目录
归并排序,其实就是一种分治算法 ,那么在了解归并排序之前,我们先来看看什么是分治算法。在算法设计中,我们引入分而治之的策略,称为分治算法,其本质就是将一个大规模的问题分解为若干个规模较小的相同子问题,分而治之。
将要解决的问题分解为若干个规模较小、相互独立、与原问题形式相同的子问题。
求解各个子问题。由于各个子问题与原问题形式相同,只是规模较小而已,而当子问题划分得足够小时,就可以用简单的方法解决。
按原问题的要求,将子问题的解逐层合并构成原问题的解。
归并排序是比较稳定的排序方法。它的基本思想是把待排序的元素分解成两个规模大致相等的子序列。如果不易分解,将得到的子序列继续分解,直到子序列中包含的元素个数为1。因为单个元素的序列本身就是有序的,此时便可以进行合并,从而得到一个完整的有序序列。
将待排序的元素分成大小大致一样的两个子序列。
对两个子序列进行个并排序。
将排好序的有序子序列进行合并,得到最终的有序序列。
首先我们先给定一个无序的数列(42,15,20,6,8,38,50,12),我们进行合并排序数列,如下图流程图所示:
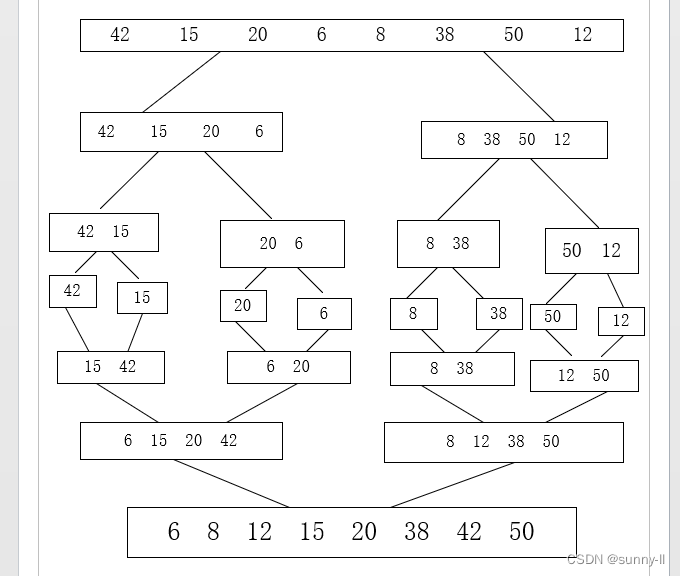
步骤一:首先将待排序的元素分成大小大致相同的两个序列。
步骤二:再把子序列分成大小大致相同的两个子序列。
步骤三:如此下去,直到分解成一个元素停止,这时含有一个元素的子序列都是有序的。
步骤四:进行合并操作,将两个有序的子序列合并为一个有序序列,如此下去,直到所有的元素都合并为一个有序序列。
举例,下面我将以序列(4,9,15,24,30,2,6,18,20)进行图解。
(1)初始化:i = low,j = mid+1,mid = (low+hight)/2 ,申请一个辅助数组 b
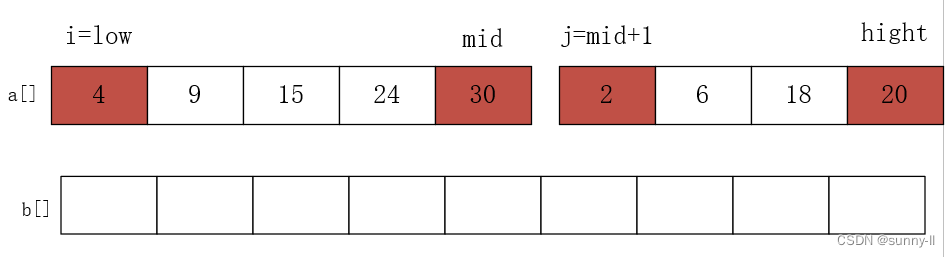
int* b = new int[hight - low + 1]; //用 new 申请一个辅助函数
int i = low, j = mid + 1, k = 0; // k为 b 数组的小标(2)现在比较 a [i] 和 b[j] ,将较小的元素放在 b 数组中,相应的指针向后移动,直到 i > mid 或者 j>hight 时结束。
while (i <= mid && j <= hight)
