
DNS(Domain Name System)是域名系统的英文缩写,是一种组织成域层次结构的计算机和网络服务命名系统,用于 TCP/IP 网络。
通常我们有两种方式识别主机:通过主机名或者 IP 地址。人们喜欢便于记忆的主机名表示,而路由器则喜欢定长的、有着层次结构的 IP 地址。为了满足这些不同的偏好,我们就需要一种能够进行主机名到IP 地址转换的目录服务,域名系统作为将域名和 IP 地址相互映射的一个分布式数据库,能够使人更方便地访问互联网。
因此,即使不使用域名也可以通过IP地址来寻址目的主机,但域名与IP地址相比,便于人们记忆。因此对于大多数网络应用,我们一般使用域名来访问目的主机,而不是直接使用IP地址来访问。
对于本例,简单来说,当我们在浏览器地址栏中输入某个Web服务器的域名时。用户主机首先用户主机会首先在自己的DNS高速缓存中查找该域名所应的IP地址。
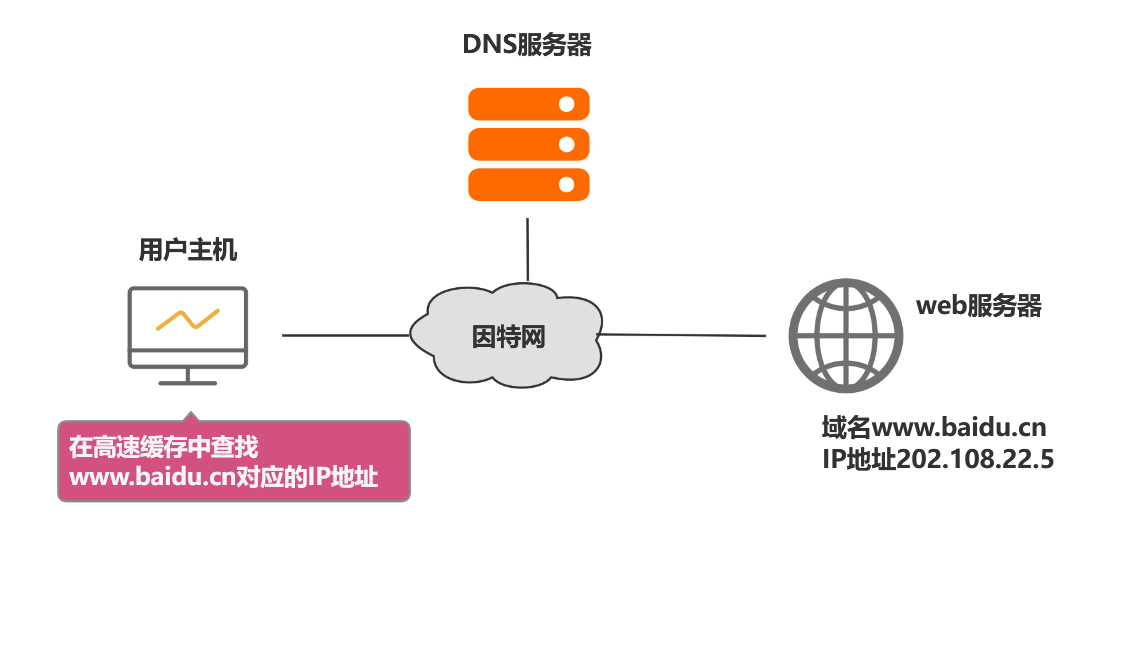
如果没有找到,则会向网络中的某台DNS服务器查询,DNS服务器中有域名和IP地映射关系的数据库。当DNS服务器收到DNS查询报文后,在其数据库中查询,之后将查询结果发送给用户主机。

现在,用户主机中的浏览器可以通过Web服务器的IP地址对其进行访问了。
层级关系特点
因特网采用层次树状结构的域名结构
