论文:CBAM: Convolutional Block Attention Module
代码: code
目录
(1)Channel attention module(CAM)
(2)Spatial attention module(SAM)
(3)Channel attention+spatial attention
CBAM( Convolutional Block Attention Module )是一种轻量级注意力模块的提出于2018年,它可以在空间维度和通道维度上进行Attention操作。论文在Resnet和MobileNet上加入CBAM模块进行对比,并针对两个注意力模块应用的先后进行实验,同时进行CAM可视化,可以看到Attention更关注目标物体。
CBAM(Convolutional Block Attention Module)是轻量级的卷积注意力模块,它结合了通道和空间的注意力机制模块。
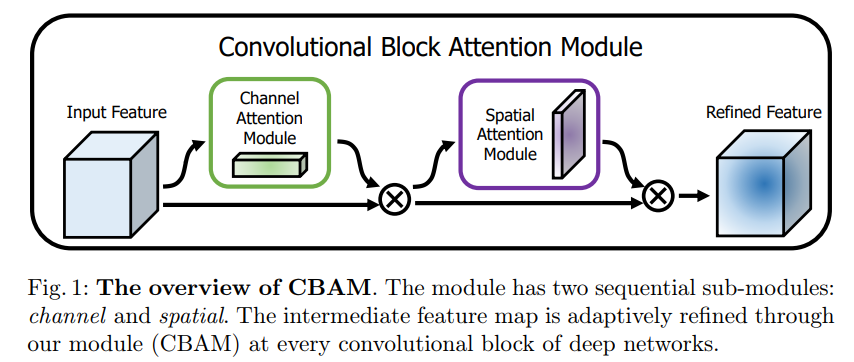
上图可以看到,CBAM包含CAM(Channel Attention Module)和SAM(Spartial Attention Module)两个子模块,分别进行通道和空间上的Attention。这样不只能够节约参数和计算力,并且保证了其能够做为即插即用的模块集成到现有的网络架构中去。
由上图所示,有输入、通道注意力模块、空间注意力模块和输出组成。输入特征,然后是通道注意力模块一维卷积
,将卷积结果乘原图,将CAM输出结果作为输入,进行空间注意力模块的二维卷积
,再将输出结果与原图相乘。
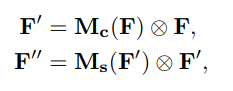
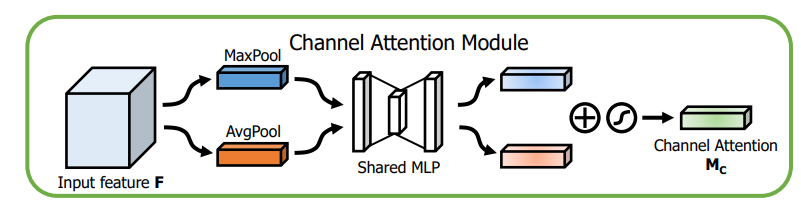
通道注意力模块:通道维度不变,压缩空间维度。该模块关注输入图片中有意义的信息(分类任务就关注因为什么分成了不同类别)。
图解:将输入的feature map经过两个并行的MaxPool层和AvgPool层,将特征图从C*H*W变为C*1*1的大小,然后经过Share MLP模块,在该模块中,它先将通道数压缩为原来的1/r(Reduction,减少率)倍,再扩张到原通道数,经过ReLU激活函数得到两个激活后的结果。将这两个输出结果进行逐元素相加,再通过一个sigmoid激活函数得到Channel Attention的输出结果,再将这个输出结果乘原图,变回C*H*W的大小。
通道注意力公式:
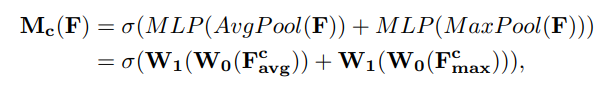
CAM与SEnet的不同之处是加了一个并行的最大池化层,提取到的高层特征更全面,更丰富。论文中也对为什么如此改动做出了解释。
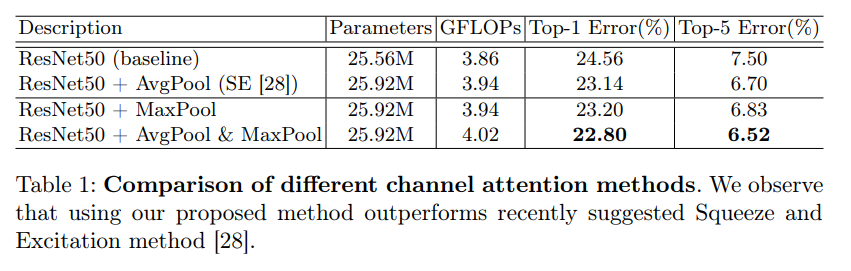
AvgPool & MaxPool对比实验
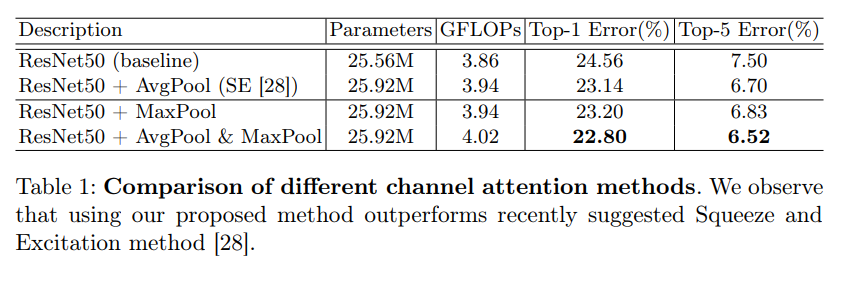
