有道无术,术尚可求,有术无道,止于术。
文章目录
Elastic是一家以搜索引擎闻名世界的软件公司。于2012年成立,总部位于美国的山景城。
2018年10月上市,目前市值近50多亿美金。❗️❗️❗️
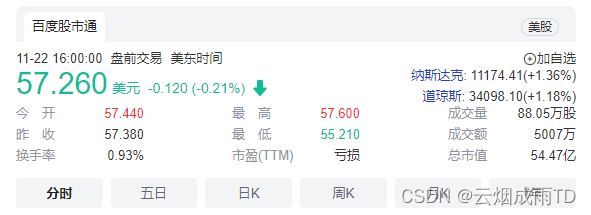
Elastic 公司致力于结构化和非结构化数据的分布式实时全文搜索及分析,典型应用场景包括日志管理、分析、系统指标分析、安全分析、企业搜索、网站搜索、应用搜索、应用性能管理APM等。
Elastic 公司产品包括享誉业界的 Elastic Stack、具备多种高级特性的商业扩展插件、云服务Elastic Cloud等。
国内代表用户:华为,联想,华大基因,腾讯,网易,阿里巴巴,百度,携程,滴滴,京东,顺丰🐆🐆🐆
Elastic Stack是一些系列能够安全可靠地获取任何来源、任何格式的数据,然后实时地对数据进行搜索、分析和可视化的软件。核心产品包括 Elasticsearch、Kibana、Beats 和 Logstash等等。
Elasticsearch 是一个分布式、RESTful 风格的搜索和数据分析引擎。作为Elastic Stack的核心,Elasticsearch 集中存储数据,并完成数据搜索、分析。
1、结构化数据
就像结构化一词所暗示的那样,这是高度组织化且格式整齐的数据,结构化数据被组织以表格格式(即,行和列)和有不同的行和列之间的关系,因此它是高度组织和格式化的,易于存储,处理和访问。
主要通过关系型数据库进行存储和管理。
2、非结构化数据
非结构化数据是未以任何预定义方式进行组织的数据,非结构化数据中的不规则性和混乱使得难以处理和理解。不适于由数据库二维表来表现,常见的包括所有格式的办公文档、Word 文档,邮件,各类报表、图片和咅频、视频信息等。
3、半结构化数据
可以更加细分具有自己特定的标签格式,可以根据需要按结构化数据来处理,也可抽取出纯文本按非结构化数据来处理的数据为半结构化数据。例如XML、JSON、HTML、NoSQL DB等。
对于结构化数据的搜索,如对数据库数据的搜索,可以使用 SQL 语句,也可以建⽴索引,通过索引快速搜索数据。
非结构化数据搜索方法主要有顺序扫描、全文搜索。
1、 顺序扫描
顺序扫描顾名思义,就是按照顺序依次扫描,例如要找出内容包含某个字符串的文件,需要依次对所有文件扫描,对于每一个文件,从头到尾扫描,如果当前文件包含该字符,此文件放入结果集,接着扫描下一个文件,直到扫描所有的文件,返回结果集。
顺序扫描查询准确率高,查询速度会随着查询数据量的增大而急速变慢。
2、 全文搜索
将非结构化数据中的一部分信息提取出来,重新组织,建立索引,使其变得有一定结构,然后对此有一定结构的数据进行搜索,从而达到搜索相对较快的目的。这种先建立索引,再对索引进行搜索的过程就叫全文检索(Full-text Search)。
例如字典的拼音表和部首检字表就相当于字典的索引,对每一个字的解释是非结构化的,如果字典没有音节表和部首检字表,在茫茫辞海中找一个字只能顺序扫描。
然而字的某些信息可以提取出来进行结构化处理,比如读音,就比较结构化,分声母和的母,分别只有几种可以一一列举,于是将读音拿出来按一定的顺序排列,每一项读音都指向此字的详细解释的页数。我们搜索时按结构化的拼音搜到读音,然后按其指向的页数,便可找到我们的非结构化数据也即对字的解释。
虽然创建索引的过程也是非常耗时的,但是索引一旦创建就可以多次使用,全文检索主要处理的是查询,所以耗时间创建索引是值得的。
互联网全文搜索引擎就是通过从互联网上提取的各个网站的信息(以网页文字为主)而建立的数据库中,检索与用户查询条件匹配的相关记录,然后按一定的排列顺序将结果返回给用户。国外代表有 Google,国内则有百度。
Shay Banon是ElasticSearch的创始人,他曾说过:搜索是每一个软件都必须拥有的功能
2004年Shay Banon基于Lucene开发了Compass(ES的前身)。
2010年Shay Banon重写了Compass,取名ElasticSearch。
2010年2 月,Elasticsearch第一个公开版本正式发行,成为Github上最受欢迎的开源项目之一。
1、分布式
无论Elasticsearch是在一个节点上运行,还是在一个包含 300 个节点的集群上运行,都能够以相同的方式与Elasticsearch进行通信。
它能够水平扩展,每秒钟可处理海量事件,同时能够自动管理索引和查询在集群中的分布方式,以实现极其流畅的操作。
2、高可用
Elasticsearch 自动检测硬件、网络故障,并确保集群(和数据)的安全性和可用性。
Elasticsearch 运行在一个分布式的环境中,通过跨集群复制功能,辅助集群可以作为热备份随时投入使用。
