文章目录
int main()
{
string str;
while (cin >> str)
{
cout << str << endl;
}
return 0;
}

我们在OJ的时候经常会用到while(cin >> str),这里的流提取实际上是个阻塞操作,只要缓冲区还有数据就继续读,默认以空格或者换行结束,有空格说明是把两段字符串尾插到str。
那么它是怎么结束呢?
答案是输入[Ctrl]-c或者[Ctrl]-z + 换行。
[Ctrl]-c是发送信号结束进程。
[Ctrl]-z + 换行是通过返回值条件判断结束while循环,具体看下面讲解。
cin >> str的返回值是一个istream类
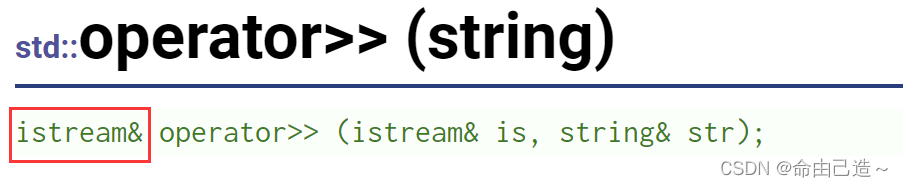
实际上返回的就是cin对象。而c++98支持了隐式类型转换,把istream转换为bool,所以能够条件判断。
具体是怎么转换的呢?
看下面这个例子:
class A
{
public:
A(int a)
: _a(a)
{}
private:
int _a;
};
int main()
{
// 内置类型转换成自定义类型
A a = 1;
return 0;
}
这里按道理来说是构造一个临时对象再拷贝构造,而编译器优化成了直接构造。如果没有单参数的构造函数就无法转换。
那如果我们想要让自定义类型转换成内置类型呢?
直接int aa = a;肯定会报错。
但是我们可以加一个特殊的重载函数。
class A
{
public:
A(int a)
: _a(a)
{}
operator int()
{
return _a;
}
private:
int _a;
};
int main()
{
// 内置类型转换成自定义类型
A a = 1;
// 自定义类型转化成内置类型
int aa = a;
cout << aa << endl;
return 0;
}
而我们上面说的把istream转化成bool类型就是类似这样实现的。
operator bool() 里面会检查是特殊字符([Ctrl]-z )就会返回false。
我们知道cin和scanf都有自己的缓冲区,而如果我们用scanf写入再用cout输出,就会导致速度变慢很多(缓冲区拷贝)。
而sync_with_stdio函数是一个“是否兼容stdio”的开关,C++为了兼容C,保证程序在使用了std::printf和std::cout的时候不发生混乱,将输出流绑到了一起。
决定C++标准streams(cin,cout,cerr…)是否与相应的C标准程序库文件(stdin,stdout,stderr)同步,也就是是否使用相同的stream缓冲区,缺省情况是同步的,但由于同步会带来某些不必要的负担,因此该函数作用就是我们自己可以取消同步 。
#include <iostream>
int main()
{
std::ios::sync_with_stdio(false);
std::cin.tie(0);
// IO
}
文件的读写有两种:
1️⃣ 二进制读写
2️⃣ 文本读写

ofstream是写入文件,而ifstream是从文件中读取。


这里的参数表示我们想以什么样的方式打开文件。
比方说当我们想用二进制的方式打开文件:
ofs.open ("test.txt", std::ofstream::out | std::ofstream::binary)
而我们也可以在构造的时候直接传进参数。

ofstream ofs("test.txt", std::ios_base::out | std::ios_base::binary)
struct ServerInfo
{
char _address[32];
int _port;
};
struct Config
{
public:
Config(const char* filename)
: _filename(filename)
{}
void Write(ServerInfo info)
{
ofstream ofs("test.txt", std::ios_base::out | std::ios_base::binary);
ofs.write((char*)&info, sizeof info);
}
void Read(ServerInfo& info)
{
ifstream ifs("test.txt", std::ios_base::in | std::ios_base::binary);
ifs.read((char*)&info, sizeof info);
}
private:
string _filename;
};
int main()
{
Config con("text.txt");
ServerInfo si = { "aaaaaa", 910 };
con.Write(si);
return 0;
}
而我们也可以把数据读回来。
int main()
{
Config con("text.txt");
//ServerInfo si = { "aaaaaa", 910 };
//con.Write(si);
ServerInfo si;
con.Read(si);
cout << si._address << " " << si._port << endl;
return 0;
}

