以下是分页常用的方法
numbers=list(range(50))
page=Paginator(numbers,10)
print(page.num_pages)#获取总共分了多少页
print(page.count)#总共多少条数据
page_1=page.get_page(1)#获取第一页数据
print('pake_1',page_1.number)#获取当前所在分页
print(page_1.has_next())#获取有没有下一页
print(page_1.paginator.num_pages)#用当前页面的对象,去获取总共多少页
print(page_1.paginator.count)#用当前页面的对象,去获取总共有多少条数据
print(page_1.has_previous())#获取有没有上一页
print(page_1.has_other_pages())#获取有没有其他页
# print(page_1.previous_page_number())#获取上一页的页码
print(page.get_page(2).object_list)#object_list返回的数据是一个list
。。。。。。。。。。。。。。。
前后端不分离的写法: 基础条件是先建好数据库,下边这是我建的数据库的样式,怎么创建数据库的表结构,看我之前的博客 首先第一步需要先导入:
from django.core.paginator import Paginator #这个是处理分页的
,然后写一个接口,返回给HTML文件,之后在html中调用这个接口里边的方法
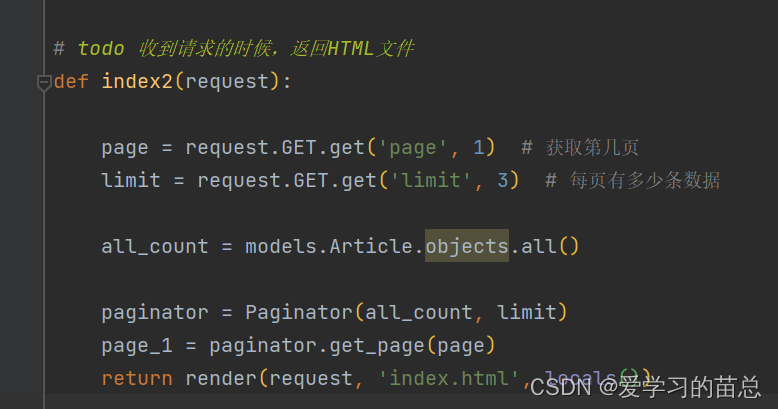
# todo 收到请求的时候,返回HTML文件
def index2(request):
page = request.GET.get('page', 1) # 获取第几页
limit = request.GET.get('limit', 3) # 每页有多少条数据
