 规范标准日志格式,有利于正确的识别出日志关键元信息,以满足查询,告警和聚合计算的需求。从以上格式日志,通过filebeat转换后的结果如下:
规范标准日志格式,有利于正确的识别出日志关键元信息,以满足查询,告警和聚合计算的需求。从以上格式日志,通过filebeat转换后的结果如下: 时间戳,日志级别,线程名,类名,eventName,和自定义字段将被日志采集Agent解析后和其他元数据如域名,容器名或主机名一起以JSON格式上报。自定义字段是开发人员根据业务需要打印到日志,主要支持功能:
时间戳,日志级别,线程名,类名,eventName,和自定义字段将被日志采集Agent解析后和其他元数据如域名,容器名或主机名一起以JSON格式上报。自定义字段是开发人员根据业务需要打印到日志,主要支持功能: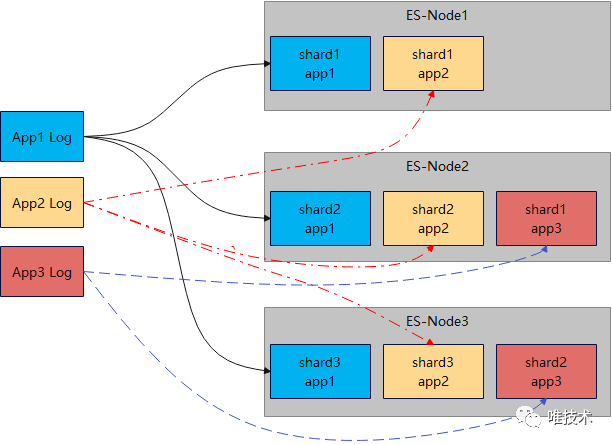 EFK日志存储在elasticsearch,每个域的日志以天粒度在ES创建一个索引,索引大小是根据前几日数据大小计算得出,每个索引分片大小不超过30G,日志量越多的域分片越多。如果一个域的日志量写入过大或超长,将会占用ES节点大量CPU来做解析和segment合并,这会影响其他域日志的正常写入,导致整体写入吞吐下降。排查是哪个域的哪个分片日志过大通常较为困难,在面对这种热点问题时经常要花很长时间。我们ES版本使用的是5.5,还不支持索引自动删除和冷热迁移,有几个脚本每日定时执行,完成删除索引,关闭索引,移动冷索引,创建新索引的任务,其中移动索引和创建新索引都是耗时非常长的操作。整个生命周期每天循环执行,如果突然一天某个步骤执行失败,或者执行时间太长,会导致整个生命周期拉长甚至无法完成,第二天的新数据写入将受到严重影响,甚至无法写入。另外ES的倒排索引需要对日志进行分词,产生的索引文件较大,占用了大量磁盘空间。不过ES也有其优点,基于倒排索引的特性使得ES查询时,1个分片只需要一个核即可完成查询,因为查询速度通常较快,QPS较高。下面是在大规模(或海量)日志存储场景下ES的主要存储优点和缺点:
EFK日志存储在elasticsearch,每个域的日志以天粒度在ES创建一个索引,索引大小是根据前几日数据大小计算得出,每个索引分片大小不超过30G,日志量越多的域分片越多。如果一个域的日志量写入过大或超长,将会占用ES节点大量CPU来做解析和segment合并,这会影响其他域日志的正常写入,导致整体写入吞吐下降。排查是哪个域的哪个分片日志过大通常较为困难,在面对这种热点问题时经常要花很长时间。我们ES版本使用的是5.5,还不支持索引自动删除和冷热迁移,有几个脚本每日定时执行,完成删除索引,关闭索引,移动冷索引,创建新索引的任务,其中移动索引和创建新索引都是耗时非常长的操作。整个生命周期每天循环执行,如果突然一天某个步骤执行失败,或者执行时间太长,会导致整个生命周期拉长甚至无法完成,第二天的新数据写入将受到严重影响,甚至无法写入。另外ES的倒排索引需要对日志进行分词,产生的索引文件较大,占用了大量磁盘空间。不过ES也有其优点,基于倒排索引的特性使得ES查询时,1个分片只需要一个核即可完成查询,因为查询速度通常较快,QPS较高。下面是在大规模(或海量)日志存储场景下ES的主要存储优点和缺点: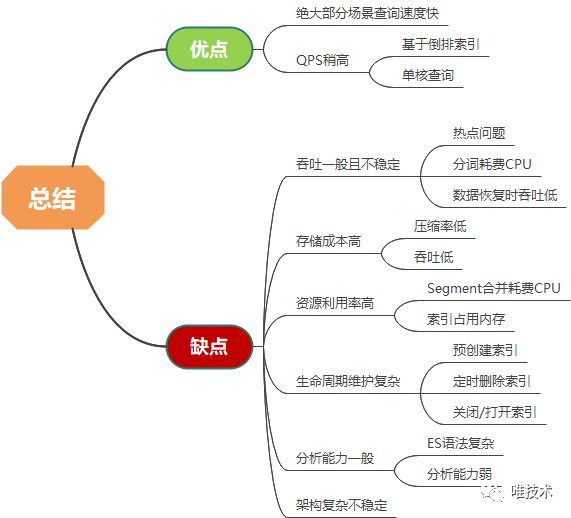
