[数据结构与算法]顺序表和链表
线性表(linear list)是n个具有相同特性的数据元素的有限序列。
线性表是一种在实际中广泛使用的数据结构,常见的线性表:顺序表、链表、栈、队列、字符串…
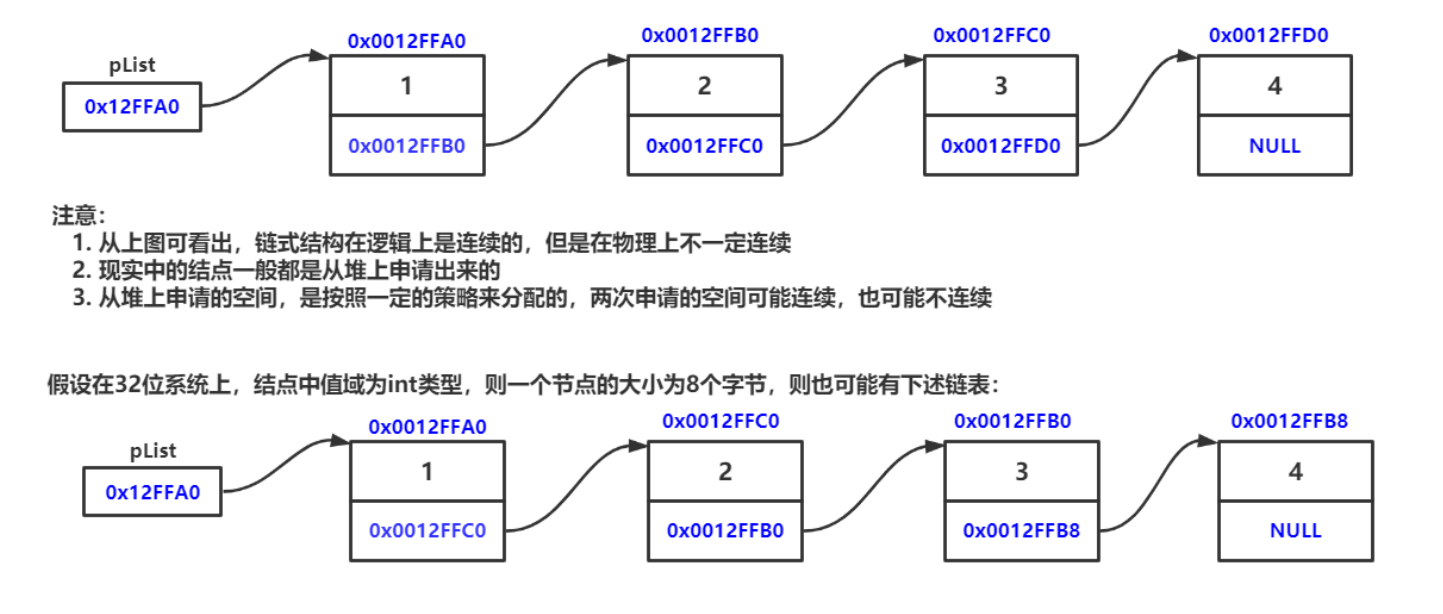
线性表在逻辑上是线性结构,也就说是连续的一条直线。但是在物理结构上并不一定是连续的,线性表在物理上存储时,通常以数组和链式结构的形式存储。
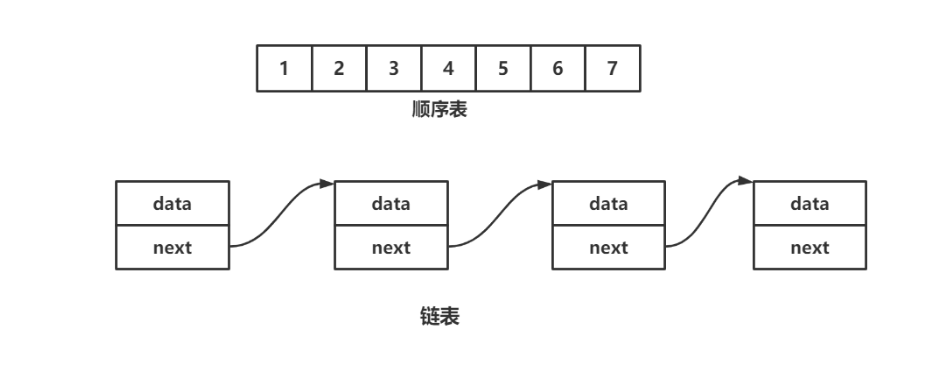
顺序表是用一段物理地址连续的存储单元依次存储数据元素的线性结构,一般情况下采用数组存储。在数组上完成数据的增删查改。
顺序表一般可以分为:静态顺序表和动态顺序表
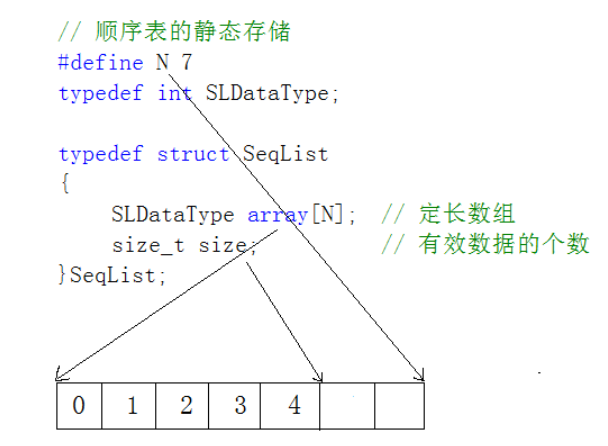
使用定长数组存储元素:
使用动态内存开辟的数组:
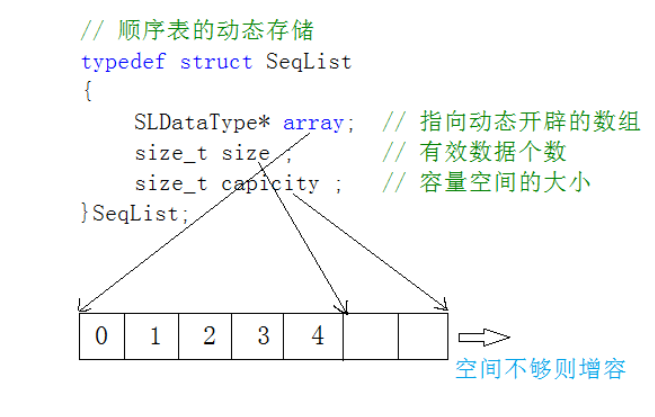
比较两种顺序表很容易做出选择,静态顺序表由于长度大小固定,必然存在内存不够用或者浪费的问题,所以通常我们讨论的顺序表也是动态表,下面就去实现动态顺序表的增删查改的各个函数接口。
以下是顺序表的接口实现:
typedef int SeqDataType;
typedef struct SeqList
{
SeqDataType* pc;//存放顺序表地址
int size;//有效数据个数
int capacity;//顺序表容量
}SeqList;
// 基本增删查改接口
// 顺序表初始化
void SeqListInit(SeqList* ps)
{
assert(ps);
ps->pc = (SeqDataType*)malloc(InitCapacity * sizeof(SeqDataType));
if (ps->pc == NULL)
{
perror("SeqListInit::");
return;
}
ps->size = 0;
ps->capacity = InitCapacity;
}
// 检查空间,如果满了,进行增容
void SeqListCheckCapacity(SeqList* ps)
{
assert(ps);
//容量已满
if (ps->size == ps->capacity)
{
//扩容两倍
SeqDataType* tmp=(SeqDataType*)realloc(ps->pc, (ps->capacity) * sizeof(SeqDataType) * 2);
if (tmp == NULL)
{
perror("SeqListCheckCapacity::");
return;
}
//printf("扩容成功\n");//测试
ps->pc = tmp;
ps->capacity *= 2;/*注意不要忘记调整容量*/
}
}
// 顺序表尾插
void SeqListPushBack(SeqList* ps, SeqDataType a)
{
assert(ps);
//SeqListCheckCapacity(ps);
ps->pc[ps->size] = a;
ps->size++;
//ps->pc[ps->size++] = a;
SeqListInsert(ps, ps->size, a);
}
// 顺序表尾删
void SeqListPopBack(SeqList* ps)
{
assert(ps);