在channel attention中,表1对于pooling的使用进行了实验对比,发现avg & max的并行池化的效果要更好。这里也有可能是池化丢失的信息太多,avg&max的并行连接方式比单一的池化丢失的信息更少,所以效果会更好一点。
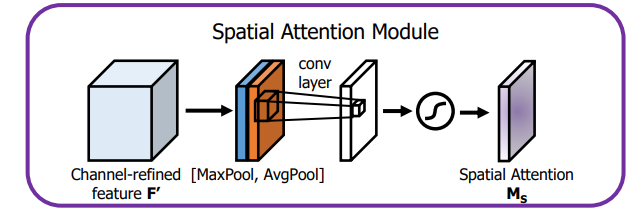
空间注意力模块:空间维度不变,压缩通道维度。该模块关注的是目标的位置信息。
图解:将Channel Attention的输出结果通过最大池化和平均池化得到两个1*H*W的特征图,然后经过Concat操作对两个特征图进行拼接,通过7*7卷积变为1通道的特征图(实验证明7*7效果比3*3好),再经过一个sigmoid得到Spatial Attention的特征图,最后将输出结果乘原图变回C*H*W大小。
空间注意力公式:
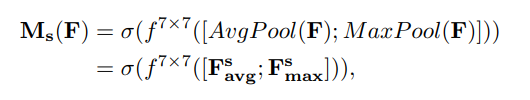
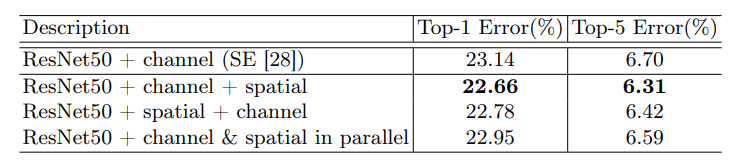
通道注意力和空间注意力这两个模块能够以并行或者串行顺序的方式组合在一块儿,关于通道和空间上的串行顺序和并行作者进行了实验对比,发现先通道再空间的结果会稍微好一点。具体实验结果如下:
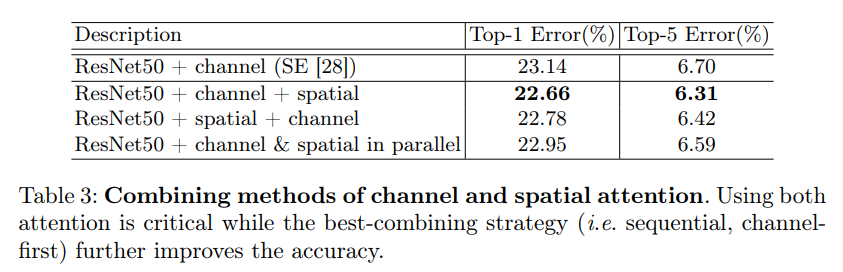
由表三可以看出,基于ResNet网络,两个Attention模块按Channel Attention + Spatial Attention的顺序效果会更好一些。
(1)Channel attention
首先是不同的通道注意力结果比较,平均池化、最大池化和两种联合使用并使用共享MLP来进行推断保存参数,结果如下:
首先,参数量和内存损耗差距不大,而错误率的提高,显然两者联合的方法更优。
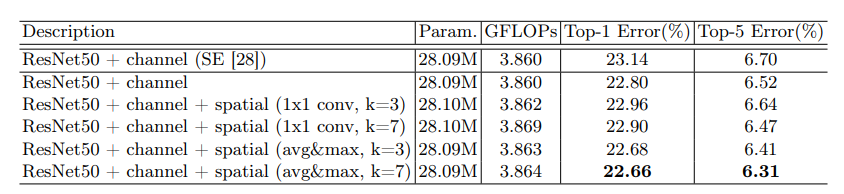
对比7*7卷积核和3*3卷积核的效果,结果7*7卷积核效果更好
对比SEnet、CAM和SAM并行、SAM+CAM和CAM+SAM的效果,最终CAM+SAM效果最好 。
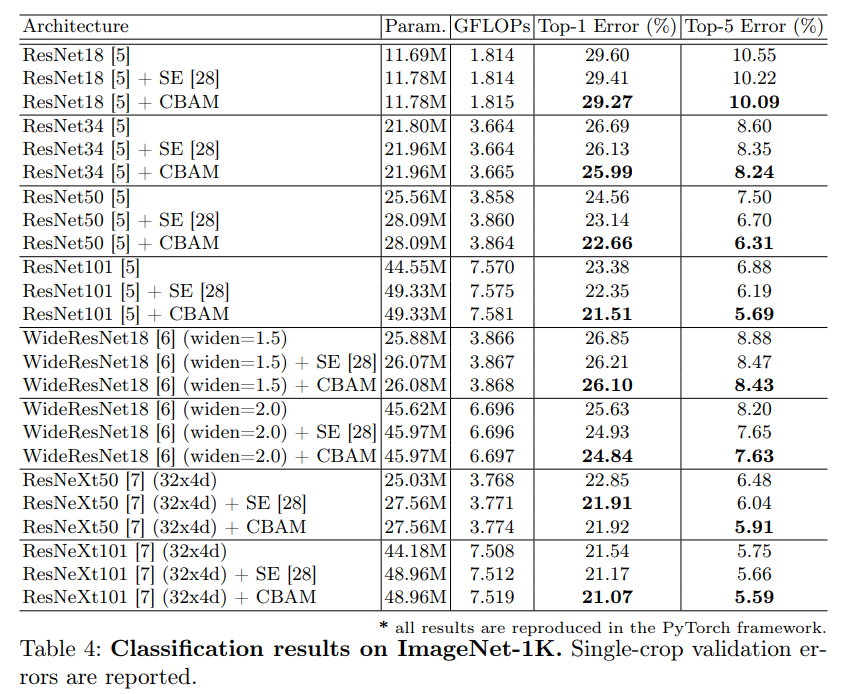
再数据集ImageNet-1K上使用ResNet网络进行对比实验
数据集:MS COCO和VOC 2007
如下表所示:
MS COCO上,CBAM在识别任务上泛化性能较基线网络有了显著提高。。
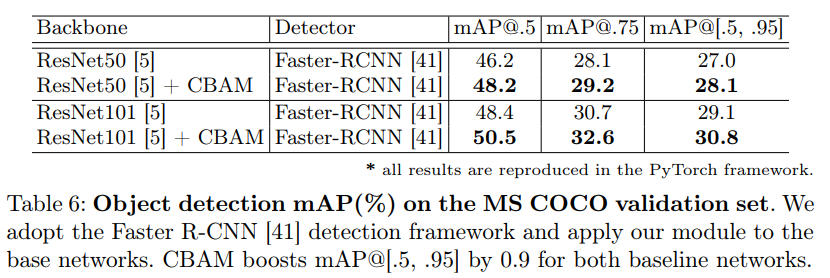
如下表:
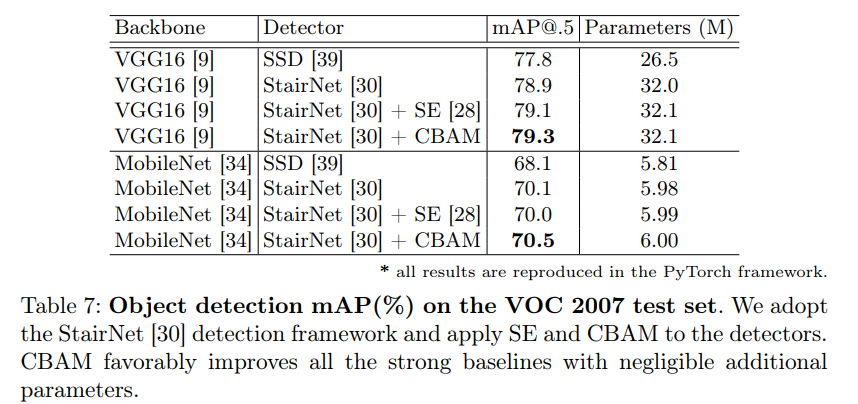
VOC 2007中,采用阶梯检测框架,并将SE和CBAM应用于检测器。CBAM极大的改善了所有强大的基线与微不足道的额外参数。

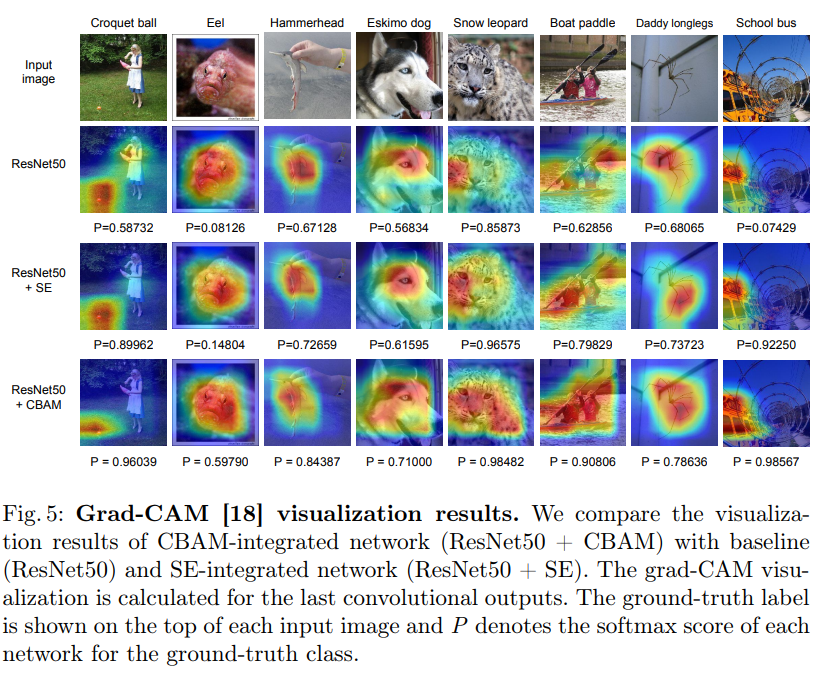
本文利用Grad CAM对不一样的网络进行可视化后,能够发现,引入 CBAM 后,特征覆盖到了待识别物体的更多部位,而且最终判别物体的几率也更高,这表示注意力机制的确让网络学会了关注重点信息。