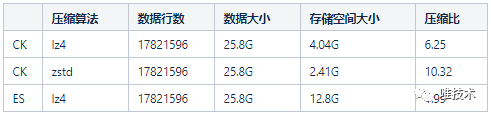 实际生产环境中zstd的日志压缩比更高,这和应用日志的相似度有关,最大达到15.8。
实际生产环境中zstd的日志压缩比更高,这和应用日志的相似度有关,最大达到15.8。 Clickhouse压缩率这么高,但没有索引,其查询速度如何?虽然没有索引,但其向量执行和SIMD配合多核CPU,可以大大缓解没有全文索引的缺点。经过多次测试对比后,其查询速度在绝大多数场景下和ES不相上下,在部分场景下甚至比ES还要快。下图是实际生产环境的数千个应用真实运行数据,查询24小时时间范围内日志和24小时以上时间范围日志的耗时对比。
Clickhouse压缩率这么高,但没有索引,其查询速度如何?虽然没有索引,但其向量执行和SIMD配合多核CPU,可以大大缓解没有全文索引的缺点。经过多次测试对比后,其查询速度在绝大多数场景下和ES不相上下,在部分场景下甚至比ES还要快。下图是实际生产环境的数千个应用真实运行数据,查询24小时时间范围内日志和24小时以上时间范围日志的耗时对比。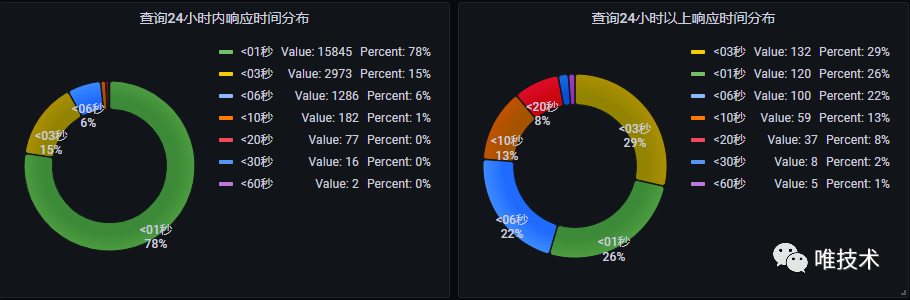 通过对日志的应用场景分析,我们发现万亿级别的日志,真正能被查询的日志数量是非常非常少的,这意味着ES对所有日志的分词索引,大多数是无效的,日志越多,这个分词消耗的资源越浪费。相对比clickhouse的MergeTree引擎专一的多,主要资源消耗是日志排序压缩和存储。另外Clickhouse的MPP架构使得集群非常稳定,几乎不要太多运维工作。下面以一幅图综合对比ES和Clickhouse的优缺点,说明为什么我们选择将clickhouse作为下一代日志存储数据库。
通过对日志的应用场景分析,我们发现万亿级别的日志,真正能被查询的日志数量是非常非常少的,这意味着ES对所有日志的分词索引,大多数是无效的,日志越多,这个分词消耗的资源越浪费。相对比clickhouse的MergeTree引擎专一的多,主要资源消耗是日志排序压缩和存储。另外Clickhouse的MPP架构使得集群非常稳定,几乎不要太多运维工作。下面以一幅图综合对比ES和Clickhouse的优缺点,说明为什么我们选择将clickhouse作为下一代日志存储数据库。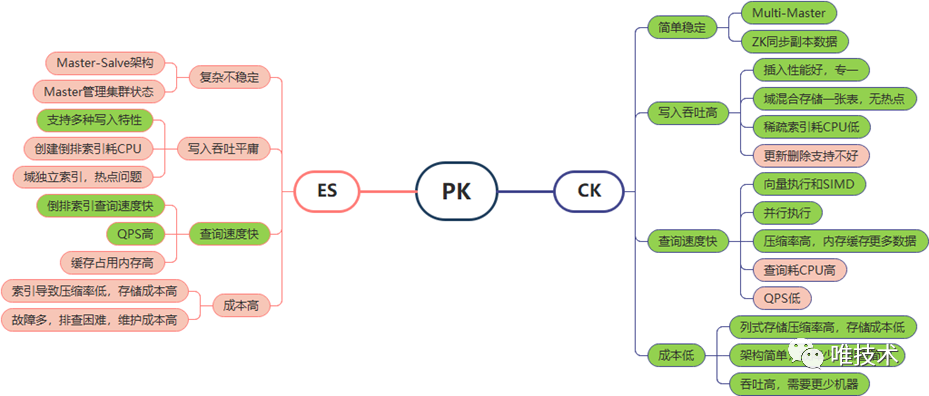
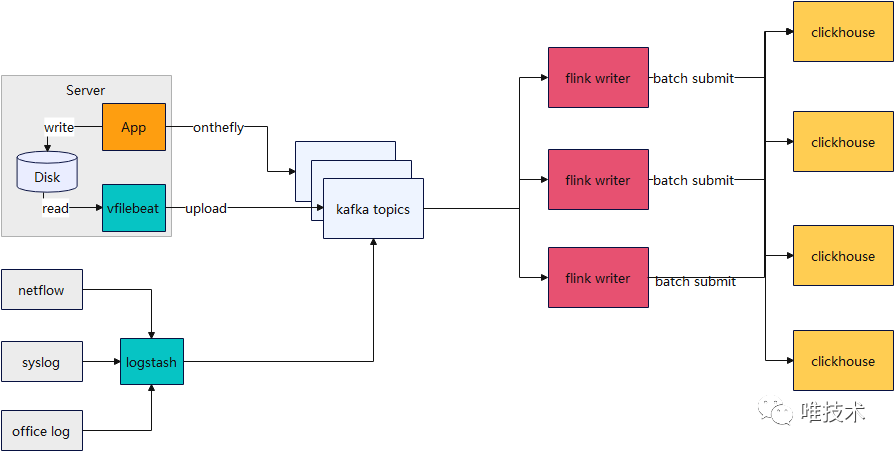
 writer把从kafka消费的数据先转换为结构化数据,vfilebeat上报的时候可能会上报一些日期较久的数据,太久的数据,报上来意义不大,并且会导致产生比较多的小part,消耗clickhosue cpu资源,这一步把这些过期超过三天的日期丢掉,无法解析的数据或者缺少必须字段的日志也会丢掉。经解析过滤后的数据再经过转换步骤,转换为clickhouse的表字段和类型。