论文信息:Detecting Deepfakes with Self-Blended Images
论文/Paper: http://arxiv.org/pdf/2204.08376
代码/Code: https://github.com/mapooon/SelfBlendedImages
作者团队:

会议:CVPR2022-Oral
动机
早期训练集的构造点是基于两种方案:对图片进行模糊处理以模拟生成图片的清晰度下降,以及合成两个图片来制造伪影,以便于学习。然而随着深度伪造技术的进步,清晰度逐渐上升,前者已经不再适用。而后者在低质量数据集上又难以检测伪影,鲁棒性较差。

创新
提出新的合成训练数据—自混合图像(SBIs)来检测深度伪造,其思想为:更通用和几乎不可能识别的假样本鼓励分类器学习通用且健壮的表示,不会过度适应特定于操作的伪影,泛化性更强。
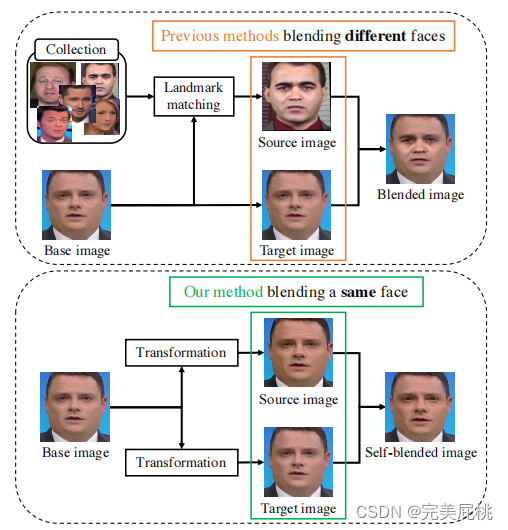
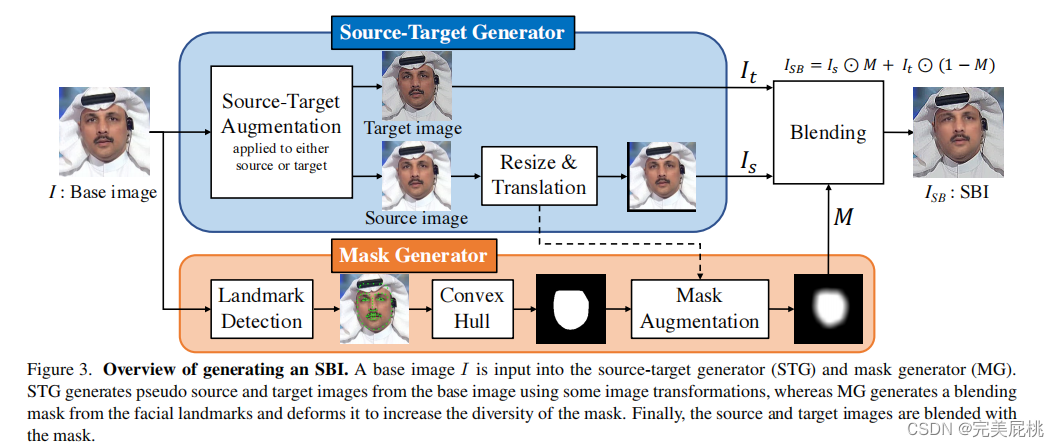
本文的主要工作Self-Blended Images (SBIs)分为两部分:STG和MG。
Source-Target Generator (STG) 通过一张图片,用简单的图像处理得到target image和source image。具体地说,对两张图片分别进行随机的图像处理,如RGB,亮度,HSV等值的偏移,作为颜色变换。以及下采样或锐化,作为频率变换。最后,为了模拟边界混合和landmark不匹配,对source image进行resize。
