问题说明
一天下午,在北京客户现场的同学反馈我们elasticsearch出现的大量的异常,他反馈说他使用多线程写入大量数据到elasticsearch集群时,隔一段时间之后就会出现CircuitBreakingException,多尝试几次后,他就把问题反馈到我们这边了

解决思路
1.降低并发度
看到这个问题我首先想到的是减少写入的并发量,毕竟很明显是达到内存的阈值
ES 为了避免 OOM 会设置一些 circuit breaker (断路器),这些断路器的作用就是在内存不够的时候主动拒绝接下来的操作,而不是进一步的分配内存最终产生 OutOfMemoryError,断路器的作用就是保护整个进程不至于挂掉。
因此我就跟现场同学说,先把并发度降下来,我们是16个进程,先改为4个进程,发现问题还存在,于是我就跟现场同学说,把并发度降低为单线程,结果问题依然存在。
2.提高阈值
竟然降低并发解决不了,我们就想到能不能提高的elasticsearch熔断的阈值,给它更大的内存进行处理,当然这种方式是指标不治本的,于是我们参考官方熔断阈值设置,因此我将一些阈值动态的调大了,结果发现线程同学反馈问题依旧存在,调大了没有起到什么作用。而且过了一会,现场同学反馈我们集群状态变为yello了,出现了很多unassign的分片,而且此时kibana也变得很不稳定,经常性的卡死,同时还出现节点丢失的情况

3.尝试解决未分配分片
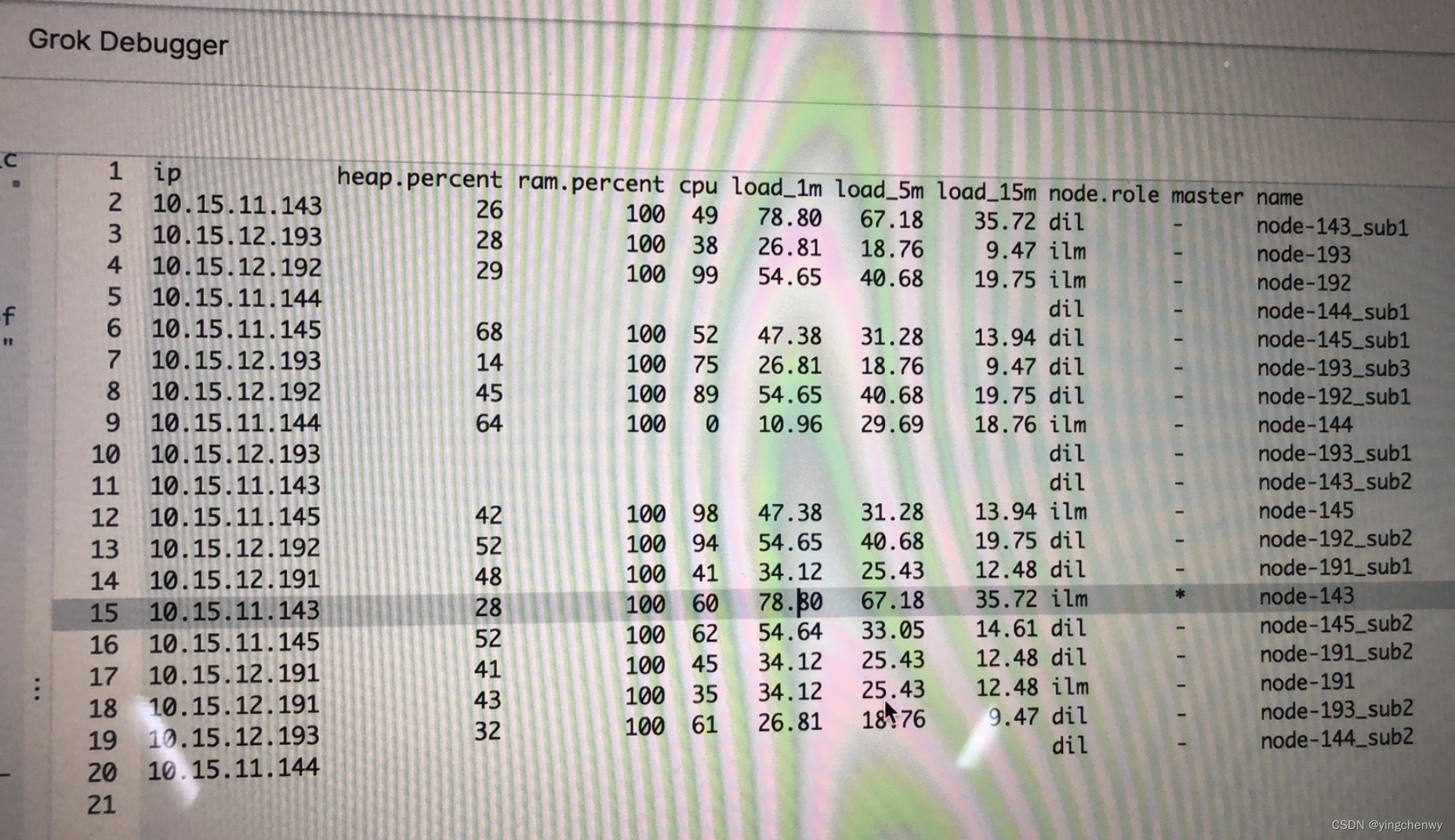
因为,于是就让现场同学停止写入,先等待集群状态恢复为green,决定先等半个小时,让es集群自动进行平衡,结果半小时之后,es集群并没有恢复,此时觉得问题有些大了,感觉集群出了较大的问题,于是我们尝试分析unassign的原因,于是使用Cluster allocation explain API对这些unassign的分片进行分析,分析结果如下
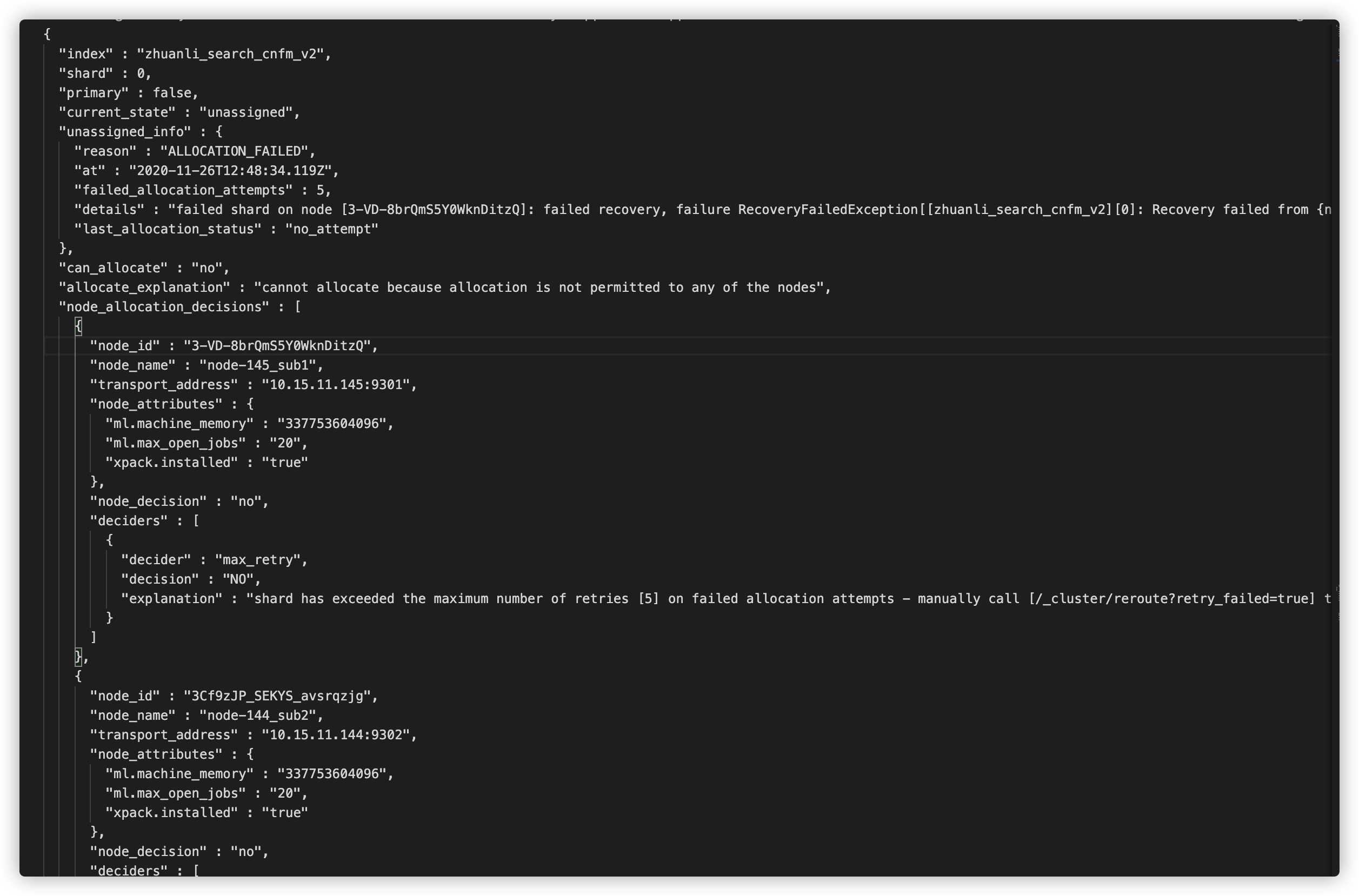