代码实现:
import torch
import torch.nn as nn
class CBAMLayer(nn.Module):
def __init__(self, channel, reduction=16, spatial_kernel=7):
super(CBAMLayer, self).__init__()
# channel attention 压缩H,W为1
self.max_pool = nn.AdaptiveMaxPool2d(1)
self.avg_pool = nn.AdaptiveAvgPool2d(1)
# shared MLP
self.mlp = nn.Sequential(
# Conv2d比Linear方便操作
# nn.Linear(channel, channel // reduction, bias=False)
nn.Conv2d(channel, channel // reduction, 1, bias=False),
# inplace=True直接替换,节省内存
nn.ReLU(inplace=True),
# nn.Linear(channel // reduction, channel,bias=False)
nn.Conv2d(channel // reduction, channel, 1, bias=False)
)
# spatial attention
self.conv = nn.Conv2d(2, 1, kernel_size=spatial_kernel,
padding=spatial_kernel // 2, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
max_out = self.mlp(self.max_pool(x))
avg_out = self.mlp(self.avg_pool(x))
channel_out = self.sigmoid(max_out + avg_out)
x = channel_out * x
max_out, _ = torch.max(x, dim=1, keepdim=True)
avg_out = torch.mean(x, dim=1, keepdim=True)
spatial_out = self.sigmoid(self.conv(torch.cat([max_out, avg_out], dim=1)))
x = spatial_out * x
return x
x = torch.randn(1,1024,32,32)
net = CBAMLayer(1024)
y = net.forward(x)
print(y.shape)
