Volatile关键字的作用主要有如下两个:
1.线程的可见性:当一个线程修改一个共享变量时,另外一个线程能读到这个修改的值。
2. 顺序一致性:禁止指令重排序。
我们先通过一个例子来看看线程的可见性:
public class VolatileTest {
boolean flag = true;
public void updateFlag() {
this.flag = false;
System.out.println("修改flag值为:" + this.flag);
}
public static void main(String[] args) {
VolatileTest test = new VolatileTest();
new Thread(() -> {
while (test.flag) {
}
System.out.println(Thread.currentThread().getName() + "结束");
}, "Thread1").start();
new Thread(() -> {
try {
Thread.sleep(2000);
test.updateFlag();
} catch (InterruptedException e) {
}
}, "Thread2").start();
}
}
打印结果如下,我们可以看到虽然线程Thread2已经把flag 修改为false了,但是线程Thread1没有读取到flag修改后的值,线程一直在运行
修改flag值为:false
我们把flag 变量加上volatile:
volatile boolean flag = true;
重新运行程序,打印结果如下。Thread1结束,说明Thread1读取到了flage修改后的值
修改flag值为:false
Thread1结束
说到可见性,我们需要先了解一下Java内存模型,Java内存模型如下所示:
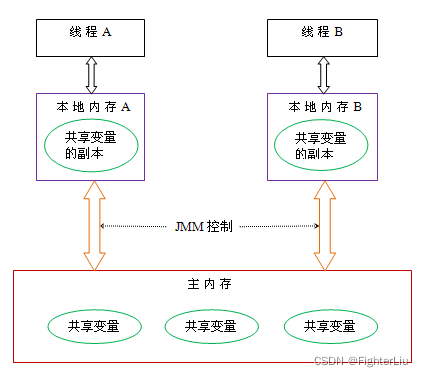
线程之间的共享变量存储在主内存中(Main Memory)中,每个线程都一个都有一个私有的本地内存(Local Memory),本地内存中存储了该线程以读/写共享变量的副本。
所以当一个线程把主内存中的共享变量读取到自己的本地内存中,然后做了更新。在还没有把共享变量刷新的主内存的时候,另外一个线程是看不到的。
如何把修改后的值刷新到主内存中的?
现代的处理器使用写缓冲区临时保存向内存写入的数据。写缓冲区可以保证指令流水线持续运行,它可以避免由于处理器停顿下来等向内存写入数据而产生的延迟。同时,通过以批处理的方式刷新写缓冲区,以及合并写缓冲区中对同一内存地址的多次写,较少对内存总线的占用。但是什么时候写入到内存是不知道的。
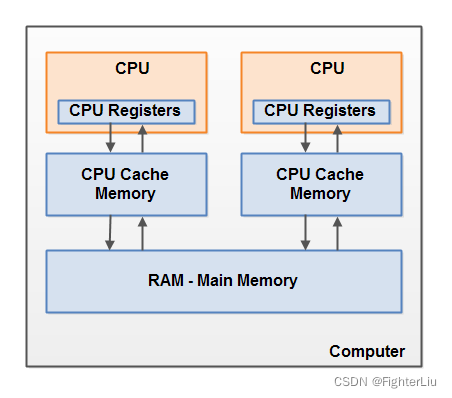
所以就引入了volatile,volatile是如何保证可见性的呢?