{
if (a[i] <= a[j])
{
b[k++] = a[i++]; //按从小到大存放在 b 数组里面
}
else
{
b[k++] = a[j++];
}
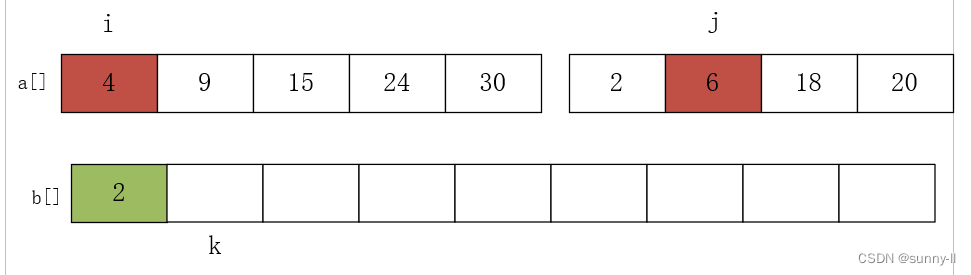
}进行第一次比较 a[i]=4 和 a[j]=2,将较小的元素 2 放入数组 b 中,j++,k++,如下图:
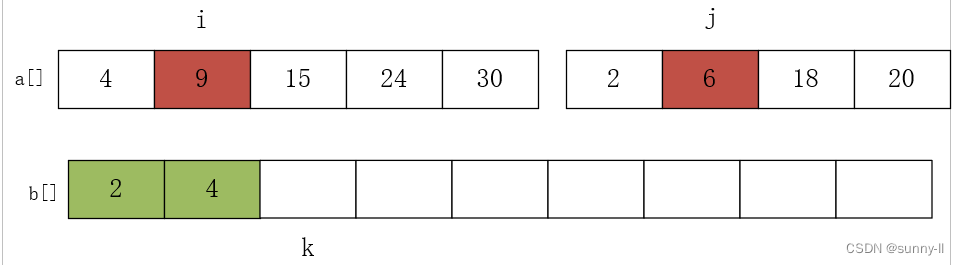
进行第二次比较 a[i]=4 和 a[j]=6,将较小的元素放 4 入数组 b 中,i++,k++,如下图:
进行第三次比较 a[i]=9 和 a[j]=6,将较小的元素放 6 入数组 b 中,j++,k++,如下图:
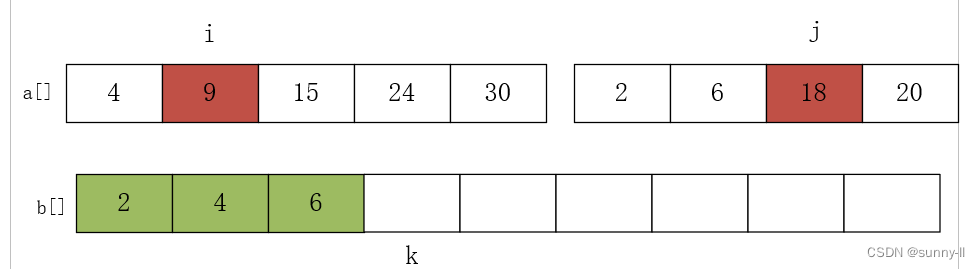
进行第四次比较 a[i]=9 和 a[j]=18,将较小的元素放 9 入数组 b 中,i++,k++,如下图:
 进行第五次比较 a[i]=15 和 a[j]=18,将较小的元素放 15 入数组 b 中,i++,k++,如下图:
进行第五次比较 a[i]=15 和 a[j]=18,将较小的元素放 15 入数组 b 中,i++,k++,如下图:
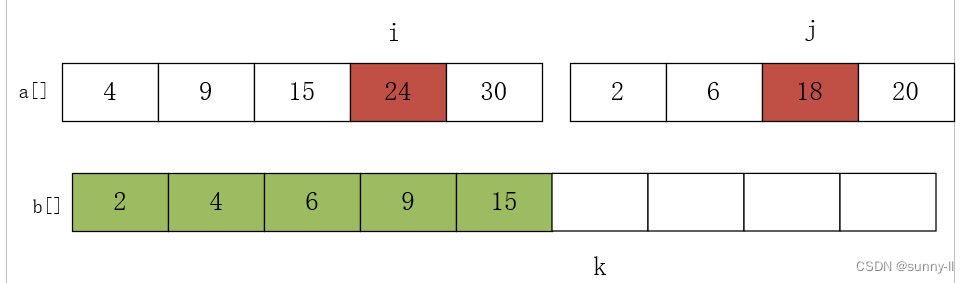
进行第六次比较 a[i]=24 和 a[j]=18,将较小的元素放 18 入数组 b 中,j++,k++,如下图:

进行第七次比较 a[i]=24 和 a[j]=20,将较小的元素放 20 入数组 b 中,j++,k++,如下图:
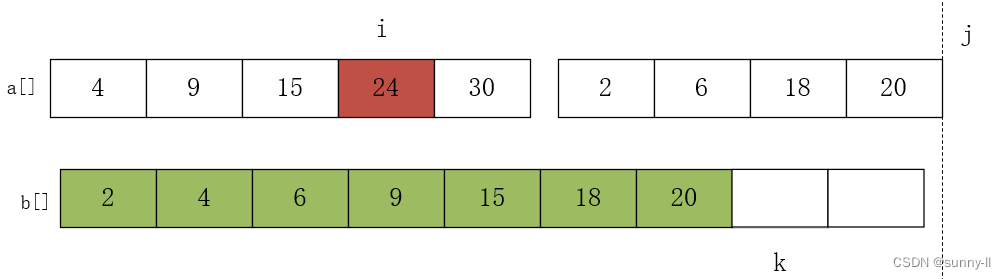 此时,j>hight 了,while循环结束,但 a 数组还剩下元素(i<mid)可直接放入 b 数组就可以了。如下图所示:
此时,j>hight 了,while循环结束,但 a 数组还剩下元素(i<mid)可直接放入 b 数组就可以了。如下图所示:

while (i <= mid) // j 序列结束,将剩余的 i 序列补充在 b 数组中
{
b[k++] = a[i++];
}
while (j <= hight)// i 序列结束,将剩余的 j 序列补充在 b 数组中
