 len 参数引用的缓冲区创建的消息。
int zmq_setsockopt (void *socket, int option_name, const void *option_value, size_t option_len);
zmq_setsockopt() 函数应将 option_name 参数指定的选项设置为 option_value 参数指向的值,用于 socket 参数指向的 ØMQ 套接字。option_len 参数是以字节为单位的选项值的大小。对于采用“字符串”类型值的选项,提供的字节数据应该不包含零字节,或者以单个零字节结尾(终止 ASCII NUL 字符)。
void *zmq_ctx_new ();
创建新的 ZeroMQ context。如果成功的话,这个函数会为新创建的上下文返回一个 opaque 句柄。否则返回 NULL。
void *zmq_socket (void *context, int type);
这个函数使用具体的上下文创建一个 zmq 套接字并为新创建的套接字返回一个 opaque 句柄。type 参数指定了套接字的类型,这决定了在套接字上的对话语义。
新创建的套接字开始是未绑定的,同时不与任何端点有联系。为了做到一个消息跟着套接字流动这样的操作,必须用 zmq_connect() 连接至少一个端点,或者是至少一个端点必须被使用 zmq_bind() 创建为了传入的连接。
int zmq_bind (void *socket, const char *endpoint); 在一个套接字上接受传入的连接。
这个函数绑定套接字到一个局部的端点然后在这个端点上接受传入的连接。
endpoint 参数是一个包含了 transport:// 跟随着一个 地址 的字符串。transport 指定了是用什么协议。地址 决定了绑定到哪个地址。
该函数支持以下协议:
int zmq_connect (void *socket, const char *endpoint); 从套接字上创建发出的连接。
这个函数把套接字连接到端点上然后在那个端点上接受传入的连接。
endpoint 参数是一个包含了 transport:// 跟随着一个 地址 的字符串。transport 指定了是用什么协议。地址 决定了连接到哪个地址。
该函数支持的协议同上。
由于其他语言的字符串格式不像 C 的格式是 str\0 而是 str 的,因此需要手动添加最后的终止符。因此原教程编写了比较方便使用的方法。原文中建立了一个规则,即 ZeroMQ 字符串是指定长度的,并且在没有尾随 null 的情况下在线发送。在最简单的情况下(我们将在示例中这样做),一个 ZeroMQ 字符串巧妙地映射到一个 ZeroMQ 消息帧。
在 C 中,接收 ZeroMQ 字符串并将其作为有效的 C 字符串传递给应用程序:
// Receive ZeroMQ string from socket and convert into C string
// Chops string at 255 chars, if it's longer
static char *s_recv (void *socket) {
char buffer [256];
int size = zmq_recv (socket, buffer, 255, 0);
if (size == -1)
return NULL;
if (size > 255)
size = 255;
buffer [size] = \0;
/* use strndup(buffer, sizeof(buffer)-1) in *nix */
return strdup (buffer);
}
这形成了一个方便的辅助函数,本着让我们可以重用有利可图的东西的精神,让我们编写一个类似的 s_send 函数,以正确的 ZeroMQ 格式发送字符串,并将其打包到一个我们可以重用的头文件中。
结果是 zhelpers.h,这个头文件可以让我们可以用 C 编写更甜美和更短的 ZeroMQ 应用程序。这是一个相当长的源代码,并且只能在 C 中使用,所以请 在闲暇时阅读它。
从一个 Hello World 示例开始。我们将制作一个客户端和一个服务器。客户端向服务器发送“Hello”,服务器回复“World”。这是 C 中的服务器,它在端口 5555 上打开一个 ZeroMQ 套接字,读取其上的请求,并用“World”回复每个请求:
// Hello World server
#include <zmq.h>
#include <stdio.h>
#include <unistd.h>
#include <string.h>
#include <assert.h>
int main (void)
{
