当你乘坐火车的时候,你不会想到一个30000mA(111Wh)的充电宝突然无法带上车了,你会不会生气呢?最新的铁路携带物品规定于7月开始实施,充电宝最多携带两个,每个额定容量不超过100Wh,也就是27000mA,所以过安检会让你要么寄快递,要么让别人来拿,要么留下,反正你是带不上火车的,要是你强行带走,可能警察也会强行把你带走。吃一点长一智,所以每次出行乘坐交通工具时,先看一看携带物品是否可以上车,充电宝、打火机、压缩性气体罐装物品如喷雾、香水、酒等等,不然非常影响你的出行,当然开车不需要考虑这些问题。说到底,还是没钱,还是要努力学习啊。
这次总结的是(三)接口自动化测试-Python自带Requests+Unittest框架,此Python库是一款非常好用的脚本工具,毕竟Python语言容易上手,所以使用Python编写脚本进行测试也是非常方便的。
参赛话题:学习笔记
| 工具 | 手写脚本 |
| 灵活性差 | 灵活性高 |
| 操作简单 | 需要一定的编程能力 |
| 用于较为单一的接口测试 | 用于业务连续的接口测试 |
(1)简单
(2)高级
(3)面向对象
(4)可扩展
(5)免费和开源
(6)边编译边执行
(7)可移植
(8)丰富的库
(1)官方文档:urllib.request --- 用于打开 URL 的可扩展库 — Python 3.10.7 文档
(2)Requests是唯一的一个非转基因的Python HTTP库,可以安全享用。
(3)特点
Keep-Alive&连接池
国际化域名和URL
带持久Cookies的会话
浏览器式的SSL认证
自动内容解码
Unicode响应体
文件分块上传、下载
流下载
连接超时
分块请求
(1)非Python自带库,需单独安装
windows→pip install requests、easy_install requests、或者pycharm中安装
linux→sudo pip install requests
(1)requests.request() #构造一个请求,支持以下各种方法
(2)requests.get() #获取html的主要方法(至少有一个参数-接口地址、有返回值的方法。返回值就是本次请求的服务器响应结果)
(3)requests.post() #向html网页提交post请求的方法
(4)requests.head() #获取html头部信息的主要方法
(5)requests.put() #向html提交put请求的方法
(6)requests.patch() #向html提交局部修改的请求
(7)requests.delete() #向html提交删除请求
(1)Response常用属性
(2)r.status_code #http请求的返回状态,若为200则表示请求成功
(3)r.text #http响应内容的字符串形式,即返回的页面内容
(4)r.recoding #从http header中猜测的相应内容编码方式
(5)r.rapparent_encoding #从内容中分析处的响应内容编码方式(备选)
(6)r.content #http响应内容的二进制形式
(1)发送不带参数的GET请求requests.get("url")
(2)获取和输出各种响应值
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# author:bigbear
# datetime:2022/8/19 8:25
# software: PyCharm
"""get请求"""
# (1)导入requests包
import requests
import json
# (2)构造一个不带参数的get请求
response = requests.get("http://www.baidu.com")
print(f"本次响应数据类型是{type(response)}")
# (3)输出本次响应的状态码
print(f"\n\n本次响应状态码数据类型是{type(response.status_code)}")
print(f"本次响应状态码是{response.status_code}")
# (4)输出本次响应的所有文本
print(f"\n\n本次响应文本数据类型是{type(response.text)}")
response.encoding = "utf-8"
print(f"本次响应文本是{response.text}")
# (5)输出本次响应的所有值
print(f"\n\n本次响应cookies数据类型是{type(response.cookies)}")
response.encoding = "utf-8"
print(f"本次响应网站的Cookies是{response.cookies}")
# (6)判断:本次请求后,服务器响应返回的字符串中,是否有“百度一下,你就知道”
exp = "百度一下,你就知道"
if exp in response.text:
print(f"\n\n响应值中包含你希望的字符串:{exp}。")
else:
print("\n\n响应值中不包含你希望的字符串。")(1)发送带参数的GET请求requests.get("url", params=params)
(2)获取和输出各种响应值
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# author:bigbear
# datetime:2022/8/19 8:25
# software: PyCharm
"""get请求"""
