作者:变速风声
链接:https://juejin.cn/post/7104090532015505416
在开发中遇到一个业务诉求,需要在千万量级的底池数据中筛选出不超过 10W 的数据,并根据配置的权重规则进行排序、打散(如同一个类目下的商品数据不能连续出现 3 次)。
下面对该业务诉求的实现,设计思路和方案优化进行介绍,对「千万量级数据中查询 10W 量级的数据」设计了如下方案
scroll scan 深翻页方案整体方案设计为:
技术方案如下:
Hive 表)导入到 Clickhouse 中,后续使用 CK 表进行数据筛选。SelectionQueryCondition。result 列表中。//分页大小 默认 5000
int pageSize = this.getPageSize();
//页码数
int pageCnt = totalNum / this.getPageSize() + 1;
List<Map<String, Object>> result = Lists.newArrayList();
List<Future<List<Map<String, Object>>>> futureList = new ArrayList<>(pageCnt);
//开启多线程调用
for (int i = 1; i <= pageCnt; i++) {
//将业务配置的筛选规则和排序规则 构建为 SelectionQueryCondition 对象
SelectionQueryCondition selectionQueryCondition = buildSelectionQueryCondition(selectionQueryRuleData);
selectionQueryCondition.setPageSize(pageSize);
selectionQueryCondition.setPage(i);
futureList.add(selectionQueryEventPool.submit(new QuerySelectionDataThread(selectionQueryCondition)));
}
for (Future<List<Map<String, Object>>> future : futureList) {
//RPC 调用
List<Map<String, Object>> queryRes = future.get(20, TimeUnit.SECONDS);
if (CollectionUtils.isNotEmpty(queryRes)) {
// 将目标数据存放在 result 中
result.addAll(queryRes);
}
}
对目标数据 result 进行排序,得到最终的「结果数据」。
推荐一个开源免费的 Spring Boot 最全教程:
在「初版设计方案」章节的第 3 步提到了「从 CK 底池表取目标数据时,开启多线程,进行分页筛选」。此处对 CK 分页查询进行介绍。
封装了 queryPoolSkuList 方法,负责从 CK 表中获得目标数据。该方法内部调用了 sqlSession.selectList 方法。
public List<Map<String, Object>> queryPoolSkuList( Map<String, Object> params ) {
List<Map<String, Object>> resultMaps = new ArrayList<>();
QueryCondition queryCondition = parseQueryCondition(params);
List<Map<String, Object>> mapList = lianNuDao.queryPoolSkuList(getCkDt(),queryCondition);
if (CollectionUtils.isNotEmpty(mapList)) {
for (Map<String,Object> data : mapList) {
resultMaps.add(camelKey(data));
}
}
return resultMaps;
}
// lianNuDao.queryPoolSkuList
@Autowired
@Qualifier("ckSqlNewSession")
private SqlSession sqlSession;
public List<Map<String, Object>> queryPoolSkuList( String dt, QueryCondition queryCondition ) {
queryCondition.setDt(dt);
queryCondition.checkMultiQueryItems();
return sqlSession.selectList("LianNu.queryPoolSkuList",queryCondition);
}
sqlSession.selectList 方法中调用了和 CK 交互的 queryPoolSkuList 查询方法,部分代码如下。
<select id="queryPoolSkuList" parameterType="com.jd.bigai.domain.liannu.QueryCondition" resultType="java.util.Map">
select sku_pool_id,i
tem_sku_id,
skuPoolName,
price,
...
...
businessType
from liannu_sku_pool_indicator_all
where
dt=#{dt}
and
<foreach collection="queryItems" separator=" and " item="queryItem" open=" " close=" " >
<choose>
<when test="queryItem.type == 'equal'">
${queryItem.field} = #{queryItem.value}
</when>
...
...