// Socket to talk to clients
void *context = zmq_ctx_new ();
void *responder = zmq_socket (context, ZMQ_REP);
int rc = zmq_bind (responder, "tcp://*:5555");
assert (rc == 0);
while (1) {
char buffer [10];
zmq_recv (responder, buffer, 10, 0);
printf ("Received Hello\n");
sleep (1); // Do some 'work'
zmq_send (responder, "World", 5, 0);
}
return 0;
}
// Hello World client
#include <zmq.h>
#include <string.h>
#include <stdio.h>
#include <unistd.h>
int main (void)
{
printf ("Connecting to hello world server...\n");
void *context = zmq_ctx_new ();
void *requester = zmq_socket (context, ZMQ_REQ);
zmq_connect (requester, "tcp://localhost:5555");
int request_nbr;
for (request_nbr = 0; request_nbr != 10; request_nbr++) {
char buffer [10];
printf ("Sending Hello %d...\n", request_nbr);
zmq_send (requester, "Hello", 5, 0);
zmq_recv (requester, buffer, 10, 0);
printf ("Received World %d\n", request_nbr);
}
zmq_close (requester);
zmq_ctx_destroy (context);
return 0;
}
如果您终止服务器 (Ctrl-C) 并重新启动它,客户端将无法正常恢复。从崩溃的进程中恢复并不是那么容易。
一个推送天气更新的示例,其中包含邮政编码、温度和相对湿度。我们将生成随机值,就像真实的气象站一样。
// Weather update server
// Binds PUB socket to tcp://*:5556
// Publishes random weather updates
#include "zhelpers.h"
int main (void)
{
// Prepare our context and publisher
void *context = zmq_ctx_new ();
void *publisher = zmq_socket (context, ZMQ_PUB);
int rc = zmq_bind (publisher, "tcp://*:5556");
assert (rc == 0);
// Initialize random number generator
srandom ((unsigned) time (NULL));
while (1) {
// Get values that will fool the boss
int zipcode, temperature, relhumidity;
zipcode = randof (100000);
temperature = randof (215) - 80;
relhumidity = randof (50) + 10;
// Send message to all subscribers
char update [20];
sprintf (update, "%05d %d %d", zipcode, temperature, relhumidity);
s_send (publisher, update);
}
zmq_close (publisher);
zmq_ctx_destroy (context);
return 0;
}
这种更新流没有开始也没有结束,就像一个永无止境的广播。
这是客户端应用程序,它侦听更新流并获取与指定邮政编码有关的任何内容,默认情况下是纽约市,因为这是开始任何冒险的好地方:
// Weather update client
// Connects SUB socket to tcp://localhost:5556
// Collects weather updates and finds avg temp in zipcode
