之前我们对hdfs的操作主要是通过在linux命令行里进行的,而在实际的应用中,为了实现本地与HDFS 的文件传输,我们主要借助于eclipse的开发环境开发的javaAPI来实现对远程HDFS的文件创建,上传,下载和删除等操作
Hadoop中关于文件操作类基本上全部是在"org.apache.hadoop.fs"包中,Hadoop类库中最终面向用户提供的接口类是FileSystem,该类封装了几乎所有的文件操作,例如CopyToLocalFile、CopyFromLocalFile、mkdir及delete等。综上基本上可以得出操作文件的程序库框架:
operator( ) {
得到Configuration对象
得到FileSystem对象
进行文件操作
}
下面介绍实现上述程序库框架中各个操作的具体步骤
Java抽象类org.apache.hadoop.fs.FileSystem定义了hadoop的一个文件系统接口。该类是一个抽象类,通过以下两种静态工厂方法可以过去FileSystem实例:
public static FileSystem.get(Configuration conf) throws IOException
public static FileSystem.get(URI uri, Configuration conf) throws IOException
HDFS上的文件创建,上传,下载,删除等操作的具体方法实现:
(1)public boolean mkdirs(Path f) throws IOException
一次性新建所有目录(包括父目录), f是完整的目录路径。
(2)public FSOutputStream create(Path f) throws IOException
创建指定path对象的一个文件,返回一个用于写入数据的输出流
create()有多个重载版本,允许我们指定是否强制覆盖已有的文件、文件备份数量、写入文件缓冲区大小、文件块大小以及文件权限。
(3)public boolean copyFromLocal(Path src, Path dst) throws IOException
将本地文件拷贝到文件系统
(4)public boolean exists(Path f) throws IOException
检查文件或目录是否存在
(5)public boolean delete(Path f, Boolean recursive)
永久性删除指定的文件或目录,如果f是一个空目录或者文件,那么recursive的值就会被忽略。只有recursive=true时,一个非空目录及其内容才会被删除。
(6)FileStatus类封装了文件系统中文件和目录的元数据,包括文件长度、块大小、备份、修改时间、所有者以及权限信息
废话说了一大堆,还是直接上操作过程吧,就是简单的用java实现一个小的功能好在各个平台上都能运行。
首先前提条件是你要先把hadoop搭好,然后把hadoopAPI插件装到你的eclipse下
参考之前博客里的操作。
然后,再来看下面一波操作。
首先你要启动hadoop
./start-all.sh
然后需要下载hadoop的依赖包hadoop2lib.tar.gz,解压备用
新建JAVA项目,名为hadoop4

然后新建包
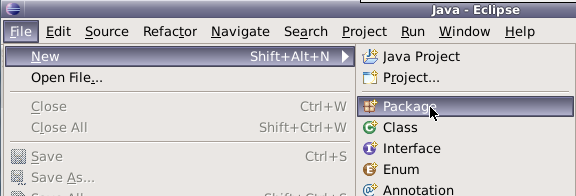
在hadoop4项目下创建目录,名为hadoop4lib,用于存放项目所需依赖包。


从hadoop2lib目录下拷贝所有jar包到项目下的hadoop4lib目录,就像这样
然后add to build path, 按住shift键选中第一个jar,然后点击最后一个,全选,右击,选择buildPath=》Add to Build Path,这样环境就准备好了
还记得新建的包吗?对,就是my.hdfs,再包里写自己的API就好了。其实就是新建类
比如:在my.hdfs包下,新建类MakeDir,程序功能是在HDFS的根目录下,创建名为hdfstest的目录。
package my.hdfs;
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
public class MakeDir {
public static void main(String[] args) throws IOException, URISyntaxException {
Configuration conf = new Configuration();
String hdfsPath = “hdfs://localhost:9000”;
FileSystem hdfs = FileSystem.get(new URI(hdfsPath), conf);
String newDir = “/hdfstest”;
boolean result = hdfs.mkdirs(new Path(newDir));
if (result) {
System.out.println(“Success!”);
}else {
System.out.println(“Failed!”);
}
}
}
新建类TouchFile,程序功能是在HDFS的目录/hdfstest下,创建名为touchfile的文件。
package my.hdfs;
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
public class TouchFile {
public static void main(String[] args) throws IOException, URISyntaxException {
Configuration configuration = new Configuration();
String hdfsPath = "hdfs://localhost:9000";
FileSystem hdfs = FileSystem.get(new URI(hdfsPath), configuration);