all_count = models.Article.objects.all()
paginator = Paginator(all_count, limit)
page_1 = paginator.get_page(page)
return render(request, 'index.html', locals())
之后在HTML文件中,调用这个方法里边的内容,这里边每个方法是干啥用的,在文章上边看就行
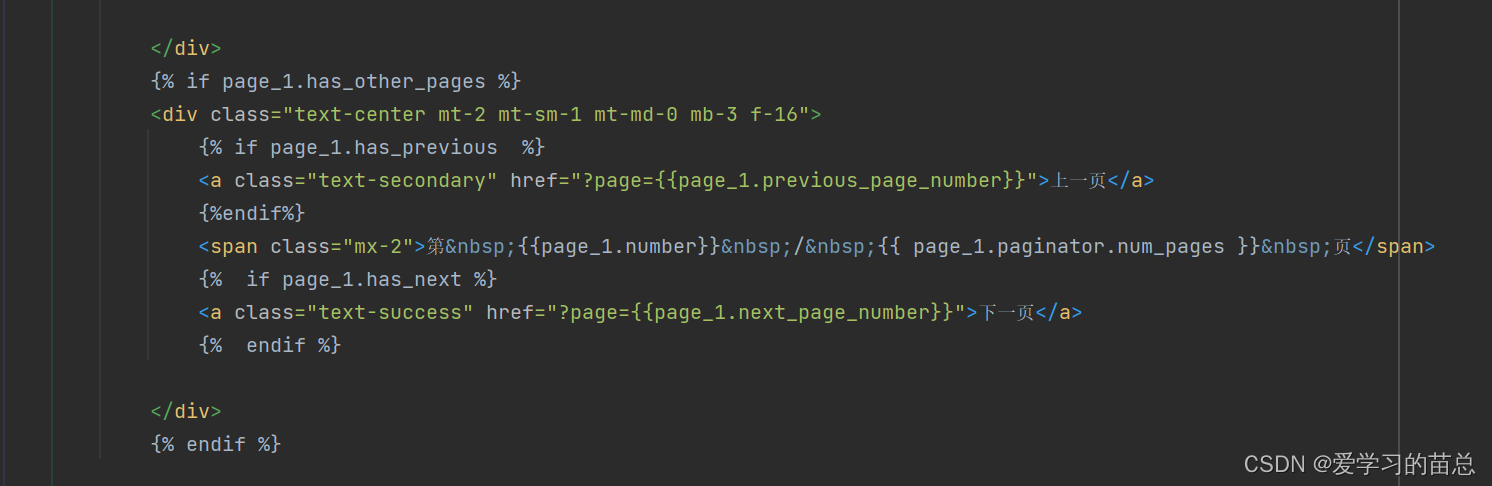
{% if page_1.has_other_pages %}
<div class="text-center mt-2 mt-sm-1 mt-md-0 mb-3 f-16">
{% if page_1.has_previous %}
<a class="text-secondary" href="?page={{page_1.previous_page_number}}">上一页</a>
{%endif%}
<span class="mx-2">第 {{page_1.number}} / {{ page_1.paginator.num_pages }} 页</span>
{% if page_1.has_next %}
<a class="text-success" href="?page={{page_1.next_page_number}}">下一页</a>
{% endif %}
</div>
{% endif %}
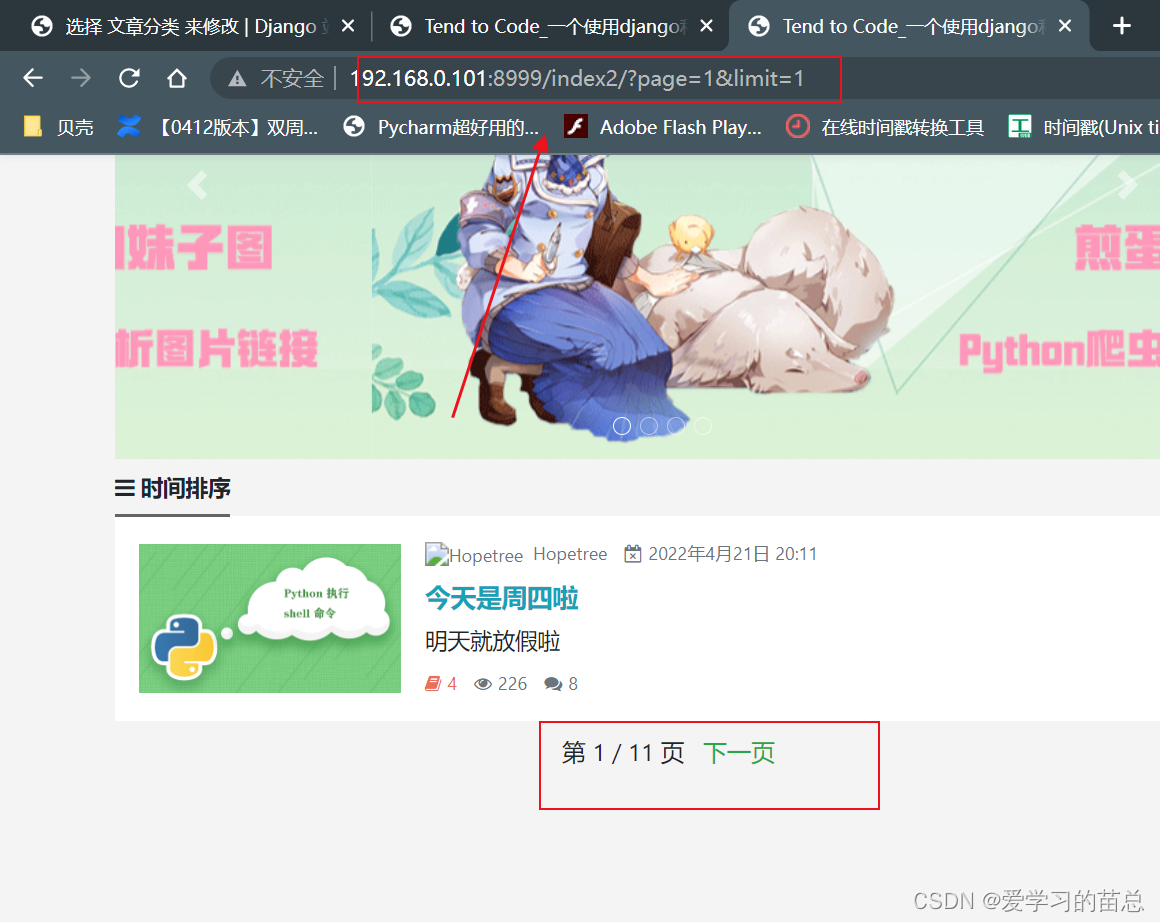
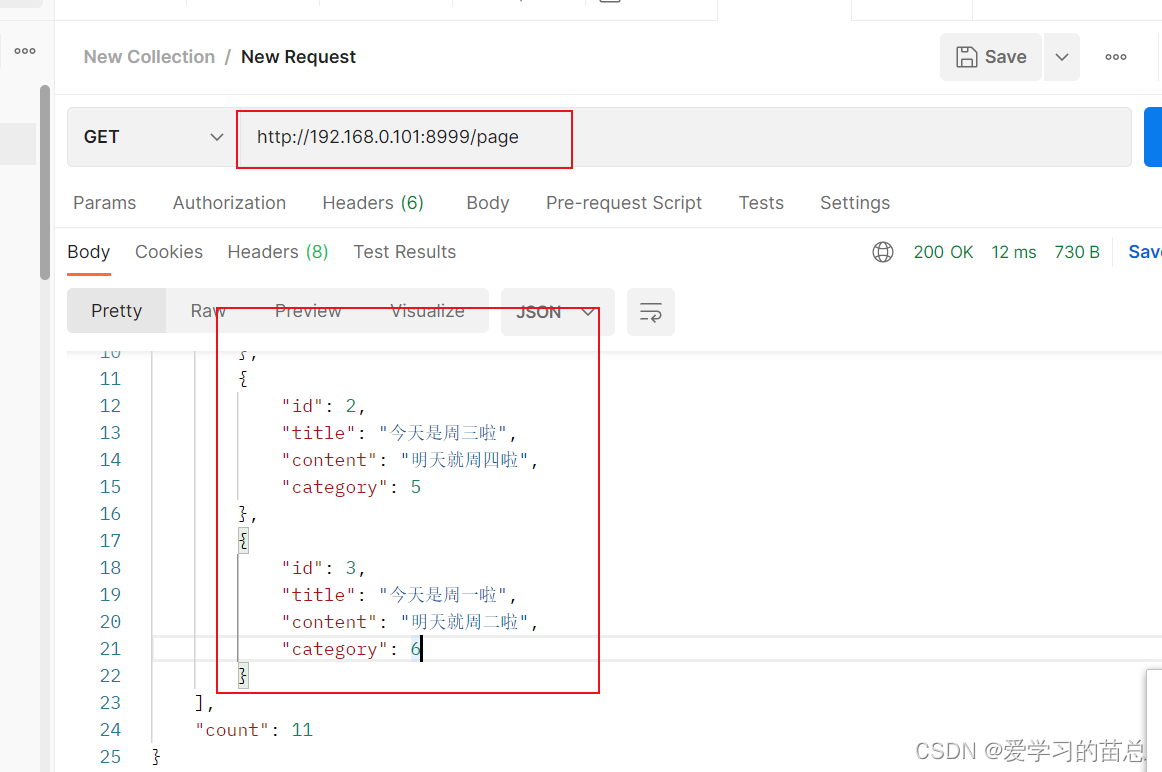
最后请求接口:http://IP:8999/index2/?page=1&limit=1 这个里边的page和limit是可以传递不同的参数的,样式见下边截图
二、第二种做分页的方法是前后端分离的写法,前提条件和上边一样,但是这个是自己写一个接口,然后前端在调用这个接口的数据
