一、引言
二叉树在应用时,经常需要知道二叉树的深度。二叉树的深度就是二叉树的层数,即从树根算起,到最底下一层的层数是多少,即二叉树中结点的最大层次值。
本文给出了计算二叉树深度的算法,包括递归算法和非递归算法。
二、计算二叉树的基本方法
如下图所示的二叉树,其深度是4。
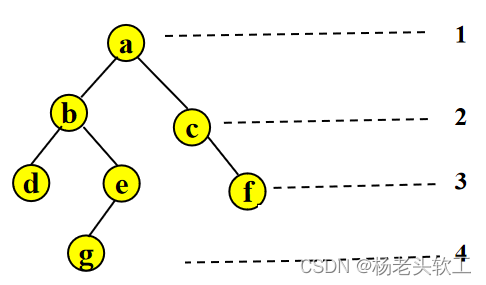
说到层数,大家自然会想到二叉树的层次遍历法。没错,其实我们只要一层一层的来遍历二叉树,当遍历到每一层的最右侧结点时,一层就遍历结束,因此可以考虑把每一层的最右侧结点作为每一层的标志,每当访问到该结类点时,二叉树的层数就可以增加1。
现在就会遇到一个问题:如何识别每一层最右侧的结点呢?
这时得回忆一下层次遍历算法,使用了队列来缓存二叉树上全部的结点,当初并没有识别每一层的最右侧结点。但是我们在层次遍历的过程中会发现,队列的队首总会走到每一层最右侧的结点位置,因此可以考虑通过判断队首的位置来识别最右侧结点,进而就可以得到层数。而且大家还会发现一个结论,那就是每一层最右侧的结点的左或者右子树也可能是下一层的最右侧结点(层尾结点)。当发现了这个结论,那么计算二叉树的深度就变得轻而易举了。
下面以上图为例演示一下按照层次遍历时,来识别二叉树深度的过程。
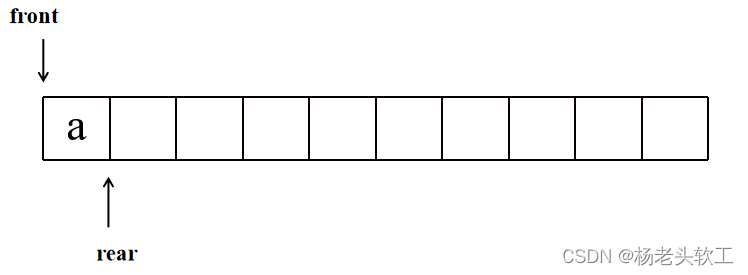
Step 1:树根a进队列,队列状态如下图所示:
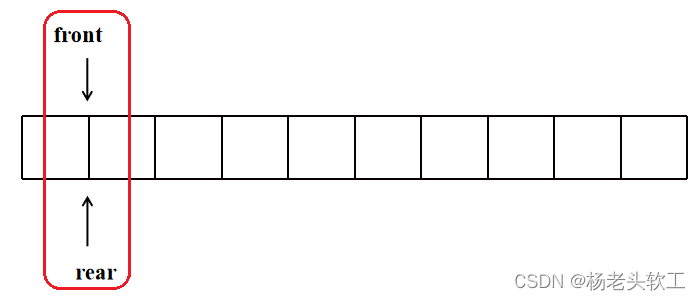
 Step 2:队首出队列,队列状态如下图所示:
Step 2:队首出队列,队列状态如下图所示:
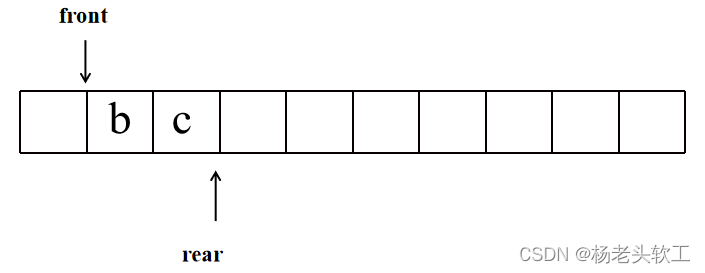
此时队首和队尾指向了同一个位置,也就是第一层遍历结束了,之后访问出队列的元素,并判断其左右子树是否为空,不空则继续入队列,所以就得到如下图所示的队列:
Step 3:结点a的左、右结点入队列
此时,其实我们又发现了:rear指向了队尾的前一个位置,就是一层结束的位置,如果在此处设个标志,是否可行?我们接着往下看。
Step 4:队首继续出队列、访问,访问之后,其左右子树非空的话,则继续入队列。
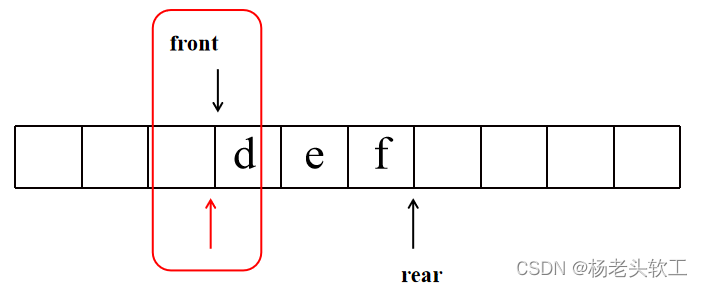 当连续两次队首出队列之后,队列状态如上图所示,这是就会发现front的位置和新增加的标志位置相同了,这是其实又是一层的结束位置。
当连续两次队首出队列之后,队列状态如上图所示,这是就会发现front的位置和新增加的标志位置相同了,这是其实又是一层的结束位置。
到这里,是不是就可以发现,引入这个标志的用处了?