# (1)导入requests包
import requests
import json
# (2)构造一个不带参数的get请求、带参数的get请求、带参数的post请求
get_parameter = {
"q": "apple",
"from": "en",
"to": "zh",
"appid": "xxx",
"salt": "202002121503",
"sign": "7105f811ca9d3835146ed9c44ab46770",
}
response1 = requests.get("https://fanyi-api.baidu.com/api/trans/vip/translate", params=get_parameter)
print(f"\n本次响应数据类型是{type(response1)}")
# (3)输出本次响应的状态码
print(f"\n本次响应状态码数据类型是{type(response1.status_code)}")
print(f"本次响应状态码是{response1.status_code}")
# (4)输出本次响应的所有文本
print(f"\n本次响应文本数据类型是{type(response1.text)}")
response1.encoding = "utf-8"
print(f"本次响应文本是{response1.text}")
# (5)输出本次响应的所有值
print(f"\n本次响应cookies数据类型是{type(response1.cookies)}")
response1.encoding = "utf-8"
print(f"本次响应网站的Cookies是{response1.cookies}")
# (6)判断:本次请求后,服务器响应返回的字符串中,是否有“百度一下,你就知道”
exp = "apple"
if exp in response1.text:
print(f"\n响应值中包含你希望的字符串:{exp}。")
else:
print("\n响应值中不包含你希望的字符串。")#!/usr/bin/env python
# -*- coding:utf-8 -*-
# author:bigbear
# datetime:2022/8/19 10:33
# software: PyCharm
"""
使用Python加requests库方式实现:输入一个字符串,通过百度翻译接口,输出其中文翻译内容
技术点:
(1)输入函数input
(2)get请求
(3)带参数(构造数据:随机数函数random、加密函数MD5)
appid-xxx、密钥-zzz
(4)字符串的拼接
(5)字符编码的转换(输入字符串必须转化为utf-8)
(6)只输出翻译结即可(apple-苹果)
(7)使用函数的方式调用
"""
import hashlib
from random import randint
import requests
# 设定字符编码格式
encoding = "utf-8"
def get_md5(content):
"""MD5加密函数"""
# 获取一个MD5加密算法对象
md = hashlib.md5()
# 对字符串编码转化为“utf-8”,否则会报TypeError: Unicode-objects must be encoded before hashing
md.update(content.encode(encoding))
# 返回加密后的16进制字符串
return md.hexdigest()
def test_baidu_input():
"""百度翻译函数"""
# 定义接口URL
url = "https://fanyi-api.baidu.com/api/trans/vip/translate"
# 定义APPID
app_id = "xxx"
# 定义密钥secretkey
secret_key = "zzz"
# 定义随机数salt,直接转换为字符串
salt = str(randint(100000, 999999))
print(f"salt:{salt}")
# 定义被翻译的字符串q
q = input("请输入你要翻译的内容:")
# 定义源语言from=auto,翻译语言to=zh
tr_from = "auto"
tr_to = "zh"
# 加密字符串拼接
splicing_sign = app_id + q + salt + secret_key
sign = get_md5(splicing_sign)
print(f"sign:{sign}")
# 构造参数
data = {"q": q, "from": tr_from, "to": tr_to, "appid": app_id, "salt": salt, "sign": sign}
# 构造get请求
res = requests.get(url, params=data)
# 响应结果JSON格式化:res.json()等同于json.load(res.text)
result = res.json()
tr_res = result["trans_result"][0]["dst"]
print(f"翻译结果:{tr_res}")
test_baidu_input()(1)发送带参数的POST请求requests.get("url", data=params)(等同于以字典的形式提交form表单数据)
(2)获取和输出各种响应值
