有时,为了对某个sql语句进行效率测试,我们需要海量数据时,可以用此法为表创建海量数据
-- 为了对某个sql语句进行效率测试,我们需要海量数据时,可以用此法为表创建海量数据
CREATE TABLE my_tab01(
id INT ,
`name` VARCHAR(32),
sal DOUBLE,
job VARCHAR(32),
deptno INT
)
DESC my_tab01
SELECT * FROM my_tab01
-- 演示如何自我复制
-- 1.先把emp表的记录复制到my_tab01
INSERT INTO my_tab01
(id,`name`,sal,job,deptno)
SELECT empno,ename,sal,job,deptno FROM emp;
-- 2.自我复制
INSERT INTO my_tab01
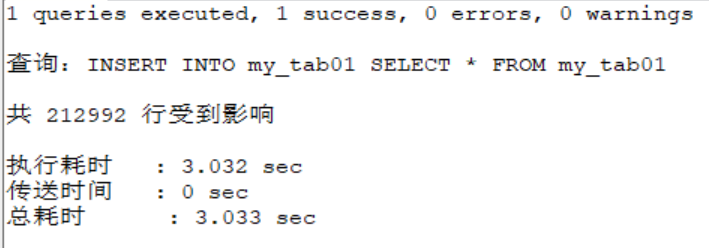
SELECT * FROM my_tab01;
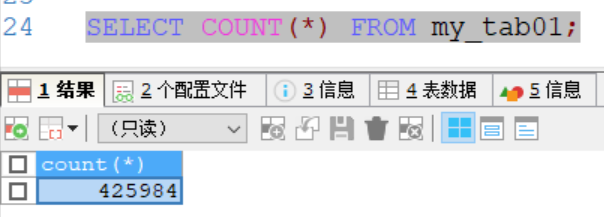
SELECT COUNT(*) FROM my_tab01;
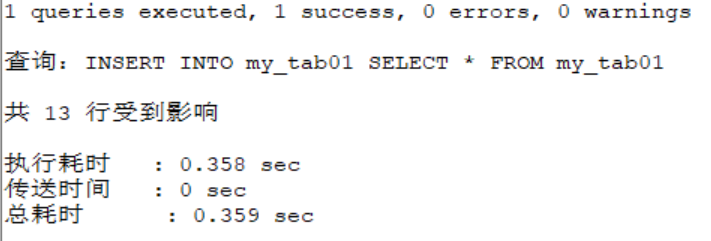
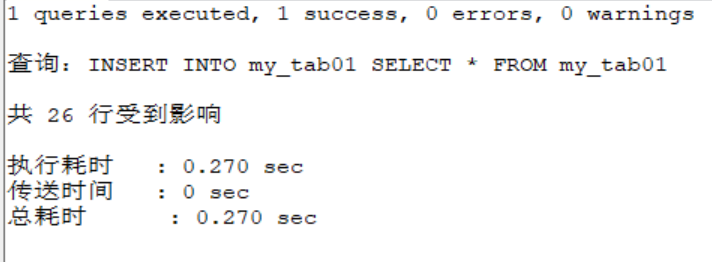
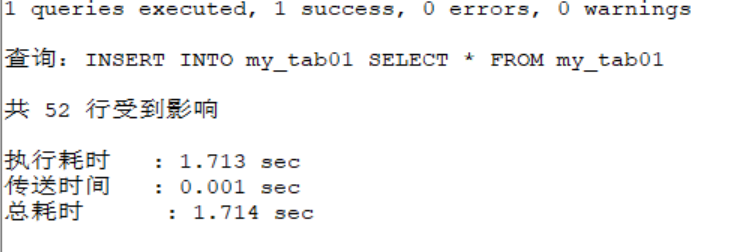
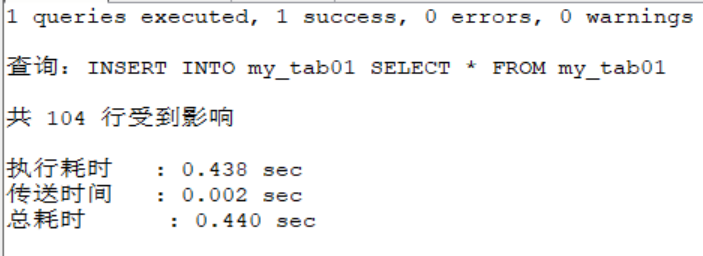
.....
