有些软件对于安装路径有一定的要求,例如:路径中不能有空格,不能有中文,不能有特殊符号,等等。
为了避免不必要的麻烦,也懒得一一辨别踩坑,我们人为作出「统一的约定」:
Elasticsearch 只有解压版本,没有安装版
Elastic 官网:https://www.elastic.co/cn/
Elastic 有一条完整的产品线及解决方案:Elasticsearch、Kibana、Logstash 等,前面说的三个就是大家常说的 ELK 技术栈。

Elasticsearch 具备以下特点:
kibana 从 7.11 开始升级了 node.js 的版本,因此,从这个版本开始不再支持 win7,也就是说,win7 能使用的 kibana 的最后的版本是 7.10.2 。

本步骤是可选操作:如果机子内存足够大也可以不改配置
我们进入 elasticsearch-7.11.1/config 目录:
需要修改的配置文件有两个:
Elasticsearch 基于 Lucene 的,而 Lucene 底层是 java 实现,若本机内存不够需要配置 jvm 参数。
在jvm.options.d文件下创建配置文件(文件后缀是options即可)例如heap.options
内存占用太多了,我们调小一些:
-Xms512m
-Xmx512m
elasticsearch.yml 配置文件暂时不用改动。
进入 elasticsearch-7.11.1\bin 目录
双击 elasticsearch.bat,启动成功时,会显示 started 字样,并且可我们在浏览器中访问:http://127.0.0.1:9200,可见类似如下内容:
{
"name" : "DESKTOP-T540P",
"cluster_name" : "elasticsearch",
"cluster_uuid" : "XvelzExUQgud2iqO9QLA4w",
"version" : {
"number" : "7.11.1",
"build_flavor" : "default",
"build_type" : "zip",
"build_hash" : "747e1cc71def077253878a59143c1f785afa92b9",
"build_date" : "2021-01-13T00:42:12.435326Z",
"build_snapshot" : false,
"lucene_version" : "8.7.0",
"minimum_wire_compatibility_version" : "6.8.0",
"minimum_index_compatibility_version" : "6.0.0-beta1"
},
"tagline" : "You Know, for Search"
}
我们生活中的数据总体分为两种:
| # | 数据类型 | 说明 |
|---|---|---|
| 1 | 结构化数据 | 指具有固定格式或有限长度的数据,如数据库,元数据等。 |
| 2 | 非结构化数据 | 指不定长或无固定格式的数据,如邮件,word文档等磁盘上的文件 |
最常见的结构化数据也就是数据库中的数据。
结构化数据很容易查询,因为结构化的数据存储是有规律的。以数据库数据为例,它们有行,有列,有格式/类型,连数据的长度都是固定的。
非结构化数据的查询方式
顺序扫描法(Serial Scanning)
想象一下你在 Word 文档中使用 Ctrl + f 进行搜索。
所谓顺序扫描,比如要找内容包含某一个字符串的文件,就是一个文档一个文档的看,对于每一个文档,从头看到尾,如果此文档包含此字符串,则此文档为我们要找的文件,接着看下一个文件,直到扫描完所有的文件。
这个过程是相当慢的。
全文检索(Full-text Search)
将非结构化数据中的一部分信息提取出来,重新组织,使其变得有一定结构,然后对此有一定结构的数据进行搜索,从而达到搜索相对较快的目的。这部分从非结构化数据中提取出的然后重新组织的信息,我们称之索引。
从非结构化数据中提取出来的信息,通常也就是你所关注的核心信息,或者是搜索关键字。
例如:字典。字典有两套索引:拼音表和部首检字表。拼音表就是提取的各个文字的读音信息而组成的索引;部首检字表就是提取的各个文字的偏旁部首信息而组成的索引。
Note:一份非结构化数据,可以不止有一份索引。
这种先建立索引,再对索引进行搜索的过程就叫全文检索(全文检索通常使用倒排索引来实现)(Full-text Search)。
正排索引和倒排索引区别
正排索引:由key查询实体的过程,使用正排索引
倒排索引:与正排索引相反,由item查询key的过程,使用倒排索引
举个例子
举个例子,假设有3个网页:
url1 -> “我爱北京”
url2 -> “我爱到家”
url3 -> “到家美好”
这是一个正排索引:
Map结构如下
分词之后:
url1 -> {我,爱,北京}
url2 -> {我,爱,到家}
url3 -> {到家,美好}
这是一个分词后的正排索引:
分词后倒排索引:
Map结构如下
我 -> {url1, url2}
爱 -> {url1, url2}
北京 -> {url1}
到家 -> {url2, url3}
美好 -> {url3}
由检索词item快速找到包含这个查询词的网页Map就是倒排索引
虽然创建索引的过程也是非常耗时的,但是索引一旦创建就可以多次使用,全文检索主要处理的是查询,所以耗时间创建索引是值得的。
可以使用 Lucene 实现全文检索。Lucene 是 apache 下的一个开放源代码的全文检索引擎工具包。提供了完整的查询引擎和索引引擎,部分文本分析引擎。
Lucene 的目的是为软件开发人员提供一个简单易用的工具包,以方便的在目标系统中实现全文检索的功能。
Lucene 只是一个库(类似于汽车发动机),而非独立的产品。通过 Lucene 实现搜索功能,但你仍需作大量的其他的工作。Solr 和 ElasticSearch 都是基于 Lucene 的搜索引擎产品。
对于数据量大、数据结构不固定的数据可采用全文检索方式搜索,比如百度、Google 等搜索引擎、论坛站内搜索、电商网站站内搜索等
Elasticsearch 是一个基于 Lucene 的搜索服务器,它采用 Java 语言编写,使用 Lucene 构建索引、提供搜索功能,并以 Apache 许可条款发布。
Elasticsearch 对外提供了 RESTful API ,以使你能通过多种形式操作它。
Elasticsearch 的优点
你完全可以将 Elasticsearch 当作一个数据库(NoSQL)来看待,以便于你的理解,也更方便与你通过现象看到它的本质。实际上在很多使用场景中,Elasticsearch 确实就是在扮演 NoSQL 数据库的角色。
类似于数据库的层次结构,Elastic Search 也是如此:
mysql es
└── database └── index
└── table └── type
└── row └── document
另外,在 SQL 数据库中被我们称作『列』的东西,实际上也被称作『字段』,只不过我们更习惯于使用前者。而 Elastic Search(和 Lucene)则是使用后一种称呼。
虽然和 RDMS(关系型数据库) 中的概念有一一对应的关系,但是 Elasticsearch 正在一步步弱化 type 的概念,并计划在未来移除 type 这个概念。
这种情况下就类似于,数据库中人为约定:一个 database 里默认有且仅有一个 table 。此时,这个 table 叫什么,实际上就无关紧要了。即便是有这样的奇怪的约定,但是实际上仍不影响我们使用 MySQL,因为你仍然可以建多个 database 。
6.0 的时候,已经默认只能支持一个索引中有且仅有一个 type 了;7.0 的时候,如果你在命令中指定 type 时,Elasticsearch 会提示你 type 被废弃(deprecated),建议使用 _doc 关键字替代。Elastic Search 的一个特点就是对外提供 Restful API 来对其进行操作,因此,它直接利用 HTTP 的四种不同请求方式来表示当前操作是增删改查中的哪一种。
| HTTP 请求方式 | 操作 |
|---|---|
| POST | 新增操作,类似于 INSERT |
| DELETE | 删除操作,类似于 DELETE |
| PUT | 修改操作,类似于 UPDATE |
| GET | 查询操作,类似于 SELECT |
和数据库中的字段(列)有数据类型的概念一样,ElasticSearch 中 document 的每个『字段』也有数据类型的概念。ElasticSearch 支持的数据类型有:
字符串型:text,keyword
text 会被分词器分词;keyword 不会被分词器分词
数字:long, integer, short, double, float
日期:date
逻辑:boolean
再复杂一些的数据类型有:
和数据库一样,Elastic Search 也有 集群、节点、分片、备份的概念。
另外,Elasticsearch 流行的原因之一就是其内置了集群功能,即它本身『天生』就是分布式的。即便你在单机上只有一个节点,Elasticsearch 也将它当做一个集群来看待。默认也会对你的数据进行分片和副本操作,当你向集群添加新数据时,数据也会在新加入的节点中进行平衡。
对比关系型数据库,创建索引就等于创建数据库。
在postman 中,向ES服务器发送PUT 请求:http://127.0.0.1:9200/shopping
在postman 中,向ES服务器发送GET请求:http://127.0.0.1:9200/shopping
查看ES 中所有索引 ,向ES服务器发送GET请求:http://127.0.0.1:9200/_cat/indices?v
向ES服务器发送DELETE 请求:
http://127.0.0.1:9200/shopping
在postman 中,向ES服务器发送POST 请求:
http://127.0.0.1:9200/shopping/_doc
请求体
{
"title":"小米手机",
"category":"小米",
"image":"http://127.0.0.1/9000/phone/1111.jpg",
"price":3333.00
}
此时的请求会给这个文档自动生成一个id
指定id生成文档
向ES服务器发送PUT 请求:
http://127.0.0.1:9200/shopping/_doc/1001
请求体
{
"title":"小米手机1",
"category":"小米1",
"image":"http://127.0.0.1/9000/phone/1111.jpg",
"price":3333.00
}
向ES服务器发送GET 请求:
http://127.0.0.1:9200/shopping/_doc/1001
向ES服务器发送GET 请求:
http://127.0.0.1:9200/shopping/_doc/1001/_source
查询索引下所有文档数据,向ES服务器发送GET 请求:
http://127.0.0.1:9200/shopping/_doc/_search
向ES服务器发送DELETE请求:
http://127.0.0.1:9200/shopping/_doc/1
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>
老版本配置方式(已被废弃,不再推荐使用)
略。
新版本配置方式(推荐使用)
新的配置方式使用的是 High Level REST Client 的方式来替代之前的 Transport Client 方式,使用的是 HTTP 请求,和 Kibana 一样使用的是 Elasticsearch 的 9200 端口。
这种配置方案中,你使用的不是配置文件,而是自定义配置类:
/**
* 你也可以不继承 AbstractElasticsearchConfiguration 类,而将 ESConfig 写成一般的配置类的型式。
* 不过继承 AbstractElasticsearchConfiguration 好处在于,它已经帮我们配置好了 elasticsearchTemplate 直接使用。
*/
@Configuration
public class ESConfig extends AbstractElasticsearchConfiguration {
@Override
public RestHighLevelClient elasticsearchClient() {
ClientConfiguration clientConfiguration = ClientConfiguration.builder()
.connectedTo("localhost:9200")
.build();
return RestClients.create(clientConfiguration).rest();
}
}
Elasticsearch 中的 PO 类:
@Document(indexName = "books", shards = 1, replicas = 0)
@Data
public class Book {
@Id
@Field(type = FieldType.Keyword)
private String id;
@Field(type = FieldType.Text)
private String title;
@Field(type = FieldType.Keyword)
private String language;
@Field(type = FieldType.Keyword)
private String author;
@Field(type = FieldType.Float)
private Float price;
@Field(type = FieldType.Text)
private String description;
}
@Repository
public interface BookRepository extends ElasticsearchRepository<Book, String> {
}
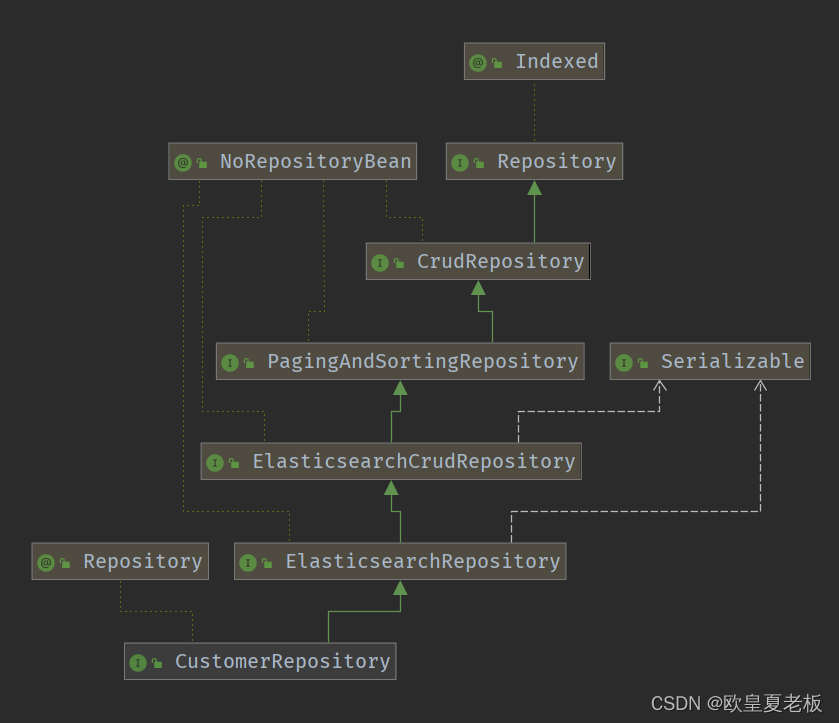
我们自定义的 CustomerRepository 接口,从它的祖先们那里继承了大量的现成的方法,除此之外,它还可以按 spring data 的规则定义特定的方法。
// 创建索引
@Test
public void indexList() {
System.out.println("创建索引");
}
// 删除索引
@Test