域名的结构由若干个分量组成,各分量之间用“点”隔开,分别代表不同级别的域名。
域名系统既不规定一个域名需要包含多少个下级域名,也不规定每一级的域名代表什么意思。
各级域名由其上一级的域名管理机构管理,而最高的顶级域名则由因特网名称与数字地址分配机构ICANN进行管理。
因特网的域名空间
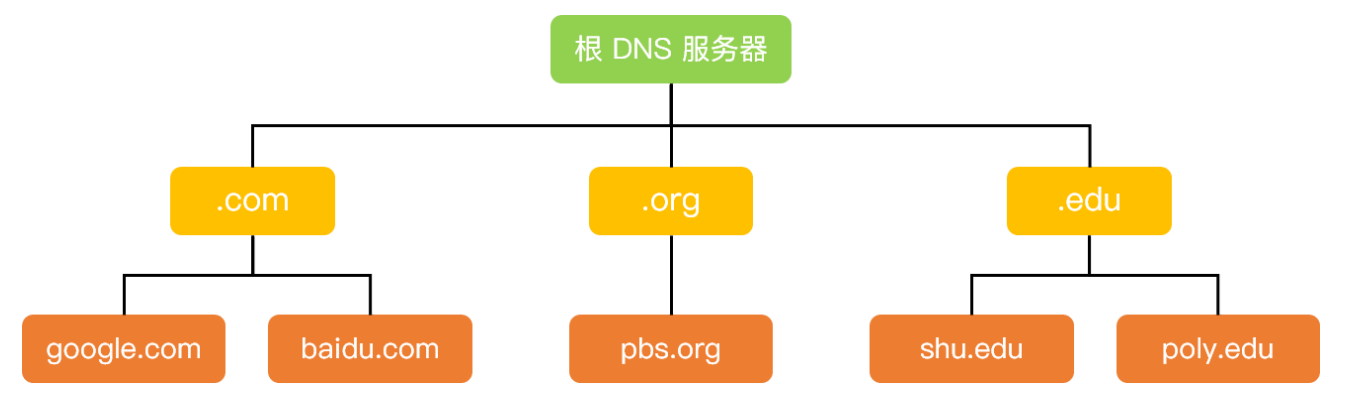
上图展示了 DNS 服务器的部分层次结构,从上到下依次为根域名服务器、顶级域名服务器和权威域名服务器。域名和IP地址的映射关系必须保存在域名服务器中,供所有其他应用查询。显然不能将所有信息都储存在一台域名服务器中。DNS使用分布在各地的域名服务器来实现域名到IP地址的转换。
域名服务器可以划分为以下四种不同的类型:
域名解析包含两种查询方式,分别是递归查询和迭代查询。
如果主机所询问的本地域名服务器不知道被查询域名的 IP 地址,那么本地域名服务器就以 DNS 客户端的身份,向其他根域名服务器继续发出查询请求报文,即替主机继续查询,而不是让主机自己进行下一步查询。
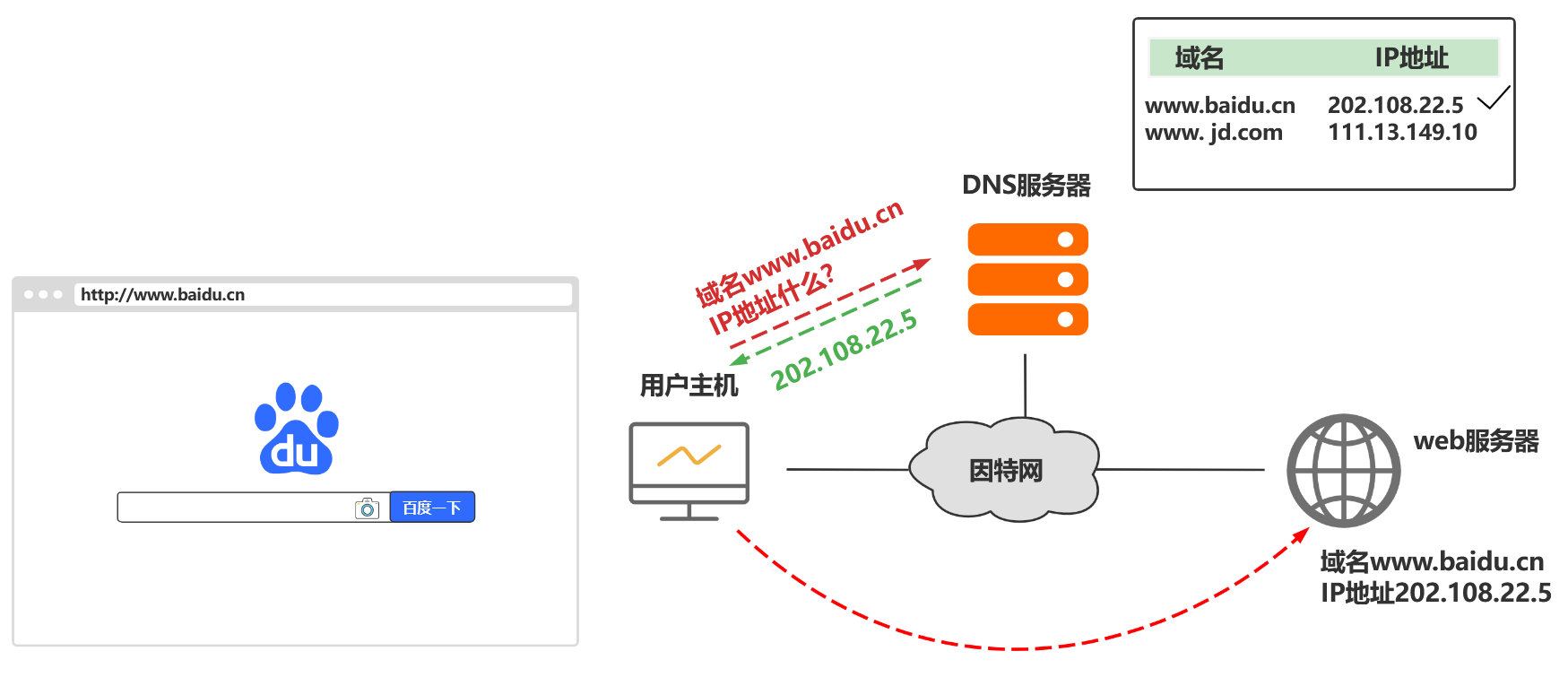
我们以一个例子来了解DNS递归查询的工作原理,假设图中的主机 (IP地址为m.xyz.com) 想知道域名y.abc.com的IP地址。
过程如图所示:

当查询到域名对应的IP地址后,查询结果会在之前受委托的各域名服务器之间传递,最终传回给用户主机。
过程如图所示:
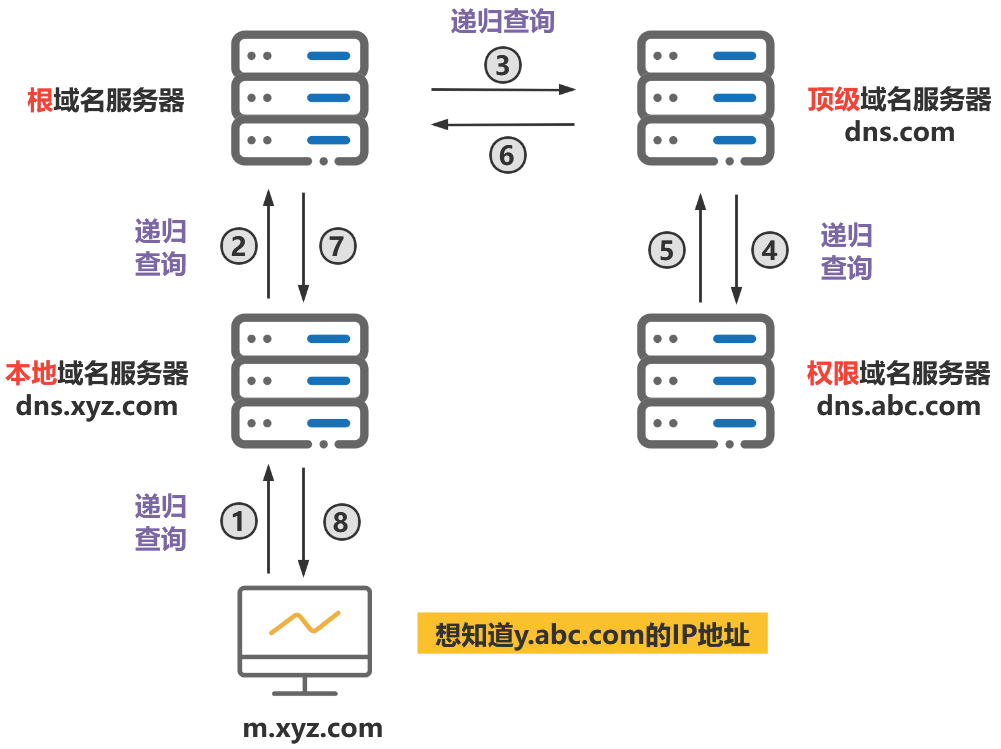
当根域名服务器收到本地域名服务器发出的迭代查询请求报文时,要么给出所要查询的IP 地址,要么告诉本地服务器下一步应该找哪个域名服务器进行查询,然后让本地服务器进行后续的查询。
迭代查询过程如下:
过程如图所示:
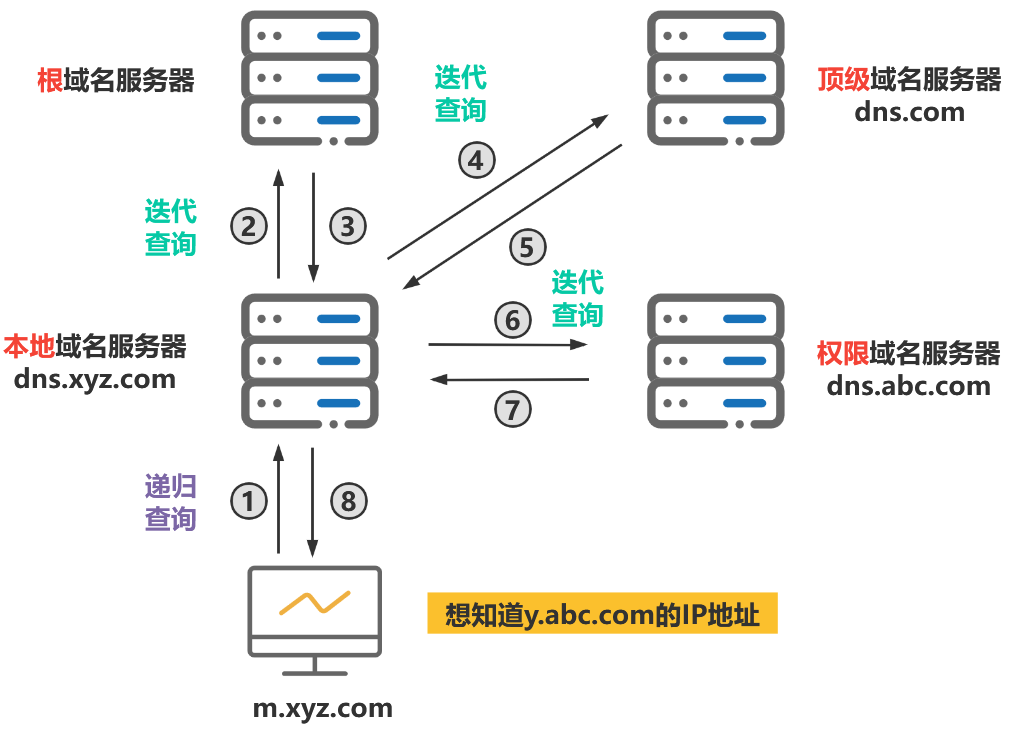
由于递归查询对于被查询的域名服务器负担太大,通常采用以下模式:从请求主机到本地域名服务器的查询是递归查询,而其余的查询是迭代查询。
为了提高DNS的查询效率,并减轻根域名服务器的负荷和减少因特网上的DNS查询报文数量,在域名服务器中广泛地使用了高速缓存。高速缓存用来存放最近查询过的域名以及从何处获得域名映射信息的记录。
由于域名到IP地址的映射关系并不是永久不变,为保持高速缓存中的内容正确,域名服务器应为每项内容设置计时器并删除超过合理时间的项(例如,每个项目只存放两天)。
不但在本地域名服务器中需要高速缓存,在用户主机中也很需要。许多用户主机在启动时从本地域名服务器下载域名和IP地址的全部数据库,维护存放自己最近使用的域名的高速缓存,并且只在从缓存中找不到域名时才向域名服务器查询。同理,主机也需要保持高速缓存中内容的正确性。