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# author:bigbear
# datetime:2022/8/19 8:25
# software: PyCharm
"""get请求"""
# (1)导入requests包
import requests
import json
# (2)构造一个不带参数的get请求、带参数的get请求、带参数的post请求
post_parameter = {
"q": "apple",
"from": "en",
"to": "zh",
"appid": "xxx",
"salt": "202002121503",
"sign": "7105f811ca9d3835146ed9c44ab46770",
"Content-Type": "application/x-www-form-urlencoded",
}
response2 = requests.post("https://fanyi-api.baidu.com/api/trans/vip/translate", data=post_parameter)
print(f"\n本次响应数据类型是{type(response2)}")
# (3)输出本次响应的状态码
print(f"\n本次响应状态码数据类型是{type(response2.status_code)}")
print(f"本次响应状态码是{response2.status_code}")
# (4)输出本次响应的所有文本
print(f"\n本次响应文本数据类型是{type(response2.text)}")
response2.encoding = "utf-8"
print(f"本次响应文本是{response2.text}")
# (5)输出本次响应的所有值
print(f"\n本次响应cookies数据类型是{type(response2.cookies)}")
response2.encoding = "utf-8"
print(f"本次响应网站的Cookies是{response2.cookies}")
# (6)判断:本次请求后,服务器响应返回的字符串中,是否有“百度一下,你就知道”
exp = "苹果"
if exp in response2.text:
print(f"\n响应值中包含你希望的字符串:{exp}。")
else:
print("\n响应值中不包含你希望的字符串。")
response.json()等同于json.loads(response.text)
# (1)导入requests包
import requests
import json
get_parameter = {
"q": "apple",
"from": "en",
"to": "zh",
"appid": "20200211000382774",
"salt": "202002121503",
"sign": "7105f811ca9d3835146ed9c44ab46770",
}
response1 = requests.get("https://fanyi-api.baidu.com/api/trans/vip/translate", params=get_parameter)
print(type(response1.json()), response1.json())
print(response1.json()["error_msg"], json.loads(response1.text))(1)unittest工作原理
unittest:单元测试框架,作为自动化测试框架的用例组织执行框架
核心:TestCase测试用例(每个测试方法都是test开头、setUp()初始化、tearDown销毁)、TestSuite测试套件、TestRunner测试运行器、TestLoader测试用例加载器、Fixture
内容:编写web自动化-webdriver、编写接口自动化-requests请求、编写移动端自动化-python+appium+unittest
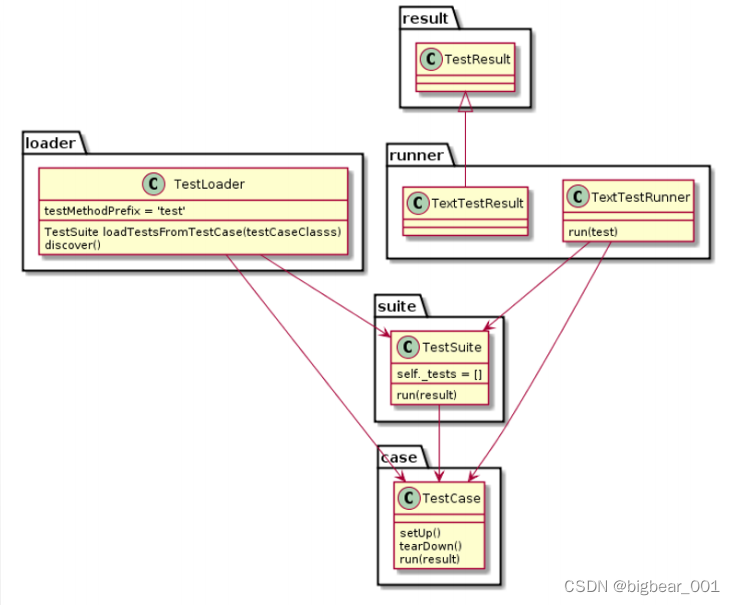
(2)unittest主要结构
创建测试类(继承unittest.TestCase类)
编写测试用例
定义测试套件(流程unittest.TestSuite())
加载测试用例
创建测试报告(HTMLTestRunner)
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# author:bigbear
# datetime:2022/8/20 9:41
# software: PyCharm
"""
快速搭建unittest框架:
(1)创建测试类
"""
import unittest
import requests
class TestV2ex(unittest.TestCase):
"""定义一个测试类,继承unittest.TestCase类"""
def setUp(self) -> None:
"""初始化方法"""
print("初始化属性")
def tearDown(self) -> None:
"""定义结束方法"""
print("所有用例执行结束")
def test_hot(self):
"""自定义测试方法"""
# driver = webdriver.Firefox()
def test_node(self):
"""自定义测试方法"""