public void indexList() {
restTemplate.indexOps(IndexCoordinates.of("books")).delete();
System.out.println("删除索引");
}
@Test
public void indexList() {
List<BookPo> lists = new ArrayList<>();
lists.add(new BookPo("2","java 程序设计","小孔明",45.4F,
"java 语言","2033-03-03","一本好书"));
lists.add(new BookPo("3","java 编程思想","小孔明",45.4F,
"java 语言","2033-03-03","一本好书"));
lists.add(new BookPo("4","java 逻辑","小孔明",45.4F,
"java 语言","2033-03-03","一本好书"));
lists.add(new BookPo("5","java 面向对象","小孔明",45.4F,
"java 语言","2033-03-03","一本好书"));
bookEsDao.saveAll(lists);
}
修改和新增是同一个接口,区分的依据就是id,这一点跟我们在页面发起PUT请求是类似的。
BookPo bookPo = new BookPo("5","java 程序设计","小孔明","java 语言",
45.4F,"2016-03-03","很好");
booksEsDao.save(bookPo);
//由于上面的id = 5 已经存在,故再次save 就是修改
@Test
public void test2(){
bookEsDao.deleteById("1");
bookEsDao.deleteAll();
}
1、ElasticsearchRepository提供了一些基本的查询方法:
@Test
public void testQuery(){
Optional<BookPo> optional = this.bookEsDao.findById("1");
System.out.println(optional.get());
}
@Test
public void testFind(){
// 查询全部,并按照价格降序排序
//写法一:
Iterable<BookPo> items = this.bookEsDao.findAll(Sort.by(Sort.Direction.DESC,
"price"));
//写法二:
Iterable<BookPo> items = this.booksEsDao.findAll(Sort.by(Sort.Order.desc("price")));
2、分页查询
Spring Data 自带的分页方案:
@Test
public void testByPage(){
Sort sort = Sort.by(Sort.Direction.ASC,"id");
//分页
PageRequest pageRequest = PageRequest.of(0,2,sort);
Page<Product> all = productDao.findAll(pageRequest);
for (Product product : all) {
System.out.println(product);
}
}
3、自定义方法查询
Spring Data 的另一个强大功能,是根据方法名称自动实现功能。
比如:你的方法名叫做:findByTitle,那么它就知道你是根据title查询,然后自动帮你完成,无需写实现类。
当然,方法名称要符合一定的约定
| Keyword | Sample | Elasticsearch Query String |
|---|---|---|
And | findByNameAndPrice | {"bool" : {"must" : [ {"field" : {"name" : "?"}}, {"field" : {"price" : "?"}} ]}} |
Or | findByNameOrPrice | {"bool" : {"should" : [ {"field" : {"name" : "?"}}, {"field" : {"price" : "?"}} ]}} |
Is | findByName | {"bool" : {"must" : {"field" : {"name" : "?"}}}} |
Not | findByNameNot | {"bool" : {"must_not" : {"field" : {"name" : "?"}}}} |
Between | findByPriceBetween | {"bool" : {"must" : {"range" : {"price" : {"from" : ?,"to" : ?,"include_lower" : true,"include_upper" : true}}}}} |