首先导入:
from django.forms import model_to_dict #这个是转字典的,要是不导入这个的话,接口返回json的时候会报错
然后,重新定义一个接口
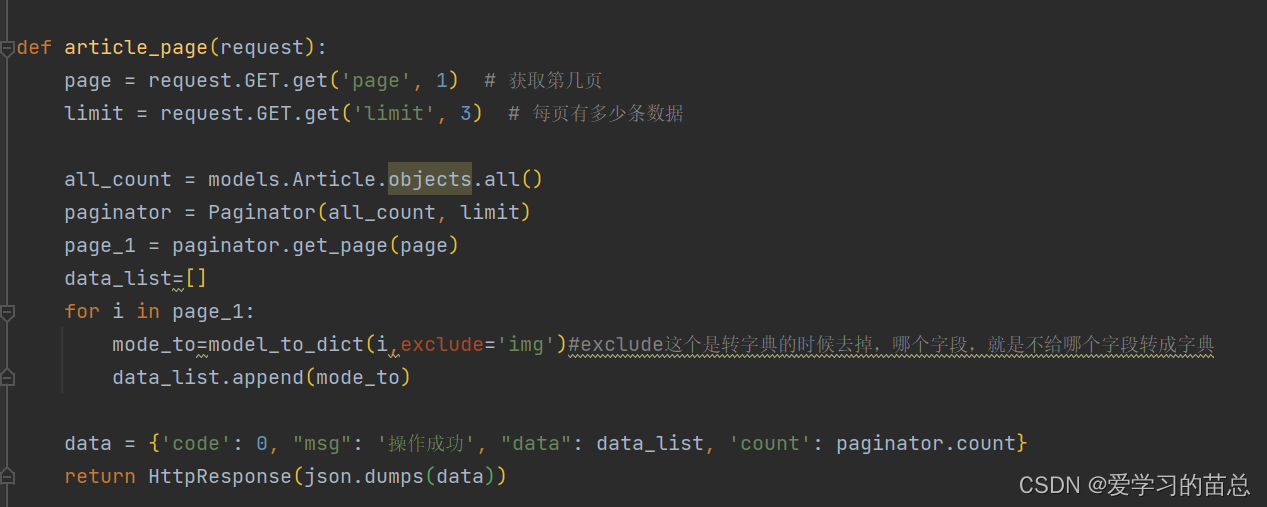
def article_page(request):
page = request.GET.get('page', 1) # 获取第几页
limit = request.GET.get('limit', 3) # 每页有多少条数据
all_count = models.Article.objects.all()
paginator = Paginator(all_count, limit)
page_1 = paginator.get_page(page)
data_list=[]
for i in page_1:
mode_to=model_to_dict(i,exclude='img')#exclude这个是转字典的时候去掉,哪个字段,就是不给哪个字段转成字典
data_list.append(mode_to)
data = {'code': 0, "msg": '操作成功', "data": data_list, 'count': paginator.count}
return HttpResponse(json.dumps(data))
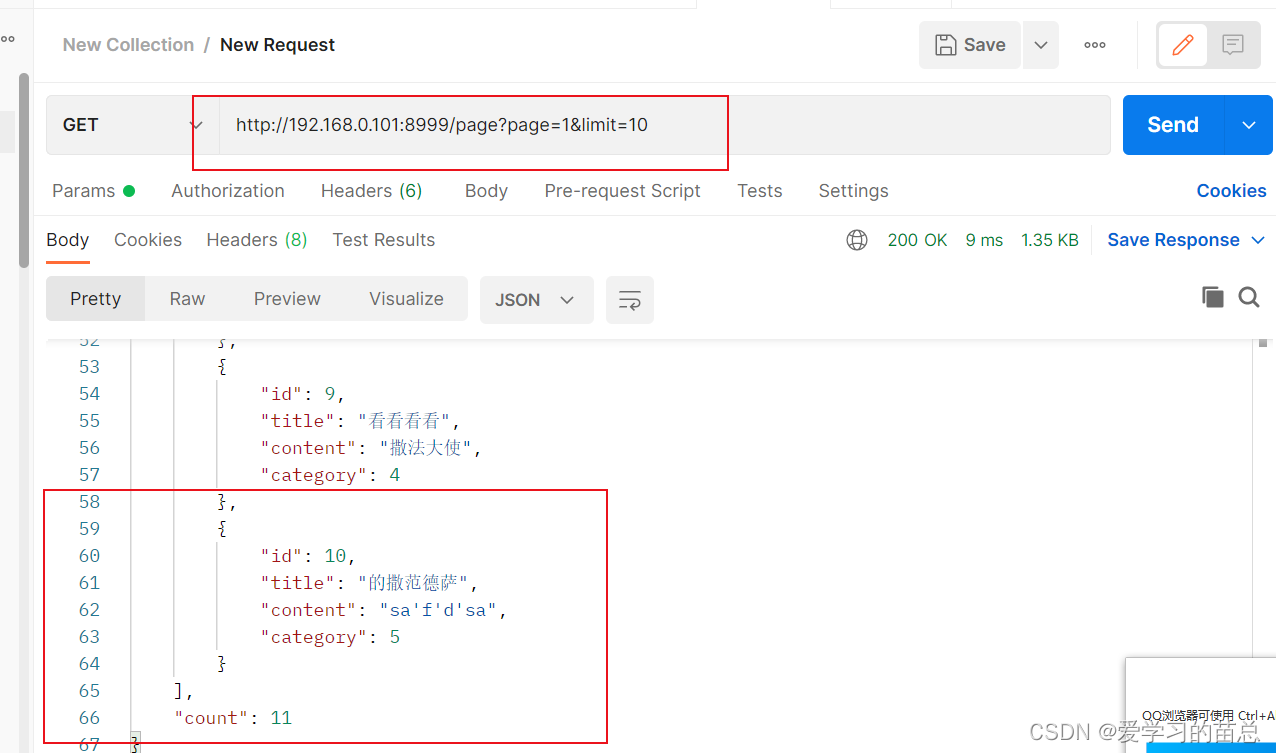
之后在postman上请求这个接口,然后这个接口就会返回分页的信息了,具体要返回什么信息的话,的看你想要什么,接口返回的样式
第二种,接口请求的样式:
我在Rails应用程序中使用CarrierWave/Fog将视频上传到AmazonS3。有没有办法判断上传的进度,让我可以显示上传进度如何? 最佳答案 CarrierWave和Fog本身没有这种功能;你需要一个前端uploader来显示进度。当我不得不解决这个问题时,我使用了jQueryfileupload因为我的堆栈中已经有jQuery。甚至还有apostonCarrierWaveintegration因此您只需按照那里的说明操作即可获得适用于您的应用的进度条。 关于ruby-on-r