{
b[k++] = a[j++];
}现在将 b 数组的元素赋值给 a 数组,再将 b 数组销毁,即可。
for (int i = low; i <= hight; i++) //将 b 数组的值传递给数组 a
{
a[i] = b[k++];
}
delete[]b; // 辅助数组用完后,将其的空间进行释放(销毁)(3)递归的形式进行归并排序
void mergesort(int* a, int low, int hight) //归并排序
{
if (low < hight)
{
int mid = (low + hight) / 2;
mergesort(a, low, mid); //对 a[low,mid]进行排序
mergesort(a, mid + 1, hight); //对 a[mid+1,hight]进行排序
merge(a, low, mid, hight); //进行合并操作
}
}#include <stdio.h>
#include <iostream>
#include <algorithm>
#include <cstdlib>
#include <cmath>
using namespace std;
void merge(int* a, int low, int mid, int hight) //合并函数
{
int* b = new int[hight - low + 1]; //用 new 申请一个辅助函数
int i = low, j = mid + 1, k = 0; // k为 b 数组的小标
while (i <= mid && j <= hight)
{
if (a[i] <= a[j])
{
b[k++] = a[i++]; //按从小到大存放在 b 数组里面
}
else
{
b[k++] = a[j++];
}
}
while (i <= mid) // j 序列结束,将剩余的 i 序列补充在 b 数组中
{
b[k++] = a[i++];
}
while (j <= hight)// i 序列结束,将剩余的 j 序列补充在 b 数组中
{
b[k++] = a[j++];
}
k = 0; //从小标为 0 开始传送
for (int i = low; i <= hight; i++) //将 b 数组的值传递给数组 a