在X86处理器下通过工具获取JIT编译器生成的汇编指令来查看对volatile进行写操作时,会多出lock addl。Lock前缀的指令在多核处理器下会引发两件事情:
在执行程序时,为了提高性能,编译器和处理器常常会对指令做重排序。重排序分为如下三种:

1属于编译器重排序,2和3属于处理器重排序。这些重排序可能会导致多线程程序出现内存可见性问题。
当变量声明为volatile时,Java编译器在生成指令序列时,会插入内存屏障指令。通过内存屏障指令来禁止重排序。
JMM内存屏障插入策略如下:
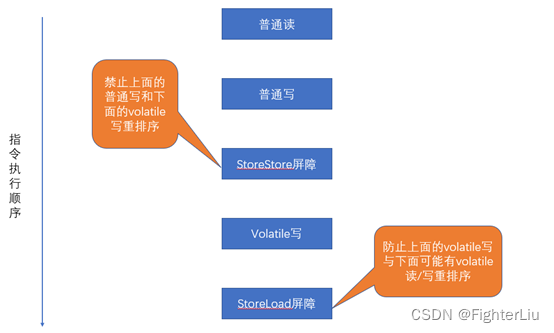
在每个volatile写操作的前面插入一个StoreStore屏障,后面插入一个StoreLoad屏障。
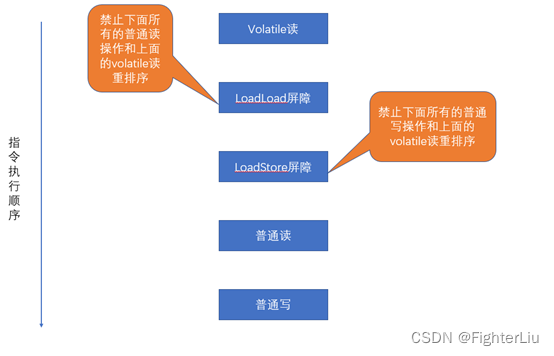
在每个volatile读操作后面插入一个LoadLoad,LoadStore屏障。
Volatile写插入内存屏障后生成指令序列示意图:
Volatile读插入内存屏障后生成指令序列示意图:
通过上面这些我们可以得出如下结论:编译器不会对volatile读与volatile读后面的任意内存操作重排序;编译器不会对volatile写与volatile写前面的任意内存操作重排序。
防止重排序使用案例:
public class SafeDoubleCheckedLocking {
private volatile static Instance instane;
public static Instance getInstane(){
if(instane==null){
synchronized (SafeDoubleCheckedLocking.class){
if(instane==null){
instane=new Instance();
}
}
}
return instane;
}
}
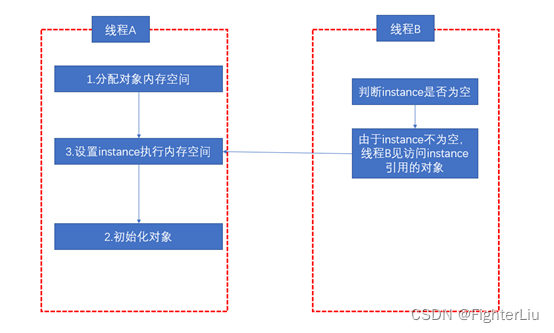
创建一个对象主要分为如下三步:
如果instane 不加volatile,上面的2,3可能会发生重排序。假设A,B两个线程同时获取,A线程获取到了锁,发生了指令重排序,先设置了instance指向内存空间。这个时候B线程也来获取,instance不为空,这样B拿到了没有初始化完成的单例对象(如下图)
参考:《Java并发编程的艺术》
如果您尝试在Ruby中的nil对象上调用方法,则会出现NoMethodError异常并显示消息:"undefinedmethod‘...’fornil:NilClass"然而,有一个tryRails中的方法,如果它被发送到一个nil对象,它只返回nil:require'rubygems'require'active_support/all'nil.try(:nonexisting_method)#noNoMethodErrorexceptionanymore那么try如何在内部工作以防止该异常? 最佳答案 像Ruby中的所有其他对象
我正在尝试学习Ruby词法分析器和解析器(whitequarkparser)以了解更多有关从Ruby脚本进一步生成机器代码的过程。在解析以下Ruby代码字符串时。defadd(a,b)returna+bendputsadd1,2它导致以下S表达式符号。s(:begin,s(:def,:add,s(:args,s(:arg,:a),s(:arg,:b)),s(:return,s(:send,s(:lvar,:a),:+,s(:lvar,:b)))),s(:send,nil,:puts,s(:send,nil,:add,s(:int,1),s(:int,3))))任何人都可以向我解释生成的
我目前正在尝试学习RubyonRails和测试框架RSpec。assigns在此RSpec测试中做什么?describe"GETindex"doit"assignsallmymodelas@mymodel"domymodel=Factory(:mymodel)get:indexassigns(:mymodels).shouldeq([mymodel])endend 最佳答案 assigns只是检查您在Controller中设置的实例变量的值。这里检查@mymodels。 关于ruby-o
