

🐱🐉作者简介:大家好,我是黑洞晓威,一名大二学生,希望和大家一起进步。
👿本文收录于 算法,本专栏是针对大学生、初学算法的人准备,解析常见的数据结构与算法,同时备战蓝桥杯。
首先要知道数组在内存中的存储方式,这样才能真正理解数组相关的题
数组是存放在连续内存空间上的相同类型数据的集合。
数组可以方便的通过下标索引的方式获取到下标下对应的数据。
举一个字符数组的例子,如图所示:
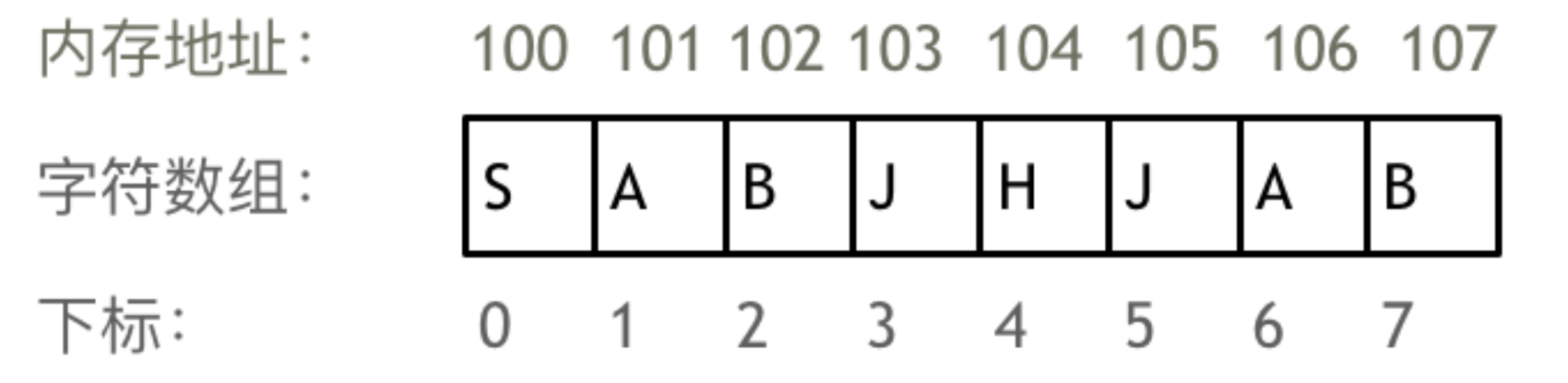
需要两点注意的是
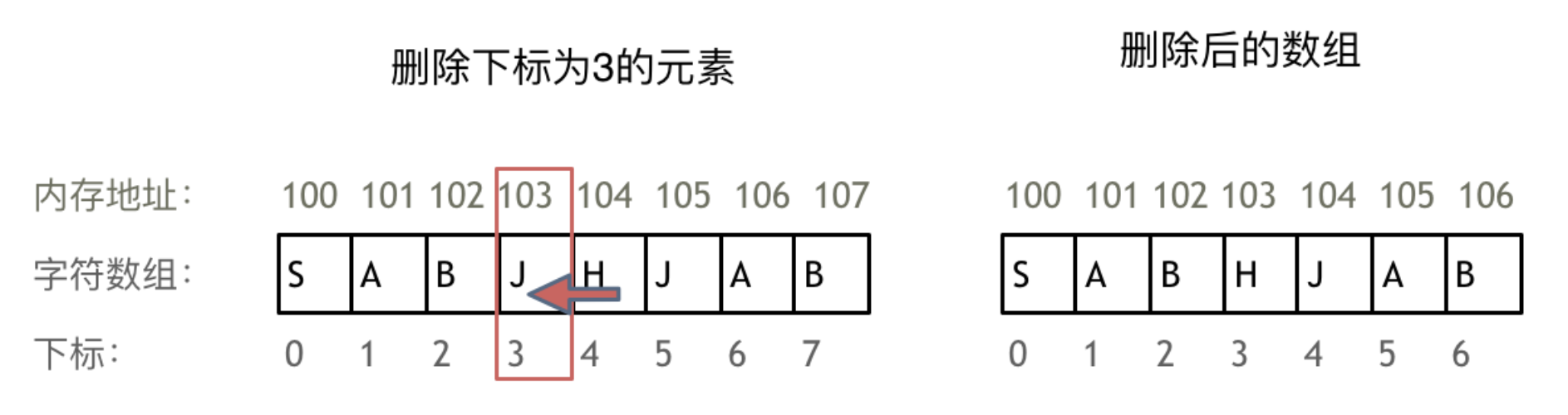
正是因为数组的在内存空间的地址是连续的,所以我们在删除或者增添元素的时候,就难免要移动其他元素的地址。
例如删除下标为3的元素,需要对下标为3的元素后面的所有元素都要做移动操作,如图所示:

优点:查询/查找/检索某个下标上的元素时效率极高。
原因:
第一:每一个元素的内存地址在空间存储上是连续的。
第二:每一个元素类型相同,所以占用空间大小一样。
第三:知道第一个元素内存地址,知道每一个元素占用空间的大小,又知道下标,所以通过一个数学表达式就可以计算出某个下标上元素的内存地址。直接通过内存地址定位元素,所以数组的检索效率是最高的。
注意:
缺点:
第一:由于为了保证数组中每个元素的内存地址连续,所以在数组上随机删除或者增加元素的时候,效率较低,因为随机增删元素会涉及到后面元素统一向前或者向后位移的操作。
第二:数组不能存储大数据量。
因为很难在内存空间上找到一块特别大的连续的内存空间。
注意:
对于数组中最后一个元素的增删,是没有效率影响的。
数组(Array)是一种线性表数据结构。它用一组连续的内存空间,来存储一组具有相同类型的数据。
这个定义里有几个关键词,理解了这几个关键词,我想你就能彻底掌握数组的概念了。下面就从我的角度分别给你“点拨”一下。
第一是 线性表(Linear List)。顾名思义,线性表就是数据排成像一条线一样的结构。每个线性表上的数据最多只有前和后两个方向。其实除了数组,链表、队列、栈等也是线性表结构。

而与它相对立的概念是 非线性表,比如二叉树、堆、图等。之所以叫非线性,是因为,在非线性表中,数据之间并不是简单的前后关系。

第二个是 连续的内存空间和相同类型的数据。正是因为这两个限制,它才有了一个堪称“杀手锏”的特性:“随机访问”。但有利就有弊,这两个限制也让数组的很多操作变得非常低效,比如要想在数组中删除、插入一个数据,为了保证连续性,就需要做大量的数据搬移工作。
说到数据的访问,那你知道数组是如何实现根据下标随机访问数组元素的吗?
我们拿一个长度为10的int类型的数组int[] a = new int[10]来举例。在我画的这个图中,计算机给数组a[10],分配了一块连续内存空间1000~1039,其中,内存块的首地址为base_address = 1000。

我们知道,计算机会给每个内存单元分配一个地址,计算机通过地址来访问内存中的数据。当计算机需要随机访问数组中的某个元素时,它会首先通过下面的寻址公式,计算出该元素存储的内存地址:
a[i]_address = base_address + i * data_type_size
其中data_type_size表示数组中每个元素的大小。我们举的这个例子里,数组中存储的是int类型数据,所以data_type_size就为4个字节。这个公式非常简单,我就不多做解释了。
这里我要特别纠正一个“错误”。问到数组和链表的区别,很多人都回答说,“链表适合插入、删除,时间复杂度O(1);数组适合查找,查找时间复杂度为O(1)”。
实际上,这种表述是不准确的。数组是适合查找操作,但是查找的时间复杂度并不为O(1)。即便是排好序的数组,你用二分查找,时间复杂度也是O(logn)。所以,正确的表述应该是,数组支持随机访问,根据下标随机访问的时间复杂度为O(1)。
前面概念部分我们提到,数组为了保持内存数据的连续性,会导致插入、删除这两个操作比较低效。现在我们就来详细说一下,究竟为什么会导致低效?又有哪些改进方法呢?
我们先来看 插入操作。
假设数组的长度为n,现在,如果我们需要将一个数据插入到数组中的第k个位置。为了把第k个位置腾出来,给新来的数据,我们需要将第k~n这部分的元素都顺序地往后挪一位。那插入操作的时间复杂度是多少呢?你可以自己先试着分析一下。
如果在数组的末尾插入元素,那就不需要移动数据了,这时的时间复杂度为O(1)。但如果在数组的开头插入元素,那所有的数据都需要依次往后移动一位,所以最坏时间复杂度是O(n)。 因为我们在每个位置插入元素的概率是一样的,所以平均情况时间复杂度为(1+2+…n)/n=O(n)。
如果数组中的数据是有序的,我们在某个位置插入一个新的元素时,就必须按照刚才的方法搬移k之后的数据。但是,如果数组中存储的数据并没有任何规律,数组只是被当作一个存储数据的集合。在这种情况下,如果要将某个数据插入到第k个位置,为了避免大规模的数据搬移,我们还有一个简单的办法就是,直接将第k位的数据搬移到数组元素的最后,把新的元素直接放入第k个位置。
为了更好地理解,我们举一个例子。假设数组a[10]中存储了如下5个元素:a,b,c,d,e。
我们现在需要将元素x插入到第3个位置。我们只需要将c放入到a[5],将a[2]赋值为x即可。最后,数组中的元素如下: a,b,x,d,e,c。

利用这种处理技巧,在特定场景下,在第k个位置插入一个元素的时间复杂度就会降为O(1)。这个处理思想在快排中也会用到,我会在排序那一节具体来讲,这里就说到这儿。
我们再来看 删除操作。
跟插入数据类似,如果我们要删除第k个位置的数据,为了内存的连续性,也需要搬移数据,不然中间就会出现空洞,内存就不连续了。
和插入类似,如果删除数组末尾的数据,则最好情况时间复杂度为O(1);如果删除开头的数据,则最坏情况时间复杂度为O(n);平均情况时间复杂度也为O(n)。
实际上,在某些特殊场景下,我们并不一定非得追求数组中数据的连续性。如果我们将多次删除操作集中在一起执行,删除的效率是不是会提高很多呢?
我们继续来看例子。数组a[10]中存储了8个元素:a,b,c,d,e,f,g,h。现在,我们要依次删除a,b,c三个元素。

为了避免d,e,f,g,h这几个数据会被搬移三次,我们可以先记录下已经删除的数据。每次的删除操作并不是真正地搬移数据,只是记录数据已经被删除。当数组没有更多空间存储数据时,我们再触发执行一次真正的删除操作,这样就大大减少了删除操作导致的数据搬移。
给你一个数组 nums 和一个值 val,你需要 原地 移除所有数值等于 val 的元素,并返回移除后数组的新长度。
不要使用额外的数组空间,你必须仅使用 O(1) 额外空间并 原地 修改输入数组。
元素的顺序可以改变。你不需要考虑数组中超出新长度后面的元素。
示例 1:
输入:nums = [3,2,2,3], val = 3
输出:2, nums = [2,2]
解释:函数应该返回新的长度 2, 并且 nums 中的前两个元素均为 2。你不需要考虑数组中超出新长度后面的元素。例如,函数返回的新长度为 2 ,而 nums = [2,2,3,3] 或 nums = [2,2,0,0],也会被视作正确答案。
这个题目暴力的解法就是两层for循环,一个for循环遍历数组元素 ,第二个for循环更新数组。
很明显暴力解法的时间复杂度是O(n^2),这道题目暴力解法在leetcode上是可以过的。
代码如下:
class Solution {
public:
int removeElement(vector<int>& nums, int val) {
int size = nums.size();
for (int i = 0; i < size; i++) {
if (nums[i] == val) { // 发现需要移除的元素,就将数组集体向前移动一位
for (int j = i + 1; j < size; j++) {
nums[j - 1] = nums[j];
}
i--; // 因为下标i以后的数值都向前移动了一位,所以i也向前移动一位
size--; // 此时数组的大小-1
}
}
return size;
}
};
思路及算法
由于题目要求删除数组中等于val的元素,因此输出数组的长度一定小于等于输入数组的长度,我们可以把输出的数组直接写在输入数组上。可以使用双指针:右指针right指向当前将要处理的元素,左指针left指向下一个将要赋值的位置。
·如果右指针指向的元素不等于val,它一定是输出数组的一个元素,我们就将右指针指向的元素复制到左指针位置,然后将左右指针同时右移;
·如果右指针指向的元素等于val,它不能在输出数组里,此时左指针不动,右指针右移一位。
整个过程保持不变的性质是:区间[0, left)中的元素都不等于value。当左右指针遍历完输入数组以后,left的值就是输出数组的长度。
这样的算法在最坏情况下(输入数组中没有元素等于value),左右指针各遍历了数组一次。
class Solution {
public int removeElement(int[] nums, int val) {
// 快慢指针
int slowIndex = 0;
for (int fastIndex = 0; fastIndex < nums.length; fastIndex++) {
if (nums[fastIndex] != val) {
nums[slowIndex] = nums[fastIndex];
slowIndex++;
}
}
return slowIndex;
}
}

给你一个按 非递减顺序 排序的整数数组 nums,返回 每个数字的平方 组成的新数组,要求也按 非递减顺序 排序。
示例 1:
输入:nums = [-4,-1,0,3,10] 输出:[0,1,9,16,100] 解释:平方后,数组变为 [16,1,0,9,100],排序后,数组变为 [0,1,9,16,100]
示例 2:
输入:nums = [-7,-3,2,3,11] 输出:[4,9,9,49,121]

最直观的想法,莫过于:每个数平方之后,排个序,美滋滋,代码如下:
class Solution {
public:
vector<int> sortedSquares(vector<int>& A) {
for (int i = 0; i < A.size(); i++) {
A[i] *= A[i];
}
sort(A.begin(), A.end()); // 快速排序
return A;
}
};
这个时间复杂度是 O(n + nlogn), 可以说是O(nlogn)的时间复杂度,但为了和下面双指针法算法时间复杂度有鲜明对比,我记为 O(n + nlog n)。
数组其实是有序的, 只不过负数平方之后可能成为最大数了。
那么数组平方的最大值就在数组的两端,不是最左边就是最右边,不可能是中间。
此时可以考虑双指针法了,i指向起始位置,j指向终止位置。
定义一个新数组result,和A数组一样的大小,让k指向result数组终止位置。
class Solution {
public int[] sortedSquares(int[] nums) {
int right = nums.length - 1;
int left = 0;
int[] result = new int[nums.length];
int index = result.length - 1;
while (left <= right) {
if (nums[left] * nums[left] > nums[right] * nums[right]) {
// 正数的相对位置是不变的, 需要调整的是负数平方后的相对位置
result[index--] = nums[left] * nums[left];
++left;
} else {
result[index--] = nums[right] * nums[right];
--right;
}
}
return result;
}
}
感谢大家的阅读,文章通过网络资源与自己的学习过程整理出来,希望能帮助到大家。
才疏学浅,难免会有纰漏,如果你发现了错误的地方,可以提出来,我会对其加以修改。

我有多个ActiveRecord子类Item的实例数组,我需要根据最早的事件循环打印。在这种情况下,我需要打印付款和维护日期,如下所示:ItemAmaintenancerequiredin5daysItemBpaymentrequiredin6daysItemApaymentrequiredin7daysItemBmaintenancerequiredin8days我目前有两个查询,用于查找maintenance和payment项目(非排他性查询),并输出如下内容:paymentrequiredin...maintenancerequiredin...有什么方法可以改善上述(丑陋的)代
我的代码目前看起来像这样numbers=[1,2,3,4,5]defpop_threepop=[]3.times{pop有没有办法在一行中完成pop_three方法中的内容?我基本上想做类似numbers.slice(0,3)的事情,但要删除切片中的数组项。嗯...嗯,我想我刚刚意识到我可以试试slice! 最佳答案 是numbers.pop(3)或者numbers.shift(3)如果你想要另一边。 关于ruby-多次弹出/移动ruby数组,我们在StackOverflow上找到一
我需要读入一个包含数字列表的文件。此代码读取文件并将其放入二维数组中。现在我需要获取数组中所有数字的平均值,但我需要将数组的内容更改为int。有什么想法可以将to_i方法放在哪里吗?ClassTerraindefinitializefile_name@input=IO.readlines(file_name)#readinfile@size=@input[0].to_i@land=[@size]x=1whilex 最佳答案 只需将数组映射为整数:@land边注如果你想得到一条线的平均值,你可以这样做:values=@input[x]
我正在使用puppet为ruby程序提供一组常量。我需要提供一组主机名,我的程序将对其进行迭代。在我之前使用的bash脚本中,我只是将它作为一个puppet变量hosts=>"host1,host2"我将其提供给bash脚本作为HOSTS=显然这对ruby不太适用——我需要它的格式hosts=["host1","host2"]自从phosts和putsmy_array.inspect提供输出["host1","host2"]我希望使用其中之一。不幸的是,我终其一生都无法弄清楚如何让它发挥作用。我尝试了以下各项:我发现某处他们指出我需要在函数调用前放置“function_”……这
这个问题在这里已经有了答案:Checktoseeifanarrayisalreadysorted?(8个答案)关闭9年前。我只是想知道是否有办法检查数组是否在增加?这是我的解决方案,但我正在寻找更漂亮的方法:n=-1@arr.flatten.each{|e|returnfalseife
我有一个这样的哈希数组:[{:foo=>2,:date=>Sat,01Sep2014},{:foo2=>2,:date=>Sat,02Sep2014},{:foo3=>3,:date=>Sat,01Sep2014},{:foo4=>4,:date=>Sat,03Sep2014},{:foo5=>5,:date=>Sat,02Sep2014}]如果:date相同,我想合并哈希值。我对上面数组的期望是:[{:foo=>2,:foo3=>3,:date=>Sat,01Sep2014},{:foo2=>2,:foo5=>5:date=>Sat,02Sep2014},{:foo4=>4,:dat
我正在尝试在Ruby中制作一个cli应用程序,它接受一个给定的数组,然后将其显示为一个列表,我可以使用箭头键浏览它。我觉得我已经在Ruby中看到一个库已经这样做了,但我记不起它的名字了。我正在尝试对soundcloud2000中的代码进行逆向工程做类似的事情,但他的代码与SoundcloudAPI的使用紧密耦合。我知道cursesgem,我正在考虑更抽象的东西。广告有没有人见过可以做到这一点的库或一些概念证明的Ruby代码可以做到这一点? 最佳答案 我不知道这是否是您正在寻找的,但也许您可以使用我的想法。由于我没有关于您要完成的工作
我使用Ember作为我的前端和GrapeAPI来为我的API提供服务。前端发送类似:{"service"=>{"name"=>"Name","duration"=>"30","user"=>nil,"organization"=>"org","category"=>nil,"description"=>"description","disabled"=>true,"color"=>nil,"availabilities"=>[{"day"=>"Saturday","enabled"=>false,"timeSlots"=>[{"startAt"=>"09:00AM","endAt"=>
我正在尝试按0-9和a-z的顺序创建数字和字母列表。我有一组值value_array=['0','1','2','3','4','5','6','7','8','9','a','b','光盘','e','f','g','h','i','j','k','l','m','n','o','p','q','r','s','','u','v','w','x','y','z']和一个组合列表的数组,按顺序,这些数字可以产生x个字符,比方说三个list_array=[]和一个当前字母和数字组合的数组(在将它插入列表数组之前我会把它变成一个字符串,]current_combo['0','0','0']
查看我的Ruby代码:h=Hash.new([])h[0]=:word1h[1]=h[1]输出是:Hash={0=>:word1,1=>[:word2,:word3],2=>[:word2,:word3]}我希望有Hash={0=>:word1,1=>[:word2],2=>[:word3]}为什么要附加第二个哈希元素(数组)?如何将新数组元素附加到第三个哈希元素? 最佳答案 如果您提供单个值作为Hash.new的参数(例如Hash.new([]),完全相同的对象将用作每个缺失键的默认值。这就是您所拥有的,那是你不想要的。您可以改用