</choose>
</foreach>
<if test="orderBy == null">
group by sku_pool_id,item_sku_id
</if>
<if test="orderBy != null">
group by sku_pool_id,item_sku_id,${orderBy} order by ${orderBy} ${orderAd}
</if>
<if test="limitEnd != 0">
limit #{limitStart},#{limitEnd}
</if>
</select>
可以看到,在 CK 分页查询时,是通过 limit #{limitStart},#{limitEnd} 实现的分页。
limit 分页方案,在「深翻页」时会存在性能问题。初版方案上线后,在 1000W 量级的底池数据中筛选 10W 的数据,最坏耗时会达到 10s~18s 左右。
对于 CK 深翻页时候的性能问题,进行了优化,使用 Elasticsearch 的 scroll scan 翻页方案进行优化。
ES 翻页,有下面几种方案
from + size 翻页scroll 翻页scroll scan 翻页search after 翻页| 翻页方式 | 性能 | 优点 | 缺点 | 场景 |
|---|---|---|---|---|
from + size |
低 | 灵活性好,实现简单 | 深度分页问题 | 数据量比较小,能容忍深度分页问题 |
scroll |
中 | 解决了深度分页问题 | 需要维护一个 scrollId(快照版本),无法反应数据的实时性;可排序,但无法跳页查询 |
查询海量数据 |
scroll scan |