如图所示:

如果本地域名服务器不久前已经有用户查询过域名为y.abc.com的IP地址,则本地域名服务器的高速缓存中应该存有该域名对应的IP地址。因此,直接把高速缓存中存放的上次查询结果(即y.abc.com的IP地址)告诉用户。
1、DNS为什么用UDP?
更正确的答案是 DNS 既使用 TCP 又使用 UDP。当进行区域传送(主域名服务器向辅助域名服务器传送变化的那部分数据)时会使用 TCP,因为数据同步传送的数据量比一个请求和应答的数据量要多,而 TCP 允许的报文长度更长,因此为了保证数据的正确性,会使用基于可靠连接的 TCP。
当客户端向 DNS 服务器查询域名 ( 域名解析) 的时候,一般返回的内容不会超过 UDP 报文的最大长度,即 512 字节。用 UDP 传输时,不需要经过 TCP 三次握手的过程,从而大大提高了响应速度,但这要求域名解析器和域名服务器都必须自己处理超时和重传从而保证可靠性。
2、递归查询和递归查询区别?
递归查询: 如果主机所询问的本地域名服务器不知道被查询域名的 IP 地址,那么本地域名服务器就以 DNS 客户端的身份,向其他根域名服务器继续发出查询请求报文,即替主机继续查询,而不是让主机自己进行下一步查询。
