 Bytebase 是一个开源数据库 DevOps 工具,它相当于在整个应用程序开发生命周期中管理数据库的 GitLab,它为 DBA 和开发人员提供了一个基于 Web 的工作空间,以安全有效地协作和管理数据库变更。随着 DevOps 进入主流,大部分团队采用 GitLab/GitHub 等工具来管理代码,并开始采用 Terraform 来管理基础设施,同样的,Bytebase 就是在应用程序开发期间管理数据库的这样的一个工具。Bytebase 是对现有云提供商的数据库平台或公司内部数据库运维平台的补充,虽然这些平台负责数据库实例级别的操作(例如配置数据库实例),但 Bytebase 会帮助团队使用配置的数据库来构建他们的应用程序。
Bytebase 是一个开源数据库 DevOps 工具,它相当于在整个应用程序开发生命周期中管理数据库的 GitLab,它为 DBA 和开发人员提供了一个基于 Web 的工作空间,以安全有效地协作和管理数据库变更。随着 DevOps 进入主流,大部分团队采用 GitLab/GitHub 等工具来管理代码,并开始采用 Terraform 来管理基础设施,同样的,Bytebase 就是在应用程序开发期间管理数据库的这样的一个工具。Bytebase 是对现有云提供商的数据库平台或公司内部数据库运维平台的补充,虽然这些平台负责数据库实例级别的操作(例如配置数据库实例),但 Bytebase 会帮助团队使用配置的数据库来构建他们的应用程序。docker run --init \
--name bytebase \
--restart always \
--add-host host.docker.internal:host-gateway \
--publish 8080:8080 \
--volume ~/.bytebase/data:/var/opt/bytebase \
bytebase/bytebase:1.2.2 \
--data /var/opt/bytebase \
--host http://localhost \
--port 8080apiVersion: apps/v1
kind: Deployment
metadata:
name: bytebase
namespace: default
spec:
selector:
matchLabels:
app: bytebase
template:
metadata:
labels:
app: bytebase
spec:
containers:
- name: bytebase
image: bytebase/bytebase:1.2.2
args: ["--data", "/var/opt/bytebase", "--host", "http://localhost", "--port", "8080"]
ports:
- containerPort: 8080
