看到这篇文章的标题,是不是有小伙伴会感到惊讶呢?
Postman不是做接口测试的吗?为什么还能做UI自动化测试呢?
其实,只要你了解Selenium的运行原理,就可以理解为什么Postman也能实现UI自动化测试了。
运行代码,启动浏览器后,webdriver会将浏览器绑定到特定的端口,作为webdriver的remote server(远程服务端),而client(客户端,也就是测试脚本,可以是Python或者Java代码)会借助CommandExecutor创建sessionId,发送http请求给remote server,remote server收到http请求后,调用webdriver完成操作,并将http响应结果返回给client。
所以,本质上是调用http请求的过程,因此也就可以理解为什么可以使用Postman实现UI自动化测试。
以上我们知道了Selenium的底层原理其实就是调用http请求的过程,那么我们要想调用接口就需要知道接口信息,包括请求方式、请求地址、请求参数、请求格式等。
这些接口信息,我们可以通过对源码的分析得到。
运行chromedriver.exe
Selenium脚本:
from selenium import webdriver
driver = webdriver.Chrome()
执行上述代码,程序会打开Chrome浏览器。(前提:已经正确配置了Chrome驱动和对应的版本)
那么,Selenium是如何实现这一过程的呢?
源码分析:
D:\Python3\Lib\site-packages\selenium\webdriver\chrome\webdriver.py


我们可以看到它执行了一个cmd命令,这个命令主要是启动chromedriver.exe浏览器驱动,我们每次执行脚本前,程序会自动帮我们启动浏览器驱动。
由于我们跳过了代码脚本,因此需要手动启动浏览器驱动。
地址及端口号:127.0.0.1:9515
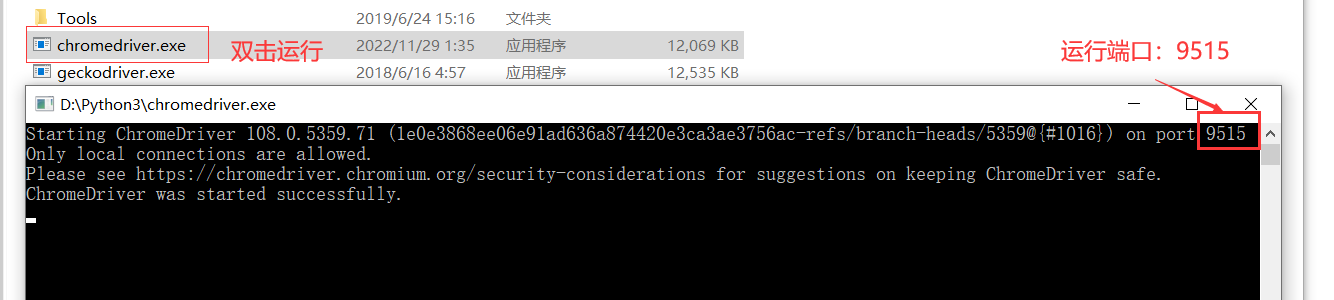
新建浏览器会话
D:\Python3\Lib\site-packages\selenium\webdriver\remote\webdriver.py
继续查看源码,这里有一行重要的代码:

start_session()这个方法是向地址http://127.0.0.1:9515/session发送了一个post请求,参数是JSON格式,然后返回一个特定的响应信息给程序,主要就是新建了一个sessionId。