转换操作从schema和metadata表读取域日志存储的元信息,schema定义了clickhouse本地表和全局表名,字段信息,以及默认的日志字段和表字段的映射关系。metadata定义了域日志具体使用的schema信息,日志存储的时长,域分区字段值,域自定义字段映射到的表字段,通过这些域级别的配置信息,我们做到可以指定域存储的表,存储的时长,超大日志域独立分区存储,降低日志合并的CPU消耗。自定义字段默认是按照数组存储,有些域打印的自定义日志字段较多,在日志量大的情况下,速度较慢,配置了自定义映射物理字段存储,可以提供比数组更快的查询速度和压缩率。1)clickhouse表schema信息
writer把从kafka消费的数据先转换为结构化数据,vfilebeat上报的时候可能会上报一些日期较久的数据,太久的数据,报上来意义不大,并且会导致产生比较多的小part,消耗clickhosue cpu资源,这一步把这些过期超过三天的日期丢掉,无法解析的数据或者缺少必须字段的日志也会丢掉。经解析过滤后的数据再经过转换步骤,转换为clickhouse的表字段和类型。转换操作从schema和metadata表读取域日志存储的元信息,schema定义了clickhouse本地表和全局表名,字段信息,以及默认的日志字段和表字段的映射关系。metadata定义了域日志具体使用的schema信息,日志存储的时长,域分区字段值,域自定义字段映射到的表字段,通过这些域级别的配置信息,我们做到可以指定域存储的表,存储的时长,超大日志域独立分区存储,降低日志合并的CPU消耗。自定义字段默认是按照数组存储,有些域打印的自定义日志字段较多,在日志量大的情况下,速度较慢,配置了自定义映射物理字段存储,可以提供比数组更快的查询速度和压缩率。1)clickhouse表schema信息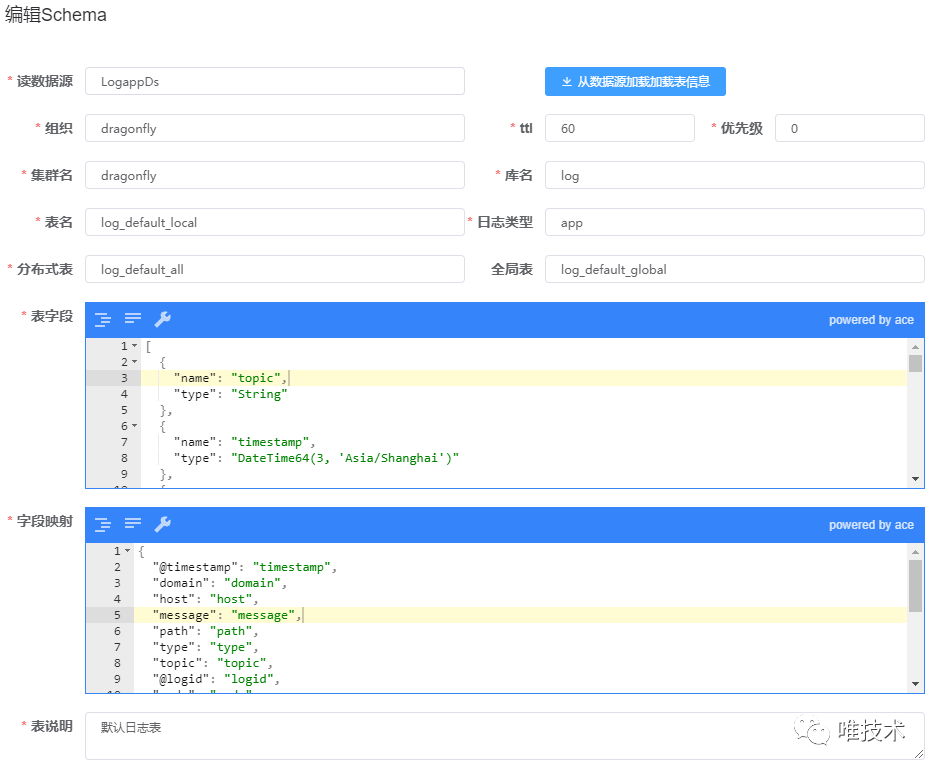 2)域自定义存储元数据信息
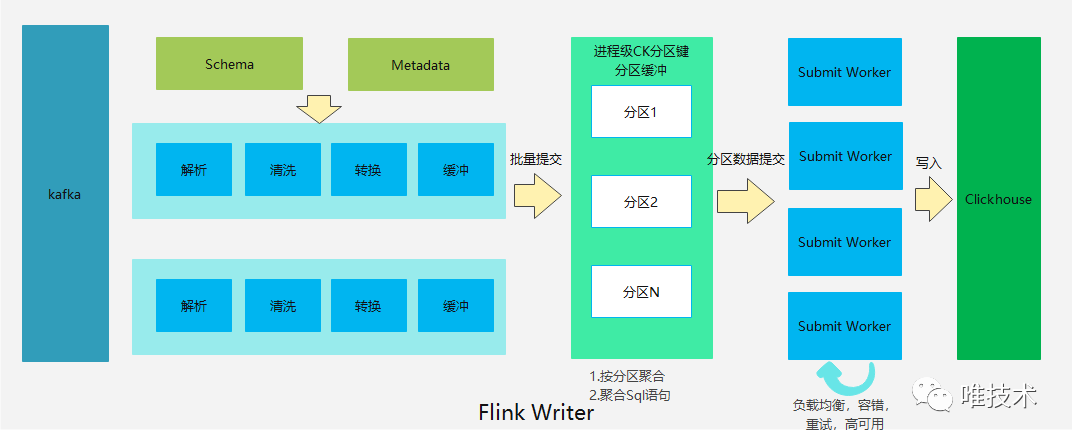
2)域自定义存储元数据信息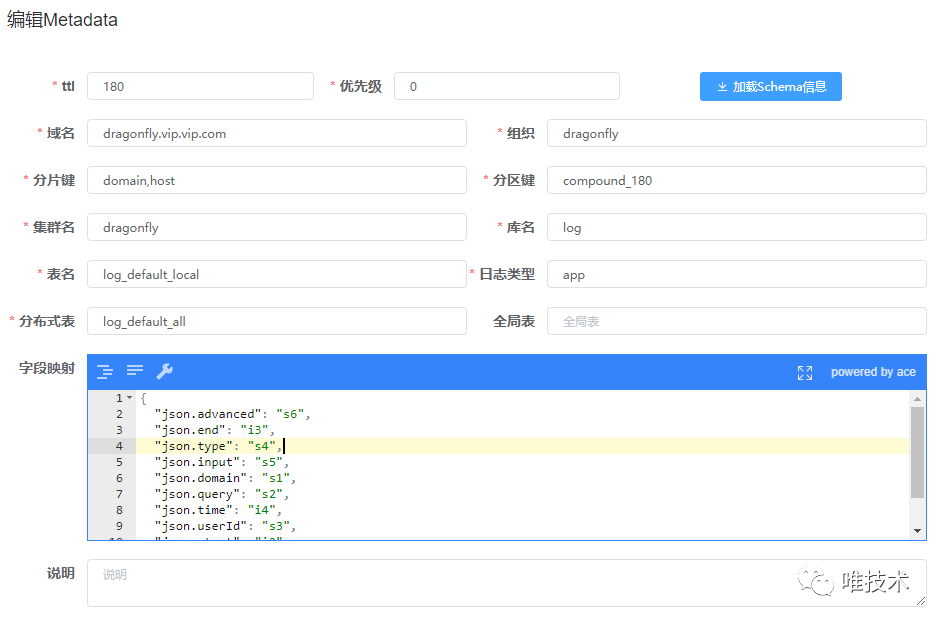 经过转换后的数据,携带了存储到CK表所需要的所有信息,将临时存储在本地的一个队列内,本地队列可能混合存储了多个域多张表的日志,达到指定的长度或时间后,再被提交到一个进程级的全局队列内。因为writer进程是多线程消费多个kafka分区,全局队列将同一个表多个线程的数据合并到一起,使得单次提交的批次更大,全局线程短暂缓冲,当满足写入条数,大小或超时后,数据将被作为一次写入,提交到submit worker线程。submit worker负责数据的写入,高可用,负载均衡,容错和重试等逻辑。submit收到提交的批量数据后,随机寻找一个可用的clickhosue分片,提交写入到分片节点。clickhouse集群配置是双副本,当一个副本节点失败时,将尝试切换写入到另一个节点上,如果两个都失败,则暂时剔除分片,重新寻找一个健康的分片写入。