res = requests.get("http://www.baidu.com")
return res
def test_user(self):
"""自定义测试方法"""
a = 1
b = 2
self.assertEqual(a, b)
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# author:bigbear
# datetime:2022/8/20 12:22
# software: PyCharm
"""
快速搭建unittest框架:
(2)编写测试用例
(3)定义测试套件(流程)
(4)加载测试用例
(5)创建测试报告:使用unittest框架内容HTMLTestRunner导出HTML格式的测试报告
"""
import unittest
from HTTPTestRunner import HTMLTestRunner
from unittest_api import TestV2ex
# 构建测试套件(流程)
testsuite = unittest.TestSuite()
# 加载测试用例
testsuite.addTest(TestV2ex("test_hot"))
testsuite.addTest(TestV2ex("test_node"))
testsuite.addTest(TestV2ex("test_user"))
# 创建测试报告
fp = open('./report.html', 'wb') # wb:以二进制的格式写入
"""
HTMLTestRunner:
(1)https://pypi.python.org/pypi/HTMLTestRunner
(2)python下的Lib目录,新建一个HTMLTestRunner.py文件,把内容直接复制进去并修改
第94行,将import StringIO修改成import io
第539行,将self.outputBuffer = StringIO.StringIO()修改成self.outputBuffer = io.StringIO()
第642行,将if not rmap.has_key(cls):修改成if not cls in rmap:
第766行,将uo = o.decode(‘latin-1’)修改成uo = e
第772行,将ue = e.decode(‘latin-1’)修改成ue = e
第631行,将print >> sys.stderr, ‘\nTime Elapsed: %s’ % (self.stopTime-self.startTime)修改
成print(sys.stderr, ‘\nTime Elapsed: %s’ % (self.stopTime-self.startTime))
"""
# stream:文件信息流;title:报告的标题;description:一般写对于测试环境的描述信息(操作系统、浏览器……);tester:测试人员
runner = HTMLTestRunner(stream=fp, title='测试报告', description='执行报告')
runner.run(testsuite)
fp.close()
(1)使用CSV外部文件
参数化:
程序中(代码本身:random、list、range)
外部数据文件(CSV文件、text文件)
(2)断言
自带断言方法
assertEqual(a, b) a==b
assertNotEqual(a, b) a!=b
assertTrue(x) bool(x) is True
assertFalse(x) booI(x) is False
assertIs(a, b) a is b
assertIsNot(a, b) a is not b
assertIsNone(x) x is None
assertIsNotNone(x) x is not None
assertIn(a, b) a in b
assertNotIn(a, b) a not in b
assertIsInstance(a, b) isinstance(a,b)
assertNotIsInstance(a, b) not isinstance(a,b)
自写判断进行结果输出
if-else
try-except-finally异常捕获
(1)测试报告
框架内容-HTMLTestRunner(python2,修改内容可在python3中使用)
导出HTML格式的测试报告
runner = HTMLTestRunner(stream=fp, title='测试报告', description='执行报告')
# 创建测试报告
fp = open('./report.html', 'wb') # wb:以二进制的格式写入
"""
HTMLTestRunner:
(1)https://pypi.python.org/pypi/HTMLTestRunner
(2)python下的Lib目录,新建一个HTMLTestRunner.py文件,把内容直接复制进去并修改
第94行,将import StringIO修改成import io
第539行,将self.outputBuffer = StringIO.StringIO()修改成self.outputBuffer = io.StringIO()
第642行,将if not rmap.has_key(cls):修改成if not cls in rmap:
第766行,将uo = o.decode(‘latin-1’)修改成uo = e
