文章目录
黏菌算法由李世民等人发表于2020年,模拟了黏菌觅食过程中的行为和形态变化。
黏菌在有丝分裂后形成的变形体成熟之后,进入营养生长时期,会形成网状型态,且依照食物、水与氧气等所需养分改变其表面积。在黏菌算法中,黏菌会根据当前位置的客观条件(适应度函数优劣),决定每个个体所在位置的权重,然后个体会根据权重决定新的位置在哪。
当黏菌接近食物源时,生物振荡器会通过静脉产生传播波,来增加细胞质流量。食物浓度越高,生物振荡器产生的传播波越强,细胞质流动越快。黏菌算法就是通过模拟黏菌这种捕食行为来实现智能寻优功能的。
借鉴黏菌的生物行为,可以抽象出三个规则:
更新个体位置这一步模拟了黏菌的生物行为:利用生物振荡器产生的传播波改变静脉中的细胞质流动速度。
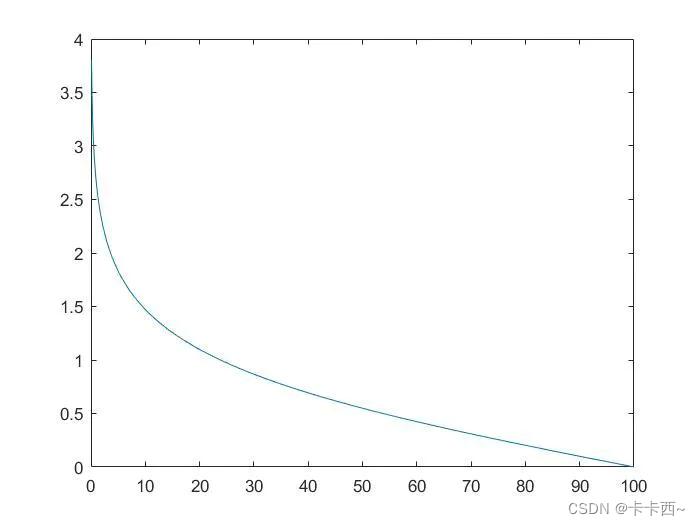
算法是这样模拟的:通过vb,vc,W来模拟静脉宽度的变化和振荡器振荡频率变化,当食物浓度低时,慢慢接近食物,扩大全局搜索能力,当找到优质食物时,迅速接近食物,加强局部搜索能力。
公式解读:第一个子公式获取的是全局随机位置,类似于GA中的变异操作;第二个是在当前最优位置的附近搜索,类似于局部搜索;第三个没看懂,好像会让个体最优值能收敛到0,当最优解不为0时效果不好。
参数说明表:
| 符号 | 含义 | 符号 | 含义 |
|---|---|---|---|
| W | 黏菌重量 | a,p | 一个参数 |
| r | 随机数[0,1] | S(i) | 第i个黏菌个体的适应度值 |
| bF | 当前迭代中最优适应度值 | wF | 当前迭代中最差适应度值 |
| t | 当前迭代次数 | T | 最大迭代次数 |
| vb | 随机数[-a,a] | vc | 随机数[-b,b] |
| DF | 所有迭代中的最优适应度值 | N | 黏菌的种群规模 |
| ub | 搜索空间的上界 | lb | 搜索空间的下界 |
| X ( t ) X(t) X(t) | 第t次迭代时黏菌的位置 | X b ( t ) X_b(t) Xb(t) | 第t次迭代时的最佳位置 |
| X A ( t ) , X B ( t ) X_A(t),X_B(t) XA(t),XB(t) | 第t次迭代时随机选择的两个黏菌个体 | z | 随机分布的黏菌个体占总体的比例 |
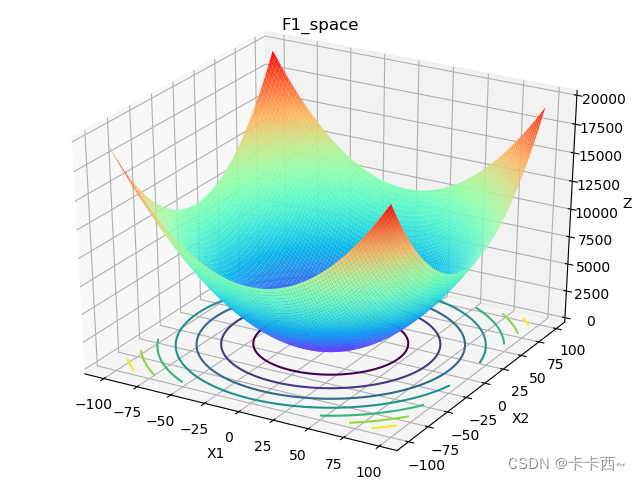
求解下列函数的最小值:
f
(
x
1
,
x
2
)
=
x
1
2
+
x
2
2
f(x_1,x_2)=x_1^2+x_2^2
f(x1,x2)=x12+x22
标准答案是0,函数长这个样子:
主函数:
import numpy as np
from matplotlib import pyplot as plt
import SMA
'''适应度函数'''
def fun(X):
Results = np.sum(X ** 2)
return Results
'''主函数 '''
# 设置参数
pop = 30 # 种群数量
MaxIter = 500 # 最大迭代次数
dim = 2 # 维度
lb = -10 * np.ones(dim) # 下边界
ub = 10 * np.ones(dim) # 上边界
# 调用SMA算法
GbestScore, GbestPositon, Curve = SMA.SMA(pop, dim, lb, ub, MaxIter, fun)
print('最优适应度值:', GbestScore)
print('最优解[x1,x2]:', GbestPositon)
# 绘制适应度曲线
plt.figure(1)
plt.plot(Curve, 'r-', linewidth=2)
plt.xlabel('Iteration', fontsize='medium')
plt.ylabel("Fitness", fontsize='medium')
plt.grid()
plt.title('SMA', fontsize='large')
plt.show()
SMA.py:
import numpy as np
import copy as copy
'''黏菌优化算法'''
'''
Args:
pop: 种群数量
dim: 个体维度
lb: 下边界,维度[1,dim]
ub: 上边界,维度[1,dim]
MaxIter: 最大迭代次数
fun: 适应度函数接口
Returns:
GbestScore: 最优解对应的适应度值
GbestPositon: 最优解
Curve: 画迭代曲线用的
'''
def SMA(pop, dim, lb, ub, MaxIter, fun):
# 1.设置参数,初始化种群,并计算适应度值
# 设置参数
z = 0.03 # 一个参数,更新个体位置时用,表示随机分布的黏菌个体占总体的比例
Curve = np.zeros([MaxIter, 1]) # 画迭代图用
W = np.zeros([pop, dim]) # 黏菌权重
# 初始化种群
X = initialization(pop, ub, lb, dim)
# 计算适应度值
fitness = CaculateFitness(X, fun) # 计算适应度值
