
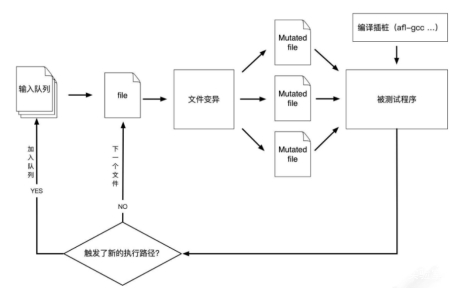
AFL(American Fuzzy Lop)是由安全研究员Micha Zalewski 开发的一款基于覆盖引导(Coverage-guided)的模糊测试工具,它通过记录输入样本的代码覆盖率,从而调整输入样本以提高覆盖率,增加发现漏洞的概率。
①从源码编译程序时进行插桩,以记录代码覆盖率(Code Coverage);
②选择一些输入文件,作为初始测试集加入输入队列(queue);
③将队列中的文件按一定的策略进行“突变”;
④如果经过变异文件更新了覆盖范围,则将其保留添加到队列中;
⑤上述过程会一直循环进行,期间触发了crash的文件会被记录下来。
1.安装AFL
下载源码

Make

llvm_mode安装

之后输入以下命令进行安装

2.AFL测试
下载一个有缺陷的c文件

使用 afl-gcc/afl-clang 编译

生成一些种子语料库

开始fuzz
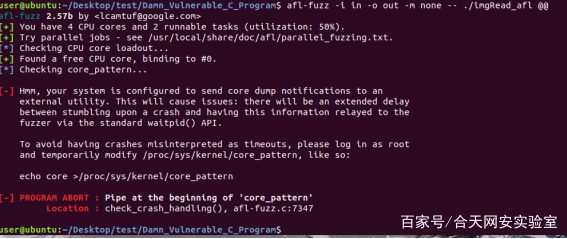
提示修改/proc/sys/kernel/core_pattern

再次运行之前的代码可看到fuzz进度
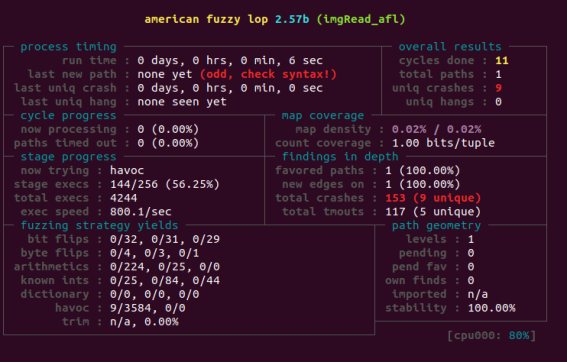
现在就表示我们的ACL已经安装成功了,注意出现(odd,check syntax!)是表示样例根本没有进入到测试中去,需要调整语料库。
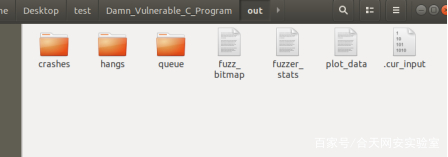
Ctrl+C打断可以在out文件里看见我们的测试信息
3.并行fuzz测试
每个afl-fuzz进程占用CPU的一个核,实际上如果是多核的主机,AFL就可以并行工作
首先先看自己有多少内核
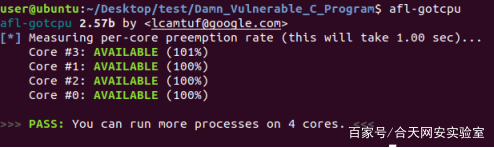
以上可以看出有四个内核意味着可以同时运行4个实例
首先指定主实例 -M 用于主实例,将 -S 添加到所有从属实例。它们可以相互同步
主实例:afl-fuzz -M master -i in/ -o out/ -m none -- ./imgRead_afl @@
从实例:afl-fuzz -S slave1 -i in/ -o out/ -m none -- ./imgRead_afl @@