第772行,将ue = e.decode(‘latin-1’)修改成ue = e
第631行,将print >> sys.stderr, ‘\nTime Elapsed: %s’ % (self.stopTime-self.startTime)修改
成print(sys.stderr, ‘\nTime Elapsed: %s’ % (self.stopTime-self.startTime))
"""
# stream:文件信息流;title:报告的标题;description:一般写对于测试环境的描述信息(操作系统、浏览器……);tester:测试人员
runner = HTMLTestRunner(stream=fp, title='测试报告', description='执行报告')
runner.run(testsuite)
fp.close()
(2)日志
APP---adb
adb logcat #打印默认日志数据
adb logcat -v time *:e --pid=<pid> >D:\log.txt #打印详细时间(-v time)、级别是Error(*:e)和给定pid中(--pid=<pid>)的日志数据并保存到电脑固定位置
Linux---查看系统运行日志
生成日志(标准化格式:程序员按企业设计输出系统运行信息)
用途:系统运行异常时查看异常信息(用户名、时间和日期、操作事件、操作对象、操作内容、信息级别显示(info/warning/error/exception))
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# author:bigbear
# datetime:2022/8/20 12:21
# software: PyCharm
"""测试日志输出"""
import time
info_type = 3
def log():
"""以标准格式输出一些脚本运行过程中的重要信息"""
fp = open('./log.txt', 'a+')
# 运行时间记录:年月日时分秒
e_t = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())
print(e_t)
# 获取当前运行的文件名和函数名
f_n = log.__name__
print(f_n)
# 模拟信息类型的判断
# msg_type = "info"
if info_type == 0:
msg_type = "info"
elif info_type == 1:
msg_type = "warning"
elif info_type == 2:
msg_type = "error"
else:
msg_type = "exception"
# 组织一条写入log.txt的信息
info = f"[{e_t}][{msg_type}]:{f_n}\n"
# 将info写入log
fp.write(info)
fp.close()
log()
log.txt日志文件
[2022-08-20 12:47:10][info]:log [2022-08-20 12:47:14][warning]:log [2022-08-20 12:47:17][error]:log [2022-08-20 12:47:20][exception]:log [2022-09-07 16:37:17][exception]:log [2022-09-07 16:37:54][exception]:log
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# author:bigbear
# datetime:2022/9/27 18:15
# software: PyCharm
"""
1、使用unittest框架
2、定义请求方法
3、在方法中完成请求
4、对返回值进行JSON格式化
5、对格式化后的数据进行类型(字典、列表)判断
6、对接口数据进行断言
7、将日志信息进行组合写入日志文件
"""
import time
import unittest
import requests
class TestV2ex(unittest.TestCase):
"""对v2ex网站进行测试"""
def setUp(self) -> None:
"""初始化测试环境"""
def test_hot(self):
"""对热点话题接口进行测试"""
# 定义函数开始时间
start_time = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())
# URL地址
url = "https://www.v2ex.com/api/topics/hot.json"
# 发送请求
res = requests.get(url)
# JSON格式化响应结果
result = res.json()
# 定义表示返回值中数据元素个数的变量
res_num = 0
# 判断数据类型,确定元素个数
res_type = type(result)
if isinstance(result, dict):
res_num = 1
elif isinstance(result, list):
res_num = len(result)
else:
print("无该数据类型")
# 预期结果
except_num = 10
# 断言
try:
self.assertEqual(except_num, res_num, "个数不一样!!!")
