JavaWeb-封装工具类
大概内容:
自定义格式的标题,及对应的数据,每个sheet页的表头及数据都可以不同,具体根据实际业务去变更,可以仿照这个例子去编写,这里提供的是最基础的多sheet页导出,如果需要多行表头复杂业务的多sheet页导出可参考我另一篇复杂表头,多行表头导出,如果导出不确定行数列数跟随业务的增长而变动的导出参考另一篇不确定行数列数数据的工具类
2023.3.29补充
上面两个链接老是失效,在我主页搜索对应的名称就能找到
提示:以下是本篇文章正文内容,下面案例可供参考
本篇测试数据为两个sheet页的导出功能,测试中导出到本地,工具类有导出到浏览器的封装方法,可直接使用
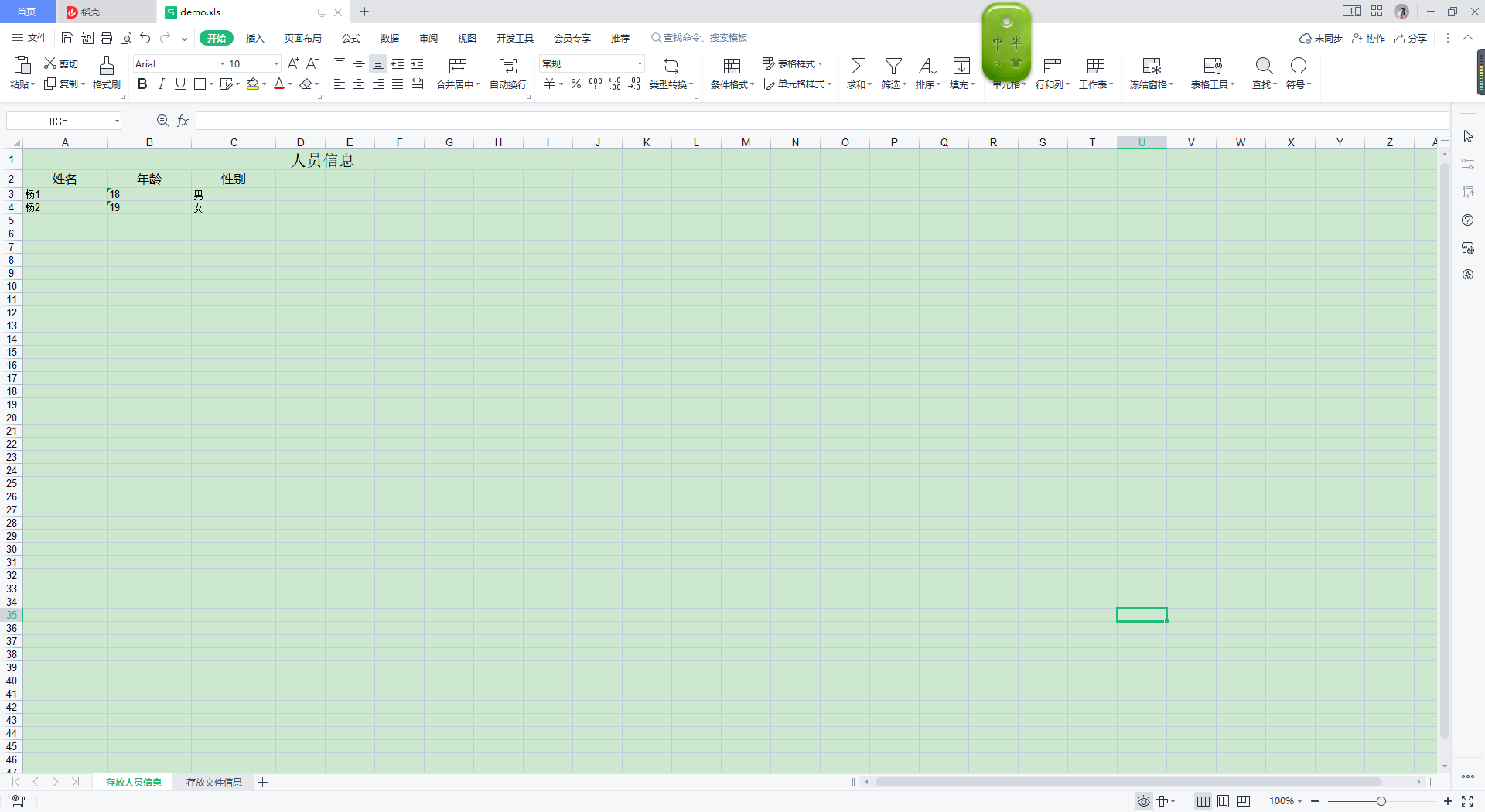
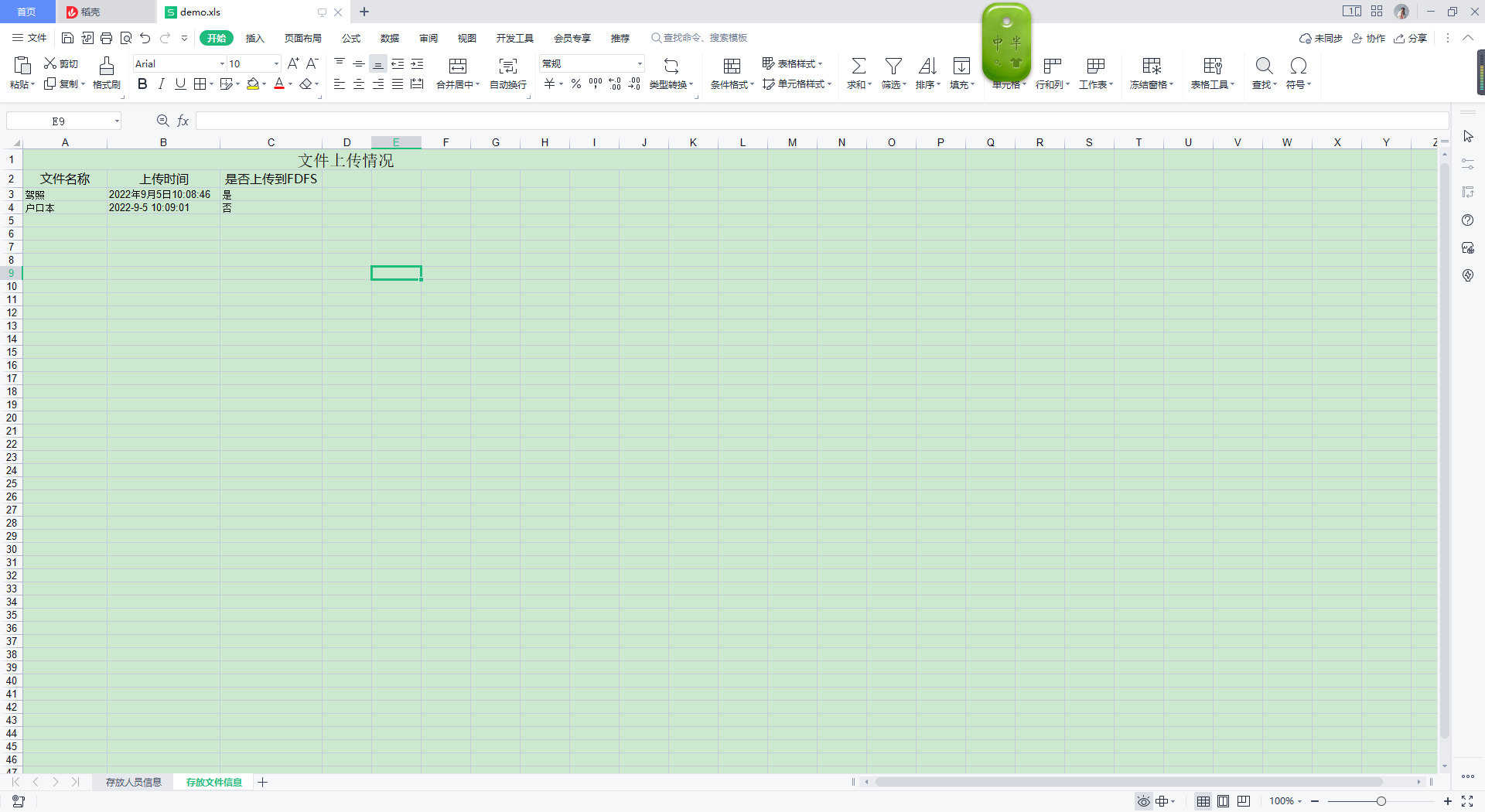
业务层调用
//假设这是需要导出的数据
public static void main(String[] args) {
/** 第一页数据 */
List<String[]> dataAllOne = new ArrayList<>();
String[] data1 = (String[]) Arrays.asList("杨1", "18", "男").toArray();
String[] data2 = (String[]) Arrays.asList("杨2", "19", "女").toArray();
dataAllOne.add(data1);
dataAllOne.add(data2);
/** 第二页数据 */
List<String[]> dataAllTwo = new ArrayList<>();
String[] data3 = (String[]) Arrays.asList("驾照", "2022年9月5日10:08:46", "是").toArray();
String[] data4 = (String[]) Arrays.asList("户口本", "2022-9-5 10:09:01", "否").toArray();
dataAllTwo.add(data3);
dataAllTwo.add(data4);
ArrayList<ExcelExp> list = new ArrayList<>();
ExcelExp excelExp1 = new ExcelExp("存放人员信息", (String[]) Arrays.asList("姓名", "年龄", "性别").toArray(), dataAllOne, "人员信息");
ExcelExp excelExp2 = new ExcelExp("存放文件信息", (String[]) Arrays.asList("文件名称", "上传时间", "是否上传到FDFS").toArray(), dataAllTwo, "文件上传情况");
list.add(excelExp1);
list.add(excelExp2);
Workbook workbook = ExcelExportUtil.exportManySheetExcel(list);
//导出数据到excel
FileOutputStream fileOutputStream = null;
try {
fileOutputStream = new FileOutputStream("F:/新建文件夹/demo.xls");
workbook.write(fileOutputStream);
fileOutputStream.flush();
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
if(fileOutputStream != null){
try {
fileOutputStream.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