写入数据到Clickhouse我们使用的是clickhouse-jdbc,起初写入时消耗内存和CPU都较大,对jdbc源码进行分析后,我们发现jdbc写入数据时,先把所有数据转换成一个List对象,这个list对象相当于提交数据的byte[]副本格式,为了降低这个占用,在数据转换步骤我们进行优化,每条日志数据直接转换为jdbc可以直接使用的List数据,这样jdbc在构造生成SQL的时候,拿到的数据其实是List的一个引用,这个优化降低了约三分之一内存消耗。另外对writer进程做火焰图分析时,我们发现jdbc在生成SQL时,会把提交数据的每个字符进行判定,识别出特殊字符如'\', '\n', '\b'等做转义,这个转义操作使用的是map函数,在数据量大时,消耗了约17%的CPU,我们对此做了优化,使用swtich后,内存大幅降低,节约了13%的CPU消耗。clickhouse的弱集群概念保证了单节点宕机时,整个集群几乎不受影响,submit高可用保证了当节点异常时,数据仍然可以正常写入到健康节点,从而使得整个日志写入非常稳定,几乎没有因为节点宕机导致的延迟情况。关于日志摄入Clickhouse的方式,石墨开源了另一种摄入方式,创建KafkaEngine表直接消费clickhouse,再将数据导入到物化视图内,通过物化视图最终导入到本地表。这种方式好处是节省了一个writer的组件,上报到kafka的数据直接就可以存储到clickhouse,但缺点非常多:
经过转换后的数据,携带了存储到CK表所需要的所有信息,将临时存储在本地的一个队列内,本地队列可能混合存储了多个域多张表的日志,达到指定的长度或时间后,再被提交到一个进程级的全局队列内。因为writer进程是多线程消费多个kafka分区,全局队列将同一个表多个线程的数据合并到一起,使得单次提交的批次更大,全局线程短暂缓冲,当满足写入条数,大小或超时后,数据将被作为一次写入,提交到submit worker线程。submit worker负责数据的写入,高可用,负载均衡,容错和重试等逻辑。submit收到提交的批量数据后,随机寻找一个可用的clickhosue分片,提交写入到分片节点。clickhouse集群配置是双副本,当一个副本节点失败时,将尝试切换写入到另一个节点上,如果两个都失败,则暂时剔除分片,重新寻找一个健康的分片写入。写入数据到Clickhouse我们使用的是clickhouse-jdbc,起初写入时消耗内存和CPU都较大,对jdbc源码进行分析后,我们发现jdbc写入数据时,先把所有数据转换成一个List对象,这个list对象相当于提交数据的byte[]副本格式,为了降低这个占用,在数据转换步骤我们进行优化,每条日志数据直接转换为jdbc可以直接使用的List数据,这样jdbc在构造生成SQL的时候,拿到的数据其实是List的一个引用,这个优化降低了约三分之一内存消耗。另外对writer进程做火焰图分析时,我们发现jdbc在生成SQL时,会把提交数据的每个字符进行判定,识别出特殊字符如'\', '\n', '\b'等做转义,这个转义操作使用的是map函数,在数据量大时,消耗了约17%的CPU,我们对此做了优化,使用swtich后,内存大幅降低,节约了13%的CPU消耗。