在之前的out文件夹会多出俩个不同的文件夹masterh和slave1
现在尝试假如我们一次性运行5个实例会怎么样
在运行第5个实例后报错,其他实例不受影响,也可以确定4个核在运行中

libjpeg是专门处理Jpeg解码、编码、转码的自由软件库。libjpeg-turbo是其fork版本,还有一个基于libjpeg-turbo的fork的版本是MozJpeg。
1.编译libjpeg-turbo
首先下载libjpeg-turbo
之后需要修改cmakelist.txt,进行插桩编译
在cmakelist.txt中,在cmake_minimum_required命令下添加编译器选项,在前面添加,免得被覆盖,进行插桩编译
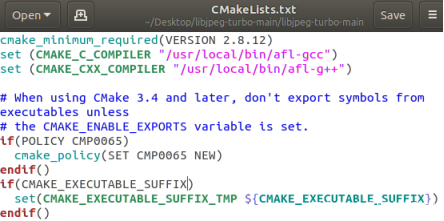
之后在libjpeg-turbo文件夹下
mkdir build
cd build
cmake ..
make
sudo make install
安装好之后build的内容如下
之后利用程序的示例对是否成功安装libjpeg-turbo库进行测试

该函数有俩个参数 一个输入文件名,一个作为输出文件名
具体作用就是调用了turbojpeg.h这个库函数对输入的jpg图片进行压缩
因为修改了cmake中的编译器设置,应该库函数里已经是被插过桩的,所以在编译时是可以不用afl-gcc编译也可以进行检测
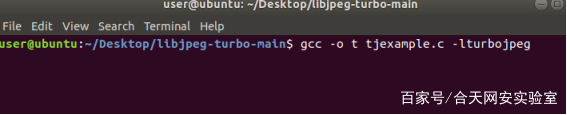
这样是可以生成可执行文件,也可以实现压缩图片的功能,这里也对之前的样例进行了修改,只接收一个变量,并且不对压缩文件进行保存

但在进行模糊测试时出现以下问题
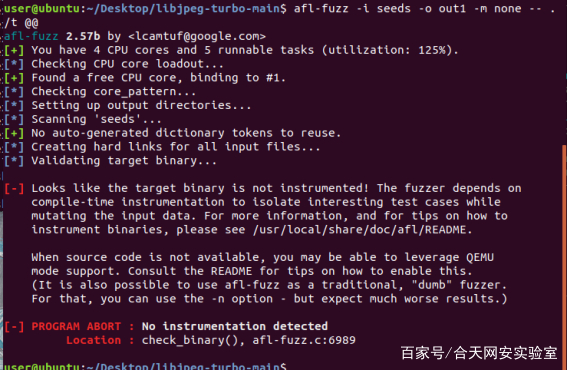
没有插桩信息,无法进行测试
发现它是动态编译的,虽然应该其动态链接库是插过桩的。但最后已知没有实现。这里最后考虑是想通过链接静态库实现。也是在网上查询未果后,发现在根目录下输入 make test,可以调用他自己的样例进行测试,这其中就包括了静态链接的测试
在一个静态链接测试的项目下,查看其ling.txt,得到静态编译的方式
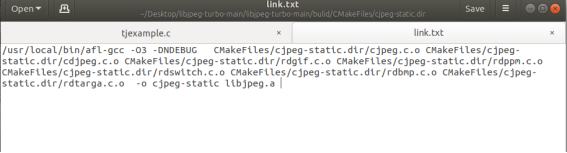
最后对自己的编译自己的样例