volumeMounts:
- name: data
mountPath: /var/opt/bytebase
volumes:
- name: data
emptyDir: {}
---
apiVersion: v1
kind: Service
metadata:
name: bytebase-entrypoint
namespace: default
spec:
type: LoadBalancer
selector:
app: bytebase
ports:
- protocol: TCP
port: 8080
targetPort: 8080 admin 账号创建后,我们可以注册一个普通的账号会被授予 Workspace Developer 角色。
admin 账号创建后,我们可以注册一个普通的账号会被授予 Workspace Developer 角色。 登录后进入到 Bytebase 的主页我们就可以根据需要创建项目、添加数据实例或者环境了,下面的一些图展示了 Bytebase 的一些示例。
登录后进入到 Bytebase 的主页我们就可以根据需要创建项目、添加数据实例或者环境了,下面的一些图展示了 Bytebase 的一些示例。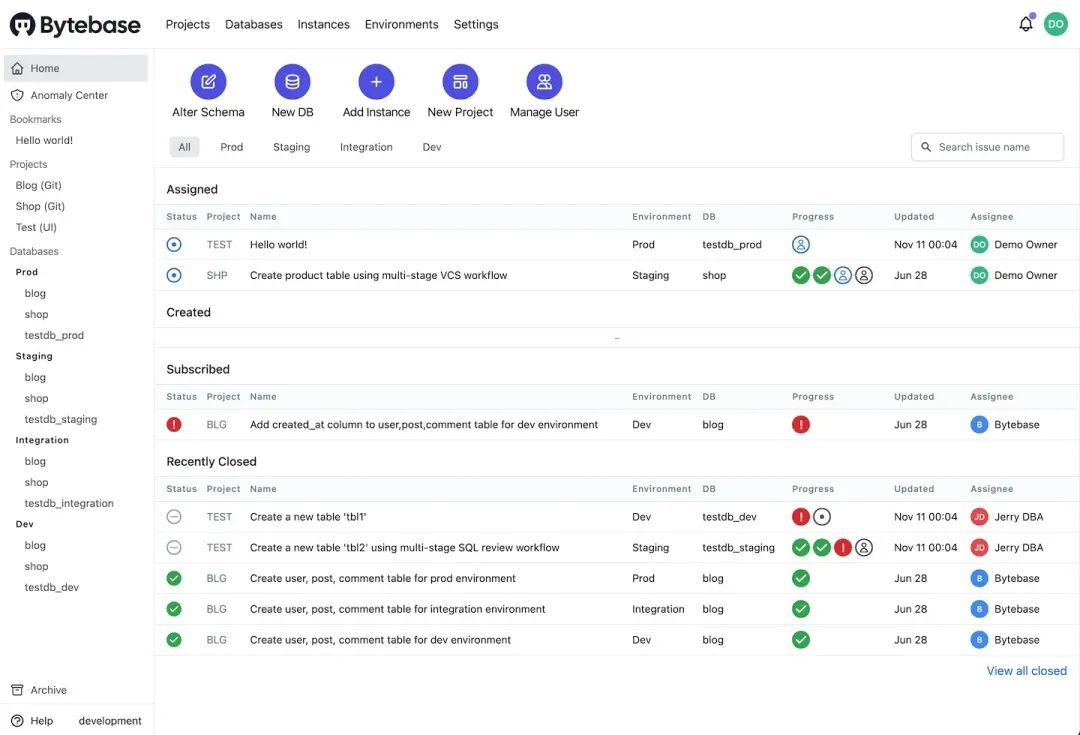 图 1 - Dashboard
图 1 - Dashboard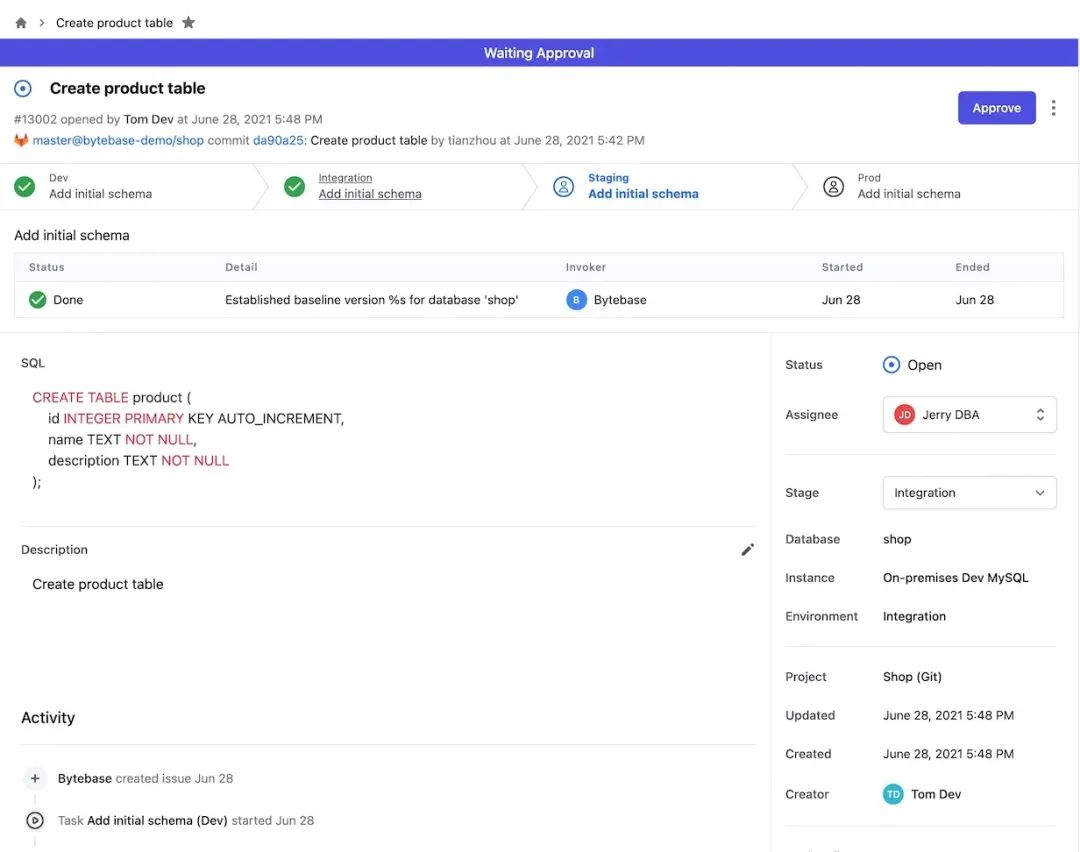 图 2 - SQL review issue 流水线
图 2 - SQL review issue 流水线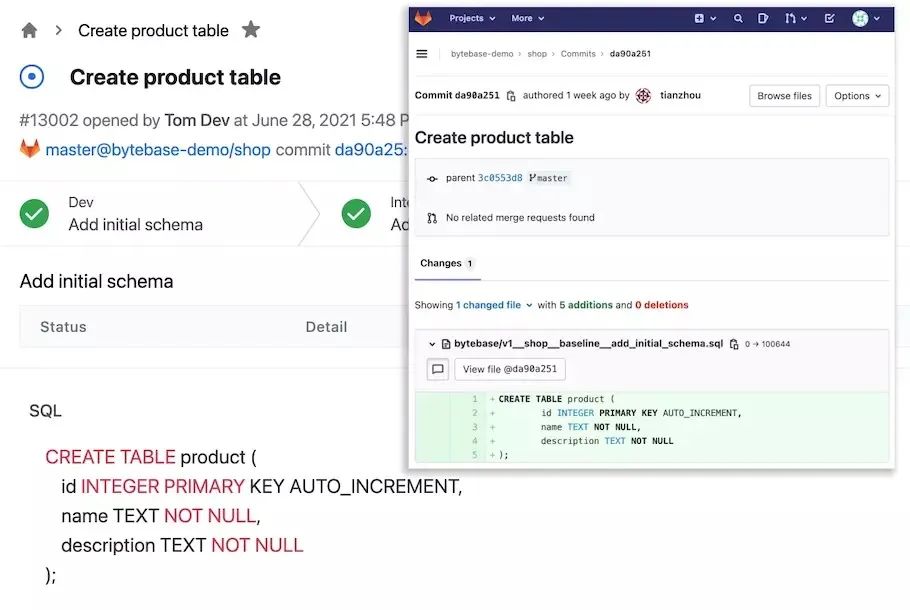 图 3 - 基于 GitLab 的 schema 迁移(Database as code)
图 3 - 基于 GitLab 的 schema 迁移(Database as code)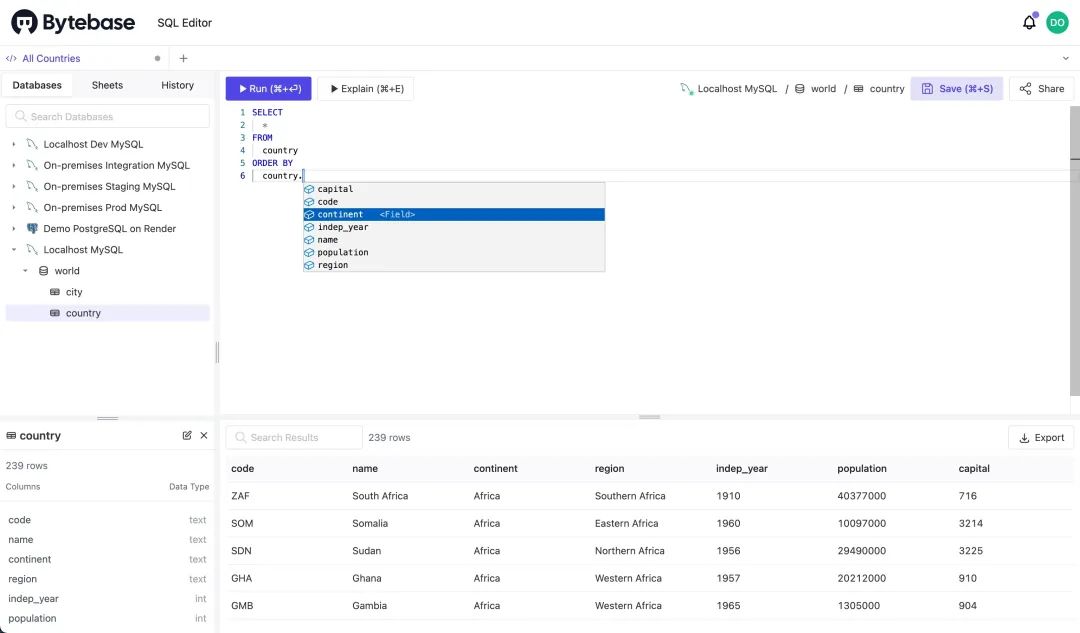 图 4 - 内置的 SQL 编辑器此外 Bytebase 还可以了一些在线 Demo 可以体验,地址:https://demo.bytebase.com,我们可以前往进行体验。关于 Bytebase 的更多使用可以参考官方文档 https://www.bytebase.com/docs 了解更多相关信息。
图 4 - 内置的 SQL 编辑器此外 Bytebase 还可以了一些在线 Demo 可以体验,地址:https://demo.bytebase.com,我们可以前往进行体验。关于 Bytebase 的更多使用可以参考官方文档 https://www.bytebase.com/docs 了解更多相关信息。Git 仓库:https://github.com/bytebase/bytebase。