clickhouse的弱集群概念保证了单节点宕机时,整个集群几乎不受影响,submit高可用保证了当节点异常时,数据仍然可以正常写入到健康节点,从而使得整个日志写入非常稳定,几乎没有因为节点宕机导致的延迟情况。关于日志摄入Clickhouse的方式,石墨开源了另一种摄入方式,创建KafkaEngine表直接消费clickhouse,再将数据导入到物化视图内,通过物化视图最终导入到本地表。这种方式好处是节省了一个writer的组件,上报到kafka的数据直接就可以存储到clickhouse,但缺点非常多: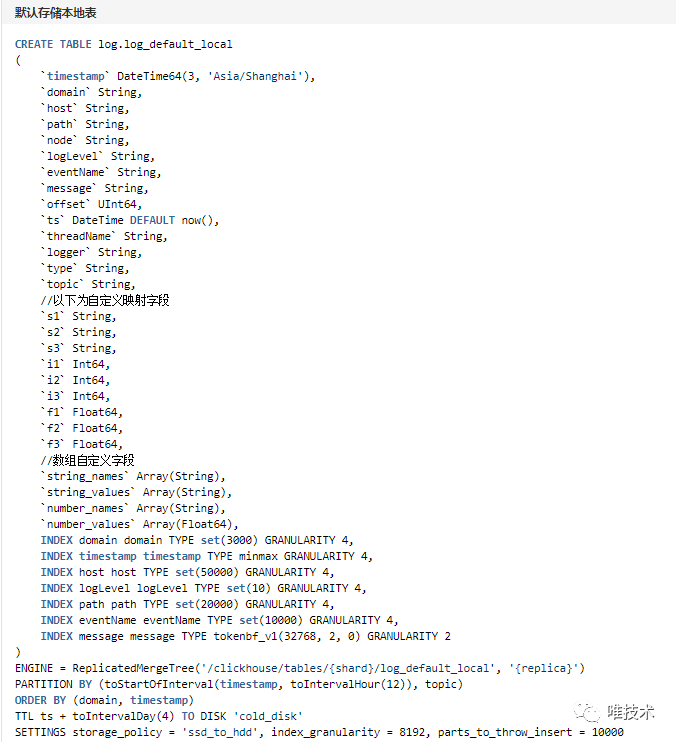
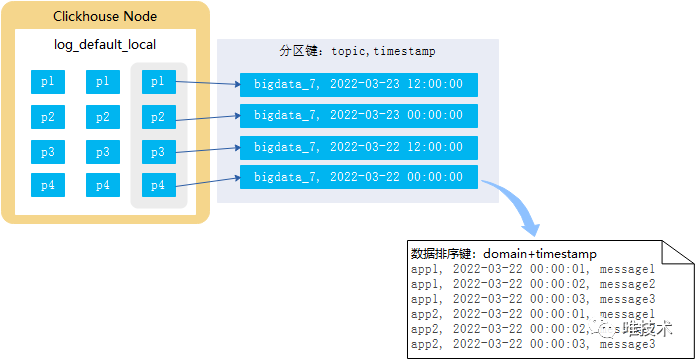 MergeTree采用类似LSM-Tree数据结构存储,每次提交的批量数据,按照表的分区键,分别保存到不同的part目录内,一个part内的行数据按照排序键进行排序后,再按列压缩存储到不同的文件内,Clickhouse后台任务会持续对这些每个小型的part进行合并,生成更大的part。MergeTree虽然没有ES的倒排索引,但有更轻量级的分区键,主键索引和跳数索引。
MergeTree采用类似LSM-Tree数据结构存储,每次提交的批量数据,按照表的分区键,分别保存到不同的part目录内,一个part内的行数据按照排序键进行排序后,再按列压缩存储到不同的文件内,Clickhouse后台任务会持续对这些每个小型的part进行合并,生成更大的part。MergeTree虽然没有ES的倒排索引,但有更轻量级的分区键,主键索引和跳数索引。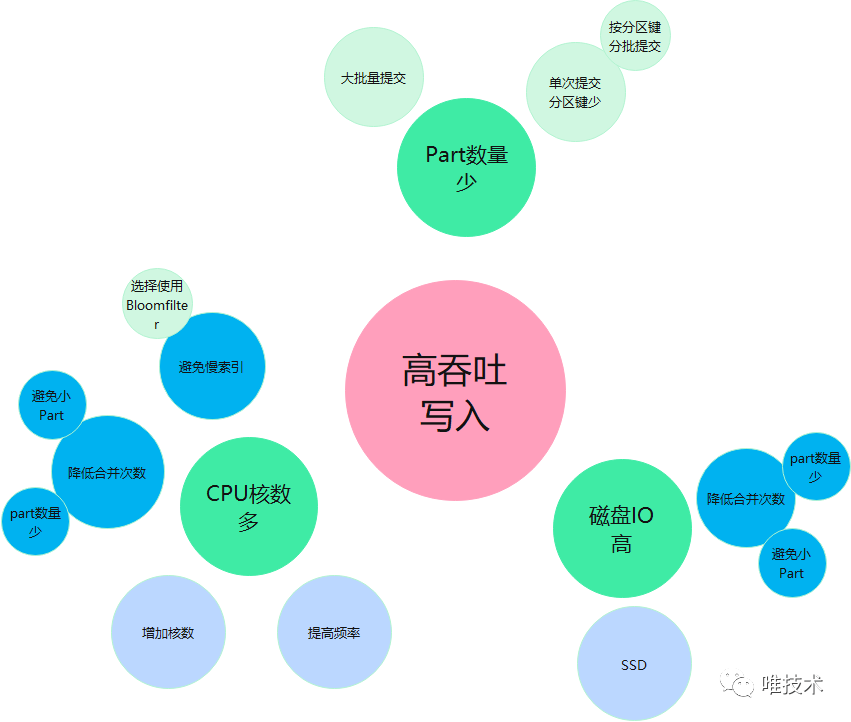 将图中的方法按照实现手段进行分类:
将图中的方法按照实现手段进行分类: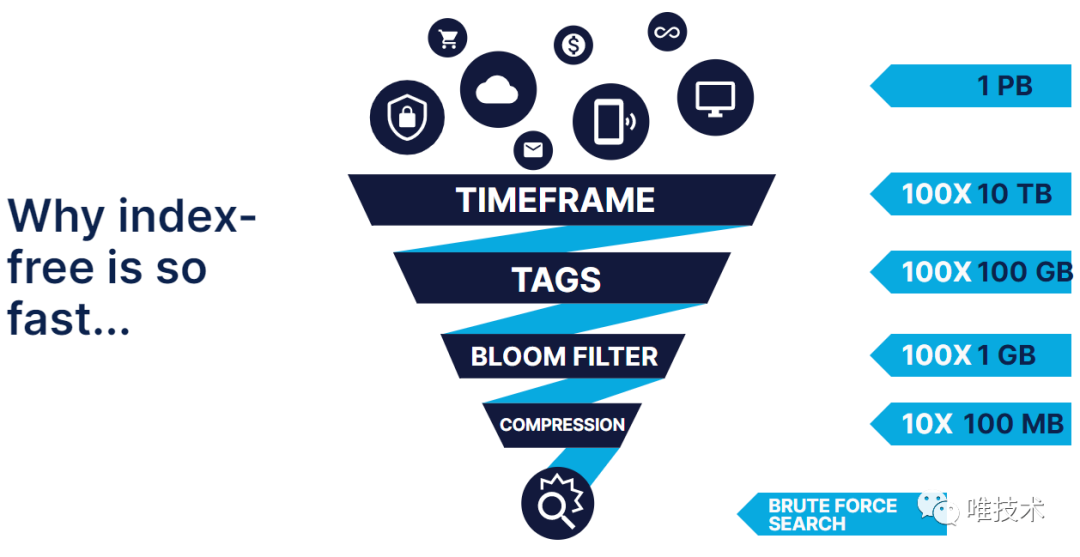 1PB的数据存储,没有了全文索引的情况,直接暴力检索一个关键字,肯定是超时的,如果先经过时间,标签以及bloomfilter进行过滤筛选后,再执行暴力搜索,则需要检索的数据量会小的多。MergeTree引擎是列式存储,压缩率很高,高压缩率有很多优势,从磁盘读取的数据量少,页面缓存需要的内存少,更多的文件可以缓存在高速内存中,Clickhouse有和Humio一样的向量化执行和SIMD,在查询时,这些内存中的压缩数据块会被CPU批量的执行SIMD指令,由于块足够小,通常为压缩前1M,这样函数向量执行和SIMD计算的数据足够全部放在cpu缓存内,不仅减少了函数调用次数,并且cpu cache的miss率大大降低。查询速度相比没有向量执行和SIMD有数倍提升。
1PB的数据存储,没有了全文索引的情况,直接暴力检索一个关键字,肯定是超时的,如果先经过时间,标签以及bloomfilter进行过滤筛选后,再执行暴力搜索,则需要检索的数据量会小的多。MergeTree引擎是列式存储,压缩率很高,高压缩率有很多优势,从磁盘读取的数据量少,页面缓存需要的内存少,更多的文件可以缓存在高速内存中,Clickhouse有和Humio一样的向量化执行和SIMD,在查询时,这些内存中的压缩数据块会被CPU批量的执行SIMD指令,由于块足够小,通常为压缩前1M,这样函数向量执行和SIMD计算的数据足够全部放在cpu缓存内,不仅减少了函数调用次数,并且cpu cache的miss率大大降低。查询速度相比没有向量执行和SIMD有数倍提升。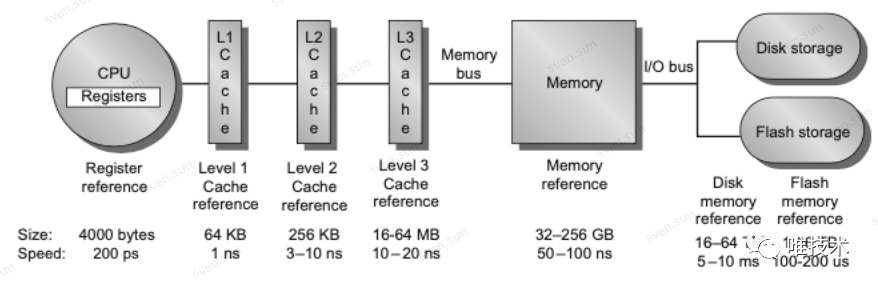