之后开始模糊测试
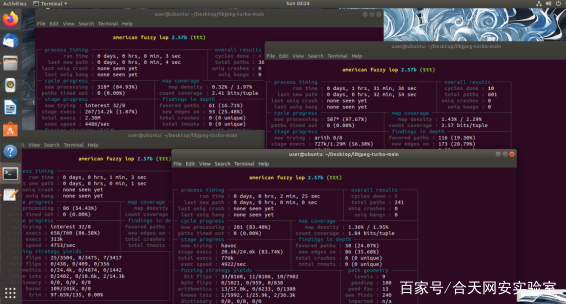
总共测试次数超过1亿次,开了4个并行
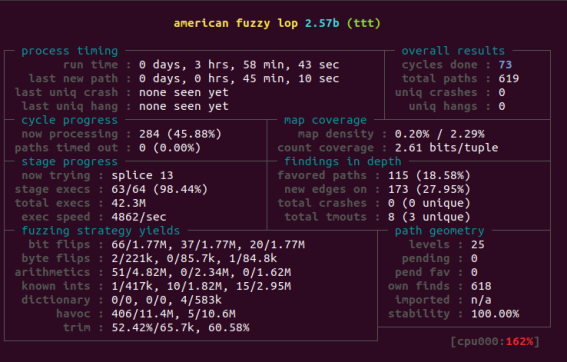
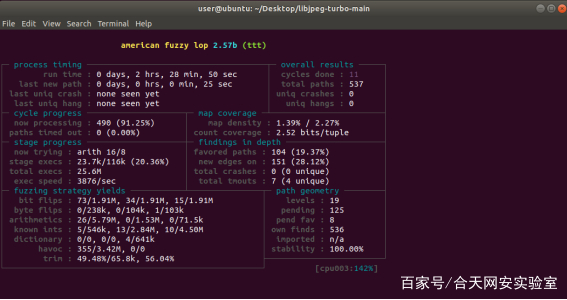
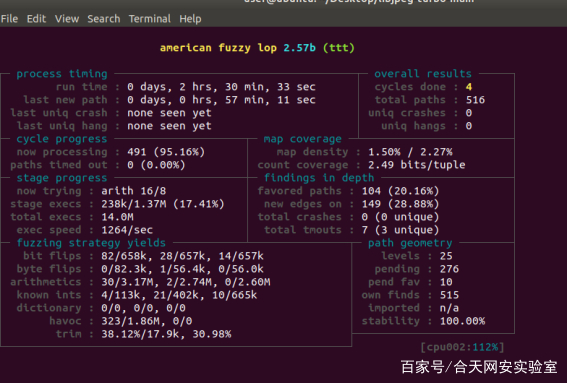
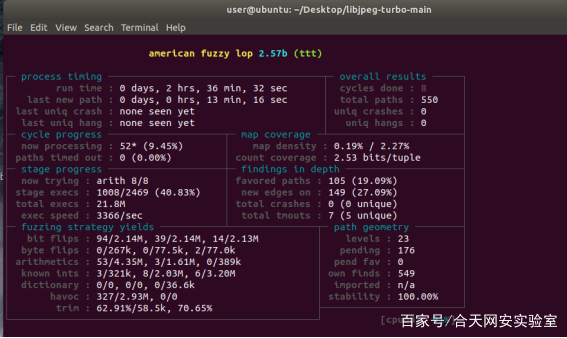
4个样例的的最开始输入都是不一样的,可以从路径速度和总量上看出明显的区别,确实libjpeg-turbo在更新2.0之后,其安全性能得到了极大的提升,没有收到一个报错信息。
2.内存错误检查工具
这里有很多的内存检查工具,这里举个大概,只大概研究ASAN (-fsanitize=address)的使用和与AFL测试的结合
这里测试了几个漏洞文件以此来明晰ASAN的作用
编译文件模板如下
g++ -fsanitize=address -fno-omit-frame-pointer -o t xxx.cpp
这里只对几种漏洞进行展示
use-after-fee
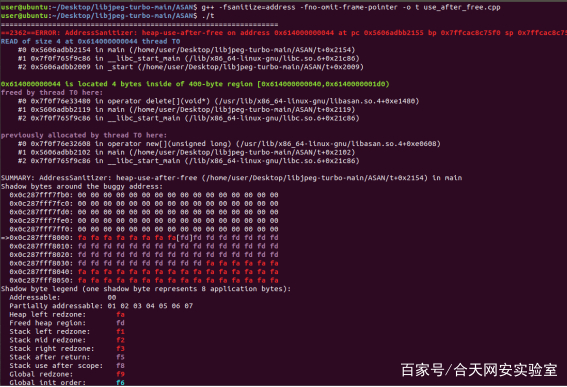
可以看到漏洞的名称和发生的内存地址
stack buffer overflow
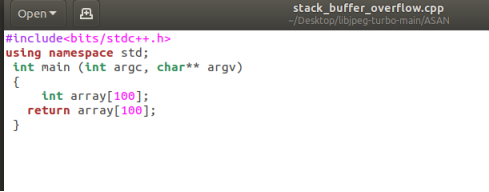

