人脸表情识别是模式识别中一个非常重要却十分复杂的课题。首先对计算机人脸表情识别技术的研究背景及发展历程作了简单回顾。然后对近期人脸表情识别的方法进行了分类综述。通过对各种识别方法的分析与比较 ,提出了人脸表情识别技术实用化所需要考虑的几个方面 ,进而展望了今后人脸表情识别技术的发展方向。
Python基于OpenCV的人脸表情识别系统[源码&部署教程]_哔哩哔哩_bilibili
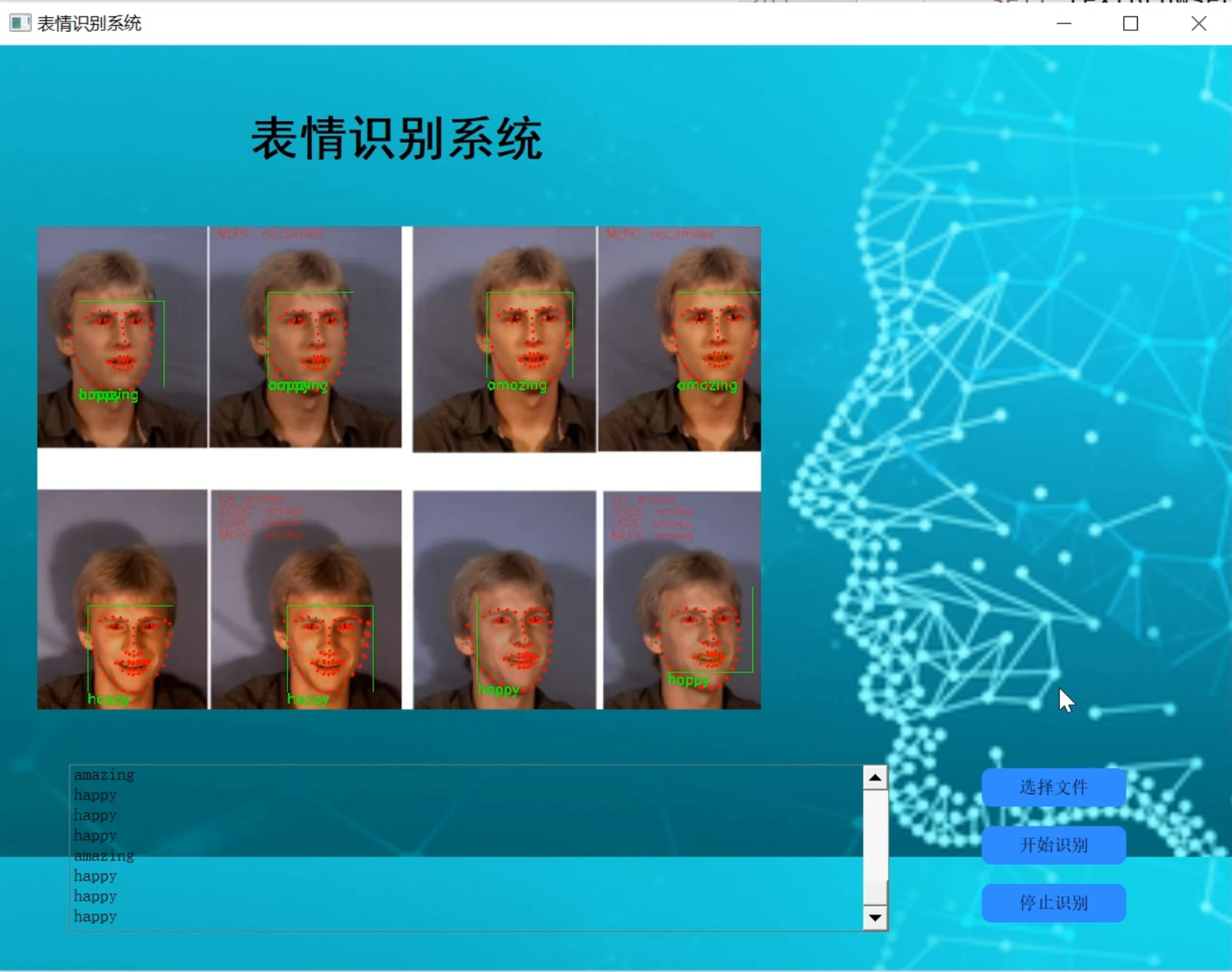
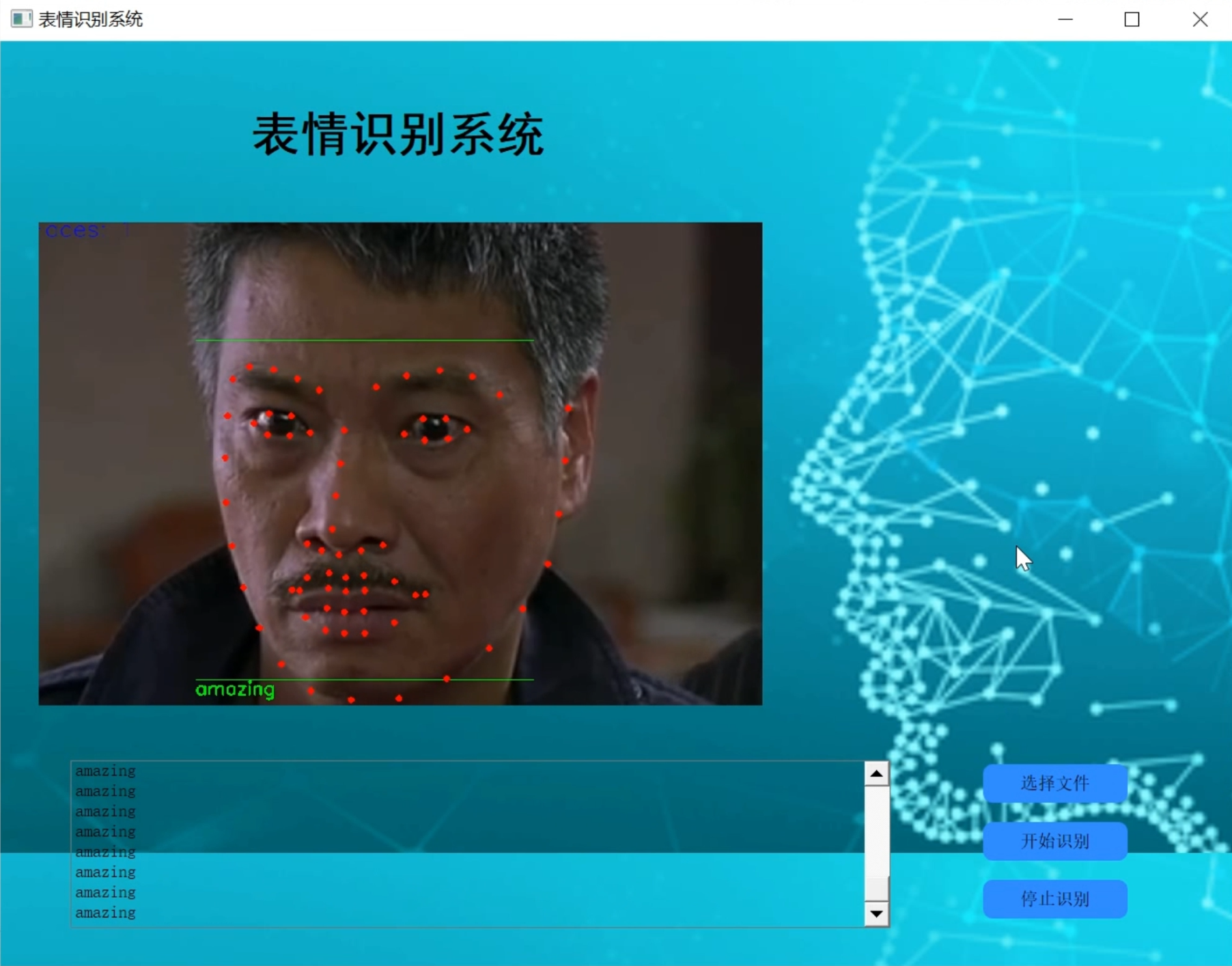
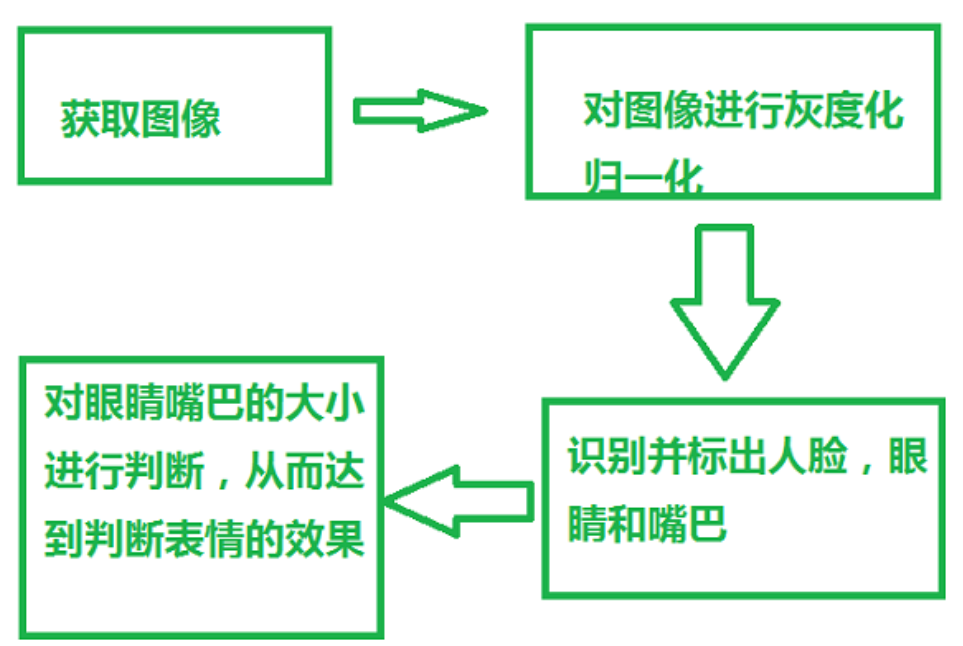
人脸表情识别中需要运用人脸检测技术,识别人脸之后,再对表情图像做预处理(彩色图像灰度化、图像几何归一化和光照预处理),然后再对表情特征进行提取,分析,从而实现对表情的识别。国内外对于人脸的表情识别的研究近几年非常的多,涌现出了很多的算法,但对于表情的识别精度还是有待改进。
人脸表情识别中需要运用人脸检测技术,识别人脸之后,再对表情图像做预处理(彩色图像灰度化、图像几何归一化和光照预处理),然后再对表情特征进行提取,分析,从而实现对表情的识别。国内外对于人脸的表情识别的研究近几年非常的多,涌现出了很多的算法,但对于表情的识别精度还是有待改进。
本设计报告采用人脸检测技术,并进行标记,图像灰度化,图像几何归一化等方法,通过提取出嘴巴,眼睛两个地方的大小变化进行判断。
Fer2013人脸表情数据集由35886张人脸表情图片组成,其中,测试图(Training)28708张,公共验证图(PublicTest)和私有验证图(PrivateTest)各3589张,每张图片是由大小固定为48×48的灰度图像组成,共有7种表情,分别对应于数字标签0-6,具体表情对应的标签和中英文如下:0 anger 生气; 1 disgust 厌恶; 2 fear 恐惧; 3 happy 开心; 4 sad 伤心;5 surprised 惊讶; 6 normal 中性。
但是,数据集并没有直接给出图片,而是将表情、图片数据、用途的数据保存到csv文件中,如下图所示,
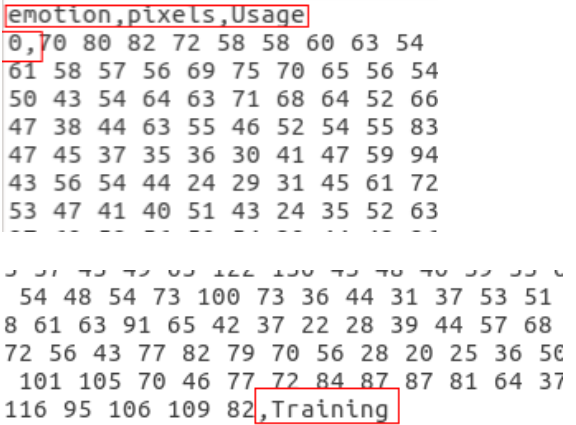