-- 如何删掉一张表的重复记录
-- 1.先创建一张表 my_tab02
CREATE TABLE my_tab02 LIKE emp; -- 这个语句将 emp表的结构(列),复制到my_tab02
DESC my_tab02;
-- 2.让my_tab02 有重复的记录
INSERT INTO my_tab02
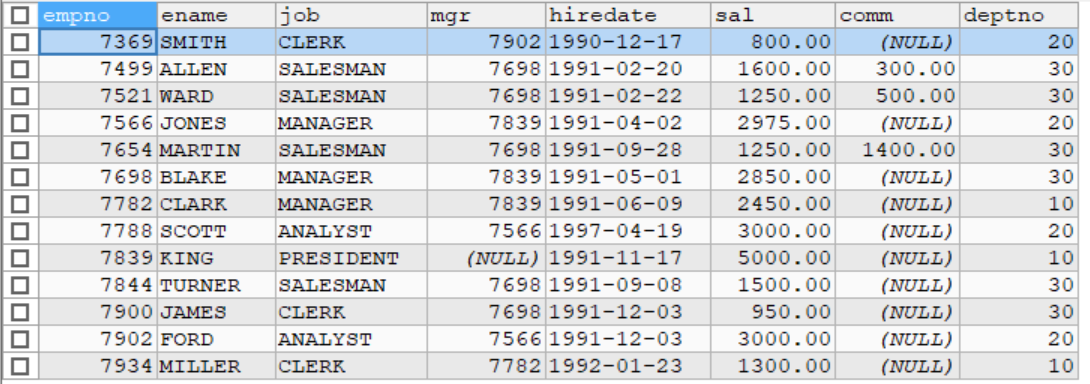
SELECT * FROM emp;
SELECT * FROM my_tab02;
-- 3.考虑去重
/*
思路:
(1)先创建一张临时表 my_tmp,该表的结构和 my_tab02 一样
(2)把 my_tab02 的记录通过 distinct 关键字处理后,把记录复制到 my_tmp
(3)清除掉 my_tab02 的记录
(4)把 my_tmp 的记录复制到 my_tab02 中
(5)drop 掉 my_tmp表
*/
-- 3.1 先创建一张临时表 my_tmp,该表的结构和 my_tab02 一样
CREATE TABLE my_tmp LIKE my_tab02;
-- 3.2 把 my_tab02 的记录通过 distinct 关键字处理后,把记录复制到 my_tmp
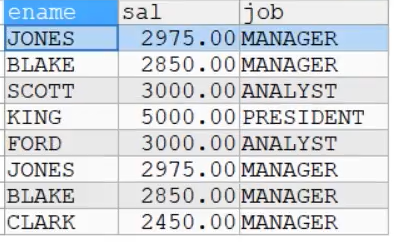
INSERT INTO my_tmp
SELECT DISTINCT * FROM my_tab02;
-- 3.3 清除掉 my_tab02 的记录
DELETE FROM my_tab02;
-- 3.4 把 my_tmp 的记录复制到 my_tab02 中
INSERT INTO my_tab02
SELECT * FROM my_tmp;
-- 3.5 drop 掉 my_tmp表
DROP TABLE my_tmp;
SELECT * FROM my_tab02;
有时候在实际应用中,为了合并多条select语句的结果,可以使用集合操作符号union、union all、
该操作符用于取得两个结果集的并集。当使用该操作符时,不会取消重复行

该操作符与union all相似。但是会自动去掉结果集中的重复行

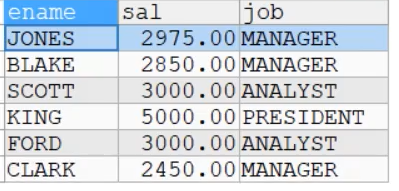
前面我们学习的查询,是利用where子句对两张表或者多张表,形成的笛卡尔集进行筛选,根据关联条件,显示所有匹配的记录,匹配不上的就不显示
比如:列出部门名称和这些部门的员工名称和工作,同时要求显示出那些没有员工的部门
-- 外连接
-- 比如:列出部门名称和这些部门的员工名称和工作,同时要求显示出那些没有员工的部门
-- 使用我们学过的多表查询的SQL,看看效果如何?