3、廉价存储
数据是不断变化的,这使得存储和搜索全部数据变得非常昂贵。Elasticsearch 能让您在性能和成本之间取得平衡。可以将数据存储在本地以实现快速查询,也可以将无限量的数据远程存储于低成本的服务器上。
4、智能搜索
基于各项元素(从词频或新近度到热门度等)对搜索结果进行排序。将这些内容与功能进行混搭,以优化向用户显示结果的方式。
而且,由于我们的大部分用户都是真实的人,Elasticsearch 具备齐全功能,可以处理包括各种复杂情况(例如拼写错误)在内的人为错误。
5、搜索方式多样性
通过 Elasticsearch,能够执行及合并多种类型的搜索(结构化数据、非结构化数据、地理位置、指标),搜索方式随心而变。
6、海量数据
找到与查询最匹配的 10 个文档并不困难。但如果面对的是十亿行日志,又该如何解读呢?Elasticsearch 聚合让您能够从大处着眼,探索数据的趋势和规律。
7、速度快
通过有限状态转换器实现了用于全文检索的倒排索引,实现了用于存储数值数据和地理位置数据的BKD树,以及用于分析的列存储。
而且由于每个数据都被编入了索引,因此不用因为某些数据没有索引而烦心。可以用快到令人惊叹的速度使用和访问所有数据。
适用于所有数据类型。数字、文本、地理位置、结构化数据、非结构化数据。全文本搜索只是全球众多公司利用 Elasticsearch 解决各种挑战的冰山一角。

GitHub: 2013 年初,抛弃了 Solr,采取 Elasticsearch 来做 PB 级的搜索。 GitHub 使用Elasticsearch 搜索 20TB 的数据,包括 13 亿文件和 1300 亿行代码。
维基百科:以Elasticsearch为基础的核心搜索架构。
百度:目前广泛使用 Elasticsearch 作为文本数据分析,采集百度所有服务器上的各类指标数据及用户自定义数据,通过对各种数据进行多维分析展示,辅助定位分析实例异常或业务层面异常。目前覆盖百度内部 20 多个业务线(包括云分析、网盟、预测、文库、直达号、钱包、 风控等),单集群最大 100 台机器,200个 ES 节点,每天导入 30TB+数据。
新浪:使用Elasticsearch分析处理 32 亿条实时日志。
阿里:使用 Elasticsearch 构建日志采集和分析体系。
Stack Overflow:解决 Bug 问题的网站,全英文,编程人员交流的网站。
Beats系列集合了多种单一用途数据采集器,可以从成百上千或成千上万台机器和系统向 Logstash 或 Elasticsearch 发送数据。

Logstash是具有实时流水线能力的开源的数据收集引擎。可以动态统一不同来源的数据,并将数据标准化到您选择的目标输出。它提供了大量插件,可帮助我们解析,丰富,转换和缓冲任何类型的数据。
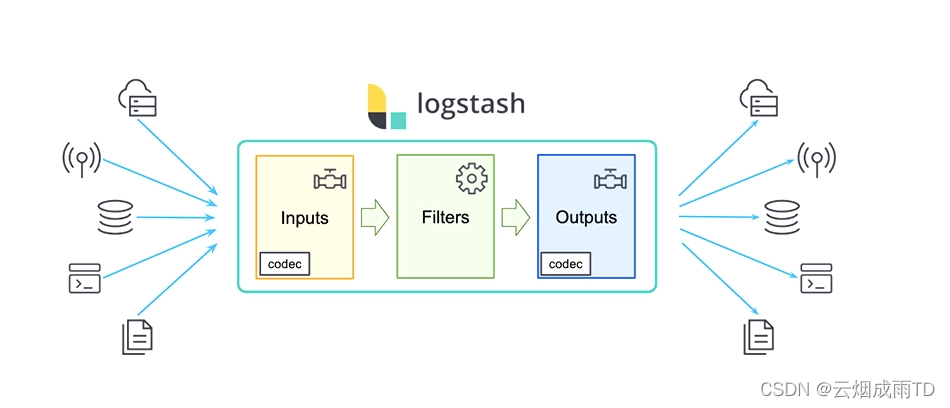
Kibana 是一个免费且开放的用户可视化界面,能够让您对Elasticsearch数据进行可视化。
关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭4年前。Improvethisquestion我想在固定时间创建一系列低音和高音调的哔哔声。例如:在150毫秒时发出高音调的蜂鸣声在151毫秒时发出低音调的蜂鸣声200毫秒时发出低音调的蜂鸣声250毫秒的高音调蜂鸣声有没有办法在Ruby或Python中做到这一点?我真的不在乎输出编码是什么(.wav、.mp3、.ogg等等),但我确实想创建一个输出文件。
这里是Ruby新手。完成一些练习后碰壁了。练习:计算一系列成绩的字母等级创建一个方法get_grade来接受测试分数数组。数组中的每个分数应介于0和100之间,其中100是最大分数。计算平均分并将字母等级作为字符串返回,即“A”、“B”、“C”、“D”、“E”或“F”。我一直返回错误:avg.rb:1:syntaxerror,unexpectedtLBRACK,expecting')'defget_grade([100,90,80])^avg.rb:1:syntaxerror,unexpected')',expecting$end这是我目前所拥有的。我想坚持使用下面的方法或.join,
在应用开发中,有时候我们需要获取系统的设备信息,用于数据上报和行为分析。那在鸿蒙系统中,我们应该怎么去获取设备的系统信息呢,比如说获取手机的系统版本号、手机的制造商、手机型号等数据。1、获取方式这里分为两种情况,一种是设备信息的获取,一种是系统信息的获取。1.1、获取设备信息获取设备信息,鸿蒙的SDK包为我们提供了DeviceInfo类,通过该类的一些静态方法,可以获取设备信息,DeviceInfo类的包路径为:ohos.system.DeviceInfo.具体的方法如下:ModifierandTypeMethodDescriptionstatic StringgetAbiList()Obt