Mask Generator (MG) 通过target image和source image的landmarks,整合得到masks,以便混合。具体地说,MG检测input image的面部区域,通过凸包计算一个初始mask,之后随机改变mask的形状和blend比例以增加多样性。最后经过两次不同的高斯滤波进行平滑处理。
Blending
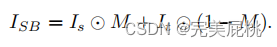
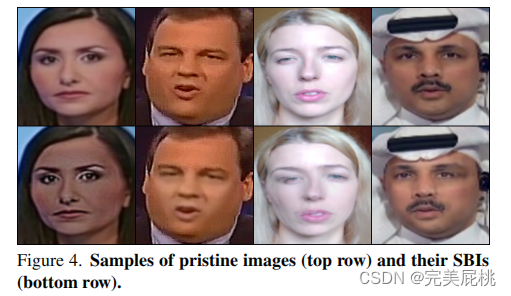
骨干网络:EfficientNet-b4(ImageNet SOTA)
目标函数:交叉熵损失
实验结果
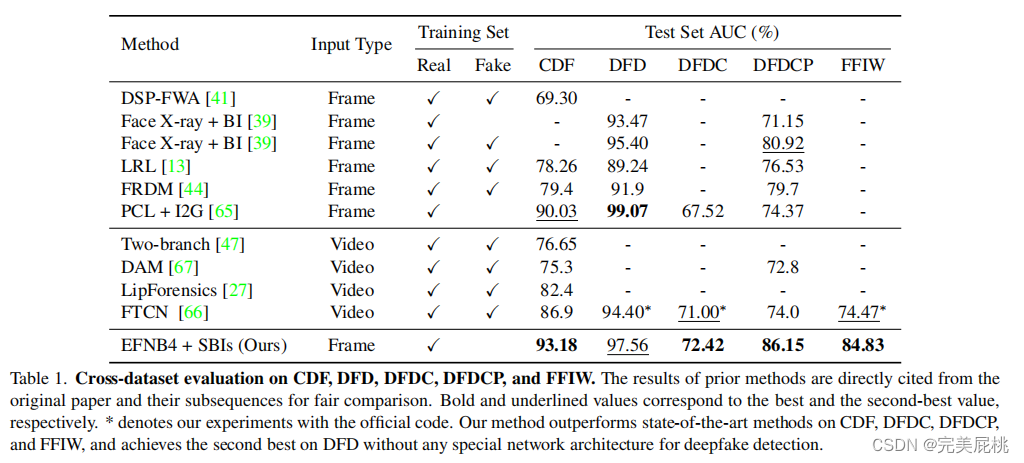
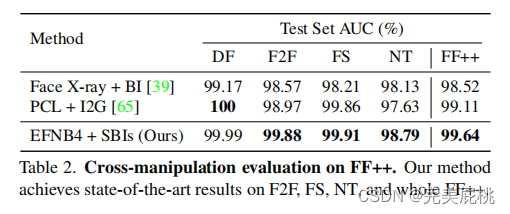
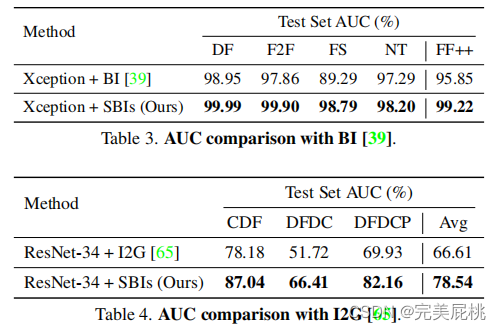
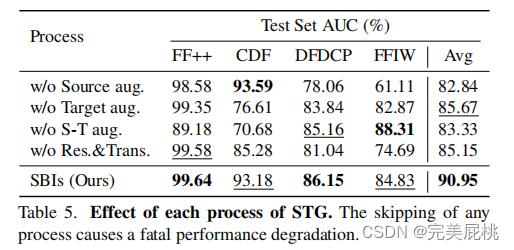
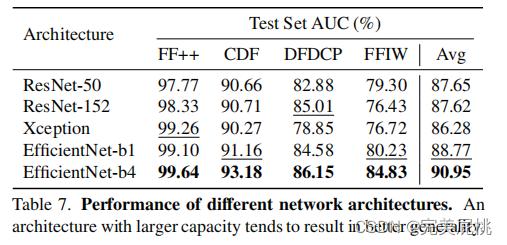

优势
常规的blend方法往往会导致overfit,例如,一些混合伪影的交换并不规则,模型会因此表现得更趋向于检测到混合图像而非深度伪造图像。本文的核心目标是检测伪影,不管合成的是否是同一身份人脸,只需关注合成产生的伪影,同一身份人脸不同增强之后再合成可以更大程度地保留伪影的影响(显然,使用原图像得到的交换对往往是规则的)
限制
难以捕捉视频帧间时间不一致性。
对全图合成效果不佳(因为训练只关注人脸部分)。