还有很多其他类型的漏洞可以进行检测
Address Sanitizer 用法 - 简书 (jianshu.com)
在AFL中启用ASAN的方式也比较简单
在make时加上AFL_USE_ASAN=1

注意之后编译文件时需要加上启用asan的参数,不然会报错

3.构造自己的字典
AFL自带自己的一个字典库,主要用于各种变异操作的
如下是AFL的jpeg的字典

为了符合jpeg图片的实际,需要分析在jpeg中出现次数多且固定的字符
这里挑选一些频率较高的字符加入字典

这里挑选的字符主要来源自各种jpeg的开头部分
之后如果要使用字典需要使用-x参数进行指定字典文件

https://paper.seebug.org/496/#dictionary
4.语料库蒸馏
afl-cmin的核心思想是:尝试找到与语料库全集具有相同覆盖范围的最小子集。 举个例子,假设有多个文件,都覆盖了相同的代码,那么就丢掉多余的文件。

最后只留下一个文件
afl-tmin(减小单个输入文件的大小)
afl-tmin有两种工作模式,
instrumented mode和crash mode。默认的工作方式是instrumented mode

后面查资料得到tmin只能处理文件,文件夹需要修改脚本
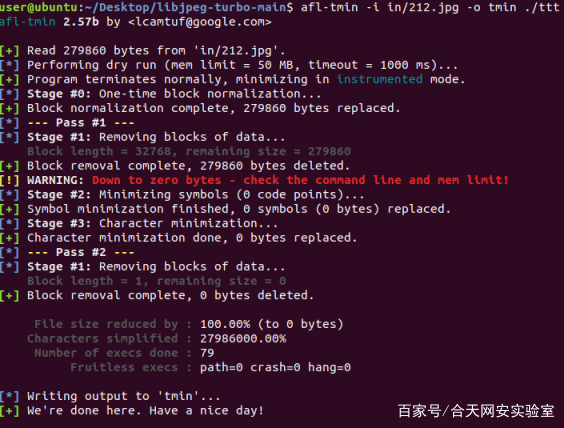
精简到0bytes,后面在网上看到了相似的例子,这和tmin的精简策略有关,确实存在这种情况。
如果加上了参数-x,就会调用crash mode模式,会把导致程序非正常退出的文件直接剔除。这里测试的样例并没有crash例子,所以不进行测试。
5.持久模式
在持久模式下,AFL 仅模糊部分程序,而不是整个程序。当只想模糊复杂软件中的特定功能时,这很有用。与分叉服务器模式相比,这提供了许多速度改进。
具体例子如下:

对想要进行的部分进行修改

此时修改的文件是turbojpeg.c
再修改cmakelist.txt如下
之后对库进行重新编译
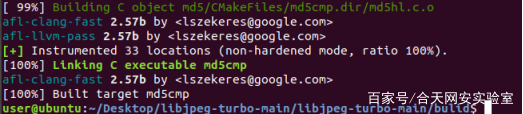
编译方式