except AssertionError as ae:
print(ae)
finally:
# 定义函数结束时间
end_time = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())
# 组合日志信息
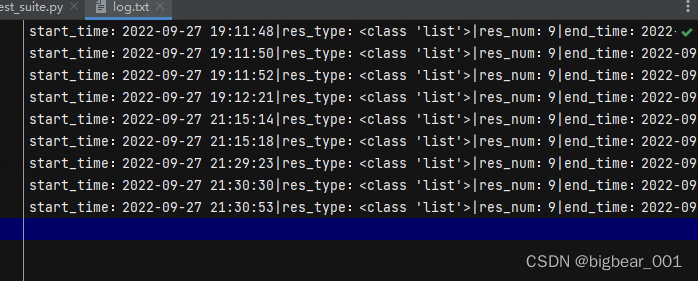
log_info = f"start_time:{start_time}|res_type:{res_type}|res_num:{res_num}|end_time:{end_time}"
# 输出测试日志
with open("./log/log.txt", "a+", encoding="utf-8") as f:
f.write(log_info)
f.write("\n")
def tearDown(self) -> None:
"""重置测试环境"""
if __name__ == '__main__':
unittest.main()
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# author:bigbear
# datetime:2022/9/27 18:15
# software: PyCharm
"""
快速搭建unittest框架:
(2)编写测试用例
(3)定义测试套件(流程)
(4)加载测试用例
(5)创建测试报告:使用unittest框架内容HTMLTestRunner导出HTML格式的测试报告
HTMLTestRunner:
(1)https://pypi.python.org/pypi/HTMLTestRunner
(2)python下的Lib目录,新建一个HTMLTestRunner.py文件,把内容直接复制进去并修改
第94行,将import StringIO修改成import io
第539行,将self.outputBuffer = StringIO.StringIO()修改成self.outputBuffer = io.StringIO()
第642行,将if not rmap.has_key(cls):修改成if not cls in rmap:
第766行,将uo = o.decode(‘latin-1’)修改成uo = e
第772行,将ue = e.decode(‘latin-1’)修改成ue = e
第631行,将print >> sys.stderr, ‘\nTime Elapsed: %s’ % (self.stopTime-self.startTime)修改
成print(sys.stderr, ‘\nTime Elapsed: %s’ % (self.stopTime-self.startTime))
"""
import time
import unittest
from HTTPTestRunner import HTMLTestRunner
from test_case import TestV2ex
# 构建测试套件(流程)
test_suite = unittest.TestSuite()
# 加载测试用例
test_suite.addTest(TestV2ex("test_hot"))
# 创建测试报告
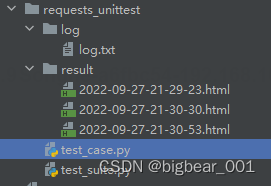
f_t = time.strftime("%Y-%m-%d-%H-%M-%S", time.localtime())
filename = f"./result/{f_t}.html"
with open(filename, "wb") as f:
"""wb:以二进制的格式写入"""
# stream:文件信息流;title:报告的标题;description:一般写对于测试环境的描述信息(操作系统、浏览器……);tester:测试人员
runner = HTMLTestRunner(stream=f, title='测试报告', description='执行报告')
runner.run(test_suite)

愿你我都能为中华民族的伟大复兴尽一份绵薄力量,让中华文化的根扎根在中国这片绿水青山之上,让新一代中华儿女传承与发扬!!!
---无名之辈
以上内容均是本人自学,当然是有网上公布的内容,如有冒犯,请留言,立即改正,谢谢!
看完要是觉得对自己有用,动一下您那根金色的会一指禅的右手食指,按一下您的鼠标左键,在对应的那个位置点个赞,亦或者在评论区留下您的绝顶好句,亦或者收藏在您的收藏夹里,再走也不迟嘛!您说要不要得!谢谢您的阅读和赞赏!