类classAprivatedeffooputs:fooendpublicdefbarputs:barendprivatedefzimputs:zimendprotecteddefdibputs:dibendendA的实例a=A.new测试a.foorescueputs:faila.barrescueputs:faila.zimrescueputs:faila.dibrescueputs:faila.gazrescueputs:fail测试输出failbarfailfailfail.发送测试[:foo,:bar,:zim,:dib,:gaz].each{|m|a.send(m)resc
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
使用带有Rails插件的vim,您可以创建一个迁移文件,然后一次性打开该文件吗?textmate也可以这样吗? 最佳答案 你可以使用rails.vim然后做类似的事情::Rgeneratemigratonadd_foo_to_bar插件将打开迁移生成的文件,这正是您想要的。我不能代表textmate。 关于ruby-使用VimRails,您可以创建一个新的迁移文件并一次性打开它吗?,我们在StackOverflow上找到一个类似的问题: https://sta
查看Ruby的CSV库的文档,我非常确定这是可能且简单的。我只需要使用Ruby删除CSV文件的前三列,但我没有成功运行它。 最佳答案 csv_table=CSV.read(file_path_in,:headers=>true)csv_table.delete("header_name")csv_table.to_csv#=>ThenewCSVinstringformat检查CSV::Table文档:http://ruby-doc.org/stdlib-1.9.2/libdoc/csv/rdoc/CSV/Table.html
我发现ActiveRecord::Base.transaction在复杂方法中非常有效。我想知道是否可以在如下事务中从AWSS3上传/删除文件:S3Object.transactiondo#writeintofiles#raiseanexceptionend引发异常后,每个操作都应在S3上回滚。S3Object这可能吗?? 最佳答案 虽然S3API具有批量删除功能,但它不支持事务,因为每个删除操作都可以独立于其他操作成功/失败。该API不提供任何批量上传功能(通过PUT或POST),因此每个上传操作都是通过一个独立的API调用完成的