假设我做了一个模块如下:m=Module.newdoclassCendend三个问题:除了对m的引用之外,还有什么方法可以访问C和m中的其他内容?我可以在创建匿名模块后为其命名吗(就像我输入“module...”一样)?如何在使用完匿名模块后将其删除,使其定义的常量不再存在? 最佳答案 三个答案:是的,使用ObjectSpace.此代码使c引用你的类(class)C不引用m:c=nilObjectSpace.each_object{|obj|c=objif(Class===objandobj.name=~/::C$/)}当然这取决于
作为我的Rails应用程序的一部分,我编写了一个小导入程序,它从我们的LDAP系统中吸取数据并将其塞入一个用户表中。不幸的是,与LDAP相关的代码在遍历我们的32K用户时泄漏了大量内存,我一直无法弄清楚如何解决这个问题。这个问题似乎在某种程度上与LDAP库有关,因为当我删除对LDAP内容的调用时,内存使用情况会很好地稳定下来。此外,不断增加的对象是Net::BER::BerIdentifiedString和Net::BER::BerIdentifiedArray,它们都是LDAP库的一部分。当我运行导入时,内存使用量最终达到超过1GB的峰值。如果问题存在,我需要找到一些方法来更正我的代
如何在buildr项目中使用Ruby?我在很多不同的项目中使用过Ruby、JRuby、Java和Clojure。我目前正在使用我的标准Ruby开发一个模拟应用程序,我想尝试使用Clojure后端(我确实喜欢功能代码)以及JRubygui和测试套件。我还可以看到在未来的不同项目中使用Scala作为后端。我想我要为我的项目尝试一下buildr(http://buildr.apache.org/),但我注意到buildr似乎没有设置为在项目中使用JRuby代码本身!这看起来有点傻,因为该工具旨在统一通用的JVM语言并且是在ruby中构建的。除了将输出的jar包含在一个独特的、仅限ruby
在rails源中:https://github.com/rails/rails/blob/master/activesupport/lib/active_support/lazy_load_hooks.rb可以看到以下内容@load_hooks=Hash.new{|h,k|h[k]=[]}在IRB中,它只是初始化一个空哈希。和做有什么区别@load_hooks=Hash.new 最佳答案 查看rubydocumentationforHashnew→new_hashclicktotogglesourcenew(obj)→new_has
我有一个包含模块的模型。我想在模块中覆盖模型的访问器方法。例如:classBlah这显然行不通。有什么想法可以实现吗? 最佳答案 您的代码看起来是正确的。我们正在毫无困难地使用这个确切的模式。如果我没记错的话,Rails使用#method_missing作为属性setter,因此您的模块将优先,阻止ActiveRecord的setter。如果您正在使用ActiveSupport::Concern(参见thisblogpost),那么您的实例方法需要进入一个特殊的模块:classBlah