很好奇,就使用rubyonrails自动化单元测试而言,你们正在做什么?您是否创建了一个脚本来在cron中运行rake作业并将结果邮寄给您?git中的预提交Hook?只是手动调用?我完全理解测试,但想知道在错误发生之前捕获错误的最佳实践是什么。让我们理所当然地认为测试本身是完美无缺的,并且可以正常工作。下一步是什么以确保他们在正确的时间将可能有害的结果传达给您? 最佳答案 不确定您到底想听什么,但是有几个级别的自动代码库控制:在处理某项功能时,您可以使用类似autotest的内容获得关于哪些有效,哪些无效的即时反馈。要确保您的提
我正在编写一个包含C扩展的gem。通常当我写一个gem时,我会遵循TDD的过程,我会写一个失败的规范,然后处理代码直到它通过,等等......在“ext/mygem/mygem.c”中我的C扩展和在gemspec的“扩展”中配置的有效extconf.rb,如何运行我的规范并仍然加载我的C扩展?当我更改C代码时,我需要采取哪些步骤来重新编译代码?这可能是个愚蠢的问题,但是从我的gem的开发源代码树中输入“bundleinstall”不会构建任何native扩展。当我手动运行rubyext/mygem/extconf.rb时,我确实得到了一个Makefile(在整个项目的根目录中),然后当
我有一个围绕一些对象的包装类,我想将这些对象用作散列中的键。包装对象和解包装对象应映射到相同的键。一个简单的例子是这样的:classAattr_reader:xdefinitialize(inner)@inner=innerenddefx;@inner.x;enddef==(other)@inner.x==other.xendenda=A.new(o)#oisjustanyobjectthatallowso.xb=A.new(o)h={a=>5}ph[a]#5ph[b]#nil,shouldbe5ph[o]#nil,shouldbe5我试过==、===、eq?并散列所有无济于事。
我有一些Ruby代码,如下所示:Something.createdo|x|x.foo=barend我想编写一个测试,它使用double代替block参数x,这样我就可以调用:x_double.should_receive(:foo).with("whatever").这可能吗? 最佳答案 specify'something'dox=doublex.should_receive(:foo=).with("whatever")Something.should_receive(:create).and_yield(x)#callthere
Sinatra新手;我正在运行一些rspec测试,但在日志中收到了一堆不需要的噪音。如何消除日志中过多的噪音?我仔细检查了环境是否设置为:test,这意味着记录器级别应设置为WARN而不是DEBUG。spec_helper:require"./app"require"sinatra"require"rspec"require"rack/test"require"database_cleaner"require"factory_girl"set:environment,:testFactoryGirl.definition_file_paths=%w{./factories./test/
我遵循MichaelHartl的“RubyonRails教程:学习Web开发”,并创建了检查用户名和电子邮件长度有效性的测试(名称最多50个字符,电子邮件最多255个字符)。test/helpers/application_helper_test.rb的内容是:require'test_helper'classApplicationHelperTest在运行bundleexecraketest时,所有测试都通过了,但我看到以下消息在最后被标记为错误:ERROR["test_full_title_helper",ApplicationHelperTest,1.820016791]test
我收到这个错误:RuntimeError(自动加载常量Apps时检测到循环依赖当我使用多线程时。下面是我的代码。为什么会这样?我尝试多线程的原因是因为我正在编写一个HTML抓取应用程序。对Nokogiri::HTML(open())的调用是一个同步阻塞调用,需要1秒才能返回,我有100,000多个页面要访问,所以我试图运行多个线程来解决这个问题。有更好的方法吗?classToolsController0)app.website=array.join(',')putsapp.websiteelseapp.website="NONE"endapp.saveapps=Apps.order("
我已经构建了一些serverspec代码来在多个主机上运行一组测试。问题是当任何测试失败时,测试会在当前主机停止。即使测试失败,我也希望它继续在所有主机上运行。Rakefile:namespace:specdotask:all=>hosts.map{|h|'spec:'+h.split('.')[0]}hosts.eachdo|host|begindesc"Runserverspecto#{host}"RSpec::Core::RakeTask.new(host)do|t|ENV['TARGET_HOST']=hostt.pattern="spec/cfengine3/*_spec.r
我在app/helpers/sessions_helper.rb中有一个帮助程序文件,其中包含一个方法my_preference,它返回当前登录用户的首选项。我想在集成测试中访问该方法。例如,这样我就可以在测试中使用getuser_path(my_preference)。在其他帖子中,我读到这可以通过在测试文件中包含requiresessions_helper来实现,但我仍然收到错误NameError:undefinedlocalvariableormethod'my_preference'.我做错了什么?require'test_helper'require'sessions_hel
只是想确保我理解了事情。据我目前收集到的信息,Cucumber只是一个“包装器”,或者是一种通过将事物分类为功能和步骤来组织测试的好方法,其中实际的单元测试处于步骤阶段。它允许您根据事物的工作方式组织您的测试。对吗? 最佳答案 有点。它是一种组织测试的方式,但不仅如此。它的行为就像最初的Rails集成测试一样,但更易于使用。这里最大的好处是您的session在整个Scenario中保持透明。关于Cucumber的另一件事是您(应该)从使用您的代码的浏览器或客户端的角度进行测试。如果您愿意,您可以使用步骤来构建对象和设置状态,但通常您