直接copy改吧改吧就可以使用,有详细注释
import org.apache.poi.hssf.usermodel.*;
import org.apache.poi.ss.usermodel.HorizontalAlignment;
import org.apache.poi.ss.usermodel.Workbook;
import org.apache.poi.ss.util.CellRangeAddress;
import javax.servlet.ServletOutputStream;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import java.io.*;
import java.net.URLEncoder;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
import java.util.Map;
/**
* @Description: java导出功能(多个sheet页数据导出)
*
* @Author: 杨永卓
* @Date: 2022/9/5 10:31
*/
public final class ExcelExportUtil {
private ExcelExportUtil (){}
private static ExcelExportUtil excelExportUtil = null;
static{
/** 类加载时创建,只会创建一个对象 */
if(excelExportUtil == null) excelExportUtil = new ExcelExportUtil ();
}
/**
* @param @param file 导出文件路径
* @param @param mysheets
* @return void
* @throws
* @Title: exportManySheetExcel
* @Description: 可生成单个、多个sheet
*/
public static Workbook exportManySheetExcel(List<ExcelExp> mysheets) {
HSSFWorkbook wb = new HSSFWorkbook();// 创建工作薄
List<ExcelExp> sheets = mysheets;
// 表头样式
HSSFCellStyle style = wb.createCellStyle();
style.setAlignment(HorizontalAlignment.CENTER); // 创建一个居中格式
// 字体样式
HSSFFont fontStyle = wb.createFont();
fontStyle.setFontName("微软雅黑");
fontStyle.setFontHeightInPoints((short) 12);
// fontStyle.setBoldweight(HSSFFont.BOLDWEIGHT_BOLD);
style.setFont(fontStyle);
for (ExcelExp excel : sheets) {
// 新建一个sheet
HSSFSheet sheet = wb.createSheet(excel.getFileName());// 获取该sheet名称
String[] handers = excel.getHanders();// 获取sheet的标题名
HSSFRow tableName = sheet.createRow(0);
HSSFCell cellName = tableName.createCell(0);
sheet.addMergedRegion(new CellRangeAddress(0, 0, 0, 9));