中 | 基于 scroll 方案,进一步提升了海量数据查询的性能 |
无法排序,其余缺点同 scroll |
查询海量数据 |
search after |
高 | 性能最好,不存在深度分页问题,能够反映数据的实时变更 | 实现复杂,需要有一个全局唯一的字段。连续分页的实现会比较复杂,因为每一次查询都需要上次查询的结果 | 不适用于大幅度跳页查询,适用于海量数据的分页 |
对上述几种翻页方案,查询不同数目的数据,耗时数据如下表。
| ES 翻页方式 | 1-10 | 49000-49010 | 99000-99010 |
|---|---|---|---|
| from + size | 8ms | 30ms | 117ms |
| scroll | 7ms | 66ms | 36ms |
| search_after | 5ms | 8ms | 7ms |
此处,分别使用 Elasticsearch 的 scroll scan 翻页方案、初版中的 CK 翻页方案进行数据查询,对比其耗时数据。
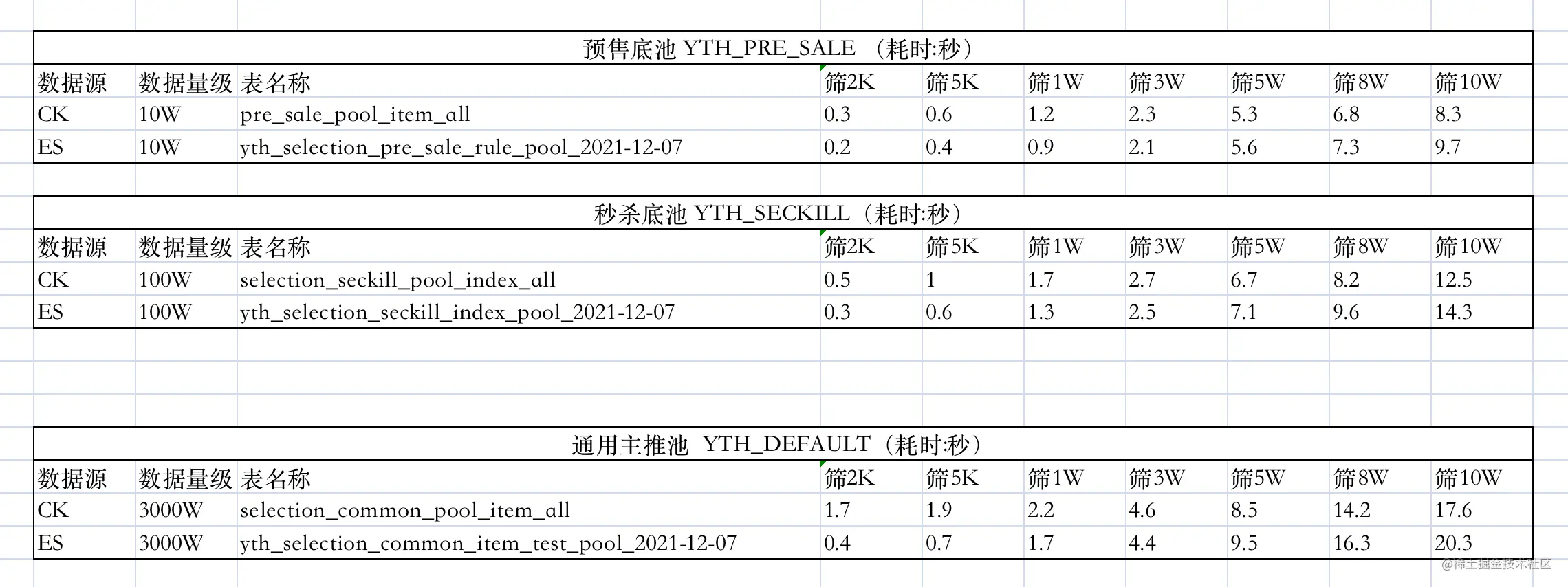
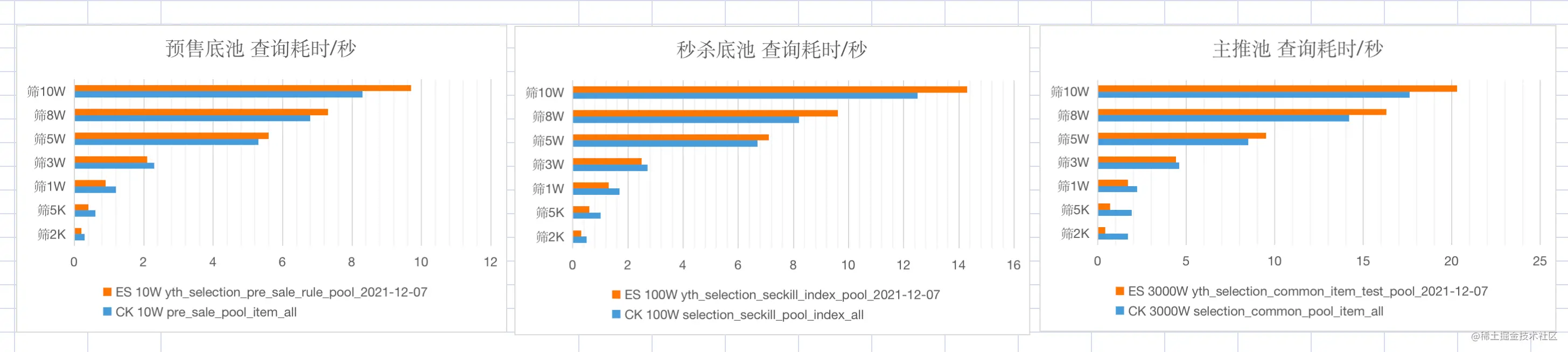
如上测试数据,可以发现,以十万,百万,千万量级的底池为例
在「使用 ES Scroll Scan 优化深翻页」中,使用 Elasticsearch 的 scroll scan 翻页方案对深翻页问题进行了优化,但在实现时为单线程调用,所以最终测试耗时数据并不是特别理想,和 CK 翻页方案性能差不多。