SELECT dname,ename,job
FROM emp,dept
WHERE emp.deptno = dept.deptno
ORDER BY dname
-- 原先的办法只能显示有员工的记录,如果有一个部门没有员工,就无法显示该部门
如下:只能显示三个部门
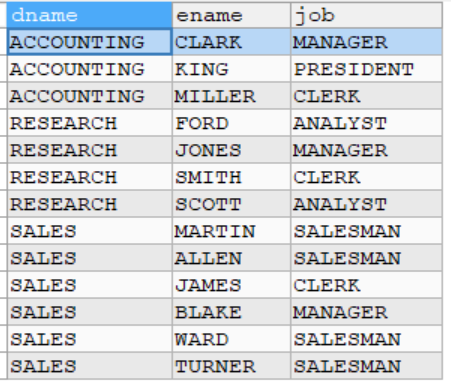
这时候就需要用到外连接
左外连接(如果左侧的表完全显示,我们就说是左外链接)
select ... from 表1 left join 表2 on 条件
表1就是左表 ,表2就是右表
左侧的表完全显示是指,即使左边的表跟右边的表没有匹配上,也会将左侧的表完全显示
右外连接(如果右侧的表完全显示,我们就说是右外链接)
select ... from 表1 right join 表2 on 条件
表1为左表 ,表2为右表
右侧的表完全显示是指,即使右边的表跟左边的表没有匹配上,也会将右侧的表完全显示
例子
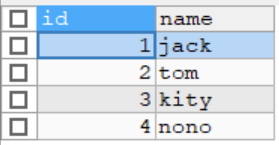
先创建两张表stu,exam
-- 创建 stu
CREATE TABLE stu(
id INT,
`name` VARCHAR(32)
);
INSERT INTO stu VALUES(1,'jack'),(2,'tom'),(3,'kity'),(4,'nono');
SELECT * FROM stu;
-- 创建 exam
CREATE TABLE exam(
id INT,
grade INT
);
INSERT INTO exam VALUES(1,56),(2,76),(11,8);
SELECT * FROM exam;
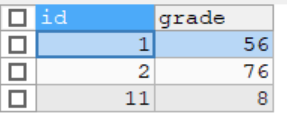
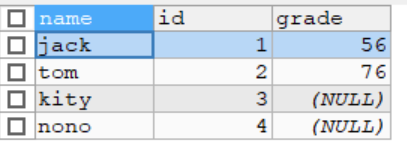
要求1:使用左连接(显示所有人的成绩,如果没有成绩,也要显示该人的姓名和id号 )
-- 使用左连接
-- (显示所有人的成绩,如果没有成绩,也要显示该人的姓名和id号)
SELECT `name`,stu.id,grade
FROM stu,exam
WHERE stu.id = exam.id
-- 改成左外连接
SELECT `name`,stu.id,grade
FROM stu LEFT JOIN exam
ON stu.id = exam.id
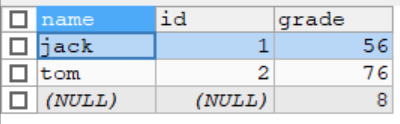
要求2:右连接(显示所有成绩,如果没有名字匹配就显示空)
-- 右外连接
SELECT `name`,stu.id,grade
FROM stu RIGHT JOIN exam
ON stu.id = exam.id
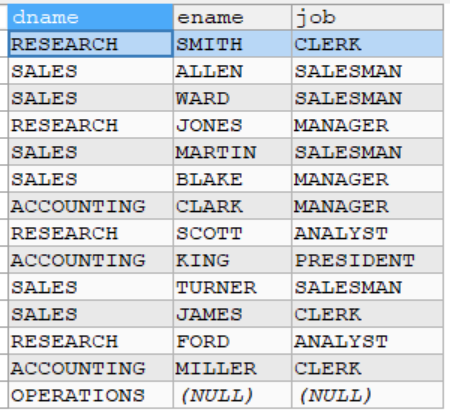
例子2
列出部门名称和这些部门的员工信息(名字和工作),同时列出那些没有员工的部门
-- 列出部门名称和这些部门的员工信息(名字和工作),同时列出那些没有员工的部门
-- 1. 使用左外连接实现
SELECT dname,ename,job
FROM dept LEFT JOIN emp
ON dept.deptno = emp.deptno
-- 2. 使用右外连接实现
SELECT dname,ename,job
FROM emp RIGHT JOIN dept
ON dept.deptno = emp.deptno
在实际的开发中绝大多数情况下使用的是前面学过的连接
我正在用Ruby编写一个简单的程序来检查域列表是否被占用。基本上它循环遍历列表,并使用以下函数进行检查。require'rubygems'require'whois'defcheck_domain(domain)c=Whois::Client.newc.query("google.com").available?end程序不断出错(即使我在google.com中进行硬编码),并打印以下消息。鉴于该程序非常简单,我已经没有什么想法了-有什么建议吗?/Library/Ruby/Gems/1.8/gems/whois-2.0.2/lib/whois/server/adapters/base.