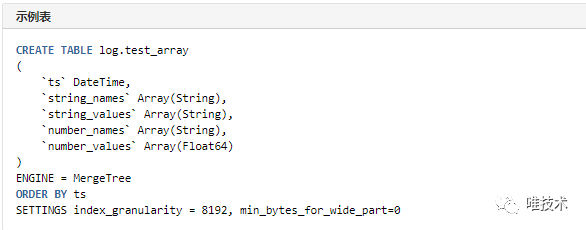 [type]_names和[type]_values分别存储对应数据类型字段的名称和值。1)插入
[type]_names和[type]_values分别存储对应数据类型字段的名称和值。1)插入 多层嵌套的json字段将被打平存储,例如{"json": {"name": "tom"}}将转换为 json_name="tom"字段。不再支持数组的存储,数组字段值将被转换为字符串存储,例如:{"json": [{"name": "tom", "age": 18}]},转换为json="[{\"name\": \"tom\", \"age\": 18}]"。2)查询
多层嵌套的json字段将被打平存储,例如{"json": {"name": "tom"}}将转换为 json_name="tom"字段。不再支持数组的存储,数组字段值将被转换为字符串存储,例如:{"json": [{"name": "tom", "age": 18}]},转换为json="[{\"name\": \"tom\", \"age\": 18}]"。2)查询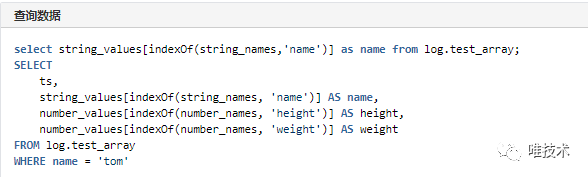 原来的映射自定义字段目前仍然保留10个,如果不够,可以随时添加,可以支持一些域的固定自定义字段,或者一些特殊类型的日志,例如审计日志,系统日志等,这些字段在查询的时候用户可以使用原来的名称,访问Clickhouse之前会被替换为表字段名称自定义字段的另一个方案是存储在map内,可以节约两个字段,查询也更简单,但经过我们测试,查询性能没有数组好:
原来的映射自定义字段目前仍然保留10个,如果不够,可以随时添加,可以支持一些域的固定自定义字段,或者一些特殊类型的日志,例如审计日志,系统日志等,这些字段在查询的时候用户可以使用原来的名称,访问Clickhouse之前会被替换为表字段名称自定义字段的另一个方案是存储在map内,可以节约两个字段,查询也更简单,但经过我们测试,查询性能没有数组好: 新版查询会自动对用户输入的查询语句进行分析,添加上查询的应用域名和时间范围等,降低用户操作难度,支持多租户隔离。自定义字段的查询是非常繁琐的,我们也做了一个简化操作:
新版查询会自动对用户输入的查询语句进行分析,添加上查询的应用域名和时间范围等,降低用户操作难度,支持多租户隔离。自定义字段的查询是非常繁琐的,我们也做了一个简化操作: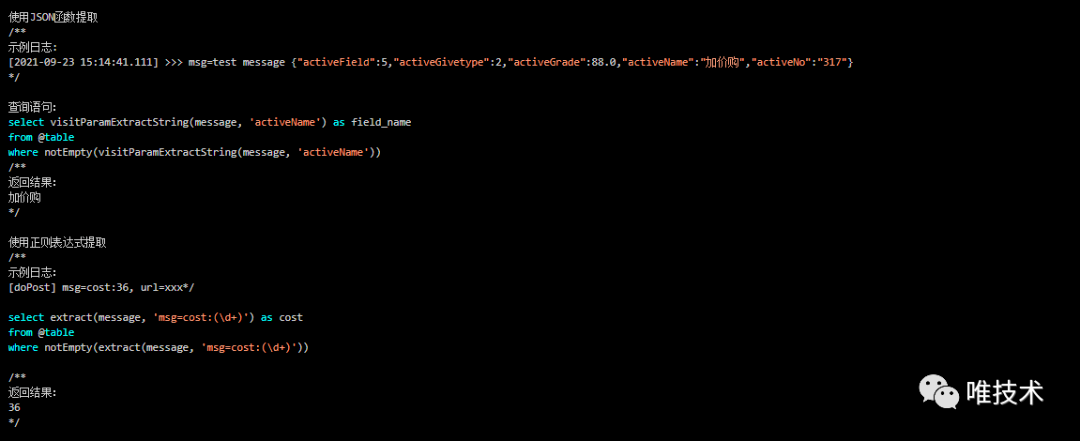