String filePath = "/hdfstest/touchfile";
FSDataOutputStream create = hdfs.create(new Path(filePath));
System.out.println("Finish!");
}
}
创建类CopyFromLocalFile.class,程序功能是将本地linux操作系统上的文件/data/hadoop4/sample_data,上传到HDFS文件系统的/hdfstest目录下。
package my.hdfs;
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
public class CopyFromLocalFile {
public static void main(String[] args) throws IOException, URISyntaxException {
Configuration conf = new Configuration();
String hdfsPath = "hdfs://localhost:9000";
FileSystem hdfs = FileSystem.get(new URI(hdfsPath), conf);
String from_Linux = "/data/hadoop4/sample_data";
String to_HDFS = "/hdfstest/";
hdfs.copyFromLocalFile(new Path(from_Linux), new Path(to_HDFS));
System.out.println("Finish!");
}
}
创建类CopyToLocalFile.class,程序功能是将HDFS文件系统上的文件/hdfstest/sample_data,下载到本地/data/hadoop4/copytolocal 。
package my.hdfs;
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
public class CopyToLocalFile {
public static void main(String[] args) throws IOException, URISyntaxException {
Configuration conf = new Configuration();
String hdfsPath = "hdfs://localhost:9000";
FileSystem hdfs = FileSystem.get(new URI(hdfsPath), conf);
String from_HDFS = "/hdfstest/sample_data";
String to_Linux = "/data/hadoop4/copytolocal";
hdfs.copyToLocalFile(false, new Path(from_HDFS), new Path(to_Linux));
System.out.println("Finish!");
}
}
新建类ListFiles,程序功能是列出HDFS文件系统/hdfstest目录下,所有的文件,以及文件的权限、用户组、所属用户。
package my.hdfs;
import java.io.FileNotFoundException;
import java.io.IOException;
import java.net.URI;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
public class IteratorListFiles {
public static void main(String[] args) throws IOException {
Configuration conf = new Configuration();
String hdfspath = "hdfs://localhost:9000/";
FileSystem hdfs = FileSystem.get(URI.create(hdfspath), conf);
String watchHDFS = "/";
iteratorListFile(hdfs, new Path(watchHDFS));
}
public static void iteratorListFile(FileSystem hdfs, Path path)
throws FileNotFoundException, IOException {
FileStatus[] files = hdfs.listStatus(path);
for (FileStatus file : files) {
if (file.isDirectory()) {
System.out.println(file.getPermission() + " " + file.getOwner()
+ " " + file.getGroup() + " " + file.getPath());
iteratorListFile(hdfs, file.getPath());
} else if (file.isFile()) {
System.out.println(file.getPermission() + " " + file.getOwner()
+ " " + file.getGroup() + " " + file.getPath());
}
}
}
}
新建类LocateFile,程序功能是查看HDFS文件系统上,文件/hdfstest/sample_data的文件块信息。
package my.hdfs;
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.BlockLocation;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
public class LocateFile {