#include "zhelpers.h"
int main (int argc, char *argv [])
{
// Socket to talk to server
printf ("Collecting updates from weather server...\n");
void *context = zmq_ctx_new ();
void *subscriber = zmq_socket (context, ZMQ_SUB);
int rc = zmq_connect (subscriber, "tcp://localhost:5556");
assert (rc == 0);
// Subscribe to zipcode, default is NYC, 10001
const char *filter = (argc > 1)? argv [1]: "10001 ";
rc = zmq_setsockopt (subscriber, ZMQ_SUBSCRIBE,
filter, strlen (filter));
assert (rc == 0);
// Process 100 updates
int update_nbr;
long total_temp = 0;
for (update_nbr = 0; update_nbr < 100; update_nbr++) {
char *string = s_recv (subscriber);
int zipcode, temperature, relhumidity;
sscanf (string, "%d %d %d",
&zipcode, &temperature, &relhumidity);
total_temp += temperature;
free (string);
}
printf ("Average temperature for zipcode '%s' was %dF\n",
filter, (int) (total_temp / update_nbr));
zmq_close (subscriber);
zmq_ctx_destroy (context);
return 0;
}
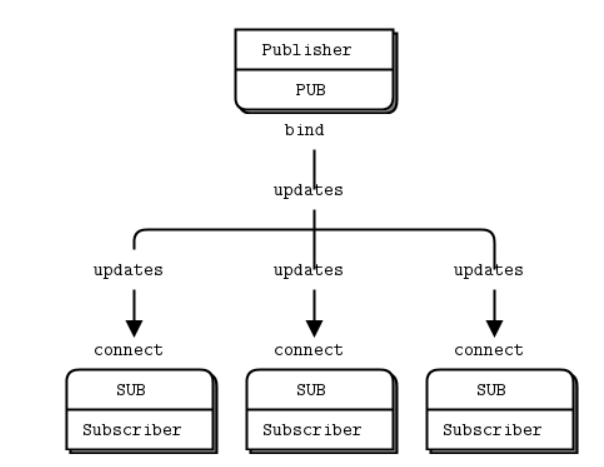
请注意,当您使用 SUB 套接字时,您必须使用 zmq_setsockopt() 和 ZMQ_SUBSCRIBE 设置订阅,如此代码所示。如果您不设置任何订阅,您将不会收到任何消息。这是初学者常犯的错误。订阅者可以设置多个订阅,这些订阅被加在一起。也就是说,如果更新匹配任何订阅,订阅者就会收到它。订户也可以取消特定的订阅。订阅通常(但不总是)是一个可打印的字符串。请参阅 zmq_setsockopt() 以了解其工作原理。
PUB-SUB 套接字对是异步的。客户端在一个循环中执行 zmq_recv()(或者一次,如果这就是它仅需要调用一次的话)。尝试向 SUB 套接字发送消息将导致错误。同样,该服务器端会根据需要经常执行 zmq_send() ,但不得在 PUB 套接字上执行 zmq_recv()。
理论上,对于 ZeroMQ 套接字,哪一端连接和哪一端绑定并不重要。但是,在实践中存在未记录(原文:undocumented)的差异,文章稍后会谈到。现在,除非您的网络设计使接下来的操作不可能,请绑定 PUB 并连接 SUB。
关于 PUB-SUB 套接字,还有一件更重要的事情需要了解:您无法准确知道订阅者何时开始接收消息。即使你启动一个订阅者,等待一段时间,然后再启动发布者,订阅者也总是会错过发布者发送的第一条消息。这是因为当订阅者连接到发布者时(需要很短但非零的时间),发布者可能已经在发送消息了。
这种“反应迟钝”的症状经常影响到足够多的人,因此我们将对其进行详细解释。请记住,ZeroMQ 执行异步 I/O,即在后台执行。假设您有两个节点按以下顺序执行此操作:
那么订阅者很可能不会收到任何东西。你会眨眼(blink),检查你是否设置了正确的过滤器,然后再试一次,订阅者仍然不会收到任何东西。
建立 TCP 连接涉及往返握手,这需要几毫秒,具体取决于您的网络和对等点之间的跃点数。在那个时候,ZeroMQ 可以发送很多消息。为了便于讨论,假设建立连接需要 5 毫秒,并且同一链路每秒可以处理 1M 消息。在订阅者连接到发布者的 5 毫秒内,发布者仅需 1 毫秒即可发送这些 1K 消息。
在 第 2 章 - 套接字和模式中,我们将解释如何同步发布者和订阅者,以便在订阅者真正连接并准备好之前您不会开始发布数据。有一个简单而愚蠢的方法可以延迟发布者,那就是休眠(sleep)。但是,不要在实际应用程序中这样做,因为它非常脆弱,而且不优雅且缓慢。使用睡眠向自己证明发生了什么,然后等待这章内容 第 2 章 - 套接字和模式,看看如何正确地做到这一点。