接口信息:
url: /session
method: POST
content_type: application/json
请求参数:
{
"capabilities": {
"browserName": "chrome"
}
}
调用接口:
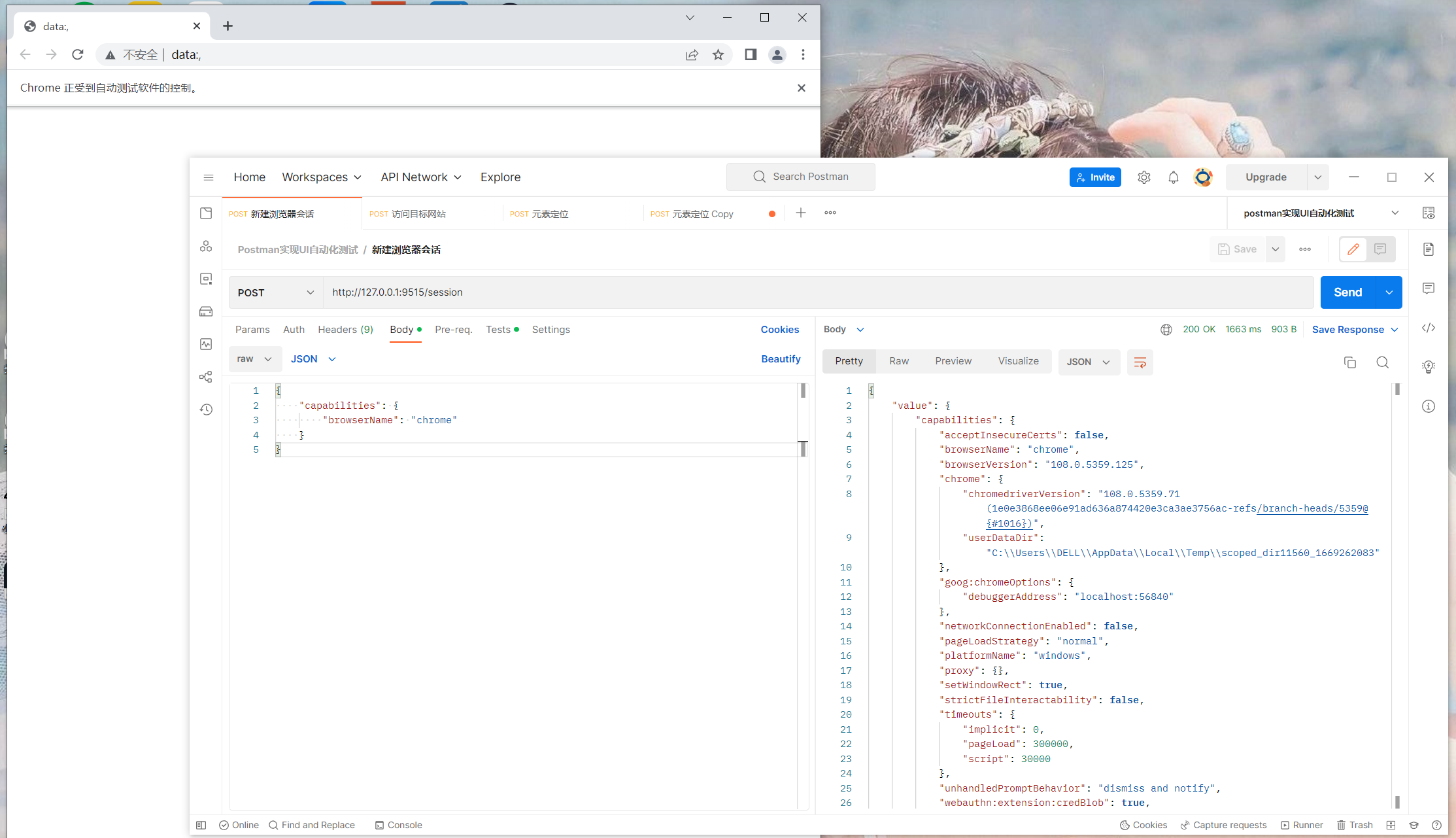
访问目标网站
Selenium脚本:
driver.get("https://www.baidu.com")
执行以上代码,可以访问目标网站。
源码分析:
D:\Python3\Lib\site-packages\selenium\webdriver\remote\remote_connection.py
在RemoteConnection这个类中,定义了所有selenium操作需要的接口地址(这些接口地址全部封装在浏览器驱动程序中)。

其中Command.GET: ("POST", "/session/$sessionId/url")这个地址就是实现访问一个网站的URL。

紧接着,可以看到主要是通过execute()方法调用_request()方法通过urllib3标准库向服务器发送对应操作请求地址,进而实现浏览器各种操作。
而打开浏览器和操作浏览器实现各种动作是通过上一步新建浏览器会话返回的sessionId实现的关联。你也会发现后面操作的各种接口地址中都存在一个$sessionId,以达到能够在同一个浏览器中做操作。


