作者:ThinkingKeep
链接:https://juejin.cn/post/7118954784853327903
细心的朋友应该会发现,最近,继新浪微博之后,头条、腾讯、抖音、知乎、快手、小红书等各大平台陆陆续续都上线了“网络用户IP地址显示功能”,境外用户显示的是国家,国内的用户显示的省份,而且此项显示无法关闭,归属地强制显示。
作为技术人,那!这个功能要怎么实现呢?
首先需要写一个 IP 获取的工具类,因为每一次用户的 Request 请求,都会携带上请求的 IP 地址放到请求头中
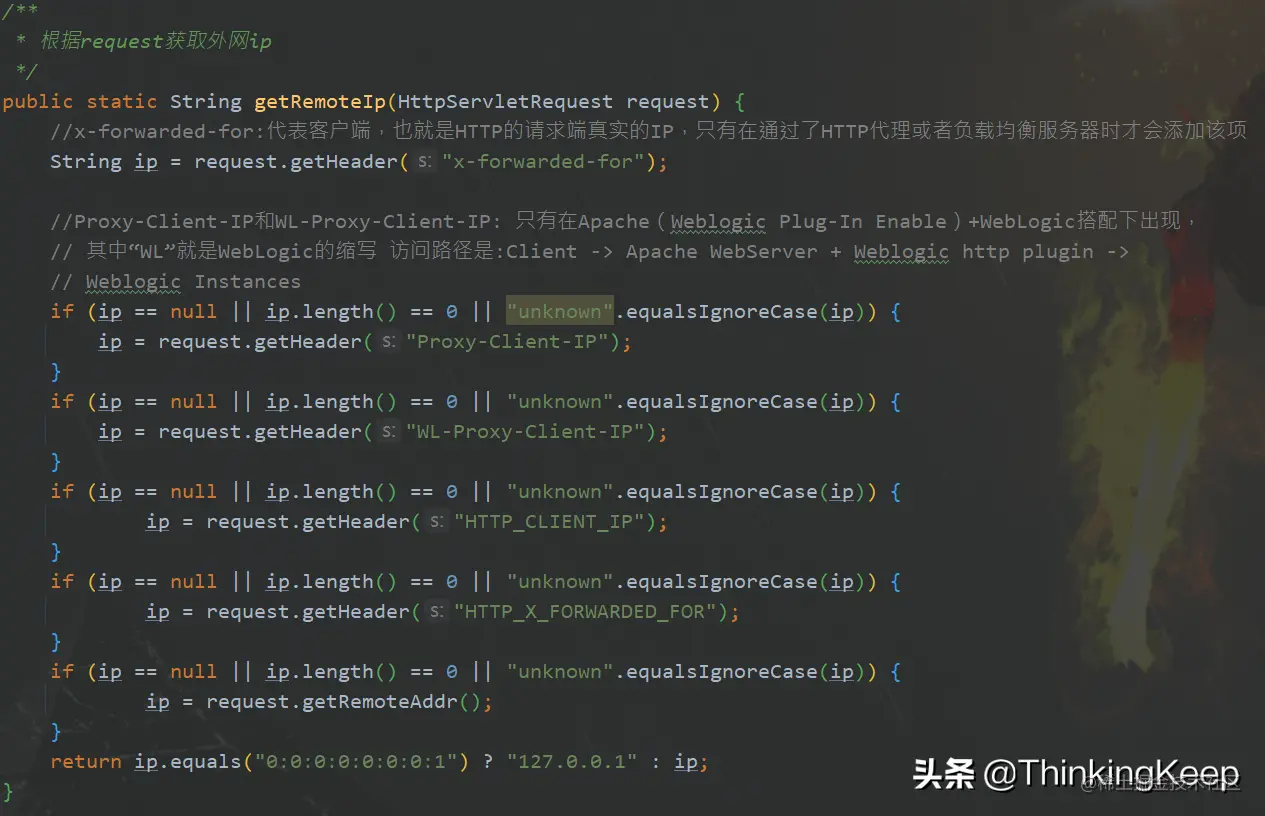
通过此方法,从请求Header中获取到用户的IP地址
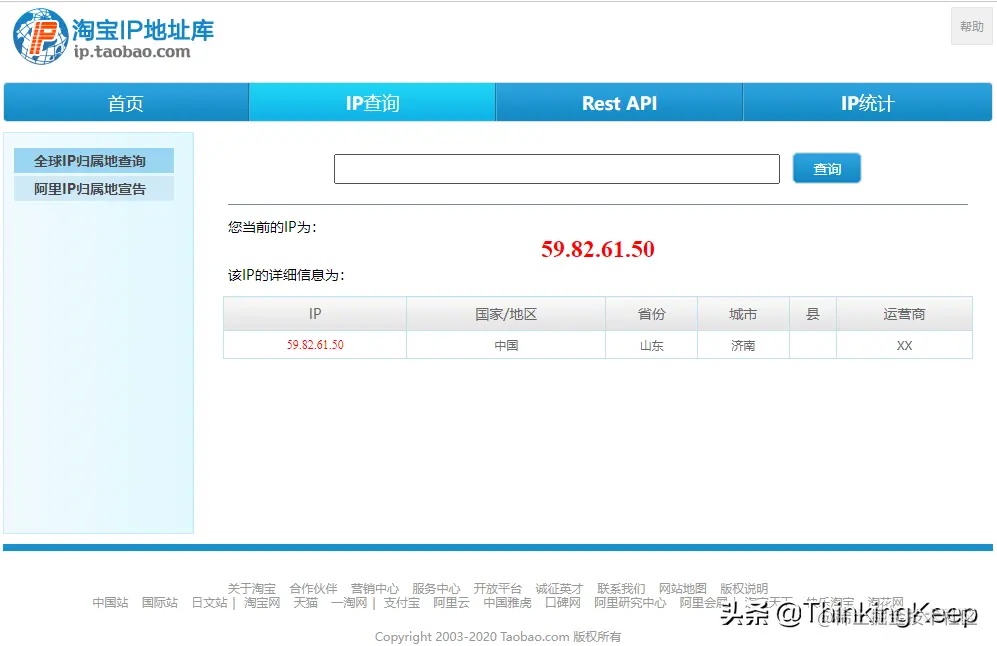
目前本人在做的项目中,也有获取IP地址归属地省份、城市的需求,用的是:淘宝IP库
地址:ip.taobao.com/

原来的请求源码如下:
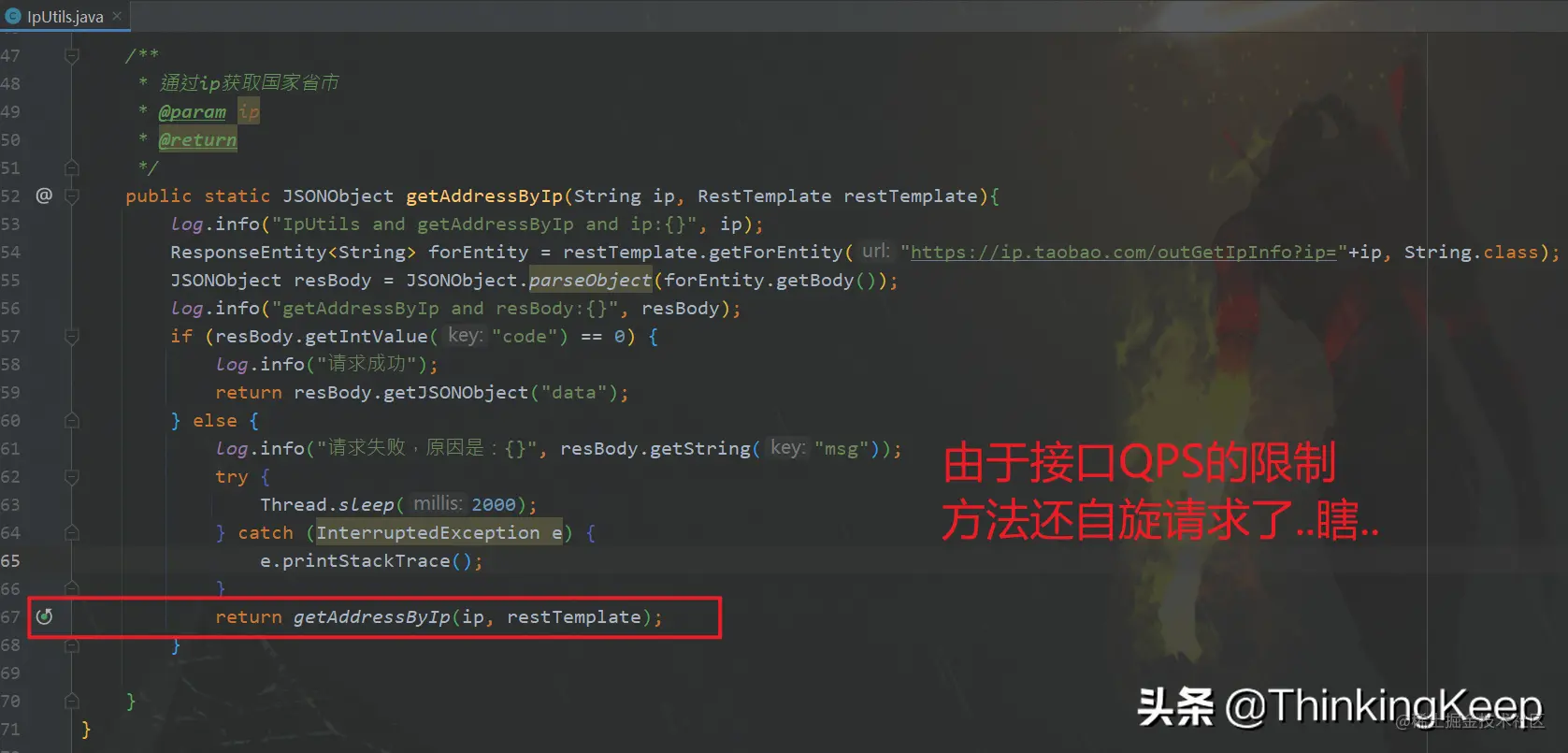
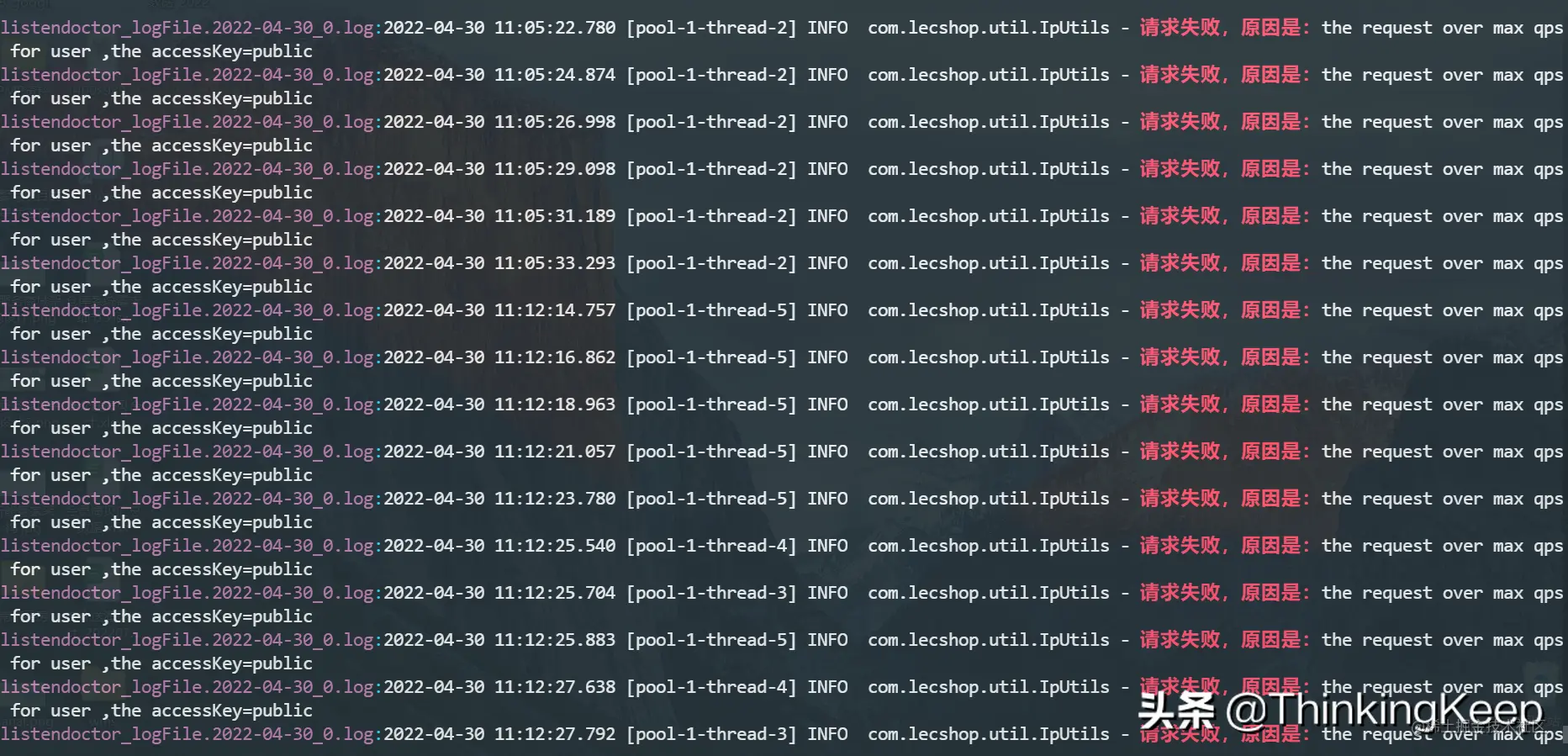
可以看到日志log文件中,大量的the request over max qps for user问题

目前最新已更新到了v2.0版本,ip2region v2.0是一个离线IP地址定位库和IP定位数据管理框架,10微秒级别的查询效率,准提供了众多主流编程语言的 xdb 数据生成和查询客户端实现。
数据聚合了一些知名ip到地名查询提供商的数据,这些是他们官方的的准确率,经测试着实比经典的纯真IP定位准确一些。
已经集成的客户端有:java、C#、php、c、python、nodejs、php扩展(php5和php7)、golang、rust、lua、lua_c, nginx。
| binding | 描述 | 开发状态 | binary查询耗时 | b-tree查询耗时 | memory查询耗时 |
|---|---|---|---|---|---|
| c | ANSC c binding | 已完成 | 0.0x毫秒 | 0.0x毫秒 | 0.00x毫秒 |
| c# | c# binding | 已完成 | 0.x毫秒 | 0.x毫秒 | 0.1x毫秒 |
| golang | golang binding | 已完成 | 0.x毫秒 | 0.x毫秒 | 0.1x毫秒 |