可以看到内存中和写出去显示出来的不一样。
当然我们可以用文本读写的方式。
struct ServerInfo
{
char _address[32];
int _port;
};
struct Config
{
public:
Config(const char* filename)
: _filename(filename)
{}
void Write(ServerInfo info)
{
ofstream ofs(_filename);
// 重载
ofs << info._address << endl;
ofs << info._port << endl;
}
void Read(ServerInfo& info)
{
ifstream ifs(_filename);
// 重载
ifs >> info._address;
ifs >> info._port;
}
private:
string _filename;
};
int main()
{
Config con("text.txt");
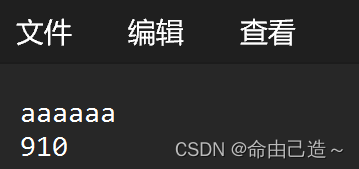
ServerInfo si = { "aaaaaa", 910 };
con.Write(si);
/*ServerInfo si;
con.Read(si);
cout << si._address << " " << si._port << endl;*/
return 0;
}

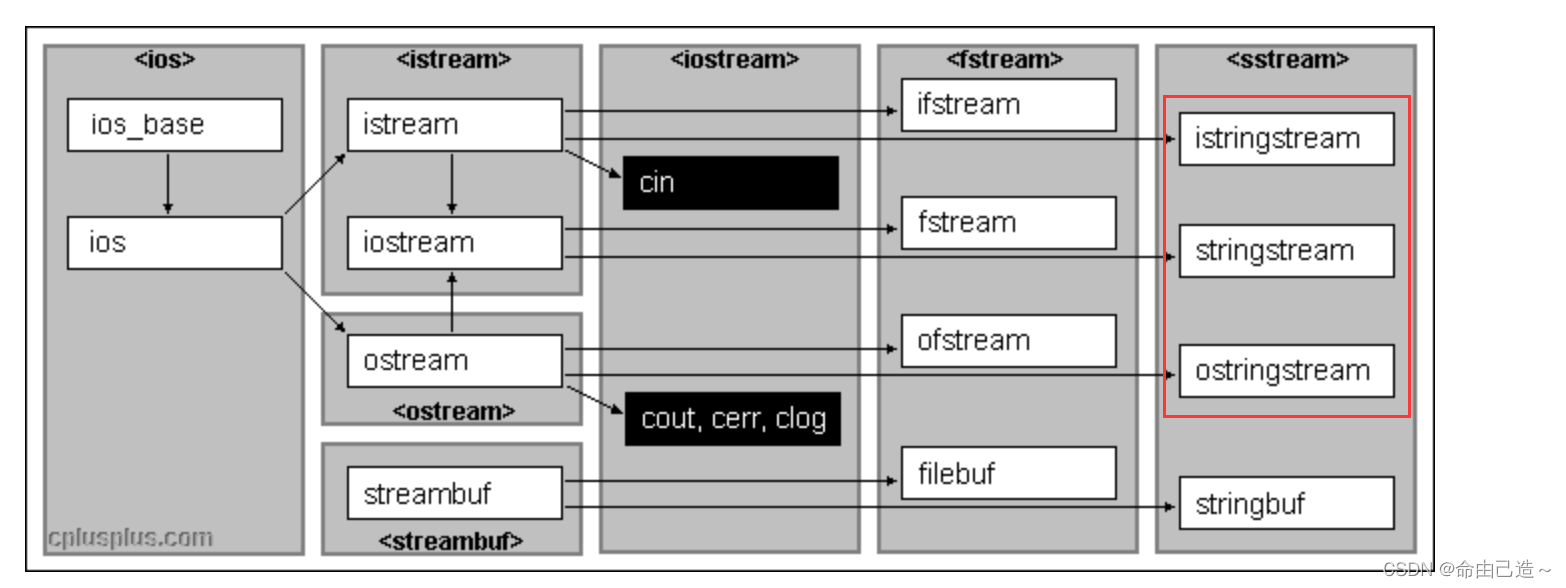
在程序中如果想要使用stringstream,必须要包含头文件。在该头文件下,标准库三个类:
istringstream、ostringstream 和 stringstream,分别用来进行流的输入、输出和输入输出操作。
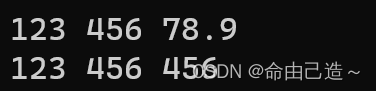
int main()
{
int a = 123;
const char* b = "456";
double c = 78.9;
ostringstream os;
os << a;
os << b;
os << c;
cout << os.str() << endl;
return 0;
}