我刚刚被困在这个问题上一段时间了。以这个基地为例:moduleTopclassTestendmoduleFooendend稍后,我可以通过这样做在Foo中定义扩展Test的类:moduleTopmoduleFooclassSomeTest但是,如果我尝试通过使用::指定模块来最小化缩进:moduleTop::FooclassFailure这失败了:NameError:uninitializedconstantTop::Foo::Test这是一个错误,还是仅仅是Ruby解析变量名的方式的逻辑结果? 最佳答案 Isthisabug,or
我的主要目标是能够完全理解我正在使用的库/gem。我尝试在Github上从头到尾阅读源代码,但这真的很难。我认为更有趣、更温和的踏脚石就是在使用时阅读每个库/gem方法的源代码。例如,我想知道RubyonRails中的redirect_to方法是如何工作的:如何查找redirect_to方法的源代码?我知道在pry中我可以执行类似show-methodmethod的操作,但我如何才能对Rails框架中的方法执行此操作?您对我如何更好地理解Gem及其API有什么建议吗?仅仅阅读源代码似乎真的很难,尤其是对于框架。谢谢! 最佳答案 Ru
我想获取模块中定义的所有常量的值:moduleLettersA='apple'.freezeB='boy'.freezeendconstants给了我常量的名字:Letters.constants(false)#=>[:A,:B]如何获取它们的值的数组,即["apple","boy"]? 最佳答案 为了做到这一点,请使用mapLetters.constants(false).map&Letters.method(:const_get)这将返回["a","b"]第二种方式:Letters.constants(false).map{|c
我的假设是moduleAmoduleBendend和moduleA::Bend是一样的。我能够从thisblog找到解决方案,thisSOthread和andthisSOthread.为什么以及什么时候应该更喜欢紧凑语法A::B而不是另一个,因为它显然有一个缺点?我有一种直觉,它可能与性能有关,因为在更多命名空间中查找常量需要更多计算。但是我无法通过对普通类进行基准测试来验证这一点。 最佳答案 这两种写作方法经常被混淆。首先要说的是,据我所知,没有可衡量的性能差异。(在下面的书面示例中不断查找)最明显的区别,可能也是最著名的,是你的
几个月前,我读了一篇关于rubygem的博客文章,它可以通过阅读代码本身来确定编程语言。对于我的生活,我不记得博客或gem的名称。谷歌搜索“ruby编程语言猜测”及其变体也无济于事。有人碰巧知道相关gem的名称吗? 最佳答案 是这个吗:http://github.com/chrislo/sourceclassifier/tree/master 关于ruby-寻找通过阅读代码确定编程语言的rubygem?,我们在StackOverflow上找到一个类似的问题: