
图片在业务应用场景是一个常见的元素,veImageX(简称ImageX)为业务提供了灵活、高效的一站式图片处理解决方案,包括了服务端 SDK、上传 SDK 和客户端图片加载 SDK。
在介绍 veImageX 图片加载 SDK 之前先看看业内目前有哪些主流的图片加载 SDK,veImageX 图片加载 SDK 是使用 Objective-C 语言开发的,业内使用 Objective-C 语言实现的主流开源图片加载 SDK 有 YYWebImage,SDWebImage 等
veImageX 图片加载 SDK 也是借鉴各家之所长,基于一些业务实际线上应用的属性自研了一套图片加载 SDK,相比于这些开源图片加载 SDK,主要有以下特性:
随着时间的推移,SDK 的功能越来越多,各种业务对 SDK 的功能选择也开始多样化起来,特别是在 App 包体积日益增长需要降低的大背景下,SDK 也需要做包体积瘦身,面对以上种种问题,SDK 对功能的模块化/插件化能力的要求也越来越高,SDK 的架构也就随之演变成下图的样子。
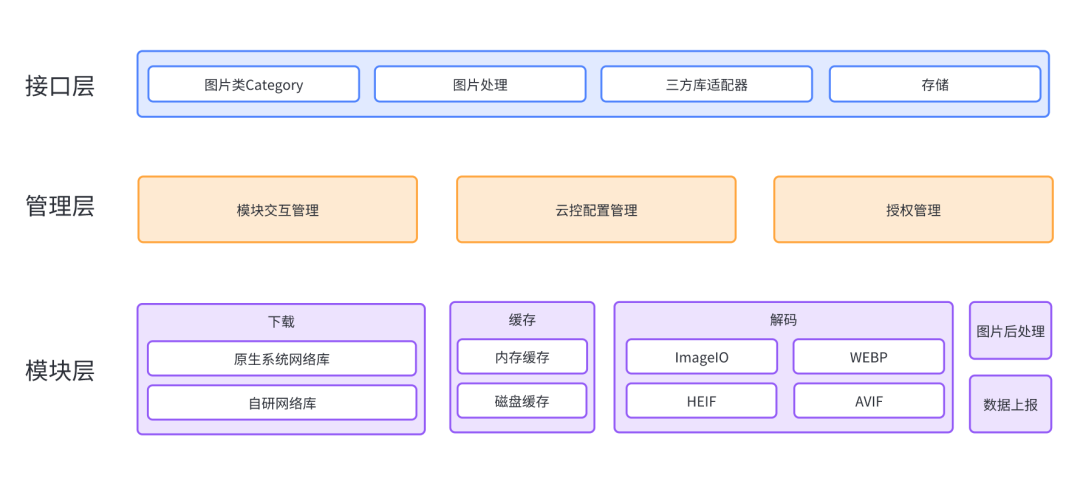
SDK 主要分为三层
业务上图片的主流应用场景就是加载网络图片,以 iOS 原生系统控件 UIImageView 为例,通过 SDK 加载一张网络图片的完整流程如下:
发起图片请求 -> 查询内存缓存 -> 查询磁盘缓存 -> 加入下载队列 -> 开始下载 -> 获取到服务端图片未解码数据 -> 从图片未解码数据中解码后得到可以渲染的图片 -> 将解码后的图片和图片未解码数据分别缓存进内存和磁盘 -> UIImageView 渲染解码后的图片,至此,一张网络图片被成功加载并展示给用户。
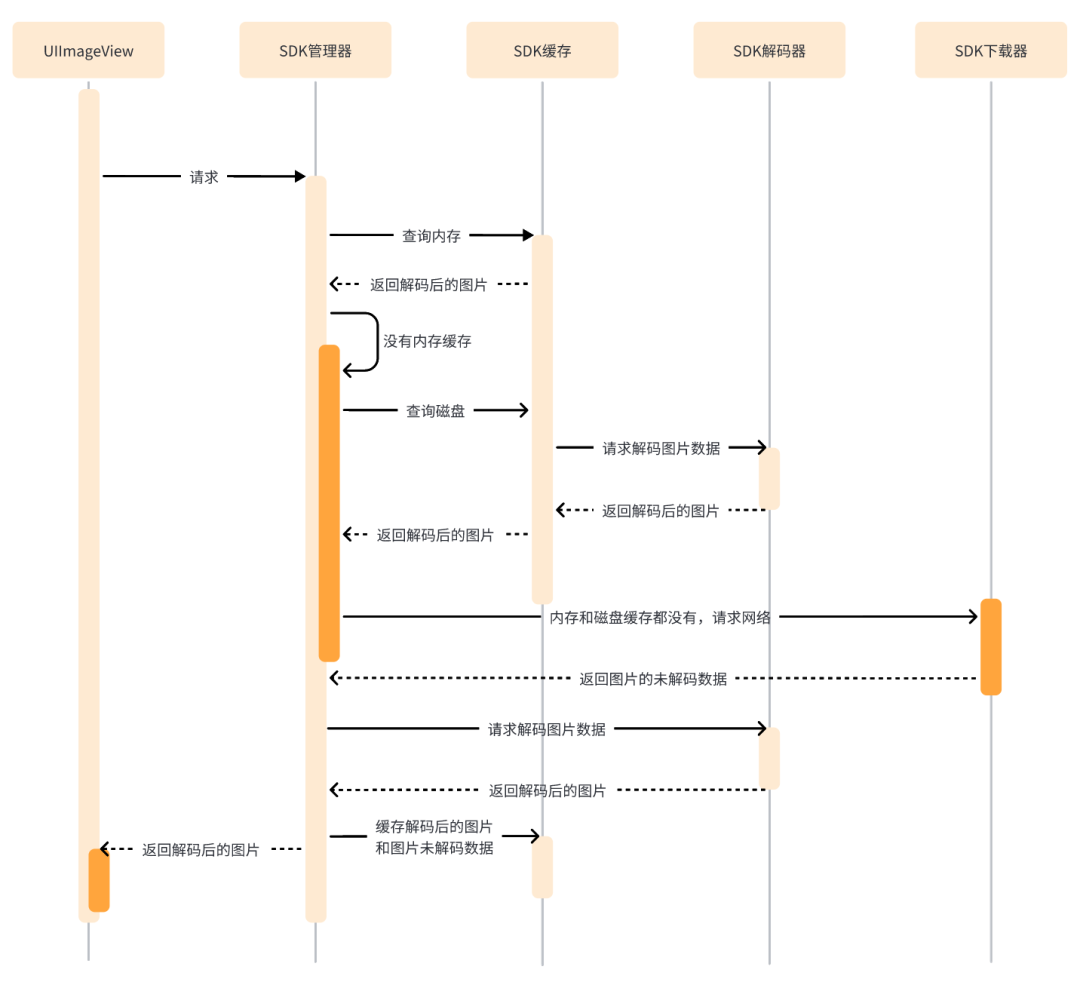
在了解完 SDK 的主流场景中网络图片的完整加载流程后,下面分别介绍一下 SDK 加载流程中的下载、缓存、解码、日志上报与图片后处理这五大主要模块。