HSSFCellStyle titleStyle = wb.createCellStyle();
// 设置单元格样式
HSSFFont titleFont = wb.createFont(); // 标题字体
titleFont.setFontHeightInPoints((short) 16); // 字号
titleStyle.setFont(titleFont);
titleStyle.setAlignment(HorizontalAlignment.CENTER);
cellName.setCellStyle(titleStyle);
// 设置单元格内容
cellName.setCellValue(excel.getTableName());
HSSFRow rowFirst = sheet.createRow(1);// 第一个sheet的第一行为标题
// 写标题
for (int i = 0; i < handers.length; i++) {
// 获取第一行的每个单元格
HSSFCell cell = rowFirst.createCell(i);
// 往单元格里写数据
cell.setCellValue(handers[i]);
cell.setCellStyle(style); // 加样式
sheet.setColumnWidth(i, 4000); // 设置每列的列宽
}
// 写数据集
List<String[]> dataset = excel.getDataset();
for (int i = 0; i < dataset.size(); i++) {
String[] data = dataset.get(i);// 获取该对象
// 创建数据行
HSSFRow row = sheet.createRow(i + 2);
for (int j = 0; j < data.length; j++) {
// 设置对应单元格的值
row.createCell(j).setCellValue(data[j]);
}
}
}
return wb;
}
public static void outputXls(Workbook workbook, String fileName, HttpServletResponse response,
HttpServletRequest request) {
ByteArrayOutputStream os = new ByteArrayOutputStream();
try {
workbook.write(os);
byte[] content = os.toByteArray();
InputStream is = new ByteArrayInputStream(content);
// 设置response参数,可以打开下载页面
response.reset();
response.setContentType("application/vnd.ms-excel;charset=utf-8");
response.setHeader("Content-Disposition",
"attachment;filename=" + encodeFileName(fileName + ".xls", request));
ServletOutputStream out = response.getOutputStream();
BufferedInputStream bis = null;
BufferedOutputStream bos = null;
try {
bis = new BufferedInputStream(is);
bos = new BufferedOutputStream(out);
byte[] buff = new byte[2048];
int bytesRead;
// Simple read/write loop.