因为当前层最后一个结点,它的左子树或者右子树也基本上就是下一层的最后一个结点,当然了如果当前层的最右侧结点的左右子树同时为空,则也可能是再左侧一些的结点是下一层的队尾(如图中所示的结点g就不是上一层尾结点的子树)。因此,我们在设定了当前层最右侧标志之后,则该最右侧结点的左或右子树入队列后的队尾,是不是就可能是新的标志位了?对头,就是这样的。
所以当某个结点的左右子树入队列的时候,队尾就可能是一层的结束位置。这也就是为什么在算法中是执行了某个结点的左右子树都入队列之后才判断是否是一层的结束了。(说的好像有点啰嗦了,原谅我)
进而只需要判断队首front的值和新增加的标志(不妨记为levelLoc)的值是否相同即可,相同则表示一层结束,总层数就可以加1了,同时把levelLoc的值更新为队列当前的队尾这是因为此时队尾可能就是上一层队尾的子树。
后面的步骤就不用再赘述了,直接上代码。
三、计算二叉树深度的源代码:
1、结点结构
typedef struct node
{
char data;
struct node *Lchild;
struct node *Rchild;
}BiTree;
2、递归算法
int BiTreeDepth( BiTree *T )
{
int dep1 = 0, dep2 = 0;
if ( T == NULL )
return 0;
else
{
dep1 = BiTreeDepth( T->Lchild );
dep2 = BiTreeDepth( T->Rchild );
if ( dep1 > dep2 )
return dep1 + 1;
else
return dep2 + 1;
}
}
3、非递归算法
int Search_Depth( BiTree *T)
{
BiTree *Queue[MAX_NODE]
BiTree *p = T;
int front=0 , rear=0, depth=0, levelLoc;
// level总是指向访问层的最后一个结点在队列的位置
if( T != NULL )
Queue[++rear] = p; //根结点入队
levelLoc = rear; //根是第1层的最后一个节点
while ( front < rear )
{
p = Queue[ ++front ];
if ( p->Lchild != NULL ) Queue[ ++rear ] = p->Lchild; //左结点入队
if ( p->Rchild != NULL ) Queue[ ++rear ] = p->Rchild; //右结点入队
if ( front == levelLoc ) //访问到当前层的最后一个结点
{
depth++;
levelLoc = rear;
}
}
return depth;
}
这里是Ruby新手。完成一些练习后碰壁了。练习:计算一系列成绩的字母等级创建一个方法get_grade来接受测试分数数组。数组中的每个分数应介于0和100之间,其中100是最大分数。计算平均分并将字母等级作为字符串返回,即“A”、“B”、“C”、“D”、“E”或“F”。我一直返回错误:avg.rb:1:syntaxerror,unexpectedtLBRACK,expecting')'defget_grade([100,90,80])^avg.rb:1:syntaxerror,unexpected')',expecting$end这是我目前所拥有的。我想坚持使用下面的方法或.join,
目录一.加解密算法数字签名对称加密DES(DataEncryptionStandard)3DES(TripleDES)AES(AdvancedEncryptionStandard)RSA加密法DSA(DigitalSignatureAlgorithm)ECC(EllipticCurvesCryptography)非对称加密签名与加密过程非对称加密的应用对称加密与非对称加密的结合二.数字证书图解一.加解密算法加密简单而言就是通过一种算法将明文信息转换成密文信息,信息的的接收方能够通过密钥对密文信息进行解密获得明文信息的过程。根据加解密的密钥是否相同,算法可以分为对称加密、非对称加密、对称加密和非
目录前言滤波电路科普主要分类实际情况单位的概念常用评价参数函数型滤波器简单分析滤波电路构成低通滤波器RC低通滤波器RL低通滤波器高通滤波器RC高通滤波器RL高通滤波器部分摘自《LC滤波器设计与制作》,侵权删。前言最近需要学习放大电路和滤波电路,但是由于只在之前做音乐频谱分析仪的时候简单了解过一点点运放,所以也是相当从零开始学习了。滤波电路科普主要分类滤波器:主要是从不同频率的成分中提取出特定频率的信号。有源滤波器:由RC元件与运算放大器组成的滤波器。可滤除某一次或多次谐波,最普通易于采用的无源滤波器结构是将电感与电容串联,可对主要次谐波(3、5、7)构成低阻抗旁路。无源滤波器:无源滤波器,又称