下载模块的主要任务是通过网络库把网络图片从服务端下载到客户端,这个过程对图片加载来讲是非常重要的一环,下载的成功与否直接决定了图片能否正确展示,而网络库的性能也决定了图片下载的快慢,最终反映到用户的感受体验上。所以,下载模块中的下载任务除了支持苹果原生系统的网络库实现外,也支持字节内部强大的自研网络库 TTNetwork 实现,该库不仅做了一些网络相关优化,例如 HTTPDNS,HTTP2+HTTPS 连接复用优化、链路选择、动态策略等,支持最新的网络协议 QUIC,也提供了更为细粒度的网络监控,为 SDK 的图片下载提供了高效的支持。SDK 默认支持原生网络库与自研网络库,如果业务有自己的网络库,也可以通过插件化的形式集成进来。
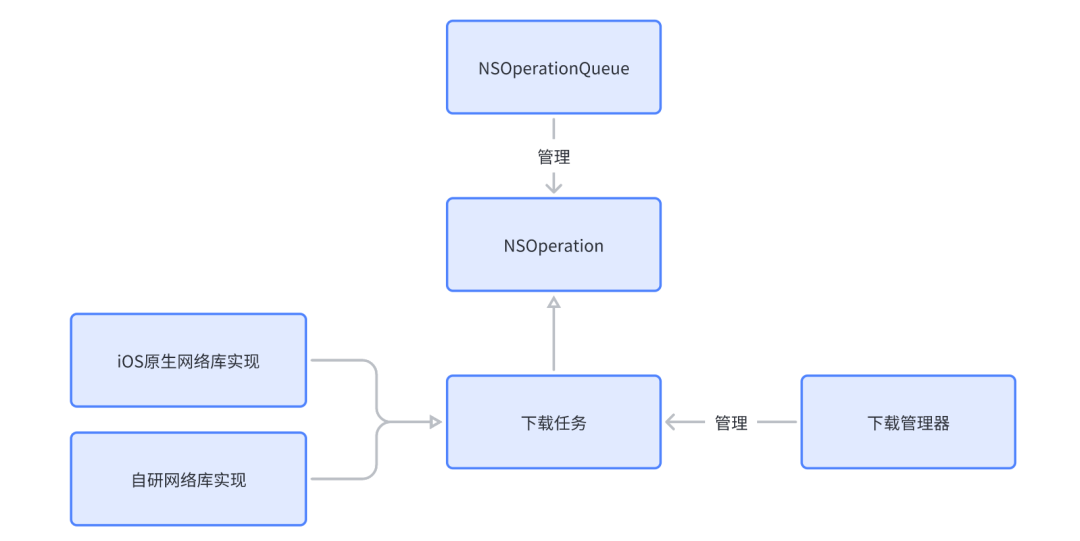
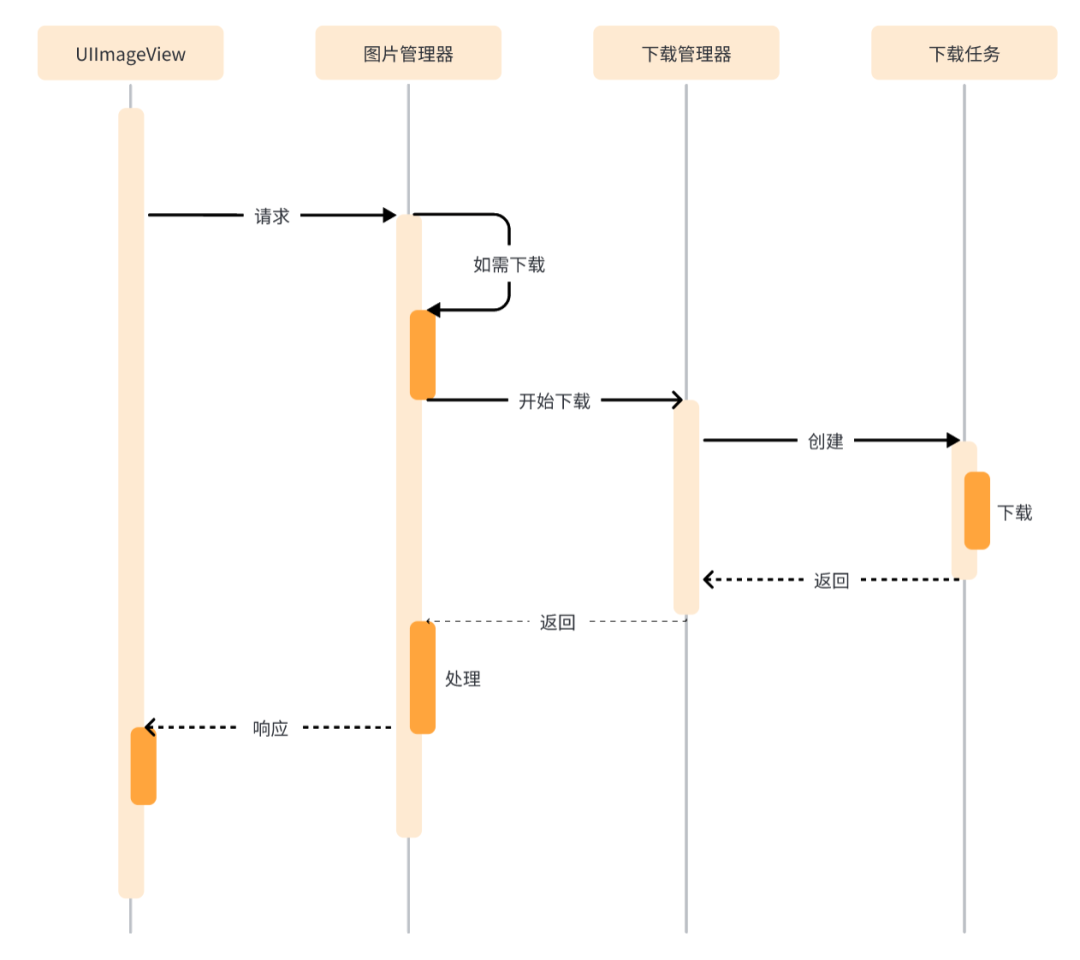
业务上一般会并发下载多张图片,在 Feed 流场景中如果用户来回滑动图片,同样的图片会发生多次请求,如果相同图片的多个请求都去反复下载图片,这样显然会浪费用户流量,也会增加带宽成本。SDK 会管理这些并发的下载任务,并标记相同的图片请求,避免这种问题的发生。下载任务的管理与调度通过 iOS 系统原生的 NSOperation 与 NSOperationQueue 实现,同时会根据请求参数生成一个 Identifier,用来唯一标识一个下载任务,交由下载管理器去管理,这样就能避免在同一个时间段内重复多次下载相同的图片。
缓存模块由内存和磁盘共同组成一个二级缓存结构,当一张图片被下载到客户端上时,会被缓存进内存和磁盘缓存,如果 App 生命周期内再请求这张图片,则可以从内存缓存中查到,如果冷启动 App 后再请求这张图片,则可以从磁盘缓存中查到。这样不仅可以加快图片的加载速度,提升用户体验,也可以降低用户流量,节省带宽成本。再对缓存加上过期时间限制,就可以解决图片的时效性问题。
内存缓存方面除了支持 iOS 原生的 NSCache 外,还支持 Strong-Weak 的弱引用缓存,当缓存对象无人持有时会被及时释放掉,降低内存占用,同时也支持 LRU 缓存。在收到内存不足的通知时会主动释放内存,缓解内存压力,同时保证线程安全。磁盘缓存方面除了支持最基本的 iOS 系统文件管理 NSFileManager,还支持 LRU 缓存,同时保证线程安全。
整体看,如果 App 内只使用同一种固定的缓存算法的话,由于图片使用场景各不相同,同一种缓存算法无法满足所有场景,缓存命中率就会偏低。除了 SDK 默认支持的缓存算法外,由于内存和磁盘缓存都是由协议定义的,业务也可以根据需求去自定义缓存,在不同场景下使用不同的缓存算法,这样可以极大的提高缓存命中率。在一些业务特定场景上 SDK 的缓存命中率能够达到 80% 左右,随着缓存命中率的提升,带来的带宽成本节省收益也越大。
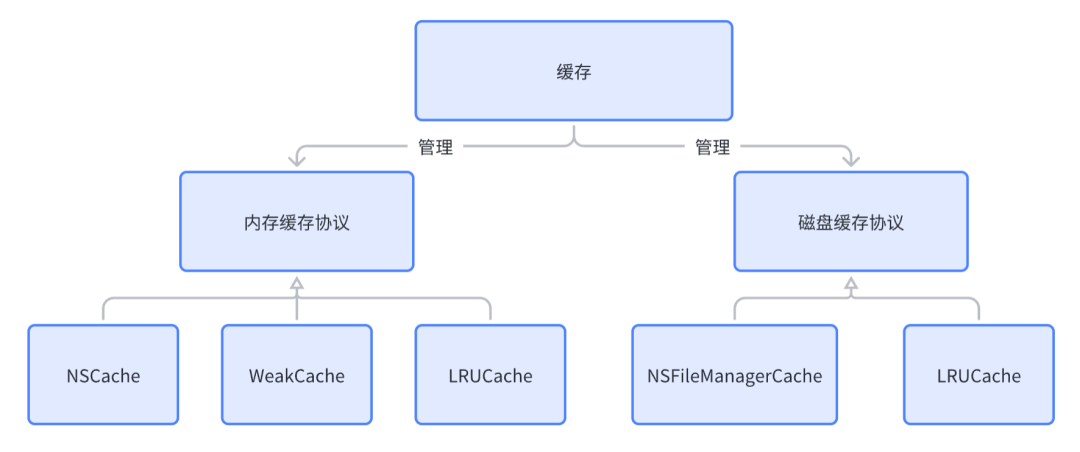
图片下载到客户端上后都是未经过解码前的数据,想要把图片正确展示给用户,就必须对它进行解码。图片解码上支持通过 iOS 原生系统的解码框架 ImageIO 进行解码,即苹果原生能支持的格式,SDK 也能支持。除此之外,像 WebP、AVIF、VVIC(字节基于 BVC 算法自研的图片格式)等原生不支持的图片格式,SDK 通过自研解码器或者开源解码器的支持,也都能解码这些格式的图片。当有新格式的图片要支持时,只需实现对应格式的动静图协议就能以插件化的形式集成进 SDK,达到支持新格式图片的目的。
HEIF 这种高压缩率格式的图片在字节跳动公司内部的应用已经比较成熟了。带宽节省方面,相比 WebP,在同质量下还能再节约 30% 的带宽成本,为公司节省了大量的带宽成本。加载优化方面,HEIF 支持渐进式加载,可以先加载 HEIF 缩略图,再加载 HEIF 原图,在网络质量不好的场景下也能有不错的图片加载体验。SDK 有了公司内部自研的高性能 HEIF 软件解码库的支持,让 HEIF 格式图片的解码支持摆脱了 iOS 系统的限制,不再局限在 iOS 11 及以上才能使用 HEIF 静图,iOS 13 及以上才能使用 HEIF 动图,在低版本 iOS 上也能支持 HEIF 动静图,极大的提升了 HEIF 的应用范围,收获了大量的带宽成本节省收益。
在图片加载完后,业务也可以根据需要再次对图片进行各种实时转换,比如说加圆角、超分等,这些都是通过图片后处理来完成。下面介绍下 SDK 的一个特色能力:超分。
超分,即超分辨率,指的是基于机器学习/深度学习方法,从给定的低分辨率图片中恢复高分辨率的图片,借助图片后处理,可以在移动端上做到图片实时超分。
一般可以用于两种场景,一是用于提升用户体验,当原图片分辨率低、清晰度低时,对其进行超分后,可以用来提升清晰度,以达到提升用户观看体验的目的;二是用于降档超分,用户在请求高分辨率的图片时,可以在传输过程中降低图片的分辨率,然后在客户端上进行超分,提升到原请求的分辨率,以达到节省带宽成本的目的。

SDK 包含了三大日志模块,图片性能日志、用户感知日志,大图监控日志,为业务的运营及产品的体验提升提供了全面的数据支持。配合火山引擎 veImageX 的控制台,可以实时查看各项可视化大盘数据,全方位的监控图片的各项指标。
其中,图片性能日志包括了图片 URL、下载耗时、解码耗时、错误码、图片来源等数据,用来监控图片各项性能指标;用户感知日志包括了图片 URL、ImageView 的 Size、ImageView 展示图片耗时等数据,用来监控用户体验各项指标;大图监控日志则包含了大图 URL、内存占用大小、图片文件体积、图片分辨率大小等数据,可以全面的监控异常大图情况。
SDK 致力于极致的图片加载用户体验,为此,SDK 做了很多相关性能优化,下面主要介绍下 SDK 如何提升图片加载体验、降低内存占用、优化动图播放。
图片加载的快慢直接影响到用户的使用体验,高效的图片加载是 SDK 不可或缺的能力。
加载静图大图,或者加载多帧数动图,亦或者在弱网场景下,都可以开启图片渐进式加载来提升图片的加载体验。
SDK 支持传统的 PNG、JPEG 静图渐进式加载,也支持HEIF静图渐进式加载,先加载 HEIF 缩略图,再加载HEIF原图。SDK 同时也支持动图的渐进式加载,动图可以边下载边播放,在正常网络下,可以提高首帧的加载速度,在弱网下,类似于视频播放的缓冲机制,也可以提升动图的播放体验。
在图片解码方面,SDK 支持 Force Decode,能够提前把 Bitmap Buffer 转移到渲染进程,减少了未来渲染时再去拷贝的耗时,如果原始解码出来的 Bitmap Buffer,iOS 硬件屏幕不直接支持,会提前转换好,避免渲染时在主线程的转换开销,提高图片的加载帧率。
通常情况下,App 内图片的场景还是很多的,当加载大量图片时,图片所占的内存可能会很大,如果内存占用过高,会带来 OOM 问题,给用户的感受跟 Crash 一样,都是应用突然闪退。
SDK 有如下的几种方案来降低图片内存占用:
当系统内存紧张,收到内存不足通知时,缓存模块会及时释放内存缓存,同时也提供接口,由业务在适当时机主动释放内存缓存。
图片在内存中的占用大小可以简单用如下公式来估算:
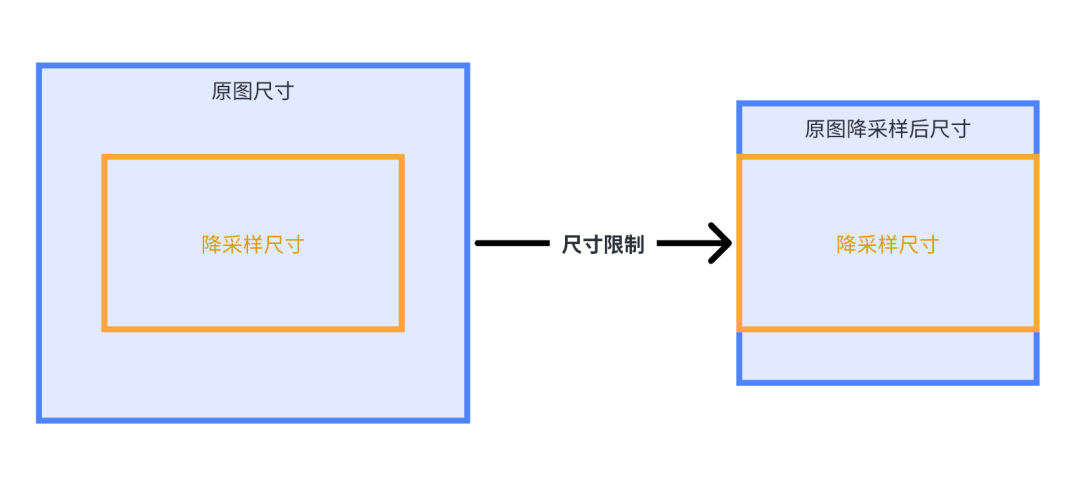
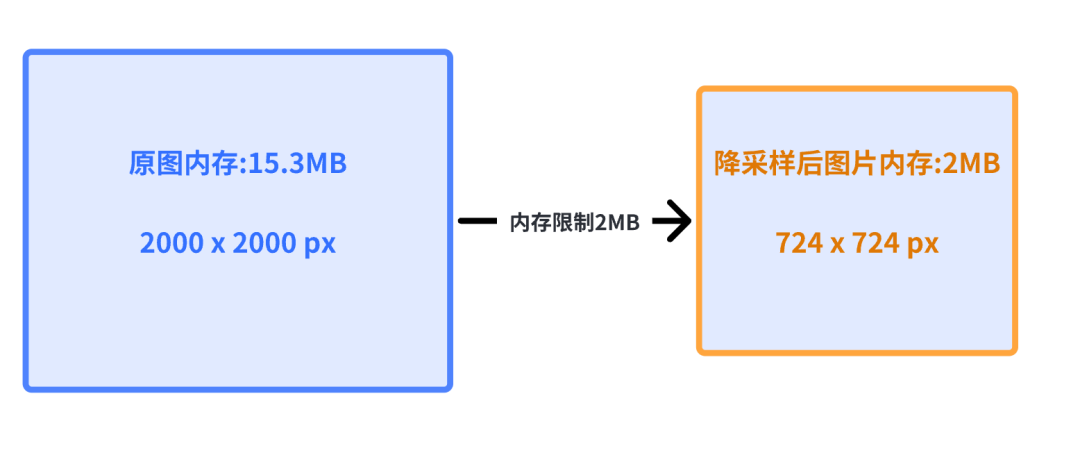
