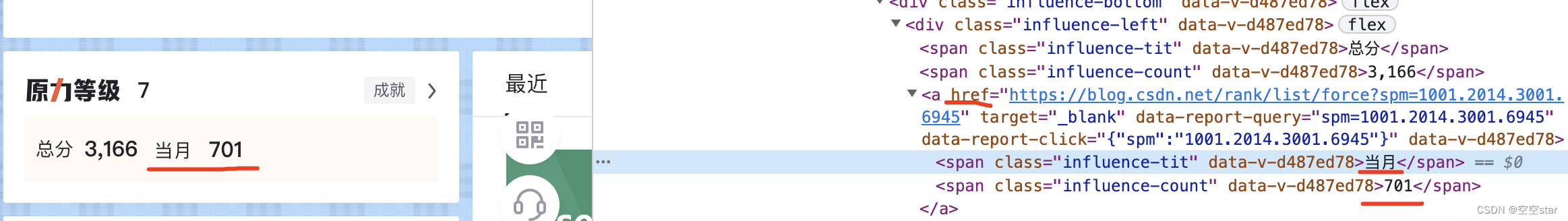文章目录
大家好,我是空空star,本篇给大家分享一下Selenium八大元素定位方式。
本篇使用的selenium版本如下:
Version: 4.8.2
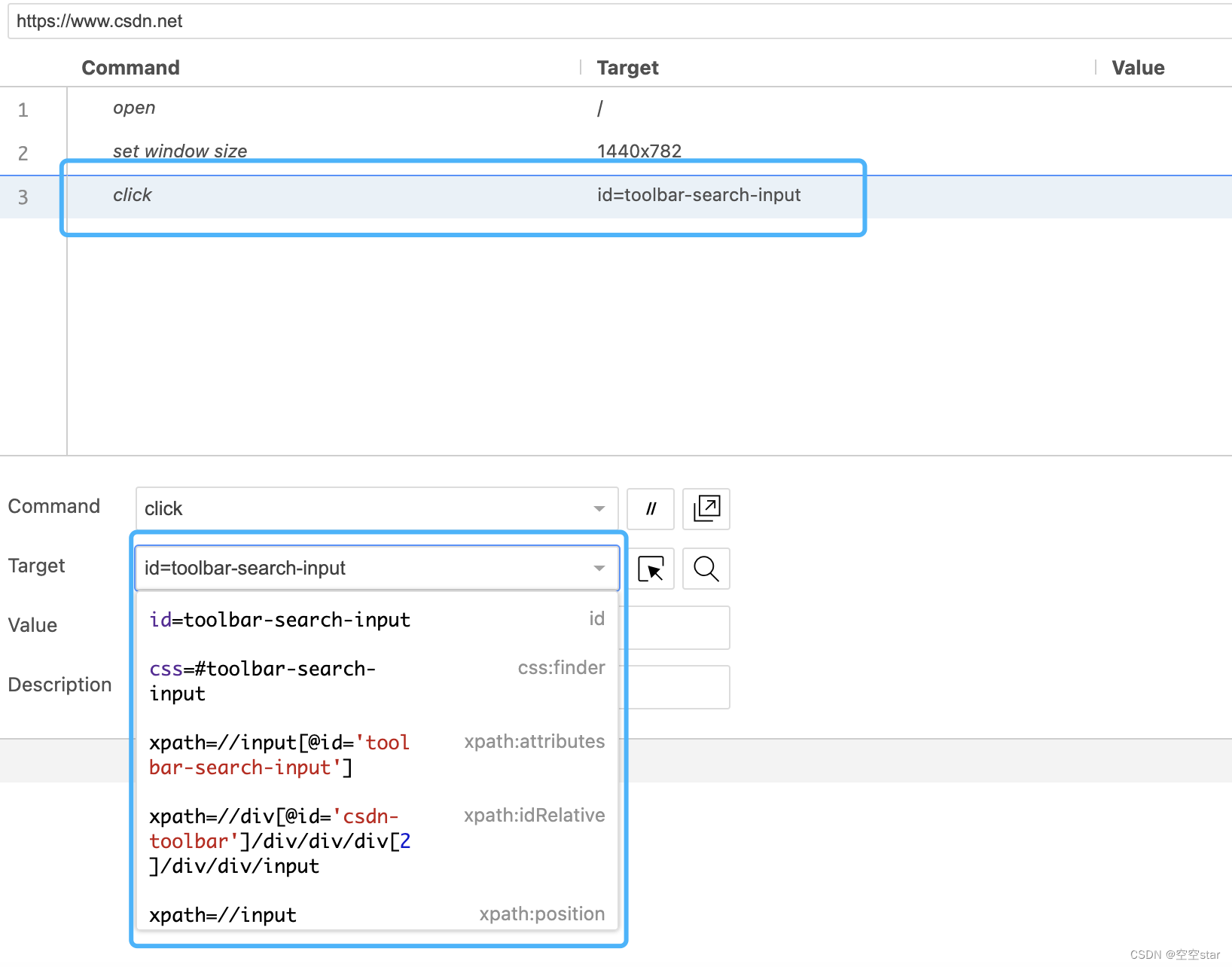
这里以C站首页toolbar输入框元素为例