if (ps->size != 0)
{
ps->pc[ps->size - 1] = 0;
ps->size--;
}
else
{
printf("error\n");//不要忘记判断有效数据size个数
}
}
// 顺序表头插
void SeqListPushFront(SeqList* ps,SeqDataType a)
{
assert(ps);
//SeqListCheckCapacity(ps);
//int end = ps->size - 1;
//while (end >= 0)
//{
// ps->pc[end + 1] = ps->pc[end];
// end--;
//}
//ps->pc[0] = a;
//ps->size++;/*不要忘记size*/
SeqListInsert(ps, 0, a);
}
// 顺序表头删
void SeqListPopFront(SeqList* ps)
{
assert(ps);
int begin = 0;
if (ps->size == 0)//判断数据有效
{
printf("error\n");
return;
}
while (begin < (ps->size - 1))
{
ps->pc[begin] = ps->pc[begin + 1];
begin++;
}
ps->size--;/*不要忘记size*/
}
// 顺序表查找
int SeqListFind(SeqList* ps, SeqDataType a)
{
assert(ps);
for (int i = 0; i < ps->size; i++)
{
if (ps->pc[i] == a)
{
return i;
}
}
return -1;
}
// 顺序表在pos位置插入x
void SeqListInsert(SeqList* ps, int pos, SeqDataType a)
{
assert(ps);
assert(pos >= 0 && pos <= ps->size);
SeqListCheckCapacity(ps);
int end = ps->size - 1;
while (end >= pos)
{
ps->pc[end + 1] = ps->pc[end];
end--;
}
ps->pc[pos] = a;
ps->size++;
}
// 顺序表删除pos位置的值
void SeqListErase(SeqList* ps, int pos)
{
assert(ps);
assert(pos >= 0 && pos < ps->size);
int end = ps->size - 1;
while (end >= pos)
{
ps->pc[pos] = ps->pc[pos+1];
pos++;
}
ps->size--;
}
// 顺序表销毁
void SeqListDestroy(SeqList* ps)
{
assert(ps);
ps->size = 0;
ps->capacity = 0;
free(ps->pc);
ps->pc = NULL;
}
// 顺序表打印
void SeqListPrint(SeqList* ps)
{
assert(ps);
for (int i = 0; i < ps->size; i++)
{
printf("%d ", ps->pc[i]);
}
}
概念:链表是一种物理存储结构上非连续、非顺序的存储结构,数据元素的逻辑顺序是通过链表中的指针链接次序实现的