| java | java binding | 已完成 | 0.x毫秒 | 0.x毫秒 | 0.1x毫秒 |
| lua | lua实现的binding | 已完成 | 0.x毫秒 | 0.x毫秒 | 0.x毫秒 |
| lua_c | lua的c扩展 | 已完成 | 0.0x毫秒 | 0.0x毫秒 | 0.00x毫秒 |
| nginx | nginx的c扩展 | 已完成 | 0.0x毫秒 | 0.0x毫秒 | 0.00x毫秒 |
| nodejs | nodejs | 已完成 | 0.x毫秒 | 0.x毫秒 | 0.1x毫秒 |
| php | php实现的binding | 已完成 | 0.x毫秒 | 0.1x毫秒 | 0.1x毫秒 |
| php5_ext | php5的c扩展 | 已完成 | 0.0x毫秒 | 0.0x毫秒 | 0.00x毫秒 |
| php7_ext | php7的c扩展 | 已完成 | 0.0毫秒 | 0.0x毫秒 | 0.00x毫秒 |
| python | python bindng | 已完成 | 0.x毫秒 | 0.x毫秒 | 0.x毫秒 |
| rust | rust binding | 已完成 | 0.x毫秒 | 0.x毫秒 | 0.x毫秒 |
1、标准化的数据格式
每个 ip 数据段的 region 信息都固定了格式:国家|区域|省份|城市|ISP,只有中国的数据绝大部分精确到了城市,其他国家部分数据只能定位到国家,后前的选项全部是0。
2、数据去重和压缩
xdb 格式生成程序会自动去重和压缩部分数据,默认的全部 IP 数据,生成的 ip2region.xdb 数据库是 11MiB,随着数据的详细度增加数据库的大小也慢慢增大。
3、极速查询响应
即使是完全基于 xdb 文件的查询,单次查询响应时间在十微秒级别,可通过如下两种方式开启内存加速查询:
4、极速查询响应
v2.0 格式的 xdb 支持亿级别的 IP 数据段行数,region 信息也可以完全自定义,例如:你可以在 region 中追加特定业务需求的数据,例如:GPS信息/国际统一地域信息编码/邮编等。也就是你完全可以使用 ip2region 来管理你自己的 IP 定位数据。
引入maven仓库:
<dependency>
<groupId>org.lionsoul</groupId>