迭代查询: 当根域名服务器收到本地域名服务器发出的迭代查询请求报文时,要么给出所要查询的IP 地址,要么告诉本地服务器下一步应该找哪个域名服务器进行查询,然后让本地服务器进行后续的查询。
3、使用域名访问web服务器过程
具体请看本专栏的这篇文章:面试官问我:从地址栏输入URL到显示页面都发生了什么?
4、讲讲DNS解析过程?
详细解析过程请看上文DNS域名解析过程,这里我们做一个总结:
浏览器缓存——》系统hosts文件——》本地DNS解析器缓存——》本地域名服务器(本地配置区域资源、本地域名服务器缓存)——》根域名服务器——》主域名服务器——》下一级域名域名服务器 客户端——》本地域名服务器(递归查询) 本地域名服务器—》DNS服务器的交互查询是迭代查询
|
|

我有一个字符串input="maybe(thisis|thatwas)some((nice|ugly)(day|night)|(strange(weather|time)))"Ruby中解析该字符串的最佳方法是什么?我的意思是脚本应该能够像这样构建句子:maybethisissomeuglynightmaybethatwassomenicenightmaybethiswassomestrangetime等等,你明白了......我应该一个字符一个字符地读取字符串并构建一个带有堆栈的状态机来存储括号值以供以后计算,还是有更好的方法?也许为此目的准备了一个开箱即用的库?