我知道我可以指定某些字段来使用pluck查询数据库。ids=Item.where('due_at但是我想知道,是否有一种方法可以指定我想避免从数据库查询的某些字段。某种反拔?posts=Post.where(published:true).do_not_lookup(:enormous_field) 最佳答案 Model#attribute_names应该返回列/属性数组。您可以排除其中一些并传递给pluck或select方法。像这样:posts=Post.where(published:true).select(Post.attr
//1.验证返回状态码是否是200pm.test("Statuscodeis200",function(){pm.response.to.have.status(200);});//2.验证返回body内是否含有某个值pm.test("Bodymatchesstring",function(){pm.expect(pm.response.text()).to.include("string_you_want_to_search");});//3.验证某个返回值是否是100pm.test("Yourtestname",function(){varjsonData=pm.response.json
1.在Python3中,下列关于数学运算结果正确的是:(B)a=10b=3print(a//b)print(a%b)print(a/b)A.3,3,3.3333...B.3,1,3.3333...C.3.3333...,3.3333...,3D.3.3333...,1,3.3333...解析: 在Python中,//表示地板除(向下取整),%表示取余,/表示除(Python2向下取整返回3)2.如下程序Python2会打印多少个数:(D)k=1000whilek>1: print(k)k=k/2A.1000 B.10C.11D.9解析: 按照题意每次循环K/2,直到K值小于等
我正在尝试查询我的Rails数据库(Postgres)中的购买表,我想查询时间范围。例如,我想知道在所有日期的下午2点到3点之间进行了多少次购买。此表中有一个created_at列,但我不知道如何在不搜索特定日期的情况下完成此操作。我试过:Purchases.where("created_atBETWEEN?and?",Time.now-1.hour,Time.now)但这最终只会搜索今天与那些时间的日期。 最佳答案 您需要使用PostgreSQL'sdate_part/extractfunction从created_at中提取小时
我在Rails上使用带有ruby的solr。一切正常,我只需要知道是否有任何现有代码来清理用户输入,比如以?开头的查询。或* 最佳答案 我不知道执行此操作的任何代码,但理论上可以通过查看parsingcodeinLucene来完成并搜索thrownewParseException(只有16个匹配!)。在实践中,我认为您最好只捕获代码中的任何solr异常并显示“无效查询”消息或类似信息。编辑:这里有几个“sanitizer”:http://pivotallabs.com/users/zach/blog/articles/937-s
我正在为锦标赛开发一个Rails应用程序。我在这个查询中使用了三个模型:classPlayertruehas_and_belongs_to_many:tournamentsclassTournament:destroyclassPlayerMatch"Player",:foreign_key=>"player_one"belongs_to:player_two,:class_name=>"Player",:foreign_key=>"player_two"在tournaments_controller的显示操作中,我调用以下查询:Tournament.where(:id=>params
我想用sunspot重现以下原始solr查询q=exact_term_text:fooORterm_textv:foo*ORalternate_text:bar*但我无法通过标准的太阳黑子界面理解这是否可能以及如何实现,因为看起来:fulltext方法似乎不接受多个文本/搜索字段参数我不知道将什么参数作为第一个参数传递给fulltext,就好像我通过了"foo"或"bar"结果不匹配如果我传递一个空参数,我得到一个q=*:*范围过滤器(例如with(:term).starting_with('foo*')(顾名思义)作为过滤器查询应用,因此不参与评分。似乎可以手动编写字符串(或者可能使
例如,假设我有一个名为Products的模型,并且在ProductsController中,我有以下代码用于product_listView以显示已排序的产品。@products=Product.order(params[:order_by])让我们想象一下,在product_listView中,用户可以使用下拉菜单按价格、评级、重量等进行排序。数据库中的产品不会经常更改。我很难理解的是,每次用户选择新的order_by过滤器时,rails是否必须查询,或者rails是否能够以某种方式缓存事件记录以在服务器端重新排序?有没有一种方法可以编写它,以便在用户排序时rails不会重新查询结果
我目前正在尝试了解RoR。我将两个字符串传递到我的Controller中。一个是随机的十六进制字符串,另一个是电子邮件。该项目用于对数据库进行简单的电子邮件验证。我遇到的问题是当我输入如下内容来测试我的页面时:http://signup.testsite.local/confirm/da2fdbb49cf32c6848b0aba0f80fb78c/bob.villa@gmailcom我在:email的参数散列中得到的全部是'bob'。我在gmail和com之间留下了.,因为那样会导致匹配根本不起作用。我的路由匹配如下:match"confirm/:code/:email"=>"conf