<artifactId>ip2region</artifactId>
<version>2.6.4</version>
</dependency>
import org.lionsoul.ip2region.xdb.Searcher;
import java.io.*;
import java.util.concurrent.TimeUnit;
public class SearcherTest {
public static void main(String[] args) {
// 1、创建 searcher 对象
String dbPath = "ip2region.xdb file path";
Searcher searcher = null;
try {
searcher = Searcher.newWithFileOnly(dbPath);
} catch (IOException e) {
System.out.printf("failed to create searcher with `%s`: %s\n", dbPath, e);
return;
}
// 2、查询
try {
String ip = "1.2.3.4";
long sTime = System.nanoTime();
String region = searcher.search(ip);
long cost = TimeUnit.NANOSECONDS.toMicros((long) (System.nanoTime() - sTime));
System.out.printf("{region: %s, ioCount: %d, took: %d μs}\n", region, searcher.getIOCount(), cost);
} catch (Exception e) {
System.out.printf("failed to search(%s): %s\n", ip, e);
}
// 3、备注:并发使用,每个线程需要创建一个独立的 searcher 对象单独使用。
}
}
我们可以提前从 xdb 文件中加载出来 VectorIndex 数据,然后全局缓存,每次创建 Searcher 对象的时候使用全局的 VectorIndex 缓存可以减少一次固定的 IO 操作,从而加速查询,减少 IO 压力。
import org.lionsoul.ip2region.xdb.Searcher;