LessThanEqual | findByPriceLessThan | {"bool" : {"must" : {"range" : {"price" : {"from" : null,"to" : ?,"include_lower" : true,"include_upper" : true}}}}} |
GreaterThanEqual | findByPriceGreaterThan | {"bool" : {"must" : {"range" : {"price" : {"from" : ?,"to" : null,"include_lower" : true,"include_upper" : true}}}}} |
Before | findByPriceBefore | {"bool" : {"must" : {"range" : {"price" : {"from" : null,"to" : ?,"include_lower" : true,"include_upper" : true}}}}} |
After | findByPriceAfter | {"bool" : {"must" : {"range" : {"price" : {"from" : ?,"to" : null,"include_lower" : true,"include_upper" : true}}}}} |
Like | findByNameLike | {"bool" : {"must" : {"field" : {"name" : {"query" : "?*","analyze_wildcard" : true}}}}} |
StartingWith | findByNameStartingWith | {"bool" : {"must" : {"field" : {"name" : {"query" : "?*","analyze_wildcard" : true}}}}} |
EndingWith | findByNameEndingWith | {"bool" : {"must" : {"field" : {"name" : {"query" : "*?","analyze_wildcard" : true}}}}} |
Contains/Containing | findByNameContaining | {"bool" : {"must" : {"field" : {"name" : {"query" : "**?**","analyze_wildcard" : true}}}}} |
In | findByNameIn(Collection<String>names) | {"bool" : {"must" : {"bool" : {"should" : [ {"field" : {"name" : "?"}}, {"field" : {"name" : "?"}} ]}}}} |
NotIn | findByNameNotIn(Collection<String>names) | {"bool" : {"must_not" : {"bool" : {"should" : {"field" : {"name" : "?"}}}}}} |
Near | findByStoreNear | Not Supported Yet ! |
True | findByAvailableTrue | {"bool" : {"must" : {"field" : {"available" : true}}}} |
False | findByAvailableFalse | {"bool" : {"must" : {"field" : {"available" : false}}}} |
OrderBy | findByAvailableTrueOrderByNameDesc | {"sort" : [{ "name" : {"order" : "desc"} }],"bool" : {"must" : {"field" : {"available" : true}}}} |
如:
public interface EsBooksDao extends ElasticsearchRepository<BookPo,String>{
public List<BookPo> findBookPoByAuthor(String author);
public List<BookPo> findBookPoByTitleAndPrice(String title,float price);
List<BookPo> findByPriceBetween(float price1, float price2);
}