public static void main(String[] args) throws IOException, URISyntaxException {
Configuration conf = new Configuration();
String hdfsPath = "hdfs://localhost:9000";
FileSystem hdfs = FileSystem.get(new URI(hdfsPath), conf);
Path file = new Path("/hdfstest/sample_data");
FileStatus fileStatus = hdfs.getFileStatus(file);
BlockLocation[] location = hdfs.getFileBlockLocations(fileStatus, 0, fileStatus.getLen());
for (BlockLocation block : location) {
String[] hosts = block.getHosts();
for (String host : hosts) {
System.out.println("block:" +block + " host:"+ host);
}
}
}
}
新建类WriteFile,程序功能是在HDFS上,创建/hdfstest/writefile文件并在文件中写入内容“hello world hello data!”。
package my.hdfs;
import java.io.IOException;
import java.net.URI;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
public class WriteFile {
public static void main(String[] args) throws IOException {
Configuration conf = new Configuration();
String hdfsPath = "hdfs://localhost:9000";
FileSystem hdfs = FileSystem.get(URI.create(hdfsPath), conf);
String filePath = "/hdfstest/writefile";
FSDataOutputStream create = hdfs.create(new Path(filePath));
System.out.println("Step 1 Finish!");
String sayHi = "hello world hello data!";
byte[] buff = sayHi.getBytes();
create.write(buff, 0, buff.length);
create.close();
System.out.println("Step 2 Finish!");
}
}
在Eclipse里执行,然后在HDFS上查看实验结果。
hadoop fs -lsr /hdfstest
hadoop fs -cat /hdfstest/writefile
首先切换到/data/hadoop4目录下,将该目录下的所有文件删除(此时要求/data/hadoop4中必须全是文件,不能有目录)。
cd /data/hadoop4
rm -r /data/hadoop4/*
然后在该目录下新建两文件,分别命名为file1 ,file2。
touch file1
touch file2
向file1和file2中,分别输入内容如下
echo "hello file1" > file1
echo "hello file2" > file2
在my.hdfs包下,新建类PutMerge,程序功能是将Linux本地文件夹/data/hadoop4/下的所有文件,上传到HDFS上并合并成一个文件/hdfstest/mergefile。
package my.hdfs;
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
public class PutMerge {
public static void main(String[] args) throws IOException, URISyntaxException {
Configuration conf = new Configuration();
String hdfsPath = "hdfs://localhost:9000";
FileSystem hdfs = FileSystem.get(new URI(hdfsPath), conf);
FileSystem local = FileSystem.getLocal(conf);
String from_LinuxDir = "/data/hadoop4/";
String to_HDFS = "/hdfstest/mergefile";
FileStatus[] inputFiles = local.listStatus(new Path(from_LinuxDir));
FSDataOutputStream out = hdfs.create(new Path(to_HDFS));
for (FileStatus file : inputFiles) {
FSDataInputStream in = local.open(file.getPath());
byte[] buffer = new byte[256];
int bytesRead = 0;
while ( (bytesRead = in.read(buffer) ) > 0) {
out.write(buffer, 0, bytesRead);
}
in.close();
}
System.out.println("Finish!");
}
}