{
a[i] = b[k++];
}
delete[]b; // 辅助数组用完后,将其的空间进行释放(销毁)
}
void mergesort(int* a, int low, int hight) //归并排序
{
if (low < hight)
{
int mid = (low + hight) / 2;
mergesort(a, low, mid); //对 a[low,mid]进行排序
mergesort(a, mid + 1, hight); //对 a[mid+1,hight]进行排序
merge(a, low, mid, hight); //进行合并操作
}
}
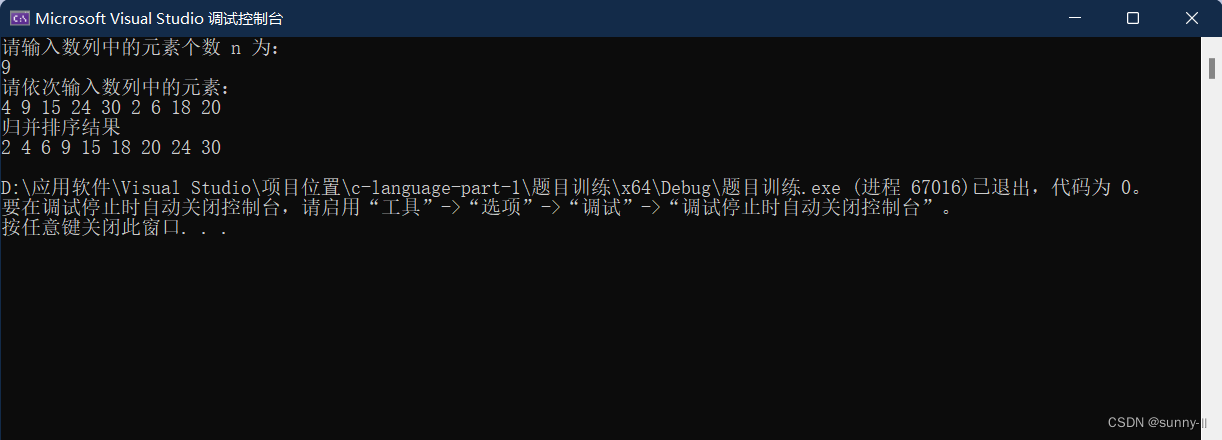
int main()
{
int n, a[100];
cout << "请输入数列中的元素个数 n 为:" << endl;
cin >> n;
cout << "请依次输入数列中的元素:" << endl;
for (int i = 0; i < n; i++)
{
cin >> a[i];
}
mergesort(a, 0, n-1);
cout << "归并排序结果" << endl;
for (int i = 0; i < n; i++)
{
cout << a[i] << " ";
}
cout << endl;
return 0;
}
以下就是我对分治算法:归并排序的理解,如果有不懂和发现问题的小伙伴,请在评论区说出来哦,同时我还会继续更新对分治算法的理解,请持续关注我哦!!!!!!!!

我有一个字符串input="maybe(thisis|thatwas)some((nice|ugly)(day|night)|(strange(weather|time)))"Ruby中解析该字符串的最佳方法是什么?我的意思是脚本应该能够像这样构建句子:maybethisissomeuglynightmaybethatwassomenicenightmaybethiswassomestrangetime等等,你明白了......我应该一个字符一个字符地读取字符串并构建一个带有堆栈的状态机来存储括号值以供以后计算,还是有更好的方法?也许为此目的准备了一个开箱即用的库?