QueryBuilders.queryStringQuery() #指定字符串作为关键词查询,关键词支持分词
QueryBuilders.queryStringQuery("华为手机").defaultField("description");
//不指定feild,查询范围为所有feild
QueryBuilders.queryStringQuery("华为手机");
//指定多个feild
QueryBuilders.queryStringQuery("华为手机").field("title").field("description");
QueryBuilders.boolQuery #子方法must可多条件联查
QueryBuilders.termQuery #精确查询指定字段不支持分词
QueryBuilders.termQuery("description", "华为手机")
QueryBuilders.matchQuery #按分词器进行模糊查询支持分词
QueryBuilders.matchQuery("description", "华为手机")
QueryBuilders.rangeQuery #按指定字段进行区间范围查询
- `QueryBuilders.boolQuery()`
- `QueryBuilders.boolQuery().must()`:相当于 and
- `QueryBuilders.boolQuery().should()`:相当于 or
- `QueryBuilders.boolQuery().mustNot()`:相当于 not
@Test
void contextLoads1() {
NativeSearchQuery query = new NativeSearchQueryBuilder()
.withQuery(QueryBuilders.queryStringQuery("华为手机").defaultField("description"))
.withPageable(PageRequest.of(0,5))
.build();
SearchHits<Product> search = restTemplate.search(query, Product.class);
List<SearchHit<Product>> searchHits = search.toList();
for (SearchHit<Product> searchHit : searchHits) {
System.out.println(searchHit.getContent());
}
}
场景一:对外暴露的数据(数据量大的)的用es,如果不需要对外暴露,不需要全文检索的话,那么直接从数据查,所以做项目分析数据分成2块(哪些数据需要放es,从es查,哪些不需要)
场景二:作为mysql的外置索引,把作为数据库查询条件的列数据放到es里面,这样在查询的时候,先从es查询出符合条件的id,然后根据id去数据库查,数据维护大,一旦es宕机,就麻烦了
1.postman介绍Postman一款非常流行的API调试工具。其实,开发人员用的更多。因为测试人员做接口测试会有更多选择,例如Jmeter、soapUI等。不过,对于开发过程中去调试接口,Postman确实足够的简单方便,而且功能强大。2.下载安装官网地址:https://www.postman.com/下载完成后双击安装吧,安装过程极其简单,无需任何操作3.使用教程这里以百度为例,工具使用简单,填写URL地址即可发送请求,在下方查看响应结果和响应状态码常用方法都有支持请求方法:getpostputdeleteGet、Post、Put与Delete的作用get:请求方法一般是用于数据查询,
Ⅰ软件测试基础一、软件测试基础理论1、软件测试的必要性所有的产品或者服务上线都需要测试2、测试的发展过程3、什么是软件测试找bug,发现缺陷4、测试的定义使用人工或自动的手段来运行或者测试某个系统的过程。目的在于检测它是否满足规定的需求。弄清预期结果和实际结果的差别。5、测试的目的以最小的人力、物力和时间找出软件中潜在的错误和缺陷6、测试的原则28原则:20%的主要功能要重点测(eg:支付宝的支付功能,其他功能都是次要的)80%的错误存在于20%的代码中7、测试标准8、测试的基本要求功能测试性能测试安全性测试兼容性测试易用性测试外观界面测试可靠性测试二、质量模型衡量一个优秀软件的维度①功能性功
在VMware16.2.4安装Ubuntu一、安装VMware1.打开VMwareWorkstationPro官网,点击即可进入。2.进入后向下滑动找到Workstation16ProforWindows,点击立即下载。3.下载完成,文件大小615MB,如下图:4.鼠标右击,以管理员身份运行。5.点击下一步6.勾选条款,点击下一步7.先勾选,再点击下一步8.去掉勾选,点击下一步9.点击下一步10.点击安装11.点击许可证12.在百度上搜索VM16许可证,复制填入,然后点击输入即可,亲测有效。13.点击完成14.重启系统,点击是15.双击VMwareWorkstationPro图标,进入虚拟机主