fitness, sortIndex = SortFitness(fitness) # 对适应度值排序
X = SortPosition(X, sortIndex) # 种群排序
GbestScore = copy.copy(fitness[0])
GbestPositon = copy.copy(X[0, :])
for t in range(MaxIter):
worstFitness = fitness[-1]
bestFitness = fitness[0]
S = bestFitness - worstFitness + 10E-8 # 当前最优与最差适应度的差值,算权重W用,10E-8为极小值,避免分母为0;
# 2.更新权重W和参数a、参数b
# 权重W
for i in range(pop):
if i < pop / 2: # 适应度值排前一半的W计算
W[i, :] = 1 + np.random.random([1, dim]) * np.log10((bestFitness - fitness[i]) / (S) + 1 + 10E-8)
else: # 适应度值排后一半的W计算
W[i, :] = 1 - np.random.random([1, dim]) * np.log10((bestFitness - fitness[i]) / (S) + 1 + 10E-8)
# 参数b
b = 1 - (t / MaxIter)
# 参数a
if b != -1 and b != 1:
a = np.math.atanh(b)
else:
a = 1
# 3.位置更新,分三种情况
for i in range(pop):
# 3.1如果r<z,按第一个子公式更新位置
if np.random.random() < z:
X[i, :] = (ub.T - lb.T) * np.random.random([1, dim]) + lb.T
# 否则,更新参数p,vb,vc,继续判断
else:
p = np.tanh(abs(fitness[i] - GbestScore))
vb = 2 * a * np.random.random([1, dim]) - a
vc = 2 * b * np.random.random([1, dim]) - b
for j in range(dim):
r = np.random.random()
A = np.random.randint(pop) # 随机选择两个黏菌个体
B = np.random.randint(pop)
# 3.2如果r<p,按第二个子公式更新位置
if r < p:
X[i, j] = GbestPositon[j] + vb[0, j] * (W[i, j] * X[A, j] - X[B, j])
# 3.3按第三个子公式更新位置
else:
X[i, j] = vc[0, j] * X[i, j]
X = BorderCheck(X, ub, lb, pop, dim) # 边界检查
fitness = CaculateFitness(X, fun) # 计算适应度值
fitness, sortIndex = SortFitness(fitness) # 对适应度值排序,得到排好序的适应度值和对应的索引
X = SortPosition(X, sortIndex) # 根据排好序的索引对种群排序
if (fitness[0] <= GbestScore): # 更新全局最优
GbestScore = copy.copy(fitness[0])
GbestPositon = copy.copy(X[0, :])
Curve[t] = GbestScore
return GbestScore, GbestPositon, Curve
运行结果:
最优适应度值: [6.28823104e-226]
最优解: [[-1.77578646e-113 1.77054045e-113]]
可以看到答案非常接近最优适应度值0。
集思广益:
| 文献 | 改进策略 |
|---|---|
| Shimin Li, Huiling Chen, Mingjing Wang, Ali Asghar Heidari,Seyedali Mirjalili.Slime mould algorithm: A new method for stochastic optimization,Future Generation Computer Systems,2020(111),300-323 | 原论文 |
| 网站 | 改进了p的更新公式,位置更新公式的第三个子公式 |
| 郭雨鑫,刘升,张磊,黄倩.精英反向与二次插值改进的黏菌算法[J].计算机应用研究,2021,38(12):3651-3656. | 精英反向学习,二次插值 |
| 刘宇凇,刘升.无迹西格玛点引导的拟反向黏菌算法及其工程应用[J/OL].计算机应用研究:1-9[2022-10-17]. | 布朗运动,莱维飞行机制 |
| Improved slime mould algorithm with elitist strategy and its application to structural optimization with natural frequency constraints,IEEE | 精英替换策略 |