使用selenium IDE打开我们要获取元素的页面,在该页面进行的一系列操作都记录下来,找到点击首页toolbar输入框的这一步,Target中有获取该元素的各种方式。
driver.find_element(By.ID, '元素id值')
driver.find_elements(By.ID, '元素id值')[index]
通过ID定位到我的个人主页toolbar输入框,输入 空空star
from selenium import webdriver
from time import sleep
from selenium.webdriver.common.by import By
# 启动浏览器实例,创建webdriver对象
driver = webdriver.Chrome()
# 打开网页
driver.get('https://blog.csdn.net/weixin_38093452')
# 窗口最大化
driver.maximize_window()
# 隐式等待5秒
driver.implicitly_wait(5)
# 通过id定位到toolbar输入框元素
search = driver.find_element(By.ID, 'toolbar-search-input')
# 向输入框输入 空空star
search.send_keys('空空star')
sleep(5)
# 结束webdriver进程
driver.quit()

driver.find_element(By.NAME, 'name属性值')
driver.find_elements(By.NAME, 'name属性值')[index]
通过NAME定位到搜索输入框,输入 空空star
from selenium import webdriver
from time import sleep
from selenium.webdriver.common.by import By
# 启动浏览器实例,创建webdriver对象
driver = webdriver.Chrome()
# 打开网页
driver.get('https://so.csdn.net/')
# 窗口最大化
driver.maximize_window()
# 隐式等待5秒
driver.implicitly_wait(5)
keyword = driver.find_element(By.NAME, 'keyword')
keyword.send_keys('空空star')
sleep(5)
# 结束webdriver进程
driver.quit()

driver.find_element(By.CLASS_NAME, '元素class的值')
driver.find_elements(By.CLASS_NAME, '元素class的值')[index]
通过CLASS_NAME定位到我的码龄
from selenium import webdriver
from time import sleep
from selenium.webdriver.common.by import By
# 启动浏览器实例,创建webdriver对象
driver = webdriver.Chrome()
# 打开网页
driver.get('https://blog.csdn.net/weixin_38093452')
# 窗口最大化
driver.maximize_window()
# 隐式等待5秒
driver.implicitly_wait(5)
age = driver.find_element(By.CLASS_NAME, 'person-code-age')
print(age.text)
sleep(5)
# 结束webdriver进程
driver.quit()

driver.find_element(By.TAG_NAME, '元素tag名称')
driver.find_elements(By.TAG_NAME, '元素tag名称')[index]
通过TAG_NAME定位到我的个人主页toolbar输入框,输入 通过tag输入空空star
虽然个人主页页面中有多个input框,但是toolbar的input框是第一个,所以直接用find_element就可以,如果不在第一个,就需要find_elements,然后指定索引就可以。
from selenium import webdriver
from time import sleep
from selenium.webdriver.common.by import By
# 启动浏览器实例,创建webdriver对象
driver = webdriver.Chrome()
# 打开网页
driver.get('https://blog.csdn.net/weixin_38093452')
# 窗口最大化
driver.maximize_window()
# 隐式等待5秒
driver.implicitly_wait(5)
driver.find_element(By.TAG_NAME, 'input').send_keys('通过tag输入空空star')
# driver.find_elements(By.TAG_NAME, 'input')[0].send_keys('通过tag输入空空star')
sleep(5)
# 结束webdriver进程
driver.quit()

