场景将提供一台配置了CentOS 8.5操作系统的ECS实例(云服务器)。通过本教程的操作带您体验如何将PolarDB-X通过Canal与ClickHouse进行互通,搭建一个实时分析系统。点击前往

1. 创建实验资源
开始实验之前,您需要先创建ECS实例资源。
在实验室页面,单击创建资源。
(可选)在实验室页面左侧导航栏中,单击云产品资源列表,可查看本次实验资源相关信息(例如IP地址、用户信息等)。
说明 :资源创建过程需要1~3分钟。
2. 安装PolarDB-X
本步骤将指导您如何安装PolarDB-X。
(1) 执行如下命令,安装Docker。
curl -fsSL https://get.docker.com | bash -s docker --mirror Aliyun
(2) 执行如下命令,启动Docker。
systemctl start docker
docker run -d --name some-polardb-x -p 8527:8527 polardbx/polardb-x:2.1.0
3. 登录PolarDB-X数据库
本步骤将指导您如何登录PolarDB-X数据库。
PolarDB-X支持通过MySQL Client命令行、第三方客户端以及符合MySQL交互协议的第三方程序代码进行连接。本实验场景主要介绍如何通过MySQL Client命令行连接到PolarDB-X数据库。
yum install mysql -y
mysql -V
返回结果如下,表示您已成功安装MySQL。

说明:
本实验场景中的PolarDB-X数据库用户名和密码已预设,请您使用下方命令登录即可。
如遇到mysql: [Warning] Using a password on the command line interface can be insecure.ERROR 2013 (HY000): Lost connection to MySQL server at 'reading initial communication packet', system error: 0报错,请您稍等一分钟,重新执行登录命令即可。
mysql -h127.0.0.1 -P8527 -upolardbx_root -p123456
返回结果如下,表示您已成功登录PolarDB-X数据库。
4. 搭建实时分析系统
本步骤将指导您如何使用PolarDB-X+Canal+ClickHouse搭建实时分析系统。
Canal是一款流行的MySQL Binlog增量订阅工具,详情请参见Canal说明文档。Canal提供了Docker镜像,详情请参见Canal Docker镜像文档。
(1) 执行如下命令,下载脚本。
wget https://raw.githubusercontent.com/alibaba/canal/master/docker/run.sh
(2) 执行如下命令,构建一个destination name为test的队列。
注意 :您需要将none_loopback_host_ip修改为云产品资源列表中的ECS的弹性IP,请勿使用localhost或127.0.0.1。
sh run.sh -e canal.auto.scan=false \
-e canal.destinations=test \
-e canal.instance.master.address=none_loopback_host_ip:8527 \
-e canal.instance.dbUsername=polardbx_root \
-e canal.instance.dbPassword=123456 \
-e canal.instance.connectionCharset=UTF-8 \
-e canal.instance.tsdb.enable=true \
-e canal.instance.gtidon=false
ClickHouse是一款分析系统,详情请参见ClickHouse官方文档。ClickHouse提供了Docker镜像,详情请参见ClickHouseDocker镜像文档。
执行如下命令,部署ClickHouse。
docker run -d --name some-clickhouse-server --ulimit nofile=262144:262144 -p 8123:8123 yandex/clickhouse-server
(1) 执行如下命令,登录PolarDB-X数据库。
mysql -h127.0.0.1 -P8527 -upolardbx_root -p123456
(2) 执行如下SQL语句,创建数据库testdb。
CREATE DATABASE testdb;
(3) 执行如下SQL语句,使用数据库testdb。
USE testdb;
(4) 执行如下SQL语句,创建test表。
CREATE TABLE test(
id INT(11) AUTO_INCREMENT PRIMARY KEY,
name CHAR(20) not null );
(5) 输入exit退出数据库。
(6) 执行如下命令,登录ClickHouse数据库。
docker run -it --rm --link some-clickhouse-server:clickhouse-server yandex/clickhouse-client --host clickhouse-server
(7) 执行如下SQL语句,创建数据库testdb。
CREATE DATABASE testdb;
(8) 执行如下SQL语句,使用数据库testdb。
USE testdb;
(9) 执行如下SQL语句,创建test表。
Create Table test(id INT(32),name CHAR(20)) Engine = MergeTree() Order By id;
(10) 输入exit退出数据库。
经过以上步骤,您已经准备好了PolarDB-X、Canal Server和ClickHouse三个容器,并且在源端(PolarDB-X)和目标端(ClickHouse)建好了测试用的数据库和表。接下来我们通过Canal Client消费Canal Server获取的增量数据,并将源端DML中的Insert事件投递到ClickHouse中。
(1) 执行如下命令,使用yum安装JDK 1.8。
yum -y install java-1.8.0-openjdk*
(2) 执行如下命令,下载polardb-x-to-clickhouse-canal-client.jar投递代码文件。
wget https://labfileapp.oss-cn-hangzhou.aliyuncs.com/polardb-x-to-clickhouse-canal-client.jar
(3) 执行如下命令,运行polardb-x-to-clickhouse-canal-client.jar代码文件。
java -jar polardb-x-to-clickhouse-canal-client.jar
注意:请勿中断投递代码文件,否则会造成投递失败。
(4) 投递链路已成功打通,接下来您可以在源端(PolarDB-X)执行INSERT语句,并观察目标端(ClickHouse)中的数据变化。
在实验页面,单击右上角的 图标,创建新的终端窗口。
图标,创建新的终端窗口。

(5) 在新的终端窗口中,执行如下命令,登录PolarDB-X数据库。
mysql -h127.0.0.1 -P8527 -upolardbx_root -p123456
(6) 执行如下SQL语句,使用数据库testdb。
USE testdb;
(7) 执行如下SQL语句,插入一条数据。
INSERT INTO test(name) values("polardb-x"), ("is"), ("awsome");
(8) 输入exit退出数据库。
(9) 执行如下命令,登录ClickHouse数据库。
docker run -it --rm --link some-clickhouse-server:clickhouse-server yandex/clickhouse-client --host clickhouse-server
(10) 执行如下SQL语句,使用数据库testdb。
USE testdb;
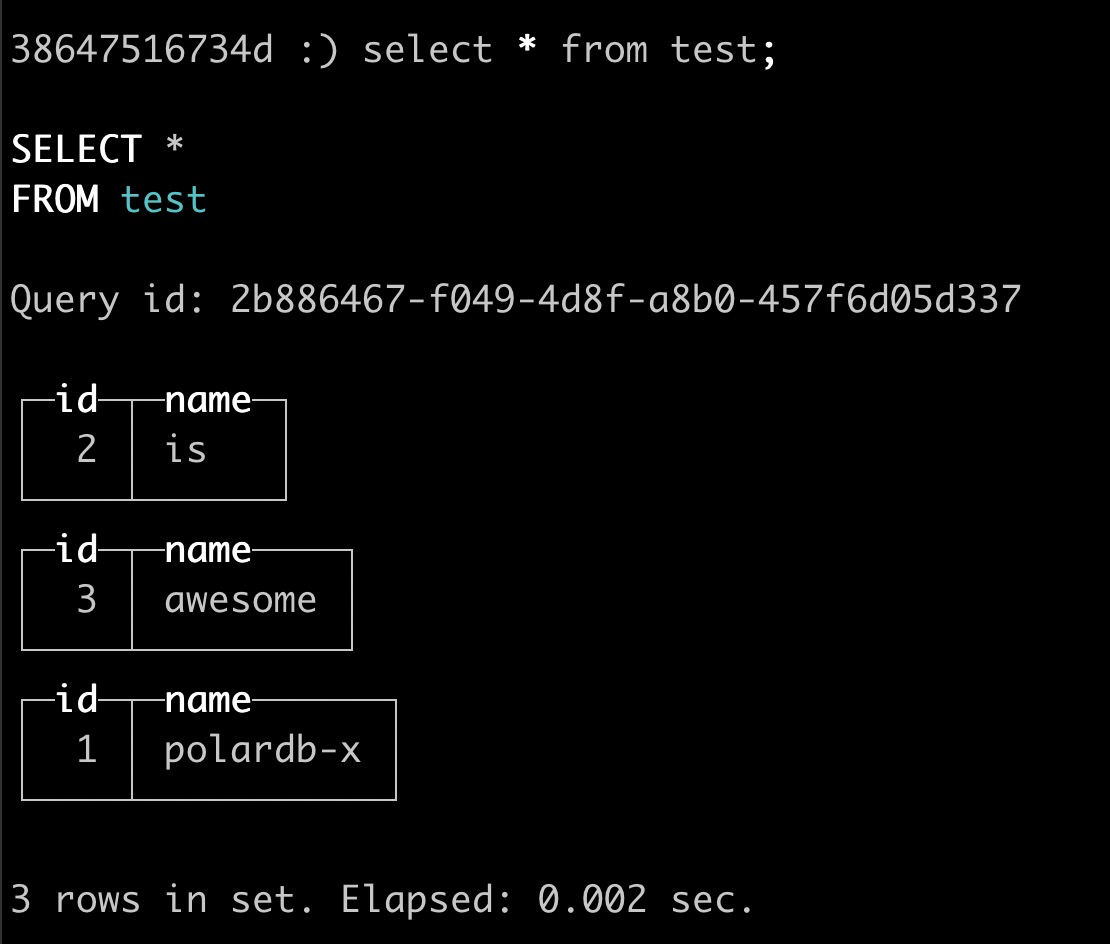
(11) 执行如下SQL语句,查询test表
SELECT * FROM test;
返回结果如下,您可以看到目标端(ClickHouse)接收到投递过来的数据。
5. 了解更多
如果您想了解更多有关PolarDB-X分布式事务实现原理,详情请参见PolarDB-X分布式事务实现原理(一)。
如果您想了解更多有关PolarDB-X全局Binlog解读,详情请参见PolarDB-X全局Binlog解读。
如果您想了解更多有关PolarDB-X全局Binlog解读之DDL,详情请参见PolarDB-X全局 Binlog解读之DDL。
恭喜完成
我正在学习如何使用Nokogiri,根据这段代码我遇到了一些问题:require'rubygems'require'mechanize'post_agent=WWW::Mechanize.newpost_page=post_agent.get('http://www.vbulletin.org/forum/showthread.php?t=230708')puts"\nabsolutepathwithtbodygivesnil"putspost_page.parser.xpath('/html/body/div/div/div/div/div/table/tbody/tr/td/div
总的来说,我对ruby还比较陌生,我正在为我正在创建的对象编写一些rspec测试用例。许多测试用例都非常基础,我只是想确保正确填充和返回值。我想知道是否有办法使用循环结构来执行此操作。不必为我要测试的每个方法都设置一个assertEquals。例如:describeitem,"TestingtheItem"doit"willhaveanullvaluetostart"doitem=Item.new#HereIcoulddotheitem.name.shouldbe_nil#thenIcoulddoitem.category.shouldbe_nilendend但我想要一些方法来使用
关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭4年前。Improvethisquestion我想在固定时间创建一系列低音和高音调的哔哔声。例如:在150毫秒时发出高音调的蜂鸣声在151毫秒时发出低音调的蜂鸣声200毫秒时发出低音调的蜂鸣声250毫秒的高音调蜂鸣声有没有办法在Ruby或Python中做到这一点?我真的不在乎输出编码是什么(.wav、.mp3、.ogg等等),但我确实想创建一个输出文件。
给定这段代码defcreate@upgrades=User.update_all(["role=?","upgraded"],:id=>params[:upgrade])redirect_toadmin_upgrades_path,:notice=>"Successfullyupgradeduser."end我如何在该操作中实际验证它们是否已保存或未重定向到适当的页面和消息? 最佳答案 在Rails3中,update_all不返回任何有意义的信息,除了已更新的记录数(这可能取决于您的DBMS是否返回该信息)。http://ar.ru
我在我的项目目录中完成了compasscreate.和compassinitrails。几个问题:我已将我的.sass文件放在public/stylesheets中。这是放置它们的正确位置吗?当我运行compasswatch时,它不会自动编译这些.sass文件。我必须手动指定文件:compasswatchpublic/stylesheets/myfile.sass等。如何让它自动运行?文件ie.css、print.css和screen.css已放在stylesheets/compiled。如何在编译后不让它们重新出现的情况下删除它们?我自己编译的.sass文件编译成compiled/t
我正在寻找执行以下操作的正确语法(在Perl、Shell或Ruby中):#variabletoaccessthedatalinesappendedasafileEND_OF_SCRIPT_MARKERrawdatastartshereanditcontinues. 最佳答案 Perl用__DATA__做这个:#!/usr/bin/perlusestrict;usewarnings;while(){print;}__DATA__Texttoprintgoeshere 关于ruby-如何将脚
Rackup通过Rack的默认处理程序成功运行任何Rack应用程序。例如:classRackAppdefcall(environment)['200',{'Content-Type'=>'text/html'},["Helloworld"]]endendrunRackApp.new但是当最后一行更改为使用Rack的内置CGI处理程序时,rackup给出“NoMethodErrorat/undefinedmethod`call'fornil:NilClass”:Rack::Handler::CGI.runRackApp.newRack的其他内置处理程序也提出了同样的反对意见。例如Rack
在选择我想要运行操作的频率时,唯一的选项是“每天”、“每小时”和“每10分钟”。谢谢!我想为我的Rails3.1应用程序运行调度程序。 最佳答案 这不是一个优雅的解决方案,但您可以安排它每天运行,并在实际开始工作之前检查日期是否为当月的第一天。 关于ruby-如何每月在Heroku运行一次Scheduler插件?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/8692687/
我有一个对象has_many应呈现为xml的子对象。这不是问题。我的问题是我创建了一个Hash包含此数据,就像解析器需要它一样。但是rails自动将整个文件包含在.........我需要摆脱type="array"和我该如何处理?我没有在文档中找到任何内容。 最佳答案 我遇到了同样的问题;这是我的XML:我在用这个:entries.to_xml将散列数据转换为XML,但这会将条目的数据包装到中所以我修改了:entries.to_xml(root:"Contacts")但这仍然将转换后的XML包装在“联系人”中,将我的XML代码修改为
我有一大串格式化数据(例如JSON),我想使用Psychinruby同时保留格式转储到YAML。基本上,我希望JSON使用literalstyle出现在YAML中:---json:|{"page":1,"results":["item","another"],"total_pages":0}但是,当我使用YAML.dump时,它不使用文字样式。我得到这样的东西:---json:!"{\n\"page\":1,\n\"results\":[\n\"item\",\"another\"\n],\n\"total_pages\":0\n}\n"我如何告诉Psych以想要的样式转储标量?解