当然我们也可以把每个数据都提取出来。但此时输入的时候就要空格或者换行隔开。
int main()
{
int a = 123;
const char* b = "456";
double c = 78.9;
ostringstream os;
os << a << " ";
os << b << " ";
os << c << " ";
string ret = os.str();
cout << ret << endl;
int d;
char e[20];
double f;
istringstream is(ret);
is >> d >> e >> f;
cout << d << " ";
cout << e << " ";
cout << e << " ";
return 0;
}
序列化指的是将一个内存对象转化成一串字节数据(存储在一个字节数组中),可用于保存到本地文件或网络传输。反序列化就是将字节数据还原成内存对象。
总结
序列化:将对象变成字节流的形式传出去。
反序列化:从字节流恢复成原来的对象。
简单来说,对象序列化通经常使用于两个目的:
1️⃣ 将对象存储于硬盘上,便于以后反序列化使用;
2️⃣ 在网络上传送对象的字节序列
我们现在模拟一个聊天的发送窗口。
class Date
{
friend ostream& operator << (ostream& out, const Date& d);
friend istream& operator >> (istream& in, Date& d);
public:
Date(int year = 1, int month = 1, int day = 1)
:_year(year)
, _month(month)
, _day(day)
{}
private:
int _year;
int _month;
int _day;
};
istream& operator >> (istream& in, Date& d)
{
in >> d._year >> d._month >> d._day;
return in;
}
ostream& operator << (ostream& out, const Date& d)
{
out << d._year << " " << d._month << " " << d._day;
return out;
}
struct ServerInfo
{
friend istream& operator >> (istream& in, ServerInfo& si);
friend ostream& operator << (ostream& out, ServerInfo& si);
string _name;// 昵称
Date _d;// 时间
string _msg;// 信息
};
istream& operator >> (istream& in, ServerInfo& si)
{
in >> si._name >> si._d >> si._msg;
return in;
}
ostream& operator << (ostream& out, ServerInfo& si)
{
out << si._name << " ";
out << si._d << " ";
out << si._msg << " ";
return out;
}
int main()
{
ServerInfo p{ "海阔天空", {2023, 4, 19}, "hello" };
stringstream os;
os << p;
string ret = os.str();
ServerInfo is;
stringstream oss(ret);
oss >> is;
cout << "-------------------------------------------------------" << endl;
cout << "昵称:" << is._name << " ";
cout << is._d << endl;
cout << is._name << ": " << is._msg << endl;
cout << "-------------------------------------------------------" << endl;
return 0;
}