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
我正在使用ruby1.9解析以下带有MacRoman字符的csv文件#encoding:ISO-8859-1#csv_parse.csvName,main-dialogue"Marceu","Giveittohimóhe,hiswife."我做了以下解析。require'csv'input_string=File.read("../csv_parse.rb").force_encoding("ISO-8859-1").encode("UTF-8")#=>"Name,main-dialogue\r\n\"Marceu\",\"Giveittohim\x97he,hiswife.\"\
简而言之错误:NOTE:Gem::SourceIndex#add_specisdeprecated,useSpecification.add_spec.Itwillberemovedonorafter2011-11-01.Gem::SourceIndex#add_speccalledfrom/opt/local/lib/ruby/site_ruby/1.8/rubygems/source_index.rb:91./opt/local/lib/ruby/gems/1.8/gems/rails-2.3.8/lib/rails/gem_dependency.rb:275:in`==':und
我正在使用ruby2.1.0我有一个json文件。例如:test.json{"item":[{"apple":1},{"banana":2}]}用YAML.load加载这个文件安全吗?YAML.load(File.read('test.json'))我正在尝试加载一个json或yaml格式的文件。 最佳答案 YAML可以加载JSONYAML.load('{"something":"test","other":4}')=>{"something"=>"test","other"=>4}JSON将无法加载YAML。JSON.load("
我想用Nokogiri解析HTML页面。页面的一部分有一个表,它没有使用任何特定的ID。是否可以提取如下内容:Today,3,455,34Today,1,1300,3664Today,10,100000,3444,Yesterday,3454,5656,3Yesterday,3545,1000,10Yesterday,3411,36223,15来自这个HTML:TodayYesterdayQntySizeLengthLengthSizeQnty345534345456563113003664354510001010100000344434113622315
我使用的第一个解析器生成器是Parse::RecDescent,它的指南/教程很棒,但它最有用的功能是它的调试工具,特别是tracing功能(通过将$RD_TRACE设置为1来激活)。我正在寻找可以帮助您调试其规则的解析器生成器。问题是,它必须用python或ruby编写,并且具有详细模式/跟踪模式或非常有用的调试技术。有人知道这样的解析器生成器吗?编辑:当我说调试时,我并不是指调试python或ruby。我指的是调试解析器生成器,查看它在每一步都在做什么,查看它正在读取的每个字符,它试图匹配的规则。希望你明白这一点。赏金编辑:要赢得赏金,请展示一个解析器生成器框架,并说明它的
我有这样的HTML代码:Label1Value1Label2Value2...我的代码不起作用。doc.css("first").eachdo|item|label=item.css("dt")value=item.css("dd")end显示所有首先标记,然后标记标签,我需要“标签:值” 最佳答案 首先,您的HTML应该有和中的元素:Label1Value1Label2Value2...但这不会改变您解析它的方式。你想找到s并遍历它们,然后在每个你可以使用next_element得到;像这样:doc=Nokogiri::HTML(
我想禁用HTTP参数的自动XML解析。但我发现命令仅适用于Rails2.x,它们都不适用于3.0:config.action_controller.param_parsers.deleteMime::XML(application.rb)ActionController::Base.param_parsers.deleteMime::XMLRails3.0中的等价物是什么? 最佳答案 根据CVE-2013-0156的最新安全公告你可以将它用于Rails3.0。3.1和3.2ActionDispatch::ParamsParser::
下面是我用来从应用程序中解析CSV的代码,但我想解析位于AmazonS3存储桶中的文件。当推送到Heroku时它也需要工作。namespace:csvimportdodesc"ImportCSVDatatoInventory."task:wiwt=>:environmentdorequire'csv'csv_file_path=Rails.root.join('public','wiwt.csv.txt')CSV.foreach(csv_file_path)do|row|p=Wiwt.create!({:user_id=>row[0],:date_worn=>row[1],:inven