同步的替代方法是简单地假设发布的数据流是无限的,没有起点也没有终点。还假设订户不关心在它启动之前发生了什么。这就是我们构建天气客户端示例的方式。
因此,客户端订阅了它选择的邮政编码并收集了该邮政编码的 100 个更新。如果邮政编码是随机分布的,这意味着来自服务器的大约一千万次更新。您可以启动客户端,然后启动服务器,客户端将继续工作。您可以根据需要随时停止和重新启动服务器,客户端将继续工作。当客户端收集到它的一百个更新时,它计算平均值,打印它,然后退出。
关于发布-订阅(pub-sub)模式的一些要点:
tcp:@< *>@*或ipc:@< >@)时,过滤发生在发布者端。使用epgm:@<//>@协议,过滤发生在订阅者端。在 ZeroMQ v2.x 中,所有过滤都发生在订阅者端。注意,Ventilator 是呼吸机,worker 是工人,sink 是水槽,我不太会翻译这三个词,因此均使用英文代替。下文中如果出现了这三种中文翻译证明是机翻忘删了233
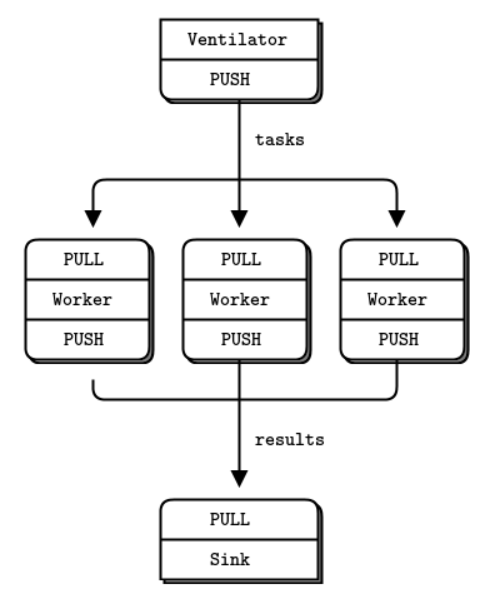
Ventilator 生成 100 个任务,每个任务都有一条消息告诉 worker 休眠一定毫秒数:
// Task ventilator
// Binds PUSH socket to tcp://localhost:5557
// Sends batch of tasks to workers via that socket
#include "zhelpers.h"
int main (void)
{
void *context = zmq_ctx_new ();
// Socket to send messages on
void *sender = zmq_socket (context, ZMQ_PUSH);
zmq_bind (sender, "tcp://*:5557");
// Socket to send start of batch message on
void *sink = zmq_socket (context, ZMQ_PUSH);
zmq_connect (sink, "tcp://localhost:5558");
printf ("Press Enter when the workers are ready: ");
getchar ();
printf ("Sending tasks to workers...\n");
// The first message is "0" and signals start of batch
s_send (sink, "0");
// Initialize random number generator
srandom ((unsigned) time (NULL));
// Send 100 tasks
int task_nbr;
int total_msec = 0; // Total expected cost in msecs
for (task_nbr = 0; task_nbr < 100; task_nbr++) {
int workload;
// Random workload from 1 to 100msecs
workload = randof (100) + 1;
total_msec += workload;
char string [10];
sprintf (string, "%d", workload);
s_send (sender, string);
}
printf ("Total expected cost: %d msec\n", total_msec);
zmq_close (sink);
zmq_close (sender);
zmq_ctx_destroy (context);
return 0;
}
这是 worker 的应用程序。它收到一条消息,休眠该秒数,然后发出已完成的信号:
// Task worker
// Connects PULL socket to tcp://localhost:5557
// Collects workloads from ventilator via that socket
// Connects PUSH socket to tcp://localhost:5558
// Sends results to sink via that socket
#include "zhelpers.h"
int main (void)
{
// Socket to receive messages on
void *context = zmq_ctx_new ();