再进行afl-fuzz(与之前一致)
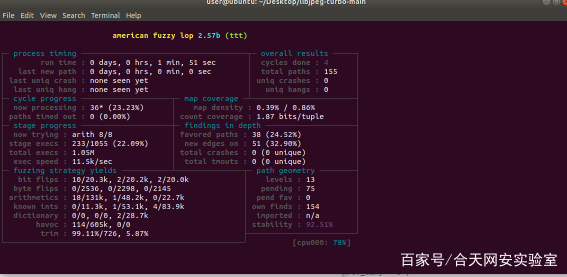
速度上确实比之前的速度要快,最快时比之前要快上俩倍多
6.Afl-cov使用
可以快速帮助我们调用lcov和gcov处理来自afl-fuzz测试用例的代码覆盖率结果
安装
GCOV,它随gcc一起发布,所以不需要再单独安装,和afl-gcc插桩编译的原理一样,gcc编译时生成插桩的程序,用于在执行时生成代码覆盖率信息
LCOV,它是GCOV的图形前端,可以收集多个源文件的gcov数据,并创建包含使用覆盖率信息注释的源代码HTML页面。

这里也可以使用apt-install afl-cov来安装,不过看网上建议这个版本实际使用上会有问题,所以这里还是直接下载源码

为了实现检查覆盖率需要修改cmakelist.txt如下
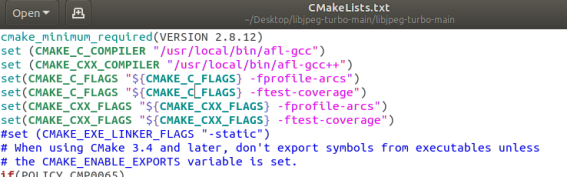
再次编译库
编译文件

这里的afl-cov选择实时监控 也就是添加--live,先启动afl-cov,后启动afl-fuzz,当afl-fuzz退出时,afl-cov就会跟着退出
启动afl-cov的命令
/home/user/Desktop/afl-cov/afl-cov -d afl-cc --live --enable-branch-coverage -c . -e "cat AFL_FILE | ./ttt AFL_FILE" --overwrite
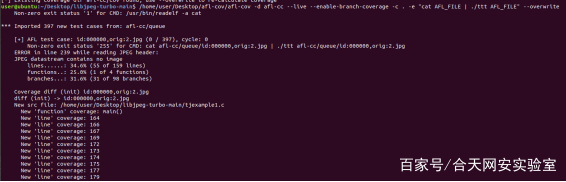
-d是之后afl-fuzz的输出文件,-c是直向源码文件的,在编译.c文件后,会生成一个.gno文件,-c 后面跟该文件的目录
启动afl-fuzz(与之前一致)

Afl-fuzz退出后,afl-cov需要等一会才能正常退出,此时就可以看见生成分析的网页了
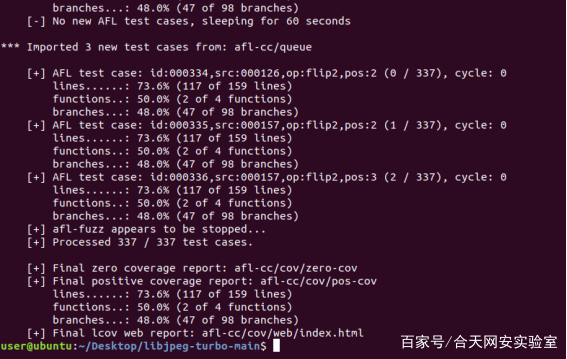
也可以针对已经生成的数据直接开启afl-cov,但要求编译已经加上了-fprofile-arcs -ftest-coverage
网页首页
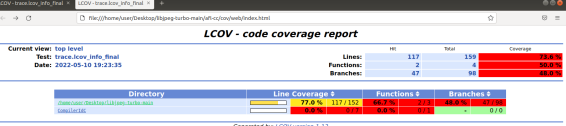
也可以进入到文件里,查看具体语句的执行次数