如上图所示,第一张图是csv文件的开头,第一行是表头,说明每列数据的含义,第一列表示表情标签,第二列即为图片数据,这里是原始的图片数据,最后一列为用途。
知道数据结构以后,就好办了,使用pandas解析csv文件,(pandas的简单用法可以查看这篇博客:https://blog.csdn.net/rookie_wei/article/details/82974277 ),再将原始图片数据保存为jpg文件,并根据用途和标签标签进行分类,分别保存到对应文件夹下,代码比较简单,并且做了详细备注,直接给完整代码如下
#encoding:utf-8
import pandas as pd
import numpy as np
import scipy.misc as sm
import os
emotions = {
'0':'anger', #生气
'1':'disgust', #厌恶
'2':'fear', #恐惧
'3':'happy', #开心
'4':'sad', #伤心
'5':'surprised', #惊讶
'6':'normal', #中性
}
#创建文件夹
def createDir(dir):
if os.path.exists(dir) is False:
os.makedirs(dir)
def saveImageFromFer2013(file):
#读取csv文件
faces_data = pd.read_csv(file)
imageCount = 0
#遍历csv文件内容,并将图片数据按分类保存
for index in range(len(faces_data)):
#解析每一行csv文件内容
emotion_data = faces_data.loc[index][0]
image_data = faces_data.loc[index][1]
usage_data = faces_data.loc[index][2]
#将图片数据转换成48*48
data_array = list(map(float, image_data.split()))
data_array = np.asarray(data_array)
image = data_array.reshape(48, 48)
#选择分类,并创建文件名
dirName = usage_data