import java.io.*;
import java.util.concurrent.TimeUnit;
public class SearcherTest {
public static void main(String[] args) {
String dbPath = "ip2region.xdb file path";
// 1、从 dbPath 中预先加载 VectorIndex 缓存,并且把这个得到的数据作为全局变量,后续反复使用。
byte[] vIndex;
try {
vIndex = Searcher.loadVectorIndexFromFile(dbPath);
} catch (Exception e) {
System.out.printf("failed to load vector index from `%s`: %s\n", dbPath, e);
return;
}
// 2、使用全局的 vIndex 创建带 VectorIndex 缓存的查询对象。
Searcher searcher;
try {
searcher = Searcher.newWithVectorIndex(dbPath, vIndex);
} catch (Exception e) {
System.out.printf("failed to create vectorIndex cached searcher with `%s`: %s\n", dbPath, e);
return;
}
// 3、查询
try {
String ip = "1.2.3.4";
long sTime = System.nanoTime();
String region = searcher.search(ip);
long cost = TimeUnit.NANOSECONDS.toMicros((long) (System.nanoTime() - sTime));
System.out.printf("{region: %s, ioCount: %d, took: %d μs}\n", region, searcher.getIOCount(), cost);
} catch (Exception e) {
System.out.printf("failed to search(%s): %s\n", ip, e);
}