接口信息:
url: /session/$sessionId/url
method: POST
content_type: application/json
请求参数:
{
"url": "目标网站地址"
}
调用接口:

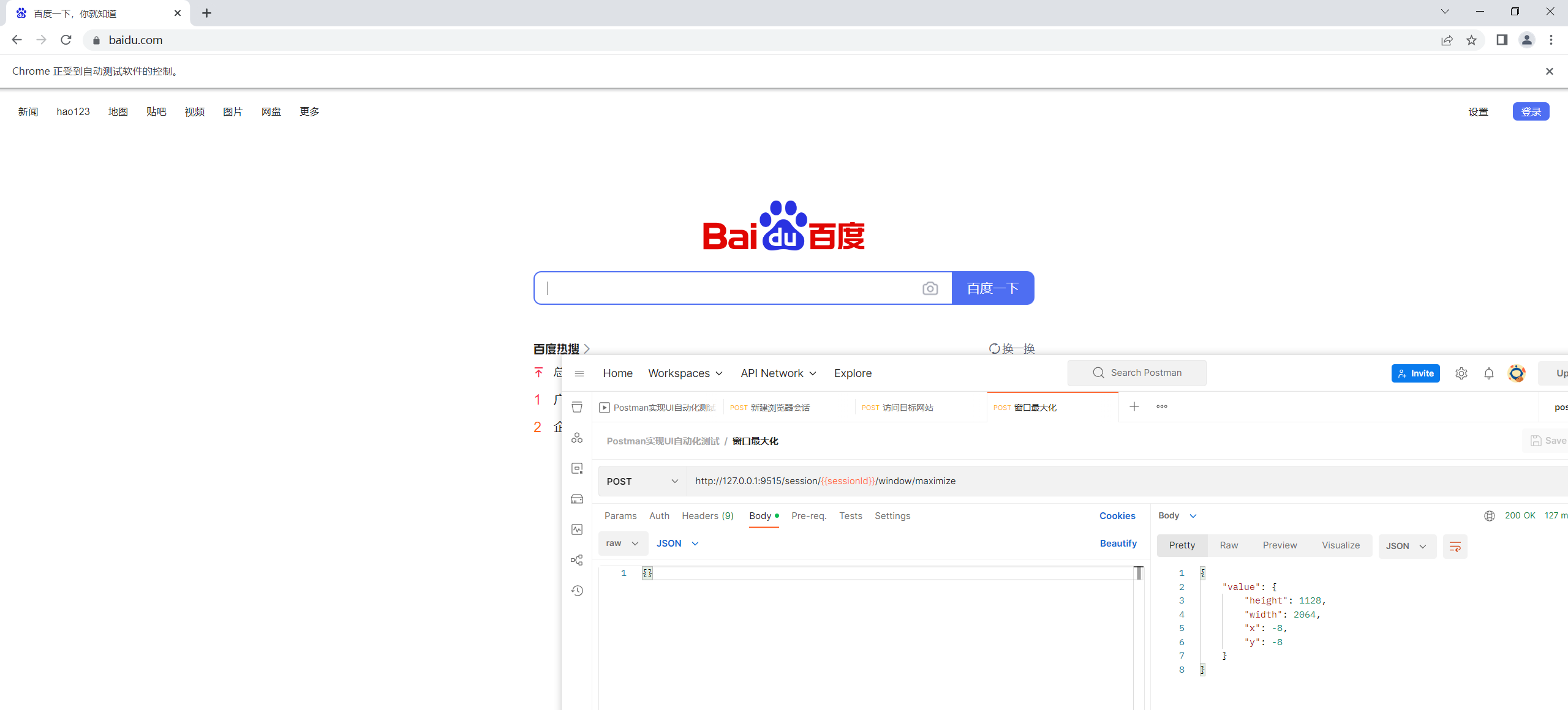
窗口最大化
Selenium脚本:
driver.maximize_window()
源码分析:

接口信息:
url: /session/$sessionId/window/maximize
method: POST
content_type: application/json
调用接口:
元素定位
Selenium脚本:
driver.find_element(By.XPATH, "//input[@id='kw']")
源码分析:


接口信息:
url: /session/$sessionId/element
method: POST
content_type: application/json
请求参数:
{
"using": "xpath", // 定位方式
"value": "//input[@id='kw']" // 值
}
接口调用:

输入文本
Selenium脚本:
driver.find_element(By.XPATH, '//input[@type="text"]').send_keys("测试蔡坨坨")
源码分析:


接口信息:
url: /session/$sessionId/element/$id/value
method: POST
content_type: application/json
请求参数:

接口调用:
点击元素
Selenium脚本:
driver.find_element(By.XPATH, "//input[@id='su']").click()
源码分析:

接口信息:
url: /session/$sessionId/element/$id/click
method: POST
content_type: application/json
接口调用:

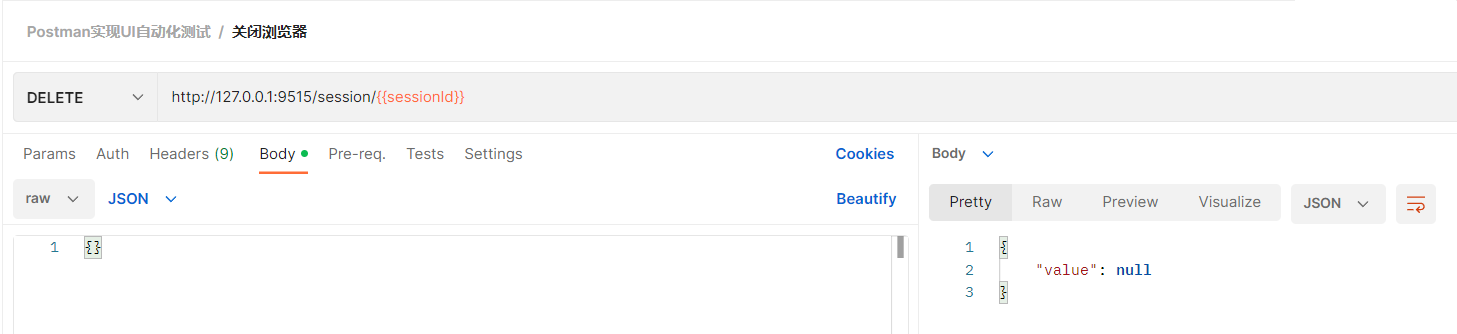
关闭浏览器
Selenium脚本:
driver.quit()
源码分析:

接口信息:
url: /session/$sessionId
method: DELETE
content_type: application/json
接口调用:
postman_collection.json
现阶段很多人都在说软件测试太内卷了,工作太难找了,竞争太激烈了。那么如何在这样的现状下使得自己更具有竞争力呢?笔者认为大家需要迅速学习软件测试的硬技能,提升自己的业务能力,早日摆脱初中级测试的Title,虽然测试人员众多,但是高级的软件测试人员还是很稀缺,有很多人挂着高级测试的头衔却还在干着初中级测试的活。在掌握这些硬技能的同时,软技能的培养同样重要,沟通能力、自主学习能力越来越被企业看重。
如果不想被这个时代淘汰,就要做好持续学习的准备。下方给大家准备了全套的软件测试,自动化测试全套教程。