emotionName = emotions[str(emotion_data)]
#图片要保存的文件夹
imagePath = os.path.join(dirName, emotionName)
# 创建“用途文件夹”和“表情”文件夹
createDir(dirName)
createDir(imagePath)
#图片文件名
imageName = os.path.join(imagePath, str(index) + '.jpg')
sm.toimage(image).save(imageName)
imageCount = index
print('总共有' + str(imageCount) + '张图片')
if __name__ == '__main__':
saveImageFromFer2013('fer2013.csv')
运行完上面的代码后,得到3个文件夹,文件下有相应的表情的子文件夹

子文件夹下又有相应的图片

百度面包多搜索标题名即可下载源码
关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭4年前。Improvethisquestion我想在固定时间创建一系列低音和高音调的哔哔声。例如:在150毫秒时发出高音调的蜂鸣声在151毫秒时发出低音调的蜂鸣声200毫秒时发出低音调的蜂鸣声250毫秒的高音调蜂鸣声有没有办法在Ruby或Python中做到这一点?我真的不在乎输出编码是什么(.wav、.mp3、.ogg等等),但我确实想创建一个输出文件。
我是Google云的新手,我正在尝试对其进行首次部署。我的第一个部署是RubyonRails项目。我基本上是在关注thisguideinthegoogleclouddocumentation.唯一的区别是我使用的是我自己的项目,而不是他们提供的“helloworld”项目。这是我的app.yaml文件runtime:customvm:trueentrypoint:bundleexecrackup-p8080-Eproductionconfig.ruresources:cpu:0.5memory_gb:1.3disk_size_gb:10当我转到我的项目目录并运行gcloudprevie