memoryCost(单位:字节)= imageWidth(单位:像素)* imageHeight(单位:像素)* 4由公式可以看出,如果想要降低内存,那么就要想办法在不影响功能和体验的前提下尽量降低图片的宽高,由此,当不能明确下载后的图片大小是否会远大于需要展示的 ImageView 的大小时,可以使用全局图片降采样功能。全局图片降采样分为以尺寸大小限制进行降采样和以内存大小限制进行降采样。
以尺寸大小限制进行降采样:
如果当前图片的长宽都大于降采样的长宽,那么把原图片长宽等比例缩放到恰好能贴到降采样尺寸的轮廓
以内存大小限制进行降采样:
如果当前图片的内存占用超过内存限制,那么把原图片长宽等比例缩放到恰好低于内存限额
每次需要渲染前,都会给业务回调当前图片的元信息,例如图片的长宽尺寸、动图的帧数、以及预估的内存消耗量,业务可以根据此信息来禁止不符合预期的超大图渲染。
实际业务场景中,待展示图片的分辨率和帧数都是未知的。在一些极端情况下(线上真实案例),某个动图分辨率是 1080p、帧数上百帧,是用户录屏生成的,是个超大的动图,解码后有超过 1 个 GB的内存占用,在一些低端机上就直接 OOM了。对于这类 OOM 情况,很难根据常规方法排查。那怎么有效监控这种不符合预期的线上大图呢,SDK 通过图片展示尺寸,图片解码后内存占用大小和图片文件体积这三个维度来定义一个大图,当一张图片触发这三个维度中任意一个维度的阈值限制时,就会被记录到大图监控日志内,这些数据后续会被上报。业务通过 veImageX 控制台就可以看到大图监控这个指标下的详细数据,当发现内存占用大小这个值异常大后,就可以及时查到相应的图片 URL,然后结合实际业务场景,及时下线这种不符合预期的超大图,降低线上 OOM 率。
动图在业务上也是一个常见应用场景,如果能做好动图的优化,也可以带来用户体验的提升。动图在播放时,会不断解码每一帧图片,这时会大量消耗 CPU 资源,SDK 内部会计算当前可用的内存以及渲染动图的所有帧需要的内存,如果当前可用内存满足渲染动图所有帧需要的内存时,SDK 会缓存动图的所有帧,以此来节省 CPU 资源,如果当前可用内存不满足渲染动图所有帧需要的内存时,SDK 会在每一帧图片播放结束之后舍弃前一帧,也就是不断重复渲染下一帧图片,通过消耗 CPU 资源节约内存,达到 CPU 消耗与内存节省的一个平衡。
