在我们常用的系统windows和Linux系统中有很多支持的压缩包格式,包括但不限于以下种类:rar、zip、tar,以下的标准库的作用就是用于压缩解压缩其中一些格式的压缩包。
import zipfile
zipfile模块操作压缩包使用ZipFile类进行操作,使用方法和open的使用方法很相似,也是使用r、w、x、a四种操作模式。基本步骤也是大致分为三步:打开文件、操作文件、关闭文件。可以使用with语法进行上下文自动操作。
注意一:zipfile也是rwxa四种模式,表示也会有文件操作中光标指针的概念。
注意二:在Python中,几乎所有涉及到文件相关的操作都是打开、操作、关闭三个步骤。
语法:ZipFile(file, mode='r', compression=ZIP_STORED, allowZip64=True)
| 参数 | 含义 |
|---|---|
| file | 文件路径 |
| mode | 操作含义,与文件操作中相同,默认为r。 |
| compression | 压缩方法,默认为ZIP_STORED。 |
| allowZip64 | 操作的压缩包文件大小大于2G时应该True, 默认为True,不用管它。 |
| 模式 | 含义 |
|---|---|
| w | 创建一个新的压缩包文件。 |
| r | 读取已有的压缩包文件。 |
| a | 向已有的压缩包文件中压缩文件。 |
在上面的compression参数中可以看到,默认的压缩方法为ZIP_STORED。其实在zipfile模块中定义了一些压缩方法常量,其中最常用的为以下两种:
ZIP_STORED = 0 # 打包归档(不压缩)
ZIP_DEFLATED = 8 # 压缩文件(压缩)
注意,压缩方法指的是将文件写入压缩包中采用的方法,所以,如果是解压缩文件,就没必要指定这个压缩方法了。
语法:write(filename, arcname=None)
语法:write(压缩文件路径,写入压缩包后的路径和名字(默认原名))
写入文件如果是文件夹,那么不会将文件夹中的内容一同写入。
这是我要压缩的文件夹。
使用ZIP_STORED压缩。
import zipfile
# 文件路径
zip_file_path = r'D:\test.zip' # 压缩包路径
file_path = r'D:\10-中日欧美信息解析' # 被压缩文件
# 默认使用ZIP_STORED
zf = zipfile.ZipFile(zip_file_path, 'w')
# 写入文件(文件夹的话,不会将文件夹中的文件一同写入)
zf.write(file_path)
# 关闭文件
zf.close()
可以看到,如果文件夹直接压缩的话,不会将其中的文件一同压缩。
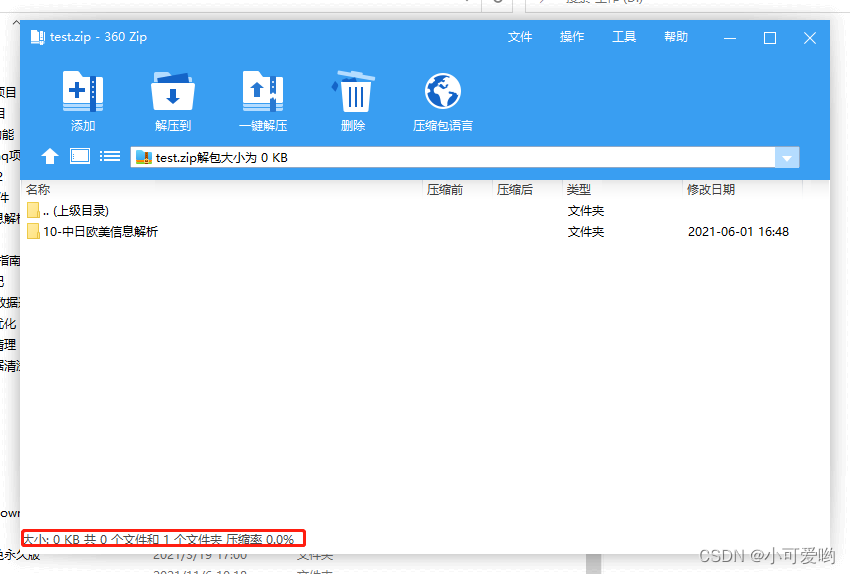
让文件夹中的所有文件迭代写入压缩包中。
import os
import zipfile
def writeZip(zf, file, arc_path=None):
"""迭代压缩文件夹"""
# 设置压缩路径
if arc_path is None:
arc_path = rf'\{os.path.basename(file)}'
# 先压缩本文件
zf.write(file, arc_path)
# 如果是文件夹
if os.path.isdir(file):
# 获取它所有的子文件
inner_files = os.listdir(file)
# 将所有的子文件压缩
for inner_file in inner_files:
inner_file = f'{file}{os.sep}{inner_file}'
arc = fr'{arc_path}\{os.path.basename(inner_file)}'
writeZip(zf, inner_file, arc)
# 文件路径
zip_file_path = r'D:\test.zip' # 压缩包路径
file_path = r'D:\10-中日欧美信息解析' # 被压缩文件
# 默认使用ZIP_STORED
zf = zipfile.ZipFile(zip_file_path, 'w')
# 写入文件(自定义一个函数,迭代压缩文件夹)
writeZip(zf, file_path)
# 关闭文件
zf.close()
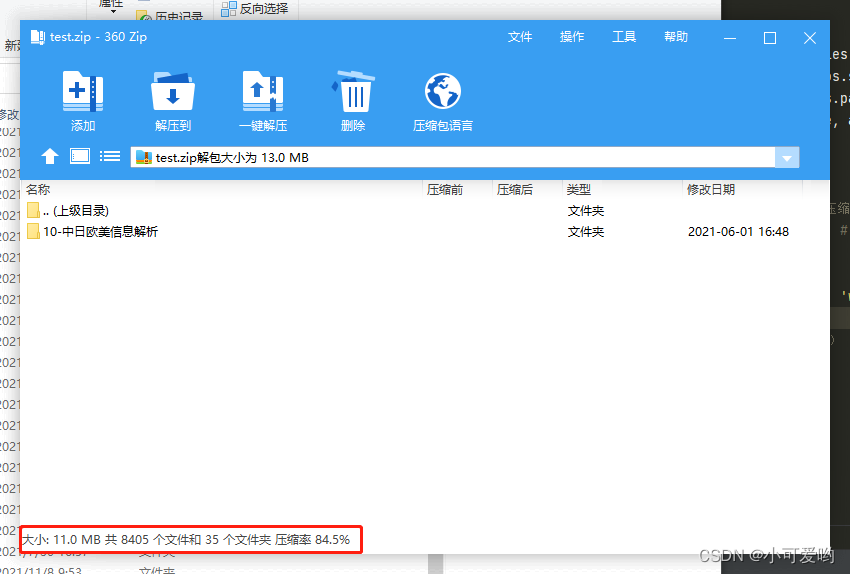
现在就可以看到,虽然所有的文件已经全部写入压缩包中,但是ZIP_STORED方法并没有压缩文件。


改用ZIP_DEFLATED方法压缩文件。
import os
import zipfile
def writeZip(zf, file, arc_path=None):
"""迭代压缩文件夹"""
# 设置压缩路径
if arc_path is None:
arc_path = rf'\{os.path.basename(file)}'
# 先压缩本文件
zf.write(file, arc_path)
# 如果是文件夹
if os.path.isdir(file):
# 获取它所有的子文件
inner_files = os.listdir(file)
# 将所有的子文件压缩
for inner_file in inner_files:
inner_file = f'{file}{os.sep}{inner_file}'
arc = fr'{arc_path}\{os.path.basename(inner_file)}'
writeZip(zf, inner_file, arc)
# 文件路径
zip_file_path = r'D:\test.zip' # 压缩包路径
file_path = r'D:\10-中日欧美信息解析' # 被压缩文件
# 使用ZIP_DEFLATED压缩
zf = zipfile.ZipFile(zip_file_path, 'w', zipfile.ZIP_DEFLATED)
# 写入文件(自定义一个函数,迭代压缩文件夹)
writeZip(zf, file_path)
# 关闭文件
zf.close()
可以看到,文件是压缩写入内部的。
解压缩有如下两种方法,注意,解压缩就是在读文件,要将操作模式变更为r。
| 方法 | 说明 |
|---|---|
| extract | 解压缩单个指定的文件。 |
| extractall | 解压缩所有的文件。 |
语法:extract(member,path=None, pwd=None)
语法:extract(指定文件(压缩包中的路径),解压到的位置(默认为当前工作目录),指定的密码(有些压缩包有密码,格式为字节流))
语法:extractall(path=None, pwd=None)
语法:extractall(解压到的位置, 密码)
注意:解压文件和路径中的文件夹同名会报错,因为文件无法重置文件夹。
import zipfile
with zipfile.ZipFile(r'D:\test.zip') as zf:
res = zf.namelist()
print(res)