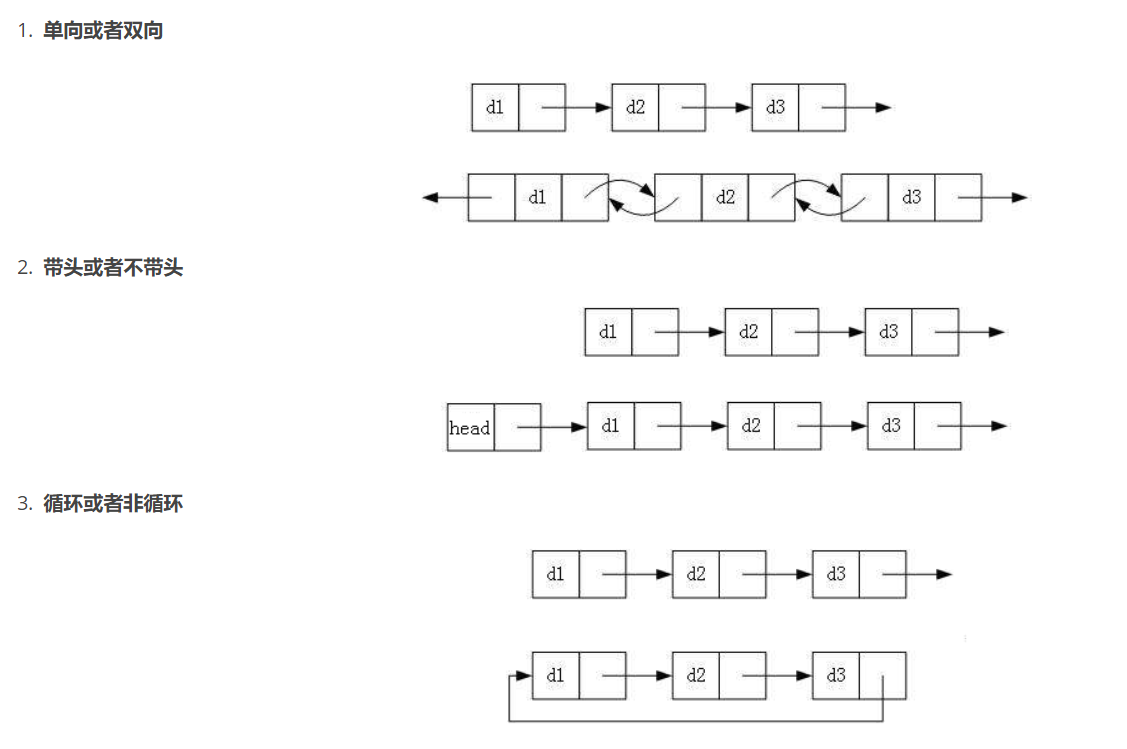
链表大致可以分为8种,看到8种虽然不少但是也没必要担心,实际上从笼统的角度来说,我个人更倾向于将链表分为2大类,一种是单链表,另一种是双向链表,其中占大头的是单链表,但是每种链表又可以分为多种(其实也就是在大体逻辑上添加了点东西重新起了一个名字罢了),只要掌握了链表的核心思想这些链表类别其实意义并不是很大,按照思路来写就可以了。
虽然种类有这么多,但是实际上我们最常用也就是最核心的两种:
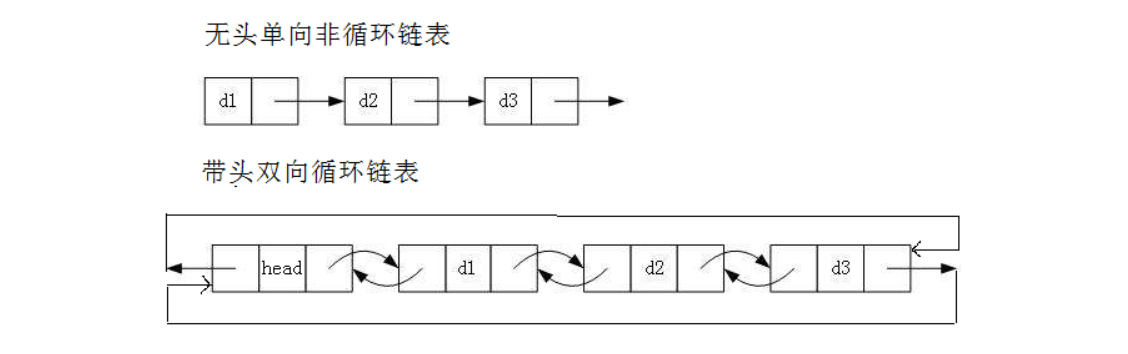
- 无头单向非循环链表:结构简单,一般不会单独用来存数据。实际中更多是作为其他数据结构的子结构,如哈希桶、图的邻接表等等。另外这种结构在笔试面试中出现很多。
- 带头双向循环链表:结构最复杂,一般用在单独存储数据。实际中使用的链表数据结构,都是带头双向循环链表。另外这个结构虽然结构复杂,但是使用代码实现以后会发现结构会带来很多优势,实现反而简单了,后面我们代码实现了就知道了。
单向链表其实就是这个
typedef int SLLDateType; typedef struct SLinkedList { SLLDateType date;//链表中每个结点的数据 struct SLinkedList* next;//下一个结点的地址 }SLinkedList; //开一个新结点 SLinkedList* BuyNewNode(SLLDateType x) { SLinkedList* newnode = (SLinkedList*)malloc(sizeof(SLinkedList)); if (newnode == NULL) { perror("BuyNewNode::"); return NULL; } newnode->date = x; newnode->next = NULL; return newnode; } //打印 void SLLPrint(SLinkedList* phead) { SLinkedList* cur = phead; while (cur) { printf("%d -> ", cur->date); cur = cur->next; } printf("NULL\n"); } //单链表尾插 void SLLPushBack(SLinkedList** pphead, SLLDateType x) { SLinkedList* newnode = BuyNewNode(x); //本身链表为空 if (*pphead==NULL) { *pphead = newnode; } else { //找尾 SLinkedList* cur = *pphead; while (cur->next != NULL) { cur = cur->next; } cur->next = newnode; } } //单链表头插 void SLLPushFront(SLinkedList** pphead,SLLDateType x) { SLinkedList* newnode = BuyNewNode(x); newnode->next = *pphead; *pphead = newnode; } //单链表尾删 void SLLPopBack(SLinkedList** pphead) { assert(*pphead);//链表为空 //单个结点 if ((*pphead)->next==NULL) { free(*pphead); *pphead = NULL; } else { //多个结点 SLinkedList* cur = *pphead; //SLinkedList* pre = *pphead; //找“尾” //while (cur->next) //{ // pre = cur; // cur = cur->next; //} //free(cur); //cur = NULL; //pre->next = NULL; /* 第二种写法 */ while (cur->next->next) { cur = cur->next; } free(cur->next); cur->next = NULL; } } //单链表头删 void SLLPopFront(SLinkedList** pphead) { assert(*pphead); SLinkedList* first = *pphead; *pphead = (*pphead)->next; free(first); first = NULL; } //单链表查找(找到返回位置也相当于修改) SLinkedList* SLLFind(SLinkedList* plist, SLLDateType x) { assert(plist); SLinkedList* cur = plist; while (cur) { while (cur->date != x) { cur = cur->next; } return cur; } return NULL; } //pos位置后插入 void SLLInsertAfter(SLinkedList* pos, SLLDateType x) { assert(pos); assert(pos->next); SLinkedList* newnode = BuyNewNode(x); newnode->next = pos->next; pos->next = newnode; } //pos位置后删除 void SLLPopAfter(SLinkedList* pos) { assert(pos); SLinkedList* del = pos->next; pos->next = pos->next->next; free(del); del = NULL; } //以下效率不高的两种方式--不推荐 //pos位置前插入 void SLLInsertFront(SLinkedList** pphead, SLinkedList* pos, SLLDateType x) { assert(pphead); if (pos == *pphead) { SLLPushFront(pphead,x); } else { SLinkedList* cur = *pphead; while (cur->next!=pos) { cur = cur->next; } SLinkedList* newnode = BuyNewNode(x); newnode->next = cur->next; cur->next = newnode; } } //pos位置删除 void SLLPopCurrent(SLinkedList** pphead, SLinkedList* pos) { assert(pphead); assert(pos); assert(*pphead); if (pos == *pphead) { SLLPopFront(pphead); } else { SLinkedList* cur = *pphead; while (cur->next != pos) { cur = cur->next; } SLinkedList* del = cur->next; cur->next = cur->next->next; free(del); del = NULL; } }单链表实际上并不适合在某个位置前面插入或删除,效率比较低,所以最后两种写法并不推荐,实际上在C++STL库中也是没有提供前插和前面删除。
一定程序上来说,其实双向链表是比单链表要简单的,例如在删除或者在pos位置前插入等多种情况时,如果是单链表每次都要从头开始去找到前一个节点,这点其实是非常麻烦的,但是双向循环链表则完美的解决了这个问题。
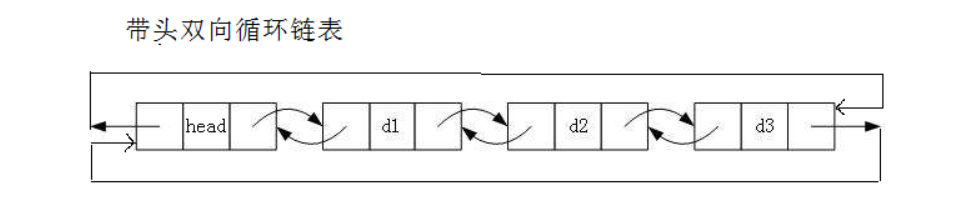
我们要实现的是这种带头双向循环的链表,如图所示:
在单向链表的基础上多一个指针,用来存储前一个位置的地址即可。
直接看接口实现:
typedef int DateType; typedef struct DListNode { struct DListNode* prev; struct DListNode* next; DateType date; }ListNode; //开一个新的节点 struct DListNode* BuyNewNode(DateType x) { ListNode* newnode = (ListNode*)malloc(sizeof(ListNode)); if (newnode == NULL) { perror("BuyNewNode fail\n"); //return NULL; exit(-1); } newnode->date = x; newnode->next = NULL; newnode->prev = NULL; return newnode; } //开头结点 struct DListNode* DLLInit() { ListNode* phead = BuyNewNode(-1); phead->next = phead; phead->prev = phead; return phead; } //检查链表是否为空 bool CheckEmpty(ListNode* head) { assert(head); /*if (head->next == head) return true; else return false;*/ return head->next == head; } //双向链表打印 void DLLPrint(ListNode* head) { assert(head); printf("<=head=>"); ListNode* cur = head->next; while (cur != head) { printf("%d<=>", cur->date); cur = cur->next; } printf("\n"); } //双向链表尾插 void DLLPushBack(ListNode* head,DateType x) { //ListNode* newnode = BuyNewNode(x); //ListNode* tail = head->prev; head tail newnode //tail->next = newnode; //newnode->prev = tail; //newnode->next = head; //head->prev = newnode; DLLInsert(head,x); } //双向链表头插 void DLLPuchFront(ListNode* head, DateType x) { //ListNode* newnode = BuyNewNode(x); //ListNode* cur = head->next; //cur->prev = newnode; //newnode->next = cur; //newnode->prev = head; //head->next = newnode; DLLInsert(head->next, x); } //双向链表尾删 void DLLPopBack(ListNode* head) { assert(head); assert(!CheckEmpty(head)); ListNode* tail = head->prev; ListNode* newtail = tail->prev; newtail->next = head; head->prev = newtail; free(tail); tail = NULL; } //双向链表头删 void DLLPopFront(ListNode* head) { assert(head); //判断链表是否为空 assert(!CheckEmpty(head)); ListNode* first = head->next; ListNode* sec = first->next; head->next = sec; sec->prev = head; free(first); first = NULL; } //双向链表查找 ListNode* DLLFind(ListNode* head, DateType x) { assert(head); ListNode* cur = head->next; while (cur != head) { if (cur->date == x) return cur; cur = cur->next; } return NULL; } //pos位置插入 void DLLInsert(ListNode* pos, DateType x) { assert(pos); ListNode* newnode = BuyNewNode(x); ListNode* prev = pos->prev; prev->next = newnode; newnode->next = pos; newnode->prev = prev; pos->prev = newnode; } //pos位置删除 void DLLErase(ListNode* pos) { assert(pos); ListNode* prev = pos->prev; ListNode* next = pos->next; prev->next = next; next->prev = prev; free(pos); pos = NULL; } //销毁 void DLLDestroy(ListNode* head) { assert(head); ListNode* cur = head->next; while (cur != head) { ListNode* next = cur->next; free(cur); cur = next; } free(head); }