业内虽然已经有很多很成熟的图片加载 SDK 了,但要契合公司自己业务发展的 SDK 也很重要,图片加载 SDK 作为 veImageX 整体产品端到端不可或缺的一环,也是在这种背景下应运而生了。除了一些性能优化外,在成本节省上,HEIF 格式的应用为公司节省了大量带宽成本,收益非常可观,并且也在持续尝试新的压缩率更高的图片格式,例如 VVIC。在前沿能力应用上,随着图片超分算法的不断迭代优化,相信在未来也能带来不错的体验上的提升和成本上的节省。
鉴于我有以下迁移:Sequel.migrationdoupdoalter_table:usersdoadd_column:is_admin,:default=>falseend#SequelrunsaDESCRIBEtablestatement,whenthemodelisloaded.#Atthispoint,itdoesnotknowthatusershaveais_adminflag.#Soitfails.@user=User.find(:email=>"admin@fancy-startup.example")@user.is_admin=true@user.save!ende
我发现ActiveRecord::Base.transaction在复杂方法中非常有效。我想知道是否可以在如下事务中从AWSS3上传/删除文件:S3Object.transactiondo#writeintofiles#raiseanexceptionend引发异常后,每个操作都应在S3上回滚。S3Object这可能吗?? 最佳答案 虽然S3API具有批量删除功能,但它不支持事务,因为每个删除操作都可以独立于其他操作成功/失败。该API不提供任何批量上传功能(通过PUT或POST),因此每个上传操作都是通过一个独立的API调用完成的
我收到这个错误:RuntimeError(自动加载常量Apps时检测到循环依赖当我使用多线程时。下面是我的代码。为什么会这样?我尝试多线程的原因是因为我正在编写一个HTML抓取应用程序。对Nokogiri::HTML(open())的调用是一个同步阻塞调用,需要1秒才能返回,我有100,000多个页面要访问,所以我试图运行多个线程来解决这个问题。有更好的方法吗?classToolsController0)app.website=array.join(',')putsapp.websiteelseapp.website="NONE"endapp.saveapps=Apps.order("