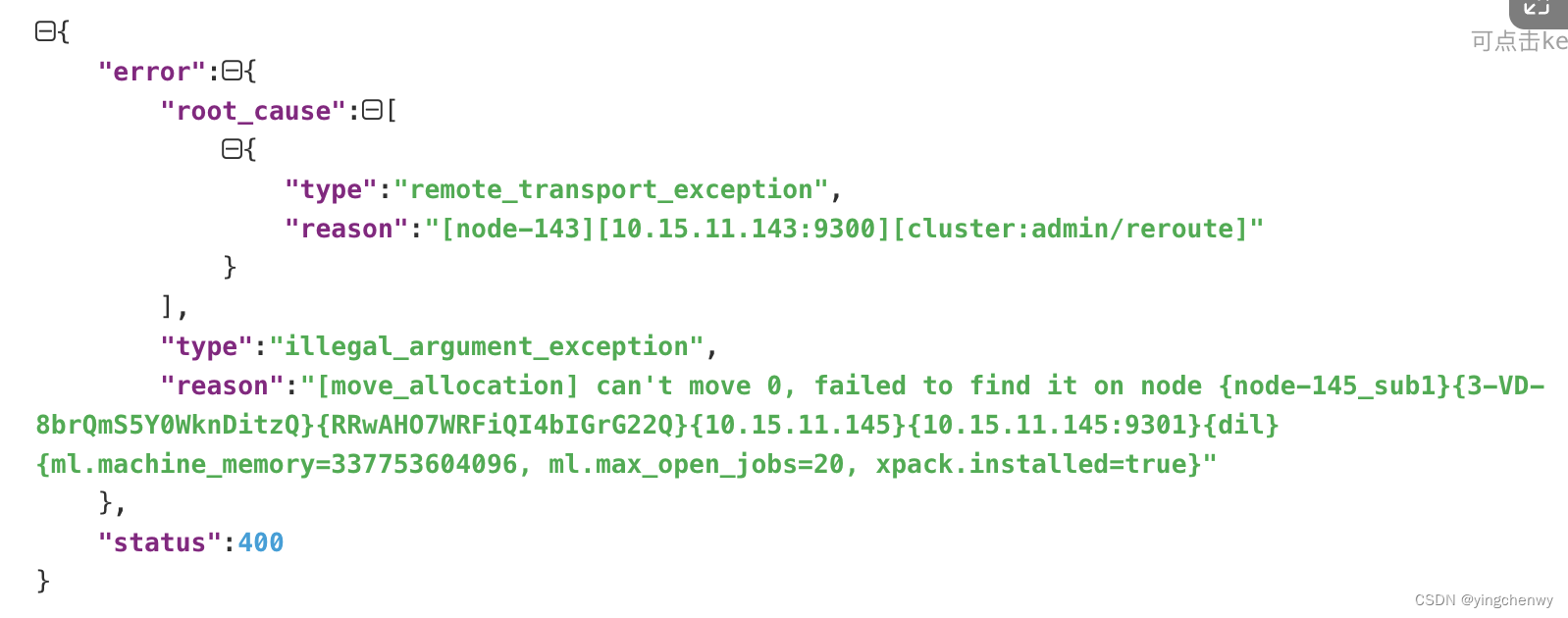
根据分析,大致是recover失败,超过了最大的尝试次数,建议我们通过手动的形式去处理,因此我们尝试通过Cluster reroute API进行手动迁移分片,当然是显而易见的失败了,错误如下
4.限制集群节点的流量
虽然觉察到可能是由于GC引起了,但我们首先希望能够通过非重启的方法先暂时去解决,然后再去分析原因,最后在最终找到解决方案,
因为我们此时节点是黄的,此时集群的容错率很低,万一为了修改某些参数在重启的过程中,存在或者某一台节点出现问题,无法正常启动,导致数据数据丢失,不到万不得已,不会重建集群。
于是我们就想到控制节点的流量,降低传输的速度,于是我们就做了如下事情
1.取消有问题的副本
2.使用Index Recover设置集群传输的速度
indices.recovery.max_bytes_per_sec:限制每个节点的出栈入站流量,默认40mb,我们这里改为20mb;indices.recovery.max_concurrent_file_chunks:每次恢复并行发送的文件块请求的数量,默认为2,这里改为1
3.重新将副本设置为1
及时,这样问题还是没有解决,过了一会依旧出现了这样的问题
5.GC参数调整
虽然之前认为GC可能存在问题,但我认为GC是果,不是因,尝试去解决让GC不正常的问题,当然都失败了。
查看kibana的监控,找到出现问题节点的监控,图如下
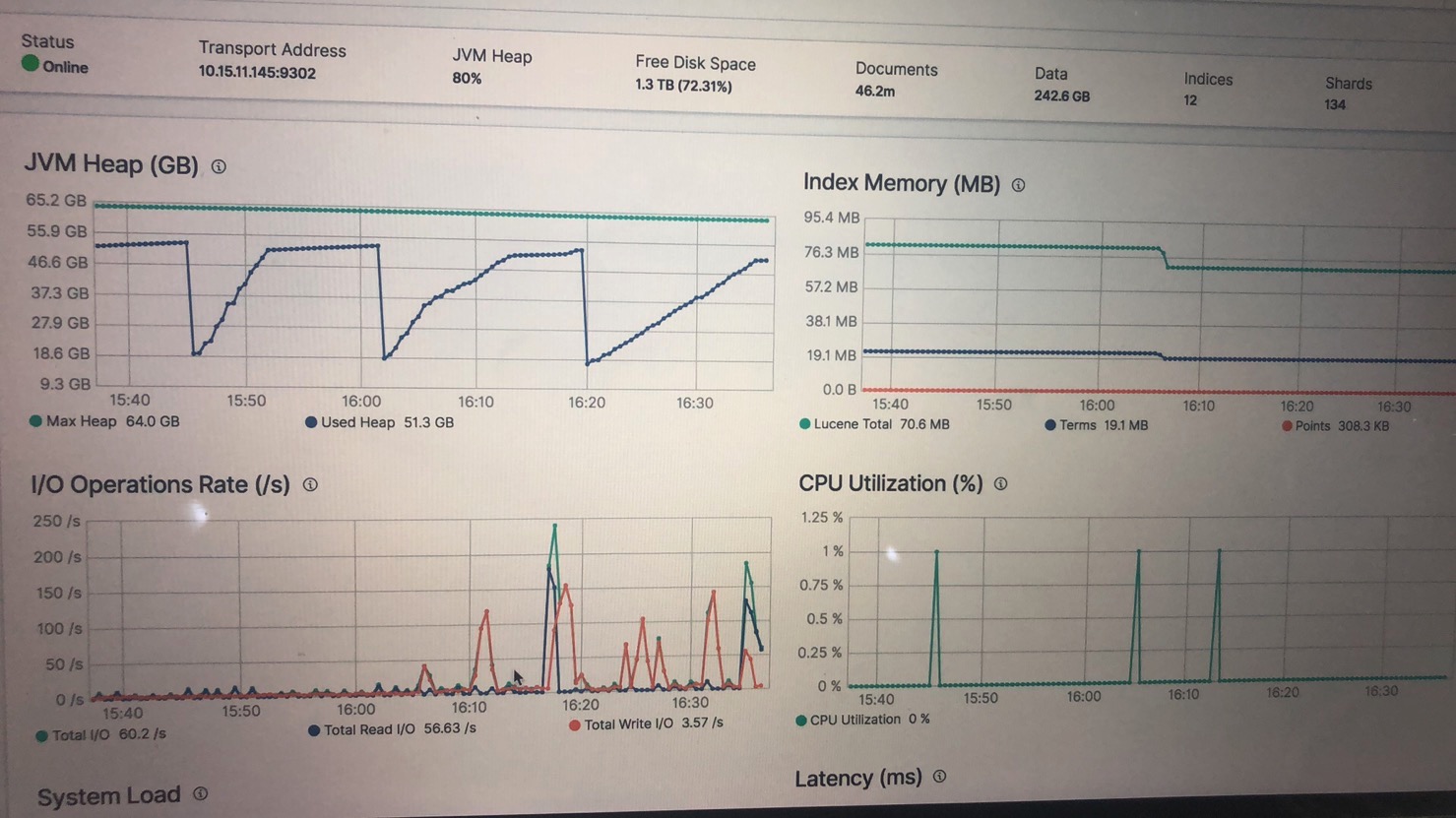
根据此图发现es节点内存占用率一直在上升,说明申请的内存大于回收的内存空间,那么到内存快满的时候还有请求进行,那么必然内存不足,触发CircuitBreakingException。那么此时会进行fullgc,导致节点假死,就出现图中的现象。
我们使用的是G1