while (-1 != (bytesRead = bis.read(buff, 0, buff.length))) {
bos.write(buff, 0, bytesRead);
}
} catch (Exception e) {
e.printStackTrace();
} finally {
if (bis != null)
bis.close();
if (bos != null)
bos.close();
}
} catch (Exception e1) {
e1.printStackTrace();
}
}
public static String encodeFileName(String fileName, HttpServletRequest request)
throws UnsupportedEncodingException {
String agent = request.getHeader("USER-AGENT");
if (null != agent && -1 != agent.indexOf("MSIE")) {
return URLEncoder.encode(fileName, "UTF-8");
} else if (null != agent && -1 != agent.indexOf("Mozilla")) {
return "=?UTF-8?B?"
+ (new String(org.apache.commons.codec.binary.Base64.encodeBase64(fileName.getBytes("UTF-8")))) + "?=";
} else {
return fileName;
}
}
/**
* 把list<map>封装成list<String[]> 由于我的结果集是List<Map<String,Object>>,所以我写了这个个方法,把它转换成List<String[]>
*
* @param list 要封装的list
* @param strKey String[]的长度
* @return
*/
public static List<String[]> listUtils(List<Map<String, Object>> list, String[] strKey) {
if (list != null && list.size() > 0) {// 如果list有值
List<String[]> strList = new ArrayList<String[]>();// 实例化一个list<string[]>
for (Map<String, Object> map : list) {// 遍历数组
String[] str = new String[strKey.length];// 实力一个string[]
Integer count = 0;// 作为str的下标,每次从0开始
for (String s : strKey) {// 遍历map中的key
if (map.get(s) != null) {
str[count] = map.get(s).toString();
} else {
str[count] = "";
}
// 把map的value赋值到str数组中
count++;// str的下标+1
}
if (str != null) {// 如果str有值,添加到strList
strList.add(str);
}
}
if (strList != null && strList.size() > 0) {// 如果strList有值,返回strList
return strList;
}
}
return null;
}
/**
* @Description: 导出对象
*
* @Author: 杨永卓
* @Date: 2022/9/5 10:34
*/
private static class ExcelExp {
private String fileName;// sheet的名称
private String[] handers;// sheet里的标题
private List<String[]> dataset;// sheet里的数据集
private String tableName;
public ExcelExp(String fileName, String[] handers, List<String[]> dataset, String tableName) {
this.fileName = fileName;
this.handers = handers;
this.dataset = dataset;
this.tableName = tableName;
}
public String getFileName() {
return fileName;
}
public void setFileName(String fileName) {
this.fileName = fileName;
}
public String[] getHanders() {
return handers;
}
public void setHanders(String[] handers) {
this.handers = handers;
}
public List<String[]> getDataset() {
return dataset;
}
public void setDataset(List<String[]> dataset) {
this.dataset = dataset;
}
public String getTableName() {
return tableName;
}
public void setTableName(String tableName) {
this.tableName = tableName;
}
}
}