我正在学习如何使用Nokogiri,根据这段代码我遇到了一些问题:require'rubygems'require'mechanize'post_agent=WWW::Mechanize.newpost_page=post_agent.get('http://www.vbulletin.org/forum/showthread.php?t=230708')puts"\nabsolutepathwithtbodygivesnil"putspost_page.parser.xpath('/html/body/div/div/div/div/div/table/tbody/tr/td/div
我有一个Ruby程序,它使用rubyzip压缩XML文件的目录树。gem。我的问题是文件开始变得很重,我想提高压缩级别,因为压缩时间不是问题。我在rubyzipdocumentation中找不到一种为创建的ZIP文件指定压缩级别的方法。有人知道如何更改此设置吗?是否有另一个允许指定压缩级别的Ruby库? 最佳答案 这是我通过查看rubyzip内部创建的代码。level=Zlib::BEST_COMPRESSIONZip::ZipOutputStream.open(zip_file)do|zip|Dir.glob("**/*")d
类classAprivatedeffooputs:fooendpublicdefbarputs:barendprivatedefzimputs:zimendprotecteddefdibputs:dibendendA的实例a=A.new测试a.foorescueputs:faila.barrescueputs:faila.zimrescueputs:faila.dibrescueputs:faila.gazrescueputs:fail测试输出failbarfailfailfail.发送测试[:foo,:bar,:zim,:dib,:gaz].each{|m|a.send(m)resc
很好奇,就使用rubyonrails自动化单元测试而言,你们正在做什么?您是否创建了一个脚本来在cron中运行rake作业并将结果邮寄给您?git中的预提交Hook?只是手动调用?我完全理解测试,但想知道在错误发生之前捕获错误的最佳实践是什么。让我们理所当然地认为测试本身是完美无缺的,并且可以正常工作。下一步是什么以确保他们在正确的时间将可能有害的结果传达给您? 最佳答案 不确定您到底想听什么,但是有几个级别的自动代码库控制:在处理某项功能时,您可以使用类似autotest的内容获得关于哪些有效,哪些无效的即时反馈。要确保您的提
假设我做了一个模块如下:m=Module.newdoclassCendend三个问题:除了对m的引用之外,还有什么方法可以访问C和m中的其他内容?我可以在创建匿名模块后为其命名吗(就像我输入“module...”一样)?如何在使用完匿名模块后将其删除,使其定义的常量不再存在? 最佳答案 三个答案:是的,使用ObjectSpace.此代码使c引用你的类(class)C不引用m:c=nilObjectSpace.each_object{|obj|c=objif(Class===objandobj.name=~/::C$/)}当然这取决于
我试图在一个项目中使用rake,如果我把所有东西都放到Rakefile中,它会很大并且很难读取/找到东西,所以我试着将每个命名空间放在lib/rake中它自己的文件中,我添加了这个到我的rake文件的顶部:Dir['#{File.dirname(__FILE__)}/lib/rake/*.rake'].map{|f|requiref}它加载文件没问题,但没有任务。我现在只有一个.rake文件作为测试,名为“servers.rake”,它看起来像这样:namespace:serverdotask:testdoputs"test"endend所以当我运行rakeserver:testid时
我的目标是转换表单输入,例如“100兆字节”或“1GB”,并将其转换为我可以存储在数据库中的文件大小(以千字节为单位)。目前,我有这个:defquota_convert@regex=/([0-9]+)(.*)s/@sizes=%w{kilobytemegabytegigabyte}m=self.quota.match(@regex)if@sizes.include?m[2]eval("self.quota=#{m[1]}.#{m[2]}")endend这有效,但前提是输入是倍数(“gigabytes”,而不是“gigabyte”)并且由于使用了eval看起来疯狂不安全。所以,功能正常,
我正在尝试使用ruby和Savon来使用网络服务。测试服务为http://www.webservicex.net/WS/WSDetails.aspx?WSID=9&CATID=2require'rubygems'require'savon'client=Savon::Client.new"http://www.webservicex.net/stockquote.asmx?WSDL"client.get_quotedo|soap|soap.body={:symbol=>"AAPL"}end返回SOAP异常。检查soap信封,在我看来soap请求没有正确的命名空间。任何人都可以建议我
关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭4年前。Improvethisquestion我想在固定时间创建一系列低音和高音调的哔哔声。例如:在150毫秒时发出高音调的蜂鸣声在151毫秒时发出低音调的蜂鸣声200毫秒时发出低音调的蜂鸣声250毫秒的高音调蜂鸣声有没有办法在Ruby或Python中做到这一点?我真的不在乎输出编码是什么(.wav、.mp3、.ogg等等),但我确实想创建一个输出文件。
Rails2.3可以选择随时使用RouteSet#add_configuration_file添加更多路由。是否可以在Rails3项目中做同样的事情? 最佳答案 在config/application.rb中:config.paths.config.routes在Rails3.2(也可能是Rails3.1)中,使用:config.paths["config/routes"] 关于ruby-on-rails-Rails3中的多个路由文件,我们在StackOverflow上找到一个类似的问题