| Dispersed foraging slime mould algorithm: Continuous and binary variants for global optimization and wrapper-based feature selection | 分散觅食策略 |
| Multilevel threshold image segmentation with diffusion association slime mould algorithm and Renyi’s entropy for chronic obstructive pulmonary disease | 扩散机制DM,关联策略AS |
| 张启明. 面向云计算任务调度的混合智能算法的研究[D].桂林理工大学,2022. | Logistic混沌映射,差分进化 |
| A novel version of slime mould algorithm for global optimization and real world engineering problems: Enhanced slime mould algorithm. | sigmoid代替arctanh |
| 文献 | 融合的智能优化算法 |
|---|---|
| 任丽莉,王志军,闫冬梅.结合黏菌觅食行为的改进多元宇宙算法[J].吉林大学学报(工学版),2021,51(06):2190-2197. | 多元宇宙算法MVO |
| 贾鹤鸣,刘宇翔,刘庆鑫,王爽,郑荣.融合随机反向学习的黏菌与算术混合优化算法[J].计算机科学与探索,2022,16(05):1182-1192. | 算术优化算法AOA |
| 刘成汉,何庆.改进交叉算子的自适应人工蜂群黏菌算法[J/OL].小型微型计算机系统:1-8[2022-10-17]. // An efficient multilevel thresholding image segmentation method based on the slime mould algorithm with bee foraging mechanism: A real case with lupus nephritis images | 人工蜂群ABC |
| 郑旸,龙英文,吉明明,顾嘉城.融合螺旋黏菌算法的混沌麻雀搜索算法与应用[J/OL].计算机工程与应用:1-11[2022-10-17]. | 麻雀搜索SSA |
| 翟青海,谢晓兰.混合云环境下考虑工作流的任务调度策略[J].桂林理工大学学报,2021,41(04):891-896. | 粒子群PSO |
| 刘磊. 基于群智能优化的多阈值图像分割方法研究及应用[D].长春师范大学,2022. // 张启明. 面向云计算任务调度的混合智能算法的研究[D].桂林理工大学,2022. // Performance optimization of differential evolution with slime mould algorithm for multilevel breast cancer image segmentation | 差分进化 |
| A novel version of slime mould algorithm for global optimization and real world engineering problems: Enhanced slime mould algorithm. | 正余弦算法SCA |
| Gradient-based optimizer improved by Slime Mould Algorithm for global optimization and feature selection for diverse computation problems | 基于梯度的优化算法 |
| An entropy minimization based multilevel colour thresholding technique for analysis of breast thermograms using equilibrium slime mould algorithm | 平衡算法EO |
| HSMA_WOA: A hybrid novel Slime mould algorithm with whale optimization algorithm for tackling the image segmentation problem of chest X-ray images | 鲸鱼优化算法 |
| LSMA-TLBO: A hybrid SMA-TLBO algorithm with lévy flight based mutation for numerical optimization and engineering design problems | 教与学TLBO |
| Towards augmented kernel extreme learning models for bankruptcy prediction: Algorithmic behavior and comprehensive analysis | 果蝇算法FOA |