因此,就这种情况我就提出了我的想法,能够提前GC,那么就能够降低内存不足状况的概率,当然这样子的话,GC会更加频繁,降低系统的吞吐量,对比现状,显然是保护es集群更加重要,于是我们就参照这个想法去调整G1回收器的参数
查询G1参数列表如下

-XX:InitiatingHeapOccupancyPercent=30 默认为45%,这里是为了让垃圾回收器提前进入垃圾回收周期
-XX:G1ReservePercent=25% 默认10%,保留更多的内存空间,避免内存不足导致错误
重启集群
此时由于集群时yello状态,表明集群万一有一台重启失败或者出现意外,那么就势必导致数据丢失,因此必要要慎重。于是,我们跟现场同步进行沟通,指定重启步骤
1.提前修改所有节点的配置
2.将有问题的索引的副本设置为0
3.限制节点流程和传输,参考上面
4.禁止集群自动分配,避免因为重启导致集群重启导致分片自动分配,同时也为了数据快速恢复,参考Cluster-level shard allocation and routing settings
PUT _cluster/settings
{
"persistent": {
"cluster.routing.allocation.enable": "none"
}
}
5.依次重启每一台几点
6.打开集群分片设置,设置策略为 "all"
7.恢复索引副本设置
上述步骤执行完成后,我们就等待集群恢复,发现副本能够正常恢复,同时并发写入也没有问题了,当然我们降低了并发度
总结
垃圾回收器改变带来的影响
一周前我们使用的垃圾回收器为CMS回收器,因为项目并发问题修改为G1,在使用CMS的时候这个问题并没有出现,但改成G1后出出现了
CMS和G1区别
CMS分为老年代和年轻代,当内存区域即将耗尽时会进行垃圾回收,回收时是线程停止的
G1内存是按region进行划分的,虽然也分年轻代和老年代,但并不严格,那块region是老年代或者新生代并非一成不变的,这是由垃圾回收器自动进行管理的,G1可以提供可预测的停顿,这是由region划分这个特性决定的