在调研阶段发现,从底池中取出 10W 的目标数据时,一个商品包含多个字段的信息(CK 表中一行记录有 150 个字段信息),如价格、会员价、学生价、库存、好评率等。对于一行记录,当减少获取字段的个数时,查询耗时会有明显下降。如对 sku1的商品,从之前获取价格、会员价、学生价、亲友价、库存等 100 个字段信息,缩减到只获取价格、库存这两个字段信息。
如下图所示,使用 ES 查询方案,对查询同样条数的场景(从千万级底池中筛选出 7W+ 条数据),获取的每条记录的字段个数从 32 缩减到 17,再缩减到 1个(其实是两个字段,一个是商品唯一标识 sku_id,另一个是 ES 对每条文档记录的 doc_id)时,查询的耗时会从 9.3s 下降到 4.2s,再下降到 2.4s。
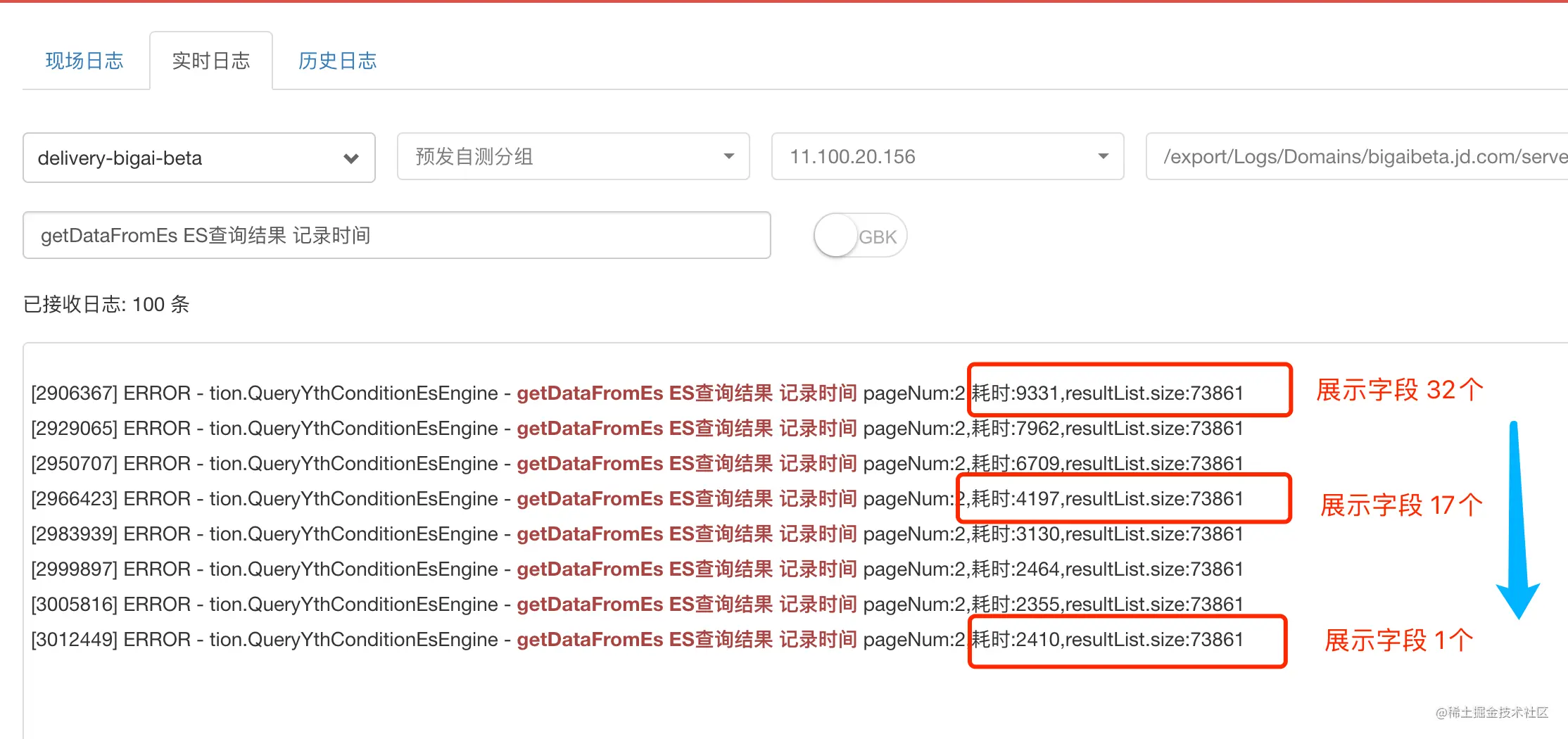
从中可以得出如下结论
fetch 阶段的耗时,远大于 query 阶段的耗时。下面对结论中涉及的 query 和 fetch 查询阶段进行补充说明。
在 ES 中,搜索一般包括两个阶段,query 和 fetch 阶段
query 阶段
doc),筛选出文档 ID(doc_id)fetch 阶段
query 阶段返回的文档 ID(doc_id),取出具体的文档(doc)filesystem cache,在内存中查找,提升了速度filesystem cache 无法容纳索引数据文件,则会基于磁盘查找,此时查询速度会明显变慢filesystem cache,保证查询速度在上文调研的基础上,发现「减少不必要的查询展示字段」可以明显缩短查询耗时。沿着这个优化思路,参照参考链接 ref-1,设计了一种新的查询方案