基础版云数据库RDS的产品系列包括基础版、高可用版、集群版、三节点企业版,本文介绍基础版实例的相关信息。RDS基础版实例也称为单机版实例,只有单个数据库节点,计算与存储分离,性价比超高。说明RDS基础版实例只有一个数据库节点,没有备节点作为热备份,因此当该节点意外宕机或者执行重启实例、变更配置、版本升级等任务时,会出现较长时间的不可用。如果业务对数据库的可用性要求较高,不建议使用基础版实例,可选择其他系列(如高可用版),部分基础版实例也支持升级为高可用版。基础版与高可用版的对比拓扑图如下所示。优势 性能由于不提供备节点,主节点不会因为实时的数据库复制而产生额外的性能开销,因此基础版的性能相对于
不知何故,我似乎无法获得包含我的聚合的响应...使用curl它按预期工作:HBZUMB01$curl-XPOST"http://localhost:9200/contents/_search"-d'{"size":0,"aggs":{"sport_count":{"value_count":{"field":"dwid"}}}}'我收到回复:{"took":4,"timed_out":false,"_shards":{"total":5,"successful":5,"failed":0},"hits":{"total":90,"max_score":0.0,"hits":[]},"a
我使用irb。下面是我写的代码。“斧头”..“bc”我期待"ax""ay""az""ba"bb""bc"但结果只是“斧头”..“bc”我该如何纠正?谢谢。 最佳答案 >puts("ax".."bc").to_aaxayazbabbbc 关于ruby-从结束值创建一系列字符串,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/7617092/
1.回顾.TransportServicepublicclassTransportServiceextendsAbstractLifecycleComponentTransportService:方法:1publicfinalTextendsTransportResponse>voidsendRequest(finalTransport.Connectionconnection,finalStringaction,finalTransportRequestrequest,finalTransportRequestOptionsoptions,TransportResponseHandlerT>
使用RubyonRails,我使用给定的增量(例如每30分钟)用时间填充“选择”。目前我正在YAML文件中写出所有的可能性,但我觉得有一种更巧妙的方法。我想我想提供一个开始时间、一个结束时间、一个增量,并且目前只提供一个名为“关闭”的选项(想想“business_hours”)。所以,我的选择可能会显示:'Closed'5:00am5:30am6:00am...[allthewayto]...11:30pm谁能想出更好的方法,或者只是将它们全部“拼写”出来的最佳方法? 最佳答案 此答案基于@emh的答案。defcreate_hour
我有一个Rails应用程序,现在设置了ElasticSearch和Tiregem以在模型上进行搜索,我想知道我应该如何设置我的应用程序以对模型中的某些索引进行模糊字符串匹配。我将我的模型设置为索引标题、描述等内容,但我想对其中一些进行模糊字符串匹配,但我不确定在何处进行此操作。如果您想发表评论,我将在下面包含我的代码!谢谢!在Controller中:defsearch@resource=Resource.search(params[:q],:page=>(params[:page]||1),:per_page=>15,load:true)end在模型中:classResource'Us
美团外卖搜索工程团队在Elasticsearch的优化实践中,基于Location-BasedService(LBS)业务场景对Elasticsearch的查询性能进行优化。该优化基于Run-LengthEncoding(RLE)设计了一款高效的倒排索引结构,使检索耗时(TP99)降低了84%。本文从问题分析、技术选型、优化方案等方面进行阐述,并给出最终灰度验证的结论。1.前言最近十年,Elasticsearch已经成为了最受欢迎的开源检索引擎,其作为离线数仓、近线检索、B端检索的经典基建,已沉淀了大量的实践案例及优化总结。然而在高并发、高可用、大数据量的C端场景,目前可参考的资料并不多。因此