深度学习部署:Windows安装pycocotools报错解决方法1.pycocotools库的简介2.pycocotools安装的坑3.解决办法更多Ai资讯:公主号AiCharm本系列是作者在跑一些深度学习实例时,遇到的各种各样的问题及解决办法,希望能够帮助到大家。ERROR:Commanderroredoutwithexitstatus1:'D:\Anaconda3\python.exe'-u-c'importsys,setuptools,tokenize;sys.argv[0]='"'"'C:\\Users\\46653\\AppData\\Local\\Temp\\pip-instal
项目介绍随着我国经济迅速发展,人们对手机的需求越来越大,各种手机软件也都在被广泛应用,但是对于手机进行数据信息管理,对于手机的各种软件也是备受用户的喜爱小学生兴趣延时班预约小程序的设计与开发被用户普遍使用,为方便用户能够可以随时进行小学生兴趣延时班预约小程序的设计与开发的数据信息管理,特开发了小程序的设计与开发的管理系统。小学生兴趣延时班预约小程序的设计与开发的开发利用现有的成熟技术参考,以源代码为模板,分析功能调整与小学生兴趣延时班预约小程序的设计与开发的实际需求相结合,讨论了小学生兴趣延时班预约小程序的设计与开发的使用。开发环境开发说明:前端使用微信微信小程序开发工具:后端使用ssm:VU
@作者:SYFStrive @博客首页:HomePage📜:微信小程序📌:个人社区(欢迎大佬们加入)👉:社区链接🔗📌:觉得文章不错可以点点关注👉:专栏连接🔗💃:感谢支持,学累了可以先看小段由小胖给大家带来的街舞👉微信小程序(🔥)目录自定义组件-behaviors 1、什么是behaviors 2、behaviors的工作方式 3、创建behavior 4、导入并使用behavior 5、behavior中所有可用的节点 6、同名字段的覆盖和组合规则总结最后自定义组件-behaviors 1、什么是behaviorsbehaviors是小程序中,用于实现
遍历文件夹我们通常是使用递归进行操作,这种方式比较简单,也比较容易理解。本文为大家介绍另一种不使用递归的方式,由于没有使用递归,只用到了循环和集合,所以效率更高一些!一、使用递归遍历文件夹整体思路1、使用File封装初始目录,2、打印这个目录3、获取这个目录下所有的子文件和子目录的数组。4、遍历这个数组,取出每个File对象4-1、如果File是否是一个文件,打印4-2、否则就是一个目录,递归调用代码实现publicclassSearchFile{publicstaticvoidmain(String[]args){//初始目录Filedir=newFile("d:/Dev");Datebeg
ES一、简介1、ElasticStackES技术栈:ElasticSearch:存数据+搜索;QL;Kibana:Web可视化平台,分析。LogStash:日志收集,Log4j:产生日志;log.info(xxx)。。。。使用场景:metrics:指标监控…2、基本概念Index(索引)动词:保存(插入)名词:类似MySQL数据库,给数据Type(类型)已废弃,以前类似MySQL的表现在用索引对数据分类Document(文档)真正要保存的一个JSON数据{name:"tcx"}二、入门实战{"name":"DESKTOP-1TSVGKG","cluster_name":"elasticsear
我对如何计算通过{%assignvar=0%}赋值的变量加一完全感到困惑。这应该是最简单的任务。到目前为止,这是我尝试过的:{%assignamount=0%}{%forvariantinproduct.variants%}{%assignamount=amount+1%}{%endfor%}Amount:{{amount}}结果总是0。也许我忽略了一些明显的东西。也许有更好的方法。我想要存档的只是获取运行的迭代次数。 最佳答案 因为{{incrementamount}}将输出您的变量值并且不会影响{%assign%}定义的变量,我
给定一个nxmbool数组:[[true,true,false],[false,true,true],[false,true,true]]有什么简单的方法可以返回“该列中有多少个true?”结果应该是[1,3,2] 最佳答案 使用转置得到一个数组,其中每个子数组代表一列,然后将每一列映射到其中的true数:arr.transpose.map{|subarr|subarr.count(true)}这是一个带有inject的版本,应该在1.8.6上运行,没有任何依赖:arr.transpose.map{|subarr|subarr.in