下面的代码工作正常:person={:a=>:A,:b=>:B,:c=>:C}berson={:a=>:A1,:b=>:B1,:c=>:C1}kerson=person.merge(berson)do|key,oldv,newv|ifkey==:aoldvelsifkey==:bnewvelsekeyendendputskerson.inspect但是如果我在“ifblock”中添加return,我会得到一个错误:person={:a=>:A,:b=>:B,:c=>:C}berson={:a=>:A1,:b=>:B1,:c=>:C1}kerson=person.merge(berson
这段代码似乎创建了一个范围从a到z的数组,但我不明白*的作用。有人可以解释一下吗?[*"a".."z"] 最佳答案 它叫做splatoperator.SplattinganLvalueAmaximumofonelvaluemaybesplattedinwhichcaseitisassignedanArrayconsistingoftheremainingrvaluesthatlackcorrespondinglvalues.Iftherightmostlvalueissplattedthenitconsumesallrvaluesw
你能解释一下吗?我想评估来自两个不同来源的值和计算。一个消息来源为我提供了以下信息(以编程方式):'a=2'第二个来源给了我这个表达式来评估:'a+3'这个有效:a=2eval'a+3'这也有效:eval'a=2;a+3'但我真正需要的是这个,但它不起作用:eval'a=2'eval'a+3'我想了解其中的区别,以及如何使最后一个选项起作用。感谢您的帮助。 最佳答案 您可以创建一个Binding,并将相同的绑定(bind)与每个eval相关联调用:1.9.3p194:008>b=binding=>#1.9.3p194:009>eva
我无法运行Spring。这是错误日志。myid-no-MacBook-Pro:myid$spring/Users/myid/.rbenv/versions/1.9.3-p484/lib/ruby/gems/1.9.1/gems/spring-0.0.10/lib/spring/sid.rb:17:in`fiddle_func':uninitializedconstantSpring::SID::DL(NameError)from/Users/myid/.rbenv/versions/1.9.3-p484/lib/ruby/gems/1.9.1/gems/spring-0.0.10/li
我定义了一个方法:defmethod(one:1,two:2)[one,two]end当我这样调用它时:methodone:'one',three:'three'我得到:ArgumentError:unknownkeyword:three我不想从散列中一个一个地提取所需的键或排除额外的键。除了像这样定义方法之外,有没有办法规避这种行为:defmethod(one:1,two:2,**other)[one,two,other]end 最佳答案 如果不想写**other中的other,可以省略。defmethod(one:1,two:2
我在RoR应用程序中有一个提交表单,是使用simple_form构建的。当字段为空白时,应用程序仍会继续下一步,而不会提示错误或警告。默认情况下,这些字段应该是required:true;但即使手动编写也行不通。该应用有3个步骤:NewPost(新View)->Preview(创建View)->Post。我的Controller和View的摘录会更清楚:defnew@post=Post.newenddefcreate@post=Post.new(params.require(:post).permit(:title,:category_id))ifparams[:previewButt
我一直在Heroku上尝试不同的缓存策略,并添加了他们的memcached附加组件,目的是为我的应用程序添加Action缓存。但是,当我在我当前的应用程序上查看Rails.cache.stats时(安装了memcached并使用dalligem),在执行应该缓存的操作后,我得到current和total_items为0。在Controller的顶部,我想缓存我有的Action:caches_action:show此外,我修改了我的环境配置(对于在Heroku上运行的配置)config.cache_store=:dalli_store我是否可以查看其他一些统计数据,看看它是否有效或我做错