| 文献 | 应用 |
|---|---|
| 高铖铖,陈锡程,张瑞,宋秋月,易东,伍亚舟.三种新型智能算法在疫情预警模型中的应用——基于百度搜索指数的COVID-19疫情预警[J].计算机工程与应用,2021,57(08):256-263. | 最小二乘支持向量机LSSVM,百度搜索指数疫情预警模型 |
| 田中大,潘信澎.小波消噪和优化支持向量机的网络流量预测[J/OL].北京邮电大学学报:1-7[2022-10-17].DOI:10.13190/j.jbupt.2021-146. // 唐雄. 基于改进黏菌优化算法的入侵检测研究[D].广西民族大学,2021. | 支持向量机,网络流量预测模型,入侵检测 |
| 臧传涛,刘冉冉,颜海彬.基于SMA-LSTM的轴承剩余寿命预测方法[J].江苏理工学院学报,2022,28(02):110-120. | LSTM,轴承剩余使用寿命预测 |
| 王鑫禄,刘大有,刘思含,王征,张丽伟,董飒.基于黏菌算法的蛋白质多序列比对[J/OL].吉林大学学报(工学版):1-11[2022-10-17]. | 预测蛋白质结构 |
| A fast community detection algorithm based on coot bird metaheuristic optimizer in social networks | 社区检测CD |
| Optimization of MLP neural network for modeling flow boiling performance of Al2O3/water nanofluids in a horizontal tube | 多层感知机MLP,人工神经网络ANN,反向传播算法BP |
| Gradient-based optimizer improved by Slime Mould Algorithm for global optimization and feature selection for diverse computation problems | 特征选择 |
| Towards augmented kernel extreme learning models for bankruptcy prediction: Algorithmic behavior and comprehensive analysis | KELM分类器,破产预测 |
| 韦鸳叶. 启发式黏菌优化算法及应用研究[D].广西民族大学,2022. | 无线传感器覆盖优化,无功功率优化调度,无人机动态目标搜索 |
| Implementing modified swarm intelligence algorithm based on Slime moulds for path planning and obstacle avoidance problem in mobile robots | 自主移动机器人AMR,路径规划与避障问题 |
| A Decomposition based Multi-Objective Heat Transfer Search algorithm for structure optimization | 多目标问题 |
| 翟青海,谢晓兰.混合云环境下考虑工作流的任务调度策略[J].桂林理工大学学报,2021,41(04):891-896. // 张启明. 面向云计算任务调度的混合智能算法的研究[D].桂林理工大学,2022. | 云计算工作流调度,任务调度 |
参考书籍:范旭,《Python智能优化算法——从原理到代码实现与应用》第一版,电子工业出版社。
目录一.加解密算法数字签名对称加密DES(DataEncryptionStandard)3DES(TripleDES)AES(AdvancedEncryptionStandard)RSA加密法DSA(DigitalSignatureAlgorithm)ECC(EllipticCurvesCryptography)非对称加密签名与加密过程非对称加密的应用对称加密与非对称加密的结合二.数字证书图解一.加解密算法加密简单而言就是通过一种算法将明文信息转换成密文信息,信息的的接收方能够通过密钥对密文信息进行解密获得明文信息的过程。根据加解密的密钥是否相同,算法可以分为对称加密、非对称加密、对称加密和非
1.问题描述使用Python的turtle(海龟绘图)模块提供的函数绘制直线。2.问题分析一幅复杂的图形通常都可以由点、直线、三角形、矩形、平行四边形、圆、椭圆和圆弧等基本图形组成。其中的三角形、矩形、平行四边形又可以由直线组成,而直线又是由两个点确定的。我们使用Python的turtle模块所提供的函数来绘制直线。在使用之前我们先介绍一下turtle模块的相关知识点。turtle模块提供面向对象和面向过程两种形式的海龟绘图基本组件。面向对象的接口类如下:1)TurtleScreen类:定义图形窗口作为绘图海龟的运动场。它的构造器需要一个tkinter.Canvas或ScrolledCanva