我正在使用的第三方API的文档状态:"[O]urAPIonlyacceptspaddedBase64encodedstrings."什么是“填充的Base64编码字符串”以及如何在Ruby中生成它们。下面的代码是我第一次尝试创建转换为Base64的JSON格式数据。xa=Base64.encode64(a.to_json) 最佳答案 他们说的padding其实就是Base64本身的一部分。它是末尾的“=”和“==”。Base64将3个字节的数据包编码为4个编码字符。所以如果你的输入数据有长度n和n%3=1=>"=="末尾用于填充n%
我有一个用户工厂。我希望默认情况下确认用户。但是鉴于unconfirmed特征,我不希望它们被确认。虽然我有一个基于实现细节而不是抽象的工作实现,但我想知道如何正确地做到这一点。factory:userdoafter(:create)do|user,evaluator|#unwantedimplementationdetailshereunlessFactoryGirl.factories[:user].defined_traits.map(&:name).include?(:unconfirmed)user.confirm!endendtrait:unconfirmeddoenden
有没有办法在这个简单的get方法中添加超时选项?我正在使用法拉第3.3。Faraday.get(url)四处寻找,我只能先发起连接后应用超时选项,然后应用超时选项。或者有什么简单的方法?这就是我现在正在做的:conn=Faraday.newresponse=conn.getdo|req|req.urlurlreq.options.timeout=2#2secondsend 最佳答案 试试这个:conn=Faraday.newdo|conn|conn.options.timeout=20endresponse=conn.get(url
我想在Ruby中创建一个用于开发目的的极其简单的Web服务器(不,不想使用现成的解决方案)。代码如下:#!/usr/bin/rubyrequire'socket'server=TCPServer.new('127.0.0.1',8080)whileconnection=server.acceptheaders=[]length=0whileline=connection.getsheaders想法是从命令行运行这个脚本,提供另一个脚本,它将在其标准输入上获取请求,并在其标准输出上返回完整的响应。到目前为止一切顺利,但事实证明这真的很脆弱,因为它在第二个请求上中断并出现错误:/usr/b
我意识到这可能是一个非常基本的问题,但我现在已经花了几天时间回过头来解决这个问题,但出于某种原因,Google就是没有帮助我。(我认为部分问题在于我是一个初学者,我不知道该问什么......)我也看过O'Reilly的RubyCookbook和RailsAPI,但我仍然停留在这个问题上.我找到了一些关于多态关系的信息,但它似乎不是我需要的(尽管如果我错了请告诉我)。我正在尝试调整MichaelHartl'stutorial创建一个包含用户、文章和评论的博客应用程序(不使用脚手架)。我希望评论既属于用户又属于文章。我的主要问题是:我不知道如何将当前文章的ID放入评论Controller。
我的工作要求我为某些测试自动生成电子邮件。我一直在四处寻找,但未能找到可以快速实现的合理解决方案。它需要在outlook而不是其他邮件服务器中,因为我们有一些奇怪的身份验证规则,我们需要保存草稿而不是仅仅发送邮件的选项。显然win32ole可以做到这一点,但我找不到任何相当简单的例子。 最佳答案 假设存储了Outlook凭据并且您设置为自动登录到Outlook,WIN32OLE可以很好地完成此操作:require'win32ole'outlook=WIN32OLE.new('Outlook.Application')message=
华为OD机试题本篇题目:明明的随机数题目输入描述输出描述:示例1输入输出说明代码编写思路最近更新的博客华为od2023|什么是华为od,od薪资待遇,od机试题清单华为OD机试真题大全,用Python解华为机试题|机试宝典【华为OD机试】全流程解析+经验分享,题型分享,防作弊指南华为o
在应用开发中,有时候我们需要获取系统的设备信息,用于数据上报和行为分析。那在鸿蒙系统中,我们应该怎么去获取设备的系统信息呢,比如说获取手机的系统版本号、手机的制造商、手机型号等数据。1、获取方式这里分为两种情况,一种是设备信息的获取,一种是系统信息的获取。1.1、获取设备信息获取设备信息,鸿蒙的SDK包为我们提供了DeviceInfo类,通过该类的一些静态方法,可以获取设备信息,DeviceInfo类的包路径为:ohos.system.DeviceInfo.具体的方法如下:ModifierandTypeMethodDescriptionstatic StringgetAbiList()Obt
C#实现简易绘图工具一.引言实验目的:通过制作窗体应用程序(C#画图软件),熟悉基本的窗体设计过程以及控件设计,事件处理等,熟悉使用C#的winform窗体进行绘图的基本步骤,对于面向对象编程有更加深刻的体会.Tutorial任务设计一个具有基本功能的画图软件**·包括简单的新建文件,保存,重新绘图等功能**·实现一些基本图形的绘制,包括铅笔和基本形状等,学习橡皮工具的创建**·设计一个合理舒适的UI界面**注明:你可能需要先了解一些关于winform窗体应用程序绘图的基本知识,以及关于GDI+类和结构的知识二.实验环境Windows系统下的visualstudio2017C#窗体应用程序三.
//1.验证返回状态码是否是200pm.test("Statuscodeis200",function(){pm.response.to.have.status(200);});//2.验证返回body内是否含有某个值pm.test("Bodymatchesstring",function(){pm.expect(pm.response.text()).to.include("string_you_want_to_search");});//3.验证某个返回值是否是100pm.test("Yourtestname",function(){varjsonData=pm.response.json