# ['10-中日欧美信息解析/', '10-中日欧美信息解析/1-代码/', ...]
比如文件的权限等。
查看压缩包中的文件信息,比如文件的大小、创建日期等。默认查看所有的文件。
语法:printdir(file=None)
import tarfile
tarfile的使用和文件操作更加的相似,只是在压缩模式上略有不同。
使用linux系统的朋友都知道,tar是Linux的一种打包方式,打包成为tar包之后,才可以使用其它的压缩程序去压缩。最常用的压缩方式是gzip,压缩率最高的方式bzip2,此外还支持另一种比较小众的xzip格式。
主要操作方法为tarfile.TarFile.open(),可以直接tarfile.open()。
语法:open(name, mode='r')
当初在学习的时候,老师还教有encoding='UTF-8'参数,但是文件操作要什么编码格式?感觉他是为了方便直接从文件操作的代码上直接复制过来的,然后没有删掉。
模式为r、w、a、x四种为主,外加使用add方法写入文件,退出依然使用close方法。
add(name, arcname)
add(压缩文件,压缩别名)
注意,压缩别名一定不要以路径分隔符为结尾,否则只会创建一个文件夹。
import tarfile
with tarfile.open('test.tar', 'w') as tf:
tf.add('test.txt')
压缩的方式主要是将模式改变,在rwx的基础上加上各个压缩的方式,变成:r:gz、w:bz2、x:xz等样式,然后在将刚才创建的tar包压缩,当然也可以直接将文件压缩成为压缩包。
注意,a模式不能配备任何压缩模式,因为gzip、bzip2、xzip不能直接往里面追加文件,所以如果要追加文件,将tar包解压缩出来,然后追加再压缩。
import tarfile
# tar包以gzip格式压缩
with tarfile.open('test.tar.gz', 'w:gz') as tf:
tf.add('test.tar')
tarfile的解压缩方法和zipfile的一模一样。
| 方法 | 含义 |
|---|---|
| extract | 解压缩指定文件 |
| extractall | 解压缩所有文件 |
zipfile和tarfile不支持删除压缩包中的文件,所以如果有需要删除压缩包中的文件,可以将压缩包解压出来,然后删除其中的文件,再压缩。
我有一个Ruby程序,它使用rubyzip压缩XML文件的目录树。gem。我的问题是文件开始变得很重,我想提高压缩级别,因为压缩时间不是问题。我在rubyzipdocumentation中找不到一种为创建的ZIP文件指定压缩级别的方法。有人知道如何更改此设置吗?是否有另一个允许指定压缩级别的Ruby库? 最佳答案 这是我通过查看rubyzip内部创建的代码。level=Zlib::BEST_COMPRESSIONZip::ZipOutputStream.open(zip_file)do|zip|Dir.glob("**/*")d
假设我做了一个模块如下:m=Module.newdoclassCendend三个问题:除了对m的引用之外,还有什么方法可以访问C和m中的其他内容?我可以在创建匿名模块后为其命名吗(就像我输入“module...”一样)?如何在使用完匿名模块后将其删除,使其定义的常量不再存在? 最佳答案 三个答案:是的,使用ObjectSpace.此代码使c引用你的类(class)C不引用m:c=nilObjectSpace.each_object{|obj|c=objif(Class===objandobj.name=~/::C$/)}当然这取决于
作为我的Rails应用程序的一部分,我编写了一个小导入程序,它从我们的LDAP系统中吸取数据并将其塞入一个用户表中。不幸的是,与LDAP相关的代码在遍历我们的32K用户时泄漏了大量内存,我一直无法弄清楚如何解决这个问题。这个问题似乎在某种程度上与LDAP库有关,因为当我删除对LDAP内容的调用时,内存使用情况会很好地稳定下来。此外,不断增加的对象是Net::BER::BerIdentifiedString和Net::BER::BerIdentifiedArray,它们都是LDAP库的一部分。当我运行导入时,内存使用量最终达到超过1GB的峰值。如果问题存在,我需要找到一些方法来更正我的代