这里有一个很好的答案解释了如何在Ruby中下载文件而不将其加载到内存中:https://stackoverflow.com/a/29743394/4852737require'open-uri'download=open('http://example.com/image.png')IO.copy_stream(download,'~/image.png')我如何验证下载文件的IO.copy_stream调用是否真的成功——这意味着下载的文件与我打算下载的文件完全相同,而不是下载一半的损坏文件?documentation说IO.copy_stream返回它复制的字节数,但是当我还没有下
我是Rails的新手,所以请原谅简单的问题。我正在为一家公司创建一个网站。那家公司想在网站上展示它的客户。我想让客户自己管理这个。我正在为“客户”生成一个表格,我想要的三列是:公司名称、公司描述和Logo。对于名称,我使用的是name:string但不确定如何在脚本/生成脚手架终端命令中最好地创建描述列(因为我打算将其设置为文本区域)和图片。我怀疑描述(我想成为一个文本区域)应该仍然是描述:字符串,然后以实际形式进行调整。不确定如何处理图片字段。那么……说来话长:我在脚手架命令中输入什么来生成描述和图片列? 最佳答案 对于“文本”数
我正在尝试解析一个文本文件,该文件每行包含可变数量的单词和数字,如下所示:foo4.500bar3.001.33foobar如何读取由空格而不是换行符分隔的文件?有什么方法可以设置File("file.txt").foreach方法以使用空格而不是换行符作为分隔符? 最佳答案 接受的答案将slurp文件,这可能是大文本文件的问题。更好的解决方案是IO.foreach.它是惯用的,将按字符流式传输文件:File.foreach(filename,""){|string|putsstring}包含“thisisanexample”结果的