// 备注:每个线程需要单独创建一个独立的 Searcher 对象,但是都共享全局的制度 vIndex 缓存。
}
}
我们也可以预先加载整个 ip2region.xdb 的数据到内存,然后基于这个数据创建查询对象来实现完全基于文件的查询,类似之前的 memory search。
import org.lionsoul.ip2region.xdb.Searcher;
import java.io.*;
import java.util.concurrent.TimeUnit;
public class SearcherTest {
public static void main(String[] args) {
String dbPath = "ip2region.xdb file path";
// 1、从 dbPath 加载整个 xdb 到内存。
byte[] cBuff;
try {
cBuff = Searcher.loadContentFromFile(dbPath);
} catch (Exception e) {
System.out.printf("failed to load content from `%s`: %s\n", dbPath, e);
return;
}
// 2、使用上述的 cBuff 创建一个完全基于内存的查询对象。
Searcher searcher;
try {
searcher = Searcher.newWithBuffer(cBuff);
} catch (Exception e) {
System.out.printf("failed to create content cached searcher: %s\n", e);
return;
}
// 3、查询
try {
String ip = "1.2.3.4";
long sTime = System.nanoTime();
String region = searcher.search(ip);
long cost = TimeUnit.NANOSECONDS.toMicros((long) (System.nanoTime() - sTime));
System.out.printf("{region: %s, ioCount: %d, took: %d μs}\n", region, searcher.getIOCount(), cost);