void *receiver = zmq_socket (context, ZMQ_PULL);
zmq_connect (receiver, "tcp://localhost:5557");
// Socket to send messages to
void *sender = zmq_socket (context, ZMQ_PUSH);
zmq_connect (sender, "tcp://localhost:5558");
// Process tasks forever
while (1) {
char *string = s_recv (receiver);
printf ("%s.", string); // Show progress
fflush (stdout);
s_sleep (atoi (string)); // Do the work
free (string);
s_send (sender, ""); // Send results to sink
}
zmq_close (receiver);
zmq_close (sender);
zmq_ctx_destroy (context);
return 0;
}
下面是 sink 的应用程序。它收集了 100 个任务,然后计算整个处理所花费的时间,因此如果有多个任务,我们可以确认这些 worker 确实在并行运行:
// Task sink
// Binds PULL socket to tcp://localhost:5558
// Collects results from workers via that socket
#include "zhelpers.h"
int main (void)
{
// Prepare our context and socket
void *context = zmq_ctx_new ();
void *receiver = zmq_socket (context, ZMQ_PULL);
zmq_bind (receiver, "tcp://*:5558");
// Wait for start of batch
char *string = s_recv (receiver);
free (string);
// Start our clock now
int64_t start_time = s_clock ();
// Process 100 confirmations
int task_nbr;
for (task_nbr = 0; task_nbr < 100; task_nbr++) {
char *string = s_recv (receiver);
free (string);
if (task_nbr % 10 == 0)
printf (":");
else
printf (".");
fflush (stdout);
}
// Calculate and report duration of batch
printf ("Total elapsed time: %d msec\n",
(int) (s_clock () - start_time));
zmq_close (receiver);
zmq_ctx_destroy (context);
return 0;
}
让我们更详细地看一下这段代码的某些方面:
zmq_connect 方法需要一定的时间。因此,当一组 workers 连接到 ventilator 时,第一个成功连接的 worker 将在短时间内收到大量消息,而其他 worker 也在连接。如果您不以某种方式同步批处理的最开头,系统将根本不会并行运行。您可以尝试取消 ventilator 中的等待,看看会发生什么。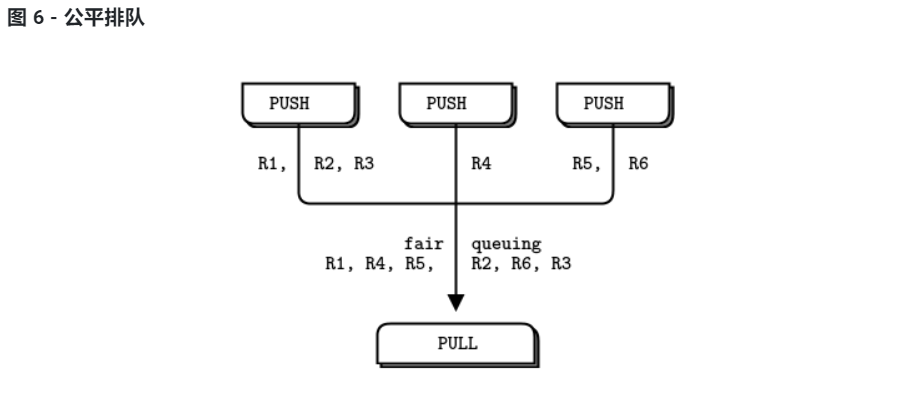
管道模式还表现出“慢连接”综合症,导致人们指责 PUSH 套接字没有正确地进行负载平衡。如果您正在使用 PUSH 和 PULL,并且您的一个工作人员收到的消息比其他工作人员多得多,那是因为 PULL 套接字的加入速度比其他套接字快,并且在其他工作人员设法连接之前获取了很多消息。如果你想要适当的负载平衡,你可能想看看 第 3 章 - 高级请求-回复模式中的负载平衡模式。
ZeroMQ 应用程序总是从创建上下文开始,然后使用它来创建套接字。在 C 中,它是zmq_ctx_new()调用。您应该在您的流程中创建和使用一个上下文。从技术上讲,上下文是单个进程中所有套接字的容器,并充当进程内套接字的传输,这是在一个进程中连接线程的最快方式。如果在运行时一个进程有两个上下文,它们就像单独的 ZeroMQ 实例。如果这正是你想要的,好的,但除此之外请记住:
在进程开始时调用 zmq_ctx_new() 一次,在结束时调用 zmq_ctx_destroy() 一次。
如果您正在使用 fork() 系统调用,请在 fork 之后,然后在子进程代码的开头执行 zmq_ctx_new()。一般来说,您会在子进程中做有趣的(ZeroMQ)事情,而在父进程中做无聊的流程管理。
使用 C 时,您必须在使用完对象后小心地释放它们,否则会导致内存泄漏、应用程序不稳定以及通常的恶果。
内存泄漏是一回事,但 ZeroMQ 对于退出应用程序的方式非常挑剔。原因是技术性的和痛苦的,但结果是如果你让任何套接字保持打开状态,zmq_ctx_destroy() 函数将永远挂起(hang)。并且即使您关闭所有套接字,且如果有待定(pending)的连接或发送,zmq_ctx_destroy() 默认情况下也会永远等待,除非您在关闭它们之前在这些套接字上设置 LINGER 为零。
我们需要担心的 ZeroMQ 对象是消息、套接字和上下文。幸运的是它非常简单,至少在简单的程序中是这样:
zmq_send() 和 zmq_recv() ,因为它避免了使用 zmq_msg_t 对象的需要。zmq_msg_recv(),请始终在完成后立即通过调用 zmq_msg_close() 释放接收到的消息。zmq_ctx_destroy()。这破坏了上下文(destroy context)。至少对于 C 开发是这样。在具有自动对象销毁功能的语言中,套接字和上下文将在您离开作用域时被销毁。如果您使用异常,则必须在类似于“最终”块的地方进行清理,这与任何资源一样。
如果您正在进行多线程工作,它会变得比这更复杂。首先,不要尝试从多个线程使用同一个套接字。请不要解释为什么您认为这会非常有趣,只是请不要这样做。接下来,您需要关闭每个有正在进行的请求的套接字。正确的方法是设置一个较低的 LINGER 值(1 秒),然后关闭套接字。如果您的语言绑定在您销毁上下文时没有自动为您执行此操作,我建议您发送一个补丁。
最后,破坏上下文。这将导致附加线程(即共享相同上下文)中的任何阻塞接收或轮询或发送返回错误。捕获该错误,然后设置 linger on,关闭该线程中的套接字,然后退出。不要两次破坏相同的上下文。主线程中的 zmq_ctx_destroy 将阻塞,直到它知道的所有套接字都安全关闭。
瞧!它非常复杂和痛苦,以至于任何称职的语言绑定作者都会自动执行此操作并使套接字关闭舞蹈变得不必要。
ZeroMQ:一个高效、可嵌入的库,可以解决应用程序在网络上变得非常灵活所需的大部分问题,而且成本不高。
具体来说:
实际上 ZeroMQ 做的远不止这些。它对您开发具有网络功能的应用程序的方式具有颠覆性的影响。从表面上看,它是一个受套接字启发的 API,您可以在其上执行 zmq_recv() 和 zmq_send()。但是消息处理很快成为中心循环,您的应用程序很快就会分解为一组消息处理任务。它优雅而自然。它可以扩展:这些任务中的每一个都映射到一个节点,并且节点通过任意传输相互通信。一个进程中的两个节点(节点是一个线程)、一个盒子上的两个节点(节点是一个进程)或一个网络中的两个节点(节点是一个盒子)——它们都是一样的,没有应用程序代码更改。
我正在使用i18n从头开始构建一个多语言网络应用程序,虽然我自己可以处理一大堆yml文件,但我说的语言(非常)有限,最终我想寻求外部帮助帮助。我想知道这里是否有人在使用UI插件/gem(与django上的django-rosetta不同)来处理多个翻译器,其中一些翻译器不愿意或无法处理存储库中的100多个文件,处理语言数据。谢谢&问候,安德拉斯(如果您已经在rubyonrails-talk上遇到了这个问题,我们深表歉意) 最佳答案 有一个rails3branchofthetolkgem在github上。您可以通过在Gemfi
我的Rails应用程序中安装了carrierwave。但是,当用户上传多页pdf时,我只希望应用程序获取文档中的第一页并将其转换为jpeg。这可能吗?用什么命令?这是我的uploader。#encoding:utf-8classImageUploader[200,300]##defscale(width,height)##dosomething#end#Createdifferentversionsofyouruploadedfiles:version:thumbdoprocess:resize_to_fill=>[150,210]process:convert=>:jpgdefful
有没有办法跳过CSV文件的第一行,让第二行作为标题?我有一个CSV文件,第一行是日期,第二行是标题,所以我需要能够在遍历它时跳过第一行。我尝试使用slice但它会将CSV转换为数组,我真的很想将其读取为CSV,以便我可以利用header。 最佳答案 根据您的数据,您可以使用另一种方法和skip_lines-option此示例跳过所有以#开头的行require'csv'CSV.parse(DATA.read,:col_sep=>';',:headers=>true,:skip_lines=>/^#/#Markcomments!)do|
很高兴看到google代码:google-api-ruby-client项目,因为这对我来说意味着Ruby人员可以使用GoogleAPI-s来完善代码。虽然我现在很困惑,因为给出的唯一示例使用Buzz,并且根据我的实验,Google翻译(v2)api的行为必须与google-api-ruby-client中的Buzz完全不同。.我对“Explorer”演示示例很感兴趣——但据我所知,它并不是一个探索器。它所做的只是调用一个Buzz服务,然后浏览它已经知道的关于Buzz服务的事情。对我来说,Explorer应该让您“发现”所公开的服务和方法/功能,而不一定已经知道它们。我很想听听使用这个
如果特定语言环境中缺少翻译,如何配置i18n以使用en语言环境翻译?当前已插入翻译缺失消息。我正在使用RoR3.1。 最佳答案 找到相似的question这里是答案:#application.rb#railswillfallbacktoconfig.i18n.default_localetranslationconfig.i18n.fallbacks=true#railswillfallbacktoen,nomatterwhatissetasconfig.i18n.default_localeconfig.i18n.fallback
我的任务是从数组中选择最高和最低的数字。我想我很清楚我想做什么,但只是努力以正确的格式访问信息以满足通过标准。defhigh_and_low(numbers)array=numbers.split("").map!{|x|x.to_i}array.sort!{|a,b|ba}putsarray[0,-1]end数字可能看起来像"80917234100",要通过,我需要输出"9234"。我正在尝试putsarray.first.last,但一直无法弄明白。 最佳答案 有Array#minmax完全满足您需要的方法:array=[80,
在使用rails4和https://github.com/globalize/globalize的情况下,我应该如何为我的模型编写表单?用于翻译。我想以一种形式显示所有翻译,如下例所示。我在这里找到了解决方案https://github.com/rilla/batch_translations但我不知道如何实现它。这个“批量翻译”是一个gem还是什么?以及如何安装它。EditingpostEnglish(defaultlocale)SpanishtranslationFrenchtranslation 最佳答案 批处理翻译gem很旧
或者好像我必须自己写方法?(保持DHA不变):ruby-1.9.2-p180:001>s='omega-3(DHA)'=>"omega-3(DHA)"ruby-1.9.2-p180:002>s.capitalize=>"Omega-3(dha)"ruby-1.9.2-p180:003>s.titleize=>"Omega3(Dha)"ruby-1.9.2-p180:005>s[0].upcase+s[1..-1]=>"Omega-3(DHA)" 最佳答案 如果我的回答只是垃圾,我深表歉意(我不做ruby)。但我相信我已经为您找到了答
我有这个字符串:auteur="comtedeFlandreetHainaut,Baudouin,Jacques,Thierry"我想删除第一个逗号之前的所有内容,即在这种情况下保留“Baudouin,Jacques,Thierry”试过这个:nom=auteur.gsub(/.*,/,'')但这会删除最后一个逗号之前的每个逗号,只保留“Thierry”。 最佳答案 auteur.partition(",").last#=>"Baudouin,Jacques,Thierry" 关于rub
我想使用部分字符串搜索数组,然后获取找到该字符串的索引。例如:a=["Thisisline1","Wehaveline2here","andfinallyline3","potato"]a.index("potato")#thisreturns3a.index("Wehave")#thisreturnsnil使用a.grep将返回完整的字符串,使用a.any?将返回正确的true/false语句,但都不会返回匹配的索引找到了,或者至少我不知道该怎么做。我正在编写一段代码,该代码读取文件、查找特定header,然后返回该header的索引,以便它可以将其用作future搜索的偏移量。如果