1.1.1 YARN的介绍 为克服Hadoop1.0中HDFS和MapReduce存在的各种问题⽽提出的,针对Hadoop1.0中的MapReduce在扩展性和多框架⽀持⽅⾯的不⾜,提出了全新的资源管理框架YARN. ApacheYARN(YetanotherResourceNegotiator的缩写)是Hadoop集群的资源管理系统,负责为计算程序提供服务器计算资源,相当于⼀个分布式的操作系统平台,⽽MapReduce等计算程序则相当于运⾏于操作系统之上的应⽤程序。 YARN被引⼊Hadoop2,最初是为了改善MapReduce的实现,但是因为具有⾜够的通⽤性,同样可以⽀持其他的分布式计算模
ES一、简介1、ElasticStackES技术栈:ElasticSearch:存数据+搜索;QL;Kibana:Web可视化平台,分析。LogStash:日志收集,Log4j:产生日志;log.info(xxx)。。。。使用场景:metrics:指标监控…2、基本概念Index(索引)动词:保存(插入)名词:类似MySQL数据库,给数据Type(类型)已废弃,以前类似MySQL的表现在用索引对数据分类Document(文档)真正要保存的一个JSON数据{name:"tcx"}二、入门实战{"name":"DESKTOP-1TSVGKG","cluster_name":"elasticsear
我是Ruby新手,并被要求在我们的新项目中使用它。我们还被要求使用Padrino(Sinatra)作为后端/框架。我们被要求使用Rspec进行测试。我一直在寻找可以指导在Padrino上使用RspecforRuby的教程。我得到的主要是引用RoR。但是,我需要RubyonPadrino。请在任何入门/指南/引用/讨论等方面指导我。如有不妥之处请指正。可能是我没有针对我的问题搜索正确的词/短语组合。我正在使用Ruby1.9.3和Padrinov.0.10.6。注意:我还提到了SOquestion,但它没有帮助。 最佳答案 我没用过Pa
不知何故,我似乎无法获得包含我的聚合的响应...使用curl它按预期工作:HBZUMB01$curl-XPOST"http://localhost:9200/contents/_search"-d'{"size":0,"aggs":{"sport_count":{"value_count":{"field":"dwid"}}}}'我收到回复:{"took":4,"timed_out":false,"_shards":{"total":5,"successful":5,"failed":0},"hits":{"total":90,"max_score":0.0,"hits":[]},"a
(本文是网络的宏观的概念铺垫)目录计算机网络背景网络发展认识"协议"网络协议初识协议分层OSI七层模型TCP/IP五层(或四层)模型报头以太网碰撞路由器IP地址和MAC地址IP地址与MAC地址总结IP地址MAC地址计算机网络背景网络发展 是最开始先有的计算机,计算机后来因为多项技术的水平升高,逐渐的计算机变的小型化、高效化。后来因为计算机其本身的计算能力比较的快速:独立模式:计算机之间相互独立。 如:有三个人,每个人做的不同的事物,但是是需要协作的完成。 而这三个人所做的事是需要进行协作的,然而刚开始因为每一台计算机之间都是互相独立的。所以前面的人处理完了就需要将数据
文章目录1.任务背景2.任务目标3.相关知识点4.任务实操4.1安装配置JDK4.2启动FISCOBCOS4.3下载解压WeBASE-Front4.4拷贝sdk证书文件4.5启动节点4.6访问节点4.7检查运行状态5.任务总结1.任务背景FISCOBCOS其实是有控制台管理工具,用来对区块链系统进行各种管理操作。但是对于初学者来说,还是可视化界面更友好,本节就来介绍WeBASE管理平台,这是一款微众银行开源的自研区块链中间件平台,可以降低区块链使用的门槛,大幅提高区块链应用的开发效率。微众银行是腾讯牵头设立的民营银行,在国内民营银行里还是比较出名的。微众银行参与FISCOBCOS生态建设,一定
1.回顾.TransportServicepublicclassTransportServiceextendsAbstractLifecycleComponentTransportService:方法:1publicfinalTextendsTransportResponse>voidsendRequest(finalTransport.Connectionconnection,finalStringaction,finalTransportRequestrequest,finalTransportRequestOptionsoptions,TransportResponseHandlerT>