原因分析
索引数据体积过大,写入消耗内存过快,同时由于垃圾回收速度过慢,导致内存不停上涨,导致错误的发生
后续改进
1.由于应用直接多线程大量数据写入,导致es集群压力过大,中间缺少一层对写入流量进行控制,同时应当对集群进行压测,了解集群的写入状况,避免集群过载
2.GC改进,有上面总结,造成熔断的一个重要原因是垃圾回收过慢,为什么回收过慢,是因为我们设置-XX:MaxGCPauseMillis=200,这个参数表示最长垃圾回收时间,该属性设置过小,导致垃圾回收过慢,因此我们可以适当调大该属性,具体多少就该进行测试了
G1回收时并非我们常见那种对所有内存区域进行回收,而是选择一部分内存块进行回收,具体回收多少,有用户设置进行决定,这里由于设置过小,导致回收过慢,也是导致熔断的原因
参考
Elasticsearch新增节点引发CircuitBreakingException错误 - 御坂研究所
Elasticsearch Guide [8.6] | Elastic
好的,所以我的目标是轻松地将一些数据保存到磁盘以备后用。您如何简单地写入然后读取一个对象?所以如果我有一个简单的类classCattr_accessor:a,:bdefinitialize(a,b)@a,@b=a,bendend所以如果我从中非常快地制作一个objobj=C.new("foo","bar")#justgaveitsomerandomvalues然后我可以把它变成一个kindaidstring=obj.to_s#whichreturns""我终于可以将此字符串打印到文件或其他内容中。我的问题是,我该如何再次将这个id变回一个对象?我知道我可以自己挑选信息并制作一个接受该信
我正在学习Rails,并阅读了关于乐观锁的内容。我已将类型为integer的lock_version列添加到我的articles表中。但现在每当我第一次尝试更新记录时,我都会收到StaleObjectError异常。这是我的迁移:classAddLockVersionToArticle当我尝试通过Rails控制台更新文章时:article=Article.first=>#我这样做:article.title="newtitle"article.save我明白了:(0.3ms)begintransaction(0.3ms)UPDATE"articles"SET"title"='dwdwd
在Cooper的书BeginningRuby中,第166页有一个我无法重现的示例。classSongincludeComparableattr_accessor:lengthdef(other)@lengthother.lengthenddefinitialize(song_name,length)@song_name=song_name@length=lengthendenda=Song.new('Rockaroundtheclock',143)b=Song.new('BohemianRhapsody',544)c=Song.new('MinuteWaltz',60)a.betwee
我早就知道Ruby中的“常量”(即大写的变量名)不是真正常量。与其他编程语言一样,对对象的引用是唯一存储在变量/常量中的东西。(侧边栏:Ruby确实具有“卡住”引用对象不被修改的功能,据我所知,许多其他语言都没有提供这种功能。)所以这是我的问题:当您将一个值重新分配给常量时,您会收到如下警告:>>FOO='bar'=>"bar">>FOO='baz'(irb):2:warning:alreadyinitializedconstantFOO=>"baz"有没有办法强制Ruby抛出异常而不是打印警告?很难弄清楚为什么有时会发生重新分配。 最佳答案
相信很多人在录制视频的时候都会遇到各种各样的问题,比如录制的视频没有声音。屏幕录制为什么没声音?今天小编就和大家分享一下如何录制音画同步视频的具体操作方法。如果你有录制的视频没有声音,你可以试试这个方法。 一、检查是否打开电脑系统声音相信很多小伙伴在录制视频后会发现录制的视频没有声音,屏幕录制为什么没声音?如果当时没有打开音频录制,则录制好的视频是没有声音的。因此,建议在录制前进行检查。屏幕上没有声音,很可能是因为你的电脑系统的声音被禁止了。您只需打开电脑系统的声音,即可录制音频和图画同步视频。操作方法:步骤1:点击电脑屏幕右下侧的“小喇叭”图案,在上方的选项中,选择“声音”。 步骤2:在“声
首先回顾一下拉格朗日定理的内容:函数f(x)是在闭区间[a,b]上连续、开区间(a,b)上可导的函数,那么至少存在一个,使得:通过这个表达式我们可以知道,f(x)是函数的主体,a和b可以看作是主体函数f(x)中所取的两个值。那么可以有, 也就意味着我们可以用来替换 这种替换可以用在求某些多项式差的极限中。方法: 外层函数f(x)是一致的,并且h(x)和g(x)是等价无穷小。此时,利用拉格朗日定理,将原式替换为 ,再进行求解,往往会省去复合函数求极限的很多麻烦。使用要注意:1.要先找到主体函数f(x),即外层函数必须相同。2.f(x)找到后,复合部分是等价无穷小。3.要满足作差的形式。如果是加
文章目录一、概述简介原理模块二、配置Mysql使用版本环境要求1.操作系统2.mysql要求三、配置canal-server离线下载在线下载上传解压修改配置单机配置集群配置分库分表配置1.修改全局配置2.实例配置垂直分库水平分库3.修改group-instance.xml4.启动监听四、配置canal-adapter1修改启动配置2配置映射文件3启动ES数据同步查询所有订阅同步数据同步开关启动4.验证五、配置canal-admin一、概述简介canal是Alibaba旗下的一款开源项目,Java开发。基于数据库增量日志解析,提供增量数据订阅&消费。Git地址:https://github.co