用于定位部分链接文本匹配的元素
driver.find_element(By.PARTIAL_LINK_TEXT, '模糊匹配的链接文本')
driver.find_elements(By.PARTIAL_LINK_TEXT, '模糊匹配的链接文本')[index]
通过PARTIAL_LINK_TEXT定位到我的当月原力
from selenium import webdriver
from time import sleep
from selenium.webdriver.common.by import By
# 启动浏览器实例,创建webdriver对象
driver = webdriver.Chrome()
# 打开网页
driver.get('https://blog.csdn.net/weixin_38093452')
# 窗口最大化
driver.maximize_window()
# 隐式等待5秒
driver.implicitly_wait(5)
name = driver.find_element(By.PARTIAL_LINK_TEXT, '当月')
print(name.text)
sleep(5)
# 结束webdriver进程
driver.quit()

查找具有完全匹配链接文本的元素
driver.find_element(By.LINK_TEXT, '完全匹配的链接文本')
driver.find_elements(By.LINK_TEXT, '完全匹配的链接文本')[index]
通过LINK_TEXT定位到猿如意这个元素
from selenium import webdriver
from time import sleep
from selenium.webdriver.common.by import By
# 启动浏览器实例,创建webdriver对象
driver = webdriver.Chrome()
# 打开网页
driver.get('https://blog.csdn.net/weixin_38093452')
# 窗口最大化
driver.maximize_window()
# 隐式等待5秒
driver.implicitly_wait(5)
name = driver.find_element(By.LINK_TEXT, '猿如意')
print(name.text)
sleep(5)
# 结束webdriver进程
driver.quit()

driver.find_element(By.XPATH, 'XPATH表达式')
driver.find_elements(By.XPATH, 'XPATH表达式')[index]
通过XPATH定位到我的昵称
from selenium import webdriver
from time import sleep
from selenium.webdriver.common.by import By
# 启动浏览器实例,创建webdriver对象
driver = webdriver.Chrome()
# 打开网页
driver.get('https://blog.csdn.net/weixin_38093452')
# 窗口最大化
driver.maximize_window()
# 隐式等待5秒
driver.implicitly_wait(5)
name = driver.find_element(By.XPATH, '//*[@id="userSkin"]/div[1]/div[2]/div[1]/div[1]/div[2]/div[1]/div/div[1]')
print(name.text)
sleep(5)
# 结束webdriver进程
driver.quit()