7.afl_postprocess使用
它最主要的作用就是可以规定生成种子的格式
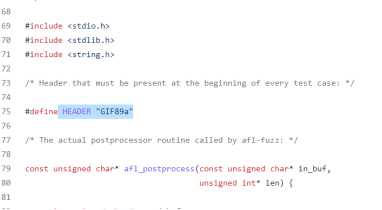
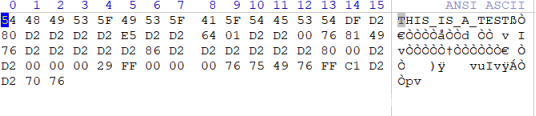
作者在github上的样例的作用是让每个测试用例开头的标头都是GIF89a
https://github.com/mirrorer/afl/blob/master/experimental/post_library/post_library.so.c
编译方法
gcc -shared -wall -O3 post_library.so.c -o post_library.so
可以看看afl-fuzz.c对该方法的支持

获取AFL_POST_LIBRARY环境变量的值,自动加载afl_postprocess函数
这里推荐使用export设定环境变量,需要说明的是export的环境变量只在当前的shell(BASH)或其子shell(BASH)下是有效的,shell关闭了,变量也就失效了,再打开新shell时就没有这个变量,需要使用的话还需要重新定义。如果需要一直使用,需要修改配置文件,方法推荐
https://blog.csdn.net/wx_it/article/details/118450790
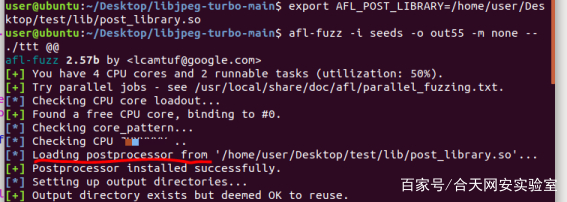
加载后处理器库成功
也可以看到我们的测试样例变成了GIF格式,后处理库有效。
测试其他的例子