我想从then子句中访问case语句表达式,即food="cheese"casefoodwhen"dip"then"carrotsticks"when"cheese"then"#{expr}crackers"else"mayo"end在这种情况下,expr是食物的当前值(value)。在这种情况下,我知道,我可以简单地访问变量food,但是在某些情况下,该值可能无法再访问(array.shift等)。除了将expr移出到局部变量然后访问它之外,是否有直接访问caseexpr值的方法?罗亚附注我知道这个具体示例很简单,只是一个示例场景。 最佳答案
据我们所知,Jekyll默认分页仅支持index.html,我想创建blog.html并在那里包含分页。有什么解决办法吗? 最佳答案 如果您创建一个名为/blog的目录并在其中放置一个index.html文件,那么您可以向_config.yml表示paginate_path:"blog/page:num"。不是使用根文件夹中的默认index.html作为分页器模板,而是使用/blog/index.html。分页器将根据需要生成类似/blog/page2/和/blog/page3/的页面。这将使您到达yourwebsite.com/b
如果我想使用“create”构建策略创建和实例,然后想使用“attributes_for”构建策略进行验证,是否可以这样做?如果我在工厂中使用序列?在Machinistgem中有可能吗? 最佳答案 不太确定我是否完全理解。而且我不是机械师的用户。但听起来您只是想做这样的事情。@attributes=FactoryGirl.attributes_for(:my_object)my_object=MyObject.create(@attributes)my_object.some_property.should==@attributes