| 不同点 | 顺序表 | 链表 |
|---|---|---|
| 存储空间上 | 物理上一定连续 | 逻辑上连续,但物理上不一定连续 |
| 随机访问 | 支持O(1) | 不支持:O(N) |
| 任意位置插入或者删除元素 | 可能需要搬移元素,效率低O(N) | 只需修改指针指向 |
| 插入 | 动态顺序表,空间不够时需要扩容 | 没有容量的概念 |
| 应用场景 | 元素高效存储+频繁访问 | 任意位置插入和删除频繁 |
| 缓存利用率 | 高 | 低 |
参考以上内容我们很容易就可以明白,顺序表和链表实际上是优势互补的关系,绝对不是哪一方绝对的优势,并且参考上图计算机内存的存储结构图我们还要学习一点知识,当然了仅仅是作为了解,毕竟这并不是数据结构学习的重点。
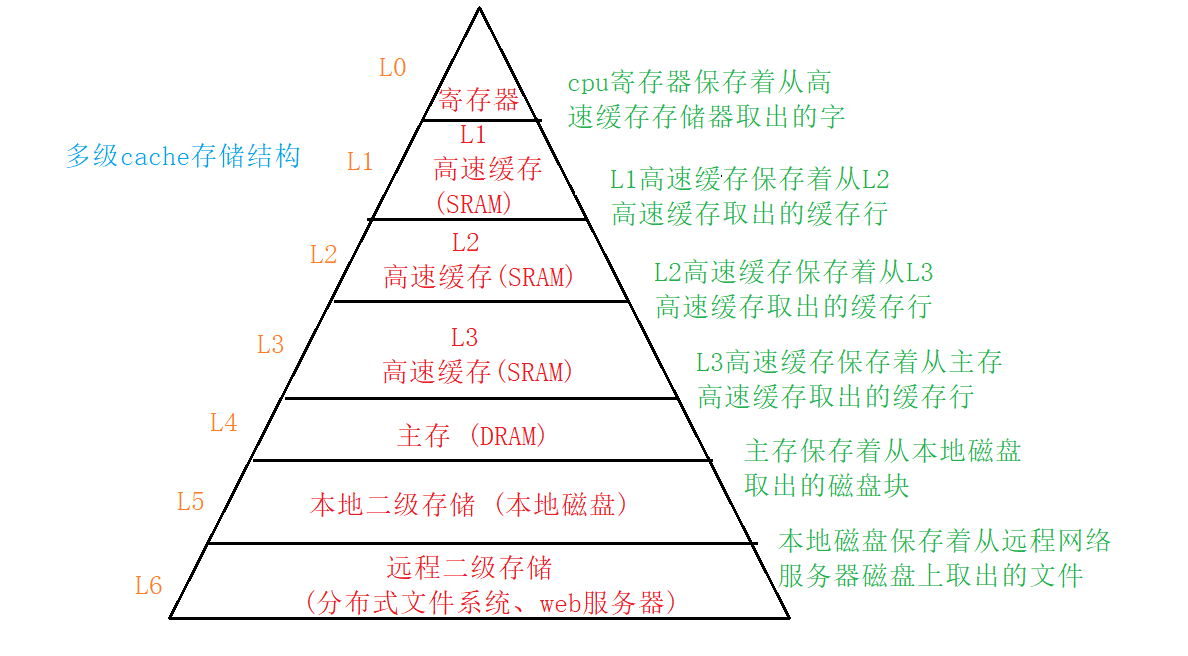
首先,我们要知道计算机存储的大致结构,如上图,大概有6个层级,其中主存和本地二级存储是我们日常最关心的,我们1通常说的内存8个G,内存16个G就是说的主存,而我们电脑的512G,1024G等等这些则是说的磁盘,或者硬盘,它的速度是比较慢的,所以造价也比较便宜,内存则更贵一些,再往上就是高速缓存区,由于CPU速度太快,通常是将内存中的数据加载到高速缓存区,然后再让CPU来读取,总之越靠近CPU的介质则速度越快,造价也就越高,所以你应该就能想明白为什么百度网盘什么的上来新用户送你1个T了吧,单纯是因为便宜。
这些计算机组成原理的知识其实是比较复杂的,我们这里就简单通俗的解释一下,更加详细的内容就到计组的时候再聊。
- 程序访问的局部性:在一个较短的时间间隔内,由程序产生的地址往往集中在存储器逻辑地址空间的很小范围内,这种对局部范围的存储器地址频繁访问,而对此范围以外的地址则访问甚少的一种现象。
- 程序访问的局部性原理和Cache的关系:利用程序访问的局部性原理,可以在主存和CPU的通用寄存器之间设置Cache,把正在执行的指令地址附近的一部分指令或数据从主存调入这个寄存器,供CPU在一段时间内使用,从而提高CPU访问存储系统的速度。当程序继续执行时,程序访问的局部性原理也不断变化,新的数据将不断地从主存调入Cache中替换掉原有的数据。
上面看不懂也没有关系,简单点来说就是在加载数据的时候,通常来说我们马上也要访问这些数据的下一个或者相邻的数据的,所以每次只加载一些需要的数据过去立马又得重新再加载相邻的数据,这样看起来就不太划算,所以通常在加载数据时,就会将你所需要的数据相邻的一些数据也一起加载过去,这也就是局部性原理的解释。
关于命中的概念,通俗上来说就是CPU在高速缓存区去读取数据,如果数据每加载一次读到了,就叫做命中;每一次加载没有读到,则叫做不命中。
关于CPU在Cache结构中的读取数据的问题,也是个头疼且复杂的问题,就不再多解释了,这里推荐一篇博客,计算机组成原理 Cache超仔细详解,关于命中的详细流程,命中率的计算等等一些其他Cache的知识也有详细解释。
不多说了,计算机组成原理真的是一门无比痛苦的课。
从以上就很容易看出,在缓存利用率方面,顺序表由于内存是连续的,而链表是一个个单个的节点连起来的,顺序表的命中率绝对要比链表高不少,但是链表又要比顺序表要灵活不少,到这里我相信你就能理解为什么说所以这两种结构是优势互补的关系了,具体使用哪种结构,当然还是要根据具体场景去抉择了,好了这篇博客到这里就结束了,多多点赞支持哦!!