这部分需要注意的是对源码的处理,确保样例格式的满足输入的要求
实验:Fuzz之AFL(合天网安实验室) 点击进入实操>>![]() https://www.yijinglab.com/expc.do?ce=7ffeb07e-680b-4490-8667-cf66b362635c 更多靶场实验练习、网安学习资料:请点击这里>>https://www.hetianlab.com/
https://www.yijinglab.com/expc.do?ce=7ffeb07e-680b-4490-8667-cf66b362635c 更多靶场实验练习、网安学习资料:请点击这里>>https://www.hetianlab.com/![]() https://www.hetianlab.com/
https://www.hetianlab.com/
我正在学习如何使用Nokogiri,根据这段代码我遇到了一些问题:require'rubygems'require'mechanize'post_agent=WWW::Mechanize.newpost_page=post_agent.get('http://www.vbulletin.org/forum/showthread.php?t=230708')puts"\nabsolutepathwithtbodygivesnil"putspost_page.parser.xpath('/html/body/div/div/div/div/div/table/tbody/tr/td/div
我有一个Ruby程序,它使用rubyzip压缩XML文件的目录树。gem。我的问题是文件开始变得很重,我想提高压缩级别,因为压缩时间不是问题。我在rubyzipdocumentation中找不到一种为创建的ZIP文件指定压缩级别的方法。有人知道如何更改此设置吗?是否有另一个允许指定压缩级别的Ruby库? 最佳答案 这是我通过查看rubyzip内部创建的代码。level=Zlib::BEST_COMPRESSIONZip::ZipOutputStream.open(zip_file)do|zip|Dir.glob("**/*")d
类classAprivatedeffooputs:fooendpublicdefbarputs:barendprivatedefzimputs:zimendprotecteddefdibputs:dibendendA的实例a=A.new测试a.foorescueputs:faila.barrescueputs:faila.zimrescueputs:faila.dibrescueputs:faila.gazrescueputs:fail测试输出failbarfailfailfail.发送测试[:foo,:bar,:zim,:dib,:gaz].each{|m|a.send(m)resc
很好奇,就使用rubyonrails自动化单元测试而言,你们正在做什么?您是否创建了一个脚本来在cron中运行rake作业并将结果邮寄给您?git中的预提交Hook?只是手动调用?我完全理解测试,但想知道在错误发生之前捕获错误的最佳实践是什么。让我们理所当然地认为测试本身是完美无缺的,并且可以正常工作。下一步是什么以确保他们在正确的时间将可能有害的结果传达给您? 最佳答案 不确定您到底想听什么,但是有几个级别的自动代码库控制:在处理某项功能时,您可以使用类似autotest的内容获得关于哪些有效,哪些无效的即时反馈。要确保您的提
假设我做了一个模块如下:m=Module.newdoclassCendend三个问题:除了对m的引用之外,还有什么方法可以访问C和m中的其他内容?我可以在创建匿名模块后为其命名吗(就像我输入“module...”一样)?如何在使用完匿名模块后将其删除,使其定义的常量不再存在? 最佳答案 三个答案:是的,使用ObjectSpace.此代码使c引用你的类(class)C不引用m:c=nilObjectSpace.each_object{|obj|c=objif(Class===objandobj.name=~/::C$/)}当然这取决于
我正在尝试使用ruby和Savon来使用网络服务。测试服务为http://www.webservicex.net/WS/WSDetails.aspx?WSID=9&CATID=2require'rubygems'require'savon'client=Savon::Client.new"http://www.webservicex.net/stockquote.asmx?WSDL"client.get_quotedo|soap|soap.body={:symbol=>"AAPL"}end返回SOAP异常。检查soap信封,在我看来soap请求没有正确的命名空间。任何人都可以建议我
关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭4年前。Improvethisquestion我想在固定时间创建一系列低音和高音调的哔哔声。例如:在150毫秒时发出高音调的蜂鸣声在151毫秒时发出低音调的蜂鸣声200毫秒时发出低音调的蜂鸣声250毫秒的高音调蜂鸣声有没有办法在Ruby或Python中做到这一点?我真的不在乎输出编码是什么(.wav、.mp3、.ogg等等),但我确实想创建一个输出文件。
我在我的项目目录中完成了compasscreate.和compassinitrails。几个问题:我已将我的.sass文件放在public/stylesheets中。这是放置它们的正确位置吗?当我运行compasswatch时,它不会自动编译这些.sass文件。我必须手动指定文件:compasswatchpublic/stylesheets/myfile.sass等。如何让它自动运行?文件ie.css、print.css和screen.css已放在stylesheets/compiled。如何在编译后不让它们重新出现的情况下删除它们?我自己编译的.sass文件编译成compiled/t
我想将html转换为纯文本。不过,我不想只删除标签,我想智能地保留尽可能多的格式。为插入换行符标签,检测段落并格式化它们等。输入非常简单,通常是格式良好的html(不是整个文档,只是一堆内容,通常没有anchor或图像)。我可以将几个正则表达式放在一起,让我达到80%,但我认为可能有一些现有的解决方案更智能。 最佳答案 首先,不要尝试为此使用正则表达式。很有可能你会想出一个脆弱/脆弱的解决方案,它会随着HTML的变化而崩溃,或者很难管理和维护。您可以使用Nokogiri快速解析HTML并提取文本:require'nokogiri'h
我想为Heroku构建一个Rails3应用程序。他们使用Postgres作为他们的数据库,所以我通过MacPorts安装了postgres9.0。现在我需要一个postgresgem并且共识是出于性能原因你想要pggem。但是我对我得到的错误感到非常困惑当我尝试在rvm下通过geminstall安装pg时。我已经非常明确地指定了所有postgres目录的位置可以找到但仍然无法完成安装:$envARCHFLAGS='-archx86_64'geminstallpg--\--with-pg-config=/opt/local/var/db/postgresql90/defaultdb/po