这个问题在这里已经有了答案:关闭10年前。PossibleDuplicate:Pythonconditionalassignmentoperator对于这样一个简单的问题表示歉意,但是谷歌搜索||=并不是很有帮助;)Python中是否有与Ruby和Perl中的||=语句等效的语句?例如:foo="hey"foo||="what"#assignfooifit'sundefined#fooisstill"hey"bar||="yeah"#baris"yeah"另外,类似这样的东西的通用术语是什么?条件分配是我的第一个猜测,但Wikipediapage跟我想的不太一样。
什么是ruby的rack或python的Java的wsgi?还有一个路由库。 最佳答案 来自Python标准PEP333:Bycontrast,althoughJavahasjustasmanywebapplicationframeworksavailable,Java's"servlet"APImakesitpossibleforapplicationswrittenwithanyJavawebapplicationframeworktoruninanywebserverthatsupportstheservletAPI.ht
导读语言模型给我们的生产生活带来了极大便利,但同时不少人也利用他们从事作弊工作。如何规避这些难辨真伪的文字所产生的负面影响也成为一大难题。在3月9日智源Live第33期活动「DetectGPT:判断文本是否为机器生成的工具」中,主讲人Eric为我们讲解了DetectGPT工作背后的思路——一种基于概率曲率检测的用于检测模型生成文本的工具,它可以帮助我们更好地分辨文章的来源和可信度,对保护信息真实、防止欺诈等方面具有重要意义。本次报告主要围绕其功能,实现和效果等展开。(文末点击“阅读原文”,查看活动回放。)Ericmitchell斯坦福大学计算机系四年级博士生,由ChelseaFinn和Chri
我可以在Azure网站上部署RubyonRails吗? 最佳答案 还没有。目前仅支持.NET和PHP。 关于ruby-on-rails-RubyonRails可以部署在Azure网站上吗?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/12964010/
导读:随着叮咚买菜业务的发展,不同的业务场景对数据分析提出了不同的需求,他们希望引入一款实时OLAP数据库,构建一个灵活的多维实时查询和分析的平台,统一数据的接入和查询方案,解决各业务线对数据高效实时查询和精细化运营的需求。经过调研选型,最终引入ApacheDoris作为最终的OLAP分析引擎,Doris作为核心的OLAP引擎支持复杂地分析操作、提供多维的数据视图,在叮咚买菜数十个业务场景中广泛应用。作者|叮咚买菜资深数据工程师韩青叮咚买菜创立于2017年5月,是一家专注美好食物的创业公司。叮咚买菜专注吃的事业,为满足更多人“想吃什么”而努力,通过美好食材的供应、美好滋味的开发以及美食品牌的孵
电脑0x0000001A蓝屏错误怎么U盘重装系统教学分享。有用户电脑开机之后遇到了系统蓝屏的情况。系统蓝屏问题很多时候都是系统bug,只有通过重装系统来进行解决。那么蓝屏问题如何通过U盘重装新系统来解决呢?来看看以下的详细操作方法教学吧。 准备工作: 1、U盘一个(尽量使用8G以上的U盘)。 2、一台正常联网可使用的电脑。 3、ghost或ISO系统镜像文件(Win10系统下载_Win10专业版_windows10正式版下载-系统之家)。 4、在本页面下载U盘启动盘制作工具:系统之家U盘启动工具。 U盘启动盘制作步骤: 注意:制作期间,U盘会被格式化,因此U盘中的重要文件请注
华为OD机试题本篇题目:明明的随机数题目输入描述输出描述:示例1输入输出说明代码编写思路最近更新的博客华为od2023|什么是华为od,od薪资待遇,od机试题清单华为OD机试真题大全,用Python解华为机试题|机试宝典【华为OD机试】全流程解析+经验分享,题型分享,防作弊指南华为o
在应用开发中,有时候我们需要获取系统的设备信息,用于数据上报和行为分析。那在鸿蒙系统中,我们应该怎么去获取设备的系统信息呢,比如说获取手机的系统版本号、手机的制造商、手机型号等数据。1、获取方式这里分为两种情况,一种是设备信息的获取,一种是系统信息的获取。1.1、获取设备信息获取设备信息,鸿蒙的SDK包为我们提供了DeviceInfo类,通过该类的一些静态方法,可以获取设备信息,DeviceInfo类的包路径为:ohos.system.DeviceInfo.具体的方法如下:ModifierandTypeMethodDescriptionstatic StringgetAbiList()Obt