sku_id(其实还包含 ES 为每条文档记录的 doc_id)rowKey。利用 rowKey 筛选一条记录时,复杂度为 O(1)。(类似于从 HashMap 中根据 key 取 value)sku_id,作为 Hbase 查询中的 rowKey,在 O(1) 复杂度下获取其他信息字段,如价格,库存等。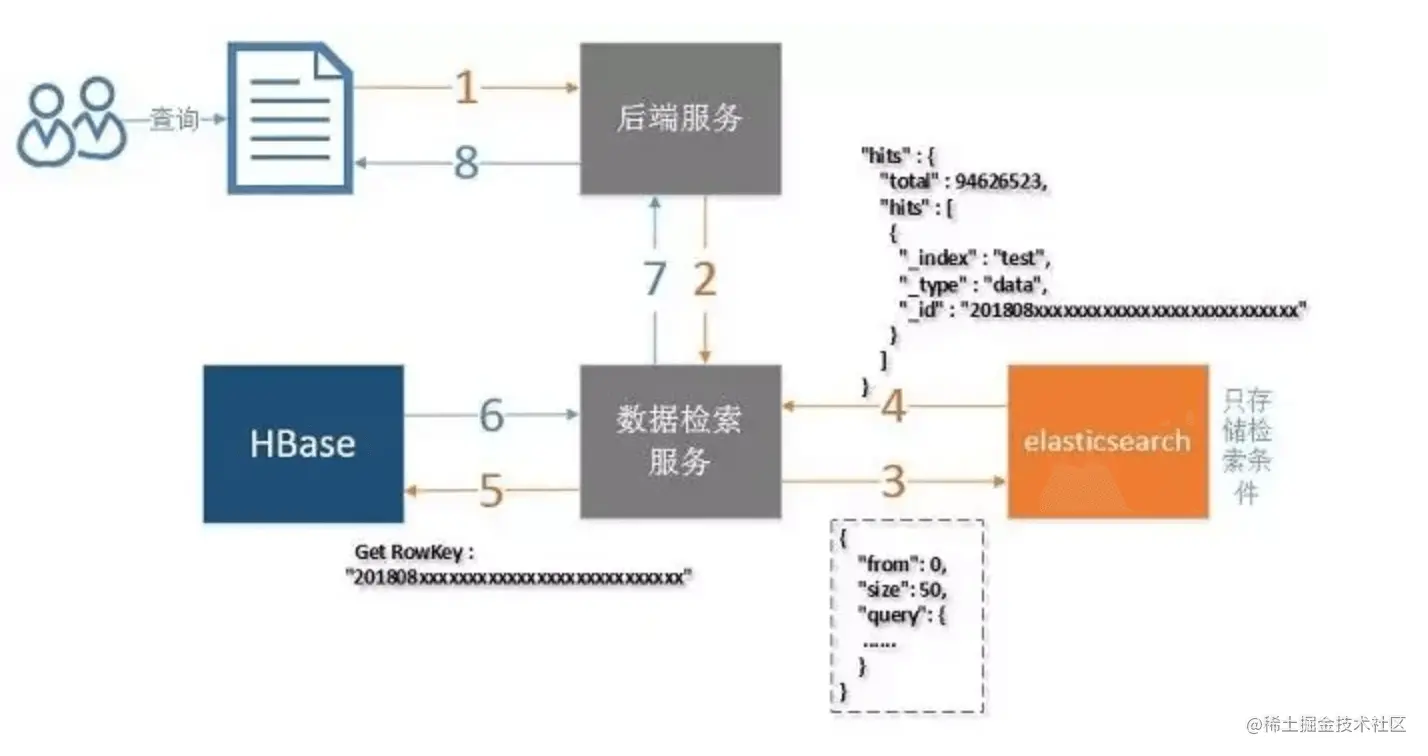
使用 ES + Hbase 组合查询方案,在线上进行了小规模的灰度测试。在 1000W 量级的底池数据中筛选 10W 的数据,对比 CK 翻页方案,最坏耗时从 10~18s 优化到了 3~6s 左右。
也应该看到,使用 ES + Hbase 组合查询方案,会增加系统复杂度,同时数据也需要同时存储到 ES 和 Hbase。
RediSearch 是基于 Redis 构建的分布式全文搜索和聚合引擎,能以极快的速度在 Redis 数据集上执行复杂的搜索查询。RedisJSON 是一个 Redis 模块,在 Redis 中提供 JSON 支持。RedisJSON 可以和 RediSearch 无缝配合,实现索引和查询 JSON 文档。
根据一些参考资料,RediSearch + RedisJSON 可以实现极高的性能,可谓碾压其他 NoSQL 方案。在后续版本迭代中,可考虑使用该方案来进一步优化。
下面给出 RediSearch + RedisJSON 的部分性能数据。
在同等服务器配置下索引了 560 万个文档 (5.3GB),RediSearch 构建索引的时间为 221 秒,而 Elasticsearch 为 349 秒。RediSearch 比 ES 快了 58%。