电脑0x0000001A蓝屏错误怎么U盘重装系统教学分享。有用户电脑开机之后遇到了系统蓝屏的情况。系统蓝屏问题很多时候都是系统bug,只有通过重装系统来进行解决。那么蓝屏问题如何通过U盘重装新系统来解决呢?来看看以下的详细操作方法教学吧。 准备工作: 1、U盘一个(尽量使用8G以上的U盘)。 2、一台正常联网可使用的电脑。 3、ghost或ISO系统镜像文件(Win10系统下载_Win10专业版_windows10正式版下载-系统之家)。 4、在本页面下载U盘启动盘制作工具:系统之家U盘启动工具。 U盘启动盘制作步骤: 注意:制作期间,U盘会被格式化,因此U盘中的重要文件请注
在应用开发中,有时候我们需要获取系统的设备信息,用于数据上报和行为分析。那在鸿蒙系统中,我们应该怎么去获取设备的系统信息呢,比如说获取手机的系统版本号、手机的制造商、手机型号等数据。1、获取方式这里分为两种情况,一种是设备信息的获取,一种是系统信息的获取。1.1、获取设备信息获取设备信息,鸿蒙的SDK包为我们提供了DeviceInfo类,通过该类的一些静态方法,可以获取设备信息,DeviceInfo类的包路径为:ohos.system.DeviceInfo.具体的方法如下:ModifierandTypeMethodDescriptionstatic StringgetAbiList()Obt
文章目录一、概述简介原理模块二、配置Mysql使用版本环境要求1.操作系统2.mysql要求三、配置canal-server离线下载在线下载上传解压修改配置单机配置集群配置分库分表配置1.修改全局配置2.实例配置垂直分库水平分库3.修改group-instance.xml4.启动监听四、配置canal-adapter1修改启动配置2配置映射文件3启动ES数据同步查询所有订阅同步数据同步开关启动4.验证五、配置canal-admin一、概述简介canal是Alibaba旗下的一款开源项目,Java开发。基于数据库增量日志解析,提供增量数据订阅&消费。Git地址:https://github.co
需求:要创建虚拟机,就需要给他提供一个虚拟的磁盘,我们就在/opt目录下创建一个10G大小的raw格式的虚拟磁盘CentOS-7-x86_64.raw命令格式:qemu-imgcreate-f磁盘格式磁盘名称磁盘大小qemu-imgcreate-f磁盘格式-o?1.创建磁盘qemu-imgcreate-fraw/opt/CentOS-7-x86_64.raw10G执行效果#ls/opt/CentOS-7-x86_64.raw2.安装虚拟机使用virt-install命令,基于我们提供的系统镜像和虚拟磁盘来创建一个虚拟机,另外在创建虚拟机之前,提前打开vnc客户端,在创建虚拟机的时候,通过vnc
ES一、简介1、ElasticStackES技术栈:ElasticSearch:存数据+搜索;QL;Kibana:Web可视化平台,分析。LogStash:日志收集,Log4j:产生日志;log.info(xxx)。。。。使用场景:metrics:指标监控…2、基本概念Index(索引)动词:保存(插入)名词:类似MySQL数据库,给数据Type(类型)已废弃,以前类似MySQL的表现在用索引对数据分类Document(文档)真正要保存的一个JSON数据{name:"tcx"}二、入门实战{"name":"DESKTOP-1TSVGKG","cluster_name":"elasticsear