SPI接收数据左移一位问题目录SPI接收数据左移一位问题一、问题描述二、问题分析三、探究原理四、经验总结最近在工作在学习调试SPI的过程中遇到一个问题——接收数据整体向左移了一位(1bit)。SPI数据收发是数据交换,因此接收数据时从第二个字节开始才是有效数据,也就是数据整体向右移一个字节(1byte)。请教前辈之后也没有得到解决,通过在网上查阅前人经验终于解决问题,所以写一个避坑经验总结。实际背景:MCU与一款芯片使用spi通信,MCU作为主机,芯片作为从机。这款芯片采用的是它规定的六线SPI,多了两根线:RDY和INT,这样从机就可以主动请求主机给主机发送数据了。一、问题描述根据从机芯片手
深度学习部署:Windows安装pycocotools报错解决方法1.pycocotools库的简介2.pycocotools安装的坑3.解决办法更多Ai资讯:公主号AiCharm本系列是作者在跑一些深度学习实例时,遇到的各种各样的问题及解决办法,希望能够帮助到大家。ERROR:Commanderroredoutwithexitstatus1:'D:\Anaconda3\python.exe'-u-c'importsys,setuptools,tokenize;sys.argv[0]='"'"'C:\\Users\\46653\\AppData\\Local\\Temp\\pip-instal
ES一、简介1、ElasticStackES技术栈:ElasticSearch:存数据+搜索;QL;Kibana:Web可视化平台,分析。LogStash:日志收集,Log4j:产生日志;log.info(xxx)。。。。使用场景:metrics:指标监控…2、基本概念Index(索引)动词:保存(插入)名词:类似MySQL数据库,给数据Type(类型)已废弃,以前类似MySQL的表现在用索引对数据分类Document(文档)真正要保存的一个JSON数据{name:"tcx"}二、入门实战{"name":"DESKTOP-1TSVGKG","cluster_name":"elasticsear