Rails2.3可以选择随时使用RouteSet#add_configuration_file添加更多路由。是否可以在Rails3项目中做同样的事情? 最佳答案 在config/application.rb中:config.paths.config.routes在Rails3.2(也可能是Rails3.1)中,使用:config.paths["config/routes"] 关于ruby-on-rails-Rails3中的多个路由文件,我们在StackOverflow上找到一个类似的问题
我有多个ActiveRecord子类Item的实例数组,我需要根据最早的事件循环打印。在这种情况下,我需要打印付款和维护日期,如下所示:ItemAmaintenancerequiredin5daysItemBpaymentrequiredin6daysItemApaymentrequiredin7daysItemBmaintenancerequiredin8days我目前有两个查询,用于查找maintenance和payment项目(非排他性查询),并输出如下内容:paymentrequiredin...maintenancerequiredin...有什么方法可以改善上述(丑陋的)代
我需要从一个View访问多个模型。以前,我的links_controller仅用于提供以不同方式排序的链接资源。现在我想包括一个部分(我假设)显示按分数排序的顶级用户(@users=User.all.sort_by(&:score))我知道我可以将此代码插入每个链接操作并从View访问它,但这似乎不是“ruby方式”,我将需要在不久的将来访问更多模型。这可能会变得很脏,是否有针对这种情况的任何技术?注意事项:我认为我的应用程序正朝着单一格式和动态页面内容的方向发展,本质上是一个典型的网络应用程序。我知道before_filter但考虑到我希望应用程序进入的方向,这似乎很麻烦。最终从任何
我有一个具有一些属性的模型:attr1、attr2和attr3。我需要在不执行回调和验证的情况下更新此属性。我找到了update_column方法,但我想同时更新三个属性。我需要这样的东西:update_columns({attr1:val1,attr2:val2,attr3:val3})代替update_column(attr1,val1)update_column(attr2,val2)update_column(attr3,val3) 最佳答案 您可以使用update_columns(attr1:val1,attr2:val2
我真的很习惯使用Ruby编写以下代码:my_hash={}my_hash['test']=1Java中对应的数据结构是什么? 最佳答案 HashMapmap=newHashMap();map.put("test",1);我假设? 关于java-等价于Java中的RubyHash,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/22737685/
我正在尝试修改当前依赖于定义为activeresource的gem:s.add_dependency"activeresource","~>3.0"为了让gem与Rails4一起工作,我需要扩展依赖关系以与activeresource的版本3或4一起工作。我不想简单地添加以下内容,因为它可能会在以后引起问题:s.add_dependency"activeresource",">=3.0"有没有办法指定可接受版本的列表?~>3.0还是~>4.0? 最佳答案 根据thedocumentation,如果你想要3到4之间的所有版本,你可以这
只是想确保我理解了事情。据我目前收集到的信息,Cucumber只是一个“包装器”,或者是一种通过将事物分类为功能和步骤来组织测试的好方法,其中实际的单元测试处于步骤阶段。它允许您根据事物的工作方式组织您的测试。对吗? 最佳答案 有点。它是一种组织测试的方式,但不仅如此。它的行为就像最初的Rails集成测试一样,但更易于使用。这里最大的好处是您的session在整个Scenario中保持透明。关于Cucumber的另一件事是您(应该)从使用您的代码的浏览器或客户端的角度进行测试。如果您愿意,您可以使用步骤来构建对象和设置状态,但通常您
我正在尝试使用boilerpipe来自JRuby。我看过guide从JRuby调用Java,并成功地将它与另一个Java包一起使用,但无法弄清楚为什么同样的东西不能用于boilerpipe。我正在尝试基本上从JRuby中执行与此Java等效的操作:URLurl=newURL("http://www.example.com/some-location/index.html");Stringtext=ArticleExtractor.INSTANCE.getText(url);在JRuby中试过这个:require'java'url=java.net.URL.new("http://www
我正在尝试按0-9和a-z的顺序创建数字和字母列表。我有一组值value_array=['0','1','2','3','4','5','6','7','8','9','a','b','光盘','e','f','g','h','i','j','k','l','m','n','o','p','q','r','s','','u','v','w','x','y','z']和一个组合列表的数组,按顺序,这些数字可以产生x个字符,比方说三个list_array=[]和一个当前字母和数字组合的数组(在将它插入列表数组之前我会把它变成一个字符串,]current_combo['0','0','0']
是否有可能:before_filter:authenticate_user!||:authenticate_admin! 最佳答案 before_filter:do_authenticationdefdo_authenticationauthenticate_user!||authenticate_admin!end 关于ruby-on-rails-before_filter运行多个方法,我们在StackOverflow上找到一个类似的问题: https://