} catch (Exception e) {
System.out.printf("failed to search(%s): %s\n", ip, e);
}
// 备注:并发使用,用整个 xdb 数据缓存创建的查询对象可以安全的用于并发,也就是你可以把这个 searcher 对象做成全局对象去跨线程访问。
}
}
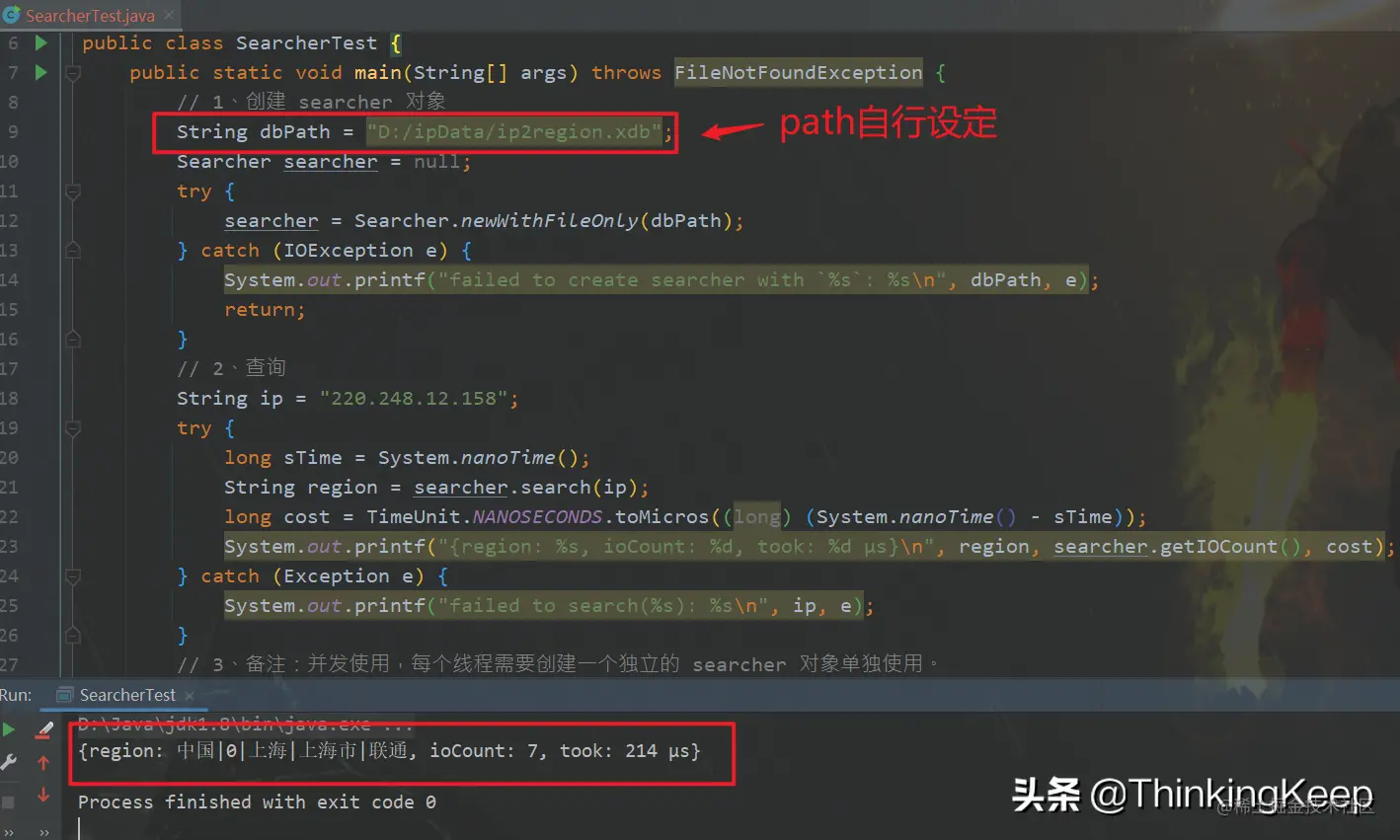
完全基于文件的查询
ip属地国内的话,会展示省份,国外的话,只会展示国家。可以通过如下图这个方法进行进一步封装,得到获取IP属地的信息。
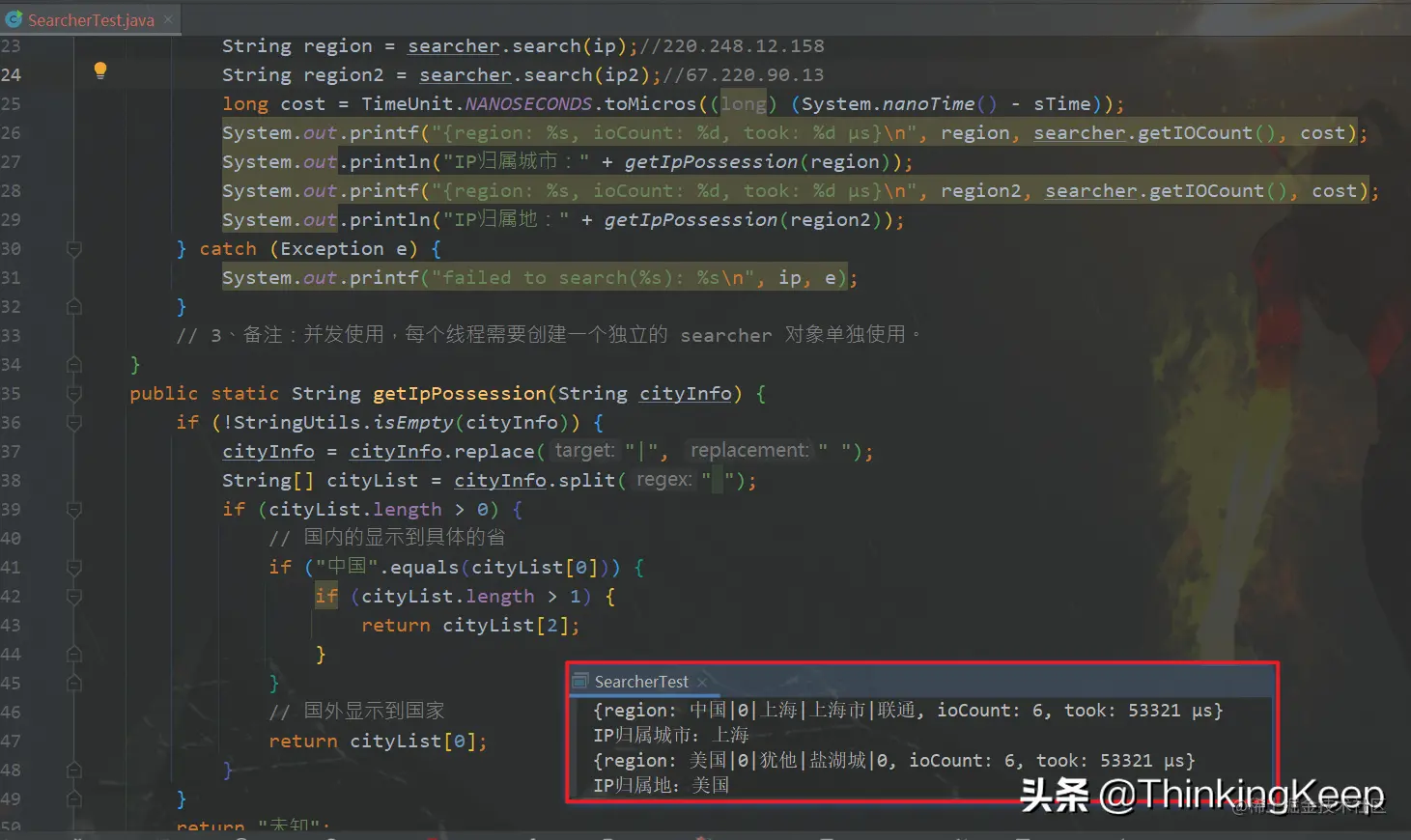
下面是官网给出的命令运行jar方式给出的测试demo,可以理解下
通过 maven 来编译测试程序。
# cd 到 java binding 的根目录
cd binding/java/
mvn compile package
然后会在当前目录的 target 目录下得到一个 ip2region-{version}.jar 的打包文件。
可以通过 java -jar ip2region-{version}.jar search 命令来测试查询:
➜ java git:(v2.0_xdb) ✗ java -jar target/ip2region-2.6.0.jar search
java -jar ip2region-{version}.jar search [command options]
options:
--db string ip2region binary xdb file path
--cache-policy string cache policy: file/vectorIndex/content
例如:使用默认的 data/ip2region.xdb 文件进行查询测试:
➜ java git:(v2.0_xdb) ✗ java -jar target/ip2region-2.6.0.jar search --db=../../data/ip2region.xdb
ip2region xdb searcher test program, cachePolicy: vectorIndex
type 'quit' to exit
ip2region>> 1.2.3.4
{region: 美国|0|华盛顿|0|谷歌, ioCount: 7, took: 82 μs}