关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭4年前。Improvethisquestion我想在固定时间创建一系列低音和高音调的哔哔声。例如:在150毫秒时发出高音调的蜂鸣声在151毫秒时发出低音调的蜂鸣声200毫秒时发出低音调的蜂鸣声250毫秒的高音调蜂鸣声有没有办法在Ruby或Python中做到这一点?我真的不在乎输出编码是什么(.wav、.mp3、.ogg等等),但我确实想创建一个输出文件。
大约一年前,我决定确保每个包含非唯一文本的Flash通知都将从模块中的方法中获取文本。我这样做的最初原因是为了避免一遍又一遍地输入相同的字符串。如果我想更改措辞,我可以在一个地方轻松完成,而且一遍又一遍地重复同一件事而出现拼写错误的可能性也会降低。我最终得到的是这样的:moduleMessagesdefformat_error_messages(errors)errors.map{|attribute,message|"Error:#{attribute.to_s.titleize}#{message}."}enddeferror_message_could_not_find(obje
我有一个包含模块的模型。我想在模块中覆盖模型的访问器方法。例如:classBlah这显然行不通。有什么想法可以实现吗? 最佳答案 您的代码看起来是正确的。我们正在毫无困难地使用这个确切的模式。如果我没记错的话,Rails使用#method_missing作为属性setter,因此您的模块将优先,阻止ActiveRecord的setter。如果您正在使用ActiveSupport::Concern(参见thisblogpost),那么您的实例方法需要进入一个特殊的模块:classBlah
我刚刚被困在这个问题上一段时间了。以这个基地为例:moduleTopclassTestendmoduleFooendend稍后,我可以通过这样做在Foo中定义扩展Test的类:moduleTopmoduleFooclassSomeTest但是,如果我尝试通过使用::指定模块来最小化缩进:moduleTop::FooclassFailure这失败了:NameError:uninitializedconstantTop::Foo::Test这是一个错误,还是仅仅是Ruby解析变量名的方式的逻辑结果? 最佳答案 Isthisabug,or
我想获取模块中定义的所有常量的值:moduleLettersA='apple'.freezeB='boy'.freezeendconstants给了我常量的名字:Letters.constants(false)#=>[:A,:B]如何获取它们的值的数组,即["apple","boy"]? 最佳答案 为了做到这一点,请使用mapLetters.constants(false).map&Letters.method(:const_get)这将返回["a","b"]第二种方式:Letters.constants(false).map{|c
我的假设是moduleAmoduleBendend和moduleA::Bend是一样的。我能够从thisblog找到解决方案,thisSOthread和andthisSOthread.为什么以及什么时候应该更喜欢紧凑语法A::B而不是另一个,因为它显然有一个缺点?我有一种直觉,它可能与性能有关,因为在更多命名空间中查找常量需要更多计算。但是我无法通过对普通类进行基准测试来验证这一点。 最佳答案 这两种写作方法经常被混淆。首先要说的是,据我所知,没有可衡量的性能差异。(在下面的书面示例中不断查找)最明显的区别,可能也是最著名的,是你的
我一直致力于让我们的Rails2.3.8应用程序在JRuby下正确运行。一切正常,直到我启用config.threadsafe!以实现JRuby提供的并发性。这导致lib/中的模块和类不再自动加载。使用config.threadsafe!启用:$rubyscript/runner-eproduction'pSim::Sim200Provisioner'/Users/amchale/.rvm/gems/jruby-1.5.1@web-services/gems/activesupport-2.3.8/lib/active_support/dependencies.rb:105:in`co