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
我正在使用ruby1.9解析以下带有MacRoman字符的csv文件#encoding:ISO-8859-1#csv_parse.csvName,main-dialogue"Marceu","Giveittohimóhe,hiswife."我做了以下解析。require'csv'input_string=File.read("../csv_parse.rb").force_encoding("ISO-8859-1").encode("UTF-8")#=>"Name,main-dialogue\r\n\"Marceu\",\"Giveittohim\x97he,hiswife.\"\
我有一个用户工厂。我希望默认情况下确认用户。但是鉴于unconfirmed特征,我不希望它们被确认。虽然我有一个基于实现细节而不是抽象的工作实现,但我想知道如何正确地做到这一点。factory:userdoafter(:create)do|user,evaluator|#unwantedimplementationdetailshereunlessFactoryGirl.factories[:user].defined_traits.map(&:name).include?(:unconfirmed)user.confirm!endendtrait:unconfirmeddoenden
简而言之错误:NOTE:Gem::SourceIndex#add_specisdeprecated,useSpecification.add_spec.Itwillberemovedonorafter2011-11-01.Gem::SourceIndex#add_speccalledfrom/opt/local/lib/ruby/site_ruby/1.8/rubygems/source_index.rb:91./opt/local/lib/ruby/gems/1.8/gems/rails-2.3.8/lib/rails/gem_dependency.rb:275:in`==':und
目录一.加解密算法数字签名对称加密DES(DataEncryptionStandard)3DES(TripleDES)AES(AdvancedEncryptionStandard)RSA加密法DSA(DigitalSignatureAlgorithm)ECC(EllipticCurvesCryptography)非对称加密签名与加密过程非对称加密的应用对称加密与非对称加密的结合二.数字证书图解一.加解密算法加密简单而言就是通过一种算法将明文信息转换成密文信息,信息的的接收方能够通过密钥对密文信息进行解密获得明文信息的过程。根据加解密的密钥是否相同,算法可以分为对称加密、非对称加密、对称加密和非
华为OD机试题本篇题目:明明的随机数题目输入描述输出描述:示例1输入输出说明代码编写思路最近更新的博客华为od2023|什么是华为od,od薪资待遇,od机试题清单华为OD机试真题大全,用Python解华为机试题|机试宝典【华为OD机试】全流程解析+经验分享,题型分享,防作弊指南华为o
C#实现简易绘图工具一.引言实验目的:通过制作窗体应用程序(C#画图软件),熟悉基本的窗体设计过程以及控件设计,事件处理等,熟悉使用C#的winform窗体进行绘图的基本步骤,对于面向对象编程有更加深刻的体会.Tutorial任务设计一个具有基本功能的画图软件**·包括简单的新建文件,保存,重新绘图等功能**·实现一些基本图形的绘制,包括铅笔和基本形状等,学习橡皮工具的创建**·设计一个合理舒适的UI界面**注明:你可能需要先了解一些关于winform窗体应用程序绘图的基本知识,以及关于GDI+类和结构的知识二.实验环境Windows系统下的visualstudio2017C#窗体应用程序三.
MIMO技术的优缺点优点通过下面三个增益来总体概括:阵列增益。阵列增益是指由于接收机通过对接收信号的相干合并而活得的平均SNR的提高。在发射机不知道信道信息的情况下,MIMO系统可以获得的阵列增益与接收天线数成正比复用增益。在采用空间复用方案的MIMO系统中,可以获得复用增益,即信道容量成倍增加。信道容量的增加与min(Nt,Nr)成正比分集增益。在采用空间分集方案的MIMO系统中,可以获得分集增益,即可靠性性能的改善。分集增益用独立衰落支路数来描述,即分集指数。在使用了空时编码的MIMO系统中,由于接收天线或发射天线之间的间距较远,可认为它们各自的大尺度衰落是相互独立的,因此分布式MIMO
在VMware16.2.4安装Ubuntu一、安装VMware1.打开VMwareWorkstationPro官网,点击即可进入。2.进入后向下滑动找到Workstation16ProforWindows,点击立即下载。3.下载完成,文件大小615MB,如下图:4.鼠标右击,以管理员身份运行。5.点击下一步6.勾选条款,点击下一步7.先勾选,再点击下一步8.去掉勾选,点击下一步9.点击下一步10.点击安装11.点击许可证12.在百度上搜索VM16许可证,复制填入,然后点击输入即可,亲测有效。13.点击完成14.重启系统,点击是15.双击VMwareWorkstationPro图标,进入虚拟机主