我一直在尝试用Ruby实现Luhn算法。我一直在执行以下步骤:该公式根据其包含的校验位验证数字,该校验位通常附加到部分帐号以生成完整帐号。此帐号必须通过以下测试:从最右边的校验位开始向左移动,每第二个数字的值加倍。将乘积的数字(例如,10=1+0=1、14=1+4=5)与原始数字的未加倍数字相加。如果总模10等于0(如果总和以零结尾),则根据Luhn公式该数字有效;否则无效。http://en.wikipedia.org/wiki/Luhn_algorithm这是我想出的:defvalidCreditCard(cardNumber)sum=0nums=cardNumber.to_s.s
下面是我写的一个计算斐波那契数列中的值的方法:deffib(n)ifn==0return0endifn==1return1endifn>=2returnfib(n-1)+(fib(n-2))endend它工作到n=14,但在那之后我收到一条消息说程序响应时间太长(我正在使用repl.it)。有人知道为什么会这样吗? 最佳答案 Naivefibonacci进行了大量的重复计算-在fib(14)fib(4)中计算了很多次。您可以将内存添加到您的算法中以使其更快:deffib(n,memo={})ifn==0||n==1returnnen
为了防止在迁移到生产站点期间出现数据库事务错误,我们遵循了https://github.com/LendingHome/zero_downtime_migrations中列出的建议。(具体由https://robots.thoughtbot.com/how-to-create-postgres-indexes-concurrently-in概述),但在特别大的表上创建索引期间,即使是索引创建的“并发”方法也会锁定表并导致该表上的任何ActiveRecord创建或更新导致各自的事务失败有PG::InFailedSqlTransaction异常。下面是我们运行Rails4.2(使用Acti
我正在开发一个类似微论坛的项目,其中一个特殊用户发布一条快速(接近推文大小)的主题消息,订阅者可以用他们自己的类似大小的消息来响应。直截了当,没有任何形式的“挖掘”或投票,只是每个主题消息的响应按时间顺序排列。但预计会有很高的流量。我们想根据它们引起的响应嗡嗡声来标记主题消息,使用0到10的等级。在谷歌上搜索了一段时间的趋势算法和开源社区应用示例,到目前为止已经收集到两个有趣的引用资料,但我还没有完全理解它们:Understandingalgorithmsformeasuringtrends,关于使用基线趋势算法比较维基百科页面浏览量的讨论,在SO上。TheBritneySpearsP
我收到错误:unsupportedcipheralgorithm(AES-256-GCM)(RuntimeError)但我似乎具备所有要求:ruby版本:$ruby--versionruby2.1.2p95OpenSSL会列出gcm:$opensslenc-help2>&1|grepgcm-aes-128-ecb-aes-128-gcm-aes-128-ofb-aes-192-ecb-aes-192-gcm-aes-192-ofb-aes-256-ecb-aes-256-gcm-aes-256-ofbRuby解释器:$irb2.1.2:001>require'openssl';puts
文章目录一.Dijkstra算法想解决的问题二.Dijkstra算法理论三.java代码实现一.Dijkstra算法想解决的问题解决的问题:求解单源最短路径,即各个节点到达源点的最短路径或权值考察其他所有节点到源点的最短路径和长度局限性:无法解决权值为负数的情况二.Dijkstra算法理论参数:S记录当前已经处理过的源点到最短节点U记录还未处理的节点dist[]记录各个节点到起始节点的最短权值path[]记录各个节点的上一级节点(用来联系该节点到起始节点的路径)Dijkstra算法步骤:(1)初始化:顶点集S:节点A到自已的最短路径长度为0。只包含源点,即S={A}顶点集U:包含除A外的其他顶
对于体育新闻中文文本的关键字提取,常用的算法包括TF-IDF、TextRank和LDA等。它们的基本步骤如下:1.TF-IDF算法: -将文本进行分词和词性标注处理。-统计每个词在文本中的词频(TF)。-计算每个词在整个语料库中出现的文档频率(DF)和逆文档频率(IDF)。-计算每个词的TF-IDF值,并按照值的大小进行排序,选择排名前几的词作为关键字。2.TextRank算法:-将文本进行分词和词性标注处理。-将分词结果转化成图模型,每个词语为节点,根据词语之间的共现关系建立边。-对图模型进行迭代计算,计算每个节点的PageRank值,表示该节点的重要性。-选择排名前几的节点作为关键字。3.
我正在尝试计算由二进制形式的1和0的P数表示的数字的数量。如果P=2,则表示的数字为0011、1100、0110、0101、1001、1010,所以计数为6。我试过:[0,0,1,1].permutation.to_a.uniq但这不是大数的最佳解决方案(P可以什么可能是最好的排列技术,或者我们是否有任何直接的数学来做到这一点? 最佳答案 Numberofpermutationcanbecalculatedusingfactorial.a=[0,0,1,1](1..a.size).inject(:*)#=>4!=>24要计算重复项,