我一直致力于让我们的Rails2.3.8应用程序在JRuby下正确运行。一切正常,直到我启用config.threadsafe!以实现JRuby提供的并发性。这导致lib/中的模块和类不再自动加载。使用config.threadsafe!启用:$rubyscript/runner-eproduction'pSim::Sim200Provisioner'/Users/amchale/.rvm/gems/jruby-1.5.1@web-services/gems/activesupport-2.3.8/lib/active_support/dependencies.rb:105:in`co
我们目前正在为ROR3.2开发自定义cms引擎。在这个过程中,我们希望成为我们的rails应用程序中的一等公民的几个类类型起源,这意味着它们应该驻留在应用程序的app文件夹下,它是插件。目前我们有以下类型:数据源数据类型查看我在app文件夹下创建了多个目录来保存这些:应用/数据源应用/数据类型应用/View更多类型将随之而来,我有点担心应用程序文件夹被这么多目录污染。因此,我想将它们移动到一个子目录/模块中,该子目录/模块包含cms定义的所有类型。所有类都应位于MyCms命名空间内,目录布局应如下所示:应用程序/my_cms/data_source应用程序/my_cms/data_ty
1.错误信息:Errorresponsefromdaemon:Gethttps://registry-1.docker.io/v2/:net/http:requestcanceledwhilewaitingforconnection(Client.Timeoutexceededwhileawaitingheaders)或者:Errorresponsefromdaemon:Gethttps://registry-1.docker.io/v2/:net/http:TLShandshaketimeout2.报错原因:docker使用的镜像网址默认为国外,下载容易超时,需要修改成国内镜像地址(首先阿里
print"Enteryourpassword:"pass=STDIN.noecho(&:gets)puts"Yourpasswordis#{pass}!"输出:Enteryourpassword:input.rb:2:in`':undefinedmethod`noecho'for#>(NoMethodError) 最佳答案 一开始require'io/console'后来的Ruby1.9.3 关于ruby-为什么不能使用类IO的实例方法noecho?,我们在StackOverflow上