因为我现在正在做一些时间测量,我想知道是否可以在不使用Benchmark类或命令行实用程序time的情况下测量用户时间或系统时间。使用Time类只显示挂钟时间,而不显示系统和用户时间,但是我正在寻找具有相同灵active的解决方案,例如time=TimeUtility.now#somecodeuser,system,real=TimeUtility.now-time原因是我有点不喜欢Benchmark,因为它不能只返回数字(编辑:我错了-它可以。请参阅下面的答案。)。当然,我可以解析输出,但感觉不对。*NIX系统的time实用程序也应该可以解决我的问题,但我想知道是否已经在Ruby中实
在Ruby中,以毫秒为单位获取自纪元(1970)以来的当前系统时间的正确方法是什么?我试过了Time.now.to_i,好像不是我想要的结果。我需要结果显示毫秒并且使用long类型,而不是float或double。 最佳答案 (Time.now.to_f*1000).to_iTime.now.to_f显示包含十进制数字的时间。要获得毫秒数,只需将时间乘以1000。 关于ruby-以毫秒为单位获取当前系统时间,我们在StackOverflow上找到一个类似的问题:
如何在出现异常时指定全局救援,如果您将Sinatra用于API或应用程序,您将如何处理日志记录? 最佳答案 404可以在not_found方法的帮助下处理,例如:not_founddo'Sitedoesnotexist.'end500s可以通过调用带有block的错误方法来处理,例如:errordo"Applicationerror.Plstrylater."end错误的详细信息可以通过request.env中的sinatra.error访问,如下所示:errordo'Anerroroccured:'+request.env['si
我正在使用ruby标准记录器,我想要每天轮换一次,所以在我的代码中我有:Logger.new("#{$ROOT_PATH}/log/errors.log",'daily')它运行完美,但它创建了两个文件errors.log.20130217和errors.log.20130217.1。如何强制它每天只创建一个文件? 最佳答案 您的代码对于长时间运行的应用程序是正确的。发生的事情是您在给定的一天多次运行代码。第一次运行时,Ruby会创建一个日志文件“errors.log”。当日期改变时,Ruby将文件重命名为“errors.log
在运行Cucumber测试时,我得到(除了测试结果)大量调试/日志相关的输出形式:D,[2013-03-06T12:21:38.911829#49031]DEBUG--:SOAPrequest:D,[2013-03-06T12:21:38.911919#49031]DEBUG--:Pragma:no-cache,SOAPAction:"",Content-Type:text/xml;charset=UTF-8,Content-Length:1592W,[2013-03-06T12:21:38.912360#49031]WARN--:HTTPIexecutesHTTPPOSTusingt