driver.find_element(By.CSS_SELECTOR, 'CSS选择器')
driver.find_elements(By.CSS_SELECTOR, 'CSS选择器')[index]
通过css选择器定位到原力总分元素
from selenium import webdriver
from time import sleep
from selenium.webdriver.common.by import By
# 启动浏览器实例,创建webdriver对象
driver = webdriver.Chrome()
# 打开网页
driver.get('https://blog.csdn.net/weixin_38093452')
# 窗口最大化
driver.maximize_window()
# 隐式等待5秒
driver.implicitly_wait(5)
name = driver.find_element(By.CSS_SELECTOR, '#userSkin > div.user-profile-body > div > div.user-profile-body-left > div > div.user-influence-list > ul > li > div.influence-bottom > div > span.influence-count')
print(name.text)
sleep(5)
# 结束webdriver进程
driver.quit()
| 八大元素定位方式 |
|---|
| ID |
| NAME |
| CLASS_NAME |
| TAG_NAME |
| PARTIAL_LINK_TEXT |
| LINK_TEXT |
| XPATH |
| CSS_SELECTOR |
我试图获取一个长度在1到10之间的字符串,并输出将字符串分解为大小为1、2或3的连续子字符串的所有可能方式。例如:输入:123456将整数分割成单个字符,然后继续查找组合。该代码将返回以下所有数组。[1,2,3,4,5,6][12,3,4,5,6][1,23,4,5,6][1,2,34,5,6][1,2,3,45,6][1,2,3,4,56][12,34,5,6][12,3,45,6][12,3,4,56][1,23,45,6][1,2,34,56][1,23,4,56][12,34,56][123,4,5,6][1,234,5,6][1,2,345,6][1,2,3,456][123
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
question的一些答案关于redirect_to让我想到了其他一些问题。基本上,我正在使用Rails2.1编写博客应用程序。我一直在尝试自己完成大部分工作(因为我对Rails有所了解),但在需要时会引用Internet上的教程和引用资料。我设法让一个简单的博客正常运行,然后我尝试添加评论。靠我自己,我设法让它进入了可以从script/console添加评论的阶段,但我无法让表单正常工作。我遵循的其中一个教程建议在帖子Controller中创建一个“评论”操作,以添加评论。我的问题是:这是“标准”方式吗?我的另一个问题的答案之一似乎暗示应该有一个CommentsController参
查看我的Ruby代码:h=Hash.new([])h[0]=:word1h[1]=h[1]输出是:Hash={0=>:word1,1=>[:word2,:word3],2=>[:word2,:word3]}我希望有Hash={0=>:word1,1=>[:word2],2=>[:word3]}为什么要附加第二个哈希元素(数组)?如何将新数组元素附加到第三个哈希元素? 最佳答案 如果您提供单个值作为Hash.new的参数(例如Hash.new([]),完全相同的对象将用作每个缺失键的默认值。这就是您所拥有的,那是你不想要的。您可以改用
在应用开发中,有时候我们需要获取系统的设备信息,用于数据上报和行为分析。那在鸿蒙系统中,我们应该怎么去获取设备的系统信息呢,比如说获取手机的系统版本号、手机的制造商、手机型号等数据。1、获取方式这里分为两种情况,一种是设备信息的获取,一种是系统信息的获取。1.1、获取设备信息获取设备信息,鸿蒙的SDK包为我们提供了DeviceInfo类,通过该类的一些静态方法,可以获取设备信息,DeviceInfo类的包路径为:ohos.system.DeviceInfo.具体的方法如下:ModifierandTypeMethodDescriptionstatic StringgetAbiList()Obt
本文主要介绍在使用Selenium进行自动化测试或者任务时,对于使用了iframe的页面,如何定位iframe中的元素文章目录场景描述解决方案具体代码场景描述当我们在使用Selenium进行自动化测试的时候,可能会遇到一些界面或者窗体是使用HTML的iframe标签进行承载的。对于iframe中的标签,如果直接查找是无法找到的,会抛出没有找到元素的异常。比如近在咫尺的例子就是,CSDN的登录窗体就是使用的iframe,大家可以尝试通过F12开发者模式查看到的tag_name,class_name,id或者xpath来定位中的页面元素,会抛出NoSuchElementException异常。解决
1.postman介绍Postman一款非常流行的API调试工具。其实,开发人员用的更多。因为测试人员做接口测试会有更多选择,例如Jmeter、soapUI等。不过,对于开发过程中去调试接口,Postman确实足够的简单方便,而且功能强大。2.下载安装官网地址:https://www.postman.com/下载完成后双击安装吧,安装过程极其简单,无需任何操作3.使用教程这里以百度为例,工具使用简单,填写URL地址即可发送请求,在下方查看响应结果和响应状态码常用方法都有支持请求方法:getpostputdeleteGet、Post、Put与Delete的作用get:请求方法一般是用于数据查询,
Ⅰ软件测试基础一、软件测试基础理论1、软件测试的必要性所有的产品或者服务上线都需要测试2、测试的发展过程3、什么是软件测试找bug,发现缺陷4、测试的定义使用人工或自动的手段来运行或者测试某个系统的过程。目的在于检测它是否满足规定的需求。弄清预期结果和实际结果的差别。5、测试的目的以最小的人力、物力和时间找出软件中潜在的错误和缺陷6、测试的原则28原则:20%的主要功能要重点测(eg:支付宝的支付功能,其他功能都是次要的)80%的错误存在于20%的代码中7、测试标准8、测试的基本要求功能测试性能测试安全性测试兼容性测试易用性测试外观界面测试可靠性测试二、质量模型衡量一个优秀软件的维度①功能性功
ES一、简介1、ElasticStackES技术栈:ElasticSearch:存数据+搜索;QL;Kibana:Web可视化平台,分析。LogStash:日志收集,Log4j:产生日志;log.info(xxx)。。。。使用场景:metrics:指标监控…2、基本概念Index(索引)动词:保存(插入)名词:类似MySQL数据库,给数据Type(类型)已废弃,以前类似MySQL的表现在用索引对数据分类Document(文档)真正要保存的一个JSON数据{name:"tcx"}二、入门实战{"name":"DESKTOP-1TSVGKG","cluster_name":"elasticsear
我有一个使用SeleniumWebdriver和Nokogiri的Ruby应用程序。我想选择一个类,然后对于那个类对应的每个div,我想根据div的内容执行一个Action。例如,我正在解析以下页面:https://www.google.com/webhp?sourceid=chrome-instant&ion=1&espv=2&ie=UTF-8#q=puppies这是一个搜索结果页面,我正在寻找描述中包含“Adoption”一词的第一个结果。因此机器人应该寻找带有className:"result"的div,对于每个检查它的.descriptiondiv是否包含单词“adoption