ip2region>>
输入 ip 即可进行查询测试,也可以分别设置 cache-policy 为 file/vectorIndex/content 来测试三种不同缓存实现的查询效果。
可以通过 java -jar ip2region-{version}.jar bench 命令来进行 bench 测试,一方面确保 xdb 文件没有错误,一方面可以评估查询性能:
➜ java git:(v2.0_xdb) ✗ java -jar target/ip2region-2.6.0.jar bench
java -jar ip2region-{version}.jar bench [command options]
options:
--db string ip2region binary xdb file path
--src string source ip text file path
--cache-policy string cache policy: file/vectorIndex/content
例如:通过默认的 data/ip2region.xdb 和 data/ip.merge.txt 文件进行 bench 测试:
➜ java git:(v2.0_xdb) ✗ java -jar target/ip2region-2.6.0.jar bench --db=../../data/ip2region.xdb --src=../../data/ip.merge.txt
Bench finished, {cachePolicy: vectorIndex, total: 3417955, took: 8s, cost: 2 μs/op}
可以通过分别设置 cache-policy 为 file/vectorIndex/content 来测试三种不同缓存实现的效果。 @Note: 注意 bench 使用的 src 文件要是生成对应 xdb 文件相同的源文件。
到这里获取用户IP属地已经完成啦,这篇文章介绍的v2.0版本,有兴趣的小伙伴可以登录上门的github地址了解下v1.0版本
如若觉得有用,欢迎收藏+点赞,如遇到什么问题,欢迎留言讨论
近期热文推荐:
1.1,000+ 道 Java面试题及答案整理(2022最新版)
4.别再写满屏的爆爆爆炸类了,试试装饰器模式,这才是优雅的方式!!
觉得不错,别忘了随手点赞+转发哦!