很好奇,就使用rubyonrails自动化单元测试而言,你们正在做什么?您是否创建了一个脚本来在cron中运行rake作业并将结果邮寄给您?git中的预提交Hook?只是手动调用?我完全理解测试,但想知道在错误发生之前捕获错误的最佳实践是什么。让我们理所当然地认为测试本身是完美无缺的,并且可以正常工作。下一步是什么以确保他们在正确的时间将可能有害的结果传达给您? 最佳答案 不确定您到底想听什么,但是有几个级别的自动代码库控制:在处理某项功能时,您可以使用类似autotest的内容获得关于哪些有效,哪些无效的即时反馈。要确保您的提
我正在使用i18n从头开始构建一个多语言网络应用程序,虽然我自己可以处理一大堆yml文件,但我说的语言(非常)有限,最终我想寻求外部帮助帮助。我想知道这里是否有人在使用UI插件/gem(与django上的django-rosetta不同)来处理多个翻译器,其中一些翻译器不愿意或无法处理存储库中的100多个文件,处理语言数据。谢谢&问候,安德拉斯(如果您已经在rubyonrails-talk上遇到了这个问题,我们深表歉意) 最佳答案 有一个rails3branchofthetolkgem在github上。您可以通过在Gemfi
我正在编写一个包含C扩展的gem。通常当我写一个gem时,我会遵循TDD的过程,我会写一个失败的规范,然后处理代码直到它通过,等等......在“ext/mygem/mygem.c”中我的C扩展和在gemspec的“扩展”中配置的有效extconf.rb,如何运行我的规范并仍然加载我的C扩展?当我更改C代码时,我需要采取哪些步骤来重新编译代码?这可能是个愚蠢的问题,但是从我的gem的开发源代码树中输入“bundleinstall”不会构建任何native扩展。当我手动运行rubyext/mygem/extconf.rb时,我确实得到了一个Makefile(在整个项目的根目录中),然后当
我有一个围绕一些对象的包装类,我想将这些对象用作散列中的键。包装对象和解包装对象应映射到相同的键。一个简单的例子是这样的:classAattr_reader:xdefinitialize(inner)@inner=innerenddefx;@inner.x;enddef==(other)@inner.x==other.xendenda=A.new(o)#oisjustanyobjectthatallowso.xb=A.new(o)h={a=>5}ph[a]#5ph[b]#nil,shouldbe5ph[o]#nil,shouldbe5我试过==、===、eq?并散列所有无济于事。
我有一些Ruby代码,如下所示:Something.createdo|x|x.foo=barend我想编写一个测试,它使用double代替block参数x,这样我就可以调用:x_double.should_receive(:foo).with("whatever").这可能吗? 最佳答案 specify'something'dox=doublex.should_receive(:foo=).with("whatever")Something.should_receive(:create).and_yield(x)#callthere
Sinatra新手;我正在运行一些rspec测试,但在日志中收到了一堆不需要的噪音。如何消除日志中过多的噪音?我仔细检查了环境是否设置为:test,这意味着记录器级别应设置为WARN而不是DEBUG。spec_helper:require"./app"require"sinatra"require"rspec"require"rack/test"require"database_cleaner"require"factory_girl"set:environment,:testFactoryGirl.definition_file_paths=%w{./factories./test/
我遵循MichaelHartl的“RubyonRails教程:学习Web开发”,并创建了检查用户名和电子邮件长度有效性的测试(名称最多50个字符,电子邮件最多255个字符)。test/helpers/application_helper_test.rb的内容是:require'test_helper'classApplicationHelperTest在运行bundleexecraketest时,所有测试都通过了,但我看到以下消息在最后被标记为错误:ERROR["test_full_title_helper",ApplicationHelperTest,1.820016791]test
我有一个用户工厂。我希望默认情况下确认用户。但是鉴于unconfirmed特征,我不希望它们被确认。虽然我有一个基于实现细节而不是抽象的工作实现,但我想知道如何正确地做到这一点。factory:userdoafter(:create)do|user,evaluator|#unwantedimplementationdetailshereunlessFactoryGirl.factories[:user].defined_traits.map(&:name).include?(:unconfirmed)user.confirm!endendtrait:unconfirmeddoenden
我已经构建了一些serverspec代码来在多个主机上运行一组测试。问题是当任何测试失败时,测试会在当前主机停止。即使测试失败,我也希望它继续在所有主机上运行。Rakefile:namespace:specdotask:all=>hosts.map{|h|'spec:'+h.split('.')[0]}hosts.eachdo|host|begindesc"Runserverspecto#{host}"RSpec::Core::RakeTask.new(host)do|t|ENV['TARGET_HOST']=hostt.pattern="spec/cfengine3/*_spec.r
我在app/helpers/sessions_helper.rb中有一个帮助程序文件,其中包含一个方法my_preference,它返回当前登录用户的首选项。我想在集成测试中访问该方法。例如,这样我就可以在测试中使用getuser_path(my_preference)。在其他帖子中,我读到这可以通过在测试文件中包含requiresessions_helper来实现,但我仍然收到错误NameError:undefinedlocalvariableormethod'my_preference'.我做错了什么?require'test_helper'require'sessions_hel