假设我在我的Rails应用中某处定义了一个名为bla的函数。在ruby或rails中有没有一种方法可以动态/以编程方式打印用于定义该函数的代码?例如:defblaputs"HiThere"end然后如果我调用一个函数,例如get_definition:putsget_definition(:bla)这会打印出来"puts\"HiThere\""有规范的方法吗?我以前实际上不需要这样做,而且我知道这在Rails中并不是很常见的做法。我也不想使用元(反射)编程定义我的方法,然后存储用于定义我的方法的字符串。感谢您的帮助! 最佳答案
我知道Ruby是动态和强类型的,但据我所知,由于每个参数缺少显式类型表示法(或契约),当前语法不允许在编译时检查参数类型。如果我想执行编译时类型检查,我有哪些(实际成熟的)选项?更新我的意思是类型检查类似于典型的静态类型语言。比如C。例如,C函数表示每个参数的类型,编译器检查传入的参数是否正确。voidfunc1(structAAAaaa){structBBBbbb;func1(bbb);//Wrongtype.Compiletimeerror.}作为另一个例子,Objective-C通过放置显式类型信息来做到这一点。-(id)method1:(AAA*)aaa{BBB*bbb=[[A
从Ruby2.4.0开始,对于使用某些已弃用的功能,会出现弃用警告。例如,Bignum、Fixnum、TRUE和FALSE都会触发弃用警告。当我修复我的代码时,有相当多的代码我希望它保持沉默,尤其是在Rails中。我该怎么做? 最佳答案 moduleKerneldefsuppress_warningsoriginal_verbosity=$VERBOSE$VERBOSE=nilresult=yield$VERBOSE=original_verbosityreturnresultendend>>X=:foo=>:foo>>X=:bar