我正在阅读SandiMetz的POODR,并且遇到了一个我不太了解的编码原则。这是代码:classBicycleattr_reader:size,:chain,:tire_sizedefinitialize(args={})@size=args[:size]||1@chain=args[:chain]||2@tire_size=args[:tire_size]||3post_initialize(args)endendclassMountainBike此代码将为其各自的属性输出1,2,3,4,5。我不明白的是查找方法。当一辆山地自行车被实例化时,因为它没有自己的initialize方法
有时我需要处理键/值数据。我不喜欢使用数组,因为它们在大小上没有限制(很容易不小心添加超过2个项目,而且您最终需要稍后验证大小)。此外,0和1的索引变成了魔数(MagicNumber),并且在传达含义方面做得很差(“当我说0时,我的意思是head...”)。散列也不合适,因为可能会不小心添加额外的条目。我写了下面的类来解决这个问题:classPairattr_accessor:head,:taildefinitialize(h,t)@head,@tail=h,tendend它工作得很好并且解决了问题,但我很想知道:Ruby标准库是否已经带有这样一个类? 最佳
我们的git存储库中目前有一个Gemfile。但是,有一个gem我只在我的环境中本地使用(我的团队不使用它)。为了使用它,我必须将它添加到我们的Gemfile中,但每次我checkout到我们的master/dev主分支时,由于与跟踪的gemfile冲突,我必须删除它。我想要的是类似Gemfile.local的东西,它将继承从Gemfile导入的gems,但也允许在那里导入新的gems以供使用只有我的机器。此文件将在.gitignore中被忽略。这可能吗? 最佳答案 设置BUNDLE_GEMFILE环境变量:BUNDLE_GEMFI
我喜欢使用Textile或Markdown为我的项目编写自述文件,但是当我生成RDoc时,自述文件被解释为RDoc并且看起来非常糟糕。有没有办法让RDoc通过RedCloth或BlueCloth而不是它自己的格式化程序运行文件?它可以配置为自动检测文件后缀的格式吗?(例如README.textile通过RedCloth运行,但README.mdown通过BlueCloth运行) 最佳答案 使用YARD直接代替RDoc将允许您包含Textile或Markdown文件,只要它们的文件后缀是合理的。我经常使用类似于以下Rake任务的东西:
我想让一个yaml对象引用另一个,如下所示:intro:"Hello,dearuser."registration:$introThanksforregistering!new_message:$introYouhaveanewmessage!上面的语法只是它如何工作的一个例子(这也是它在thiscpanmodule中的工作方式。)我正在使用标准的rubyyaml解析器。这可能吗? 最佳答案 一些yaml对象确实引用了其他对象:irb>require'yaml'#=>trueirb>str="hello"#=>"hello"ir