数据建立索引后,使用 32 个客户端对两个单词进行检索,RediSearch 的吞吐量达到 12.5K ops/sec,ES 的吞吐量为 3.1K ops/sec,RediSearch 比ES 要快 4 倍。同时,RediSearch 的延迟为 8ms,而 ES 为 10ms,RediSearch 延迟稍微低些。
| 对比 | Redisearch | Elasticsearch |
|---|---|---|
| 搜索引擎 | 专用引擎 | 基于 Lucene 引擎 |
| 编程语言 | C 语言 | Java |
| 存储方案 | 内存 | 磁盘 |
| 协议 | Redis 序列化协议 | HTTP |
| 集群 | 企业版支持 | 支持 |
| 性能 | 简单查询高于 ES | 复杂查询时高于 RediSearch |
根据官网的性能测试报告,RedisJson + RedisSearch 可谓碾压其他 NoSQL
在混合工作负载场景中,实时更新不会影响 RedisJSON 的搜索和读取性能,而 ES 会受到影响。
此外,RedisJSON 的读取、写入和负载搜索延迟,在更高的百分位数中远比 ES 和 MongoDB 稳定。当增加写入比率时,RedisJSON 还能处理越来越高的整体吞吐量。而当写入比率增加时,ES 会降低它可以处理的整体吞吐量。
本文从一个业务诉求触发,对「千万量级数据中查询 10W 量级的数据」介绍了不同的设计方案。对于「在 1000W 量级的底池数据中筛选 10W 的数据」的场景,不同方案的耗时如下
scroll scan 深翻页方案,相比 CK 方案,并未见到明显优化参考资料:
近期热文推荐:
1.1,000+ 道 Java面试题及答案整理(2022最新版)
4.别再写满屏的爆爆爆炸类了,试试装饰器模式,这才是优雅的方式!!
觉得不错,别忘了随手点赞+转发哦!
类classAprivatedeffooputs:fooendpublicdefbarputs:barendprivatedefzimputs:zimendprotecteddefdibputs:dibendendA的实例a=A.new测试a.foorescueputs:faila.barrescueputs:faila.zimrescueputs:faila.dibrescueputs:faila.gazrescueputs:fail测试输出failbarfailfailfail.发送测试[:foo,:bar,:zim,:dib,:gaz].each{|m|a.send(m)resc
出于纯粹的兴趣,我很好奇如何按顺序创建PI,而不是在过程结果之后生成数字,而是让数字在过程本身生成时显示。如果是这种情况,那么数字可以自行产生,我可以对以前看到的数字实现垃圾收集,从而创建一个无限系列。结果只是在Pi系列之后每秒生成一个数字。这是我通过互联网筛选的结果:这是流行的计算机友好算法,类机器算法:defarccot(x,unity)xpow=unity/xn=1sign=1sum=0loopdoterm=xpow/nbreakifterm==0sum+=sign*(xpow/n)xpow/=x*xn+=2sign=-signendsumenddefcalc_pi(digits
我有一个模型:classItem项目有一个属性“商店”基于存储的值,我希望Item对象对特定方法具有不同的行为。Rails中是否有针对此的通用设计模式?如果方法中没有大的if-else语句,这是如何干净利落地完成的? 最佳答案 通常通过Single-TableInheritance. 关于ruby-on-rails-Rails-子类化模型的设计模式是什么?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.co
我正在用Ruby编写一个简单的程序来检查域列表是否被占用。基本上它循环遍历列表,并使用以下函数进行检查。require'rubygems'require'whois'defcheck_domain(domain)c=Whois::Client.newc.query("google.com").available?end程序不断出错(即使我在google.com中进行硬编码),并打印以下消息。鉴于该程序非常简单,我已经没有什么想法了-有什么建议吗?/Library/Ruby/Gems/1.8/gems/whois-2.0.2/lib/whois/server/adapters/base.
如何在buildr项目中使用Ruby?我在很多不同的项目中使用过Ruby、JRuby、Java和Clojure。我目前正在使用我的标准Ruby开发一个模拟应用程序,我想尝试使用Clojure后端(我确实喜欢功能代码)以及JRubygui和测试套件。我还可以看到在未来的不同项目中使用Scala作为后端。我想我要为我的项目尝试一下buildr(http://buildr.apache.org/),但我注意到buildr似乎没有设置为在项目中使用JRuby代码本身!这看起来有点傻,因为该工具旨在统一通用的JVM语言并且是在ruby中构建的。除了将输出的jar包含在一个独特的、仅限ruby
我正在使用的第三方API的文档状态:"[O]urAPIonlyacceptspaddedBase64encodedstrings."什么是“填充的Base64编码字符串”以及如何在Ruby中生成它们。下面的代码是我第一次尝试创建转换为Base64的JSON格式数据。xa=Base64.encode64(a.to_json) 最佳答案 他们说的padding其实就是Base64本身的一部分。它是末尾的“=”和“==”。Base64将3个字节的数据包编码为4个编码字符。所以如果你的输入数据有长度n和n%3=1=>"=="末尾用于填充n%
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
为什么4.1%2返回0.0999999999999996?但是4.2%2==0.2。 最佳答案 参见此处:WhatEveryProgrammerShouldKnowAboutFloating-PointArithmetic实数是无限的。计算机使用的位数有限(今天是32位、64位)。因此计算机进行的浮点运算不能代表所有的实数。0.1是这些数字之一。请注意,这不是与Ruby相关的问题,而是与所有编程语言相关的问题,因为它来自计算机表示实数的方式。 关于ruby-为什么4.1%2使用Ruby返
exe应该在我打开页面时运行。异步进程需要运行。有什么方法可以在ruby中使用两个参数异步运行exe吗?我已经尝试过ruby命令-system()、exec()但它正在等待过程完成。我需要用参数启动exe,无需等待进程完成是否有任何rubygems会支持我的问题? 最佳答案 您可以使用Process.spawn和Process.wait2:pid=Process.spawn'your.exe','--option'#Later...pid,status=Process.wait2pid您的程序将作为解释器的子进程执行。除
鉴于我有以下迁移:Sequel.migrationdoupdoalter_table:usersdoadd_column:is_admin,:default=>falseend#SequelrunsaDESCRIBEtablestatement,whenthemodelisloaded.#Atthispoint,itdoesnotknowthatusershaveais_adminflag.#Soitfails.@user=User.find(:email=>"admin@fancy-startup.example")@user.is_admin=true@user.save!ende