我想将html转换为纯文本。不过,我不想只删除标签,我想智能地保留尽可能多的格式。为插入换行符标签,检测段落并格式化它们等。输入非常简单,通常是格式良好的html(不是整个文档,只是一堆内容,通常没有anchor或图像)。我可以将几个正则表达式放在一起,让我达到80%,但我认为可能有一些现有的解决方案更智能。 最佳答案 首先,不要尝试为此使用正则表达式。很有可能你会想出一个脆弱/脆弱的解决方案,它会随着HTML的变化而崩溃,或者很难管理和维护。您可以使用Nokogiri快速解析HTML并提取文本:require'nokogiri'h
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
我遵循了教程http://gettingstartedwithchef.com/,第1章。我的运行list是"run_list":["recipe[apt]","recipe[phpap]"]我的phpapRecipe默认Recipeinclude_recipe"apache2"include_recipe"build-essential"include_recipe"openssl"include_recipe"mysql::client"include_recipe"mysql::server"include_recipe"php"include_recipe"php::modul
有时我需要处理键/值数据。我不喜欢使用数组,因为它们在大小上没有限制(很容易不小心添加超过2个项目,而且您最终需要稍后验证大小)。此外,0和1的索引变成了魔数(MagicNumber),并且在传达含义方面做得很差(“当我说0时,我的意思是head...”)。散列也不合适,因为可能会不小心添加额外的条目。我写了下面的类来解决这个问题:classPairattr_accessor:head,:taildefinitialize(h,t)@head,@tail=h,tendend它工作得很好并且解决了问题,但我很想知道:Ruby标准库是否已经带有这样一个类? 最佳
给定一个复杂的对象层次结构,幸运的是它不包含循环引用,我如何实现支持各种格式的序列化?我不是来讨论实际实现的。相反,我正在寻找可能会派上用场的设计模式提示。更准确地说:我正在使用Ruby,我想解析XML和JSON数据以构建复杂的对象层次结构。此外,应该可以将该层次结构序列化为JSON、XML和可能的HTML。我可以为此使用Builder模式吗?在任何提到的情况下,我都有某种结构化数据-无论是在内存中还是文本中-我想用它来构建其他东西。我认为将序列化逻辑与实际业务逻辑分开会很好,这样我以后就可以轻松支持多种XML格式。 最佳答案 我最
我正在尝试使用Curbgem执行以下POST以解析云curl-XPOST\-H"X-Parse-Application-Id:PARSE_APP_ID"\-H"X-Parse-REST-API-Key:PARSE_API_KEY"\-H"Content-Type:image/jpeg"\--data-binary'@myPicture.jpg'\https://api.parse.com/1/files/pic.jpg用这个:curl=Curl::Easy.new("https://api.parse.com/1/files/lion.jpg")curl.multipart_form_
无论您是想搭建桌面端、WEB端或者移动端APP应用,HOOPSPlatform组件都可以为您提供弹性的3D集成架构,同时,由工业领域3D技术专家组成的HOOPS技术团队也能为您提供技术支持服务。如果您的客户期望有一种在多个平台(桌面/WEB/APP,而且某些客户端是“瘦”客户端)快速、方便地将数据接入到3D应用系统的解决方案,并且当访问数据时,在各个平台上的性能和用户体验保持一致,HOOPSPlatform将帮助您完成。利用HOOPSPlatform,您可以开发在任何环境下的3D基础应用架构。HOOPSPlatform可以帮您打造3D创新型产品,HOOPSSDK包含的技术有:快速且准确的CAD
目录一.加解密算法数字签名对称加密DES(DataEncryptionStandard)3DES(TripleDES)AES(AdvancedEncryptionStandard)RSA加密法DSA(DigitalSignatureAlgorithm)ECC(EllipticCurvesCryptography)非对称加密签名与加密过程非对称加密的应用对称加密与非对称加密的结合二.数字证书图解一.加解密算法加密简单而言就是通过一种算法将明文信息转换成密文信息,信息的的接收方能够通过密钥对密文信息进行解密获得明文信息的过程。根据加解密的密钥是否相同,算法可以分为对称加密、非对称加密、对称加密和非
本教程将在Unity3D中混合Optitrack与数据手套的数据流,在人体运动的基础上,添加双手手指部分的运动。双手手背的角度仍由Optitrack提供,数据手套提供双手手指的角度。 01 客户端软件分别安装MotiveBody与MotionVenus并校准人体与数据手套。MotiveBodyMotionVenus数据手套使用、校准流程参照:https://gitee.com/foheart_1/foheart-h1-data-summary.git02 数据转发打开MotiveBody软件的Streaming,开始向Unity3D广播数据;MotionVenus中设置->选项选择Unit
文章目录一、概述简介原理模块二、配置Mysql使用版本环境要求1.操作系统2.mysql要求三、配置canal-server离线下载在线下载上传解压修改配置单机配置集群配置分库分表配置1.修改全局配置2.实例配置垂直分库水平分库3.修改group-instance.xml4.启动监听四、配置canal-adapter1修改启动配置2配置映射文件3启动ES数据同步查询所有订阅同步数据同步开关启动4.验证五、配置canal-admin一、概述简介canal是Alibaba旗下的一款开源项目,Java开发。基于数据库增量日志解析,提供增量数据订阅&消费。Git地址:https://github.co