我认为最好的例子是images/文件夹或node_modules/用于将图像和依赖项包含在最终构建中,而无需花费很长时间编译。编辑:抱歉没有具体说明,但我很清楚keep_files和exclude两者都对我的情况没有帮助。exclude从编译和站点构建中排除文件夹和文件,并且每次都需要额外的流水线工具来手动移动它们。keep_files要求文件首先存在于最终构建中,这对于某些生产环境(GitHub的gh-pages等)是不可能的 最佳答案 你可能想看看这个:ExcludingadirectoryfromJekyllwatchP.S.
我尝试了以下正则表达式,但它匹配所有双引号:(?>(?这是文本的示例:"[\"mycarslastnight\",\"Burger\",\"Decaf\"shirt\",\"Mocha\",\"marshmallows\",\"CoffeeMission\"]"我要匹配的模式是第2行中双引号之间的双引号 最佳答案 一般来说,我会说:不。给定一个字符串:\"Burger\"\"Decaf\"shirt\"你如何确定哪个\"是多余的(不匹配的)?这个是在Burger之后,还是在Decaf之后,还是一个在shirt之后?还是在任何这些词之
我正在用RubyonRails重写Django应用程序,并希望为用户保留旧密码。Django使用PBKDF2SHA1作为加密机制。所以我有一个加密密码是这个pbkdf2_sha256$10000$YsnGfP4rZ1IZ$Tpf4922MoNEjuJQA9EG2Elptyt3dMAyzBPUgmunFOW4=原密码是2bulls在Ruby中,我使用PBKDF256gem和base64进行检查。Base64.encode64PBKDF256.dk("2bulls","YsnGfP4rZ1IZ",10000,32)我很期待Tpf4922MoNEjuJQA9EG2Elptyt3dMAyzBP