使用带有Rails插件的vim,您可以创建一个迁移文件,然后一次性打开该文件吗?textmate也可以这样吗? 最佳答案 你可以使用rails.vim然后做类似的事情::Rgeneratemigratonadd_foo_to_bar插件将打开迁移生成的文件,这正是您想要的。我不能代表textmate。 关于ruby-使用VimRails,您可以创建一个新的迁移文件并一次性打开它吗?,我们在StackOverflow上找到一个类似的问题: https://sta
我需要从一个View访问多个模型。以前,我的links_controller仅用于提供以不同方式排序的链接资源。现在我想包括一个部分(我假设)显示按分数排序的顶级用户(@users=User.all.sort_by(&:score))我知道我可以将此代码插入每个链接操作并从View访问它,但这似乎不是“ruby方式”,我将需要在不久的将来访问更多模型。这可能会变得很脏,是否有针对这种情况的任何技术?注意事项:我认为我的应用程序正朝着单一格式和动态页面内容的方向发展,本质上是一个典型的网络应用程序。我知道before_filter但考虑到我希望应用程序进入的方向,这似乎很麻烦。最终从任何
我想要做的是有2个不同的Controller,client和test_client。客户端Controller已经构建,我想创建一个test_clientController,我可以使用它来玩弄客户端的UI并根据需要进行调整。我主要是想绕过我在客户端中内置的验证及其对加载数据的管理Controller的依赖。所以我希望test_clientController加载示例数据集,然后呈现客户端Controller的索引View,以便我可以调整客户端UI。就是这样。我在test_clients索引方法中试过这个:classTestClientdefindexrender:template=>
如果您尝试在Ruby中的nil对象上调用方法,则会出现NoMethodError异常并显示消息:"undefinedmethod‘...’fornil:NilClass"然而,有一个tryRails中的方法,如果它被发送到一个nil对象,它只返回nil:require'rubygems'require'active_support/all'nil.try(:nonexisting_method)#noNoMethodErrorexceptionanymore那么try如何在内部工作以防止该异常? 最佳答案 像Ruby中的所有其他对象
关闭。这个问题需要detailsorclarity.它目前不接受答案。想改进这个问题吗?通过editingthispost添加细节并澄清问题.关闭8年前。Improvethisquestion为什么SecureRandom.uuid创建一个唯一的字符串?SecureRandom.uuid#=>"35cb4e30-54e1-49f9-b5ce-4134799eb2c0"SecureRandom.uuid方法创建的字符串从不重复?
我有一个正在构建的应用程序,我需要一个模型来创建另一个模型的实例。我希望每辆车都有4个轮胎。汽车模型classCar轮胎模型classTire但是,在make_tires内部有一个错误,如果我为Tire尝试它,则没有用于创建或新建的activerecord方法。当我检查轮胎时,它没有这些方法。我该如何补救?错误是这样的:未定义的方法'create'forActiveRecord::AttributeMethods::Serialization::Tire::Module我测试了两个环境:测试和开发,它们都因相同的错误而失败。 最佳答案
我有一个存储主机名的Ruby数组server_names。如果我打印出来,它看起来像这样:["hostname.abc.com","hostname2.abc.com","hostname3.abc.com"]相当标准。我想要做的是获取这些服务器的IP(可能将它们存储在另一个变量中)。看起来IPSocket类可以做到这一点,但我不确定如何使用IPSocket类遍历它。如果它只是尝试像这样打印出IP:server_names.eachdo|name|IPSocket::getaddress(name)pnameend它提示我没有提供服务器名称。这是语法问题还是我没有正确使用类?输出:ge
我想在Ruby中创建一个用于开发目的的极其简单的Web服务器(不,不想使用现成的解决方案)。代码如下:#!/usr/bin/rubyrequire'socket'server=TCPServer.new('127.0.0.1',8080)whileconnection=server.acceptheaders=[]length=0whileline=connection.getsheaders想法是从命令行运行这个脚本,提供另一个脚本,它将在其标准输入上获取请求,并在其标准输出上返回完整的响应。到目前为止一切顺利,但事实证明这真的很脆弱,因为它在第二个请求上中断并出现错误:/usr/b
我想让一个yaml对象引用另一个,如下所示:intro:"Hello,dearuser."registration:$introThanksforregistering!new_message:$introYouhaveanewmessage!上面的语法只是它如何工作的一个例子(这也是它在thiscpanmodule中的工作方式。)我正在使用标准的rubyyaml解析器。这可能吗? 最佳答案 一些yaml对象确实引用了其他对象:irb>require'yaml'#=>trueirb>str="hello"#=>"hello"ir
我的问题的一个例子是体育游戏。一场体育比赛有两支球队,一支主队和一支客队。我的事件记录模型如下:classTeam"Team"has_one:away_team,:class_name=>"Team"end我希望能够通过游戏访问一个团队,例如:Game.find(1).home_team但我收到一个单元化常量错误:Game::team。谁能告诉我我做错了什么?谢谢, 最佳答案 如果Gamehas_one:team那么Rails假设您的teams表有一个game_id列。不过,您想要的是games表有一个team_id列,在这种情况下